皆さんこんにちは、梅雨が明けて急に暑くなってきたと思っていたら、また梅雨のような感じですね。まだ気温差が大きいので体調に気をつけて頑張りましょう。
今回は、「パフォーマンスの良いSQL文について」の続きとして表結合とオプティマイザのSQL自動変換について説明しようと思いますので、参考にして下さい。
1. 表結合について
まずは、表結合について説明しましょう。
OracleデータベースでSQLの性能に大きく影響するのが表結合です。つまり、最も難しいところですが、これを上手く行うとSQLチューニングを効果的に行うことが可能です。表結合は何度か説明してきましたが、どのような結合方法(ハッシュ結合、ソート・マージ結合、ネストテッド・ループ結合など)でも、基本はできるだけ少ない行数のテーブルから結合するのが効果的です。このとき、できるだけ少ない行数にして結合すると更に効果的です(これは、第9回の「結合は件数を絞り込んでから」で少し説明しましたよね)。表結合といっても様々なパターンがあります。特に副問合せを含んだSQLは、難しくなりますので、そのようなことを少し整理して説明します。
(1)副問合せ
副問合せには、以下のSQLのようにFROM句の副問合せ(左側で、インライン・ビューと呼びます)とWHERE句の副問合せ(右側で、ネストした副問合せと呼びます)があります。それぞれは以下のような理由によって使用されます。
- 中間結果または実行計画の一部を明示的に指定するため(インライン・ビュー)
- 通常の問合せでは求められないため(ネストした副問合せ)
ネストした副問合せは、結果が1行またはTRUE/FALSEになるようにする必要がありますので、通常は条件(IN、EXISTS)や比較条件(ANY/SOME、ALL)などを使用します(=ANY/=SOMEはINと同じ動作、!=ALLはNOT INと同じ動作になります)。以下の二つのSQLは、第9回の「INとEXISTSについて」で説明したように同じ実行計画になります(右側のSQLは、後から説明するセミ結合に変換される場合もあるので、ここではNO_SEMIJOINヒントを指定しています)。
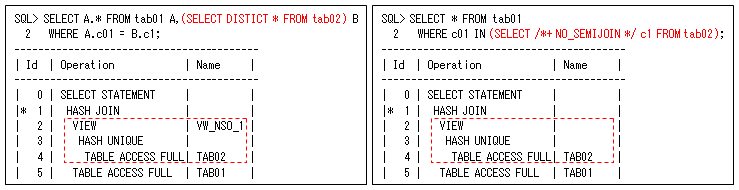
ネストした副問合せで最も効率が悪いのが、以下のような相関副問合せになります。これは、副問合せで主問合せの列を参照しているようなSQLで、基本的に副問合せ部分を複数回評価(主問合せの結果だけ実行)する必要があるので、通常は効果的に実行することはできません。

この三つのSQLは同じ実行結果になりますが、SQL構文によってこのように異なってきます。副問合せは、上記実行計画の赤い点線の部分のように、基本は個別に実行されますので、この記述で性能が大きく変わってきます。そのため、この副問合せをいかに効果的に使用するかが、SQLチューニングでは重要になります。
(2)表結合の最適化
副問合せ(またはビュー)を含んだSQLも同様に表結合を行いますが、「(1)副問合せ」で説明したように、通常の表結合と同じように扱うことはできません。そのため、効率が悪い副問合せは、効果的な実行計画になりませんので、作成するには注意が必要です。そうはいっても、効率良い副問合せを作成するのは簡単ではありませんので、オプティマイザ(CBO)が可能な範囲で、SQLを自動変換して最適な実行計画を作成します(これがCBOのメリットでもあります)。表結合を最適化するためには、一般的に以下のようなことを行います。
- ビューのマージ
ビュー(インライン・ビューも含みます)を使用している場合の一般的な動作になります。ビューを含むSQLは、最初にビューの問合せを実行する必要がありますが、それが非効率なときがあります(他のテーブルと結合するときに、表結合する順番やビューの元表の索引が使用できないなどです)。このような場合に、主問合せとマージすることで、CBOによって効果的に決めることが可能になります。 - 副問合せで行数を削減する
結合するテーブルの行数を削減できる場合に、最小限にしてから結合する動作になります。内部的に副問合せを作成して、処理する順番を調整することで可能にします(副問合せを使用している場合でも同様に動作します)。WHERE句の述語やGroup By句などをビューまたは副問合せに移動して、結合する行数を最小限にしてから結合します。
つまり、副問合せまたはビューの長所を効果的に利用して、実行計画を最適化するようにする訳です。これを基にSQLを作成すると、効率良いSQLが作成できるようになります。
2. オプティマイザのSQL自動変換について
ここからは、オプティマイザが行うSQLの自動変換について説明しましょう。
表結合などを効果的に行うように、SQLを記述するのは簡単ではないので、CBOのSQL自動変換を使用します。ここでは、このような自動変換を行う動作として、代表的な以下について説明していきます。このようなことを知っているとSQLを作成するときやSQLチューニングするときに参考になると思います。オプティマイザ統計の精度などによって、自動変換されない場合もありますので、そのような場合などにも有効です。
- ビューのマージ
- ネストした副問合せの解除
- 述語のプッシュ
- Group By/DISTINCTの配置の最適化
(1) ビューのマージ
最も簡単な変換がビューのマージです。インライン・ビューは、行数の少ない状態で表結合するように作成します。また、ビューは、セキュリティのデータ・アクセス制御などのために使用します。ただし、以下のような単純な結合などで行数が減少しないビューは、表結合の順番に影響または元表の索引が使用できないため、逆に効率が悪い場合があります。その場合は、ビューをマージしてCBOに決定してもらった方が効果的ということです。
SQL> CREATE VIEW emp_v AS 2 SELECT e.ename, d.dname, d.locid FROM emp e, dept d WHERE e.depid = d.depid; SQL> SELECT /*+ NO_MERGE(A) */ A.ename, A.dname, l.addr, l.zip 2 FROM locations l, emp_v A WHERE A.locid = l.locid; 実行計画 ------------------------------------------ | Id | Operation | Name | ------------------------------------------ | 0 | SELECT STATEMENT | | |* 1 | HASH JOIN | | |* 2 | TABLE ACCESS FULL | LOCATIONS | | 3 | VIEW | EMP_V | |* 4 | HASH JOIN | | | 5 | TABLE ACCESS FULL| DEPT | | 6 | TABLE ACCESS FULL| EMP |
このようなSQLは、CBOが以下のようにビューのマージをすることによって、コストから結合順番を任意に決めることが可能になります(この例は、LOCATIONS、DEPT、EMPの順番に結合した方が効果的な場合です)。このときにマージしたくない場合には、上記のようにNO_MERGEヒントを指定することも可能です(これは第9回で出てきましたよね)。
2 FROM locations l, emp e, dept d WHERE d.locid = l.locid AND e.depid = d.depid ;
実行計画
—————————————–
| Id | Operation | Name |
—————————————–
| 0 | SELECT STATEMENT | |
|* 1 | HASH JOIN | |
|* 2 | HASH JOIN | |
| 4 | TABLE ACCESS FULL| LOCATIONS |
| 5 | TABLE ACCESS FULL| DEPT |
| 2 | TABLE ACCESS FULL | EMP |
ただし、ネストした副問合せは、簡単にマージすることはできませんので注意してください。
(2)ネストした副問合せの解除
ネストした副問合せは、効果的に動作しない場合が多いので、それを回避するためCBOによって動作するのが、ネストした副問合せの解除(Subquery Unnesting)機能です。これはUNNESTヒントで強制的に動作させることも可能です。この機能は、ネストした副問合せを主問合せにマージ、またはインライン・ビューに変換することで、通常の結合条件(等価結合など)に変換しますが、単純に行うことはできません。例えば、重複データがあると結果が異なってしまうからです(以下の二つのSQLの結果は、tab02.c1に重複なデータが存在しているので異なっています)。
SQL> SELECT * FROM tab01 A WHERE EXISTS
2 (SELECT null FROM tab02 B WHERE A.c01 = B.c1);
C01 C02
---------- ----------
1 100
2 200
|
SQL> SELECT A.* FROM tab01 A, tab02 B
2 WHERE A.c01 = B.c1;
C01 C02
---------- ----------
1 100
2 200
2 200
|
具体的にどうのように動作するか、代表的な例(EXISTSまたはIN、NOT EXISTS、NOT IN)を使用して説明していきます。
(a)EXISTSまたはIN
EXISTS(INとANY/SOMEの一部はEXISTS条件に変換されます)を使用した副問合せは、効果的に処理するためSEMI JOIN(セミ結合)に変換します(相関関係のないIN副問合せは、「(1)副問合せ」で説明したようにインライン・ビューに変換される場合もあります。これは「(4)Group By/DISTINCTの配置の最適化」とどちらの効果が大きいかにより決まります)。セミ結合とは、重複データがあると結果が異なってしまう通常の結合を、重複データを無視するように1行見つけた時点で、そのデータを終了するようにします。これでネストした副問合せを、以下のように通常の結合と同様に行うことが可能になります。左側はネストした副問合せを解除した例(”HASH JOIN SEMI”操作で通常の結合条件になっています)、右側は解除しない例(ネストした副問合せを解除しないようにNO_UNNESTヒントを指定しているので、後から説明する直積結合と同等の動作になっています)です。
|
SQL> SELECT c01 FROM tab01 A WHERE EXISTS 2 (SELECT null FROM tab02 B 3 WHERE A.c01 = B.c1); 実行計画 ————————————- | Id | Operation | Name | ————————————- | 0 | SELECT STATEMENT | | |* 1 | HASH JOIN SEMI | | | 2 | TABLE ACCESS FULL| TAB01 | | 3 | TABLE ACCESS FULL| TAB02 | ————————————- Predicate Information (identified by operation id): ————————————————— 1 – access(“A”.”C01″=”B”.”C1″) |
SQL> SELECT c01 FROM tab01 A WHERE EXISTS 2 (SELECT /*+ NO_UNNEST */ null FROM tab02 B 3 WHERE A.c01 = B.c1); 実行計画 ————————————- | Id | Operation | Name | ————————————- | 0 | SELECT STATEMENT | | |* 1 | FILTER | | | 2 | TABLE ACCESS FULL| TAB01 | |* 3 | TABLE ACCESS FULL| TAB02 | ————————————- Predicate Information (identified by operation id): ————————————————— 1 – filter( EXISTS (SELECT /*+ NO_UNNEST */ 0 FROM “TAB02” “B” WHERE “B”.”C1″=:B1)) 3 – filter(“B”.”C1″=:B1) |
(b)NOT EXISTS
NOT EXISTSを使用した副問合せは、効果的に処理するためANTI JOIN(アンチ結合)に変換します。アンチ結合とは、結合で一致しなかった主問合せの行を結果とするようにします(これは結合方法によって処理が異なります。例えば、ハッシュ結合は結合終了後に、一致していない主問合せの行だけを結果とします)。これでネストした副問合せを、以下のように通常の結合と同様に行うことが可能になります。左側はネストした副問合せを解除した例(”HASH JOIN ANTI”操作で通常の結合条件になっています)、右側は解除しない例(これもネストした副問合せを解除しないようにNO_UNNESTヒントを指定しているので、直積結合と同等の動作になっています)です。
|
SQL> SELECT * FROM tab01 A WHERE NOT EXISTS 2 (SELECT null FROM tab02 B 3 WHERE A.c01 = B.c1); 実行計画 ————————————- | Id | Operation | Name | ————————————- | 0 | SELECT STATEMENT | | |* 1 | HASH JOIN ANTI | | | 2 | TABLE ACCESS FULL| TAB01 | | 3 | TABLE ACCESS FULL| TAB02 | ————————————- Predicate Information (identified by operation id): ————————————————— 1 – access(“A”.”C01″=”B”.”C1″) |
SQL> SELECT * FROM tab01 A WHERE NOT EXISTS 2 (SELECT /*+ NO_UNNEST */ null FROM tab02 B 3 WHERE A.c01 = B.c1); 実行計画 ————————————- | Id | Operation | Name | ————————————- | 0 | SELECT STATEMENT | | |* 1 | FILTER | | | 2 | TABLE ACCESS FULL| TAB01 | |* 3 | TABLE ACCESS FULL| TAB02 | ————————————- Predicate Information (identified by operation id): ————————————————— 1 – filter( NOT EXISTS (SELECT /*+ NO_UNNEST */ 0 FROM “TAB02” “B” WHERE “B”.”C1″=:B1)) 3 – filter(“B”.”C1″=:B1) |
(c)NOT IN
NOT IN(=ALL以外のALLも含みます)を使用した副問合せでもアンチ結合に変換されますが、NOT EXISTS副問合せとは異なり、Oracle Database 10g(Oracle10g)までNULLが格納されている可能性がある(NOT NULL制約がない)列を、述語としている問合せでアンチ結合(ネストした副問合せの解除)を行うことができませんでした。そのため、以下のように二つのテーブルの結合列に、IS NOT NULL(またはNOT NULL制約)を指定する必要があります。これはNOT IN条件で結合列にNULLが存在すると、UNKNOWN(不定)と評価されるからです。
2 (SELECT c1 FROM tab02 B WHERE c1 IS NOT NULL);
実行計画
————————————-
| Id | Operation | Name |
————————————-
| 0 | SELECT STATEMENT | |
|* 1 | HASH JOIN ANTI | |
|* 2 | TABLE ACCESS FULL| TAB01 |
|* 3 | TABLE ACCESS FULL| TAB02 |
————————————-
Predicate Information (identified by operation id):
—————————————————
1 – access(“A”.”C01″=”C1″)
2 – filter(“A”.”C01″ IS NOT NULL)
3 – filter(“C1” IS NOT NULL)
Oracle Database 11g(Oracle11g)からはNULL認識型のアンチ結合(”Null-Aware(NA) ANTI JOIN”、”Single Null-Aware(SNA) ANTI JOIN”)によって可能です。以下にNULLが格納されている可能性がある列(そのためにIS NOT NULLを入れていません)のネストした副問合せを解除した例を示します。NULLが格納されている可能性がある列の数によって”HASH JOIN ANTI NA”操作(左側)、”HASH JOIN ANTI SNA”操作(右側)になります。このときのSNAは、副問合せの結合列がNULLでない場合です。
|
SQL> SELECT * FROM tab01 A WHERE A.c01 NOT IN 2 (SELECT c1 FROM tab02 B); 実行計画 ————————————- | Id | Operation | Name | ————————————- | 0 | SELECT STATEMENT | | |* 1 | HASH JOIN ANTI NA | | | 2 | TABLE ACCESS FULL| TAB01 | | 3 | TABLE ACCESS FULL| TAB02 | ————————————- Predicate Information (identified by operation id): ————————————————— 1 – access(“A”.”C01″=”C1″) |
SQL> SELECT * FROM tab01 A WHERE A.c01 NOT IN 2 (SELECT c1 FROM tab02 B WHERE c1 IS NOT NULL); 実行計画 ————————————- | Id | Operation | Name | ————————————- | 0 | SELECT STATEMENT | | |* 1 | HASH JOIN ANTI SNA| | | 2 | TABLE ACCESS FULL| TAB01 | |* 3 | TABLE ACCESS FULL| TAB02 | ————————————- Predicate Information (identified by operation id): ————————————————— 1 – access(“A”.”C01″=”C1″) 3 – filter(“C1” IS NOT NULL) |
以下のようにOR論理条件を使用しているSQLでは、セミ結合とアンチ結合は動作しませんので注意してください。
2 WHERE NOT EXISTS (SELECT null FROM tab02 B WHERE A.c01 = B.c1)
3 OR A.c02 = 100 ;
(3)述語のプッシュ
次に、WHERE句の述語のプッシュについて説明します。
述語のプッシュとは、マージされていないビューに対して、関連する述語をビューの問合せブロックに組み込むことで最適化します。これによりプッシュされた述語を、索引アクセスやフィルター(検索条件)に使用できるので、マージされていないビューの実行計画を改善することが可能です(Group By句を使用したビューなどは、マージしない方がコストが低い場合が多いので、特に有効です)。
副問合せ(ビューも含みます)は、それぞれで実行計画が作成されるので、副問合せの述語に効果的な検索条件などが指定されていないと、最適な実行計画になりません。ただし、検索する内容によって条件が異なるビューには、検索条件を指定することができないので、以下のようにビューの外で検索条件(v.dname= ‘営業部’)を指定するのが一般的です。
2 SELECT d.dname, d.locid, COUNT(*) cnt FROM emp e, dept d WHERE e.depid = d.depid
3 GROUP BY d.dname, d.locid;
SQL> SELECT dname,addr,cnt FROM emp_v v,locations l WHERE v.locid = l.locid AND v.dname = ‘営業部’;
——————————————-
| Id | Operation | Name |
——————————————-
| 0 | SELECT STATEMENT | |
|* 1 | HASH JOIN | |
| 2 | TABLE ACCESS FULL | LOCATIONS |
| 3 | VIEW | EMP_V |
| 4 | HASH GROUP BY | |
|* 5 | HASH JOIN | |
|* 6 | TABLE ACCESS FULL| EMP |
| 6 | TABLE ACCESS FULL| DEPT |
——————————————-
Predicate Information (identified by operation id):
—————————————————
1 – access(“V”.”C01″=”L”.”C1″)
5 – access(“D”.”C01″=”E”.”C1″)
6 – filter(“E”.”DNAME”=’営業部’)
このようにビュー内の検索条件が外にある場合に、その検索時に検索条件をビューに移動させることで、最適な実行計画にするようにします。上記実行計画では、検索条件(dname= ‘営業部’)がビューに移動されています(Predicate Informationを確認すると、その操作がid=6とビュー内であることが分かります)。これをSQLで記述すると以下のようになります。
2 (SELECT d.dname, d.locid, COUNT(*) cnt FROM emp e, dept d
3 WHERE e.depid = d.depid AND e.dname = ‘営業部’ GROUP BY d.dname, d.locid) v
4 WHERE v.locid = l.locid;
検索条件以外に結合でも述語のプッシュを行います。マージされないビューは、テーブルと索引ベースのネステッド・ループ結合を行うことができません(これはビューの元表の索引を使用できないからです)。Oracle10gからのJoin Predicate Pushdown機能で、索引を利用してネステッド・ループ結合を行うことが可能です。Oracle11g からは、より拡張されています(Group By、DISTINCT、アンチ結合、セミ結合を含む問合せに対しても使用することが可能です)。Join Predicate Pushdown機能が行われたかどうかは、以下のように実行計画の”VIEW PUSHED PREDICATE”操作から確認できます(以下の例では、結合述語プッシュを行わせるためにPUSH_PREDヒントを指定しています)。
2 WHERE A.c2 = B.c02 ;
—————————————————-
| Id | Operation | Name |
—————————————————-
| 0 | SELECT STATEMENT | |
| 1 | NESTED LOOPS | |
| 2 | TABLE ACCESS FULL | TAB02 |
| 3 | VIEW PUSHED PREDICATE | |
|* 4 | FILTER | |
| 5 | SORT AGGREGATE | |
| 6 | TABLE ACCESS BY INDEX ROWID| TAB01 |
|* 7 | INDEX UNIQUE SCAN | IX_TAB01 |
—————————————————-
Predicate Information (identified by operation id):
—————————————————
4 – filter(COUNT(*)>0)
7 – access(“C02″=”A”.”C2″)
この例は、インライン・ビューにGroup By句があるので、ビューをマージしていません。そして、ビュー内の結合列の索引を使用したネステッド・ループ結合をしています。これをSQLで記述すると以下のようになりますが、これは正しいSQLではありませんので注意してください(実行するとエラーになります)。
(4)Group By/DISTINCTの配置の最適化
最後に、Group By/DISTINCTの配置の最適化について説明します。
これは、第9回の「結合は件数を絞り込んでから」で説明した例(Group By句をビューの内側に配置することで、結合に必要な件数を最小限にすることが可能です)の内容になります。この中で「さすがにオプティマイザもここまでは変換しません」と説明しましたが、Oracle11gからはGroup By Placement機能によって、以下の左側のように内部ビュー”VW_GBC_5”を作成して、CBOが自動変換するようになっています(DISTINCT Placement機能は、DISTINCTに対して同様の動作を行います)。右側のようにNO_PLACE_GROUP_BYヒントを使用して配置の最適化を行わないようにすることも可能です。オプティマイザ統計の精度などによって、すべてが自動変換される訳ではありませんので、第9回のように手動でも行えるようにしておくことも大事です。
|
SQL> SELECT A.c2, SUM(B.c2), COUNT(*) 2 FROM t01 A, t02 B 3 WHERE A.c1 = B.c1 GROUP BY A.c2; 実行計画 ——————————————- | Id | Operation | Name | ——————————————- | 0 | SELECT STATEMENT | | | 1 | HASH GROUP BY | | |* 2 | HASH JOIN | | | 3 | VIEW | VW_GBC_5 | | 4 | HASH GROUP BY | | | 5 | TABLE ACCESS FULL| T02 | | 6 | TABLE ACCESS FULL | T01 | ——————————————- Predicate Information (identified by operation id): ————————————————— 2 – access(“A”.”C1″=”ITEM_1″) |
SQL> SELECT /*+ NO_PLACE_GROUP_BY */ A.c2, 2 SUM(B.c2), COUNT(*) 3 FROM t01 A, t02 B 4 WHERE A.c1 = B.c1 GROUP BY A.c2; 実行計画 ————————————- | Id | Operation | Name | ————————————- | 0 | SELECT STATEMENT | | | 1 | HASH GROUP BY | | |* 2 | HASH JOIN | | | 3 | TABLE ACCESS FULL| T02 | | 4 | TABLE ACCESS FULL| T01 | —————————————- Predicate Information (identified by operation id): ————————————————— 2 – access(“A”.”C1″=”B”.”C3″) |
3. 直積について
ここからは、直積について説明しましょう。
表結合には、クロス結合(直積結合またはデカルト積結合)、内部結合、自己結合、自然結合、外部結合(左外部結合、右外部結合、完全外部結合)などがあります。この中であまり使用する機会がないのが、以下のように結合述語(結合条件)を指定しない直積結合です。実行計画には”MERGE JOIN (CARTESIAN)”操作が出力されます。直積とは、結合するテーブルのすべての組合せの行を求める処理になります。そのため、処理コストが高くなりますので、できれば実行しないようにしてください。
実行計画
————————————–
| Id | Operation | Name |
————————————–
| 0 | SELECT STATEMENT | |
| 1 | MERGE JOIN CARTESIAN| |
| 2 | TABLE ACCESS FULL | TAB01 |
| 3 | BUFFER SORT | |
| 4 | TABLE ACCESS FULL | TAB02 |
最近、直積結合が実行されている実行計画を見ますが、このような処理は一般的には使用することはないと思います。そのため、SQLが間違っているケースが多いと思いますので確認してください。また、表結合の順番が正しくない場合がありますので、ORDEREDヒントなどで表結合の順番を調整するのも有効な場合があります。以下の例は、表結合の順番を明確にするために、ORDEREDヒントを使用しています。それによって、右側は通常のハッシュ結合ですが、左側は直積結合が発生しています(表の結合順番がtab01、tab03、tab02になっているのに、tab01とtab03の結合述語を指定していないからです)。このような結合でも、直積結合が発生することを知っておくのも重要ですので、説明を入れておきました。
|
SQL> SELECT /*+ ORDERED */ * FROM tab01 A,tab03 C,tab02 B 2 WHERE A.c01 = B.c1 AND B.c1 = c.c1; 実行計画 —————————————- | Id | Operation | Name | —————————————- | 0 | SELECT STATEMENT | | |* 1 | HASH JOIN | | | 2 | MERGE JOIN CARTESIAN| | | 3 | TABLE ACCESS FULL | TAB01 | | 4 | BUFFER SORT | | | 5 | TABLE ACCESS FULL | TAB03 | | 6 | TABLE ACCESS FULL | TAB02 | —————————————- Predicate Information (identified by operation id): ————————————————- 1 – access(“A”.”C01″=”B”.”C1″ AND “B”.”C1″=”C”.”C1″) |
SQL> SELECT /*+ ORDERED */ * FROM tab01 A,tab02 B,tab03 C 2 WHERE A.c01 = B.c1 AND B.c1 = c.c1; 実行計画 ————————————– | Id | Operation | Name | ————————————– | 0 | SELECT STATEMENT | | |* 1 | HASH JOIN | | |* 2 | HASH JOIN | | | 3 | TABLE ACCESS FULL| TAB01 | | 4 | TABLE ACCESS FULL| TAB02 | | 5 | TABLE ACCESS FULL | TAB03 | ————————————– Predicate Information (identified by operation id): ————————————————— 1 – access(“B”.”C1″=”C”.”C1″) 2 – access(“A”.”C01″=”B”.”C1″) |
4. おわりに
今回は第25回に続きSQL文のノウハウとオプティマイザについて説明しました。また機会があれば他のことについても説明したいと思います。Oracle Database 12cがリリースされましたね。これからは(少し先になると思いますが)Oracle Database 12cも含めて説明していきますので、これからもよろしくお願いします。
それでは、次回まで、ごきげんよう。
