しばちょう先生の試して納得!DBAへの道 indexページ▶▶
みなさん、こんにちは。週末に出席した後輩の結婚披露宴が素晴らしく感動的で、また私も結婚式をやりたいなと思ってしまった”しばちょう”こと柴田長(しばた つかさ)です。
さて、今回も引き続きUNDO表領域の管理を体験して頂きたいと思います。前回はORA-1555(読取一貫性エラー)の発生を抑制するUNDO保存期間の自動チューニングをご紹介させて頂きましたが、今回は「ORA-1555が発生しなくとも実はパフォーマンスの問題が発生しているかも?」という現象に挑戦してみたいと考えています。私自身、UNDO関連の待機イベントが発生することでトランザクションのスループットやレスポンス・タイムの劣化を経験したことがありますので、そのケースを是非とも皆さんにも体験して頂いて今後の設計に生かして頂ければと考えています。

とは言え、今回扱う現象は、小規模な動作確認用の環境では再現させることが難しいです。具体的には、2CPUコアを搭載したサーバーで数セッションのユーザーから更新トランザクションを連続実行させても、CPUリソースが先に枯渇してしまう為に現象をクリアに見せることが出来ませんでした。最終的には、それなりに高スペックなサーバーで、100セッション以上のユーザーから更新トランザクションを連続実行せることで再現出来ましたので、そちらの検証データを使用しながら解説させて頂きたいと思います。もし、同様なテスト環境をお持ちの方は、是非とも同じように試して頂ければ幸いです。
本記事内にはパフォーマンスを示すデータがいくつか掲載されておりますが、あくまで学習のために掲載しているだけであり、製品の性能や動作を保証するものではございません。
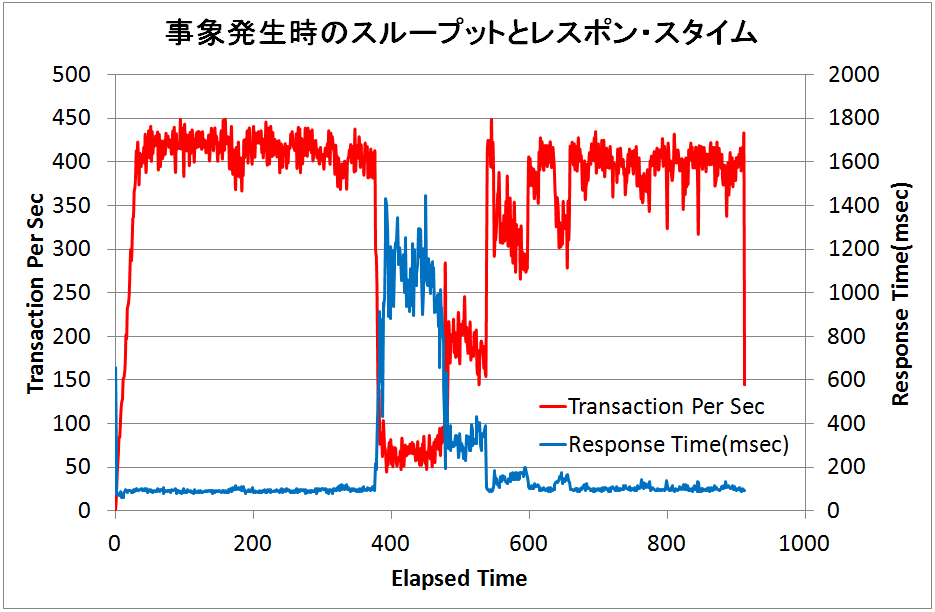
1. 次のスループットとレスポンス・タイムを表したグラフを参照し、問題点を挙げて下さい。
第29回目にして初めて、検証準備のためのSQLが無いという演習1となります。とは言え、このような演習も面白いのかもしれませんね。と言う事で、早速解説していきましょう。
データベースのパフォーマンス検証を実施する上で必ず作成することになるのが、横軸を時間軸としたスループットとレスポンス・タイムを表すグラフだと思います。そして、このグラフを見て第一に確認することは、「綺麗な線を描けているか?」です。いかがでしょう? 左側から右側へ時間の経過を表しており、400秒を経過する前あたりで、突然赤線のスループット(Transaction Per Sec = その1秒間あたりに実行できたトランザクション数)が大幅に減少してしまっていることを確認できます。スループットは秒間の処理性能ですから、その値が大きな方が優秀であることが理解できます。そして、このスループットの劣化が600秒近くまで続いてから元のスループットへ復活しているように見えますね。明らかに、上のグラフの線は「綺麗とは言えない」でしょう。問題点は、「400秒~600秒の間にあるスループットの大幅劣化である」という答えで正解です。
しかし、私が作成したワークロード(負荷と同義)が400秒~600秒の間だけ、データベース・サーバーに対する処理の要求を少なくするようにしていたらどうでしょう? 同じようなスループットの線を描くことができちゃいますよね。もちろん、私はそんな小細工はしていませんが、結果のグラフだけではなく、どのような特性のワークロードを使用してパフォーマンス検証を実施しているのかという情報もヒアリングする必要があるということも頭に入れておいてください。
とは言え、今回のグラフであればそのようなヒアリングをあまり必要としません。なぜならば、スループットの線だけではなく、もう一つの青線で表示されているレスポンス・タイム(Response Time = その1秒間に処理した全てのトランザクションのレスポンス・タイムの平均)がスループットの大幅劣化と同じタイミングで同様に劣化しているからです。レスポンス・タイムはスループットとは逆で、その値が小さければ小さいほど、速くトランザクション処理が完了したことを意味します。それが大きな値になったと言う事は、一つのトランザクションを処理する時間が長くなってしまった → 次のトランザクションを実行するまでの時間が延びる → 一秒間当たりに処理できるトランザクション量が減る → スループットが劣化した。と言う流れだと解釈できるので、ワークロードに小細工が施されていたなどと疑う余地も無いのです。
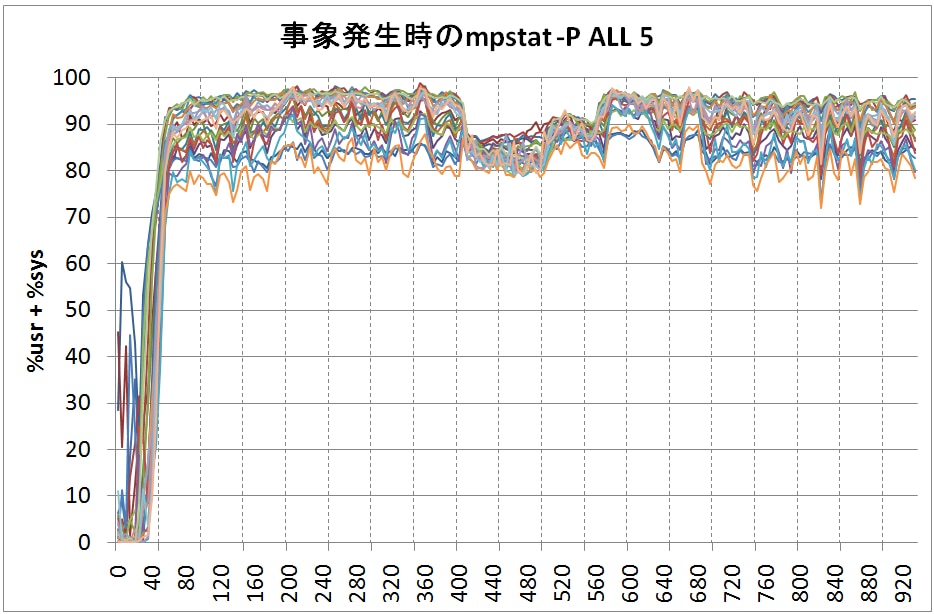
2. 次のCPU使用率のグラフを確認し、CPUリソース不足による問題か否かを判断して下さい。
皆さんがCPU使用率を確認しておきたいだろうと勝手に推測し、グラフを用意させて頂きました。
上のグラフは、データベース・サーバーでコマンド「mpstat –P ALL 5」で、5秒間隔でCPUコア毎のCPU使用率(%usr + %sys)を計測したものです。演習1で問題が発生していた期間である400~600秒の間、CPU使用率はどのように変化していたでしょう?
答えは明確ですね。CPUリソースは余っています。特定のCPUコアが100%に張り付いているわけでもなく全てのCPUコアが80~90%を推移しています、何よりもスループットが高い時の方がCPU使用率は高かったことは明らかですから、今回の問題はCPUリソースが不足して発生したとは考えにくいという結論に至りますね。ちなみに、Disk I/Oにも特に問題が無かったと言う事をお伝えしておきます。ちょっとグラフを用意するには時間がかかりそうだったので、割愛させて頂きますね。。。
さて、何が問題なのでしょう? と言う事で、いよいよDBAの腕の見せどころがやってくるわけです。ワクワクしますね!!
今回は比較的簡単な方法である、AWRレポートを比較して特定してみましょう。ちなみに、私が好きな別の方法としては以前にも少し使用したActive Session Historyがあります。こちらはV$ビューを直接参照しても良いですし、Enterprise Managerが提供するグラフを使用するのが非常に便利ですね。
3. 事象が発生する前(SnapID:287~288)と発生中(SnapID:288~289)の2つの期間のAWRを比較して下さい。
$ sqlplus /nolog
SQL> connect system
@?/rdbms/admin/awrddrpt.sql
-- 省略
Listing all Completed Snapshots
Snap
Instance DB Name Snap Id Snap Started Level
------------ ------------ --------- ------------------ -----
orclp1 ORCLP 287 11 May 2014 21:14 2
288 11 May 2014 21:19 2
289 11 May 2014 21:24 2
290 11 May 2014 21:30 2
291 11 May 2014 21:35 2
Specify the First Pair of Begin and End Snapshot Ids
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Enter value for begin_snap: 287
First Begin Snapshot Id specified: 287
Enter value for end_snap: 288
First End Snapshot Id specified: 288
-- 省略
Specify the Second Pair of Begin and End Snapshot Ids
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Enter value for begin_snap2: 288
Second Begin Snapshot Id specified: 288
Enter value for end_snap2: 289
Second End Snapshot Id specified: 289
Specify the Report Name
~~~~~~~~~~~~~~~~~~~~~~~
The default report file name is awrdiff_1_287_1_288.html To use this name,
press <return> to continue, otherwise enter an alternative.
Enter value for report_name:
Using the report name awrdiff_1_287_1_288.html
今回の私のテスト環境では、900秒間のパフォーマンス検証中に300秒毎にAWRのスナップショットを実行していた為、問題が発生していない期間(0~300秒)と問題が発生している期間(300秒~600秒)の二つの期間のAWRレポートを作成することが可能でした。とは言え、AWRレポートを二つ作成するのもカッコ悪いので、第20回の連載でも体験して頂いた、AWR期間比較レポートを作成してみました。復習になりましたが、覚えていましたかね?
4. 次のAWR期間比較レポートのTop Timed Event部分の抜粋から、待機イベントの傾向の違いを確認してください。

左側「1st」が0秒~300秒の間、つまり事象が発生しておらず期待通りのパフォーマンスを得られていた際の上位の待機イベントになります。右側「2nd」が300秒~600秒の間でパフォーマンスが劣化している期間中の上位の待機イベントとなります。
まずは左側の傾向を理解しておきましょう。CPU time(これは待機ではなく、CPUを使用していることを示す)が一番上に来ていますから、効率的にCPUを使用していると解釈して良いでしょう。もちろん、非効率なSQLが存在していて無駄にCPUを消費している場合にも、このような傾向が表れることがありますので注意が必要ですが、今回は問題の事象の原因特定ですから、現時点ではそこまで踏み込まなくても良いですね。
次に2番目の待機イベントは「log file sync」であり、Wait Classに「Commit」と記載されていることから推測できるように、この待機イベントはサーバー・プロセスのコミット待ち時間となります。LGWRがSGA内のLog BufferからDisk上のオンラインRedo Logfileへ書き出しが完了するのを待機している時間ですね。平均待機時間は7.7msecなので、速くも遅くも無い。そんな印象です。
3番目、4番目にはI/O系の待機イベントが登場しています。待機イベント名からもバレテしまいましたが、実は私のパフォーマンス検証の環境は、Exadataだったのですね。「cell single block physical read」待機イベントは、非Exadataでは「db file sequential read」待機イベントに該当します、また、「cell multiblock physical read」待機イベントは非Exadataでは「db file scattered read」待機イベントです。この待機イベントの違いは覚えていますでしょうか? と質問しようと思ったのですが、これまでの連載では解説していなかったのかもしれませんね。ちょっと見当たらなかったので。。。 タイミングがオカしいので頭出しだけしておくと、シングル・ブロック読込みか、マルチ(複数)ブロック読込みの違いになります。過去の連載を見直して、このあたりの待機イベントの体験を改めて用意しようと思いますので、詳しい解説はまたの機会にしますね。
はい。えーと、期待通りのパフォーマンスを得られていた際の上位の待機イベントの傾向の理解が済んだので、次は右側の問題の事象が発生している期間の傾向について確認していきましょう。
1番目は同様にCPU timeですので次へ進みます。2番目に「enq: US – contention」待機イベントなるものが登場していますね。一回の待機あたりの平均待機時間は1.52msecなので、非常に小さな待機ですが、待機した総数(Waits)が、他の待機イベントと比較して尋常ではない感覚を覚えて頂けると思います。「contention」と表記されていることから、何やらの競合による待機がデータベース内で発生していると推測できますから、この待機イベントが原因で、スループットやレスポンス・タイムが劣化したのではないかと第一容疑者として疑ってしまって良いと思います。
大部分の待機イベントは、リファレンス・マニュアルでその意味が紹介されていますが、今回の「enq: US – contention」待機イベントは残念ながら記述されておりませんので、簡単に私の方で解説しておきます。USはUndo Segmentの略であり、UNDOセグメントを確保/解放する処理を要求したが、他のプロセスが同じ処理を実行中なのでキューの中で順番待ちしている際に発生するイベントです。と言う事は、「UNDOセグメントが枯渇しているのでは?」とピンと来た方、ズバリ正解です!!
5. パフォーマンス検証中のTUNED_UNDORETENTIONの値を確認し、UNDO_RETENTION初期化パラメータに設定した期間、読取一貫性が保証されているのかを比較して下さい。
$ sqlplus / as sysdba
SQL> show parameter UNDO_RETENTION
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
undo_retention integer 300
SQL>
set linesize 150 pages 50000
alter session set NLS_DATE_FORMAT='HH24:MI:SS' ;
select BEGIN_TIME, END_TIME, TUNED_UNDORETENTION,
UNDOBLKS, TXNCOUNT, MAXQUERYLEN, MAXQUERYID, MAXCONCURRENCY
from V$UNDOSTAT
order by 2 ;
BEGIN_TI END_TIME TUNED_UNDORETENTION UNDOBLKS TXNCOUNT MAXQUERYLEN MAXQUERYID MAXCONCURRENCY
-------- -------- ------------------- -------- -------- ----------- ------------- --------------
21:11:37 21:21:37 420 4237587 1051457 338 0rc4km05kgzb9 139
21:21:37 21:31:37 399 4474906 1222692 940 0rc4km05kgzb9 96
21:31:37 21:35:13 517 4253 1488 1241 0rc4km05kgzb9 3
ここまでパフォーマンス劣化の問題が発生したという前提で話を進めてきましたが、この演習5は、改めて冒頭で述べた文章「ORA-1555が発生しなくとも実はパフォーマンスの問題が発生しているかも?」を確認する為のものです。UNDO保持期間は自動チューニングされると言った内容を前回の連載で体験して頂きましたので、その復習でもあります。
それほど難しくないでしょう。V$UNDOSTATビューでパフォーマンス検証中のTUNED_UNDORETENTIONの値を確認すると、UNDO_RETENTION初期化パラメータに設定されている値「300秒」よりも大きな値になっていることから、読取一貫性を300秒以上保証している事が理解できますね。
改めて今回の私のワークロードをご紹介すると、100msec程度で完了する更新トランザクションを多くのセッションから900秒間連続実行する大規模オンライン・トランザクションを想定したものであり、数十秒や数百秒といった長時間要するクエリーは実行していません。そのためUNDO保持期間の300秒は充分過ぎる期間でもあり、しかも300秒保持できるUNDO表領域のサイズであることも上記の結果から明らかです。
しかし、今回は「ORA-1555が発生しなくとも実はパフォーマンスの問題が発生していた」という事実があり、しかも、enq: US – contention待機イベントが多発していることから、UNDOセグメントが枯渇している可能性が高そうですよね。読取一貫性としてUNDO表領域は充分なサイズだけど枯渇している? 良く分からないですよね。この事実をもう少し確認してみましょう。
6. 前回の連載の演習8で使用したUNDO表領域の使用率を継続するSQLを実行し、事象発生のタイミングと使用率の関係を考察して下さい。
$
vi undo_usage.sql
-----
select to_char(sysdate,'YYYY/MM/DD HH24:MI:SS') "TIME",
round("USED_SIZE(MB)", 3) "USED(MB)",
round("TBS_SIZE(MB)", 3) "TBS(MB)",
round("USED_SIZE(MB)"/"TBS_SIZE(MB)" * 100, 3) "USAGE(%)"
from (select sum(BYTES)/1024/1024 "USED_SIZE(MB)"
from DBA_UNDO_EXTENTS
where STATUS in ('ACTIVE', 'UNEXPIRED')
and TABLESPACE_NAME = 'UNDOTBS1') ,
(select sum(BYTES)/1024/1024 "TBS_SIZE(MB)"
from DBA_DATA_FILES
where TABLESPACE_NAME = 'UNDOTBS1') ;
-----
$ ### undo_usage.sqlを5秒間隔で実行(Linux環境)
while true; do
cat undo_usage.sql
sleep 5
done | sqlplus –s / as sysdba
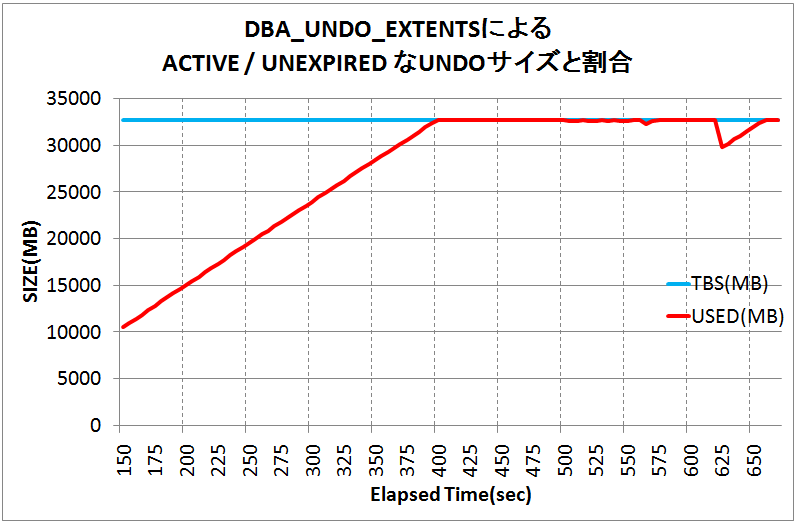
確認し易い用に、こちらもグラフ化してみました。いかがでしょうか?と言うまでも無く、400秒経過のタイミングでUNDO表領域を使い切ってしまっていることが明らかですね。このタイミングが演習1で確認したスループット/レスポンス・タイムのグラフの劣化開始のタイミングと合致することからも、今回の問題事象の犯人はUNDO表領域の枯渇と言って良いでしょう。もちろん、「300秒のUNDO保持期間は常に満たしていたけど」という部分も理解しておく必要があります。
7. 今回の900秒間のWorkloadにおいて、パフォーマンスの劣化を発生させないようにする為には、何GBの空きがあるUNDO表領域が必要になるでしょうか?
5 [GB] : 50 [sec] = X [GB] : 900 [sec]
X = 5 * 900 / 50
X = 90 [GB]
はい、最後は簡単な算数の問題となりました。演習6のUNDOセグメントの成長率から、50秒間で約5GBと推定すると、900秒間で90GBになります。よって、このWorkloadのパフォーマンス検証の際には90GBのUNDO表領域を毎回作成し直してから開始すると最速なスループットを確認することが出来るということになります。
ちなみに、このような最適なUNDO表領域のサイズにチューニングして、再度パフォーマンス検証を実施した結果のスループット・グラフは次のようになりました。問題が完全にクリアされていますね!!
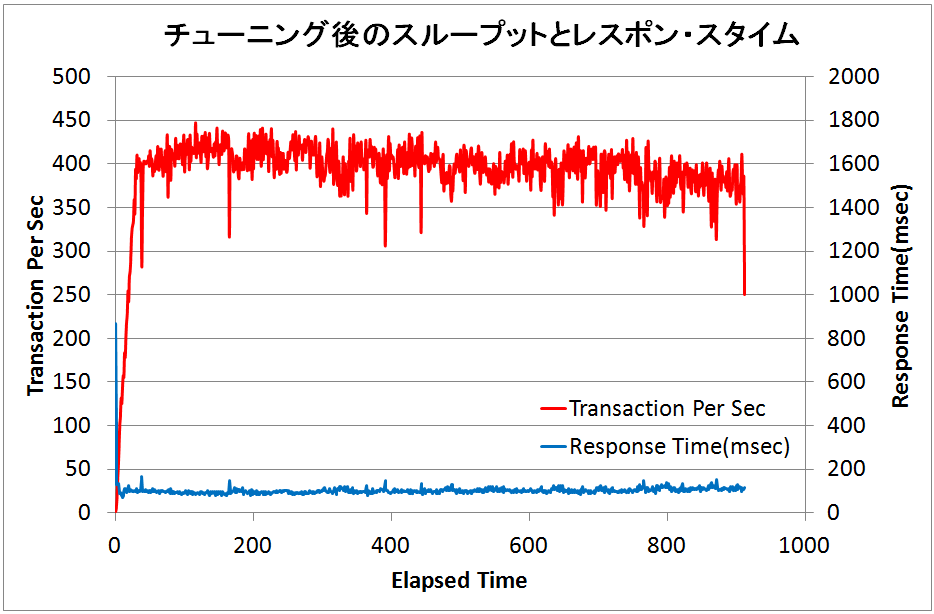
さて、いかがでしたでしょうか?
いつもの連載とは異なり手を動かす演習問題が非常に少なかったですが、データベースのパフォーマンス・チューニングの一つの例として参考になったのであれば、非常に嬉しい限りです。
UNDO表領域のサイズは、読取一貫性エラーの発生が抑止できれば良いだけではなく、パフォーマンスの劣化を避けるためのサイズ設計が必要な場合があると言う例を示したものですが、大規模データベースで、大量ユーザーによるアクセス、高頻度な更新処理の要求等の様々な条件が組み合わさった上で発生する事象であり、全てのデータベースで発生する訳ではないので、それほど慎重になる必要はありません。まず重要なのは、読取一貫性を維持できるだけのUNDO表領域のサイズにすること。次に、高いスループットが求められる連続期間の間、UNDO表領域が枯渇しないように設計する。このような流れで、データベース管理を進めていくのが良いかと思っています。
今回も最後まで体験して頂きましてありがとうございました。次回以降もどうぞよろしくお願い致します。
