※本記事は、Andrew Binstock による “The joy of writing command-line utilities, Part 2: The souped-up way to find duplicate files” を翻訳したものです。
総当たり方式でも問題なく機能するが、スマートなアルゴリズムを使えば、パフォーマンスが桁違いに向上する
September 25, 2020
本シリーズの前回の記事では、1つまたは複数のディレクトリに含まれる重複ファイルを特定するコマンドライン・ユーティリティについて紹介しました。LinuxやUNIXのfindコマンドとは異なり、このユーティリティでは、同じ内容のファイルが検索されます。ファイルの名前が違っていても検索結果には影響しません。
ユースケース:このユーティリティ(FileDedupe)は、ファイルの内容に注目するので、ミュージック・ライブラリや写真コレクションから重複ファイルを削除するときにとても役立ちます。FileDedupeの最初の実装では、総当たり方式を採用しました。つまり、ユーザーが指定したディレクトリに含まれるすべてのファイルの一覧を作成し、そのファイルすべてに対してJavaのチェックサム関数を実行し、生成されたチェックサムをテーブルに格納し、複数のファイルから生成されたチェックサムを見つけ、、チェックサムが同一のファイルをグループ化した一覧を出力します。
この総当たりバージョン(プロジェクトのWebサイトのリリース1.0)は問題なく機能しますが、動作は遅く、大量のI/Oが必要です。ファイルのチェックサムを生成するためには、すべてのバイトを読み取る必要があります。多数の音楽ファイルや高解像度動画が入った大規模なディレクトリの場合、チェックサム生成は膨大な作業となります。
今回は、前回予告したとおり、総当たり方式から進んで、すべてのファイルですべてのバイトを読み取らなくてもよいバージョンを実現します。前回の記事では設計について詳しく説明しましたが、今回は主に実装に注目します。
パフォーマンスの大幅な改善
バージョン1.0で実装したチェックサム・ソリューションは、I/Oの制約を非常に強く受けます。アプリケーションが実行されている間、CPUはほとんど動作していないように見えますが、ディスク・ドライブ(筆者のシステムではSSD)のランプは途切れることなく点滅を続けています。
したがって、明らかにわかる最適化には、ファイルI/Oの量の削減が必要でしょう。そのためには、チェックサムを生成しなければならないファイル数の減少に役立つファイル特性を見つけることが必要です。その意味で有用なデータ項目の1つが、ファイル・サイズです。サイズが異なる2つのファイルが重複ファイルということはありえません。
さらに、ファイル・サイズはファイルシステムでファイル自体のエントリに格納されるので、ディレクトリ・ツリーをたどる処理の中で高速に取得できます。そして取得したサイズをテーブル(この実装ではHashMap。図1参照)に格納し、そのサイズに対応するファイル名のリストにリンクします。ユーザーが指定したディレクトリをすべてスキャンし終えたら、ファイル・サイズのテーブルを調べて、サイズに対応するファイルが1つしかないエントリはすべて破棄できます。この作業を行うことで、一意であることがわかっているファイルのチェックサム計算を、1バイトも読み取ることなく回避しています。
ここで行うことをしっかりと理解するため、図1に示すテーブルをご覧ください。エントリのキーは、ファイル・サイズを保持するlongです。エントリの値部分は、ファイル名のArrayList(すなわち、文字列のArrayList)です。
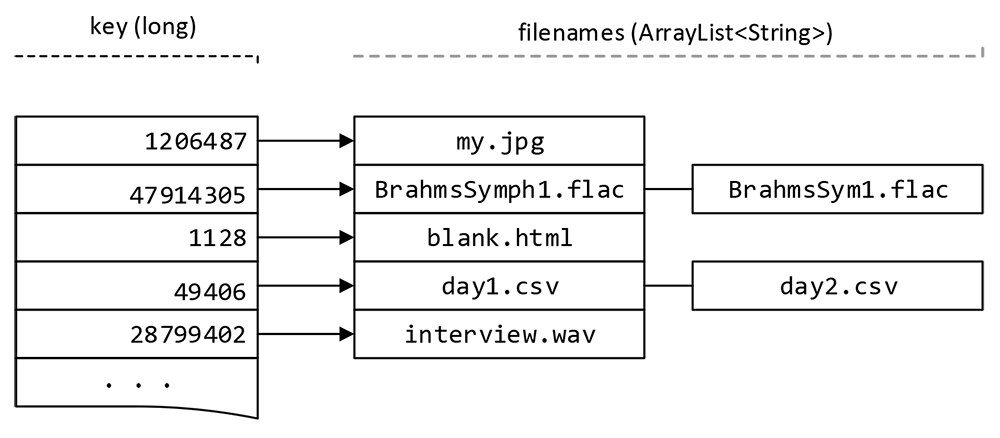
図1:ファイル・サイズと、それぞれのサイズに対応するファイル名を格納したテーブル
データが格納されたテーブルを調べると、1つ目、3つ目、5つ目のエントリはすべて、項目が1つしかないので、スキップすることができます。しかし、2つ目のエントリには複数のファイルが格納されているので、ユーティリティではチェックサム・ルーチンを実行し、ファイル名が異なっていたとしても、本当に重複ファイルであるかどうかを判定します。チェックサム(偶然ですが、これもlongです)も、図1と同じような構造のテーブルに格納します。それぞれのチェックサムが、そのチェックサムを生成したファイルの名前のArrayListを指しています。
このデータ構造は概念的には単純ですが、実装の特徴についてはさらに解説する価値があります。
主なデータ構造を探る
テーブル(図1)を宣言するJavaコードでは、HashMapクラスを使っています。
HashMap<Long, ArrayList<String>> table;
しかし、ここまで説明してきたコードには、このデータ構造に直接アクセスするものはありませんでした。その理由は、このテーブルをラッパー・クラスの中に入れているからです。単純な名前ではありますが、このラッパー・クラスはLongStringListTableとしています。この手順をはさむことで、特定のメソッド以外ではテーブルにアクセスできなくなります。皆さんが使用するほぼすべての主要なデータ構造において、これは優れた手法であり、大規模なコードベースを扱うチームで作業している場合には欠かせません。
一般的な用語を使用すれば、このクラスは「ラッパー・クラス」です。しかし、Javaで「ラッパー・クラス」と言えば、プリミティブ型に当てはまる概念がつきまといます(たとえば、Integerはintのラッパーです)。このクラスの一番の利点は、データ構造に対して他人が実行可能な操作を制限できることです。たとえば、今回のラッパー・クラスでは、エントリの追加とエントリのリストの取得しか許可していません。そうすると、他人がエントリを削除したり、既存のエントリを変更したりすることを防止できます。HashMapをそのまま使い、直接アクセスしているなら、このような制限を強制することはできないでしょう。
先ほども述べたように、もう1つのLongStringListTableインスタンスに、重複の疑いがあるファイルのチェックサムを格納します。2つの異なる目的で同じデータ構造を使用するプログラムにおいてそのデータ構造を宣言する場合、他にもいくつかの方法があります。その1つは継承を使う方法です。他の言語を経験したOOP開発者にとっては自然な方法でしょう。たとえば、LongStringListTableをスーパークラス、そしてFileSizeTableとChecksumTableを2つの派生クラスにすることが考えられます。Javaでは、extendsキーワードを使用して実現できます。しかし、継承には、派生クラスの一部はスーパークラスとは異なるという暗黙の前提があります。
(昔から使われている教育的な例で言えば、AnimalというスーパークラスにCatおよびDogという派生クラスがあり、それぞれの派生クラスにおけるmakeNoise()の実装は異なるというものです。)
しかし、今回のアプリケーションでは、派生クラスとスーパークラスに違いはないため、継承を使うと誤解を生む可能性があります。また、その点とは無関係ですが、Javaでの継承は好まれなくなっています。そのため、明らかに適切な解決策でない限り、継承は使わない方がよいでしょう。
今回は、単純な方法を採用しました。すなわち、Main.javaでテーブルのインスタンスを2つ宣言し、内部データ構造がたまたま同じである2つの異なるオブジェクトとして使用します。
先に進む前に、LongStringListTableの内部でテーブルにエントリを追加する手順をざっと見てみることにしましょう。チェックサムと、そのチェックサムに対応するファイル名を追加する場合について考えます。前回の記事のコードでは、明示的な手順を使いました。
ArrayList tableEntry = dupesTable.get( checksum );
if( tableEntry == null ) { // テーブル内でエントリがまだ見つからない場合
ArrayList<String> entry = new ArrayList<>();
entry.add( filename );
dupesTable.put( checksum, entry );
}
else {
tableEntry.add( filename );
}
このコードでは、テーブルに含まれるチェックサムを検索しています(1行目)。チェックサムがテーブル内にまだ存在しない場合は、ファイル名のArrayListを新しく作成し、そこにファイル名を追加して、そのArrayListとチェックサムを1つのエントリとしてテーブルに追加します。チェックサムがテーブル内にすでに存在する場合(else句を参照)は、既存の、ファイル名のArrayListにファイル名を追加するだけです。
このコードは明快ですが、すべてが「Javaらしい」というわけではありません。読者のMorten Hindsholm氏が賢明にも、次の機会にはJavaらしい書き方をした方がよいと提案してくれました。
public void insertEntry( String filename, Long numeric ) {
ArrayList<String> tableEntry =
table.computeIfAbsent( numeric, c -> new ArrayList<>() );
tableEntry.add( filename );
}
computeIfAbsent()メソッドは、HashMapの標準APIの一部です。このコードでは、キー(ここではnumeric)がまだテーブルにない(すなわち、absent)である場合にtableEntryを作成します。短いラムダ式は、エントリの2つ目の要素を作成する方法を表しています。この場合は、ArrayListのコンストラクタを呼び出すだけです。コンパイラでは、ArrayListの要素がStringであることを認識しています。この時点でArrayListは空ですが、次の文でArrayListにファイル名が挿入されます。エントリがすでに存在する場合は、computeIfAbsent()の手順がスキップされ、次の文にあるファイル名追加の処理が行われます。
このコードがもともとの実装よりもわかりやすいとは思わない方もいるでしょう。しかし、組み込みのAPIをJavaらしく使うことには価値があります。組み込みのAPIを使っていない場合、コードを読む次の開発者に、期待されるAPIではできない特殊なことをやっているという合図を出していることになります。その理由はいくつかあるでしょう。
- 実際に何か特殊なことをやっている
- API に気づかなかった(この場合は、コード・レビューでそっと指摘する必要があります)
- Java8 より前(つまり、言語にラムダ式が追加される前)のJDKでコンパイルするコードを書いている
テーブルの内容のストリーム
両方のテーブルとも、ある時点ですべてのエントリをたどる処理が必要です。テーブル全体をたどる処理は、2つの方法で実現できます。従来型の方法では、テーブルのすべての行をたどるイテレータを使います。新しい方法では、テーブルをストリームに変換し、ラムダ式で表現したストリーム操作を使って必要な作業を行います。ストリームによるアプローチの方が、Javaらしい方法です。行っているすべての操作を、1つの文ですばやく確認できるからです。次に示すのは、sizesTableを読み取るコードです。このコードが実行される時点で、sizesTableにはすべてのファイル・サイズと、それぞれのファイル・サイズに対応するファイル名が格納されています。
sizesTable.getFilenames().stream() // それぞれのサイズに該当するファイルのリストを取得
.filter( s -> s.size() > 1 ) // エントリとして複数のファイルを含むリストを抽出
.forEach( s -> new FilesChecksum( s, dupesTable ).go() ); // ファイルのチェックサムを計算
sizesTableに対してgetFilenames()を呼び出しています。getFilenames()は、LongStringListTableクラスに作成したメソッドの1つで、テーブルに含まれる、ファイル名のArrayListすべてからなるコレクションを返します。1行目では、このArrayListコレクションをストリームに変換しています。このストリームからエントリ数が1より多いArrayListを抽出し、該当した各ArrayListをFilesChecksumに送っています。FilesChecksumでは、ArrayList内のファイルすべてのチェックサムを計算し、その計算結果をdupesTableに格納しています。
その後、同じようなストリーム操作を使ってdupesTableをたどり、複数のファイルに関連付けられたチェックサムを探します。チェックサムが同一のファイルはすべて重複ファイルであるとわかっているので、該当するファイル名をstdoutに出力します。dupesTableをすべてたどり終えれば、処理は完了です。
まとめ
ファイル・サイズを使った処理を追加しましたが、新しくコーディングを行うだけの価値はあったでしょうか。7,201枚の写真(うち434枚が重複)を格納したテスト・ディレクトリでは、もともとのバージョンの実行に119秒かかりました。一方、ファイル・サイズの処理を組み込んだ改訂版の実行時間は16秒でした(時間はすべて、timeユーティリティで計測しました。Windowsをお使いの方には、ptimeユーティリティをお勧めします)。この最適化により、実行時間が87 %減少しました。十分に価値のある作業です。小規模なテストでも大規模なテストでも同様の結果が得られ、重複ファイルが少なかった場合(もう少し厳密に言うなら、チェックサムを計算するバイト数が少なかった場合)により良い結果が得られました。
この最適化は、FileDedupeを実装する2種類の方法を紹介できるようにするために最初から計画していたわけではありません。実際、筆者は最初のバージョンでかなり満足していました。動作が遅い点は気に入りませんでしたが、頻繁な実行は想定していませんでした。ただし、2つのちょっとした点には引っかかっていました。
その1つ目は、サイズがゼロのファイルをどう扱うかです。このようなファイルは、本質的にすべて重複ファイルです。しかし、サイズがゼロのファイルは特別な役割を持っていることがあるので、理由なく削除しない方がよいでしょう。ユーザーに警告できるように、個別に扱うべきかどうかについて悩みました。
2つ目の懸念は、チェックサムのアルゴリズムでした。Java SEの標準ライブラリでは、2つのチェックサム・アルゴリズムが提供されています。今回使わなかったのは、高速ですが100 KB未満のファイルでは信頼できないアルゴリズムです。そこで、ファイル・サイズを確認し、そのサイズをもとにどちらのアルゴリズムを使うかを決めることも考えました。どちらの点も、ファイル・サイズに関わることです。そして、ファイル・サイズの役割について考える中で、チェックサム計算の必要性を大幅に低下させるという目的においては、サイズ自体が十分に一意であるかもしれないという考えが浮かびました。それが、今回の最適化の背景にある洞察につながりました。
このユーティリティのパフォーマンスをさらにチューニングするとすれば、2つのチェックサムを使うアプローチの効果を確認することになるでしょう。さらに、テーブルに対して(現在の1つの逐次ストリームではなく)並列ストリームを使うと効果が得られるかどうかも検討するでしょう。
機能面では、デフォルトのstdoutではなく、コマンドラインで出力ファイルを指定する方法を提供してもよいでしょう。また、出力をHTMLファイルにすることも考えるでしょう。可能な場合にファイルへのクリッカブル・リンクを含めると、ユーザーは重複ファイルのコンテンツをレポートから直接調べることができます。
最後の可能性として考えられるのは、FileDedupeを実行している現在のシステムに加え、別のデスクトップやサーバーにあるリモート・ディレクトリのファイルをチェックする方法を含めることです。これはバックアップを検証する際に便利でしょう。ただし、その正しい方法は、ユーティリティで重複のないファイルのみが報告されるように、(コマンドライン・スイッチで)現在の分析を反転させることです。そうすれば、別のシステム上にあるバックアップが完璧であることを確信できます。
本シリーズの今後について
本記事と前回の記事は、Java Magazineの新シリーズの一部です。このシリーズでは、実際に役立ち、完成させることができる小さなプロジェクト、しかもサードパーティ製ライブラリを呼び出すのではなく、主にJava APIを使っているものを取り上げます。
自分のプロジェクトで好みの設計方法やコーディング方法を選べるように、プロジェクトの設計方法や実装方法をさまざまなやり方で紹介したいと考えています。今回触れたコーディング・スタイルの進化はその一例です。今回のような記事をもっと読みたい方や、取り上げてほしいプロジェクトのアイデアがある方は、ぜひTwitterでお知らせください。
さらに詳しく
- コマンドライン・ユーティリティを書く楽しさ(パート1):重複ファイルの検索
- Javaチュートリアル:コマンドライン引数
- JavaクラスHashMap
- JavaメソッドcomputeIfAbsent
- JavaメソッドgetFileName
- Linuxのfindコマンド
Andrew Binstock(@platypusguy):Java Magazineの前編集長。Dr.Dobb’s Journalの元編集長。オープンソースのiText PDFライブラリを扱う会社(2015年に他社によって買収)の共同創業者。16刷を経て、現在もロング・テールとして扱われている、Cでのアルゴリズム実装についての書籍を執筆。以前はUNIX Reviewで編集長を務め、その前にはC Gazetteを創刊し編集長を務めた。妻とともにシリコン・バレーに住んでおり、コーディングや編集をしていないときは、ピアノを学んでいる。
