Oracle Cloud Infrastructure Kubernetes Engine (OKE) now supports OCI Compute host groups for managed node pools, including the ability to quickly recycle those instances to minimize host unavailability.
Customers commonly terminate and replace worker nodes in Kubernetes clusters to address health issues and apply updates. In the case of customers with worker nodes backed bare metal shapes, for example those in use for AI/ML workloads requiring GPU accelerators, those nodes can face long termination and replacement times due to the process to ensure instances are cleaned, healthy, compliant, and secure. For customers, with dedicated capacity, OCI Compute supports the ability to “Quick Recycle” instances, by skipping the standard OCI host provisioning process to quickly make a host available for reuse after an instance is terminated.
Terminating and replacing worker nodes
In Kubernetes environments, instances are often terminated and replaced as part of routine operations: scaling node pools, applying updates, recovering unhealthy nodes, refreshing images, etc. The faster a terminated worker node can be replaced, the faster the cluster can restore capacity and return workloads to their desired state.
Customers using bare metal shapes, for example those with AI/ML workloads using GPU instances to maximize the performance of their model training, have the same need to apply updates to their nodes or address health issues. However, until now, they faced a long recycle time to relaunch new instances due to the time required for bare metal instances to be wiped, potentially physically repaired, and moved into the pool to be relaunched.
Quick recycle
The ability to quickly terminate and replace instances is especially valuable for customers running large-scale, performance-sensitive, or infrastructure-intensive workloads where worker node replacement time matters. Quick recycle helps reduce that downtime. Quick recycle is a compute host group capability that can make a host available for reuse more quickly after the worker node instance on that host is terminated. For OKE, this means that when a managed worker node instance is terminated, the underlying host can become available sooner for a replacement worker node instance, depending on the compute host group configuration.
Quick recycle works by skipping the standard OCI host provisioning process before the host is returned for reuse. This can minimize the time a host is unavailable after an instance is terminated. However, the standard host provisioning process exists for a reason: It helps ensure hosts are cleaned, healthy, compliant, and secure. For that reason, we recommend using quick recycle only with dedicated capacity, where you reserve a fixed amount of compute capacity for your exclusive use by committing to pay for it ahead of time. Hosts that are shared or used in production environments should go through full recycle.
Previously, since OKE managed node pools did not support launching instances in host groups, which are required for quick recycle, customers were limited to using self-managed worker nodes to leverage host groups. While this approach allowed for instances to be quickly recycled, it came with unnecessary management overhead: customers needed to manually manage all node lifecycle tasks, including image upgrades, bootstrapping, and scaling, without the native benefits provided by OKE managed node pools. That option remains useful for teams that want deep control over their worker node lifecycle. But many customers also want the operational simplicity offered by managed node pools.
Managed node host group support
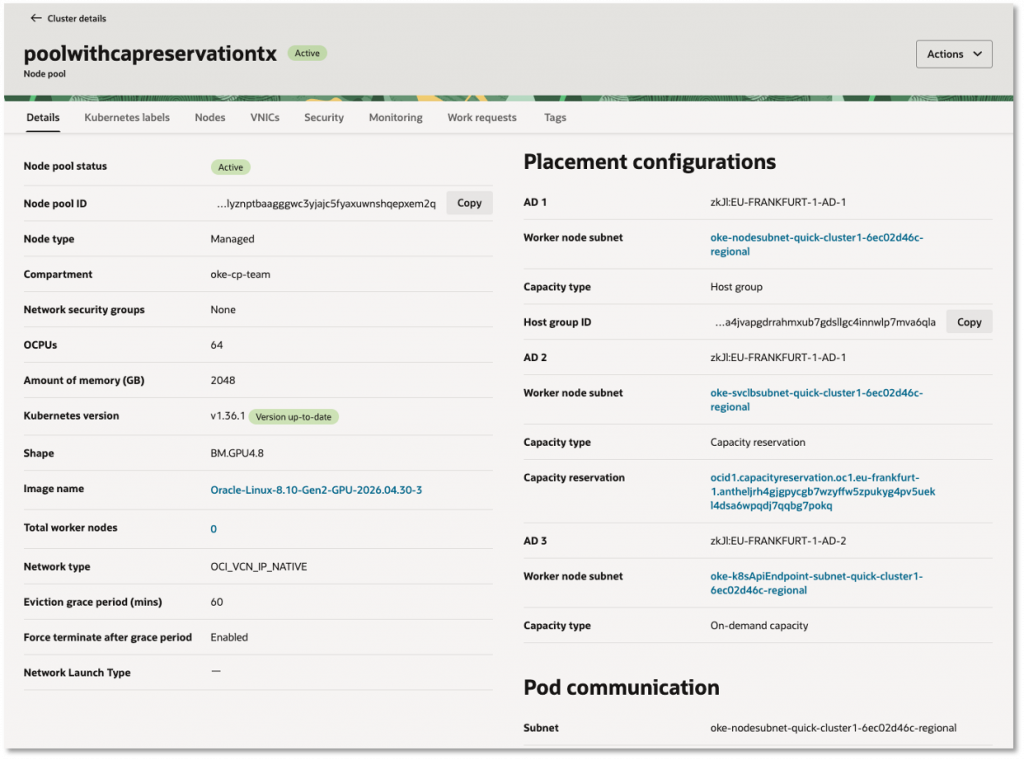
When you create node pools in OKE, you choose the capacity type for the compute instances that host your worker nodes. On-demand capacity, paying for the compute capacity you use, is the default. Reserved capacity lets you reserve capacity for future usage, helping ensure compute capacity is available when you need to create instances. Preemptible capacity offers a lower-cost option for workloads that can tolerate interruption. With compute host group support, OKE adds another important placement option for managed node pools. By adding support for host groups to managed node pools, customers can benefit from managed node capabilities, such as node pool scaling, worker node replacement, upgrades, and lifecycle operations, while benefitting from the ability to quickly recycle those instances.
As with the existing ability to terminate and replace nodes through the node cycling and delete node APIs, quick recycle honors Kubernetes availability best practices by offering you the option to set an eviction grace period, the length of time to allow nodes to be cordoned and drained before taking action on them. This option respects any pod disruption budgets set for your workloads to avoid any interruptions that might occur if a pod was still running at the time action was taken on a node. If any pods failed to evict by the end of the eviction grace period, you have the option to either cancel the operation or move ahead with the action.
Prerequisites and getting started
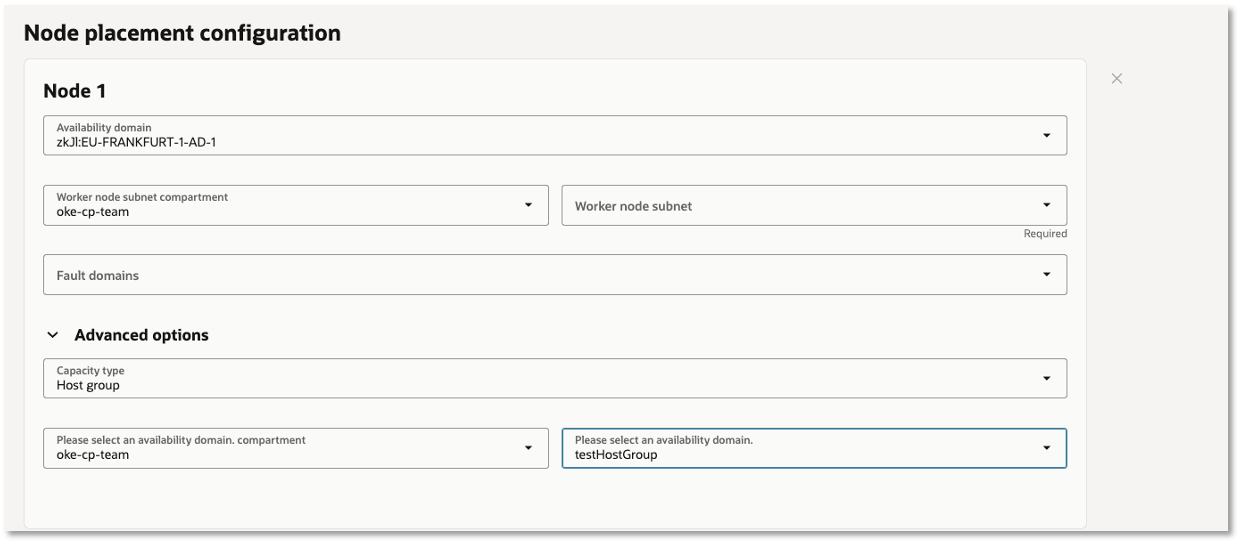
Before using a compute host group with an OKE managed node pool, there are a few prerequisites. Create and configure the compute host group in the Compute service first, and make sure its lifecycle state is ACTIVE. The compute host group must be in the same availability domain as the node pool placement configuration, and the node pool shape must match the compute host group shape. For quick recycle, use a shape that supports quick recycle and configure the host group recycle level in the Compute service before selecting the host group in OKE. You also need the required IAM policy so Kubernetes Engine can use the compute host group when launching managed worker node instances.
Once those needs are addressed, you select the host group in your OKE node pool placement configuration. When OKE launches managed worker node instances, the Compute service places those instances on hosts in the selected host group. It is worth noting that if you change the compute host group for a placement configuration, the change affects new worker node instances. Existing worker nodes are not moved automatically. To use the updated compute host group for existing nodes, terminate and replace those worker node instances so the Compute service can place the replacements on hosts in the updated group, or use destructive node pool cycling to replace any worker node instance whose host group does not match any of the host groups in the node pool placement configuration entries.
Conclusion
For teams operating fleets of bare metal instances in their Kubernetes clusters, managed node support for compute host groups and quick recycle gives OKE customers another tool for building resilient, high-performance Kubernetes platforms on OCI. It helps teams recover capacity faster, control host placement more precisely, and keep using the managed node operations that make OKE simpler to run in production. Instead of choosing between precise host placement and managed node convenience, you can use both.
Learn more
- Using Compute Host Groups to Provision Managed Nodes Documentation
- OCI Kubernetes Engine (OKE) support for Compute Host Groups and Quick Recycle Release Note
- OCI Compute Host Groups
- Kubernetes Worker Node Repair
- Get started with Oracle Cloud Infrastructure today with our Oracle Cloud Free Trial
