We are excited to announce that Oracle Cloud Infrastructure Kubernetes Engine (OKE) now supports RDMA connected OCI Compute Clusters for managed node pools to enable fast networking between worker nodes.
AI and high-performance computing workloads are pushing the infrastructure beneath Kubernetes clusters harder than ever. Distributed training, fine-tuning, and multi-node inferencing all depend on fast communication between compute instances. When thousands of GPUs are working together, network latency can become the difference between near-linear scaling and expensive idle time.
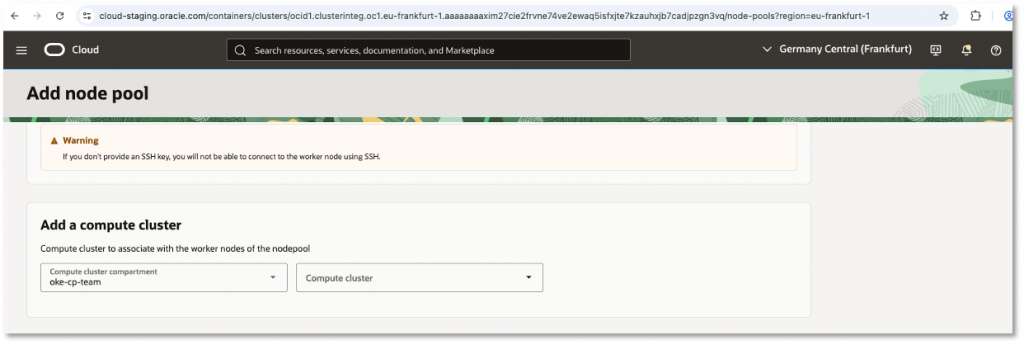
What are OCI Compute Clusters?
Compute Clusters are OCI Compute resources that provide high-bandwidth, ultra-low-latency networking between supported bare metal instances. Each node in a Compute Cluster is placed in close physical proximity to the others and connected through a remote direct memory access (RDMA) network. This RDMA fabric can deliver latency as low as single-digit microseconds.
Why does RDMA matter?
RDMA matters because because it reduces latency for workloads distributed across multiple nodes, a common pattern for AI/ML workloads. For example, during training, GPUs continuously exchange gradients, parameters, checkpoints, and intermediate data. When those exchanges cross host boundaries, they are impacted by network latency. As the number of GPUs in a training cluster increases, the network communication between those GPUs can end up taking up an even greater percentage of training time than the time required for computation, time during which high cost GPUs are sitting underutilized or idle. RDMA allows data to move directly between memory on different hosts, reducing overhead and helping keep accelerators fed with work. For workloads spanning multiple nodes, faster node-to-node communication can help improve throughput and scaling efficiency, improve GPU utilization, and reduce time to result. Put another way, RDMA networks with microsecond latencies can help turn every second a customer is paying for GPUs into realized business value.
Previously, since OKE managed node pools did not support launching instances in Compute Clusters or Cluster Networks, to use RDMA-capable networking customers were limited to self-managed worker nodes. While this addressed a fundamental need, it came with unnecessary management overhead: customers needed to manually manage all node lifecycle tasks, including image upgrades, bootstrapping, and scaling, without the native benefits provided by OKE managed node pools. That option remains useful for teams that want deep control over their worker node lifecycle. But many customers also want the operational simplicity of managed node pools. With this release, customers can now run RDMA-capable workloads on managed node pools by specifying a Compute Cluster when creating a managed node pool.
How do I use RDMA with OKE managed node pools?
Before creating a managed node pool in a Compute Cluster, there are a few requirements to keep in mind:
- The OKE cluster must be an enhanced cluster.
- The Compute Cluster must already exist in OCI Compute and be in the ACTIVE lifecycle state.
- The node pool must use a shape that supports RDMA and Compute Clusters.
- Its placement configuration must include only the availability domain that contains the Compute Cluster, and fault domains must not be specified because fault domain placement is managed by the Compute service.
- Customers also need the required IAM policy so OKE can use the Compute Cluster when launching worker node instances.
Once those prerequisites are met, simply create a new managed node pool, select the compartment that contains the Compute Cluster, and then select the Compute Cluster. When OKE creates worker nodes for that node pool, the instances backing them will be launched into the selected Compute Cluster.
Keep in mind you can only specify a Compute Cluster when creating the managed node pool. You cannot add, remove, or change the Compute Cluster later. This gives teams access to RDMA-capable networking while retaining managed node pool operations such as scaling, host OS and Kubernetes upgrades, and node replacement. Managed node pools also support day-two operational features such as configurable cordon and drain behavior, worker node property updates through node cycling, image and shape management for new nodes, and integration with OKE autoscaling patterns.
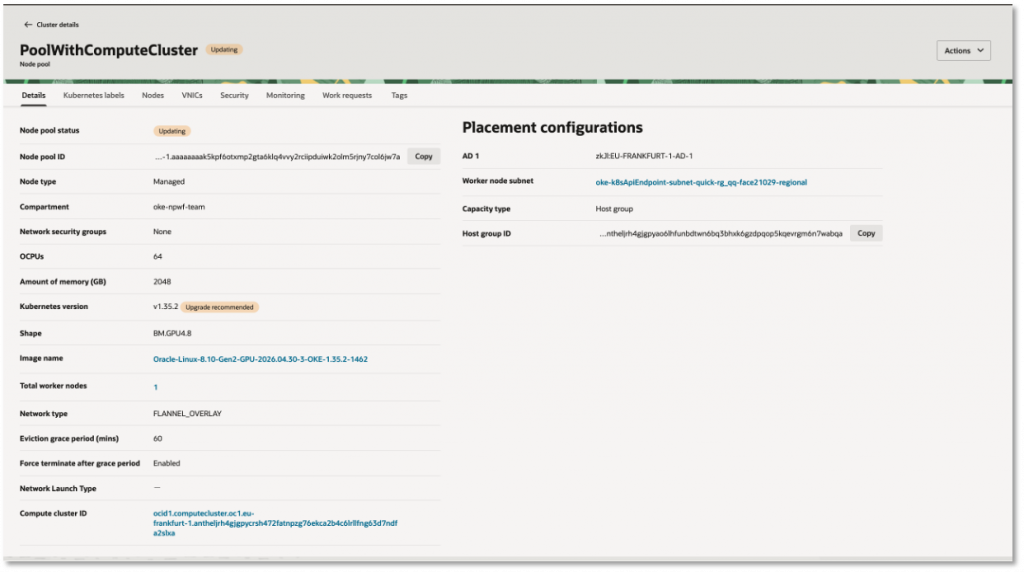
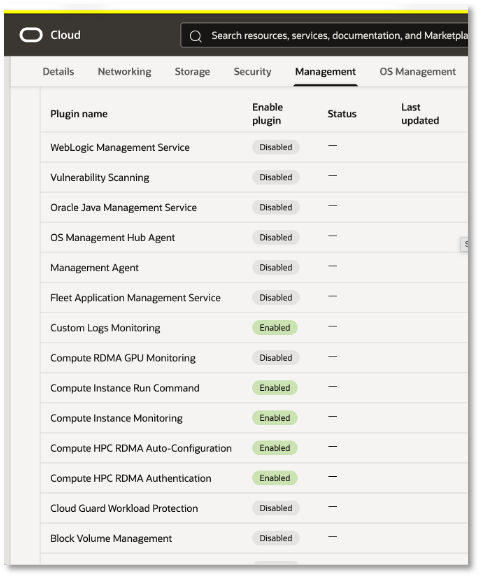
OKE also simplifies RDMA setup for these managed nodes. When a Compute Cluster is specified for a managed node pool, OKE automatically enables the Oracle Cloud Agent HPC plugins required for RDMA networking, including the Compute HPC RDMA Authentication plugin and the Compute HPC RDMA Auto-Configuration plugin.
Conclusion
This release brings together two important parts of OCI: the performance of Compute Clusters and the operational experience of OKE managed nodes. For platform teams, it means less custom node lifecycle management. For AI and HPC teams, it means access to the low-latency RDMA fabric they need for demanding distributed workloads. And for organizations standardizing on Kubernetes, it makes OKE an even stronger foundation for production AI/ML at scale.
Learn more
- Using Compute Clusters to Provision Managed Nodes Documentation
- OCI Kubernetes Engine (OKE) support for Compute Clusters Release Note
- OCI Compute Clusters
- Get started with Oracle Cloud Infrastructure today with our Oracle Cloud Free Trial
