Modern AI models like GPT-3 and GPT-4 require thousands of GPUs working together across large-scale clusters. In this environment, network performance becomes as critical as compute. Every microsecond of latency and every packet lost reduces efficiency and increases cost. This blog will explain:
- why non-blocking, lossless RDMA networks are essential for scalable AI workloads.
- The benchmark result of OCI’s AI infrastructure with OSU Micro-Benchmarks and NVIDIA Collective Communications Library (NCCL) tools.
RDMA: the key to fast, efficient GPU communication
Traditional TCP/IP networking introduces a costly “datacenter tax”: data must travel through the OS kernel, consume CPU cycles, and involve memory copies. Hyperscales have experienced that this overhead can consume up to 30% of total infrastructure cost.[ref2]
Remote Direct Memory Access (RDMA) bypasses the CPU and OS entirely, enabling direct memory-to-memory transfers between GPUs across nodes. With zero-copy, kernel bypass, and shorter physical path, RDMA reduces latency, frees up compute resources, and provides full bandwidth to GPUs. Key benefits:
- ~2μs latency, compared to 10–50μs with TCP/IP, critical for synchronizing parameters across nodes [ref5].
- Lower CPU usage, ideal for multi-GPU environments,[ref4,5]
- Higher GPU utilization, especially in collective ops like AllReduce
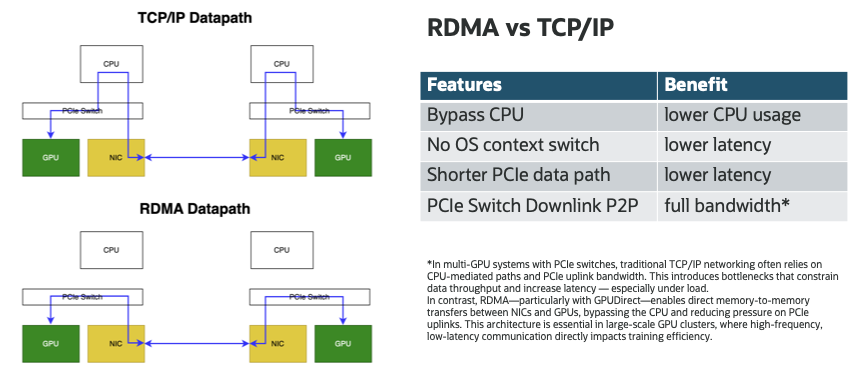
In multi-GPU systems with PCIe switches, traditional TCP/IP networking often relies on CPU-mediated paths and PCIe uplink (RC) bandwidth. This introduces bottlenecks that constrain data throughput and increase latency — especially under load. In contrast, RDMA—particularly with GPUDirect—enables direct memory-to-memory transfers between NICs and GPUs in the PCIe P2P downlink domain, bypassing the CPU and reducing pressure on PCIe uplinks. This architecture is essential in large-scale GPU clusters, where high-frequency, low-latency communication directly impacts training efficiency.
RDMA needs a lossless and nonblocking network
However, unlocking the full benefits of RDMA networking demands fundamental innovation and purpose-built infrastructure to support its low-latency, high-throughput requirements. RDMA networks are extremely sensitive to packet loss. Even a 0.1% loss rate can dramatically reduce GPU utilization. AI workloads often rely on synchronized operations like AllReduce, where the slowest packet dictates performance. Recent studies show:
- 0.1% loss: GPU utilization drops by 10%+
- 1% loss: Throughput collapses by 90%+ due to collective operation stalls
Without lossless delivery, RDMA becomes a liability instead of an advantage. Lossless networking requires:
- Explicit congestion control (e.g., DCQCN)
- Per-port packet buffering proportional to latency × throughput
- Non-blocking Clos fabrics to eliminate oversubscription bottlenecks
Non-blocking RDMA networking is key for cloud AI infrastructure
Due to the dynamic resource allocation and multitenant nature, public cloud environments introduce additional constraints:
- High efficiency: without non-blocking architectures, distributed training jobs (e.g., 26,000-GPU clusters) face throughput degradation due to retransmissions and queue buildup [ref3]
- Multi-tenancy: Different customers must share infrastructure without interference
- Elastic workloads: Jobs scale up/down dynamically and unpredictably
- Workload diversity: Mix of inference and training, large and small jobs
Only non-blocking RDMA fabrics can deliver:
- Predictable latency and bandwidth across tenants, no noisy neighbor effect.
- Scalable topology without hotspots or oversubscription
- Linear scale-out from small pods to full superclusters
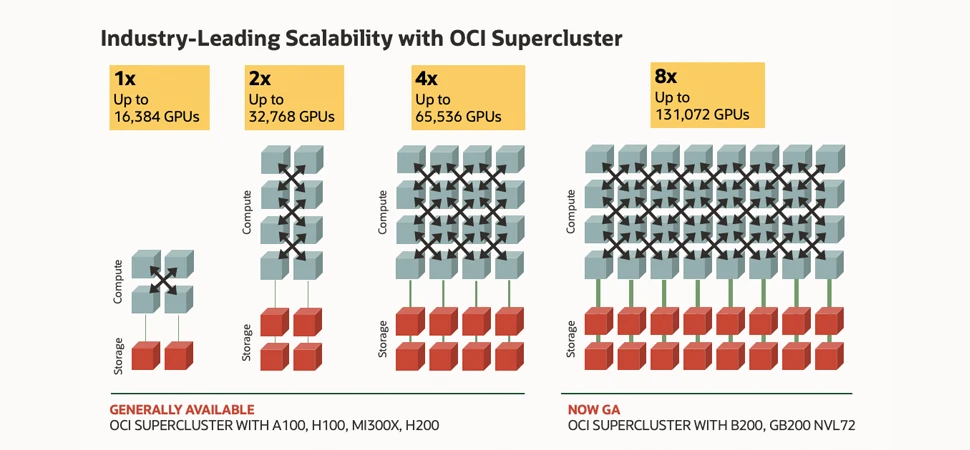
The challenge of scaling non-blocking RDMA networks and why
Scaling a non-blocking RDMA network from a few GPUs to 100,000+ GPUs is not a matter of simply adding more switches. It demands fundamental architectural innovation to keep latency low, maintain lossless behavior, and control hardware cost. Below we walk through a simple factor to show how hard to scale the lossless RDMA networking in general.
1. Why latency matters in lossless networking
At the hardware level, RDMA networks must buffer in-flight packets to ensure lossless transmission. The required buffer per port scales with:
Buffer ∝ Latency × Throughput × Bidirectionality × Safety Margin
For example:
- 400 Gbps × 2μs × 2 directions = 200 KB per port
- Add 50% margin → 300 KB × 128 ports = 38.4 MB per switch
At 10μs latency:
- 1.5 MB per port → 192 MB total — exceeds Broadcom Tomahawk 5’s 165.2 MB buffer
2. Why latency dictates scalability
To connect 100,000+ GPUs, we need multi-tier Clos topologies, often involving 6 switch hops round-trip. With 1.5μs per hop, that’s 9μs end-to-end latency.
- 400 Gbps × 9μs × 2 × 1.5 = 1.35 MB per port
- 1.35 MB × 128 = 172.8 MB — again close to ASIC buffer limits
This makes latency a scalability bottleneck — one that can only be solved by innovation, not brute-force buffering.
3. Why do we need to scale GPU clusters to 100,000+ — especially in the cloud?
The need to scale GPU infrastructure into the hundred-thousand and eventually million GPU range is not just a product of model size — it’s also driven by the economics and dynamics of cloud computing.
Large-scale GPU clusters are essential to:
- Train and serve frontier models with trillions of parameters, which would otherwise take months to train on smaller systems.
- Consolidate workloads in shared infrastructure, improving utilization and reducing per-user cost.
- Enable multi-tenant orchestration, where thousands of customers run diverse AI jobs — from batch training to low-latency inference — on the same backbone.
But the cloud introduces additional demands:
- Dynamic workload patterns: AI jobs vary in size and duration, requiring the network to adapt in real time.
- Strict isolation and fairness: One tenant’s noisy workload cannot impact another’s performance.
- Elastic scalability: Resources must be allocated and reclaimed quickly, without rearchitecting the network.
All of these conditions amplify the importance of non-blocking, low-latency RDMA networks. Only with consistently low latency and lossless performance across the fabric can cloud providers guarantee:
- Predictable performance under mixed and bursting workloads
- Efficient GPU utilization through fine-grained job scheduling
- Lower infrastructure cost by reducing overprovisioning and buffering overhead
In the cloud, scaling is not just about more GPUs. It’s about making every GPU available to any job, at any time, without bottlenecks.
OCI’s RDMA networking in practice
To demonstrate the real-world impact of OCI’s non-blocking RDMA infrastructure, we conducted a series of latency benchmarks between GPU nodes in an OCI Supercluster environment.
1. Test system configuration
- Node 1: H100.8 Shape with 16×200 Gbps RoCEv2 NIC
- Node 2: H100.8 Shape with 16×200 Gbps RoCEv2 NIC
- Driver/OS: Ubuntu 22.04 LTS with NVIDIA MLNX OFED, RDMA enabled
- Test tools: OSU Micro Benchmarking 7.5 and NCCL Test Suites
2. OSU micro benchmark test
For HPC and AI workloads, node to node latency and bandwidth are both important. We test the latency and bandwidth with the gold standard OSU micro benchmarking tools.
2.1. First install the OSU 7.5 from the source
cd osu-micro-benchmarks-7.5
# CUDA setup (adjust version if needed)
export CUDA_HOME=/usr/local/cuda-12.8
export PATH=$CUDA_HOME/bin:$PATH
export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$CUDA_HOME/targets/x86_64-linux/lib:$LD_LIBRARY_PATH
# Configure with CUDA + MPI
./configure CC=/usr/bin/mpicc \
CXX=/usr/bin/mpicxx \
--enable-cuda \
--with-cuda-include=$CUDA_HOME/include \
--with-cuda-libpath=$CUDA_HOME/targets/x86_64-linux/lib \
--enable-ncclomb \
--with-nccl=/usr
make -j 8
2.2. Latency and bandwidth test
Make sure the right environment flags are passed to the mpi.
#!/bin/bash
export UCX_TLS=rc,ud
export UCX_NET_DEVICES=mlx5_0:1,mlx5_1:1,mlx5_3:1,mlx5_4:1,mlx5_5:1,mlx5_6:1,mlx5_7:1,mlx5_8:1,mlx5_9:1,mlx5_10:1,mlx5_12:1,mlx5_13:1,mlx5_14:1,mlx5_15:1,mlx5_16:1,mlx5_17:1
# NCCL IB tuning
export NCCL_IB_HCA=mlx5_0,mlx5_1,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_7,mlx5_8,mlx5_9,mlx5_10,mlx5_12,mlx5_13,mlx5_14,mlx5_15,mlx5_16,mlx5_17
export NCCL_IB_GID_INDEX=3
export NCCL_IB_SL=0
export NCCL_IB_TC=41
export NCCL_IB_QPS_PER_CONNECTION=16
export HCOLL_ENABLE_MCAST_ALL=0
export NCCL_NET_GDR_LEVEL=2 # if your setup supports GPUDirect RDMA
export UCX_LOG_LEVEL=warn
FLAG="-np 2 -H 10.224.8.156,10.224.9.98 --bind-to numa -x UCX_TLS -x UCX_NET_DEVICES -x NCCL_IB_HCA -x NCCL_IB_GID_INDEX -x NCCL_IB_SL -x NCCL_IB_TC -x NCCL_IB_QPS_PER_CONNECTION -x NCCL_NET_GDR_LEVEL -x HCOLL_ENABLE_MCAST_ALL --mca pml ucx --mca coll_hcoll_enable 0"
Path=’./c/mpi/pt2pt/standard’
mpirun $FLAG ${path}/osu_latency
mpirun $FLAG ${path}/osu_bw
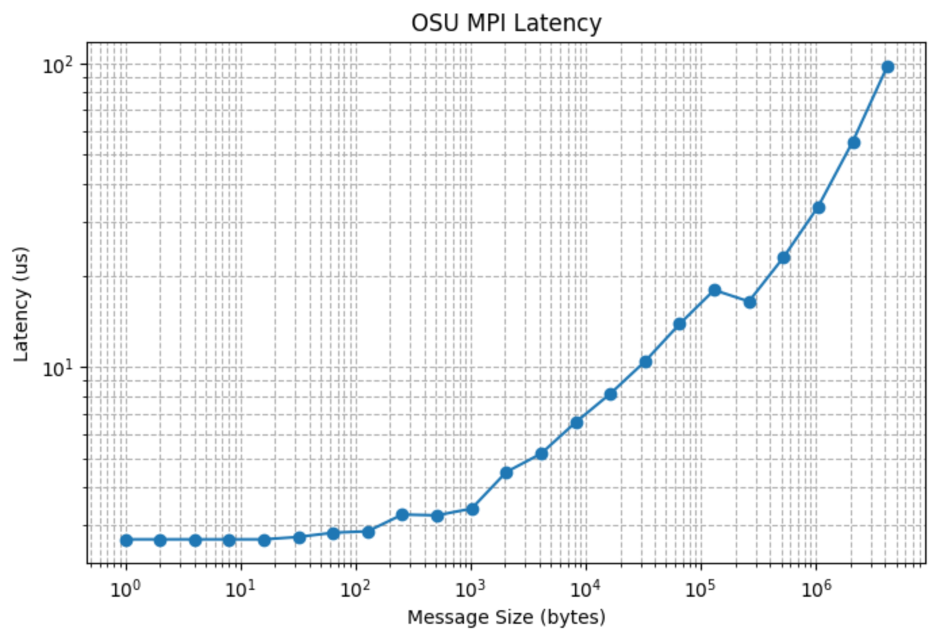
2.3. Latency and bandwidth results
Latency Table:
Size (bytes) Latency (us) 0 1 2.70 1 2 2.70 2 4 2.70 3 8 2.70 4 16 2.70 5 32 2.75 6 64 2.84 7 128 2.87 8 256 3.26 9 512 3.24 10 1024 3.41 11 2048 4.50 12 4096 5.17 ...
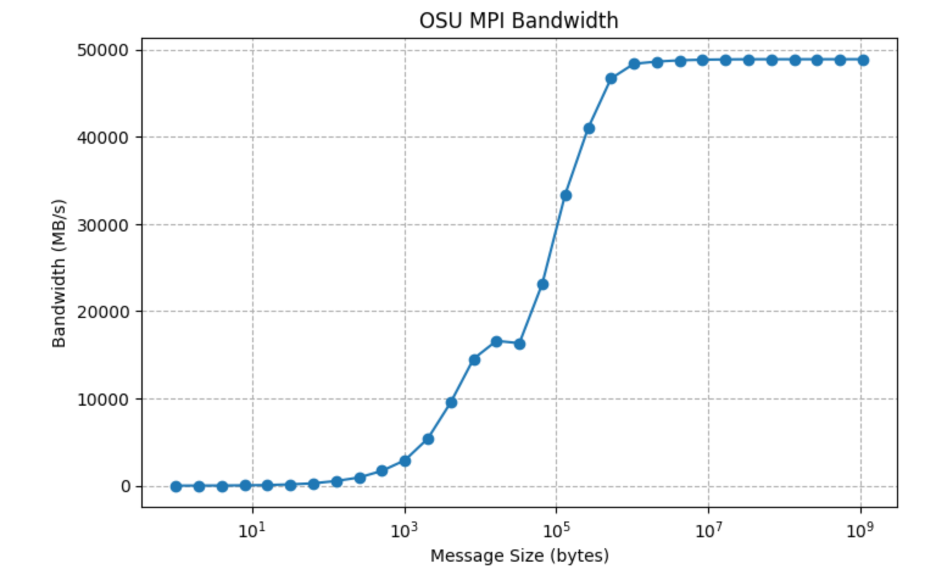
Bandwidth Table:
Size (bytes) Bandwidth (MB/s) ... 13 8192 14547.66 14 16384 16604.73 15 32768 16338.83 16 65536 23144.42 17 131072 33381.00 18 262144 40983.24 19 524288 46679.72 20 1048576 48369.05 21 2097152 48624.98 22 4194304 48768.53 23 8388608 48839.29 24 16777216 48873.73 25 33554432 48889.82 26 67108864 48892.72 27 134217728 48892.45 28 268435456 48892.20 29 536870912 48893.08 30 1073741824 48892.54
3. GPU-to-GPU across RDMA Network Test
This test forces the MPI to use device memory and test the device memory copy from one GPU to another GPU across the RDMA network.
Latency Table:
Size (bytes) Latency (us) 0 0 29.97 1 1 32.68 2 2 32.66 3 4 32.69 4 8 32.70 5 16 32.37 6 32 32.37 7 64 32.39 8 128 32.43 9 256 32.58 10 512 32.63 11 1024 32.69 12 2048 32.79 13 4096 32.77 14 8192 33.11 15 16384 33.60 16 32768 36.15 17 65536 42.50 18 131072 39.99 19 262144 47.75 20 524288 60.35
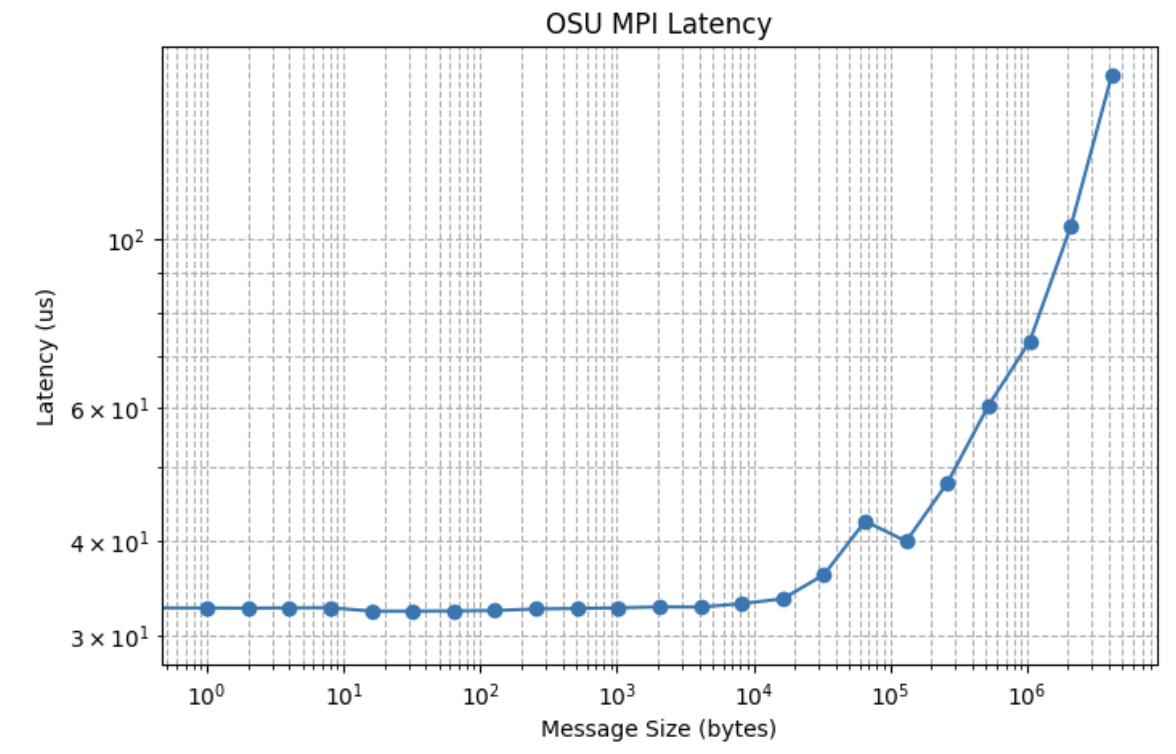
Due to GPU kernel and PCIe latency, GPU‑to‑GPU latency over RDMA is significantly higher than CPU‑to‑CPU over RDMA, as reported in “Enabling Fast Inference and Resilient Training with NCCL 2.27.” Our benchmarking data drive innovations to optimize AI workloads—through novel hardware and software pipeline optimizations—to mitigate these latency drawbacks, considering that LLM large‑scale AllReduce and LLM inferencing PD separation are sensitive to inter‑GPU memory latency.
4. NCCL Test Suites
In addition to AI workloads, collective operators with NCCL are very important as well. To test this, we use the NCCL test suites.
4.1. Compile the NCCL from source
export CUDA_HOME=/usr/local/cuda-12.8
export MPI_HOME=/usr/lib/x86_64-linux-gnu/openmpi
dpkg -l | grep nccl
git clone https://github.com/NVIDIA/nccl-tests.git
cd nccl-tests
make MPI=1 \
CUDA_HOME=${CUDA_HOME} \
MPI_HOME=${MPI_HOME} \
MPICC=$(which mpicc) \
-j all
4.2. Run NCCL All Reduce on single node with 8 GPUs
#bin/bash # this is a script to perform nccl_test echo "All Reduce Performance" ./nccl-tests/build/all_reduce_perf -b 32 -e 4G -f 2 -g 8
4.3. Run NCCL All Reduce with two nodes with 16 GPUs
#!/bin/bash
export UCX_TLS=rc,ud
# NCCL IB tuning
export NCCL_IB_GID_INDEX=3
export NCCL_IB_SL=0
export NCCL_IB_TC=41
export NCCL_IB_QPS_PER_CONNECTION=16
export HCOLL_ENABLE_MCAST_ALL=0
export NCCL_NET_GDR_LEVEL=2 # if your setup supports GPUDirect RDMA
export UCX_NET_DEVICES=mlx5_0:1,mlx5_1:1,mlx5_3:1,mlx5_4:1,mlx5_5:1,mlx5_6:1,mlx5_7:1,mlx5_8:1,mlx5_9:1,mlx5_10:1,mlx5_12:1,mlx5_13:1,mlx5_14:1,mlx5_15:1,mlx5_16:1
export NCCL_IB_HCA=mlx5_0,mlx5_1,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_7,mlx5_8,mlx5_9,mlx5_10,mlx5_12,mlx5_13,mlx5_14,mlx5_15,mlx5_16,mlx5_17
# UCX logging—silence the CUDA-copy warnings
export UCX_LOG_LEVEL=warn
mpirun -np 2 -H 10.224.8.156,10.224.9.98 --bind-to numa \
-x UCX_TLS \
-x UCX_NET_DEVICES \
-x NCCL_IB_HCA -x NCCL_IB_GID_INDEX \
-x NCCL_IB_SL -x NCCL_IB_TC -x NCCL_IB_QPS_PER_CONNECTION \
-x NCCL_NET_GDR_LEVEL \
-x HCOLL_ENABLE_MCAST_ALL \
--mca pml ucx --mca coll_hcoll_enable 0 \
./build/all_reduce_perf -b 32 -e 10G -f 2 -g 8
Result as:
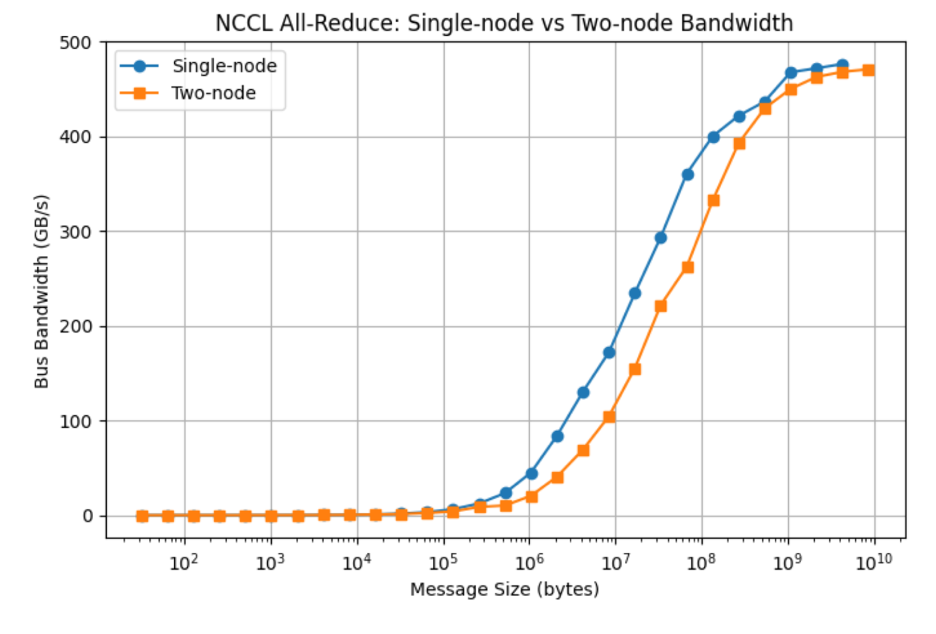
With OCI’s state-of-the-art nonblocking RDMA networking, NCCL AllReduce performance can scale without compromise.
Conclusion
Non-blocking RDMA is non-negotiable for large-scale AI, slashing latency and CPU overhead while preventing congestion. OCI leads the AI infrastructure market with RoCE-optimized networks, demonstrated scalability to over 32,000 GPUs, and ultralow latency at scale. We first explored why lossless, low-latency RDMA is critical for GPU efficiency. Then we give a detailed benchmarking setup to reach state-of-the-art performance on OCI. Our benchmarks showcase OCI’s RDMA fabric in action:
| Test | Value |
|---|---|
| Node to node CPU-to-CPU latency | 2.7 us |
| RDMA NIC bandwidth (400Gbps) | 48.77 GB/s |
| GPU to GPU Latency over RDMA networking | 29 us |
| NCCL on single node with 8 GPUs | 476.37 GB/s |
| NCCL on two nodes with 16 GPUs | 469.67 GB/s |
References
- roce-network-distributed-ai-training-at-scale
- software-defined-rdma-networks-for-large-scale-ai-infrastructure
- sigcomm24-final246
- rdma-a-deep-dive-into-remote-direct-memory-access
- networking-for-ai-workloads
- Oracle generative-ai performance
- Oracle benchmarks meta
- make-the-most-of-the-cloud-momentum-why-oci-is-winning-the-ai-workloads-game
- ai-innovators-worldwide-choose-oracle-for-ai-training-and-inferencing
- Oracle ai innovators worldwide
- Accenture-Oracle-Cloud-Performance
- gregpavlik_oracles-results-in-the-recentmlperfv41-activity
- https://tijer.org/tijer/papers/TIJER2111004.pdf
- unlocking-ai-excellence-how-modal-labs-utilizes-oci
- optimizing-ai-workloads-with-highspeed-roce-solutions
- benchmarking-oci-compute-shapes-llm-serving
- rdmabox-optimizing-rdma-for-memory-intensive-workloads
- how-rdma-is-solving-ais-scalability-problem
- test-ai-data-center-networks
- https://www.vastdata.com/blog/the-rise-of-s3-rdma
- oci-accelerates-hpc-ai-db-roce-nvidia-connectx

