※ 本記事は、Rik Kisnah, Leo Liによる”Zettascale in Practice: OSU and NCCL Benchmark on H100 Clusters for HPC and AI Workloads“を翻訳したものです。
2025年12月8日
GPT-3やGPT-4などの最新のAIモデルでは、大規模なクラスタ間で連携する数千のGPUが必要です。この環境では、ネットワーク・パフォーマンスはコンピュートと同じくらいクリティカルになります。マイクロ秒単位のレイテンシとすべてのパケットの損失により、効率が低下し、コストが増加します。このブログでは、次のことを説明します:
- スケーラブルなAIワークロードには、非ブロッキングでロスレスなRDMAネットワークが不可欠である理由。
- OCIのAIインフラストラクチャとOSUおよびNCCLツールのベンチマーク結果。
RDMA: 高速で効率的なGPU通信のキー
従来のTCP/IPネットワーキングでは、コストのかかるデータセンター税が導入されています。つまり、データはOSカーネルを経由して移動し、CPUサイクルを消費し、メモリー・コピーが必要になります。ハイパースケールは、このオーバーヘッドが総インフラストラクチャ・コストの最大30%を消費する可能性があることを経験しています。[リファレンス.2]
リモートダイレクトメモリアクセス(RDMA)はCPUとOSを完全にバイパスし、ノード間のGPU間のダイレクトメモリ転送を可能にします。コピーなし、カーネル・バイパス、および物理パスの短縮により、RDMAはレイテンシを削減し、コンピュート・リソースを解放し、GPUにフル帯域幅を提供します。主なメリット:
- TCP/IPを使用した10-50μsと比較して最大2μsのレイテンシは、ノード間でパラメータを同期するために重要です [リファレンス.5]。
- CPU使用率の低下、マルチGPU環境に最適 [リファレンス.4,5]
- GPU使用率が高い(特にAllReduceなどの集合演算)
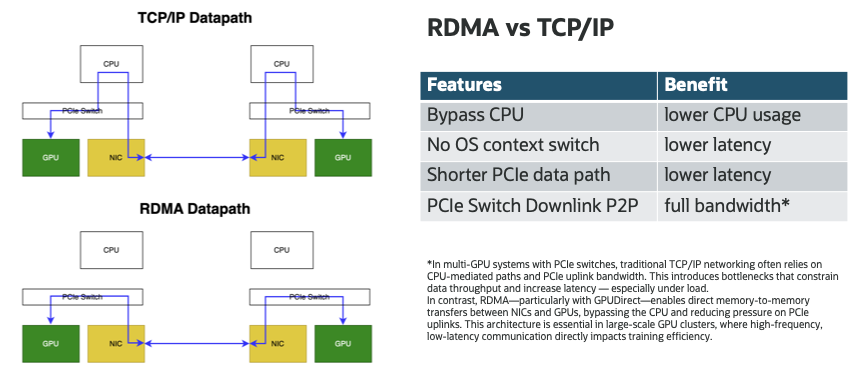
PCIeスイッチを使用するマルチGPUシステムでは、従来のTCP/IPネットワークは、多くの場合、CPU媒介パスおよびPCIeアップリンク(RC)帯域幅に依存します。これにより、データのスループットが制限され、レイテンシが増加する(特に負荷がかかる)ボトルネックが発生します。これに対して、RDMA (特にGPUDirect)は、PCIe P2Pダウンリンク・ドメイン内のNICとGPU間のメモリー間直接転送を有効にし、CPUをバイパスしてPCIeアップリンクに対する負荷を軽減します。このアーキテクチャは、高頻度で低レイテンシの通信がトレーニングの効率に直接影響する大規模なGPUクラスタに不可欠です。
RDMAには、ロスレスおよび非ブロッキング・ネットワークが必要
ただし、RDMAネットワーキングのメリットを最大限に引き出すには、低レイテンシで高スループットの要件をサポートするための基本的なイノベーションと専用インフラストラクチャが必要です。RDMAネットワークは、パケット損失に非常に敏感です。損失率が0.1%であっても、GPU使用率を大幅に削減できます。AIワークロードは、多くの場合、最も遅いパケットによってパフォーマンスが決定されるAllReduceのような同期化された操作に依存します。最近の研究によれば:
- 0.1%の損失: GPU使用率が10%以上低下
- 1%の損失: 集団運転停止によるスループットの90%以上低下
無損失の配達がなければ、RDMAは利点の代わりに責任になります。ロスレス・ネットワークには、次のものが必要です:
- 明示的な輻輳制御(DCQCNなど)
- 待機時間 × スループットに比例したポートごとのパケットバッファリング
- オーバーサブスクリプションのボトルネックを排除するための非ブロッキングClosファブリック
非ブロッキングRDMAネットワーキングがクラウドAIインフラストラクチャのキー
動的リソース割当ておよびマルチテナントの性質により、パブリック・クラウド環境では追加の制約が導入されます:
- 高効率: 非ブロッキング・アーキテクチャがない場合、分散トレーニング・ジョブ(26,000-GPUクラスタなど)は、再送信およびキュー・ビルドアップによるスループットの低下に直面 [リファレンス.3]
- マルチテナント: 異なる顧客は、干渉することなくインフラストラクチャを共有する必要あり
- 柔軟なワークロード: ジョブは動的に、予測不能にスケールアップ/スケールダウン
- ワークロードの多様性: 推論とトレーニング、大規模および小規模ジョブの混合
非ブロッキングRDMAファブリックのみが次のものを提供:
- テナント間の予測可能なレイテンシと帯域幅で、ノイジー・ネイバー効果はありません。
- ホットスポットやオーバーサブスクリプションのないスケーラブルなトポロジ
- 小型podからフル・スーパークラスタへの線形スケールアウト
非ブロッキングRDMAネットワークのスケーリングの課題とその理由
いくつかのGPUから100,000以上のGPUに非ブロッキングRDMAネットワークをスケーリングすることは、単にスイッチを追加するだけではありません。レイテンシを低く抑え、無損失な動作を維持し、ハードウェア・コストを制御するために、基本的なアーキテクチャ・イノベーションが必要です。以下では、ロスレスRDMAネットワーク全般をどのように拡張するのが難しいかを示す簡単な要素について説明します。
1. ロスレス・ネットワーキングでレイテンシが重要な理由
ハードウェア・レベルでは、RDMAネットワークは、ロスレス伝送を確保するために、処理中のパケットをバッファリングする必要があります。ポートごとに必要なバッファは、次のようにスケーリングされます:
Buffer ∝ Latency × Throughput × Bidirectionality × Safety Margin
たとえば:
- 400 Gbps × 2μs × 2 directions = 200 KB per port
- Add 50% margin → 300 KB × 128 ports = 38.4 MB per switch
10μs の待ち時間:
- 1.5 MB per port → 192 MB total — Broadcom Tomahawk 5の165.2 MBバッファを超えています
2. レイテンシがスケーラビリティを決定する理由
100,000以上のGPUを接続するには、多くの場合、6つのスイッチ・ホップ・ラウンドトリップを含む多層Closトポロジが必要です。1ホップ当たり1.5μsの場合、エンドツーエンドのレイテンシは9μsです。
- 400 Gbps × 9μs × 2 × 1.5 = 1.35 MB per port
- 1.35 MB × 128 = 172.8 MB — ASICバッファ制限に再度近い
これにより、レイテンシはスケーラビリティのボトルネックになります。これは、総当たりバッファリングではなく、イノベーションによってのみ解決できます。
3. GPUクラスタを100,000以上(特にクラウド)に拡張する必要があるのはなぜ?
GPUインフラストラクチャを10万から100万のGPU範囲に拡張する必要性は、単なるモデル・サイズの製品ではなく、クラウド・コンピューティングの経済性とダイナミクスにも左右されます。
大規模なGPUクラスタは、次の場合に不可欠です:
- 数兆個のパラメータを持つフロンティア・モデルをトレーニングして提供します。そうしないと、小規模なシステムでトレーニングするには数か月かかります。
- ワークロードを共有インフラストラクチャに統合し、使用率を向上させ、ユーザーごとのコストを削減します。
- バッチ・トレーニングから低レイテンシの推論まで、何千もの顧客が多様なAIジョブを同じバックボーンで実行するマルチテナント・オーケストレーションを可能にします。
しかし、クラウドでは追加の需要が導入されています:
- 動的ワークロード・パターン: AIジョブのサイズと期間は様々で、ネットワークがリアルタイムに適応する必要があります。
- 厳格な孤立と公平性: 1つのテナントのノイジー・ワークロードが別のテナントのパフォーマンスに影響を与えることはできません。
- 柔軟なスケーラビリティ: ネットワークを再設計することなく、リソースの割り当てと再利用を迅速に行う必要があります。
これらの条件はすべて、非ブロッキング、低レイテンシのRDMAネットワークの重要性を増幅させます。クラウド・プロバイダーが保証できるのは、一貫して低レイテンシかつロスレスなパフォーマンスをファブリック全体で実現した場合のみです:
- 混合ワークロードおよびバースティング・ワークロードでの予測可能なパフォーマンス
- きめ細かいジョブ・スケジューリングによる効率的なGPU使用率
- オーバープロビジョニングとバッファリングのオーバーヘッドを削減することで、インフラストラクチャ・コストを削減
クラウドでは、スケーリングはより多くのGPUだけではありません。すべてのGPUを、ボトルネックなく、いつでもあらゆるジョブで使用できるようにすることです。
OCIのRDMAネットワーキングの動作
OCIの非ブロッキングRDMAインフラストラクチャが実際に及ぼす影響を実証するために、OCI Supercluster環境のGPUノード間で一連のレイテンシ・ベンチマークを実施しました。
1. テスト・システム構成
- Node 1: H100.8 Shape with 16×200 Gbps RoCEv2 NIC
- Node 2: H100.8 Shape with 16×200 Gbps RoCEv2 NIC
- Driver/OS: Ubuntu 22.04 LTS with NVIDIA OFED, RDMA enabled
- テスト・ツール: OSU Micro Benchmarking 7.5 and NCCL Test Suites
2. OSU micro benchmark test
HPCおよびAIワークロードでは、ノード間レイテンシと帯域幅の両方が重要です。ゴールド標準のOSUマイクロ・ベンチマーク・ツールを使用して、レイテンシと帯域幅をテストします。
2.1. まず、ソースからOSU 7.5をインストール
cd osu-micro-benchmarks-7.5
# CUDA setup (adjust version if needed)
export CUDA_HOME=/usr/local/cuda-12.8
export PATH=$CUDA_HOME/bin:$PATH
export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$CUDA_HOME/targets/x86_64-linux/lib:$LD_LIBRARY_PATH
# Configure with CUDA + MPI
./configure CC=/usr/bin/mpicc \
CXX=/usr/bin/mpicxx \
--enable-cuda \
--with-cuda-include=$CUDA_HOME/include \
--with-cuda-libpath=$CUDA_HOME/targets/x86_64-linux/lib \
--enable-ncclomb \
--with-nccl=/usr
make -j 82.2. レイテンシおよび帯域幅テスト
適切な環境フラグがmpiに渡されていることを確認します。
#!/bin/bash
export UCX_TLS=rc,ud
export UCX_NET_DEVICES=mlx5_0:1,mlx5_1:1,mlx5_3:1,mlx5_4:1,mlx5_5:1,mlx5_6:1,mlx5_7:1,mlx5_8:1,mlx5_9:1,mlx5_10:1,mlx5_12:1,mlx5_13:1,mlx5_14:1,mlx5_15:1,mlx5_16:1,mlx5_17:1
# NCCL IB tuning
export NCCL_IB_HCA=mlx5_0,mlx5_1,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_7,mlx5_8,mlx5_9,mlx5_10,mlx5_12,mlx5_13,mlx5_14,mlx5_15,mlx5_16,mlx5_17
export NCCL_IB_GID_INDEX=3
export NCCL_IB_SL=0
export NCCL_IB_TC=41
export NCCL_IB_QPS_PER_CONNECTION=16
export HCOLL_ENABLE_MCAST_ALL=0
export NCCL_NET_GDR_LEVEL=2 # if your setup supports GPUDirect RDMA
export UCX_LOG_LEVEL=warn
FLAG="-np 2 -H 10.224.8.156,10.224.9.98 --bind-to numa -x UCX_TLS -x UCX_NET_DEVICES -x NCCL_IB_HCA -x NCCL_IB_GID_INDEX -x NCCL_IB_SL -x NCCL_IB_TC -x NCCL_IB_QPS_PER_CONNECTION -x NCCL_NET_GDR_LEVEL -x HCOLL_ENABLE_MCAST_ALL --mca pml ucx --mca coll_hcoll_enable 0"
Path=’./c/mpi/pt2pt/standard’
mpirun $FLAG ${path}/osu_latency
mpirun $FLAG ${path}/osu_bw2.3. レイテンシと帯域幅の結果
レイテンシ・テーブル:
<strong>Size (bytes) Latency (us)
0 1 2.70
1 2 2.70
2 4 2.70
3 8 2.70
4 16 2.70
5 32 2.75
6 64 2.84
7 128 2.87
8 256 3.26
9 512 3.24
10 1024 3.41
11 2048 4.50
12 4096 5.17
...
</strong>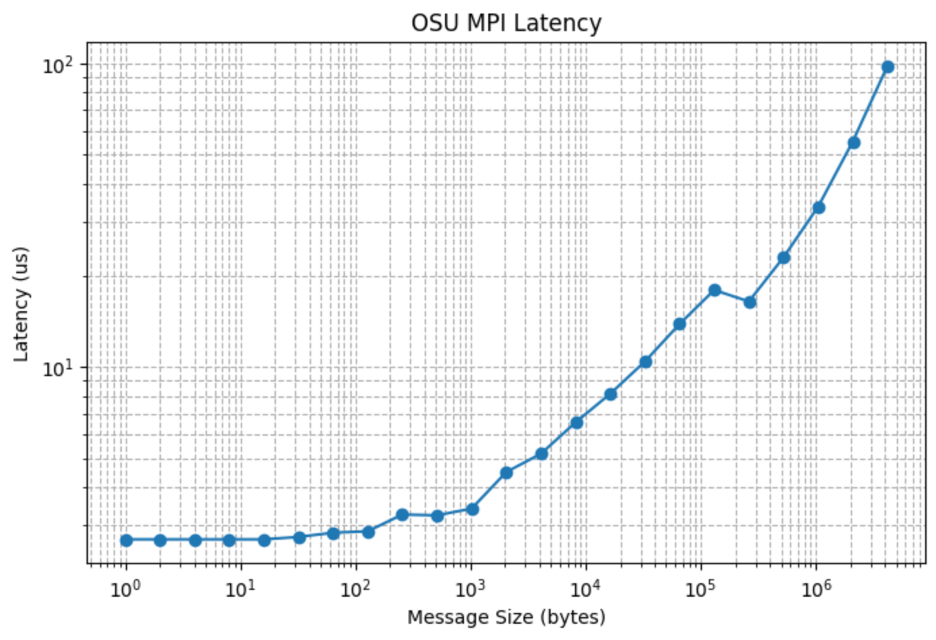
帯域幅テーブル:
<strong>Size (bytes) Bandwidth (MB/s)
...
13 8192 14547.66
14 16384 16604.73
15 32768 16338.83
16 65536 23144.42
17 131072 33381.00
18 262144 40983.24
19 524288 46679.72
20 1048576 48369.05
21 2097152 48624.98
22 4194304 48768.53
23 8388608 48839.29
24 16777216 48873.73
25 33554432 48889.82
26 67108864 48892.72
27 134217728 48892.45
28 268435456 48892.20
29 536870912 48893.08
30 1073741824 48892.54</strong>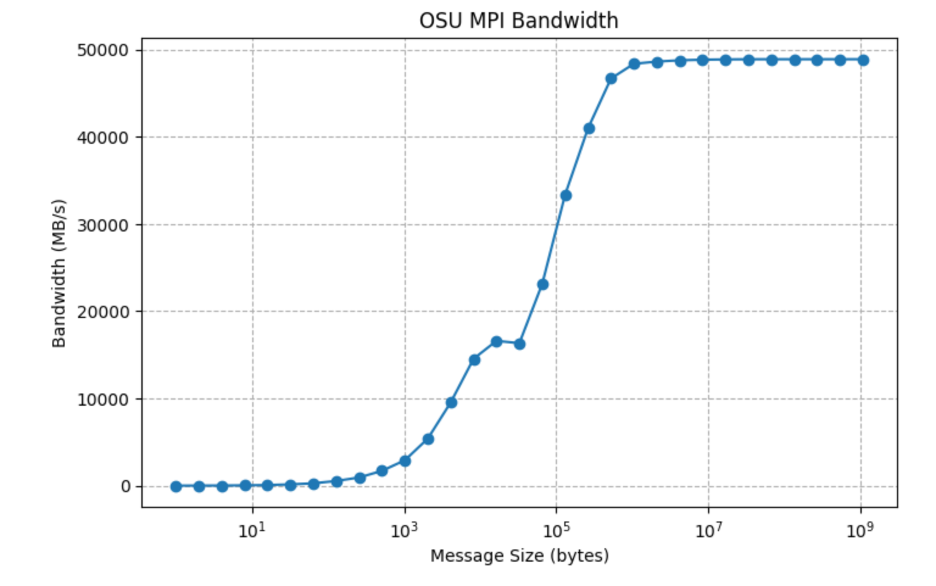
3. RDMAネットワーク・テスト全体でのGPUからGPU
このテストでは、MPIが強制的にデバイスメモリーを使用し、RDMAネットワーク上の1つのGPUからアンサーGPUへのデバイスメモリーコピーをテストします。
レイテンシ・テーブル:
Size (bytes) Latency (us)
0 0 29.97
1 1 32.68
2 2 32.66
3 4 32.69
4 8 32.70
5 16 32.37
6 32 32.37
7 64 32.39
8 128 32.43
9 256 32.58
10 512 32.63
11 1024 32.69
12 2048 32.79
13 4096 32.77
14 8192 33.11
15 16384 33.60
16 32768 36.15
17 65536 42.50
18 131072 39.99
19 262144 47.75
20 524288 60.35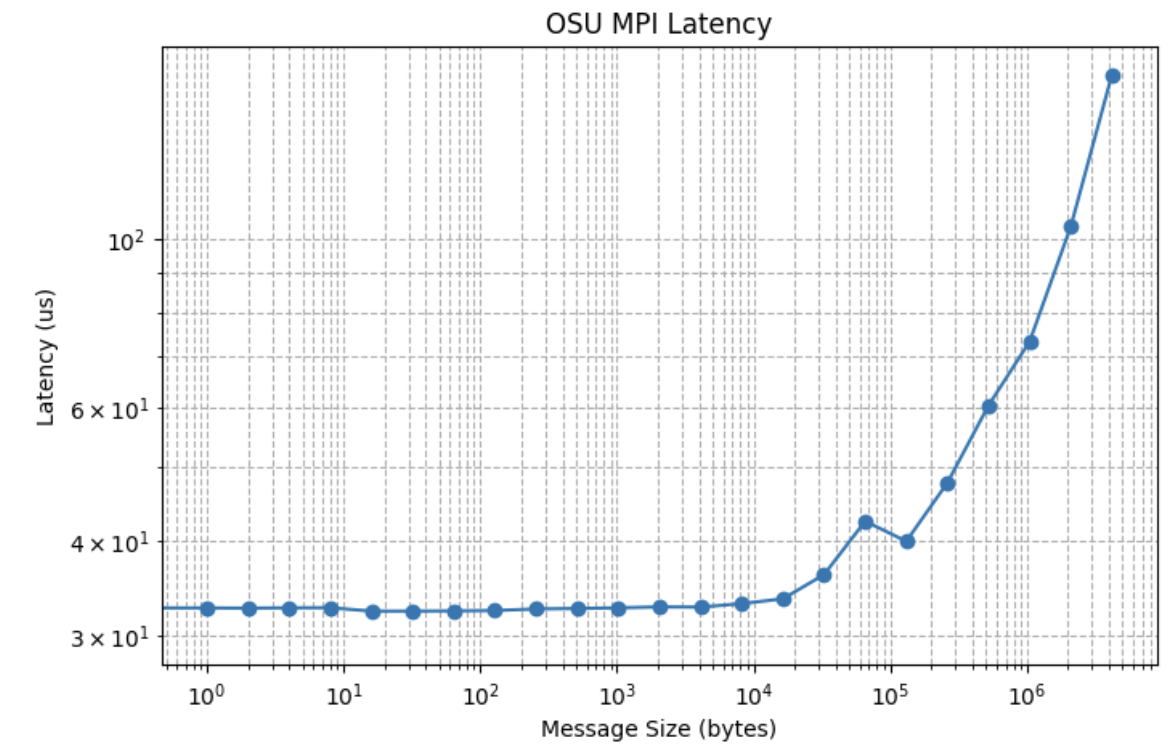
GPUカーネルおよびPCIeレイテンシにより、「NCCL 2.27による高速推論と自己回復性トレーニングの有効化」で説明されているように、RDMAに対するGPUからGPUへのレイテンシは、RDMAに対するCPUからCPUへのレイテンシよりも大幅に高くなります。オラクルのベンチマーク・データによって、新しいハードウェアおよびソフトウェア・パイプラインの最適化によるAIワークロードを最適化するためのイノベーションが促進され、LLMの大規模なAllReduceおよびLLM推論PD分離はGPU間メモリー・レイテンシに敏感であることを考慮して、これらのレイテンシの短所が軽減されます。
4. NCCLテスト・スイート
AIワークロードに加えて、NCCLを持つ集合事業者も非常に重要です。これをテストするには、NCCLテスト・スイートを使用します。
4.1. ソースからNCCLをコンパイル
export CUDA_HOME=/usr/local/cuda-12.8
export MPI_HOME=/usr/lib/x86_64-linux-gnu/openmpi
dpkg -l | grep nccl
git clone https://github.com/NVIDIA/nccl-tests.git
cd nccl-tests
make MPI=1 \
CUDA_HOME=${CUDA_HOME} \
MPI_HOME=${MPI_HOME} \
MPICC=$(which mpicc) \
-j all4.2. 8 GPUを搭載した単一ノードでNCCLすべて削減の実行
#bin/bash
# this is a script to perform nccl_test
echo "All Reduce Performance"
./nccl-tests/build/all_reduce_perf -b 32 -e 4G -f 2 -g 84.3. 16 GPUを搭載した2ノードでNCCLすべて削減の実行
#!/bin/bash
export UCX_TLS=rc,ud
# NCCL IB tuning
export NCCL_IB_GID_INDEX=3
export NCCL_IB_SL=0
export NCCL_IB_TC=41
export NCCL_IB_QPS_PER_CONNECTION=16
export HCOLL_ENABLE_MCAST_ALL=0
export NCCL_NET_GDR_LEVEL=2 # if your setup supports GPUDirect RDMA
export UCX_NET_DEVICES=mlx5_0:1,mlx5_1:1,mlx5_3:1,mlx5_4:1,mlx5_5:1,mlx5_6:1,mlx5_7:1,mlx5_8:1,mlx5_9:1,mlx5_10:1,mlx5_12:1,mlx5_13:1,mlx5_14:1,mlx5_15:1,mlx5_16:1
export NCCL_IB_HCA=mlx5_0,mlx5_1,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_7,mlx5_8,mlx5_9,mlx5_10,mlx5_12,mlx5_13,mlx5_14,mlx5_15,mlx5_16,mlx5_17
# UCX logging—silence the CUDA-copy warnings
export UCX_LOG_LEVEL=warn
mpirun -np 2 -H 10.224.8.156,10.224.9.98 --bind-to numa \
-x UCX_TLS \
-x UCX_NET_DEVICES \
-x NCCL_IB_HCA -x NCCL_IB_GID_INDEX \
-x NCCL_IB_SL -x NCCL_IB_TC -x NCCL_IB_QPS_PER_CONNECTION \
-x NCCL_NET_GDR_LEVEL \
-x HCOLL_ENABLE_MCAST_ALL \
--mca pml ucx --mca coll_hcoll_enable 0 \
./build/all_reduce_perf -b 32 -e 10G -f 2 -g 8結果:

OCIの最先端の非ブロッキングRDMAネットワーキングにより、NCCL AllReduceのパフォーマンスは妥協することなく拡張できます。
まとめ
非ブロッキングRDMAは、大規模なAIでは交渉不可能であり、遅延やCPUオーバーヘッドを低減しながら輻輳を防止します。OCIは、RoCEが最適化されたネットワークでAIインフラストラクチャ市場をリードし、32,000を超えるGPUへの拡張性を実証し、大規模な超低レイテンシを実現しています。損失のない低レイテンシのRDMAがGPU効率に重要である理由を最初に調査しました。次に、OCIで最先端のパフォーマンスを実現するための詳細なベンチマーク設定を提供します。オラクルのベンチマークでは、OCIのRDMAファブリックを実際に活用しています:
| テスト | 値 |
|---|---|
| Node to node CPU-to-CPU latency | 2.7 us |
| RDMA NIC bandwidth (400Gbps) | 48.77 GB/s |
| GPU to GPU Latency over RDMA networking | 29 us |
| NCCL on single node with 8 GPUs | 476.37 GB/s |
| NCCL on two nodes with 16 GPUs | 469.67 GB/s |
リファレンス
- roce-network-distributed-ai-training-at-scale
- software-defined-rdma-networks-for-large-scale-ai-infrastructure
- sigcomm24-final246
- rdma-a-deep-dive-into-remote-direct-memory-access
- networking-for-ai-workloads
- Oracleの生成AIパフォーマンス
- Oracleのベンチマーク meta
- make-the-most-of-the-cloud-momentum-why-oci-is-winning-the-ai-workloads-game
- ai-innovators-worldwide-choose-oracle-for-ai-training-and-inferencing
- Oracle ai innovators worldwide
- Accenture-Oracle-Cloud-Performance
- gregpavlik_oracles-results-in-the-recentmlperfv41-activity
- https://tijer.org/tijer/papers/TIJER2111004.pdf
- unlocking-ai-excellence-how-modal-labs-utilizes-oci
- optimizing-ai-workloads-with-highspeed-roce-solutions
- benchmarking-oci-compute-shapes-llm-serving
- rdmabox-optimizing-rdma-for-memory-intensive-workloads
- how-rdma-is-solving-ais-scalability-problem
- test-ai-data-center-networks
