Introduction
Generative AI is transforming how users interact with enterprise data. Instead of writing SQL, users can express intent in natural language and expect context-relevant results. This paradigm, Natural Language to SQL (NL2SQL), is key to scalable data access.
However, real-world NL2SQL remains challenging. Beyond scale and complexity, ambiguity is a central issue in enterprise data. The same query can admit multiple valid interpretations depending on business definitions, schema design, and data semantics, such as aggregation rules, filtering scope, or metric definitions.
These ambiguities often lead to SQL that is syntactically correct but semantically incorrect, a failure mode that is not addressed by standard generation or planning approaches.
Oracle recently ranked #1 in the 2025 Archer NL2SQL Evaluation Challenge with its Reasoning-based Natural Language to SQL Solution, demonstrating the value of structured planning and reasoning.
Building on this foundation, we further develop an enhanced solution focused on robustness and generalization in real-world settings, achieving #1 on the Spider 2.0 Lite leaderboard.
What is Spider 2.0 Lite?
Spider 2.0 is a NL2SQL benchmark that evaluates NL2SQL systems on realistic enterprise workflows, derived from production data applications.
Spider 2.0 Lite contains 547 examples across multiple SQL dialects (BigQuery, Snowflake, and SQLite). It retains key characteristics of enterprise NL2SQL:
- Large, complex schemas (often 1,000+ columns)
- Long-context reasoning over enterprise data
- Multi-step SQL generation, sometimes exceeding 100 lines
- Frequent ambiguity in user intent (e.g., aggregation rules, filtering scope, metric definitions)
- Strong emphasis on execution accuracy and cross-dialect generalization
Result: #1 on Spider 2.0 Lite
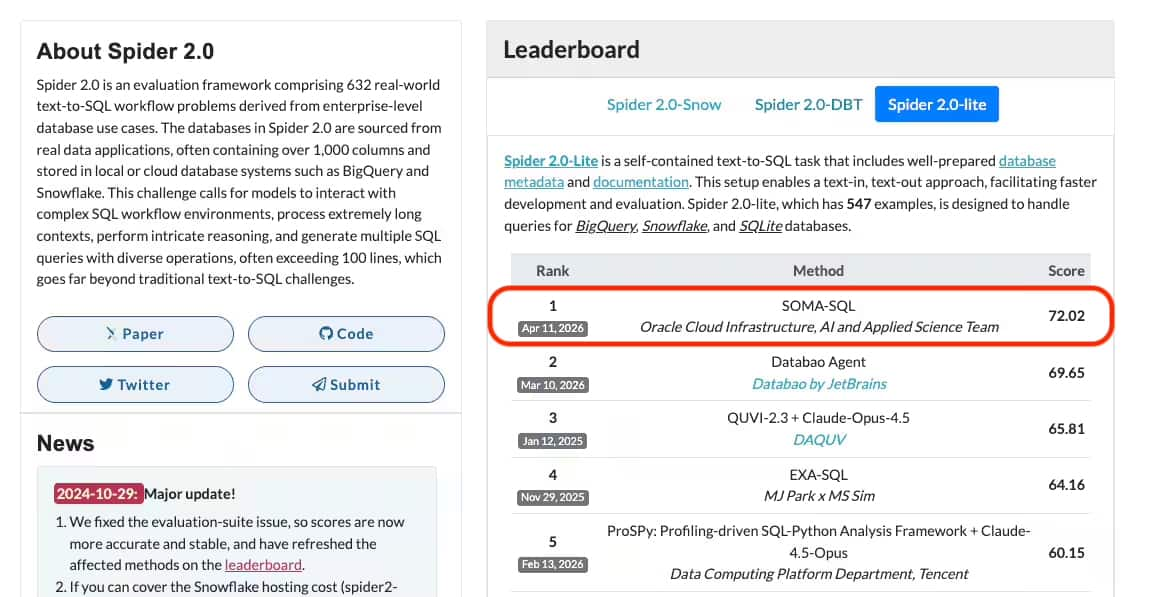
As shown in Figure 1, Oracle’s SOMA-SQL ranks #1 on the Spider 2.0 Lite leaderboard, achieving:
- 72.02% Execution Accuracy (EX@1)
This result extends Oracle’s leadership in NL2SQL following our #1 ranking on the Archer Challenge, and demonstrates strong robustness on realistic enterprise workloads across multiple SQL dialects.
Oracle’s Solution: SOMA-SQL
SOMA-SQL (Synthetic Query Logs and Probing for Multi-source Ambiguity Resolution) is a generalizable NL2SQL agent that resolves ambiguity across user queries, database schemas, and execution signals. As seen in Figure 2 below, instead of a single-pass mapping, it combines synthetic query logs, ambiguity-aware probing, schema enrichment, structured planning, and iterative SQL refinement to produce robust SQL across complex, multi-dialect enterprise environments.
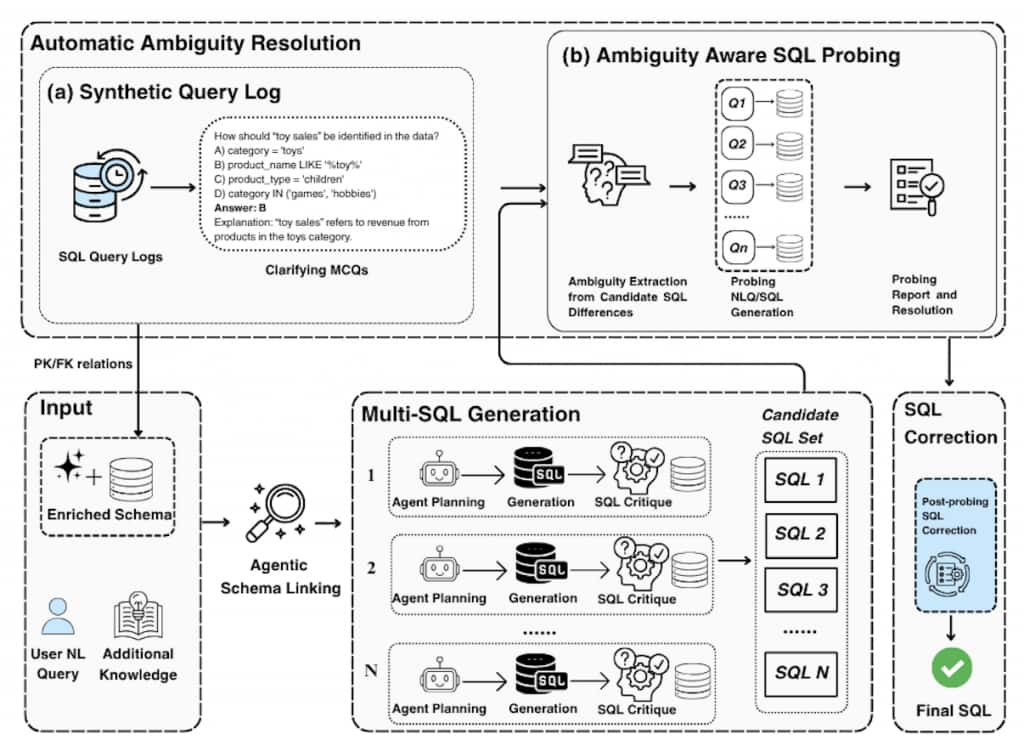
We next describe the key components of SOMA-SQL.
1. Synthetic Query Logs (Ambiguity Grounding)
We construct an ambiguity-aware query log offline by generating (natural language question, corresponding SQL query) pairs aligned with the database schema, designed to capture and simulate common sources of ambiguity. At runtime, given a new natural language question, we retrieve the most relevant examples from this log and include them as few-shot context to improve the model’s ability to interpret and resolve ambiguities.
- Construct ambiguity-aware query logs by transforming SQL variations into clarification questions (e.g., MCQs) with answers and explanations
- Enrich the query context offline using these structured ambiguity cases
- At inference time, retrieve relevant cases to guide interpretation and disambiguation
2. Schema Enrichment and Linking
We enrich the database schema offline, before any natural language query is presented, by incorporating semantic information, query-oriented documentation, and contextual signals to bridge the gap between how users express intent in natural language and how data is structured in the schema.
- Augment schema with query-specific documentation and contextual signals
- Improve alignment between user intent and database structure
- Supports large, complex enterprise schemas
3. Structured Planning and SQL Generation
We introduce an explicit planning phase that decomposes the user query into intermediate reasoning steps and systematically explores multiple interpretations, enabling more robust and accurate SQL generation.
- Decompose the user query into intermediate reasoning steps
- Generate multiple candidate SQL queries to capture alternative interpretations
4. Critique and Refinement
We add an explicit critique phase that detects semantic issues in the generated SQL by integrating signals from both the database and the LLM, summarizes them in a structured report, and then uses that report to drive query correction before execution-based validation.
- Analyze generated SQL for logical and semantic issues
- Provide structured feedback to guide correction
- Improves candidate quality before execution-based validation
5. Ambiguity-Driven Probing (Execution-Grounded Resolution)
We introduce an ambiguity probing phase that executes targeted checks against the database to distinguish competing SQL interpretations and resolve ambiguity using data-backed evidence.
- Identify implementation differences across candidate SQLs and map them to ambiguity dimensions (intent, schema, value)
- Generate targeted probing SQL queries to validate competing interpretations against the data
- Convert probe outcomes into explicit resolution decisions
- Apply data-validated fixes and select the final SQL
Conclusion
SOMA-SQL advances NL2SQL by directly addressing ambiguity in enterprise data. Achieving #1 on Spider 2.0 Lite demonstrates strong robustness and generalization across real-world workloads. This work will be integrated into the Oracle NL2SQL product and will enable customers to use natural language as a reliable interface for large-scale enterprise data systems.








