Natural language to SQL has become one of the most practical interfaces for enterprise analytics. The basic pattern is now familiar: retrieve relevant tables, link user intent to schema elements, generate SQL, then run a validation loop to repair errors. That baseline works well on demos and benchmarks. Production systems fail for a different reason: the hard part is usually not SQL syntax. It is business meaning.
In real enterprise environments, a short request like “How did OCI do last month?” is underspecified in several ways at once. “OCI” may refer to an organization, a campaign, or a region. “Did” may imply revenue, margin, bookings, or year-over-year growth. “Last month” may depend on data refresh cutoffs, fiscal calendars, and user-specific reporting rules. A useful NL2SQL system must resolve all of that before it writes a single SELECT.
This is the central idea behind OCI’s modular NL2SQL architecture: semantic enrichment should not be treated as a small add-on around prompt engineering. It should be a shared layer that improves every stage of the pipeline, from retrieval to schema linking to SQL generation, validation, and optimization.
Why Enterprise NL2SQL is Still Hard
Enterprise NL2SQL breaks down on four recurring problems.
First, user intent is ambiguous. Analysts often ask comparative or trend questions without specifying the metric, time normalization rule, or default slice they expect. The system has to infer a likely KPI, resolve temporal semantics, and apply role-aware defaults without drifting away from the actual request.
Second, business knowledge usually does not live in the schema. Terms such as “healthy growth accounts” or “North Europe” often represent internal definitions, threshold rules, org mappings, and policy constraints that are never expressed as clean table or column names. A model that only sees DDL will miss the actual business meaning.
Third, physical schema design matters. Two warehouses can represent the same analytical concept with very different SQL implications. Revenue may appear as revenue + currency_code in one dataset and as materialized revenue_usd, revenue_eur, and similar fields in another. Refunds may be negative facts in one system and explicit adjustment rows in another. The right SQL strategy depends on how the warehouse is physically modeled, not just what the user asked.
Fourth, analytics queries are highly context-sensitive. “This month’s pipeline conversion for my region” can change meaning based on the current date, data freshness policy, user identity, geography mapping, and reporting locale. These are not corner cases. They are routine requirements for enterprise trust.
OCI NL2SQL Architecture: Semantics Foundation for a Modular NL2SQL System
OCI’s design separates the system into an online execution path and an offline enrichment path.
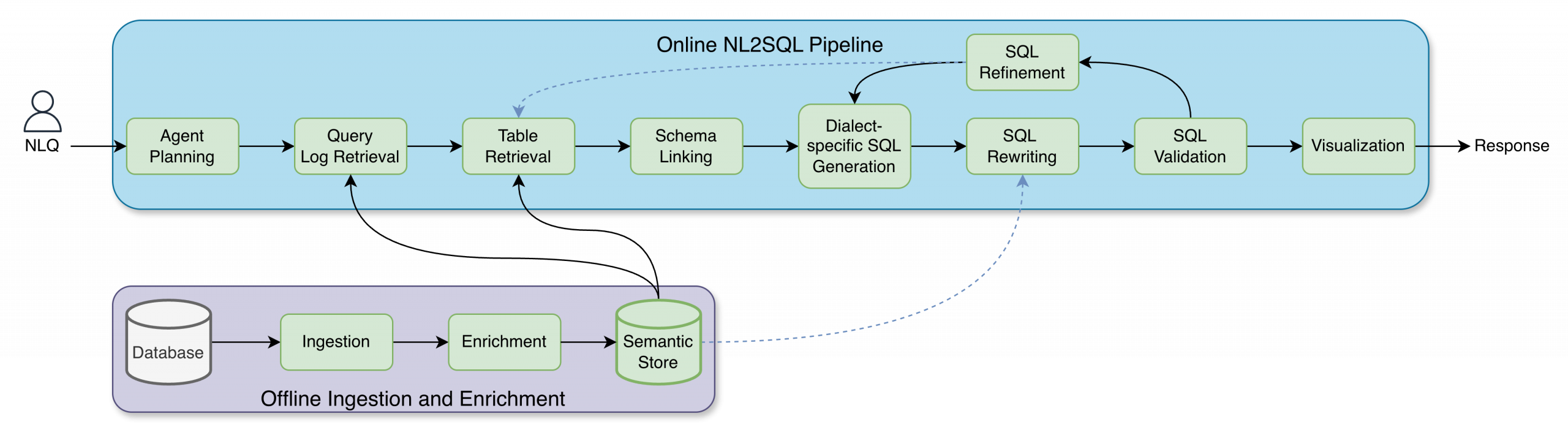
The online path handles the live user request. It starts with planning, retrieves useful prior queries and candidate tables, performs schema linking, generates dialect-specific SQL, then runs rewriting, validation, refinement, and optimization before returning results or visualizations.
The offline path builds the shared semantic foundation. It ingests schemas, metadata, operational signals, and domain artifacts; enriches them with descriptions, aliases, example values, metric definitions, contextual rules, and join hints; then stores those outputs in a centralized semantic store.
That separation is important. It lets the system improve continuously without making the serving path brittle. More importantly, it means the same semantic layer can benefit every downstream component instead of being duplicated in prompts or hidden inside one model stage.
Semantic Enrichment as the Core Primitive
The design’s strongest idea is that semantic enrichment is not just documentation generation. It is the mechanism that converts raw warehouse structure into machine-usable business context.
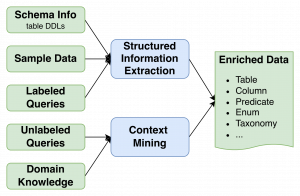
At the schema level, enrichment adds table and column descriptions, example values, likely join keys, units, and business-friendly aliases. This makes large or poorly documented schemas legible to both retrieval systems and language models.
At the organizational level, enrichment converts domain artifacts into structured knowledge: metric definitions, glossary terms, fiscal-calendar rules, territory mappings, default filters, exception handling, and policy constraints. This turns tribal knowledge into explicit constraints that can be reused consistently.
At the behavioral level, enrichment mines query logs. Labeled logs provide high-confidence examples of useful join paths, predicates, aggregation logic, and time-grain choices. Unlabeled logs still carry signal: frequent joins, common filters, popular tables, and representative literal values. Together, these traces help the system align with how analysts actually use data inside the enterprise.
Semantic Store
The semantic store is the persistent layer that sits between raw schemas and SQL generation. Instead of exposing only physical database objects, it represents business meaning in a form the rest of the system can consume: aliases, descriptions, metrics, units, join relationships, domain rules, and enriched usage patterns. That gives the runtime a grounding layer for resolving ambiguous terms and selecting the right schema elements even when database naming is inconsistent or incomplete.
This is what turns NL2SQL from a best-effort translation task into a governable system. Improvements to enrichment, governance, or policy can be made once in the semantic store and then propagate across retrieval, linking, generation, validation, and optimization.
Semantic-aware Modular NL2SQL
Once a user submits a question, semantics shape nearly every stage of execution.
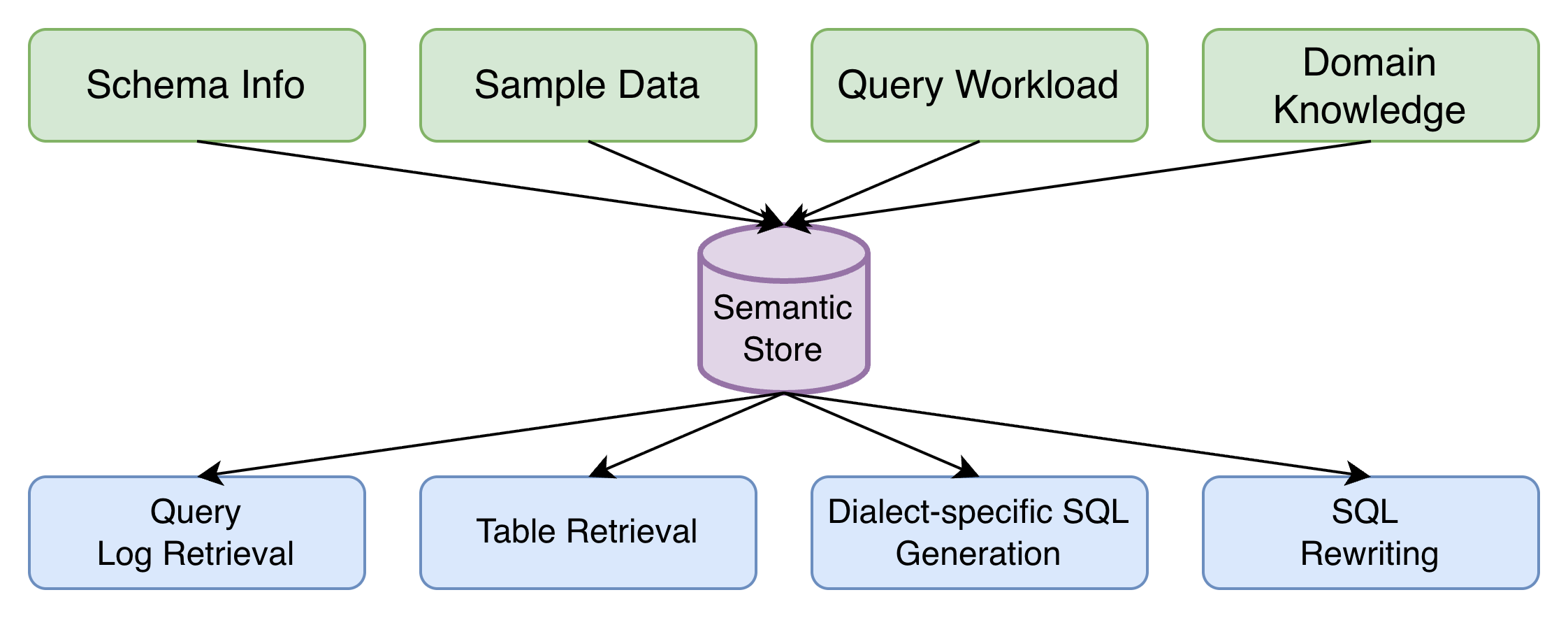
1. Table Retrieval
The system first narrows the candidate schema surface area. It selects likely tables, fields, and validated join paths before SQL generation starts. This reduces noise, improves multi-table reasoning, and lowers the chance of spurious joins. In practice, retrieval combines lexical matching, semantic similarity, ranking, and schema-aware validation to build a compact working set.
2. Schema Linking
Schema linking maps the user’s entities, metrics, filters, and time expressions to actual tables, columns, views, and join keys. In enterprise environments, simple string matching is not enough. Linking has to account for aliases, embeddings, domain synonyms, overlapping concepts, and relationship structure. The output is a small, high-confidence schema context that downstream generation can trust.
3. Dialect-Specific SQL Generation
Enterprise data stacks are heterogeneous. Oracle, PostgreSQL, MySQL, and Snowflake differ in date functions, null behavior, pagination syntax, string operations, and aggregation details. A logically correct query can still fail if it is written in the wrong dialect. OCI’s design explicitly models dialect knowledge so the generator can produce compliant SQL and correct dialect-specific failures during refinement.
4. Validation and Refinement
First-pass SQL is rarely production-ready. It may contain invalid columns, incorrect joins, missing filters, or semantics that drift from the user’s request. The validation and refinement stage checks generated SQL against schema constraints, parser behavior, and execution feedback, then repairs it iteratively. This is where the system moves from “syntactically plausible” to “semantically dependable.”
5. SQL Rewriting
Even correct SQL can be too expensive to run at enterprise scale. The optimization stage rewrites queries while preserving semantics, using lightweight statistics, explain-plan feedback, domain rules, and historical rewrite outcomes. Typical improvements include predicate refinement, join elimination, aggregation restructuring, and decomposition of expensive queries. The goal is not just correctness, but correctness that executes efficiently on large warehouses.
Why This Design Works
The key contribution of this architecture is not a single model or a single retrieval trick. It is the decision to treat semantics as shared infrastructure. That choice produces several practical advantages:
- Higher correctness because business terms, defaults, and policies are grounded before generation.
- Better consistency because shared definitions are reused across modules instead of being rediscovered per query.
- Better efficiency because retrieval and optimization operate on a cleaner, more informed search space.
- Better portability because dialect-specific behavior is modeled explicitly.
- Better extensibility because planning, RAG, calculators, and visualization tools can all consume the same semantic layer.
In other words, the system is modular at runtime, but unified by semantics.
Agentic Mode in OCI NL2SQL
One of the more interesting parts of the design is the move toward an agentic architecture. Instead of treating NL2SQL as a fixed linear pipeline, OCI is evolving toward a planning agent that explicitly decides how to solve each request before invoking tools. That planner can classify intent, decompose a complex question into substeps, decide when SQL is needed versus retrieval or deterministic calculation, and coordinate outputs for visualization.
This matters because real analytics questions are often multi-hop and mixed-mode. A single user request may require a SQL query, a calculation on top of the result, a lookup in policy documentation, and a chart. A planning layer makes those dependencies explicit. It also creates a better foundation for multi-turn conversations, replanning after failures, and asking clarifying questions only when uncertainty is genuinely high.
Multi-Turn Interaction as a First-Class Capability
The most important extension is that the system should not assume every ambiguous request must be resolved statically in a single pass. For broad prompts such as “How is OCI doing?” the path of least resistance is often interactive: clarify the business entity, metric, time range, comparison baseline, and slice with the user before committing to a particular SQL strategy.
The current modular design already provides a clean place for this behavior. Agent planner can be equipped with intent classification and disambiguation that decides whether a request is sufficiently specified to continue, whether a lightweight clarification is needed, or whether the planner should proceed with a best-supported default. Instead of being a thin chat wrapper on top of NL2SQL, the interaction becomes part of the execution logic itself.
Each turn updates structured state rather than just appending raw conversation text. The system can carry forward resolved entities, candidate KPIs, accepted defaults, user-specific scopes, and rejected interpretations. The planner can then use that evolving state to re-run retrieval, tighten schema linking, and choose a more precise SQL plan. A clarification such as “I mean OCI revenue in North America, compared with the same month last year” should immediately narrow table retrieval, refine metric definitions, and reduce unnecessary branching in downstream modules.
This also makes the architecture more robust operationally. If SQL validation surfaces an inconsistency, or if retrieval finds multiple equally plausible interpretations, the planner can return to the user with a targeted follow-up instead of guessing. Likewise, if the result suggests a natural next step, the system can preserve the analytical context across turns and treat the conversation as one evolving task rather than a sequence of disconnected NL2SQL calls. That is likely the more realistic path for enterprise analytics assistants: not a static NL2SQL engine wrapped in chat, but a modular analytical system that knows when to ask, when to infer, and when to execute.
Closing Thought
NL2SQL is often framed as a prompting problem or a model problem. In enterprise settings, it is mostly a systems problem. What makes production NL2SQL hard is not generating SQL tokens. It is grounding vague human language in business-specific meaning, schema-specific structure, execution-specific constraints, and user-specific context. OCI’s modular NL2SQL design is compelling because it addresses that full stack directly. If the next generation of analytics assistants is going to be reliable, it will likely look less like a single NL2SQL model and more like this: a semantic system with modular tools, explicit planning, and a feedback loop that learns how the business actually uses data.






