※ 本記事は、Leo Leung, John Kimによる”OCI accelerates HPC, AI, and database using RoCE and NVIDIA ConnectX“を翻訳したものです。
2023年8月1日
Oracleは、世界でトップクラスのクラウド・サービス・プロバイダの1つで、22,000を超える顧客をサポートし、四半期当たり約40億ドルの収益と40%を超える年間成長を報告しています。Oracle Cloud Infrastructure(OCI)はさらに高速に成長しており、すべてのワークロードに対して完全なクラウド・インフラストラクチャを提供します。
過去18か月に11のリージョンを追加したOCIは、現在41のリージョンを提供し、ホスト、オンプレミス、ハイブリッド、マルチクラウドのデプロイメントをサポートしています。これにより、顧客は、カスタム構築されたサードパーティ製の独立系ソフトウェア・ベンダー(ISV)とOracle applicationsをスケーラブルなアーキテクチャ上で混在させることができます。OCIは、セキュリティ、可観測性、コンプライアンス、コスト管理をサポートするスケーラブルなネットワーキングおよびツールを提供します。
OCIの差別化要因の1つは、専用オンプレミス・インフラストラクチャに匹敵する高速Infrastructure-as-a-Service(IaaS)パフォーマンスを備えた、ハイパフォーマンス・コンピューティング(HPC)、Oracle Exadata、Autonomous Database、および人工知能(AI)や機械学習(ML)などのGPUを搭載したアプリケーションを提供する能力です。この高パフォーマンスを実現するための重要なコンポーネントは、リモート・ダイレクト・メモリー・アクセス(RDMA)をサポートするスケーラブルで待機時間の短いネットワークです。詳細は、第1原則: パブリック・クラウドでの高パフォーマンス・ネットワークの構築を参照してください。
HPCおよびGPUを利用したコンピューティングのネットワーキングの課題
HPCアプリケーション、GPUを搭載したAIワークロード、およびExadata上のOracle Autonomous Databaseに共通することは、すべて分散ワークロードとして実行されることです。数十から数千のCPUとGPUを使用して、複数のノードで同時にデータ処理が行われます。これらのノードは相互に通信し、中間結果を共有してギガバイトからペタバイトのストレージで多段の問題を解決して共通データにアクセスし、分散コンピューティングの結果をまとまりのあるソリューションに組み込むことがよくあります。
これらのアプリケーションは、問題を迅速に解決するために、ノード間で通信するために高スループットおよび低レイテンシを必要とします。Amdahlの法則では、タスクの並列化からのスピードアップは、本来どれだけのタスクがシリアルであり、並列化できないかによって制限されていると規定されています。ノード間で情報を転送するために必要な時間は、本質的にタスクに直列時間を加えます。これは、ノードがデータ転送の完了を待機し、タスクのもっとも遅いノードが終了してから、ジョブの次の並列化可能な部分を開始する必要があるためです。
このため、クラスタ・ネットワークのパフォーマンスが最大になり、最適化されたネットワークによって、分散コンピュート・クラスタは、低速なネットワークで実行されている同じコンピューティング・リソースよりもはるかに早く結果を提供できます。この時間の節約により、ジョブの完了時間が短縮され、コストが削減されます。
RDMAとは?
RDMAはリモート・ダイレクト・メモリー・アクセスであり、異なるマシン間でデータを転送する最も効率的な手段です。これにより、サーバーまたはストレージ・アプライアンスは、追加のコピーを作成しなくても、ホストCPUに割り込むことなく、ネットワーク経由でデータを通信および共有できます。AI、ビッグ・データ、その他の分散型技術コンピューティング・ワークロードに使用されます。
従来のネットワークは、CPUを複数回中断し、OSカーネルを介してアプリケーションからアダプタに渡されるときに転送されるデータの複数のコピーを作成し、受信側のスタックをバックアップします。RDMAは、各端にデータのコピーを1つだけ使用し、通常はカーネルをバイパスして、CPUを中断することなく、受信側のマシンのメモリーにデータを直接配置します。
このプロセスによって、ネットワーク上の低レイテンシと高スループット、およびサーバーとストレージ・システムのCPU使用率が低下します。現在、HPC、技術コンピューティング、AIアプリケーションの大半はRDMAによって加速できます。詳細は、RDMAが高速Networksの燃料になる方法を参照してください。
InfiniBandとは?
InfiniBandは、高パフォーマンス・コンピューティング、AI、ビッグ・データおよびその他の分散型技術コンピューティング・ワークロード用に最適化された、無損失のネットワークです。通常、データ・センター・ネットワークおよびRDMAに使用可能な最大帯域幅(現在、接続あたり400Gビット/秒)がサポートされるため、マシンはホストCPUを中断することなくデータを通信および共有できます。
InfiniBandアダプタは、ネットワーク・タスクとデータ移動タスクをCPUからオフロードし、最適化された効率的なネットワーキング・スタックを備えており、CPU、GPUおよびストレージがデータを迅速かつ効率的に移動できるようにします。InfiniBandアダプタおよびスイッチは、メッセージ・パス・インタフェース(MPI)の集合操作を中心に、ネットワークで特定のコンピュートおよびデータ集計タスクを実行することもできます。
このネットワーク内コンピューティングにより、分散アプリケーションを高速化し、より迅速な問題解決を実現します。また、サーバーのCPUコアが解放され、エネルギー効率も向上します。InfiniBandは、トラフィック・ロードを自動的に均衡させ、破損したリンクを経由して接続を再ルーティングすることもできます。
その結果、AI、HPC、ビッグ・データ、その他の科学コンピューティング専用の多くのコンピューティング・クラスタがInfiniBandネットワークで実行され、最大限のパフォーマンスと効率性が得られます。分散コンピューティングのパフォーマンスが最優先事項であり、ネットワーク・アダプタ、スイッチ、および管理の特殊なスタックの採用が許容可能な場合、InfiniBandが選択したネットワークです。しかし、データセンターではさまざまな理由で、InfiniBandの代わりにEthernetを実行することを選択できます。
RoCEとは?
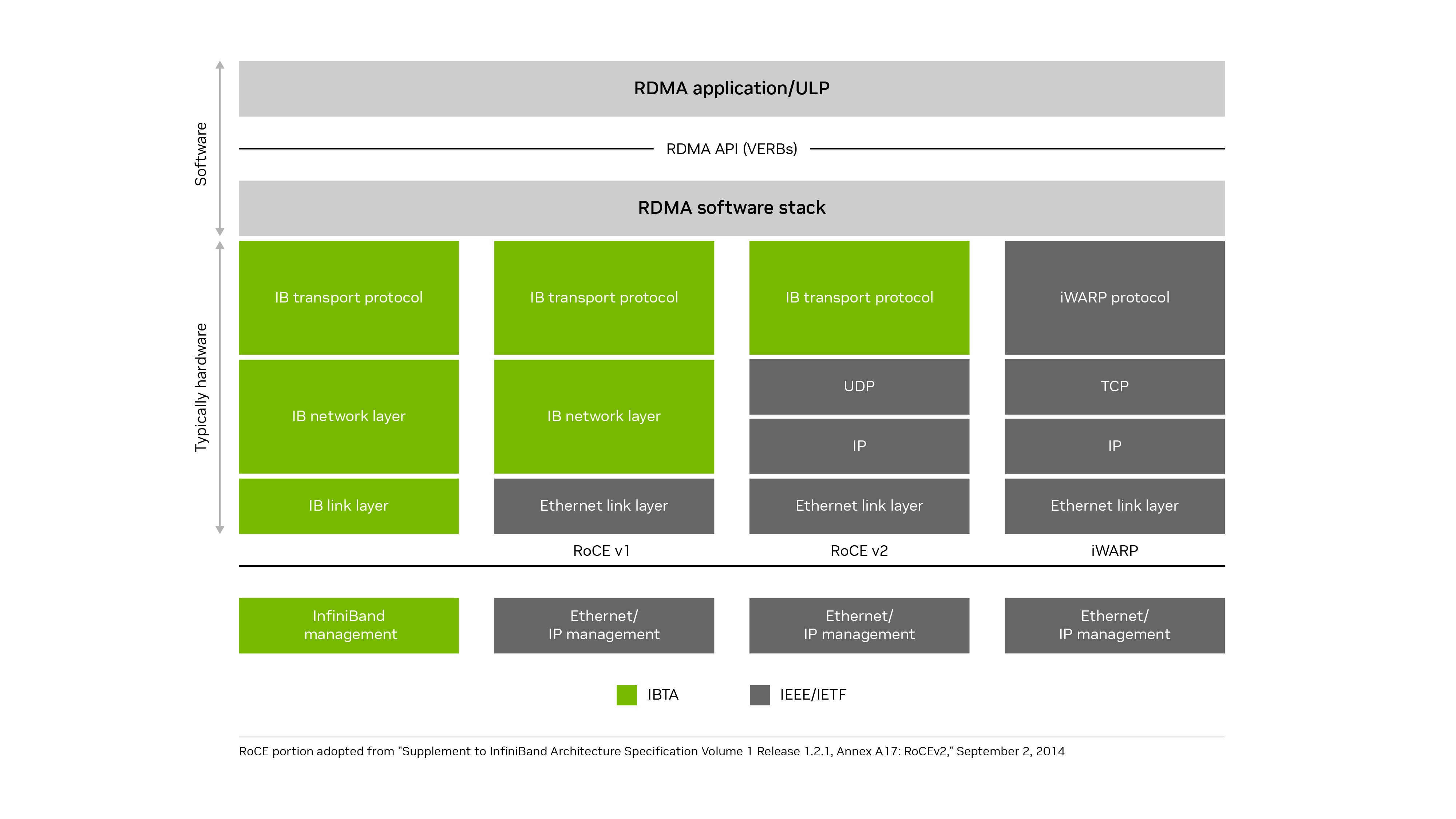
RDMA over Converged Ethernet (RoCE)はオープン標準であり、イーサネットネットワーク上でリモート・ダイレクト・メモリー・アクセスとネットワーク・オフロードを可能にします。現在および最も一般的な実装はRoCEv2です。UDP (レイヤー4)およびIP (レイヤー3)の上で動作するInfiniBand通信レイヤーを使用し、高速イーサネット(レイヤー2)接続の上で実行されます。また、リモート・ダイレクト・メモリー・アクセス、ゼロコピー・データ転送、およびデータの移動時のCPUのバイパスもサポートします。Ethernet上でIPプロトコルを使用すると、標準Ethernetネットワーク上で RoCEv2をルーティングできます。
RoCEは、InfiniBandの多くの利点をイーサネット・ネットワークにもたらします。RoCEv2は、UDPおよびIPプロトコルを介してイーサネット・ネットワーク上でInfiniBandトランスポート・レイヤーを実行します。iWARPは、イーサネット・ネットワーク上のTCPプロトコルの上にiWARPプロトコルを実行しましたが、パフォーマンスおよび実装の課題のために一般的な導入に失敗しました。
RoCEネットワークはスケーラビリティにどのように対処しますか?
RoCEは、パケット損失のレベルが非常に低いネットワーク上で最も効率的に動作します。従来、小規模な RoCEネットワークは、IEEE 802.1Qbb仕様に基づく優先順位フロー制御(PFC)を使用してネットワークを無損失にしています。いずれかの宛先がビジー状態で、すべての受信トラフィックを処理できない場合は、一時停止フレームを次のアップストリーム・スイッチ・ポートに送信し、そのスイッチは一時停止フレームで指定された時間のトラフィックを保持します。
必要に応じて、スイッチはファブリック内の次のスイッチまで一時停止フレームを送信し、最終的にトラフィックフローの発信者に送信することもできます。このフロー制御は、任意のホストまたはスイッチ上でポート・バッファーがオーバーフローしないようにし、パケットの損失を防ぎます。最大8つのトラフィック・クラスをPFCで管理できます。各クラスは独自のフローを持ち、他のクラスとは別に一時停止します。
ただし、PFCにはいくつかの制限があります。Open System Interconnection (OSI) 7層モデルの Layer-2 (Ethernet)レベルでのみ動作するため、異なるサブネット間で動作することはできません。サブネットには数千または数百万のノードを設定できますが、一般的なサブネットは254のIPアドレスに制限され、データ・センター内のいくつかのラック(通常は1ラック)で構成され、大規模な分散アプリケーションではスケーリングされません。
PFCは粗いポート・レベルで動作し、そのポートを共有するフローを区別できません。また、マルチレベル・スイッチ・ファブリックでPFCを使用する場合、1つの宛先スイッチの1つのフローの輻輳が複数のスイッチに分散し、1つのポートをRoCEフローと共有する無関係なトラフィック・フローをブロックできます。解答は通常、輻輳制御の形式を実装することです。
大規模なRoCEネットワークの輻輳管理
TCPプロトコルには、ドロップされたパケットに基づく輻輳管理のサポートが含まれています。トラフィック・フローによってエンドポイントまたはスイッチが圧倒されると、一部のパケットが削除されます。送信者が送信されたデータから確認応答を受信できなかった場合、送信者は、ネットワークの輻輳が原因でパケットが失われ、転送速度が遅くなり、失われたと思われるデータを再送信します。
この輻輳管理スキームは、イーサネット上のRDMAではうまく機能しないため、RoCEでは機能しません。RoCEはTCPを使用せず、パケットのタイムアウトを待ってから失われたデータを再送信するプロセスでは、RoCE操作を効率化するために、待機時間(および待機時間やジッタの変動)が多すぎます。
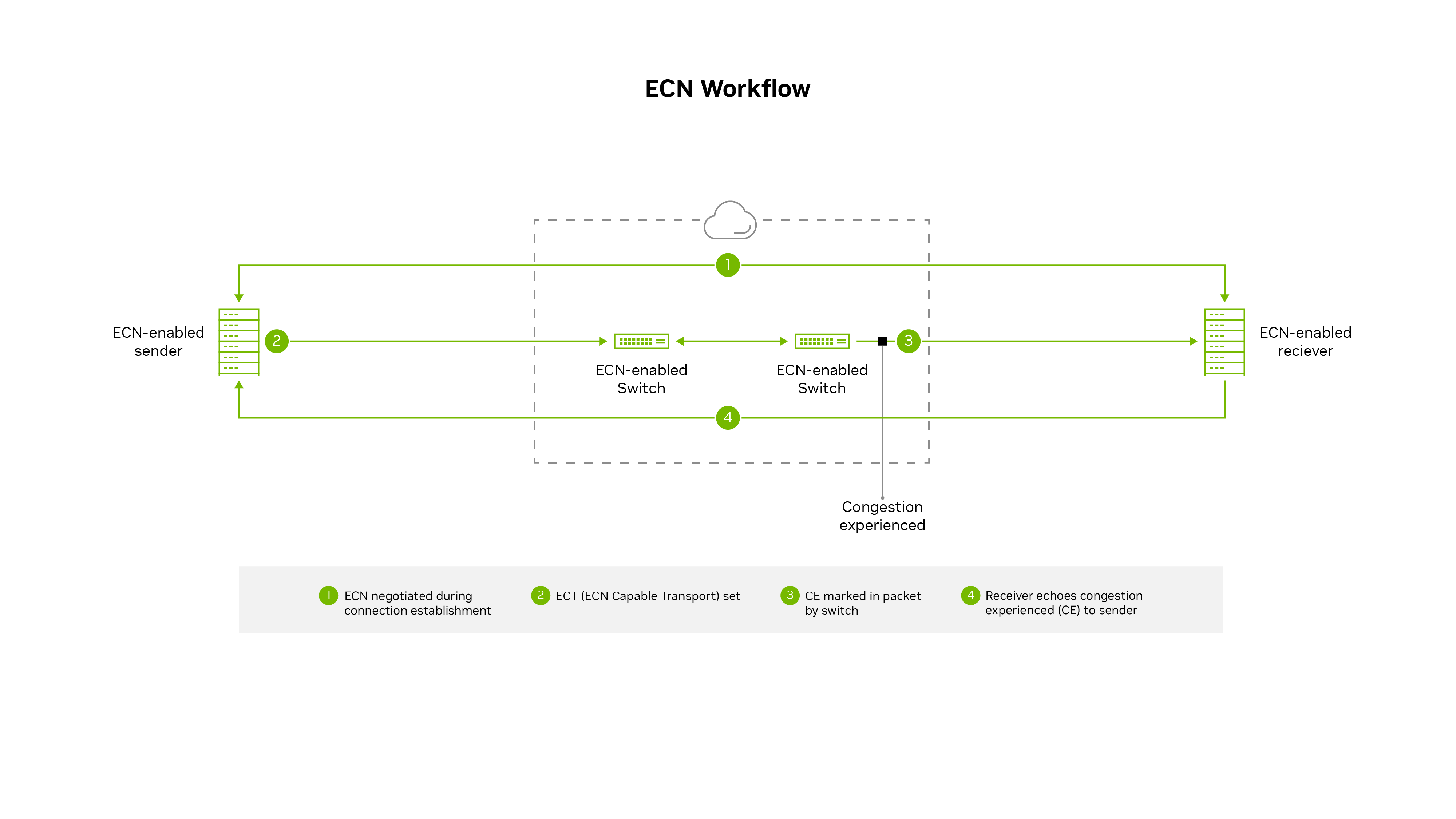
大きなRoCEネットワークは、多くの場合、明示的な輻輳通知(ECN)と呼ばれる、よりプロアクティブな輻輳制御メカニズムを実装します。このメカニズムでは、ネットワーク内で輻輳が発生した場合にスイッチがパケットをマークします。マークされたパケットは、輻輳が差し迫っていることを受信者に警告し、受信者は輻輳通知パケットまたはCNPを送信者に警告します。CNPの受信後、送信者はバックオフを認識し、フロー パスがより高いトラフィック レートを処理できるようになるまで伝送速度を一時的に遅くします。
輻輳制御はOSIモデルのレイヤー3間で機能するため、さまざまなサブネット間で機能し、数千のノードまで拡張できます。ただし、RoCEトラフィックをサポートするスイッチとアダプタの両方に変更を設定する必要があります。スイッチがパケットに輻輳のマークを付ける時期、送信者がどのくらい早くデータを送り返すか、および積極的に送信者が高速送信を再開する方法の実装の詳細は、RoCEネットワークのスケーラビリティとパフォーマンスを判断するためにすべて重要です。
その他のEthernetベースの輻輳制御アルゴリズムには、量子化輻輳通知(QCN)とデータセンターTCP (DCTCP)が含まれます。QCNでは、スイッチは潜在的な輻輳のレベルを直接フロー送信者に通知しますが、このメカニズムは L2でのみ機能します。したがって、複数のサブネットで機能することはできません。DCTCPでは、送信者のネットワーク・インタフェース・カード(NIC)を使用して、特殊なパケットの往復時間(RTT)を測定し、輻輳が発生している量と送信者がデータ送信の速度を落とす必要がある量を見積ります。
しかし、DCTCPには、輻輳が存在しない場合にデータの送信をすばやく開始または再開するためのファスト・スタート・オプションがなく、ホストCPUに負荷がかかり、受信者が送信者と通信するための適切なメカニズムがありません。いずれの場合も、DCTCPにはTCPが必要であるため、RoCEでは機能しません。
NVIDIAまたは新しいNVIDIA BlueField DPUから、より新しいRDMA対応のConnectX SmartNICsを使用する小規模なRoCEネットワークでは、ゼロ・タッチRoCE (ZTR)を使用できます。ZTRでは、スイッチにPFCまたはECNを設定せずに優れた RoCEパフォーマンスを実現できるため、ネットワーク設定が大幅に簡略化されます。ただし、ZTRの初期デプロイメントは小さいRoCEネットワーク・クラスタに制限されており、輻輳通知にRTTを使用するよりスケーラブルなバージョンのZTRはまだ証明段階にあります。
OCIがスケーラブルなRoCEネットワークを実装する方法
OCIは、特定のクラウド・ワークロードでパフォーマンスを最大化するためにRDMAが必要であると判断しました。これには、AI、HPC、Exadata、自律型データベース、およびその他のGPUを搭載したアプリケーションが含まれます。Ethernetでは、標準化された2つのRDMAオプションのうち、パフォーマンスと導入の幅が広いために RoCEを選択しました。RoCEの実装では、数千のノードを含むクラスタをまたいで実行し、一貫して低レイテンシを実現して、クラウドの顧客に優れたエクスペリエンスを提供する必要がありました。
実質的な調査、テスト、慎重な設計の後、OCIは、データ・センターの量子化輻輳通知(DC-QCN)アルゴリズムに基づいて独自の輻輳制御ソリューションをカスタマイズすることを決定しました。このアルゴリズムは、RoCEアクセラレーテッド・アプリケーション・ワークロードごとに最適化されています。OCI DC-QCNソリューションは、PFCの使用を最小限に抑えたECNに基づいています。
RoCE用の個別のネットワーク
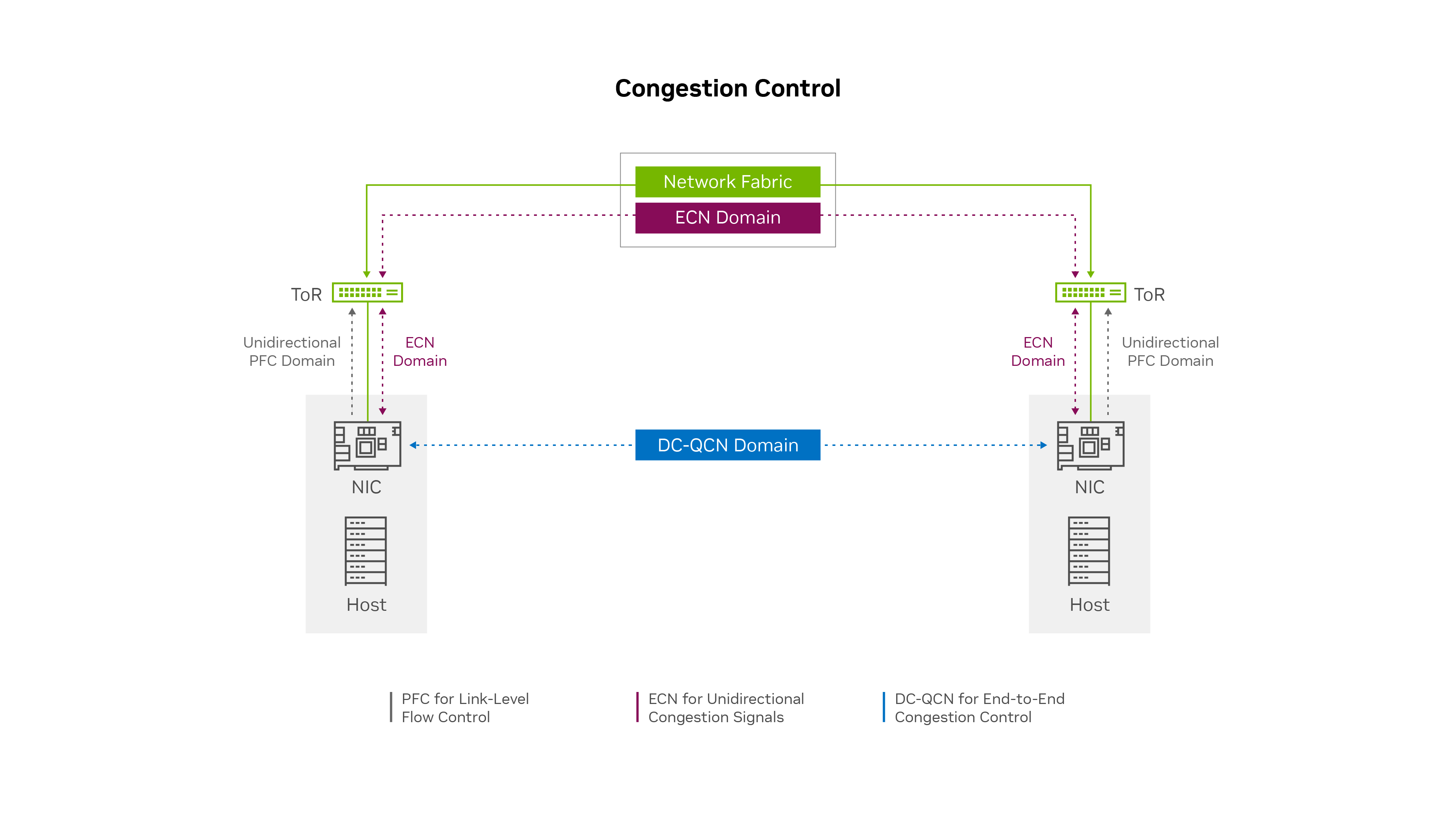
OCIは、RDMAネットワークのニーズが通常のデータ・センター・ネットワークと異なる傾向があるため、RoCEトラフィック用に別個のネットワークを構築しました。様々なタイプのアプリケーション・トラフィック、輻輳制御およびルーティング・プロトコルは、それぞれ独自のキューを持つことを好みます。通常、各NICは8つのトラフィッククラスしかサポートせず、RDMAのNICとスイッチの構成設定とファームウェアは、RDMA以外のワークロードと異なる場合があります。このような理由から、RoCEトラフィックと RoCEアクセラレーテッドアプリケーション用の別個のEthernetネットワークを使用することは理にかなっています。
エッジでのPFCの使用が限られている
OCIは限られたレベルのPFCを実装しましたが、ネットワーク・エッジでは単方向のみでした。エンドポイントは、NICバッファが一杯になった場合に、トップオブラック(ToR)スイッチに伝送を一時停止するように要求できます。ただし、ToRスイッチはエンドポイントに一時停止を要求せず、ネットワーク上の一時停止リクエストにリーフ・スイッチまたはスパイン・スイッチを渡しません。このプロセスにより、受信トラフィック・フロー・レートが受信者のデータ処理およびバッファリング能力を一時的に超えると、ヘッドオブライン・ブロックおよび輻輳の分散が防止されます。
ECNメカニズムは、PFCが非常にまれに必要であることを保証します。まれに、ECNフィードバック・メカニズムのアクティブ化中に受信ノードのNICバッファが一時的にオーバーランする場合、PFCでは、送信者がCNPを受信して送信速度を遅くするまで受信側のノードが受信データフローを短時間一時停止できます。
この意味では、(エンドポイントで)ネットワーク・エッジでのバッファ・オーバーランおよびパケット損失を防ぐために、最後の手段保護手段としてPFCを使用できます。OCIは、次世代のConnectX SmartNICsでは、ネットワークの端でもPFCが必要ない可能性があることを想定しています。
輻輳制御の複数のクラス
OCIは、ワークロードごとにDC-QCN内で少なくとも3つのカスタマイズされた輻輳制御プロファイルが必要であると判断しました。RDMAネットワーキングを必要とする分散アプリケーションの世界でも、ニーズは次のカテゴリによって異なります。:
-
レイテンシの影響を受けやすい: 一貫して低レイテンシのスループット
-
機密: 高スループット
-
混合: 低レイテンシと高スループットのバランスが必要
輻輳制御をカスタマイズするための主な設定は、キューのしきい値KminとKmaxに基づいてECNマークを送信パケットに追加するスイッチの確率P (0–1)です。Pは、スイッチ・キューがビジーでない場合に0から開始します。つまり、輻輳が発生する可能性がありません。
ポートキューがKmaxに達すると、値Pが0を超えて上昇し、パケットがECNでマークされる可能性が高くなります。キューが値Kmaxに達すると、PはPmax (通常は1)に設定されます。つまり、そのスイッチ上のそのフローのすべての送信パケットはECNでマークされます。通常、異なるDC-QCNプロファイルには、Pが0、Pが0から1の場合の輻輳範囲、およびPが1の場合の輻輳範囲があります。
しきい値のより積極的なセットでは、KminとKmaxの値が低いため、ECNパケットマーキングおよび待機時間が短くなりますが、最大スループットも低くなる可能性があります。リラックスしたしきい値のセットでは、KminとKmaxの値が高くなり、ECNを使用したパケット数が少なくなるため、待機時間が長くなり、スループットも高くなります。
図4の右側には、OCIワークロードの3つの例として、HPC、Oracle Autonomous Database、Exadata Cloud Service、およびGPUワークロードがあります。これらのサービスでは、異なるRoCE輻輳制御プロファイルが使用されます。HPCワークロードはレイテンシに敏感であり、低レイテンシを保証するためにスループットを放棄します。その結果、KmaxとKmaxは同じで低(積極的)であり、キューイングの量が少ない場合、すべてのパケットの100%がECNとマークされます。
ほとんどのGPUワークロードはレイテンシでより許されますが、最大スループットが必要です。DC-QCNプロファイルは、バッファーがKmaxからKmaxに傾くにつれて、さらに多くのパケットを徐々にマークし、それらの値を比較的高く設定して、スイッチバッファーが速度を落とすフローエンドポイントに信号を送る前に、スイッチバッファーがいっぱいに近づくようにします。
Autonomous DatabaseおよびExadata Cloud Serviceのワークロードの場合、レイテンシと帯域幅の必要なバランスが間にあります。P値のマーク付けまたは増加はKmaxとKmaxの間で段階的に増加しますが、これらの値はGPUワークロードより低いしきい値に設定されます。
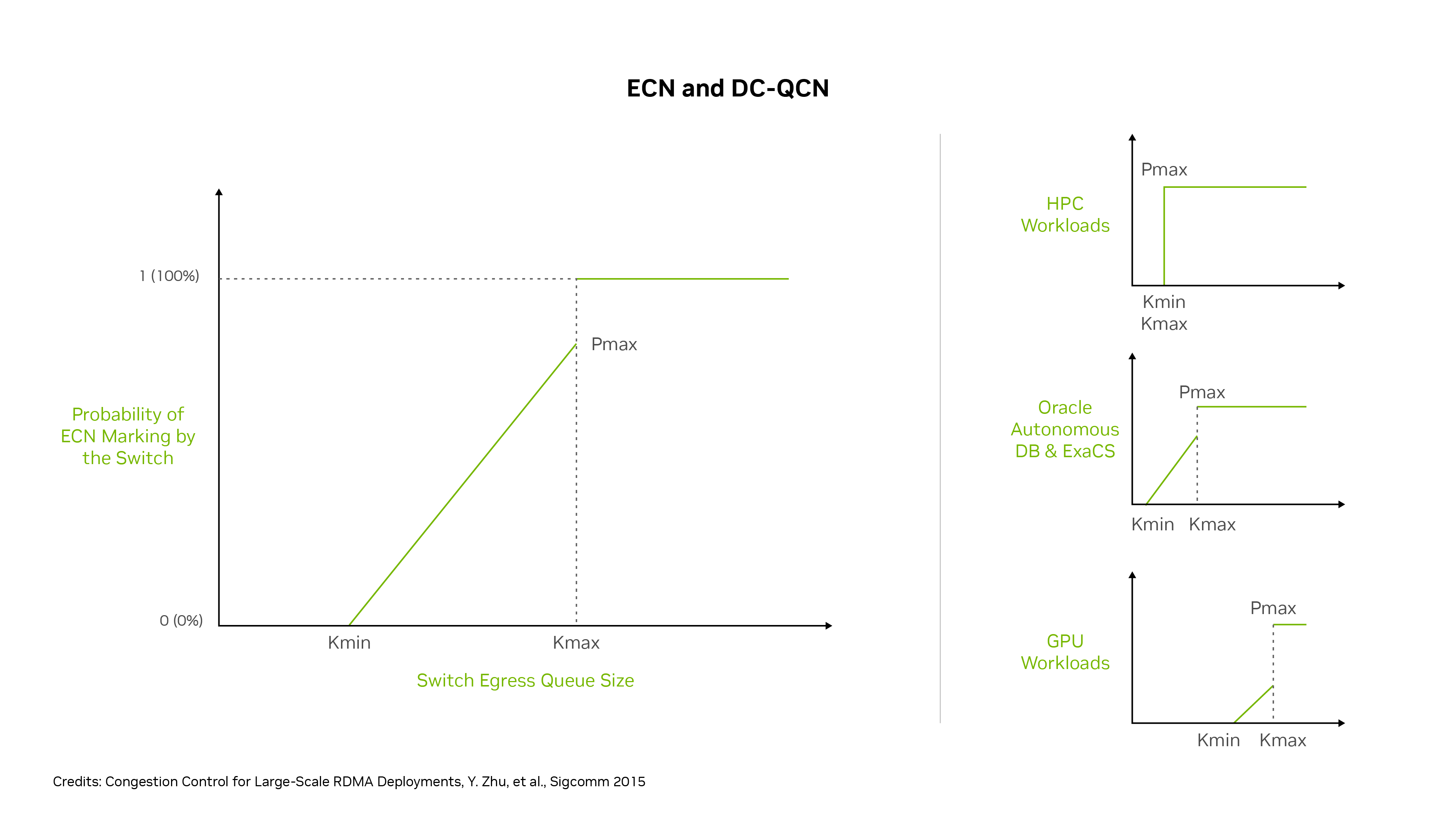
これらの設定では、キューが早期かつ積極的な輻輳制御の関与のためにKmaxレベル(これはKmaxと同じ)に達するとすぐに、HPCフローは100% ECNパケットマーキングを取得します。Oracle Autonomous DatabaseおよびExadataフローでは、中程度の早期ECNマーキングが表示されますが、バッファがKmaxレベルに達するまで、パケットの一部のみがマークされます。
他のGPUワークロードのKmax設定は高いため、スイッチ・キューが比較的いっぱいになるまでECNマーキングは開始されず、キューがいっぱいに近い場合にのみ100%のECNマーキングが発生します。様々なワークロードで、アプリケーションのパフォーマンスを最大化するために、レイテンシとスループットの理想的なバランスを実現するために必要な、カスタマイズされた輻輳制御設定を利用できます。
高度なネットワーク・ハードウェアの利用
RoCEネットワークで高パフォーマンスを実現するための重要な要素は、使用されるネットワーク・カードのタイプです。NICは、RDMAを含むネットワーク・スタックを特殊なチップにオフロードして、CPUおよびGPUから作業をオフロードします。OCIは、TCPトラフィックとRoCEトラフィックの両方に対して市場をリードするネットワーク・パフォーマンスを持つConnectX SmartNICsを使用します。
また、これらの SmartNICsは、ECNマークされたパケットまたはPFC一時停止フレームを検出し、CNPを送信し、輻輳通知に応答してデータ転送速度を下方および上方に調整するための、迅速なPFCおよびECN応答時間もサポートします。
NVIDIAは、RDMA、PFC、ECN、およびDC-QCNテクノロジの開発とサポートにおいて長年のリーダーであり、高パフォーマンスのGPUおよびGPU接続におけるリーダーとなっています。ConnectXの高度なRoCEオフロードにより、OCIネットワークでのスループットが向上し、レイテンシが低くなります。また、ハードウェアベースの迅速なECNリアクション時間は、DC-QCNがスムーズに機能することを保証するのに役立ちます。
最適化された輻輳制御スキームを専用のRoCEネットワークに実装し、ローカライズされたPFC、複数の輻輳制御プロファイル、およびNVIDIAネットワーク・アダプタを組み合わせることで、OCIは非常にスケーラブルなクラスタ・ネットワークを構築しました。これは、AIやML、HPC、Oracle Autonomous Databaseなどの分散ワークロードに最適で、InfiniBandネットワークが実現できるものに近い高スループットで低レイテンシのパフォーマンスを提供します。
データ・ローカリティの強調
OCIは、クラスタ・ネットワークのパフォーマンスを最適化し、データ局所性を管理してレイテンシを最小限に抑えます。100Gbps、200Gbps、400Gbpsのネットワーク接続の場合でも、複数のデータセンターのラックとホールにまたがることが多い RoCE接続クラスタの大規模な場合、光の速度は変化せず、ケーブルが長くなるほどレイテンシが高くなります。
データ・センター内の異なるホールへの接続では、より多くのスイッチがトラバースされ、各スイッチホップは接続待機時間に数ナノ秒を追加します。OCIは、サーバー地域情報を顧客とジョブ・スケジューラの両方と共有するため、ネットワーク内で互いに近いサーバーとGPUを使用するようにジョブをスケジュールできます。
たとえば、NVIDIA Collective Communication Library (NCCL)は、OCIネットワークトポロジおよびサーバーの近傍性情報を理解し、それに応じてGPUの作業をスケジュールできます。そのため、コンピュート接続とストレージ接続のスイッチ・ホップ数が減少し、ケーブル長が短くなるため、クラスタ内の平均レイテンシが減少します。
また、スパイン・スイッチへのトラフィックが少なくなり、トラフィック・ルーティングとロード・バランシングの意思決定が簡略化されます。また、OCIはスイッチ・ベンダーと連携して、スイッチのロードを認識しやすくしたため、負荷の少ない接続にフローをルーティングできます。各スイッチには通常、ネットワークの上下2つの接続があり、すべてのフローで複数のデータパスを使用できます。
まとめ
DC-QCN、高度なConnectX NIC、およびカスタマイズされた輻輳制御プロファイルを最適に実装して専用のRoCEネットワークに投資することで、OCIは、さまざまなワークロードやアプリケーション向けの高速コンピューティングをサポートするスケーラビリティの高いクラスタを提供します。OCIクラスタ・ネットワークは、高スループットと低レイテンシを同時に実現します。小規模なクラスタの場合、レイテンシ(往復時間の半分)は2マイクロ秒以下にすることができます。大規模なクラスタの場合、待機時間は通常4マイクロ秒未満です。非常に大きなスーパークラスタの場合、待機時間は4-8マイクロ秒の範囲で、ほとんどのトラフィックではこの範囲の下端に待機時間が表示されます。
Oracle Cloud Infrastructureは、革新的なアプローチを使用して、多くの分散ワークロードのイーサネットでスケーラブルなRDMAを搭載したネットワーキングを提供し、顧客により高いパフォーマンスと価値を提供します。
詳細は、次のリソースを参照してください。:
