皆さんこんにちは、やっと暖かくなってきたと思ったらもう梅雨ですね。今年もジメジメしていて大変ですが体調に気をつけて頑張りましょう。
今回は、第18回に読取り一貫性の説明をしましたので、その続きとして「UNDOデータ」についてと、それと同じように重要な「REDOログ」について説明しようと思いますので、参考にして下さい。未だにロールバックセグメントを使用している方もいると思いますので、これを読んだら是非ともUNDOセグメントに変更しようと思っていただけたら幸いです。
■ 1. UNDOデータについて
まずは、第15回でも簡単に説明したUNDOデータについて説明しましょう。
UNDOデータを管理するには、Oracle9iからUNDO領域管理モード(初期化パラメータUNDO_MANAGEMENT)として自動UNDO管理モード(UNDOセグメント)と手動UNDO管理モード(Oracle8i以前からのロールバックセグメント)があります。UNDOデータは、トランザクションのロールバックに使用されるのが主な目的ですが、第18回で説明した読取り一貫性にも使用されます(つまり、更新データのビフォアイメージを格納しています)。ただし、トランザクションが確定(コミットまたはロールバック)するまでは上書きされないようにしますが、確定されると必要に応じて上書きされる仕組みです。そのため、UNDOデータは以下のような相反することを行う必要があることから設定を難しくしている訳です。
・パフォーマンスのためには小さいサイズで上書きして使用したい(バッファキャッシュの消費を抑えたい)
・ORA-1555(スナップショットが古すぎます)を発生させないためにはあまり上書きさせたくない
これを自動的に行うのがOracle9iからのUNDOセグメントです。第16回で少し触れたフラッシュバック機能のフラッシュバック問合せ、フラッシュバック・テーブルなどを使用する場合は、UNDOセグメントを使用する必要がありますので注意して下さい。それでは、ロールバックセグメントとUNDOセグメントについて説明していきます。
ロールバックセグメントの動作について
ご存知ない方のために、ここでロールバックセグメント(RBS)の動作について簡単に説明します。
RBSは、セグメント数(RBS当たりのトランザクション数)、エクステントのサイズと数(MINEXTENTSパラメータとOPTIMALパラメータ)で調整します。基本はMINEXTENTS(最小のエクステント数)を上書きして使用しますが、エクステントスイッチのときに(エクステントを切替るときに)次のエクステントにアクティブ・トランザクション(確定されていないトランザクション)が存在すると、上書きできないので(ロールバックできなくなるため)エクステントを追加します(以下の図では、エクステント1から0へ切替るときエクステント0にアクティブ・トランザクション①が存在するため、エクステント2を追加しています)。また、エクステントスイッチのときに次のエクステントにアクティブ・トランザクションが存在していないと、OPTIMALサイズまで自動的に縮小(SHRINK)するためにエクステントが削除されます(OPTIMALを指定していないと自動縮小しません)。これは、一時的に大きくなった領域を削除することで効率良く動作させるためです。この判断が上手くいかないと、拡張と削除が繰り返されることになり、オーバーヘッドが多くなってしまう訳です。このようなことを机上で計算するのは難しいため、十分なテストをして確認する必要があり、RBSの設定を複雑にしているのです。UNDOセグメントの縮小については、エクステントを拡張するときに領域が圧迫すると、他のUNDOセグメントから未使用エクステントを移行して行いますので、無駄な動作はしないようにしています(拡張の基本的な動作は同じです)。
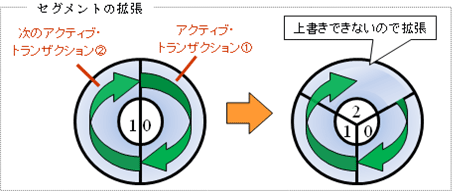
(1)ロールバックセグメント
ロールバックセグメント(RBS)を使用する場合は、正しく見積もれないと「足りなくなると大きくする」という動作が頻繁に発生してパフォーマンスが低下します。そのため、RBSの数とサイズを適切に見積もる必要があります。RBSの数は、一般的には4トランザクションにつき1つ程度のRBSを割り当てるのが望ましいです。これで自動的に負荷の少ないRBSをアサインします。RBSのサイズについては、明確なガイドラインはないので以下のようなこと(エクステントなど)を意識して見積もりを行う必要があります。私もOracleデータベースを使い始めた頃は、このRBSを非常に難しく感じた記憶があります(これができて一人前の技術者という感じですかね)。
サイズが大きいと頻繁に拡張が発生する
エクステントサイズが大きい(エクステント数が少ない)と拡張され易くなります。これは、一つのエクステントに多くのアクティブなトランザクションが格納されるため(ただし、同一ブロックに格納されるのは同一トランザクションのみです)、エクステントスイッチするときにアクティブ・トランザクションが存在する可能性が高いためです。
サイズが小さいと頻繁にエクステントスイッチが発生する
エクステントサイズが小さいと(エクステント数が多くなるため)エクステントスイッチが発生し易くなり、そのときのオーバーヘッドが大きくなります(エクステントスイッチの度に縮小を行うかの確認が必要になるためです)。
コミット済データの上書き時期に影響する
ORA-1555が発生しないようにコミット済みデータの上書き時期を調整するには、エクステントサイズ、MINEXTENTS及びOPTIMALなどで間接的に調整する必要があります(そのため、十分なテストをしてみないと発生しないか分かりません)。エクステントサイズが大きいと、上書きされると大量のUNDOデータを失ってしまいます(エクステント単位に上書きするからです)。また、小さいと短いトランザクションでは上書きされ易くなります(トランザクションが確定するまで短いからです)。そのため、MINEXTENTSで上書きの時期を調整する必要があります。
つまり、大き過ぎても小さ過ぎても(数が少な過ぎても多過ぎても)効率が悪いといことです。一般的に、OLTPシステムのような処理の短いトランザクションでは、エクステント(最小数とサイズ)を小さくすることで頻繁に上書きされるようにして、DBバッファキャッシュを無駄に消費しないように実装します。ただし、このような短いトランザクションと同時に長い検索処理を実行するような場合は、ORA-1555エラーが発生し易くなりますので注意が必要です(例えば、第18回に説明した分離レベルが「READ COMMITTED」の場合は、SQL文が実行されたときにコミットされたデータを生成する必要があるため、以下の図のようにSQL文が終了するまで上書きさせないようにする必要があります。これが「SERIALIZABLE」だとトランザクションが終了するまでですので、更に長くなります)。このようなことがRBSの設定を複雑にしている訳です。
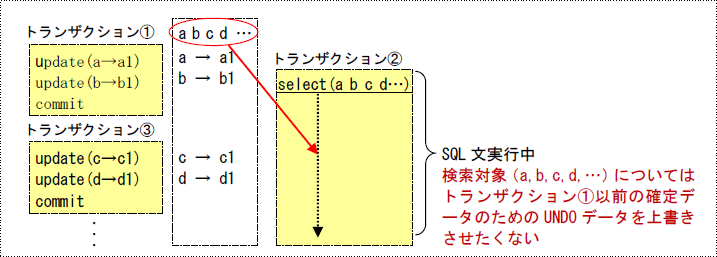
トランザクションが大きくなるバッチ処理などでは、エクステント拡張が多く発生しないように大きなエクステントサイズのRBSを割当てる必要があります(以下のSQL文で明示的にRBSを割り当てます)。ただし、パラレルDMLを使用している場合には複数のRBSが必要なため、以下のSQL文は無視されますので注意して下さい。
SQL> SET TRANSACTION USE ROLLBACK SEGMENT <ロールバックセグメント名>
このようなことをStatspackの「Rollback Segment Stats」などで動作状況を確認して調整する必要があります。以下は「Rollback Segment Stats」の例です(Wrapsがエクステントスイッチの回数、Shrinksがエクステントの縮小回数、Extendsがエクステントの拡張回数になりますので、これを見て調整します。そして、「Pct Waits」がセグメントヘッダ取得時の待ちの比率で、これが大きいとRBSの数を増やすなどを行う必要があります)。

このように検討しなければいけないことが多くあるため、設定するのが非常に大変だということが分かって頂けたかと思います。これに対してUNDOセグメントはどうなのかを次に説明しましょう。
(2)UNDOセグメント
RBSでは、セグメント数、エクステントのサイズと数で間接的に調整する必要がありましたが、UNDOセグメントはUNDO表領域(AUTOALLOCATEを使用するのでセグメントサイズでエクステントサイズが自動調整されます。RBSではAUTOALLOCATEは使用できません)と初期化パラメータUNDO_RETENTION(コミット済みデータの上書きのタイミング)を指定するだけで自動的に行ってくれるようになっています(セグメント数とエクステント数については、負荷に応じて自動的に追加と削除を行います)。ただし、自動的に行うからと言ってもUNDO表領域サイズやUNDO_RETENTIONの見積もりは行う必要があり、Oracle9iまではこの見積もり(UNDO_RETENTIONの時間でどれだけの領域が必要かを検討するなど)が以下のように大変でした
UNDO_RETENTIONの設定が難しい
この値が小さ過ぎるとORA-1555が発生する可能性があり、大きく過ぎるとUNDO表領域を無駄に消費してしまうので、効率良い値を設定するのが難しいです。そのため、Oracle Database 10gからはUNDO_RETENTIONの自動チューニングが追加されています。これは、MMONプロセスが30秒ごとに問合せの最大実行時間(v$undostat.maxquerylen)をベースに算出しますので(このときUNDO_RETENTIONが最小値になります)、RBSの例のような長いSQL文にも対応できるようにしています。
UNDO表領域の見積もりが難しい
UNDO表領域のサイズが小さいと領域不足によるORA-30036(セグメントを拡張できません)が発生してしまうので、領域不足にならないようにする必要があります。そのため、Oracle9iではUNDO表領域の領域が不足した状態になると、UNDO_RETENTIONの時間が経過していなくても上書きする場合があります(ORA-1555が発生し易くなります)。Oracle Database 10gからUNDO表領域にGUARANTEE句を設定した場合は、UNDO_RETENTIONを完全に保障できるようになっています(ただし、UNDO表領域が小さいと領域不足になります)。
UNDO_RETENTIONの自動チューニングでは、領域が不足している状況になると、UNDO_RETENTIONより小さい値にするかGUARANTEE句によって判断されます(UNDO_RETENTIONを優先する場合はGUARANTEE句を、領域不足の回避を優先する場合はNOGUARANTEE句を指定します。デフォルトはNOGUARANTEE句です)。ただし、GUARANTEE句を指定してもTUNED_UNDORETENTION(自動チューニングされた保持期間)が保障される訳ではありませんので注意して下さい。Oracle Database 10gR2から自動拡張が無効な場合は(領域不足になる可能性があるので)、UNDO表領域の使用率をベースに算出します(GUARANTEE句が設定されていないとUNDO_RETENTIONは無視されます)。
このように、UNDOセグメントではUNDO表領域のサイズが重要になります(つまり、基本はUNDO表領域のサイズだけを注意するば良いということなので、非常に簡単になったと思います)。そのため、領域不足にならないようにUNDO表領域を自動拡張(AUTOEXTEND ON)にするか、固定サイズ表領域の場合はOracle Database 10gからのUNDOアドバイザ(PL/SQLのDBMS_ADVISORパッケージでアドバイザ名を‘Undo_Advisor’として使用するかEnterprise Managerで行います)を使用して下さい(これはOracle Database EE以外でも使用できます)。
■ 2. REDOログについて
次に、REDOログについて説明します。
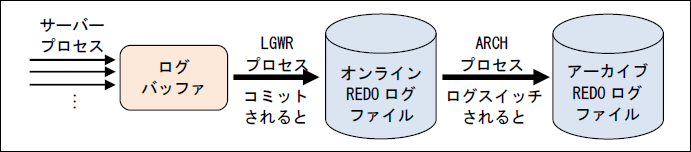
REDOログには、第12回「I/O周りについて」で説明したようにオンラインREDOログとアーカイブREDOログがあり、トランザクションのロールフォワード用のデータを出力します(ログバッファとオンラインREDOログファイルとアーカーブREDOログファイルの関係は以下の図のようになります)。オンラインREDOログファイルは、ロググループを複数作成して(最低でも2つ必要です)、そのファイルをログスイッチしながら循環して使用します。Oracleデータベースはパフォーマンス向上のため、バッファキャッシュに格納したデータをストレージに非同期で(遅延して)書込んでいるため、REDOログだけは整合性のためコミット時にディスクに書込まれます(その他に、コミットしていないダーティ・ブロックが書込まれると、「Write ahead log」によりそのREDOログが先に書込まれます。つまり、チェックポイントなどでも書込まれます。また、未書出しログがログバッファの1/3になっても書込まれます)。そのため、REDOログはトランザクション性能には重要になります。このとき、UNDOセグメント(RBS)も他のセグメント(表や索引など)と同じようにREDOログとして出力されます。このREDOログは重要ですが、あまりチューニングできる要素は多くありません。ここでは、その中からいくつか(ログバッファ、REDOログファイルのサイズ、待機イベントなど)を説明しましょう
(1)ログバッファ
ログバッファは、SGAに存在するREDOログ用のバッファです。第14回でメモリ・チューニングは説明しましたが、自動メモリ管理の対象ではないこともありログバッファを説明していなかったので、改めて説明しようと思います。
ログバッファは、一つだけなので同時トランザクションが多いとラッチ(allocationラッチ、copyラッチ、writingラッチ)の競合が発生し易くなります(copyラッチは複数指定可能ですが、allocationラッチとwritingラッチは1つだけです。Oracle9iR2からはallocationラッチも初期化パラメータLOG_PARALLELISMで複数指定可能になっています)。ただし、ラッチについては、Oracle Database 10gからはOracleデータベースがすべて自動的に最適な設定を行いますので(そのため、ラッチ関係の初期化パラメータはなくなりました)、あまり気にする必要がありません。ログバッファのサイズについては、デフォルトの5Mバイトをグラニュル・サイズ(SGAサイズが1Gバイト以下では4Mバイト、8Gバイト以下では16Mバイト、16Gバイト以下では32MバイトなどのようにSGAサイズによって変化します)に切り上げられますので、基本はデフォルトのままで問題ありませんが、「redo buffer allocation retries」統計(ログバッファに割当てできずにリトライした回数)と「log buffer space」待機イベントが多発しているような場合には増加するようにして下さい。つまり、一般的には、あまり気にする必要がないということです(自動調整がされないのは動的変更するのができないからです)。以下のSQL文でログバッファ・サイズ(Redo Buffers)を確認できます(例はデフォルトの時のログバッファです)。
SQL> SELECT * FROM v$sga ; NAME VALUE -------------------- ---------- Fixed Size 1374696 Variable Size 276825624 Database Buffers 461373440 Redo Buffers 5337088
(2)REDOログファイル
REDOログファイルは、ファイルサイズとロググループの数をどのくらいにするかが重要です。ロググループの数が少ないとログスイッチが待たされてしまう場合がありますので(このときログバッファを書込めなくなるのでトランザクションも待たされます)、3つ以上のロググループにするようにして下さい。REDOログファイルのサイズは、LGWRプロセスの書込み性能に影響を与えませんが、DBWRプロセスおよびチェックポイント動作に影響を与える場合があります(ログスイッチ時にチェックポイントが発生するためです)。そのため、ログ・ファイルが小さすぎることによるチェックポイントの追加発生(頻繁なログスイッチ)を防ぐために、ログ・ファイルを十分なサイズに設定する必要があります。ファースト・スタート・リカバリ機能(初期化パラメータFAST_START_MTTR_TARGET)を使用している場合は、REDOログファイルサイズ・アドバイザ(以下のSQL文またはEnterprise Manager)を使用することで最適なサイズを取得できますので、使用すると良いでしょう。ファースト・スタート・リカバリ機能を使用すると、インスタンスリカバリを高速化するためチェックポイントが頻繁に発生しますので、ディスク性能が更に要求されることを忘れないで下さい。
SQL> SELECT optimal_logfile_size FROM v$instance_recovery ;
(3)待機イベント
最後に、REDOログに関する主な待機イベント(ログバッファ待ち、REDOログ書込み待ち、ログスイッチ待ちの3つがあります)を簡単に説明しておきますので、参考にして下さい。
log file parallel write
LGWRプロセスがカレントログファイルに書込んでいる時の待機です。これは、REDOログファイルの書込み(サイズと回数)とディスク性能によります(書込みサイズは、トランザクションのREDOログサイズによるので、固定ではありません。最大サイズは1Mバイトです)。ログメンバーファイル(障害対応のための多重化)ごとにパラレル化されて書込まれるために、待機イベント名が「log file parallel write」になっています。1ファイルにパラレルで書込んでいる訳ではありませんので、間違えないようにして下さい(これは第12回で説明しましたよね)。
log file single write
ログファイルヘッダ・ブロックへ書込む時のみの待機です。これは、メンバーファイル追加やログスイッチによってログ順序番号が進む場合などで発生します(これは、あまり気にする必要はないですが、多い場合はファイルサイズが小さいことによるログスイッチが多いのが一般的な原因です)。 ログメンバーファイルが1つだから非パラレル化(シングルライト)になっている訳ではありませんので注意して下さい。ここあたりが待機イベントの分かり辛いところだと思います。
log buffer space
ログバッファの空き待ちです。これは、REDOログ書込みよりREDOログ生成が速い場合に起きますので、ログバッファを大きくするかオンラインREDOログファイルの書込み性能をアップして下さい。
log file sync
コミットなどのトランザクション確定時のREDOログファイル書込み待ちです(「log file parallel write」はLGWRプロセスの待ちですが、これはサーバープロセスの待ちです)。これは必ず発生する待機イベントです。REDOの書込みは整合性のため同期で行います(必ず書込み終了まで待ちます)ので、この書込み時間は多かれ少なかれ必ず待ちとして発生する訳です。ただし、全セッションが同時に待つことはありませんので(内部的にはグループ・コミットなどを使用して効率良く行っています)、REDOログファイル書込みがよほど遅くない場合以外は気にしなくて良いと思います。LGWRの書込み「log file parallel write」が遅いとこの待機イベントも長くなりますので、その場合はREDOログファイルの書込み性能を改善して下さい。
log file switch(checkpoint incomplete)
これは、ログスイッチする次のログファイルがまだ使用可能でない場合に発生する待機です。カッコの中がその理由になります。体表的なものとして「checkpoint incomplete」(チュックポイントが完了していないため)と「archiving needed」(アーカイブが完了していないため)があります。「checkpoint incomplete」のときはチェックポイントが速く終わるようにデータファイルのディスク性能を向上して下さい。「archiving needed」のときはアーカイブ格納先のディス性能を向上して下さい。または、アーカイブ先を減ら(初期化パラメータLOG_ARCHIVE_DEST_n)かARCHプロセス(初期化パラメータLOG_ARCHIVE_MAX_PROCESSES)を増やして下さい。このプロセスはアーカイブ中にログスイッチが発生すると別のプロセスで行ってくれます(ロググループ毎に行ってくれます)。それから、ログファイルサイズを大きくしてログスイッチを少なくするか、ロググループ数をもう少し多くして処理していないログファイルがないように(すべて処理中にならないように)することを検討して下さい。
LGWR wait redo copy
これはコピーラッチ待ちです。OracleがCPUコア数を基に自動調整しますのであまり気にする必要はありません。
■ 3. おわりに
今回はUNDOデータとREDOログについて説明しました。すべてを詳細に説明することはできませんでしたので、また機会があれば説明しようと思います。これからも頑張りますのでよろしくお願いします。
それでは、次回まで、ごきげんよう。
