Running performance-intensive workloads, such as simulations, was once possible only on supercomputers. Simulations are now more common, either replacing physical testing, as with computational fluid dynamics (CFD), or creating new opportunities.
To speed up simulations, engineers are running their workloads across multiple machines. If the parallel processes need information from each other, the simulation time is greatly affected by network performance. Such workloads are called “tightly coupled.” To improve the run time, Oracle Cloud Infrastructure introduced cluster networking in 2018. A cluster network is a pool of high-performance computing (HPC) instances that are connected with a high-bandwidth, ultra-low-latency network. In 2021, a new shape was made available with Intel Ice Lake processor.
With cluster networking, you can deploy a cluster in a few clicks and use our RDMA over Converged Ethernet (RoCE) v2 network with latency down to 1.7 µs (for 64-byte packets). This latency is lower than any other cloud vendor, but don’t take our word for it. In an analysis by Exabyte.io, Oracle Cloud was able to maintain the lowest latency over all (as shown in the following chart from Exabytie.io).
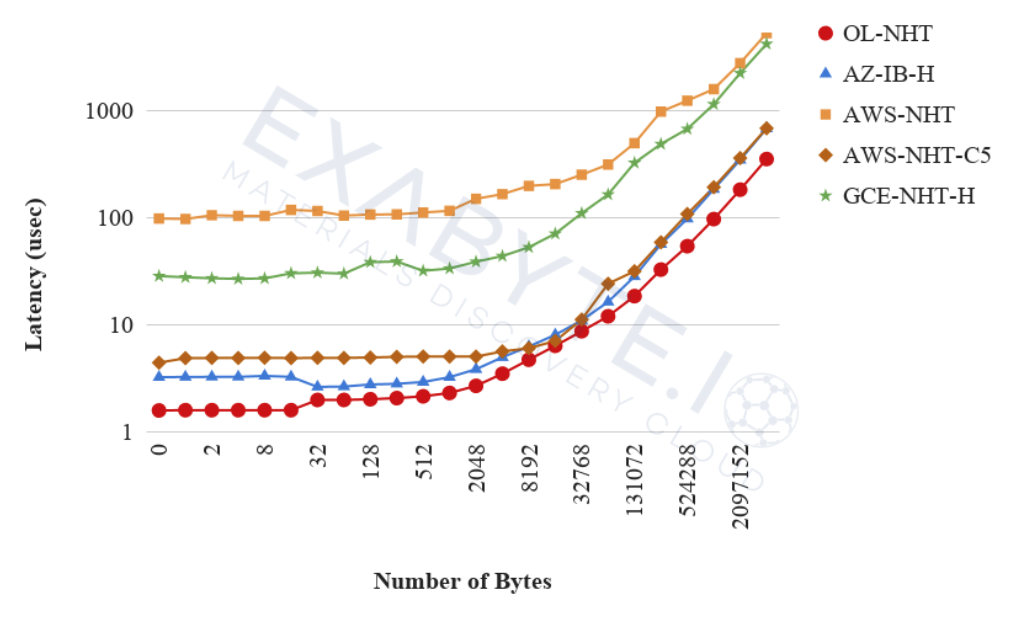
Figure 1: Results of Exabytie.io Analysis for Latency (https://docs.exabyte.io/images/benchmarks/ol-benchmarks-latency.png)
Network-bound workloads have nodes waiting on information from other nodes before they can continue with their individual tasks. A lower network latency reduces the idle time of the nodes, hence speeding up the workload. Looking at real world applications, you can also use more cores for faster results without a job price increase.
Enable Cluster Networking
Switching from InfiniBand to RoCE v2 might seem a bit daunting, but it’s as easy as modifying a few flags in your Message Passing Interface (MPI) command. This post describes what to do for the three most common MPIs: Open MPI, Intel MPI, and Platform MPI.
When you call the mpirun command or your software, the right interface and MPI flags must be specified. We recommend that you pin the processes to the first 36 cores, if you haven’t disabled hyperthreading. The following sections show you which flags to specify and how to pin processes for each of these MPIs.
Open MPI
For Open MPI prior to OpenMPI4, specify the following flags:
BM.HPC2.36
-mca btl self -x UCX_TLS=rc,self,sm -x HCOLL_ENABLE_MCAST_ALL=0 -mca coll_hcoll_enable 0 -x UCX_IB_TRAFFIC_CLASS=105 -x UCX_IB_GID_INDEX=3
To pin the processes:
--cpu-set 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35
Here is a pingpong example between two nodes:
source /usr/mpi/gcc/openmpi-3.1.1rc1/bin/mpivars.sh
mpirun -mca btl self -x UCX_TLS=rc,self,sm -x HCOLL_ENABLE_MCAST_ALL=0 -mca coll_hcoll_enable 0 -x UCX_IB_TRAFFIC_CLASS=105 -x UCX_IB_GID_INDEX=3 --cpu-set 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35 -np 2 --host hpc-node-1,hpc-node-2 /usr/mpi/gcc/openmpi-3.1.1rc1/tests/imb/IMB-MPI1 pingpong
For Open MPI starting from OpenMPI4, specify the following flags:
BM.HPC2.36
-mca pml ucx -x UCX_NET_DEVICES=mlx5_0:1 -x UCX_IB_TRAFFIC_CLASS=105 -x UCX_IB_GID_INDEX=3 -x HCOLL_ENABLE_MCAST_ALL=0 -x coll_hcoll_enable=0
BM.Optimized3.36
-mca pml ucx -x UCX_NET_DEVICES=mlx5_2:1 -x UCX_IB_TRAFFIC_CLASS=105 -x UCX_IB_GID_INDEX=3 -x HCOLL_ENABLE_MCAST_ALL=0 -x coll_hcoll_enable=0
If you are using a BM.GPU4.8 shape, you can specify different interfaces as UCX_NET_DEVICES:
Example:
-x UCX_NET_DEVICES=mlx5_0:1,mlx5_2:1,mlx5_4:1,mlx5_6:1
Warning: OpenMPI can only handle 4 interfaces at the time. You may want to switch off 4 of the 8 interfaces for BM.GPU4.8.
sudo ifdown enp94s0f0
Intel MPI
For versions earlier than version 2019, specify the following flags:
BM.HPC2.36
-iface enp94s0f0 -genv I_MPI_FABRICS=shm:dapl -genv DAT_OVERRIDE=/etc/dat.conf -genv I_MPI_DAT_LIBRARY=/usr/lib64/libdat2.so -genv I_MPI_DAPL_PROVIDER=ofa-v2-cma-roe-enp94s0f0 -genv I_MPI_FALLBACK=0
BM.Optimized3.36
-iface ens800f0 -genv I_MPI_FABRICS=shm:dapl -genv DAT_OVERRIDE=/etc/dat.conf -genv I_MPI_DAT_LIBRARY=/usr/lib64/libdat2.so -genv I_MPI_DAPL_PROVIDER=ofa-v2-cma-roe-ens800f0 -genv I_MPI_FALLBACK=0 -genv UCX_NET_DEVICES=mlx5_2:1
To pin the processes:
-genv I_MPI_PIN_PROCESSOR_LIST=0-35 -genv I_MPI_PROCESSOR_EXCLUDE_LIST=36-71
Here is a pingpong example between two nodes:
BM.HPC2.36
mpirun -ppn 1 -n 2 -hosts hpc-node-1,hpc-node-2 -iface enp94s0f0 -genv I_MPI_FABRICS=shm:dapl -genv DAT_OVERRIDE=/etc/dat.conf -genv I_MPI_DAT_LIBRARY=/usr/lib64/libdat2.so -genv I_MPI_DAPL_PROVIDER=ofa-v2-cma-roe-enp94s0f0 -genv I_MPI_FALLBACK=0 -genv I_MPI_PIN_PROCESSOR_LIST=0-35 -genv I_MPI_PROCESSOR_EXCLUDE_LIST=36-71 /opt/intel/compilers_and_libraries_2018.3./linux/mpi/intel64/bin/IMB-MPI1 pingpong
BM.Optimized3.36
mpirun -ppn 1 -n 2 -hosts hpc-node-1,hpc-node-2 -iface ens800f0 -genv I_MPI_FABRICS=shm:dapl -genv DAT_OVERRIDE=/etc/dat.conf -genv I_MPI_DAT_LIBRARY=/usr/lib64/libdat2.so -genv I_MPI_DAPL_PROVIDER=ofa-v2-cma-roe-ens800f0 -genv I_MPI_FALLBACK=0 -genv UCX_NET_DEVICES=mlx5_2:1 -genv I_MPI_PIN_PROCESSOR_LIST=0-35 -genv I_MPI_PROCESSOR_EXCLUDE_LIST=36-71 /opt/intel/compilers_and_libraries_2018.3./linux/mpi/intel64/bin/IMB-MPI1 pingpong
For version 2019 and later, specify the following flags:
BM.HPC2.36
-iface enp94s0f0 -genv I_MPI_FABRICS=shm:ofi -genv I_MPI_FALLBACK=0
BM.Optimized3.36
-iface ens800f0 -genv UCX_TLS rc,self,sm -genv UCX_NET_DEVICES mlx5_2:1 -genv I_MPI_FABRICS shm:ofi -genv I_MPI_FALLBACK 0
To pin the processes:
-genv I_MPI_PIN_PROCESSOR_LIST=0-35
Here is a pingpong example between two nodes:
BM.HPC2.36
source /opt/intel/compilers_and_libraries_2019.4.243/linux/mpi/intel64/bin/mpivars.sh
mpirun -ppn 1 -n 2 -hosts hpc-node-1,hpc-node-2 -iface enp94s0f0 -genv I_MPI_FABRICS=shm:ofi -genv I_MPI_FALLBACK=0 -genv I_MPI_PIN_PROCESSOR_LIST=0-35 /opt/intel/compilers_and_libraries_2019.4.243/linux/mpi/intel64/bin/IMB-MPI1 pingpong
BM.Optimized3.36
source /opt/intel/compilers_and_libraries_2019.4.243/linux/mpi/intel64/bin/mpivars.sh
mpirun -ppn 1 -n 2 -hosts hpc-node-1,hpc-node-2 -iface ens800f0 -genv UCX_TLS rc,self,sm -genv UCX_NET_DEVICES mlx5_2:1 -genv I_MPI_FABRICS shm:ofi -genv I_MPI_FALLBACK 0 -genv I_MPI_PIN_PROCESSOR_LIST=0-35 /opt/intel/compilers_and_libraries_2019.4.243/linux/mpi/intel64/bin/IMB-MPI1 pingpong
Platform MPI
For IBM Platform MPI, specify the following flags:
BM.HPC2.36
-intra=shm -e MPI_HASIC_UDAPL=ofa-v2-cma-roe-enp94s0f0 -UDAPL -e MPI_FLAGS=y
BM.Optimized3.36
-intra=shm -e MPI_HASIC_UDAPL=ofa-v2-cma-roe-ens800f0 -UDAPL -e MPI_FLAGS=y
To pin the processes:
-cpu_bind=MAP_CPU:0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19 ,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35
Here is a pingpong example between two nodes:
BM.HPC2.36
mpirun -d -v -prot -intra=shm -e MPI_HASIC_UDAPL=ofa-v2-cma-roe-enp94s0f0 -UDAPL -e MPI_FLAGS=y -hostlist hpc-cluster-node-1-rdma.local.rdma,hpc-cluster-node-2-rdma.local.rdma -cpu_bind=MAP_CPU:0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20, 21,22,23,24,25,26,27,28,29,30,31,32,33,34,35 mpitool -ppr 64
BM.Optimized3.36
mpirun -d -v -prot -intra=shm -e MPI_HASIC_UDAPL=ofa-v2-cma-roe-ens800f0 -UDAPL -e MPI_FLAGS=y -hostlist hpc-cluster-node-1-rdma.local.rdma,hpc-cluster-node-2-rdma.local.rdma -cpu_bind=MAP_CPU:0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20, 21,22,23,24,25,26,27,28,29,30,31,32,33,34,35 mpitool -ppr 64
That’s it! When you include those flags in the mpirun command, you will be using the ultra-low-latency connection and your network-bound workload will run much faster.
