皆さん、明けましておめでとうございます。今年も連載を続けられるように頑張りますので、よろしくお願いします。
今年最初の内容は、「パフォーマンスの良いSQL文について」の続きとして今までに説明できていなかったことをいくつか説明しようと思いますので、参考にして下さい。
■ 1. SQLを上手く使い分ける
まずは、これまでの「このようにすると効果的です」ではなく「上手く使い分ける」について説明しましょう。
ある処理を行う場合に、複数のSQL文を書くときがよくあります。これは、同じことをいくつかの方法で行うことが可能なため、使用するそれぞれの機能のどれが一番適しているかを確認するために行うようにしています(データ量や列数などの条件によってどれが適しているか異なるからです)。それぞれの機能には、必ず長所と短所がありますので、それを意識して使い分けるようになると、もっと効果的に使用できるようになると思います。今回はこのようなことについて、以下を例にまとめてみました。
- 条件で値を変える
- 横展開する
それでは、それぞれについて説明していきます。
結合するテーブル数について
ご存知ない方のために(説明していなかったので)、ここで結合するテーブル数について簡単に説明します。 結合するテーブル数をいくつまでにすれば良いかと考えたことはありませんか。できるだけSQLにしましょうと言ってもパフォーマンスのことを考えると、結合するテーブルの数には気を付ける必要があります。コスト・ベース・オプティマイザ(CBO)は、すべての結合する順番の組合せを評価して、最もコストの低いものを選択しますが、テーブル数が多いとそのコスト計算に時間が掛かるのが問題になります。そのため、その時間を抑えるために評価する組合せの最大数を決めています。Oracle9iまでは初期化パラメータOPTIMIZER_MAX_PERMUTATIONSで指定されている値(デフォルトは2,000)の組合せまで評価しますが、Oracle Database 10g以降は2,000固定となっていますので注意して下さい。組合せの数は階乗(n!)で求めることが可能ですので、6テーブルと7テーブルについては以下の組合せ数になります。
- 6テーブルは6!(6*5*4*3*2*1=720)
- 7テーブルは7!(7*6*5*4*3*2*1=5,040 )
つまり、2,000を超える7テーブル以上は、すべての組合せを評価しないことになります。7テーブル以上を結合する場合は、ベストな実行計画にならないときがありますので、ヒント文を入れるなどのチューニングが必要な場合があることを知っておきましょう(できれば多くても6個までになるように、データベース設計をするようにして下さい)。
(1)条件で値を変える
大きなテーブルを条件を変えて集計したい場合などが良くあると思いますが、これを単純にPL/SQLで1行ごとに処理を行ってしまうと時間が大幅に掛かってしまう場合があります。これは、CASE式、UNION ALL、マルチテーブル・インサート、そしてPL/SQL(場合によってはPL/SQLが効率的な場合もあります)などを使い分けることで効率良いSQL文になることを知っておきましょう。それぞれの機能に、どのような短所があるかを分かって使用することが効果的になります。
(a)CASE式
まずはCASE式から説明します。よくある例として、設定する値(計算式)が条件で異なる場合があります。このような場合は、一般的に以下のようにCASE式(またはOracle固有のDECODEファンクション)を使います。CASE式は非常に便利だと思いますが、列ごとに記述する必要があるため、同じ条件でも設定する列の数だけ記述する必要があります。例えば、以下のように列c1の値によってa1,a2,a3などに設定する値が異なる場合は、それぞれの列に同じCASE式(c1 = ’01’)を記述する必要があります。そのため、多くの列に条件で設定する場合はCASE式のオーバーヘッドが大きくなりますので注意して下さい(異なる条件判断であれば、どのようにプログラミングしても同じようになると思いますが、同じ条件判断ではCPUコストが多い条件判断をできるだけ少なくすることが重要です)。

(b)UNION ALL
同じ条件で設定する値が多い場合には、以下のようにUNION ALLを使用する方が条件指定がSELECT文ごとになるため、条件処理が緩和されます。ただし、UNION ALLはSELECT文の数だけテーブルのスキャンを行いますので、SELECT文が多い場合には注意が必要です。これについては、検索する単位にパーティション化すれば回避できますので(アクセス件数が少ない場合は索引でも回避できます)、使用するときは同時にパーティション化も検討するようにして下さい。
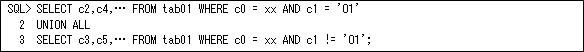
パーティション化することができない場合は、以下のようにWITH句を使用することでテーブル・スキャンは1回のスキャンで済みます。ただし、一時表を作成しますので、その一時表のサイズが大きいときは(テーブルの殆どのデータで一時表を作成するときなど)、問題になりますので注意して下さい(これは第11回で説明しましたよね)。
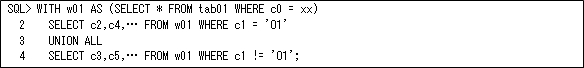
(c)マルチテーブル・インサート
マルチテーブル・インサートは、条件によって複数のテーブルをインサートするようなときに使用しますが、これは同じテーブルにも使用できますので、覚えておくと便利かと思います。これは、テーブル・スキャンや条件チェックは1回で行うことが可能ですので(以下の例のようにFIRSTにすると条件チェックは一致したら終了しますが、ALLにすると常にすべての条件チェックを行います)、インサートする必要がある場合には最もオーバーヘッドが少ない方式になると思います。

(d)PL/SQL
どれも効果的ではない場合は、PL/SQLを使用することになると思いますが、PL/SQLを使用した方が効率よい場合もあります。例えば、大量のデータを処理するときなどは、まとめて処理をするSQLでは大量のメモリ(PGA)を必要とするため、メモリ不足でTEMP領域へのI/Oが多くなり効率が悪い場合があります(特に、パラレル実行は第20回で説明したように、2つの処理までしか同時に行うことができないので、中間結果を格納する領域が必要になります。そのため、より多くのメモリが必要になります)。
TEMP領域へのI/Oは、特定の量を超えると急激に増加するため(このようになるとAWRの「PGA Aggr Target Histogram」の「M-Pass Execs」が増加します)、このときメモリ(PGA)を増加することができない(または処理するデータ量を少なくできない)場合は効率が悪くなります。そのような場合は、PL/SQLなどの1行ごとに処理を行う方が、メモリ使用量が少なくなり効果的な場合があります。ただし、ソート処理などはすべてを終了しないと結果が出ないので、このような処理は変わることはありません。
(2)横展開する
分析系のシステムだと横展開(繰り返し)を行う機会が多いと思いますが、どのように行っていますか(これは、第一正規形で排除されるものですが、分析系システムではよく使われます)。以下のテーブルの列c1が同じ値のc2,c3,c4を同じ行にしたい場合です(例えば、列c2の値によって横展開する位置が決まるように、列c1とc2でクロス集計する場合などです)。いざ行ってみようとしても慣れていないと簡単にはできないものですので、いくつかのパターン(CASE式、インライン・ビュー、PIVOT句、LISTAGG集計ファンクション)について説明します。
(a)CASE式とSUM集計ファンクション
一般的には(最も簡単に行うには)、以下のようにCASE式とSUM集計ファンクションを使用して行うと思いますが、最初のCASE式で説明したように列数が多いと、全ての列を記述するのが大変でオーバーヘッドが大きくなりますので、これは列数が少ない場合に使用することになると思います。このCASE式を使用する場合は、集計しない場合でもSUM集計ファンクションなどが必要になります(これは、CASE式だけではそれぞれの行に値が存在する列と存在しない列が作成されるため、それを同一行にするために必要になるからです)。

(b)インライン・ビュー
列が多い場合には、以下のように横展開する条件ごとにインライン・ビューを作成して行うのが効果的です。ただし、インライン・ビューの数だけテーブルをフル・スキャンする必要があります。これについてもパーティション化するかWITH句を使用すると気にする必要はありません(ただし、UNION ALLで説明したのと同じ問題があります)。これは、横展開する数(この例だとc2の数)が多いと、インライン・ビューの数が増えて記述が大変になりますので、列数が多いが横展開する数が少ない場合に使用することになると思います。

結合するテーブルの列数が多い場合はUSING句が便利ですので(視認性が良くなりますので)覚えておきましょう。このように横展開する場合に結合列は複数存在する必要がないため、以下(右)のように必要な列名だけを指定する必要があります。結合列名が同じ場合には、以下(左)のようにUSING句を使用すると簡略化できます(以下の例はどちらも同じように列c1が1つになります)。

(c)PIVOT句
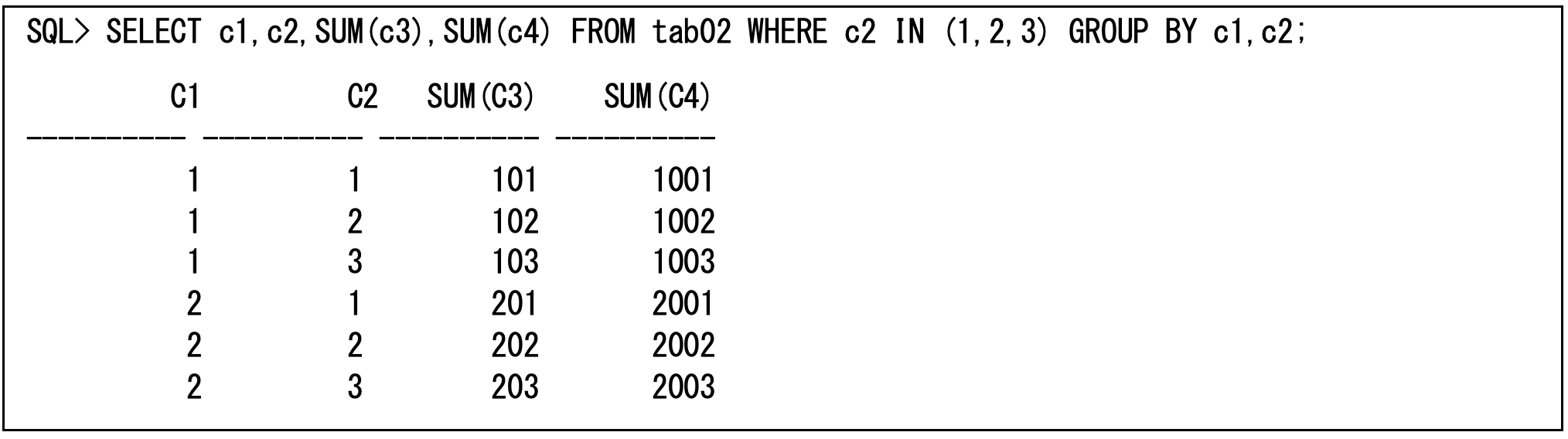
Oracle Database 11gからのPIVOT句を使用することでクロス集計(行を列に変換して集計する)問合せを記述することができます。これはPIVOT句で指定されている集計関数をPIVOT_FOR句の列に対してPIVOT_IN句の値ごとに列として実行することを意味します。以下の例では、列c2の値の1,2,3に対してSUM(c3)とSUM(c4)を行います。このとき列名が”<PIVOT_FOR句の別名>”_”<集計関数の別名>”になります(以下の例では、SUM(c3)は別名を指定していないので”<PIVOT_FOR句の別名>”だけになっています)。そして、PIVOT句で使用されていない列でGROUP BYが行われますので(以下の例では列c1になります)、集計するようなときはこれが最適だと思います(ただし、PIVOT句は記述が複雑なので慣れないと大変なところはあると思います)。

(d)LISTAGG集計ファンクション
特殊な方法としてcsvファイルに出力する(カンマ”,”などで区切って並べた)イメージなどであれば、Oracle Database 11gR2からのLISTAGG集計ファンクションを使用するのも良いと思います。これはGROUP BY列の値が同じ行に対してメジャー列をWITHIN GROUPで指定した順に区切り文字で横並びにしてくれます(このときソートしない場合はORDER BY NULLにします)。以下の例では、列c1の値が同じ行に対してメジャー列”c3||’,’||c4”を列c2の昇順に区切り文字’,’で区切って横に並べます(メジャー列には1つの列しか指定できないので、複数列指定する場合には文字列連結演算子”||”で列を結合します)。

実行計画は以下のようにSORT GROUP BYとなります(これは、ORDER BY NULLにしても変わりません)。
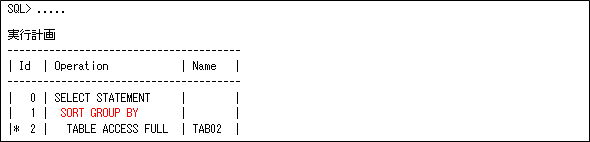
2. ファンクションを効果的に
ここでは、ファンクションの効果的な使用によりSQL文を簡略化することが可能ですので、「横展開する」で説明した以外にファンクションのことで参考になることをまとめてみました。
第9回でユーザ定義ファンクションの説明をしましたが、既存のファンクションでも効果的なものが多くありますので、「通番を振る」を例にファンクションについていくつか説明します(機会があれば他の説明もしたいと思います)。また、ユーザ定義集計ファンクションについても説明しょうと思います。
(1)通番を振る
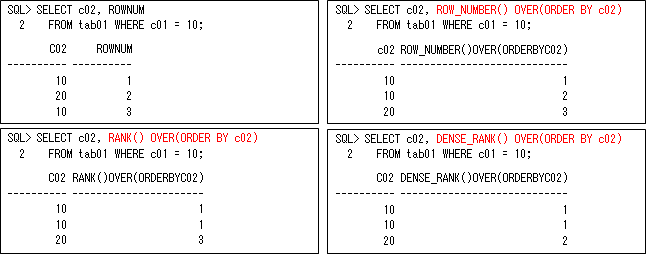
ある条件で通番を振るような場合もよくありますが、これも少々難しいと思いますがどのように行っていますか。例えば、それぞれの値によって上位5件だけを繰り返しデータとしたいときなどがよくあります。このときの上位5件をどのようにして求めるかですが、一般的には以下のようにソート後にROWNUM疑似列を使用して通番を振って求めます。

このような通番を振る処理についても、同じ値をどのようにするかなどによって難しくなってきます。そのため、ROWNUM疑似列を使用する以外に、様々なファンクション(ROW_NUMBER、RANK、DENSE_RANKなど)があるので知っておきましょう。これを上手く使い分けることで、もっと効果的に処理できるようになると思います(行いたいファンクションが存在しないかを確認してから、PL/SQLなどで作成するようにしましょう)。
このファンクションを使用することで様々な通番を振ることができますが、それぞれ以下のように多少動作が異なりますので、用途に合わせて使い分けることが重要です。
- ROWNUM疑似列は、行番号を振るだけです。
- ROW_NUMBERは、ソートして行番号を振ります。
- RANKは、ソートして行番号を振りますが、同じ値には同じ番号を振ります。
- DENSE_RANKは、ソートして値の順番を振りますので、同じ値の次の番号が抜けません。
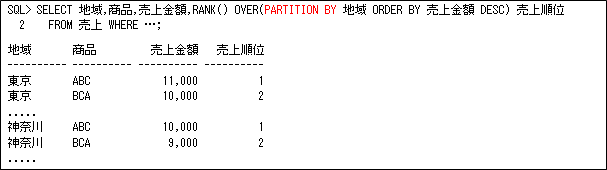
更に、QUERY_PARTITION句を使用すると、指定列ごとに通番を振ることが可能ですので、使用できる用途も多いと思います(以下の例は、売上データを地域ごとに商品の売上順位を出力します)。
このような分析ファンクションを使用すると、実行計画は以下のようにWINDOW SORTとなります。分析ファンクションでは、ANALYTIC句(OVERのカッコ内)で定義された行のグループをウィンドウとして行います。これは、そのウィンドウ単位にソートしていることを意味します。
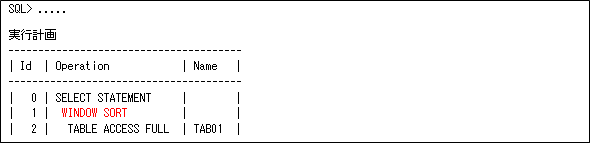
(2)ユーザー定義集計ファンクション
第11回ではユ―ザー定義ファンクションを説明しましたが、集計ファンクションについてまでは説明していなかったので、ここで説明しようと思います。「(1)通番を振る」で説明したように様々な集計ファンクションを提供していますが、独自のファンクションでグループ集計を行うような場合もあると思いますので、知っておくとSQL文にするときに便利だと思います。ユーザー定義集計ファンクションは、以下のようにAGGREGATE USINGを使用して定義します(ただし、このファンクションに指定できる入力引数は1つだけになります)。このときパラレル実行できるように、第11回で説明したPARALLEL_ENABLEも忘れないようにして下さい。

実際の集計ファンクション・プログラムは、データ・カートリッジのユーザー定義集計関数インタフェースを使用して作成します。基本は、以下の4つのODCIAggregateルーチンを使用してオブジェクト型として定義します。
- 初期化(ODCIAggregateInitialize)
- 反復(ODCIAggregateIterate)
- マージ(ODCIAggregateMerge)
- 終了(ODCIAggregateTerminate)
その他にオプションとしてODCIAggregateDeleteなどもあります(これは分析ファンクションの古い集計コンテキストから削除するときに、効果的に動作するために使用します)。それでは、分かり易いような簡単な例(0以外の件数を求める)を作成してみましょう(ユーザー定義集計ファンクションnzcntとして作成してみます)。 まずは、オブジェクト型を以下のように定義をします(ここで処理で使用する変数を定義します。この例では1つの変数cntのみを定義していますが複数でも構いません)。


次に、オブジェクト型の実装部分を以下のように定義します(定義した変数cntを使用して実装部分を記述します)。以下の例では行っていませんが、論理的なエラーがある場合にはエラー(return ODCIConst.Error)も実装して下さい。

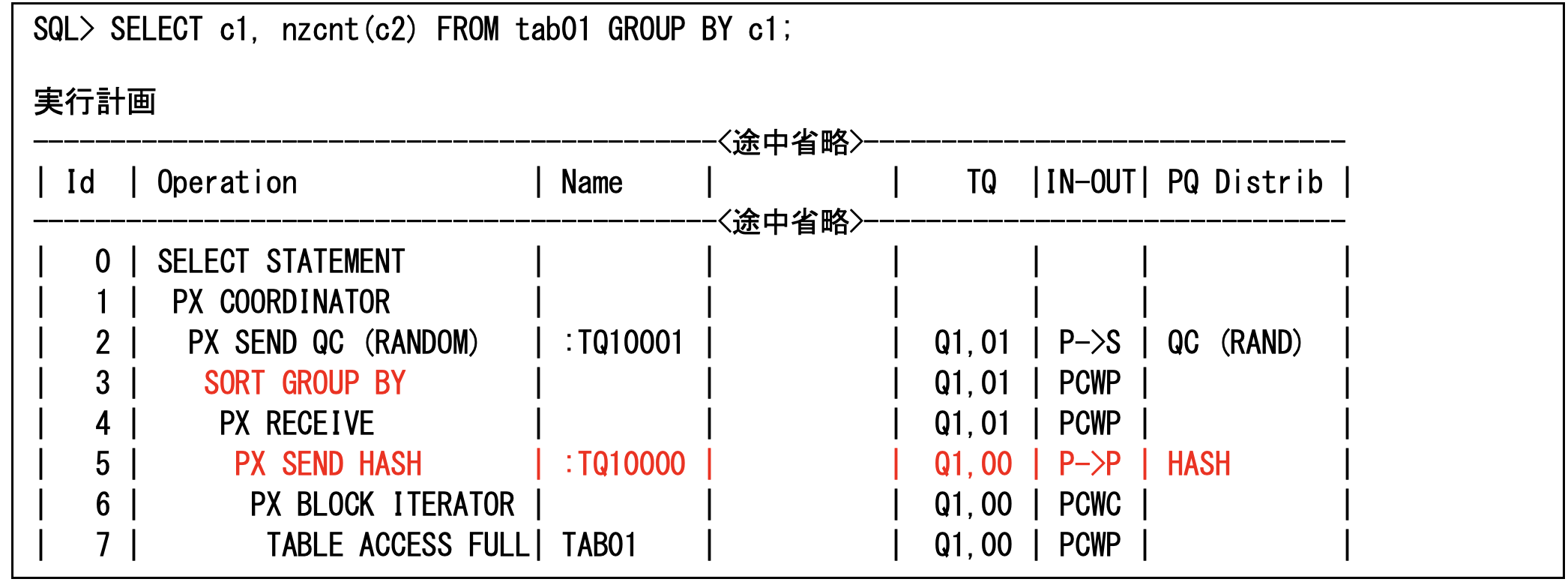
それでは、実行してみましょう。以下の実行計画のようにパラレル実行も可能です。実行計画ではSORT GROUP BYになっていますが、第20回で説明したようにPX SEND HASHですのでデータの偏りは少なくなります(これに、ORDER BY c1を指定するとPX SEND RANGEになってしまい、データが偏り易くなります)。これは、LISTAGG集計ファンクションのときでも同じです。
■ 3. おわりに
今回は第11回に続きSQL文のノウハウについて説明しました。次回は続きとしてテーブル・ファンクションについて説明したいと思いますのでよろしくお願いします。それでは、次回まで、ごきげんよう。
