※ 本記事は、Pradeep Vincent, Jag Brarによる”First Principles: Inside Zettascale OCI Superclusters for Next-gen AI“を翻訳したものです。
2025年4月28日
生成AIワークロードは、従来のクラウド・ワークロードとは異なる一連のエンジニアリングのトレードオフを促進します。そのため、オラクルは、ベスト・オブ・ブリードの生成AIワークロードのニーズに合わせて、専用の生成AIネットワークを設計しました。
Oracle CloudWorldでは、Oracle Cloud Infrastructure (OCI) スーパークラスタが利用可能になり、最大131,072のNVIDIA Blackwell GPUを搭載し、これまでにない2.4ゼタフロップのピーク・パフォーマンスを実現したとOracleが発表しました。ゼタスケール・クラスタ・ネットワークは、ポート当たり52 Pbpsの非ブロッキング・ネットワーク帯域幅を400 Gbpsで提供し、レイテンシは2μs(マイクロ秒)です。この規模により、ネットワーク帯域幅のパフォーマンスが5倍向上し、競合他社と比較して最大5倍の低ネットワーク・レイテンシを実現できます。このブログ記事では、これらの改善を支える主要なエンジニアリング・イノベーションについて考察します。
ゼタスケールのクラスタ・ネットワークは、各GPUに400Gbpsの非ブロッキング接続を備えた最大131,072GPUをサポートする3層Closトポロジです。
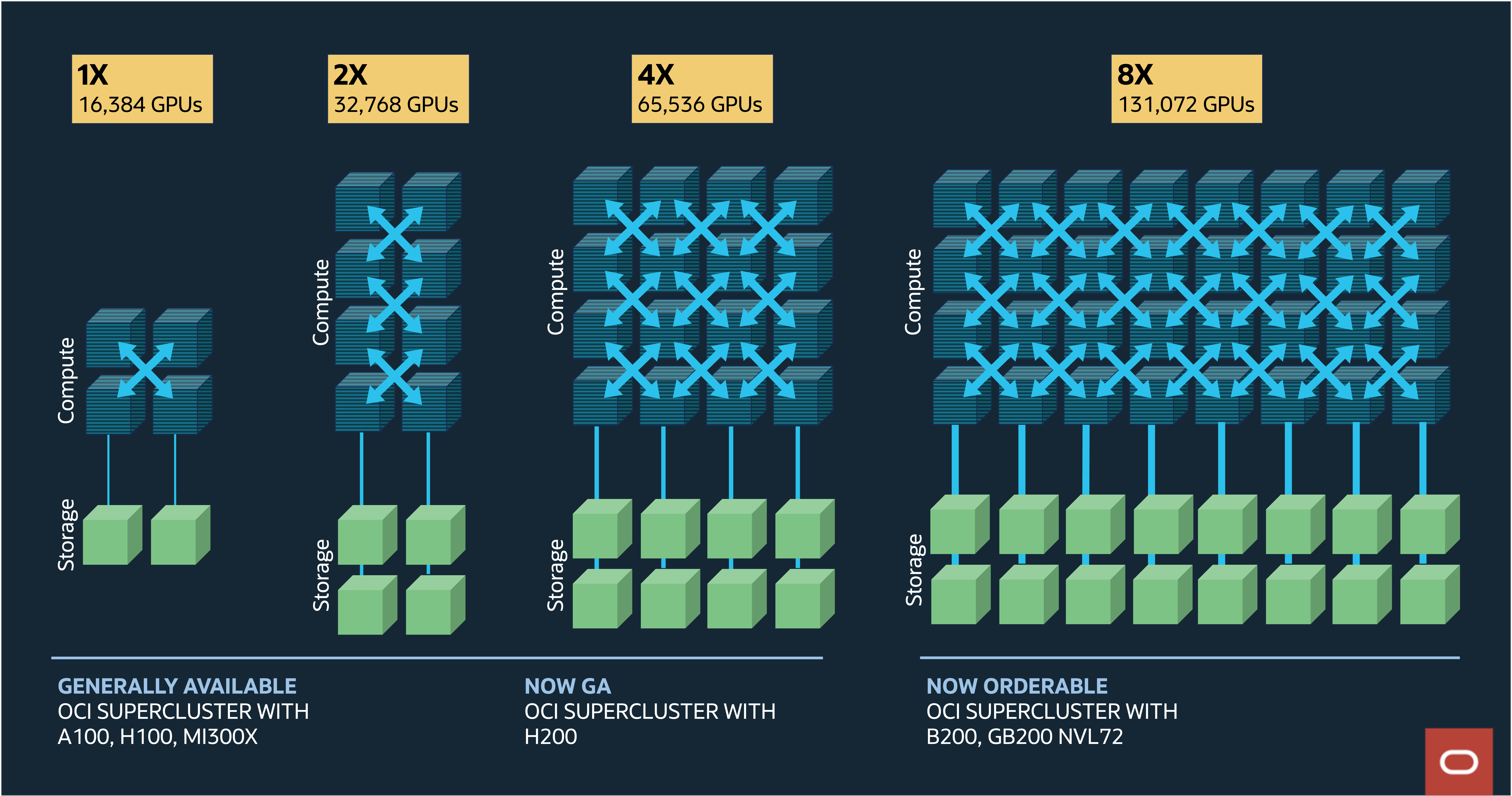
図1: 生成AI向けのOCI Supercluster製品
このネットワークは、最大のGPUクラスタをサポートしているだけでなく、低レイテンシ、高スループット、高ワークロードの回復性を維持しています。その目標を達成するためには、新しい方法で革新する必要があります。ここでは、このネットワークを可能にする次のイノベーションについて説明します:
- 超高スループットによるゼタスケールのRDMA
- 超低レイテンシ
- 高度なリンク・レジリエンスにより、ワークロードの信頼性を向上
- 高度なトラフィック・ロード・バランシング
超高スループットによるゼタスケールのRDMA
RDMAのスケーリング
以前のブログ記事では、OCIスーパークラスタが大規模な超高パフォーマンスを実現する方法について説明しました。分散システムと分散ネットワーキングの真正の原則に基づいて、ネットワークをあらゆる規模に拡張します。これらの原則の1つは、エンドポイントとネットワークのコア間の疎結合です。RDMA over Converged Ethernet (RoCE)での以前の試行は、輻輳を処理する主要なメカニズムとして優先順位フロー制御(PFC)を使用することに依存していました。PFCは、マルチテナント環境またはマルチワークロード環境では許容できないネットワーク・ブロックの問題につながることが知られています。混雑を避ける主要なメカニズムとして、PFCではなく混雑制御に依存して異なるアプローチをとりました。輻輳制御は、プロアクティブな輻輳管理メカニズムであり、クラスタネットワークのすべての層で動作します。これにより、ネットワークをブロックするリスクなく、お客様が必要とするあらゆる規模にまで拡張できるようになりました。
クラスタ・サイズが増加すると、複数のクラスタ・ワークロードを同時に使用できる柔軟性が重要になります。複数の同時ワークロードをサポートするために、生成AIや高パフォーマンス・コンピューティング・メッセージ・パス・インタフェース(HPC-MPI)などのワークロードの各クラスが独自のニーズにあわせて独自のクラスとサービス品質を取得するネットワーク内の複数のトラフィック・クラスを有効にします。
超高スループットおよび超低レイテンシ
生成AIワークロードは、ネットワークが提供できるすべての帯域幅を使用できます。オラクルの目標は、実際のワークロードを使用して、可能なかぎり低いレイテンシでラインレートのスループットを実現することです。実際のシナリオでは、非ブロッキングネットワークの場合でも、フロー衝突および結果として生じる輻輳からのリンクレベルの輻輳が局在しているため、観測されるネットワーク帯域幅が低くなる可能性があります。
オラクルは、次の革新的な手法を使用して、実際のAIワークロードに対応するライン・レート・スループットを提供してきました:
- インテリジェントなGPU配置: OCIコントロール・プレーンは、可能な限り近い顧客クラスタにGPUを配置しようとします。この短い距離は、ネットワーク近傍性を提供することで、同時にネットワーク待機時間を短縮し、スループットを自動的に改善するのに役立ちます。ネットワーク・トラフィックが多くなると、ネットワークの低レベルまでローカルに保持されるため、ネットワークの高レベルでのフロー衝突の可能性が低くなります。
- ネットワーク近傍性サービス: OCIには、ネットワーク・トポロジ情報をすべてのGPUにアドバタイズするサービスがあり、GPUが他のすべてのGPUに対してどの程度密接に配置されているかを特定するのに役立ちます。この情報により、GenAIスケジューラでジョブをスケジュールできるため、帯域幅の負荷が高く、遅延の影響を受けやすいジョブがネットワークの下位レベルにとどまります。
- 高度なトラフィック・ロード・バランシング技術: 業界パートナーと複数の新しいトラフィック・ロード・バランシング技術を先駆けて、「拡張トラフィック・ロード・バランシング」の項で説明します。これらのロード・バランシング技術は、輻輳の可能性を減らし、ネットワーク内のキューの深さを減らすことで、レイテンシを減らし、スループットを向上させます。
ネットワークは、131,072個のNVIDIA Blackwell GPUすべてについて、400Gで52Pbpsのラインレート・スループットの総容量を持っています。
超低レイテンシの実現
次の図に、OCIクラスタ・ネットワークのネットワーク・トポロジを示します。この3層Closネットワークでは、スイッチの第1層は最大256のNVIDIA GPUを提供し、最大2μs(マイクロ秒)の単方向レイテンシを実現します。2層のスイッチは、最大5μs のレイテンシで最大2048個のNVIDIA GPUに対応しています。第3層のスイッチは、最大8μsのレイテンシで最大131,072個のNVIDIA GPUに対応しています。
図2: OCI Cluster Network Fabric
ネットワークパケットを転送する場合、2マイクロ秒は大した時間ではありません。また、パケットを処理するすべてのハードウェアおよびファームウェア・コンポーネントは、待機時間を最小限に抑えるように設計および構成する必要があります。次の回路図は、ネットワーク・インタフェース・カード(NIC)のレイテンシ、スイッチのレイテンシ、トランシーバのレイテンシ、およびライト・レイテンシの速度で構成されるネットワーク・レイテンシの内訳を示しています。スイッチASICの待機時間予算はマイクロ秒未満で、通常は約90ナノ秒です。スイッチASICは、次の主要な機能を実行します:
- パケットの検証
- パケット宛先アドレスに対する参照を実行して、送信するエグレス・ポートを決定
- 宛先MAC (Layer-2)アドレスを次のホップのアドレスに書き換え
- 必要に応じて、パケットを一時キューに配置
- パケットの優先順位を確認および尊重して、適切なサービス・グレードを提供
- パケットを輻輳信号にマーキングし、選択したエグレスポートからパケットを転送するための輻輳
図3: コンポーネント間のレイテンシ
軽量レイテンシの速度は固定されています。光ファイバで、光信号が1キロメートル進むのに5μsかかり、これは1メートル当たり5ナノ秒です。レイテンシを最小限に抑えることを目的として、ネットワーク・リンクの最大許容ケーブル距離を指定し、ケーブル距離仕様に準拠するようにデータ・センター・レイアウトを設計します。たとえば、GPUとファーストホップ・スイッチ(Tier-0スイッチ)間のケーブル距離を最大40 mに制限します。
NIC、スイッチ、およびトランシーバの待機時間は、待機時間を最小限に抑えるように設計されており、シリコン・ロジックは、ネットワーク待機時間を最小限に抑えるためにパケットを排他的に処理します。動的ランダムアクセス・メモリ(DRAM)と高帯域幅(メモリ)HBMルックアップは高価であり、私たちの目標は、このようなメモリ・アクセスをパケット処理パスから排除することです。NICおよびスイッチ・シリコンがパケットを処理するために必要なルーティングおよびスイッチング構成が、SRAMやTCAMなどの非常に低レイテンシのメモリ・コンポーネントで常に使用可能であることを保証します。
ワークロードの信頼性を強化するための高度なリンク・レジリエンス
AIおよび機械学習(ML)ワークロードのパフォーマンスは、ネットワークの中断に非常に敏感です。ネットワークの中断が小さいと、ワークロードのパフォーマンスに大きく影響する可能性があります。基礎となるRDMAトランスポートはパケットの損失にも敏感で、少量のパケットのドロップによって多くのパケットが再送信される可能性があります。最後に、数千のスイッチと数万の光トランシーバを備えたこれらのワークロードの規模は、コンポーネント障害の確率が一般的なコンピューティング・ワークロードのそれよりも高いことを意味します。
オラクルは、次の機能を使用して、顧客ワークロードの自己回復性を強化しました:
- 一時的なリンク中断の軽減を目的とした、カスタマイズされたスイッチおよびNIC構成。
- ネットワーク・リンク統計を収集および分析し、差し迫った障害を予測するための高度な監視および自動化システム。
- 自動化システムは、リピート違反リンクを検出し、それらのリンクからトラフィックを移動し、修復活動を開始することで、人間がネットワーク・ダッシュボードを経由する必要なく、自動的に修復します。
- GPUがホストするOCIクラウド・エージェントは、ホスト側のリンクや環境の異常を探し、差し迫った障害を予測します。
リンク・フラップと呼ばれる障害ベクトルの1つについて詳しく見てみましょう。
リンク・フラップの定義
リンク・フラップは、リンクの状態のアップとダウンの間の遷移によって特徴付けられ、多くの場合、短い時間ウィンドウ内で修正不可能な一連のビット・エラーによってトリガーされます。たとえば、400Gイーサネット・リンクがあるとします。400G IEEE仕様では、これらのリンクに対するフォワード・エラー修正(FEC)保護が提供されており、5,140ビットの連続するFECコード・ブロックがそれぞれ1つの修正不可能なビット・エラーを持つことが許可されています。イーサネット・フレームに埋め込まれたFECコードがビットエラーを修正できないと、修正不可能なビットエラーが発生します。FECは、FECコード・ブロックで最大15ビット・エラーを修正できます。最悪の場合、修正不可能なビットエラーが20 ns (ナノ秒)のスパンに3つあり、最終的にリンクダウン・イベントが発生する可能性があります。
そのようなリンクの光学層はミリ秒以内に回復しますが、そのようなイベントに関する実際の問題は、たとえそれが逃れるとしても、これらのリンクに複数の論理レイヤーが埋め込まれているため、10-15秒間長引くイベントになることです。これらのレイヤーには、物理中依存(PMD)、物理中アタッチメント(PMA)、FEC、物理コーディング・サブレイヤー(PCS)、メディア・アクセス制御(MAC)、データリンクおよびIPレイヤーが含まれます。これらの各レイヤーには、独自の独立したリンク・トレーニング、安定化および自己回復性アルゴリズムがあり、リンクの起動に時間がかかります。
次の図は、オープン・システム相互接続に関連するこれらのレイヤーを示しています。
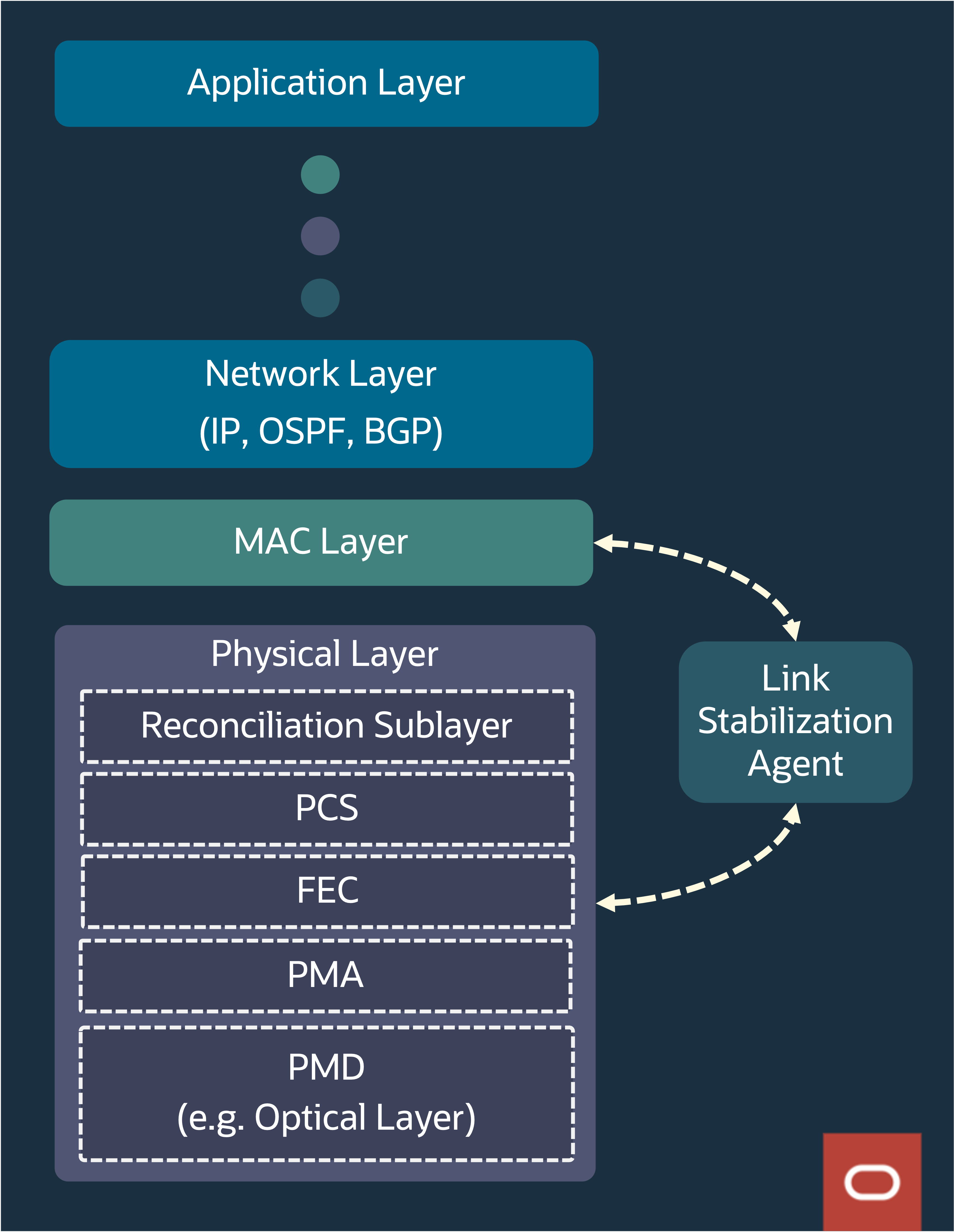
図4:OSIプロトコル・スタック
各リンク・フラップは、境界ゲートウェイ・プロトコル(BGP)やオープン最短パス・ファースト(OSPF)など、IPルーティング・プロトコルのネットワーク全体の収束イベントをトリガーします。実際、2つのイベントが発生します。1つはリンク・ダウン用、もう1つはリンク・アップ用です。ネットワーク再収束イベント自体は、一時的なマイクロループなど、独自の2番目の順序効果を持つことができます。
リンク・フラップによってワークロードが遅くなり、GPUトレーニング・シーケンスが中断される可能性もあり、ワークロードからホストをイジェクトする必要があります。つまり、リンク・フラップはGPUワークロードに大きな影響を与え、トレーニング時間を増やすことができます。リンク・フラップはコストのかかるイベントであり、リンク・フラップを防止または最小化したいと考えています。
リンク・フラップの原因
リンク・フラップは、次のような様々な理由で発生する可能性があります:
- レーザー、ファイバ・カップリング、デジタル信号プロセッサ(DSP)などのトランシーバおよびサブコンポーネントの欠陥により、信号が低下したり、信号が失われたりします。
- ファイバやコネクタの配備衛生が悪いと、ファイバ上のほこりなどの光信号が低下する可能性があります。
- 周囲動作条件の熱変動と突然の変化
- 損傷を受けやすいコンポーネントの静電放電(ESD)損傷
- アセンブリおよび製造上の欠陥
- デバイス上のソフトウェアまたはファームウェアの問題
リンク・フラップ・イベントの大部分は、特定の修復アクションを要求しない一時的なイベントによって発生することが観察されています。
リンク・フラップの軽減
PMD層の光信号を一時的に中断すると、長いリンク・フラップ・イベントが発生する可能性があります。失敗すると予想されるリンクを予測するオートメーション・システムがあり、また、リピート違反リンクを検出して修復するオートメーション・システムもあります。それでも、一部のリンクが繰返しなしのベースでフラップする確率はゼロ以外になります。このようなワンタイム犯罪者の影響を最小限に抑えたいので、リンク・デバウンスを展開します。
リンク・デバウンスは、光学信号(NICまたはスイッチ上のPMA層)の一時的な中断および1回限りの中断が発生した場合、上層(MACまたはIP層)をダウンさせず、短時間の過渡的なイベントを長時間の停止に巻き込むことを避ける手法です。さらに、リンク・デバウンスでは、IPルーティング・プロトコル・コンバージェンス・イベントも回避できます。
拡張トラフィック・ロード・バランシング
ネットワーク内のスループットの問題は、トラフィックの輻輳を引き起こす非効率的なトラフィック・ロード・バランシング、パス上のフローのオーバーパック、および均等コスト・マルチパス(ECMP)フローの衝突の一般的な結果です。ECMPはパケット・ロード・バランシング技術であり、スイッチは、フローのすべてのパケットを特定のパスに保持しながら、使用可能な並列パス上に複数のフローを分散します。トラフィック輻輳は、オーバーサブスクライブされていないネットワークでも発生する可能性があります。スイッチは、個々のフローの帯域幅要件や、ワークロードから予想されるフローの混在を認識しません。つまり、スイッチはサポートしているワークロードのフロー構成を認識しません。
集合体対応のロード・バランシング
オラクルは、トラフィックの混雑を大幅に削減できる複数の高度なトラフィック・ロード・バランシング技術を先駆けてきました。これらの技術の1つとして、スイッチ・ベンダーの1社と協力しました。この手法は、AIおよびMLの集合体を認識し、その知識を使用してMLフローをパスにマップしながら、パス上のオーバーパック・フローを回避することに依存します。
Collectives-awareロード・バランシングは革新的なトラフィック・ロード・バランシング技術であり、スイッチはML集合体に関する知識を使用して、使用可能なパス上のトラフィック・フローのマッピングを最適化します。この高度なロード・バランシング手法は、輻輳の可能性を低減することで同時にレイテンシを低減し、スループットを向上させます。
次の図は、集合を認識するロード・バランシングを示しています:
図5: ECMPベースのフローと輻輳 vs 集合認識フロー
左側の回路図は、標準のECMPロード・バランシングを示しています。このロード・バランシングでは、スイッチがMLの集合体を認識せず、赤と青のフローが混在し、流れの衝突や輻輳につながります。右側の回路図は、集合認識のロード・バランシングを示しています。このロード・バランシングでは、スイッチがML集合体を認識し、赤と青のフローの混合を回避して、フローの衝突を回避します。
まとめ
Oracle Cloud Infrastructureは、ゼタスケールのクラスタ・ネットワークを使用して、生成AIおよびディープ・ラーニング・ワークロードのネットワーク・スケーラビリティとパフォーマンスを再定義します。超高スループットのRDMA、超低レイテンシ、強化されたネットワーク・レジリエンス、インテリジェントなトラフィック・ロード・バランシングにより、次世代のAIモデルと大規模なトレーニングに必要なインフラストラクチャを実現します。
Oracle Cloud Infrastructure Engineeringは、エンタープライズ顧客のために最も要求の厳しいワークロードを処理しており、クラウド・プラットフォームの設計について異なった考え方をすることを迫られています。Pradeep Vincentや他のOracleの経験豊富なエンジニアが主催するこのFirst Principlesシリーズの一部として、これらのエンジニアリング・ディープ・ダイブがさらに多くあります。
詳細は、次のリソースを参照してください:
2. Oracle Delivers Sovereign AI Anywhere Using NVIDIA Accelerated Computing
3. NVIDIA GPU Device Plugin Add-On for OKE 提供開始の発表
