※ 本記事は、Mark Hornickによる”Data Science Agent: Native Conversational Analytics and Machine Learning in Autonomous AI Database“を翻訳したものです。
2026年4月24日
Oracle Data Science Agentは、Oracle Autonomous AI Databaseにおける新しいOracle Machine Learning (OML)機能であり、データ・サイエンスのライフサイクル全体にわたって、最新のチャットベースの体験を提供します。すべての処理はデータベース内で完結します。この機能は、あらゆるスキル・レベルのユーザーに対して分析や機械学習のハードルを下げるとともに、繰り返し可能な作業を自動化することで専門家のワークフローを加速し、さらにデータベース内で完全に動作することでガバナンスも維持します。ビジネス・アナリスト、データ・サイエンティスト、アプリケーション開発者のいずれにとっても、このエージェントはデータが存在する場所で直接、安全かつ説明可能で効率的にデータを扱う手段を提供します。
要するに、Data Science Agentは、データを移動することなく、データのプロファイリング、特徴量エンジニアリング、モデル構築を行うための、対話型でガバナンスが効き、高性能な手段です。
Data Science Agentの詳細
Data Science Agentは、Oracle Autonomous AI Databaseに組み込まれた対話型アシスタントであり、エンドツーエンドのデータ・サイエンス・ワークフローをガイドし、実行します。ユーザーはチャット形式のインタフェースを通じて操作し、内部ではPL/SQLパッケージが処理を担います。すべてがデータベース内で実行されるため、チームは高いパフォーマンス、強固なセキュリティ、そして運用のシンプルさの恩恵を受けます。エージェントの機能は、データ・エンジニアリングからモデリングまで幅広くカバーしています。データセットのプロファイリング、データの整形、相関関係の計算、特徴量選択や特徴量エンジニアリングを行うことができます。また、モデルのトレーニング、評価、比較、推論にも対応しており、学習や意思決定を支援するために指標や結果を分かりやすく説明します。
このエージェントは完全にインタラクティブな対話をサポートしており、ユーザーの要望に応じて、より自律的に動作させることも可能です。たとえば、最初はガイド付きの手順から始め、補足質問をしたり説明を確認したりした後、ワークフローに自信が持てるようになれば処理を委任する実行モードへ移行できます。あるいは、「必要なすべての手順をエンドツーエンドで実行し、最終結果を提示してください」と指示することも可能です。
さらに、トレーサビリティとガバナンスも組み込まれており、ログや永続的な会話履歴によって、チーム間および時間をまたいだ再現性が確保されます。このエージェントは効率性とコスト意識を重視して最適化されており、不必要なトークン使用や計算を最小限に抑えます。セキュリティは設計の中核にあり、ユーザーは自身のデータベース権限およびOracleのガバナンス・モデルの範囲内でのみ操作できます。さらに、エージェントがアクセスできるデータベース・オブジェクトや実行可能な操作を制限し、作業の焦点を保つために、「Conversation Objects Catalog」を通じて対象範囲を指定できます。一方で、どのオブジェクトを使用すべきか分からない場合には、「自分のデータベースにある銀行マーケティングキャンペーンに関するデータは何ですか?」といったプロンプトで、エージェントにデータベース内を探索させることもできます。
内部的には、オーケストレーションはSelect AI Agentフレームワークと統合されており、Oracle Open Agent Specificationを通じてプラグ可能な設計になっています。プロファイリングやトレーニングなど特定のタスクを実行するモジュール型ツール、ドメイン知識を組み込んだ厳選プロンプト・ライブラリ、信頼性の高いUI表示に向けて出力を構造化するレスポンス・スキーマ、そしてSelect AIによって実現されるSQL生成などが連携して動作します。大規模な機械学習モデルのトレーニングといった負荷の高い処理は非同期で実行できるため、その完了を待つ間も他の作業を継続することが可能です。
なぜこれが重要なのか
組織はしばしば、分断したツールの連携、習得の難しさ、そして繰り返し発生するセットアップ作業のために、データ・サイエンス・プロジェクトの価値創出までの時間を短縮することに苦労しています。システム間でデータを移動させることは、リスクやコスト、コンプライアンス上の負担を増大させる一方で、不透明な「ブラック・ボックス」型の自動化は信頼性や再現性を損なう可能性があります。Oracleは、Data Science AgentをOracle Autonomous AI Database内でネイティブに動作させ、データベース内機械学習機能を活用することで、これらの課題解決を支援します。このエージェントはローカル・データにアクセスできるだけでなく、DBLINKを通じてマルチクラウドやOracle以外のデータベースを含むリモート・ソースにもアクセス可能であり、データをガバナンスされた環境の外に移動することなく分析できます。また、ユーザーが望むインタラクション・レベルに適応し、ステップバイステップの対話型ガイダンスのレベルから完全に委任された実行を伴うレベルまで対応します。さらに、エージェントのアクションログを確認できるほか、会話履歴が保持されるため、継続性、再現性、監査対応が可能になります。
今すぐできること
Data Science Agentを使用することで、データ作業の中でも特に時間のかかる部分を効率化できます。まずはデータセットのプロファイリングから始め、完全性、分布、外れ値を評価し、その後データの整形、相関関係の計算、特徴量選択および特徴量エンジニアリングを行います。続いてシームレスにモデリングへ移行し、モデルのトレーニング、評価、比較、推論の実行、さらにパフォーマンス指標や結果についての明確で文脈に沿った説明を得ることができます。時間のかかるタスクについてはバックグラウンドで実行をスケジュールし、その間も作業を継続できます。エージェントは長時間実行されるジョブを管理し、セッションをブロックすることはありません。
この対話型体験は、やり取りの中でコンテキストを維持するため、これまでのステップを自然に引き継ぐことができます。たとえば、直前にプロファイリングしたデータセットをフィルタリングするようData Science Agentに依頼したり、前のやり取りで準備したトレーニング・データセットを使ってマイニング・モデルを構築するよう指示したりできます。「Conversation Objects Catalog」を使って関連する表、ビュー、マイニング・モデルを登録することで、作業範囲を明確にし、精度と効率を向上させることができます。また、会話履歴を活用して作業を保存・再開することで、プロジェクトを並行して進めたり、監査可能な履歴を維持したりすることも可能です。これらの機能は、具体的な成果につながります。すなわち、プロファイリング、特徴量エンジニアリング、モデリングといった一般的なタスクの完了までの時間短縮、手動介入なしで完了するタスクの割合の向上、使いやすさ・透明性・学習支援に関するユーザー満足度の向上、そして時間の経過とともにユーザーの自律性と知識定着が向上していることを示すエビデンスの獲得です。
はじめ方と次のステップ
Data Science Agentは、まもなくOracle Autonomous AI Database Serverless 26aiで利用可能となり、すべてのリージョンでサポートされる予定です。利用を開始するには、Oracle Machine Learningが有効化されたOracle Autonomous AI Databaseに加え、LLMの認証情報と、Select AIのDBMS_CLOUD_AIパッケージで構成したAIプロファイルが必要です。また、ユーザーの役割と権限に基づき、関連するスキーマやオブジェクトへのアクセス権も必要となります。
次に、以下の手順を実行します:
- AIプロファイルでLLM設定を定義し、DBMS_CLOUDを使用してAccess Managementに認証情報を保存します。
- Oracle Machine LearningのUIコンソールからData Science Agentを起動します (「Data Science Agent」ボタンをクリックするか、メニューから選択します)。
- 使用予定の表、ビュー、モデルをConversation Objects Catalogに登録するか、エージェントに関連性の高いデータを特定するよう依頼して、対話を開始します。
- エージェントに対して、どの程度の対話的ガイダンスまたは自律性を求めるかを指示します。
エージェントを活用する際には、次のベスト・プラクティスを考慮してください:
- まずは対話的に進めて前提条件を検証し、プロンプトを洗練させたうえで、繰り返し可能なステップは自律モードに任せ反復を高速化します。
- 精度と効率を高めるために、Conversation Objects Catalogの対象範囲を適切に絞り込みます。
- エージェントのコンテキストをリセットするには、新しい会話を開始し最新のリクエストに集中させます。
- ログ、SQLスニペット、実行詳細を定期的に確認し、透明性の確保、再現可能なワークフローの共有、監査対応を支援します。
- 会話履歴を活用してプロジェクトを再開したり、チームメンバーのオンボーディングや分析判断の記録に役立てたりします。
Select AIと同様に、さまざまなAIプロバイダーやLLMから選択することができます。Data Science Agentは、データベース内での分類および回帰アルゴリズムをサポートしており、XGBoost (26aiで利用可能)、サポート・ベクター・マシン、一般化線形モデルなどに対応しています。
たとえば、次のようなプロンプトから開始できます。「定期預金キャンペーン期間を開始します。顧客、過去のマーケティング施策、および潜在的な見込み客に関して、カタログ全体から関連データを見つけるのを手伝ってください。」
これに対して、利用可能なテーブルの詳細や、それらのデータをどのように活用できるかについての提案が返されるでしょう (図1参照)。
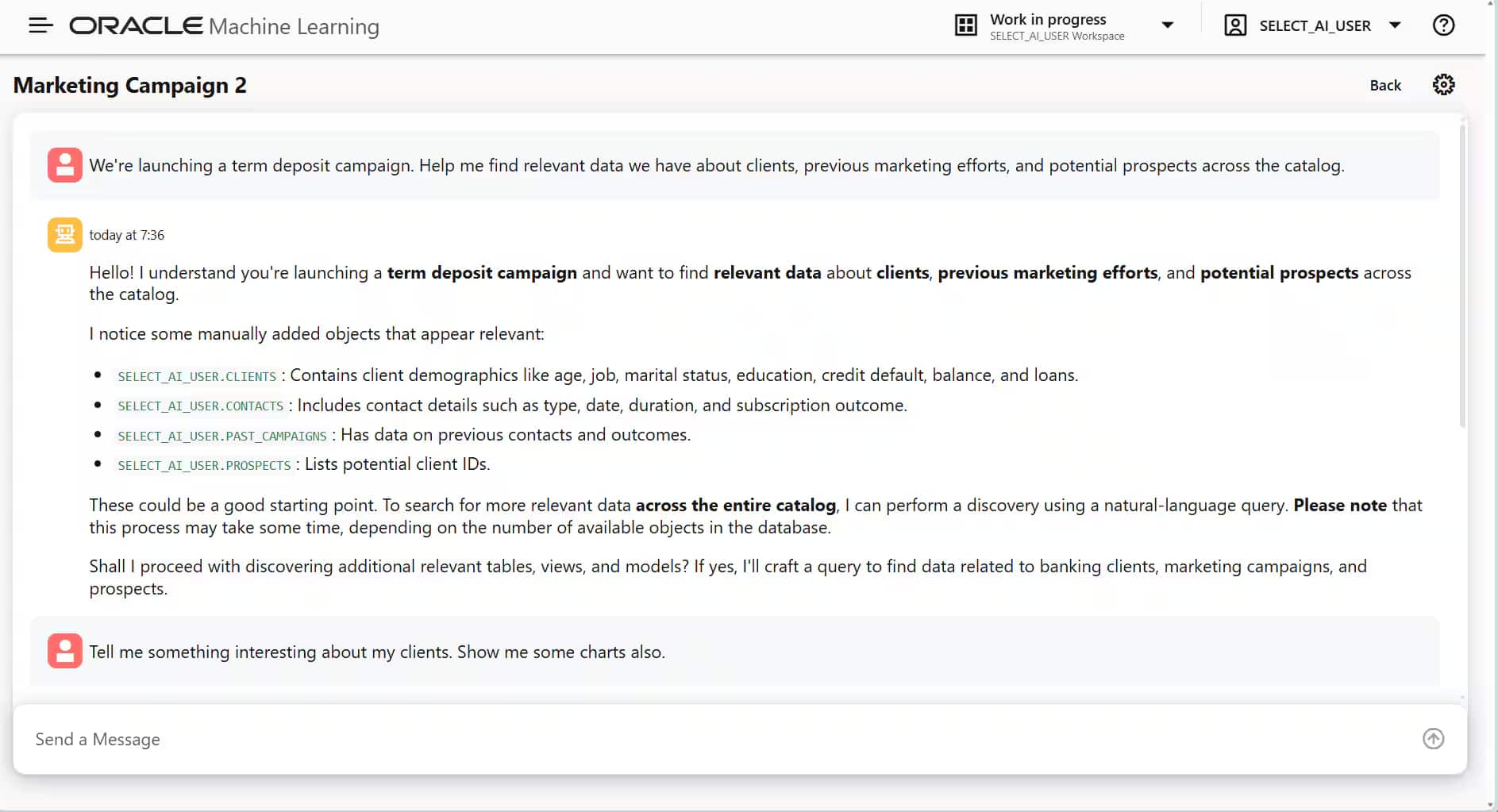
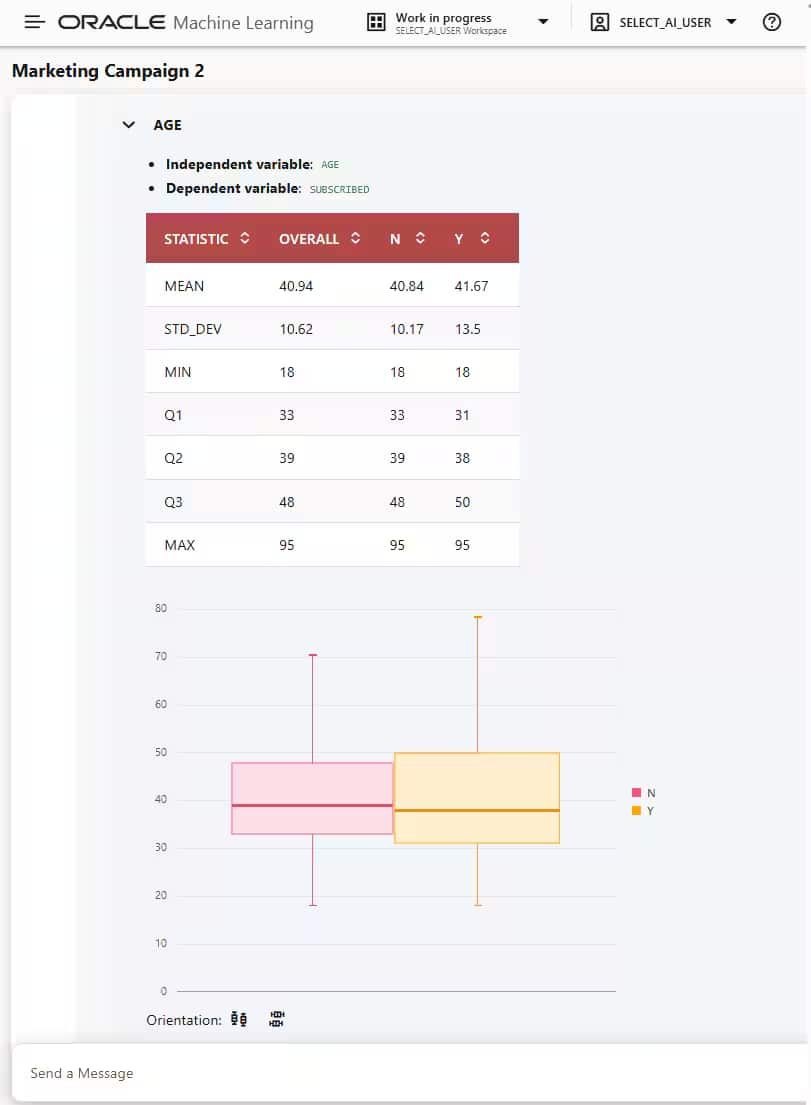
図2のように、組み込みの可視化機能を通じてデータに関する洞察を得ることができます。
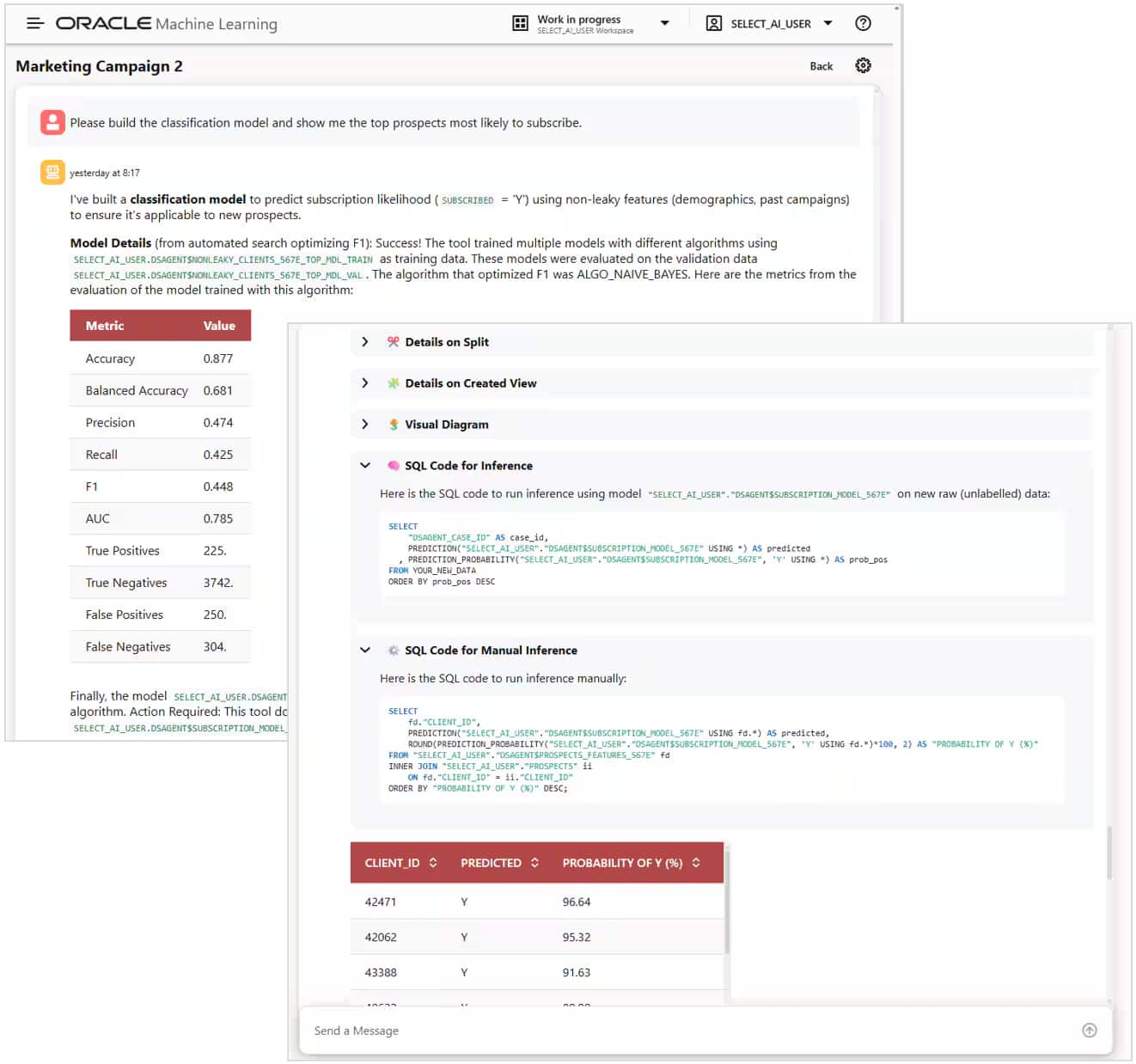
その後、分類モデルの構築と、例えばサブスクライブ(購読)する可能性が最も高い有望顧客 (プロスペクト)の上位を表示するよう依頼します。Data Science Agentは、データベース内でモデルを構築するだけでなく、図3に示されているように、精度 (accuracy)や混同行列 (confusion matrix)といった評価指標も表示します。さらに、推論に使用できるSQLの例や、購読確率の高い順に並べられた顧客IDの一覧などを提示して、リクエストを完了します。
ぜひお試しください…
Data Science Agentは、Oracle Autonomous AI Database 26aiインスタンスにネイティブに組み込まれた機能であり、サードパーティのAIプロバイダー、OCI GenAI Service、あるいは自社でホストするLLMなど、任意のLLMを利用できます。
- Autonomous AI DatabaseでData Science Agentを無料で試す
- Oracle Machine Learning ドキュメント
- Data Science Agent ドキュメント
- Select AI ドキュメント
- Select AI Agent ドキュメント
