皆さんこんにちは、今年の7月は急な雨や雷雨が多いですが、これが公開される頃には関東でも梅雨が明けていますね。
今回は、第32回で説明できなかったReal Application Clusters(RAC)でのクラスタ待機イベントについてキャッシュ・フュージョンの動作を含めながら説明しますので、参考にしてください。
1. キャッシュ・フュージョン
まずは、RACで難しいと感じている方も多いキャッシュ・フュージョンから説明します。
キャッシュ・フュージョンとは、複数インスタンス間でデータの一貫性を自動的に維持し、一つのキャッシュのように扱うことができる機能です。グローバル・キャッシュ・サービス(GCS)とグローバル・エンキュー・サービス(GES)によって、GRD(Global Resource Directory)に格納されたリソースの管理を行いますが、問題になるのはバッファ・キャッシュ上のブロックを管理するGCSになるので、ここではGCSの動作について解説します。
ローカル・キャッシュ(SQLを発行したインスタンスのバッファ・キャッシュ)にデータが存在しない場合に、マスター・インスタンスにデータを要求しますが、そのときデータの存在によって、以下の三つの動作を行います(これがキャッシュ・フュージョンの基本動作になります)。
- 2-wayブロック転送
- 3-wayブロック転送
- Grantメッセージ転送
| マスター・インスタンスについて |
(1)2-way / 3-way ブロック転送
マスターとホルダー(データ保有インスタンス)が同じリモート(またはホルダーだけリモート)であれば、そのリモート・インスタンスのLMSプロセスだけとの2-way通信(左側)、マスターとホルダーが別々のリモートであれば、マスターとホルダーのLMSプロセスとの 3-way通信(右側)になります。
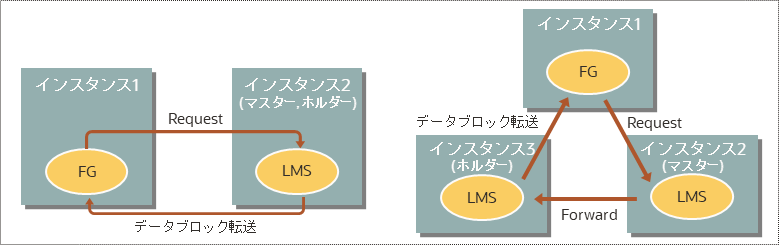
要求インスタンスは、マスターにデータ(DMLのときCurrentモードのデータ・ブロック、クエリのときはCRモードのデータ・ブロック)を要求している間、PlaceHolderイベント(”gc cr/current block request”)で待機し、データ・ブロックをホルダーから受け取るとFixed-upイベント(”gc cr/current block 2-way/3-way”などの実際の待機イベント)に変更します。PlaceHolderイベントは、AWRの「Top 10 Foreground Events by Total Wait Time(Top 10 Events)」には現れません。
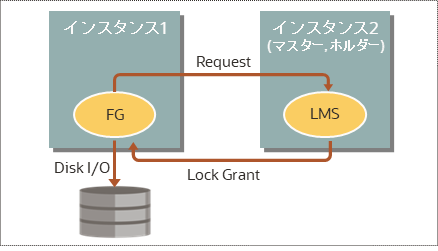
(2)Grantメッセージ転送
すべてのインスタンスにデータが存在しない場合、マスターからLock Grant(ロック権限)を受け取り、ディスクから読み込んでアクセスします(マスターでデータの存在が判断できるので3-wayはありません)。これもPlaceHolderイベントで待機し、Grantを受け取るとFixed-upイベント(”gc cr/current grant 2-way”など)に変更されます。
2. Real Application Clusters の待機イベント
次に、RAC特有の待機イベントと解決方法について説明します。
RAC特有の待機イベントは、グローバル・リソースに対する待機イベントになります。グローバル・エンキュー(バッファ・キャッシュ・ブロック以外のリソース)の待機イベントは、シングル・インスタンス環境の待機と同じ対処になるので、ここではグローバル・キャッシュ(GC)待機イベントについて取り上げます(ただし、GE待機イベントは、シングル・インスタンス環境よりもより多く発生するので、不要なパースなどは避ける必要があります)。
(1)一般的なGC待機イベント
GC待機イベントは、ブロックがローカル・キャッシュに存在するかしないかで異なります。待機イベントの関係は、以下のようになります(インスタンス1が要求で、インスタンス2がマスターとホルダーです)。この待機イベントが最も多く発生するので、これだけは改善できるようになりましょう。

(a)ローカル・キャッシュに存在しないときの待機イベント
以下は、ローカル・キャッシュに存在しないときの一般的なGC待機イベントです。これが受信時のメッセージによって変換されるFixed-upイベントになり、動作が判断できるようになっています。
|
gc [cr|current] [block|grant] [2-way|3-way|busy|congested]
gc:Global Cacheの略
cr/current:要求ブロック・タイプ
block/grant:サーバーから返されるもの
|
・2-way/3-way(ブロックがImmediateで返ってきた)
マスターやホルダーからすぐに(ブロック競合などが発生することなく)返事が返ってきたことを示しています。AWRの「Top 10 Events」に最も多く現れますが、”Avg Wait” が1ms以内で完了していれば問題はありません。問題のときには、インターコネクトの混雑(AWRのInterconnect Statistics)、LMSプライオリティの変化(AWRのリアルタイムLMSプロセス数)、ホルダーと要求側のCPU負荷状況(Run queue length/load average)などを確認してください。
・busy(競合が発生した)
ブロック競合が発生して、すぐに送信できなかったことを示しています(”gc cr grant busy”は理論的には発生しません)。これは、ホルダーのPin Time(ロックの獲得)、Build Time(CRブロックの生成)、Flush Time(ダーティ・バッファのRedoログ・フラッシュ)の問題で発生するので、AWRの「Global Cache Transfer Statistics」で受信が多いインスタンスやブロック・クラスを確認して、「Global Cache and Enqueue Services – Workload Characteristics」や「Global Current Server Statistics」で問題を特定します。セグメント統計の「Segments by CR Blocks Received/Current Blocks Received」を見ると、リモートからの受信が多いオブジェクトが分かるので、第4回の「ブロック競合について」を参考に、ブロック競合の削減も検討してください。
・congested(2-way/3-wayと同じように競合はないが混雑が発生した)
LMSプロセスにメッセージが送られてから、処理の開始がしきい値(1ms)を超えたため、混雑と判断されたことを示しています。LMSにCPUが割り当たらない、メッセージ数に対してLMSが不足しているなどの問題が考えられるので、LMSのCPU使用率などを確認して、CPUの追加、ロード・バランシング、別の時間帯や新しいノードへのオフロードなどを検討してください。
(b)ローカル・キャッシュに存在するときの待機イベント
ローカル・キャッシュに存在するが、以下のようなアクセス中のため、アクセスできないGC待機イベントです。
・gc buffer busy acquire
アクセスするバッファを、別セッションがリモート・キャッシュから取得中のためアクセスできない。
・gc buffer busy release
アクセスするバッファを、別インスタンスから要求されて解放中のためアクセスできない。
「待機イベントの関係」を見ると分かるように、別セッションのデータ要求の完了を待っているので、”gc xxx block busy”などにより長くなるような場合もあります。対処方法は、”gc xxx block busy”と同じように、ブロック競合やRedoログ・フラッシュを削減することになります。セグメント統計の「Segments by Global Cache Buffer Busy」を見ると”gc buffer busy”が多いオブジェクトが分かります。
(2)その他のGC待機イベント
その他の代表的なGC待機イベントについても参考のために載せておきます。
| 待機イベント | 説明 |
| gc [cr|current] multi block [request|grant|mixed] | リモートにフル・スキャン(マルチ・ブロック)要求を行った request: すべてがブロック転送によって満たされた grant: すべてがLock Grantによって満たされた(その後にディスク・リード) mixed: ブロック転送とディスク・リードが混在した |
| gc [cr|current] block direct read | リモート・バッファのRDMAリード(Oracle18cからのExadataのみ) |
| gc [cr|current] block lost | ブロック損失による待機(これもFixed-upイベント) ブロック転送のしきい値0.5秒を超えると、この待機として計上されて再要求する ・パケットの損失が頻繁に発生していないかネットワークの監視を行う |
Exadataでは、ハードウェアの進化を活用して、このような待機イベントを削減する機能が追加され、より利用しやすくなっています(ExadataのRAC機能については、「Oracle RAC Cache Fusion on Exadataパフォーマンス最適化」を参照してください)。待機イベントで苦労されている方は利用を検討してみてください。
3. AWRレポートのRAC Statistics
最後に、AWRレポートのRAC Statisticsについて説明します。
RACの待機イベントもAWRの「Top 10 Events」から確認しますが、RACでは根本的な原因が他のインスタンスに隠れていて現れない可能性もあります。そのため、一つのインスタンスだけでは問題を特定できない場合もあるので、RACのパフォーマンス統計や待機イベントに基づいてまとめられたRAC Statisticsを利用します(Oracle Database 12cからADDMが出力されるので、最初に参考になるものがないかを確認してください)。ここでは、以下の代表的な情報について取り上げます。
- RAC Report Summary(RAC全体の情報)
- Global Current Server Statistics(ホルダー・サイト)
- Global Cache Transfer Statistics(要求サイト)
- Interconnect Statistics(インターコネクト情報)
(1)RAC Report Summary
RAC全体のキャッシュ・フュージョンの稼働状況として、RAC Report Summaryの「インスタンス数とLMSプロセス数」、「Global Cache Load Profile(負荷状況)」、「Global Cache Efficiency Percentages(アクセスの割合)」、「Global Cache and Enqueue Services – Workload Characteristics(ワークロードの特徴)」を見ていきます。
(a)インスタンス数とLMSプロセス数
RAC Report Summaryの最初に、開始と終了スナップショット時点でオープンしているインスタンス数とLMSプロセス数が出力されているので、スナップショット間で変化していないかを確認します。Oracle Database 12cR2からの”Number of realtime LMS’s”(リアルタイムLMSプロセス数)で、すべてのLMSプロセスがリアルタイムで動作しているかも確認してください。すべてリアルタイムでない場合はその問題から解決してください。
(b)Global Cache Load Profile
このセクションは、インターコネクトを介したトラフィック(GCSが送受信したブロック、GCSとGESが送受信したメッセージ)の概要になります。「Report Summary」の「Load Profile」と同じように、何かが正しく機能していないことを示すものではないので、負荷に変化があったかどうかの確認(正常値との比較など)に使用します。
| 統計 |
意味 |
| Global Cache blocks received |
受信したブロック数(Currentブロック + CRブロック) |
| Global Cache blocks served |
送信されたブロック数(Currentブロック + CRブロック) |
| GCS/GES messages received |
リモート・インスタンスから受信したメッセージ数(GCS + GES) |
| GCS/GES messages sent |
リモート・インスタンスに送信されたたメッセージ数(GCS + GES) |
| DBWR Fusion writes |
フュージョン・ライト数(Currentブロックをクラスタ全体レベルで書込み要求した数) |
| Estd interconnect traffic (KB) |
インターコネクト・トラフィックの推定値 |
(c)Global Cache Efficiency Percentages (Target local+remote 100%)
ディスク、ローカル・キャッシュ、リモート・キャッシュから受信したバッファの割合を示しています。理想的には、ディスク・バッファ・アクセスの割合はゼロに近いことが望ましいです(リモートが多い場合も改善の余地があります)。
| 統計 |
意味 |
| Buffer access – local cache % |
ローカル・キャッシュからブロックを取得した割合 |
| Buffer access – remote cache % |
リモート・キャッシュ(キャッシュ・フュージョン)からブロックを取得した割合 |
| Buffer access – disk % |
ディスクからブロックを取得した割合 |
(d)Global Cache and Enqueue Services – Workload Characteristics
GCSとGESに関するインスタンスの全体的なパフォーマンス(レイテンシ)を示しています。このインスタンスは、どの時間が多いかを確認するのに使用します。
| 統計 |
意味 |
| Avg global cache cr block receive time (us) |
キャッシュ・フュージョンの要求側として、CR/Currentブロックを要求してから受け取るまでの平均時間(通常は1ms以内) |
| Avg global cache current block receive time (us) |
|
| Avg global cache cr block build time (us) |
キャッシュ・フュージョンのホルダー側として、CRブロックの作成、ログ・フラッシュにかかった平均時間(これが多いと他インスタンスでgc cr xxx busyが発生していると言うことです) |
| Avg global cache cr block flush time (us) |
|
| Global cache log flushes for cr blocks served % |
CRブロック総数に対するログ・フラッシュした割合 |
| Avg global cache current block pin time (us) |
キャッシュ・フュージョンのホルダー側として、Currentブロックの排他制御、ログ・フラッシュにかかった平均時間(これが多いと他インスタンスでgc current xxx busyが発生していると言うことです) |
| Avg global cache current block flush time (us) |
|
| Global cache log flushes for current blocks served % |
Currentブロック総数に対するログ・フラッシュした割合 |
| Avg LMS process busy % |
LMSプロセスの平均ビジー率 |
| Avg global enqueue get time (us) |
グローバル・エンキューの平均取得時間 |
(2)Global Current Server Statistics
このセクションは、ホルダー側の詳細で、”gc current block busy”の理由を説明しています。そのため、この待機イベントが多い場合、他のインスタンス(ホルダー側)でこの統計を確認してください。
| 統計 |
意味 |
| Pins |
CurrentブロックのPin操作数と各時間帯(<100usから<10s)の割合 時間が長い場合は、ホルダーのCPU負荷によりピン(ロック)解放が遅くなっている可能性がある |
| Flushes |
Currentブロック送信前のRedoフラッシュ操作数と各時間帯(<100usから<10s)の割合 時間が長い場合は、ログI/Oに問題があることを示している |
(3)Global Cache Transfer Statistics
このセクションは、要求(受信)側の詳細で、クラスタに参加しているインスタンス間のブロック転送情報(Immediate、Busy、Congestedごとのブロック転送の割合や平均時間など)を提供します。待機イベント(2-way/3-way、busy、congested)に対して、受信が多いインスタンスや不均衡なインスタンスなどの確認に使用します。
以下は、「Global Cache Transfer Statistics」と「Global Cache Transfer Times」で、Immediate(滞りなく転送したブロック)、Busy(競合が発生したブロック)、Congested(システム負荷で混雑が発生したブロック)ごとのブロック転送の割合と平均時間になります。
| Inst No |
受信したインスタンス番号 |
||||
| Block Class |
ブロックのクラス(data block, undo header, undo block, other) |
||||
| CR / Current |
Blocks Received |
受信したブロック数 |
CR / Current Avg Time (us) |
All |
すべての平均時間 |
| % Immed |
Immediateブロックの割合 |
Immed |
Immediateの平均時間 |
||
| % Busy |
Busyブロックの割合 |
Busy |
Busyの平均時間 |
||
| % Congst |
Congestedブロックの割合 |
Congst |
congestedの平均時間 |
||
以下は、「Global Cache Transfer (Immediate)」と「Global Cache Times (Immediate)」で、Immediateの2ホップ/3ホップのブロック割合と平均時間、ブロックロストのブロック数と平均時間になります。
| Src Inst# |
受信したインスタンス番号 |
||||
| Block Class |
ブロックのクラス(data block, undo header, undo block, other) |
||||
| Blocks Lost |
ブロックロストのブロック数 |
Lost Time |
ブロックロストの平均時間 |
||
| CR / Current |
Immed Blks Received |
Immediateで受信したブロック数 |
CR/Current Avg Time |
Immed |
Immediateの平均時間 |
| % 2hop |
2ホップ・ブロックの割合 |
2hop |
2ホップの平均時間 |
||
| % 3hop |
3ホップ・ブロックの割合 |
3hop |
3ホップの平均時間 |
||
(4)Interconnect Statistics
このセクションは、インターコネクトに対する情報(Ping時間、スループット、デバイス統計)を提供します。
以下は、「Interconnect Ping Latency Stats」で、このインスタンスからターゲット・インスタンス(自分自身も含む)へのPing時間を示します(500バイトと8Kバイトのメッセージに対するパケット転送時間で、平均時間が1ms未満で完了するのが一般的です)。これでインターコネクトの混雑状態を確認します。
| Target Instance |
ターゲットのインスタンス番号 |
| 500B Ping Count |
500バイト・メッセージのPING回数 |
| Avg Latency 500B msg |
500バイト・メッセージのPINGレイテンシ(パケット転送時間)の平均 |
| Stddev 500B msg |
500バイト・メッセージのPINGレイテンシの標準偏差 |
| 8K Ping Count |
8Kバイト・メッセージのPING回数 |
| Avg Latency 8K msg |
8Kバイト・メッセージのPINGレイテンシ(パケット転送時間)の平均 |
| Stddev 8K msg |
8Kバイト・メッセージのPINGレイテンシの標準偏差 |
4. おわりに
今回は、Real Application Clustersの待機イベントについて説明しましたが、少しは参考になりましたでしょうか。これからも頑張りますのでよろしくお願いします。
それでは、次回まで、ごきげんよう。
