※ 本記事は、Egor Pushkin, Jia Chenによる”Behind the Scenes: Using OCI Generative AI Agents to improve contextual accuracy“を翻訳したものです。
2024年7月19日
チャットボットに質問をして、問題を解決しない返答が返ってきたことはないでしょうか? 不安ですよね。それが、私たちが取り組んでいる課題です!
生成AI分野、特に大規模言語モデル(LLM)とその無限の可能性における継続的な急速な進歩は、印象的なものでした。Oracle Cloud Infrastructure(OCI)では、エンタープライズ・アプリケーションを構築し、生成AIテクノロジを使用して実際のビジネス上の問題を解決します。オラクルの目標は、状況に即した正確で関連性の高い情報を顧客に提供して、より的確な意思決定を促進することです。
以前のブログ投稿「Generative AI Serviceの深さを探る」で、生成AIのファイン・チューニングが精度を向上させ、少ない労力(数か月から数週間)でAIソリューションをカスタマイズするのにどのように役立つかについて説明しました。ファインチューニングを使用すると、LLMの動作を改善して、独自データに基づいて特定のタスクを処理できます。
私たちは、ファイン・チューニングは役に立つが、有名なLLMのハルシネーション問題は解決しないことを知っています。LLMは、正確な事実または後で検索するような客観的なデータを格納するようには設計されていません。LLMは、非常に大規模ではあるが、過去の一時点の限られたデータ・セットでトレーニングされます。現在のデータやプライベート・データを使用してトレーニングされるわけではありません。
では、どのようにしてLLMを使用して、より信頼性の高い正確な回答を作成できるのでしょうか。Retrieval-Augmented Generation (RAG)は、LLMのパワーと、モデルがこれまで参照したことのない、最新の独自データを活用するナレッジ・ベースを組み合せたものです。したがって、LLMはナレッジ・ベースから取得された事実を使用して、より正確な回答を生成できます。
技術が大規模なAIアプリケーションの構築において、10年以上にわたる経験がある技術リーダーとして、私たちはRAGのようなアプローチを業務に適用することがよくあります。脳は長年の学習と経験によって訓練されています。新しい問題を扱う際には、脳はさまざまな情報源(文書や人)から情報を取得し、蓄積された専門知識と最近の学習の両方に基づいて、技術設計と実行計画を生成します。
このブログ記事では、Generative AI Agentサービスを使用したRAGソリューションの構築について詳しく説明します。お客様は、既存のナレッジ・ベースを統合し、特定のドメインに対応したチャット・アプリケーションを作成できます。
RAGとは?
開発者およびビルダーとして、私たちは最新のAIの進歩を具体的な顧客のユース・ケースに適用することに全力で取り組んでいます。企業が重視する最も有望な初期領域の1つは、チャットボットを使用して、企業の製品やサービスに関する質問がある顧客とやり取りすることです。
現在のLLMには強力な言語機能と推論機能がありますが、効果を発揮するには、よりコンテキストに即した理解が必要です。RAGを使用したAIアシスタントにより、自社のプライベート・データを活用し、ユースケースに合わせたアシスタントを構築できます。プライベートのナレッジストアを利用することで、AIアシスタントのアウトプットは、LLMをそのまま利用するよりも、より最新で、文脈に即した、正確なものになります。 これは、顧客のエクスペリエンスを豊かにし、より良い結果を促進するのに役立つだちます。

図1: RAGの概要
OCIでのRAGのユースケースの例を見てみましょう。
OCIサポートのユース・ケース
OCIでは、AIベースのOracle Support Digital Assistantを発表しました。これは、テクニカル・サポートの問題に対処するために、顧客は、人と行うような会話ができます。これにより、ユーザーが探しているものをより早く見つけ、複数のドキュメントを顧客に関連する簡素化された回答に要約します。そのため、チケットを作成して処理する必要性を減らすのに役立ちます。
次のスクリーンショットでは、Support Digital Assistantが次のようなユーザーリクエストを受け取っています: 「私のコンピュートVMはアクセスできません。どうすればトラブルシューティングできますか?” そして、デジタル・アシスタントは、顧客が従うべき手順のリストを提供します。
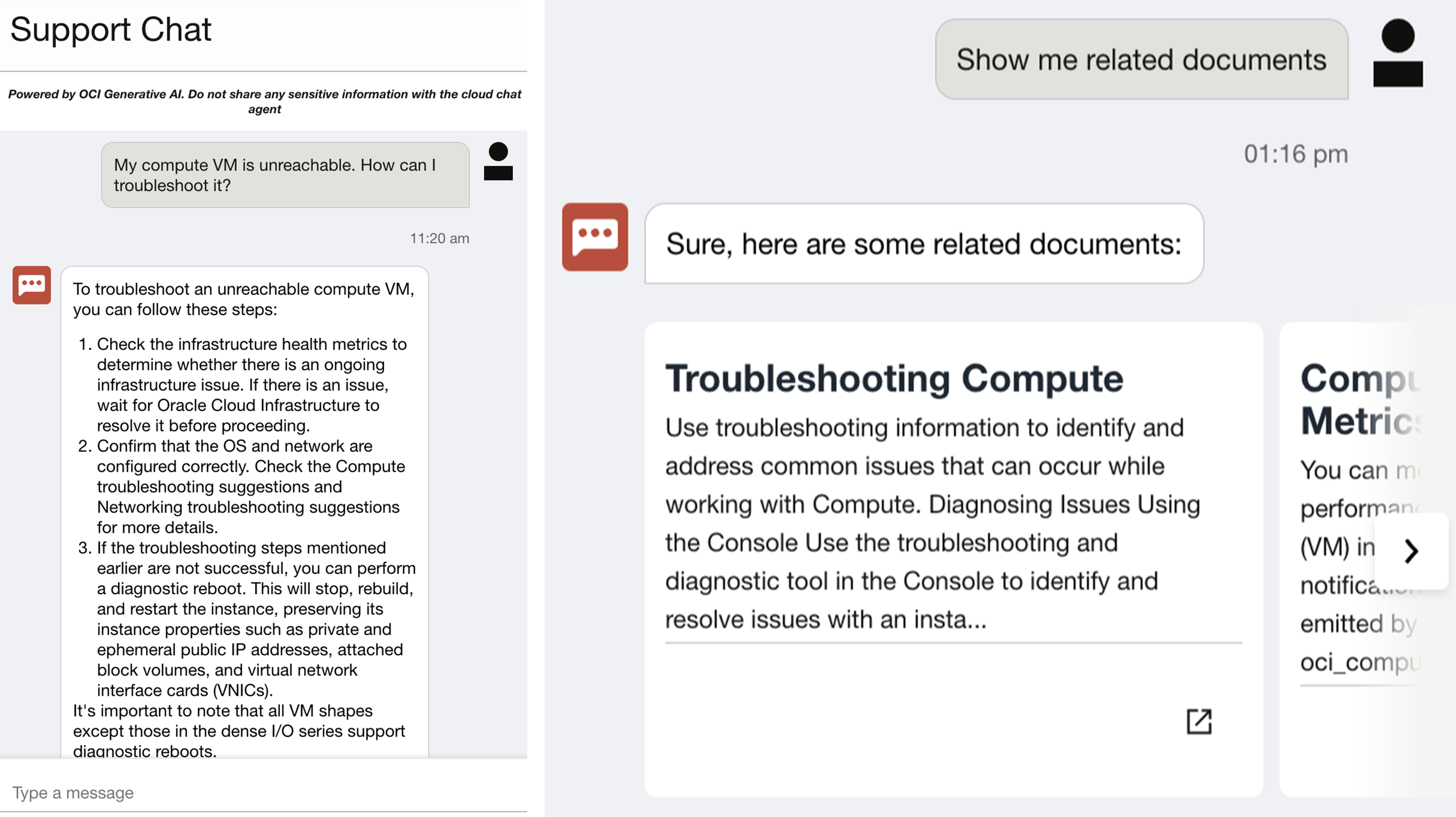
図2: OCIサポートのユース・ケース例チャット・インタフェース
関連文書は、顧客が調査するためにリンクされています。
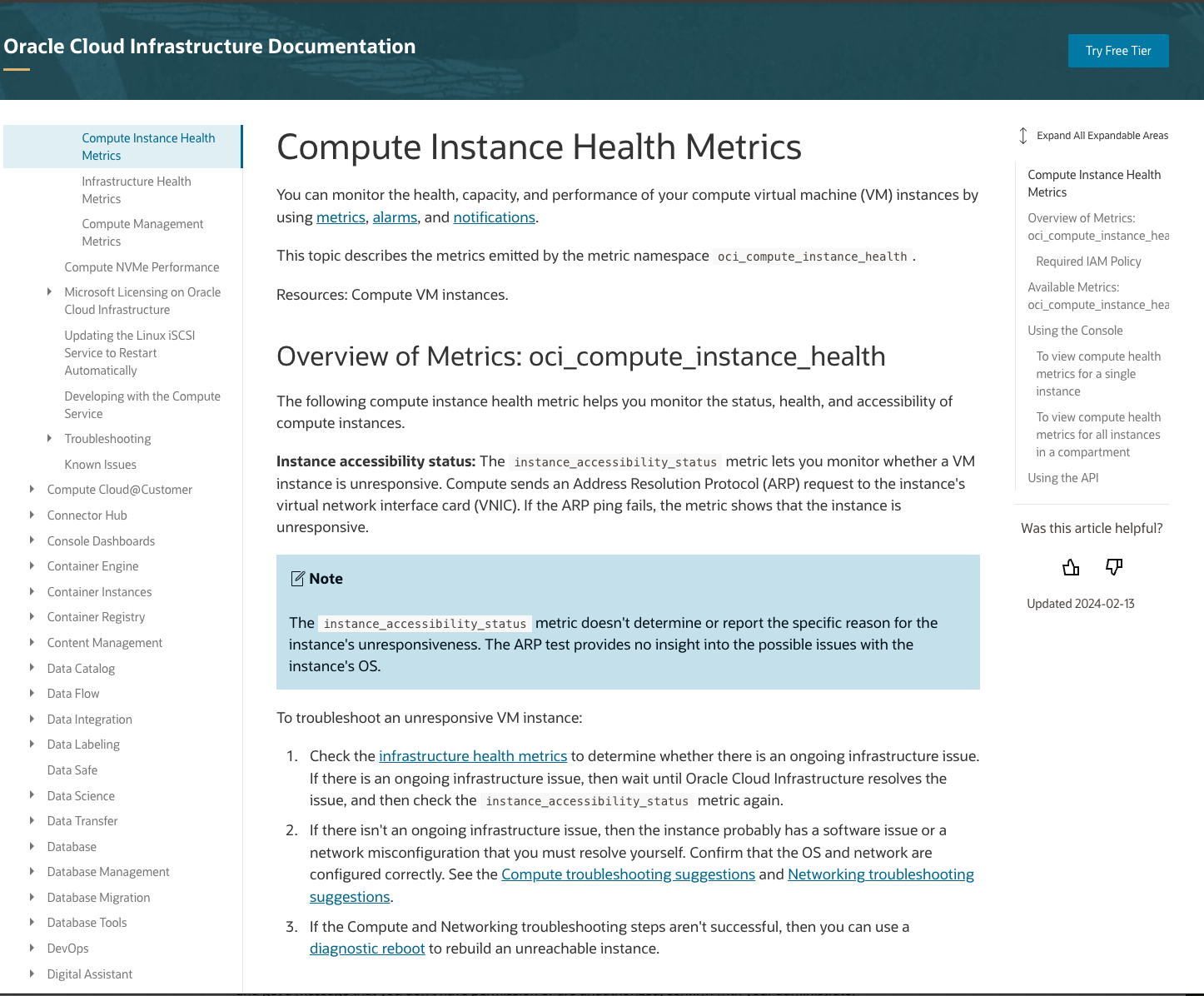
図3: OCIのユース・ケース関連ドキュメントの例
RAGシステムは、バックグラウンドで、関連するコンテンツをOCIパブリック・ドキュメントのリポジトリから引き出します。
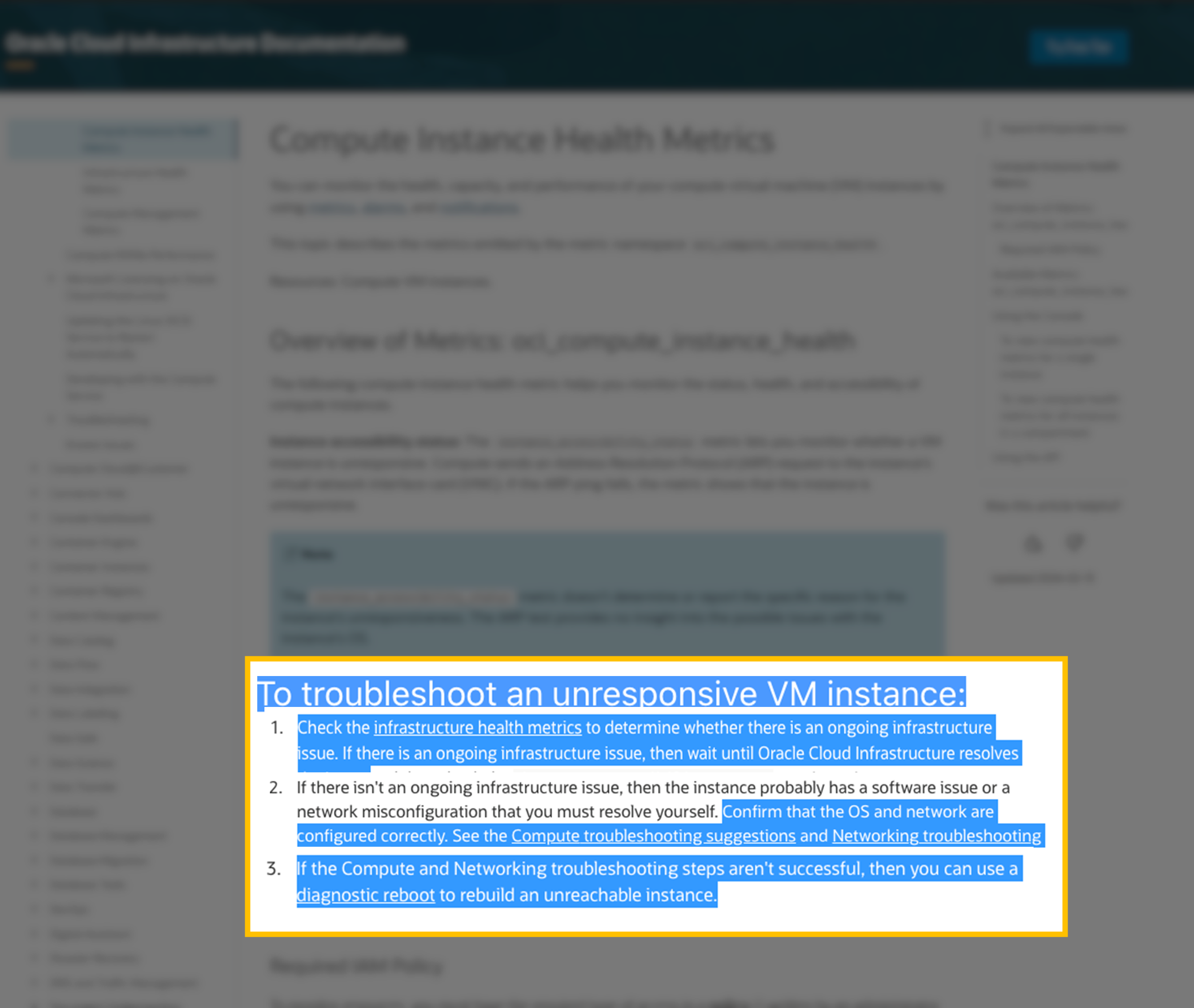
図4: 関連するコンテンツ・スニペット
入力問合せとともに、これらのコンテンツ・スニペットおよび以前の会話のコンテキストがLLMにフィードされ、ユーザーに提示する意味のあるレスポンスが生成されます。
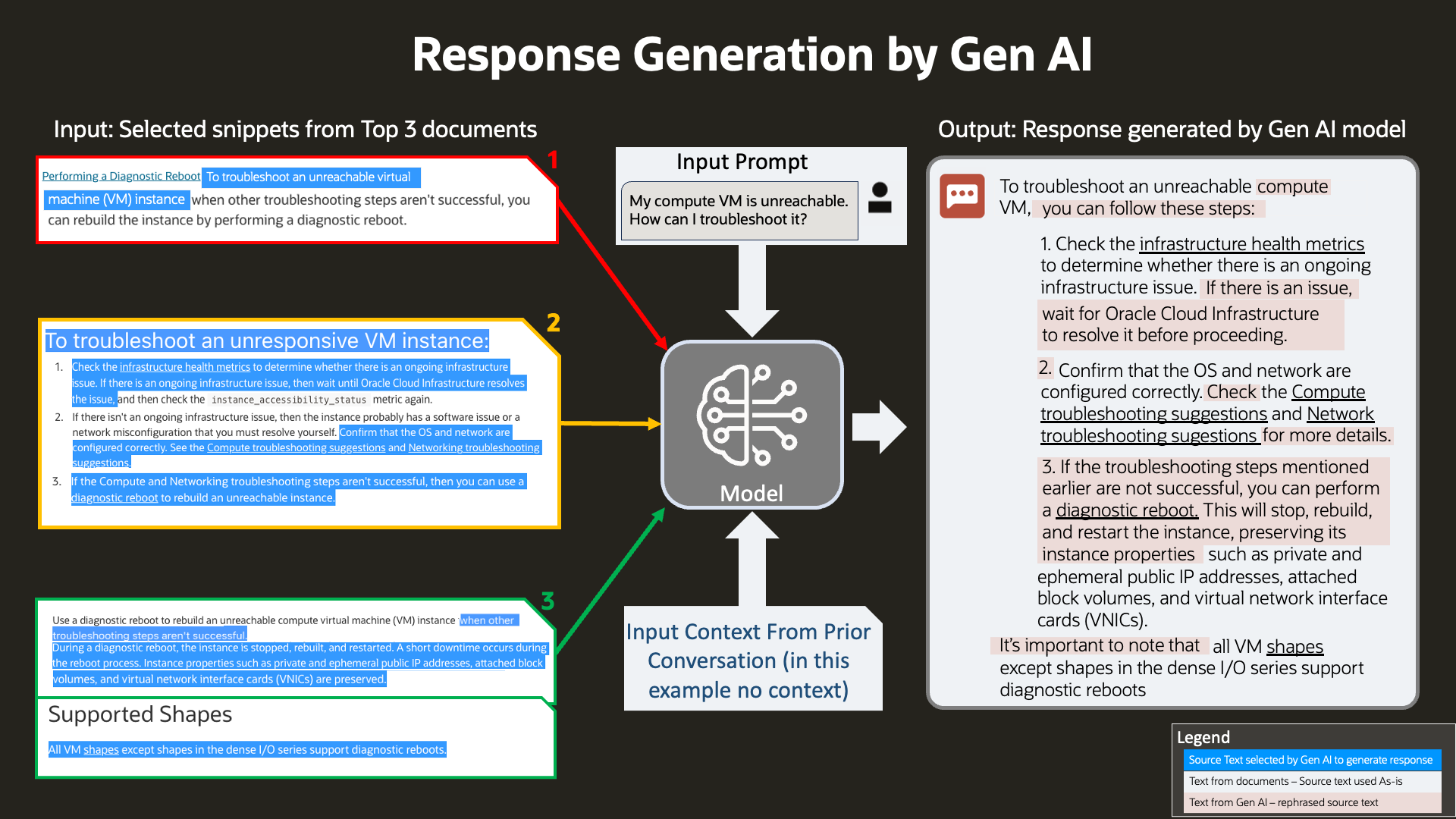
図5: レスポンス生成
長い文書を参照し、情報をまとめ、顧客の特定の質問に合せた要約された応答を生成する点において、このシステムが優れていることがわかります。このインテリジェントな要約により、OCIカスタマー・サポート・チームだけでなく、エンド・カスタマも多大な時間と労力を節約できます。また、このブログの以降のセクションでは、マルチターンの実現方法など、このユース・ケースの技術的な詳細についても詳しく説明します。
このシステムのマジックは、OCI GenAI Agent RAGによって強化されます。OCIサポート・チームは、GenAIモデルのトレーニングを必要としませんでした。実際には、モデルの選択やLLMのデプロイに関与する必要はありませんでした。OCIでは、膨大なドキュメント・セットをOpenSearchで索引付けし、数回のクリックでOCI GenAI Agentを使用してデジタル・アシスタントを起動できました。
インテリジェント・エージェント
私たちは、RAGをどのように実装したのでしょうか? まずは、検索と生成という2ステップのプロセスを事前定義した単純なRAGプロトタイプを構築することから始めました。しかし、そのソリューションには制限があることが判明し、様々な状況に対処できないことが分かりました。たとえば、LLMが直接処理できる知識の取得を必要としない質問や、複数の検索が必要な質問や、計算機などの他のツールの助けが必要な質問があります。
現実世界の多くの可能性に対応できる柔軟な方法でRAGの問題を解決するにはどうすればよいでしょうか? 広範な議論と研究の後、「インテリジェント・エージェント」の概念が登場しました。エンジニアがインテリジェント・エージェントの魅力的な世界に身を置いた時、私たちはこれらの技術が持つ信じられないほどの可能性について考えました。インテリジェント・エージェント・プラットフォームの構築に関心を持ったのは、突然ではありませんでした。それは、私たちが蓄積する膨大な量のデータの中に眠っている、未開拓の広大な可能性に対する、鋭い認識から進化したものなのです。
私たちには、データ・サイエンスのバックグラウンドがあり、データ処理と分析の困難なプロセスを経験していました。それは、時間がかかり、正直、圧倒されます。私たちは進歩しましたが、それでもデータ内に閉じ込めらている可能性の表面をかすめるのがやっとです。インテリジェント・エージェントと自律型ワーカーが日々の業務にシームレスに統合し、コンピュータ・システムとのやり取りに革命を起こし、所有するデータの真の価値を引き出す未来を想像してみてください。
テクノロジーと人間の努力がより同期して、生産的な方法で共存する未来というビジョンは、インテリジェント・エージェント・プラットフォームの開発に対する私の情熱を後押しするものです。日常的なデータ処理を自動化し、より高度なインタラクションを実現することで、これらのエージェントは、ワークフローを合理化するだけでなく、以前は膨大なデータによって見つけられなかったインサイトを発見することを約束します。
エージェントとは?
LLMを利用するエージェントは、LLMを使用して問題を把握し、問題を解決するための計画を作成し、一連のツールを利用して計画を実行するシステムです。このプロセスにより、エージェントは複雑な指示に従い、ユーザーから受け取ったシンプルで簡潔なコマンドに応じて、様々なアクティビティを実行できます。RAGは、ナレッジ・ベースからデータをフェッチするエージェントの一種です。
次のエージェントのハイレベルなワークフローは、汎用エージェントのステップを示しています:
- ユーザーは、簡単な指示を自然言語で行います。
- LLMを利用したエージェントは、会話を分析して、複数のステップで構成される計画を作成します。
- LLMを利用したエージェントは、各ステップで使用するツールとその使用方法を見つけます。
- 各ステップの結果がエージェントにフィードバックされ、再計画、プロセスの続行、応答の生成または顧客入力の要求のいずれかが行われます。
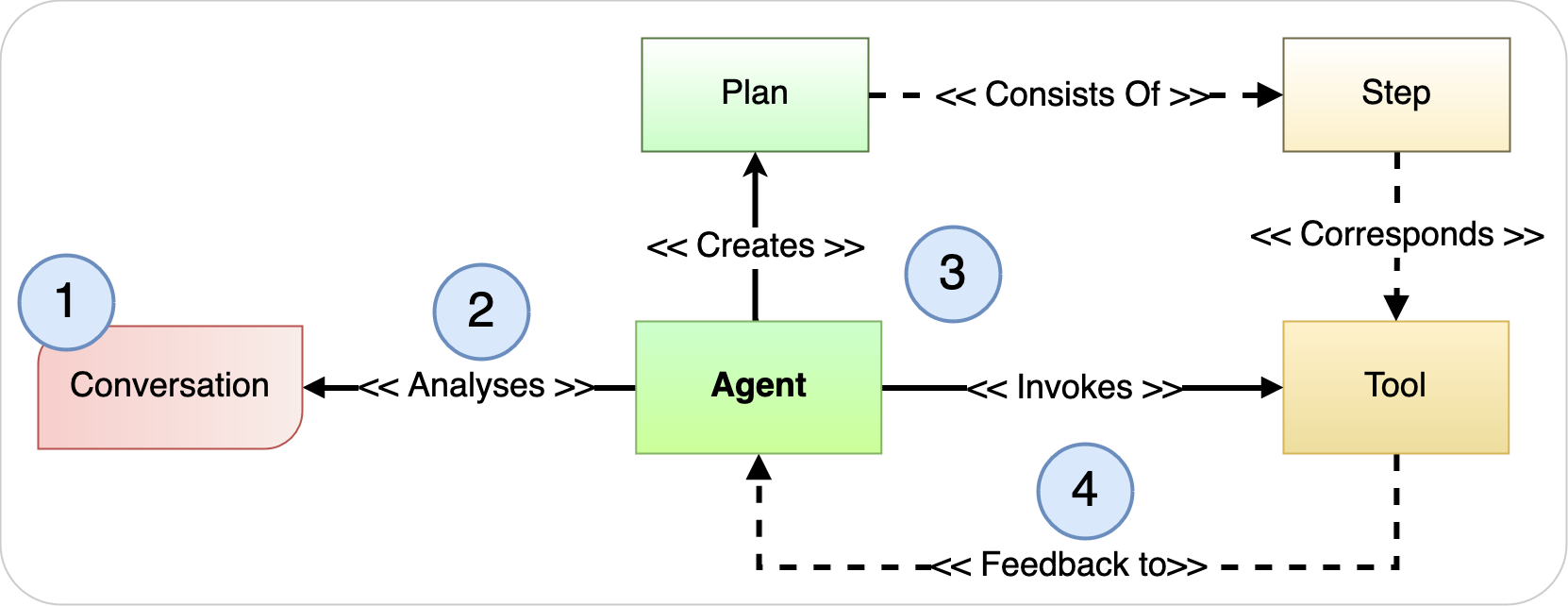
図6: エージェント・パラダイムの概要
次に、この概念的なパラダイムをどのように達成したかを見てみましょう。
OCI生成AIエージェント・サービス
私たちの目的は、RAGソリューションを柔軟な方法で提供するだけでなく、SQLやコードなどの多様な機能を備えた将来のエージェントを可能にする、汎用的なGenAIエージェント・サービスを構築することでした。
私たちは始める前に、設計の基礎となる重要な原則について考えました。他にも、次のような上位目標を特定しました:
- セキュリティ: エンタープライズ・データには真の価値があり、強力なセキュリティとガバナンスが必要です。
- 俊敏性: 高いペースで非常に革新的な分野でサービスを立ち上げています。サービスが成功するかは、迅速に反復して機能を向上させる私たちの能力にかかっています。
SOLID設計パラダイムを次の概念でフォローすることを選択しました:
- システムは、それぞれが明確な機能を持つ単一責任モジュールで構成する必要があります。
- システムは、既存のフレームワークに劇的な変更を加えることなく、時間の経過とともに拡張可能である必要がある。
- システムおよびそのサブコンポーネントは、内部実装を理解しなくても、使用方法に関する正式で正確かつ検証可能なコントラクトを定義する必要がある。
- システムとそのサブコンポーネントは疎結合である必要があります。
従来のソフトウェア・システム開発と比較して、現在AI分野で直面しているユニークな課題は、科学的発展のペースがはるかに速いことです。毎週新しいテクノロジーが登場し、数か月前に作成されたテクノロジーは、見劣りする機能となってしまいます。そのため、システムは拡張可能で反復開発しやすいことが重要です。
これらの理念と設計原則を実現するために、サービスを拡張可能でプラガブルな次のビルディング・ブロックに分割しました:
- エージェント・コア: LLMエージェントの「脳」は、コンセプトの生成、計画の作成、取るべき道筋の選択、応答の解析、および最終的にはユーザーへの最終応答の生成を行います。
- メモリー: これは、エージェントの個人的な日記のようなものですが、よりクールなものです! チャット履歴、思考と計画、およびアクションの結果のためのストレージ・システムです。
- ナレッジ・ベース: 知識の秘密の隠し場所です! これらは外部のプライベートな情報ソースであり、オラクルのLLMは、ユース・ケースに合せたより優れたデータを使用して、応答を強化します。多くの場合、このデータ・ソースはしばしばモデルの土台となるために使用されます。
- ツール: これは私たちのエージェントのスーパーパワーのようなものです! これらは、エージェントの機能を強化する追加機能であり、リアルタイム情報の関数コール、Pythonコードの実行、最新または専門的な情報のための特定のデータベースへのアクセスなど、標準的なテキスト生成以外のタスクを実行できます。
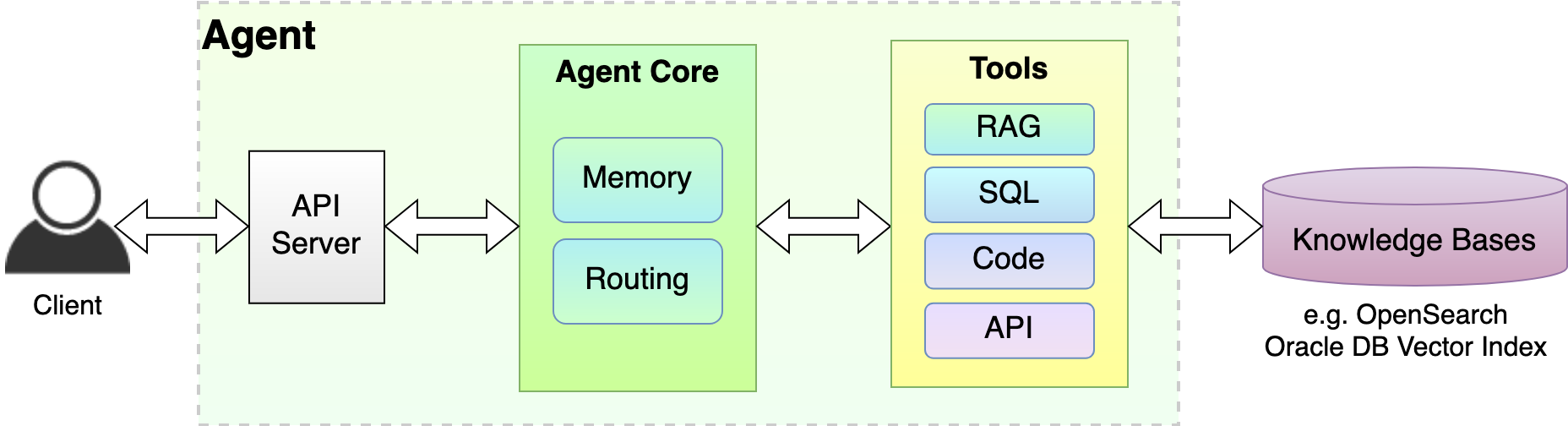
図7: エージェント・サービスの高レベル・アーキテクチャ
次に、エージェントコアとRAG検索ツールの内部動作を見てみましょう。
エージェント・コア内部
エージェント・コアは、この機械の「脳」です。様々なエージェント・タイプに対応するには、高度にカスタマイズ可能である必要があります。ここでは、エンジニアと科学者が緊密に協力して設計を繰り返し、お互いに学び合います。エンジニアはシステムの拡張性、スケーラビリティ、可観測性、レイテンシに重点を置き、科学者はモデルの選択、長期的なビジネス・シナリオ、モデルレベル、エンドツーエンドの精度に重点を置きます。
次の図は、エージェント・コアが内部的にどのように機能するかを示しています:
- オーケストレーション・ループは、エージェントが環境を観察し、その観察と内部ロジックに基づいてアクションを決定して実行し、その結果と新しい観測に基づいて理解を更新する連続サイクルです。
- アクション・ルーターは、プロセス・パスを決定し、前のステップのアクション・プランに基づいて、対応するコンポーネントにリクエストをルーティングします。
- アクション・レスポンス・パーサーは、アクションからのレスポンスを解析し、エージェント・コアに情報をフィードして、次の反復の準備をします。
- エージェント・メッセージ・ジェネレータは、ユーザーへのレスポンスを作成し、現在の会話のターンを完了します。
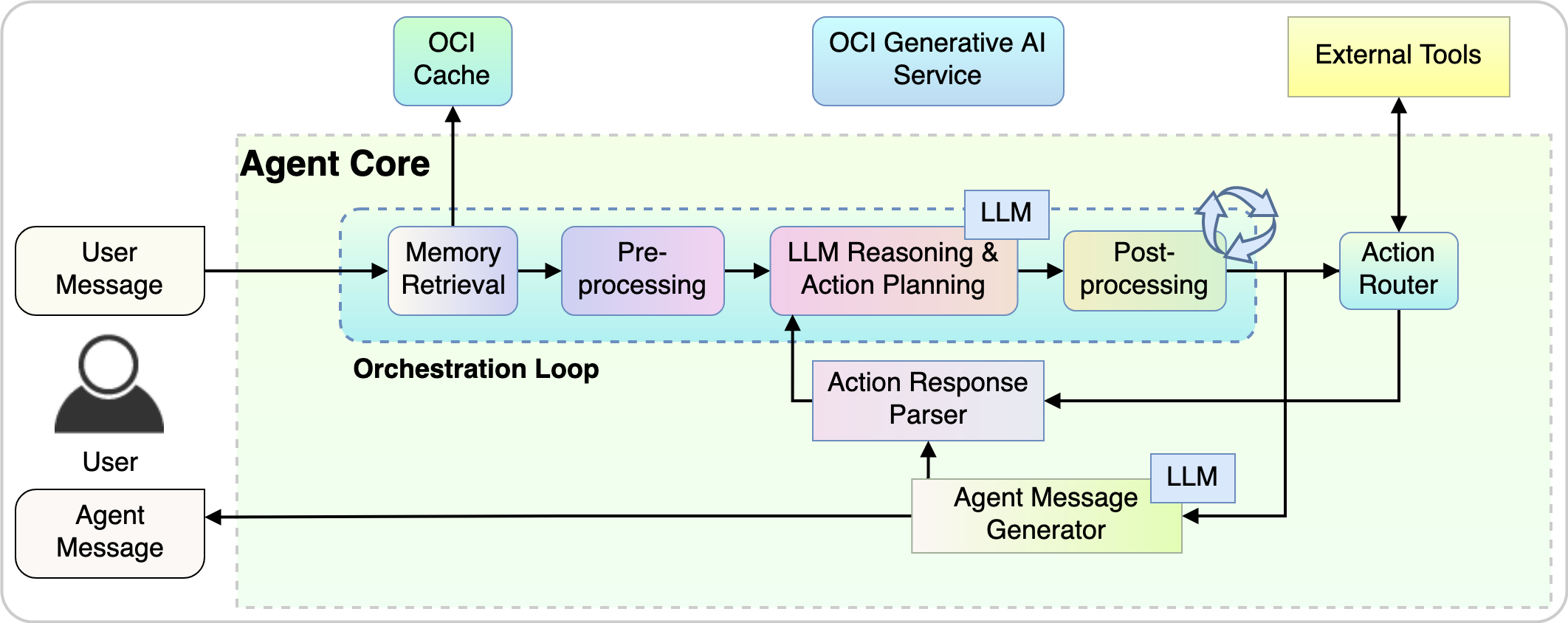
図8: エージェント・コア内部プロセス
RAG検索ツールの内部
RAGエージェントのエージェント・コアは、通常、ゼロまたは複数の取得ステップ、オプションのツール・プロセス、および最終生成ステップの計画を行います。RAG検索ツールは、様々なデータ・ソースから関連情報を取得し、RAGエージェントが作業できるように提供します。生成LLMは、後でこの情報を使用してユーザー問合せへのレスポンスを生成します。
顧客の質問に正しく回答するという点で、RAGの取得が最も重要な部分であることがわかりました。ナレッジ検索は新しい問題ではなく、検索エンジン・フィールドで十分に調査および解決されています。
そのため、従来の検索エンジンから次の主要な技術を借りて、RAG検索ツールに適用しました:
- クエリー・リライト: ユーザーの問合せを取得し、検索に適したものに変換されます。たとえば、OpenSearch検索のユーザー入力問合せの再フォーマットおよび最適化を行います。これで、検索表示のための問合せの準備ができました。
- 問合せの実行: RAG取得ツールは、準備された問合せを1つ以上のナレッジ・ベースに送信して、上位Nの関連ドキュメントを取得します。それは、必要なものを見つけるために捜索隊を送り出すようなものです。
- ドキュメントの再ランク付け(リランキング): 検索チームが結果を返した後、検索結果に磨きをかけ、補完的な基準に従ってソートします。
- ナレッジ・ベース: お客様は、すべてのドキュメントがすでに索引付けされ、準備ができている、自分のOCI OpenSearchインスタンスを使用できます。また、Object Storageバケットにあるデータを持ってくることもでき、データは、サービスが管理するナレッジ・ベースに自動的に取り込まれます。
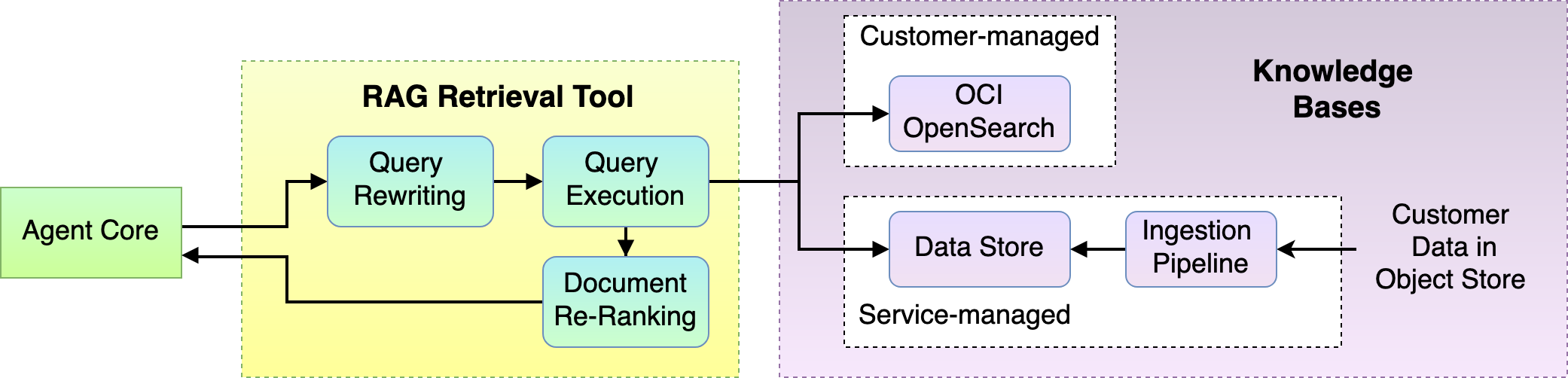
図9: 内部RAG取得ツールのプロセス
RAGを使用した生成AIエージェントにより、会話の忠実度を向上
お客様が大切にしている分野は何でしょうか? 私たちは、マルチターンの会話、データ処理と保護、正確性、安全性が最優先事項であることを学びました。その結果、GenAIエージェント・サービスが適切に実行されるように、これらの領域に多額の投資を行っています。
マルチターン会話
RAGエージェントは、マルチターン会話の忠実度の向上に対応するように設計しました。各ターンの入力と出力はメモリーに格納されます。クエリー・リライト・ステップのエージェントは、現在のユーザー問合せおよび前の会話を入力として、会話全体に関連する検索問合せを生成します。
OCIサポート・ユース・ケースの例で、各ターンの入力問合せがどのようにリライトされたかを示します。2回目と3回目のリライトには、後続の問合せの生成に不可欠な、前のステップ(リクエストとレスポンスの両方)からの重要な情報が含まれています。
- ターン1: 「私のCompute VMにアクセスできません。助けてください。」は、「Compute VMアクセス不可」になります。
- ターン2: Ok、ステップ1がよく分かりません。助けてくれますか?」は、 「Infrastructure health metrics Oracle Cloudをチェック」になります。
- ターン3: 「ここにはたくさんの指標があります。どれが私の問題に役立ちますか? 」は、「アクセス不可のVMのメトリックをインポート」になります。
会話は一番最後のターンに繋がるように構成され、シームレスに流れます。
次の図は、この例のターン2がRAGエージェント内でどのように機能するかを示しています:
- 元のユーザー問合せは、関連するドキュメントを取得するためにナレッジ・ベースに送信され、システム生成の検索問合せに書き込まれます。問合せリライト・ステップでは、先行する会話が検索語に組み込まれます。
- 検索されたドキュメントは、それらのドキュメントの埋込み、ユーザー問合せの埋込み、リライトされた問合せを入力として、再ランク付け(リランキング)されます。
- リランキング後、上位3つのドキュメントおよびすべてのコンテキスト情報が、レスポンスを生成するLLMに入力されます。
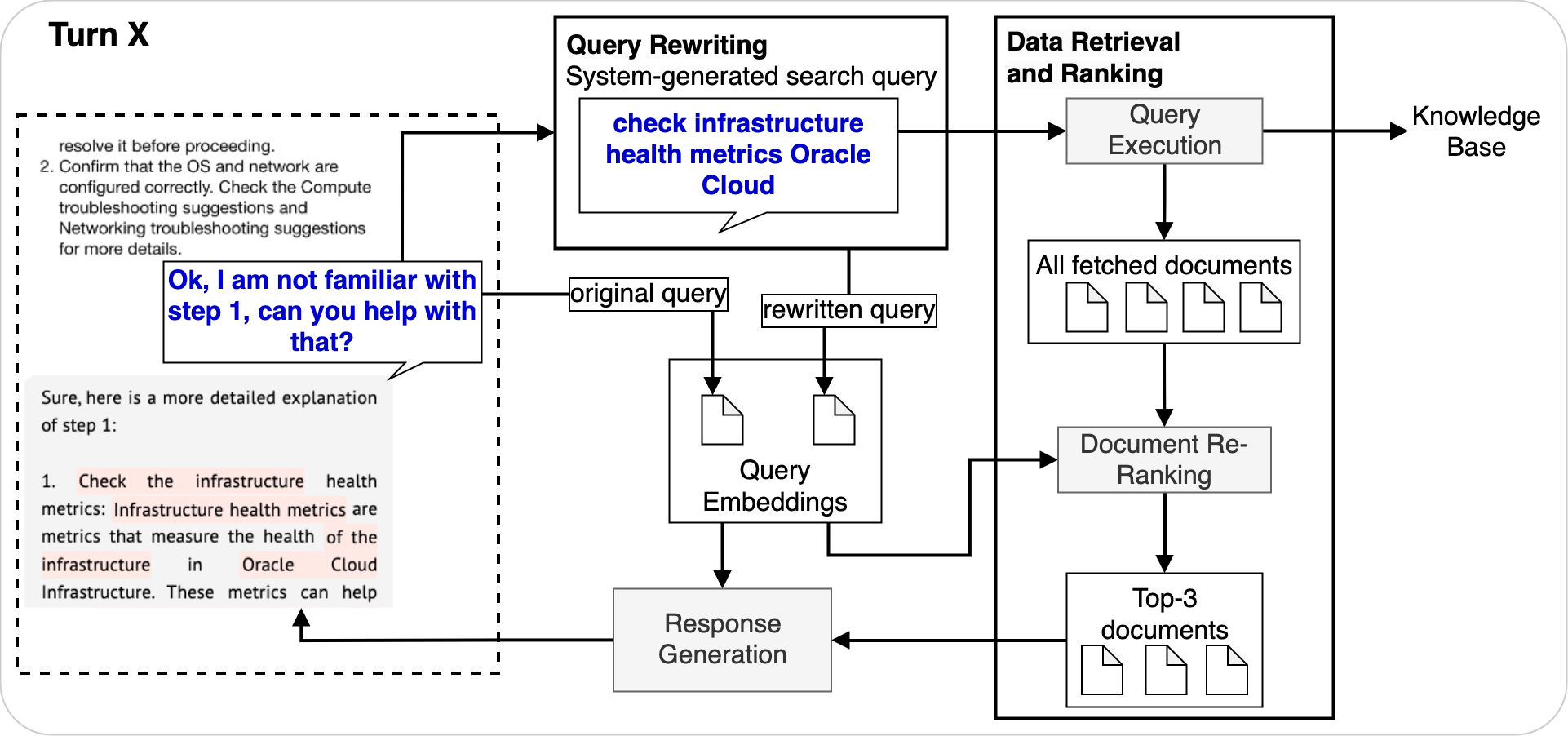
図10: マルチターンRAGの取得と生成
データ処理と保護
OCI OpenSearchを使用することで、エージェントは非構造化データを索引付けおよび格納し、より迅速で正確に取得できます。OCI OpenSearchのきめ細かなアクセス制御により、顧客は索引付けと問合せの両方において、管理の観点からデータを強力に制御できます。
顧客にはデータに関する選択肢があります。OpenSearchクラスタまたはオブジェクト・ストレージを使用して、RAGエージェントをOCIの既存の非構造化データにリンクすることを選択できます。データは分離されたワークロードで処理され、リアルタイムの会話中に問合せおよびコンテキストに基づいてのみデータが取得されます。
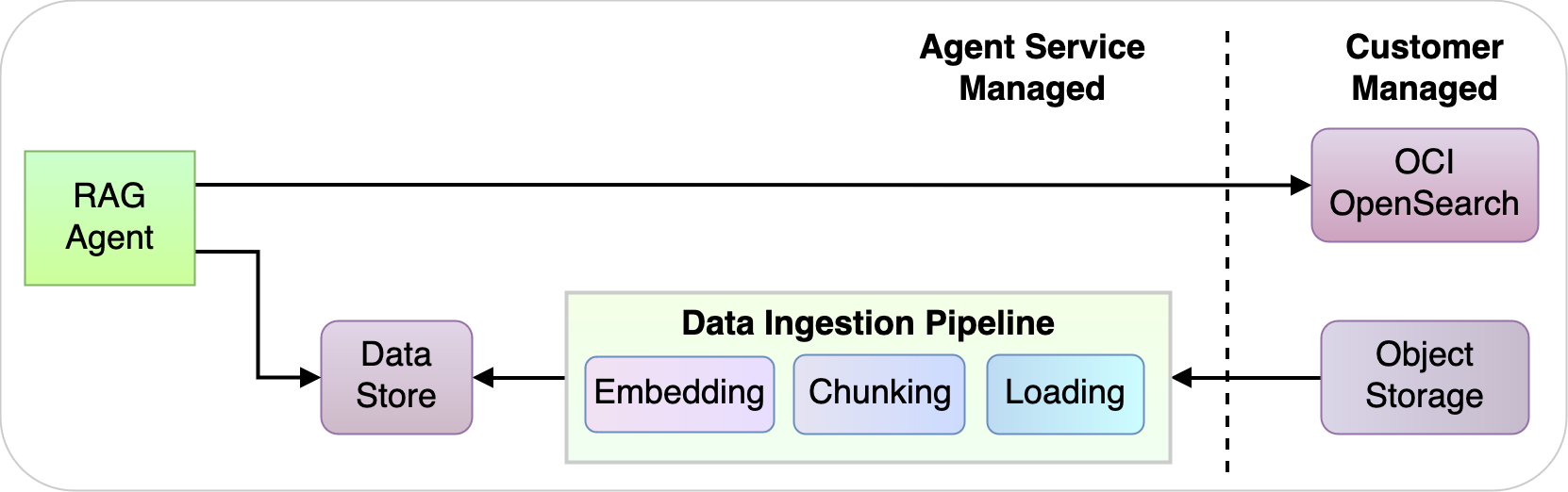
図11:RAGエージェント・データの取込みと取得
モデル精度
どんなLLMも完全な精度を持ちません。しかし、企業での採用を促進するために、RAGを含むさまざまな技術によって精度を向上させることができます。オラクルのGenAI RAGエージェントは、幻覚を減らすのに役立つデータに基づいた生成を実装しています。また、次の検証に役立つ出力ガードレールも搭載しています:
- ユーザー問合せの入力、取得したサポート内容、生成されたレスポンスを取得します。
- 生成したレスポンスの品質を複数の次元(有用性、接地性、正確性など)でで表すスコアを生成します。
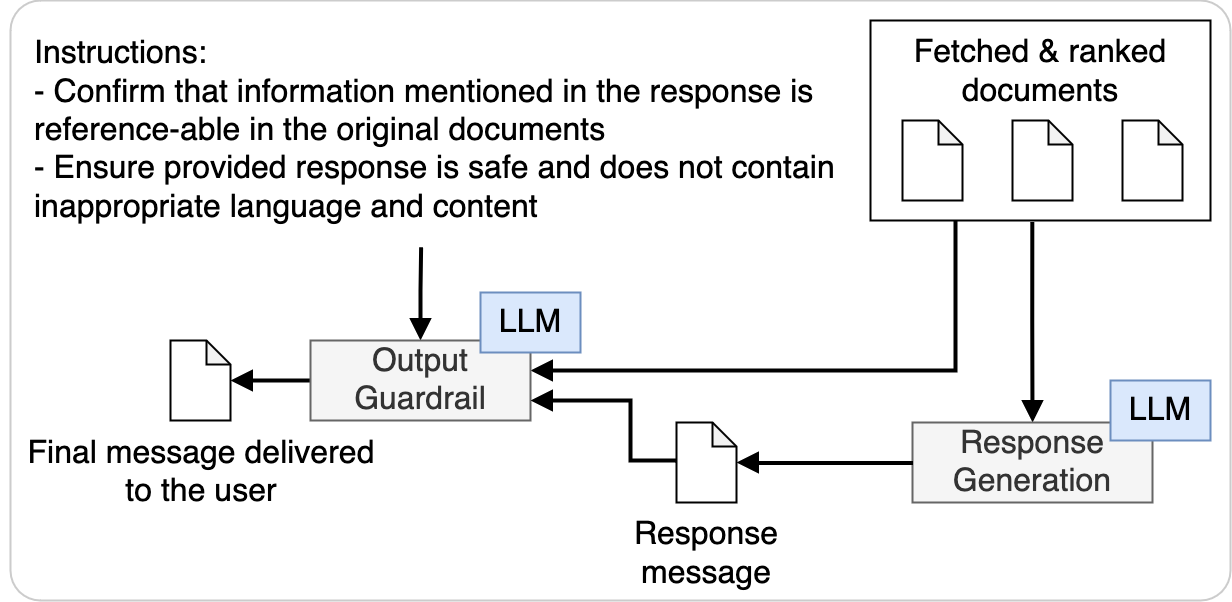
図12: RAGエージェント出力検証
GenAIエージェント・フレームワークでは、ツールを使用して、動作をコース修正するための透過的な方法を提供することもできます。これにより、よりシームレスな対話が可能になります。
次の例は、SQL生成、修正、SQL実行およびレスポンス生成などのSQL機能を持つエージェントを示しています。
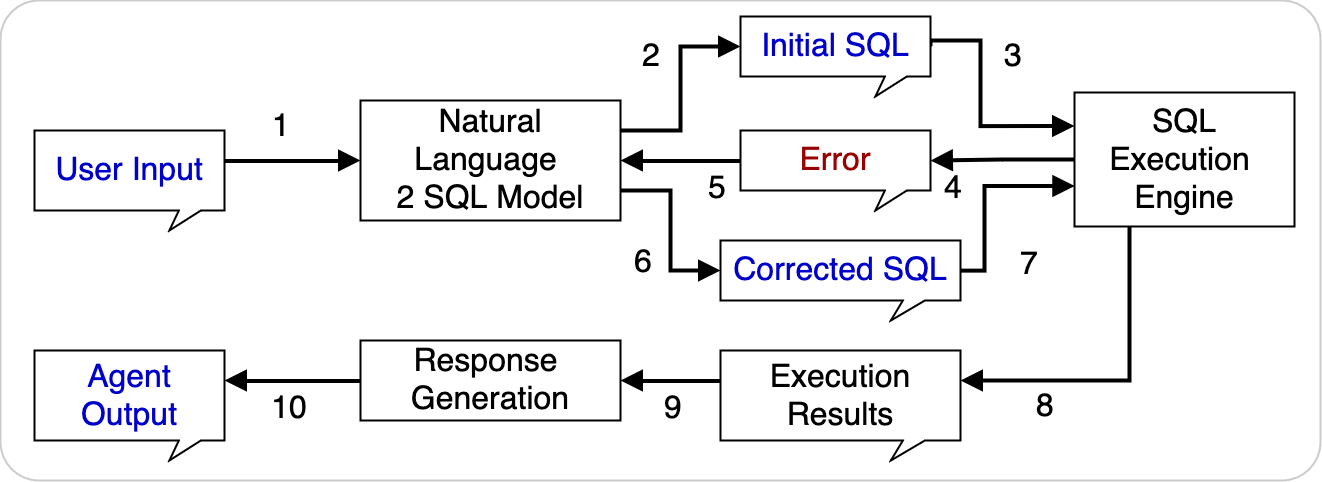
図13: SQL機能を持つエージェント
拡張性と次のステップ
今後、RAG以外のビジネス・ユース・ケースを解決するために、GenAIエージェント・フレームワークをさらに拡張できることを嬉しく思います。
最初の拡張ポイントはツールです。さまざまなビジネス目標を達成するために、さまざまなツールを使用できるようになります。
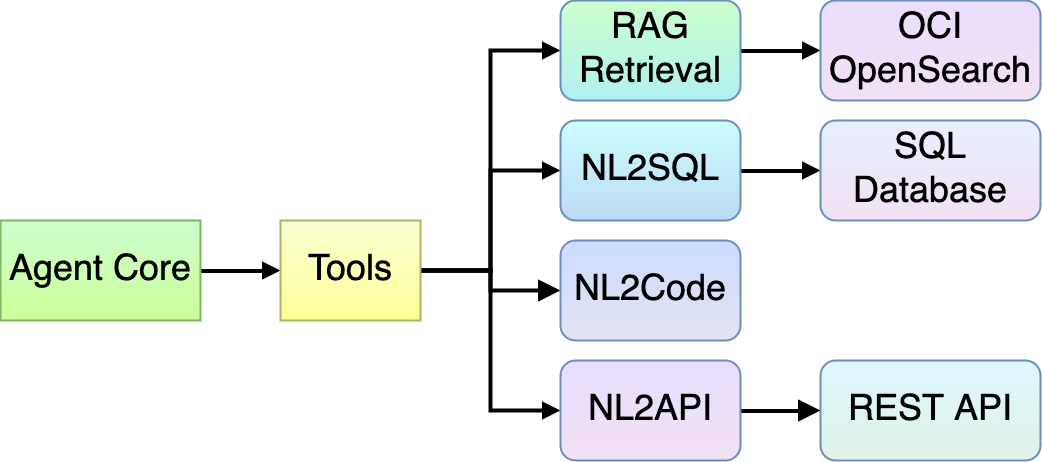
図14: エージェント拡張 — ツール
2つ目の拡張ポイントは、ナレッジ・ベースです。非構造化データ、半構造化データ、構造化データからマルチモダリティ・データまで、より多くの知識ベースでRAG機能を向上させることができます。ハイブリッド検索、キーワード検索とセマンティック検索のメリット、様々な埋込みモデルの組合せなど、様々な索引付けおよび取得手法を使用できます。
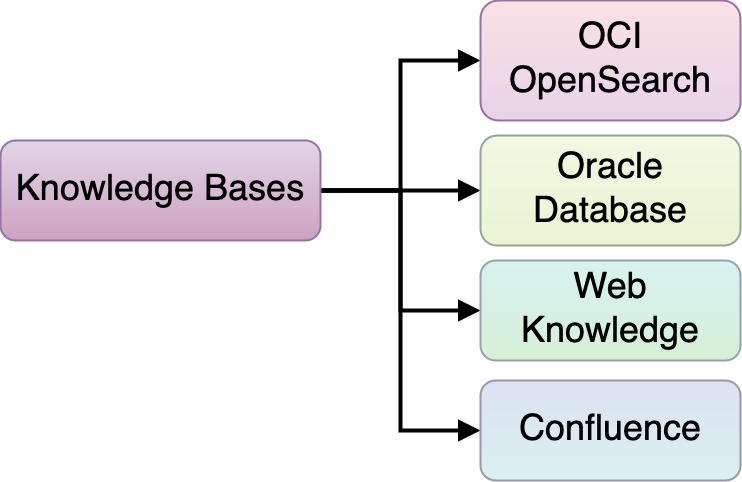
図15: エージェント拡張 — ナレッジ・ベース
まとめ
OCI生成AIサービスにおけるインテリジェント・エージェント・パラダイムの実装は、テクノロジーが自律的に環境とやり取りし、理解して、より正確で効率的、パーソナライズされたソリューションを提供する方法の変革的な前進を示しています。オラクルのサービスは、インテリジェント・エージェントの機能を活用することで、動的で適応性の高い応答によってユーザー・エクスペリエンスを向上させ、大量のデータ処理に関して効率性の新しい基準を設定します。この枠組みの中で、成長とイノベーションの可能性は計り知れません。
アルゴリズムを改良し、サービスの能力を拡大し続ける中で、インテリジェント・エージェントが達成できる限界を押し広げ、当社のサービスがテクノロジ・エクセレンスの最前線に残るよう努めています。インテリジェント・エージェントの領域へのこのジャーニーは、サービスの改善だけでなく、テクノロジについてどのように考え、対話するかを再構築することです。
生成AIエージェントは、次の機能を顧客に提供します:
- RAGパラダイムは、会話型AIのパワーを組み合わせて、最新の状況に即した豊富なデータを使用して「データとチャット」します。
- GenAIエージェントは、サービスを構成してナレッジ・ベースに接続することで、AIアプリケーションの起動の複雑さを軽減します。
- GenAIエージェントは、問合せリライティング、セマンティック再ランキング、出力ガードレールなどの複数の手法を実装して、コンテキストの正確性を向上させた高忠実度のマルチターン会話を可能にします。
現在解決している問題で、OCI生成AI RAGエージェントやその他のエージェント・タイプを使えるものはありますか? お気軽にご相談ください。詳細は、次のリソースを参照してください:
