In part two of this series on getting started with Oracle Database In-Memory I’ll explain how and when objects are populated into the In-Memory column store (IM column store) and exactly how you can control it.
Which objects are populated into the IM column store?
As I mentioned last week, only objects with the INMEMORY attribute are populated into the IM column store. The INMEMORY attribute can be specified on a tablespace, table, (sub)partition, or materialized view. In this example, the INMEMORY attribute is specified on the customers.
ALTER TABLE SH.customers INMEMORY;
By default, all of the columns in the CUSTOMERS table will be populated into the IM column store, as they automatically inherit the INMEMORY attribute from the table. However, it is possible to populate only a subset of the columns if desired by over-riding the inherited attribute.
For example, the following statement sets the In-Memory attribute on the sales table, in the SH sample schema, but it excludes the column prod_id.
ALTER TABLE SH.sales INMEMORY NO INMEMORY(prod_id);
Similarly, for a partitioned table, all of the table’s partitions inherit the INMEMORY attribute but it’s possible to populate just a subset of the partitions or sub-partitions.
However, it’s not possible to specify a subset of columns to be put into the IM column store, as INMEMORY is a segment level attribute, not a column-level attribute.
You can identify which tables have the INMEMORY attributes by looking at the new INMEMORY column in the *_TABLES dictionary tables. It’s a Boolean column, which can be set to either ENABLED or DISABLED.

In the example above you will notice that two of the tables – COSTS and SALES – don’t have a value for this Boolean column INMEMORY.
Remember, the INMEMORY attribute is a segment level attribute. Both COSTS and SALES are partitioned tables and are therefore logical objects. The INMEMORY attribute for these tables will be recorded at the partition, or sub-partition, level in *_TAB_(SUB)PARTITIONS.
How are objects populated into the IM column store?
The IM column store is populated by a set of background processes referred to as worker processes (ora_w001_orcl). Each worker process is given a subset of database blocks from the object to populate into the IM column store. Population is a streaming mechanism, simultaneously columnizing and compressing the data.
The compression used during the population of the IM column store is different from any of Oracle’s previous types of compression. These new compression algorithms not only help save space but also improve query performance by allowing queries to execute directly against the compressed columns. This means all scanning and filtering operations will execute on a much smaller amount of data. Data is only decompressed when it is required for the result set.
In-memory compression is specified using the keyword MEMCOMPRESS, a sub-clause of the INMEMORY attribute. There are six levels, each of which provides a different level of compression and performance. In this example, the orders table is partitioned and several of the partitions have been specified with a different type of in-memory compression.
CREATE TABLE orders(…)
PARTITION BY
RANGE()
( PARTITION p1 VALUES LESS
THAN (..)
INMEMORY NO MEMCOMPRESS,
PARTITION p2 VALUES LESS
THAN (..)
INMEMORY MEMCOMPRESS FOR DML,
PARTITION p3 VALUES LESS
THAN (..)
INMEMORY MEMCOMPRESS FOR QUERY,
:
PARTITION p200 VALUES LESS
THAN (..)
INMEMORY MEMCOMPRESS FOR CAPACITY);
You can identify which type of MEMCOMPRESS a table or partition has by looking at the new INMEMORY_COMPRESSION column in the *_TABLES dictionary tables.

When are objects populated into the IM column store?
Objects are populated into the IM column store either in a prioritized list immediately after the database is opened or after they are scanned (queried) for the first time. The order in which objects are populated is controlled by the keyword PRIORITY, a sub-clause of the INMEMORY attribute. There are five levels from CRITICAL to NONE.
ALTER TABLE SH.products INMEMORY PRIORITY LOW;
The default PRIORITY is NONE, which means an object is populated only after it is scanned for the first time. All objects at a given priority level must be fully populated before the population for any objects at a lower priority level can commence. However, the population order can be superseded if an object without a PRIORITY is scanned, triggering its population into the IM column store.
You can identify which PRIORITY level has been specified on a table or partition has by looking at the new INMEMORY_PRIORITY column in the *_TABLES dictionary tables.

Monitoring what’s populated into the IM column store
As I mentioned last week, there are two new v$ views, v$IM_SEGMENTS and v$IM_USER_SEGMENTS that can be used to monitor the contents of the IM column store. These views show which objects are currently populated, or being populated, into the IM column store (POPULATE_STATUS), as well as indicating whether the entire object has been populated (BYTES_NOT_POPULATED).
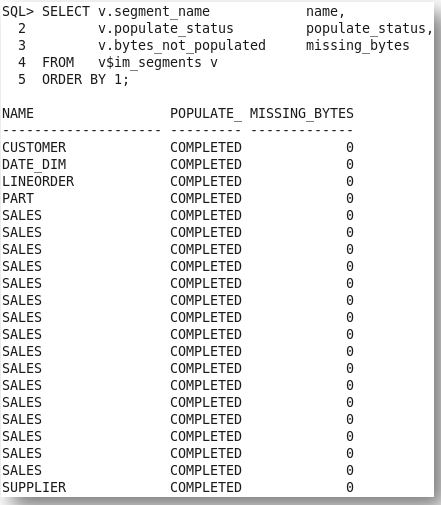
It is also possible to use these views to determine the compression ratio achieved for each object populated in the IM column store, assuming the objects were not compressed on disk, by comparing their in-memory size (INMEMORY_SIZE) to their size on disk (BYTES).
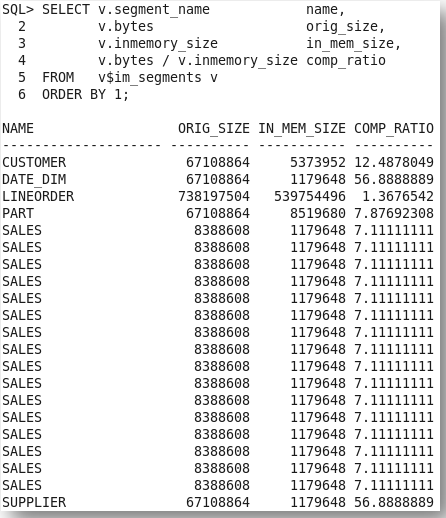
In the example above, the compression ratios vary from 1.4X to 56.8X, depending on the compression option chosen, the datatypes used and the contents of the table.
In next week’s post, I will explain why scanning and filtering are so much faster in the IM column store versus the buffer cache even though they are both in-memory.
Original publish date: August 4, 2014
