Have you ever asked a question to a chatbot, only to receive a response that didn’t solve your problem? Frustrating, isn’t it? That’s the exact challenge we’re addressing!
The on-going rapid advancements in the generative AI (GenAI) fields, particularly in large language models (LLM) and their endless possibilities, have been mind-blowing. At Oracle Cloud Infrastructure (OCI), we build enterprise applications and use GenAI technologies to help solve real business problems. Our goal is to provide customers with contextually accurate and relevant information to drive better decision-making.
In a previous blog post, Exploring the depths of the Generative AI service, we discussed how fine-tuning GenAI can help improve accuracy and customize an AI solution with less effort (from months to weeks). With fine-tuning, you can improve LLM behavior to handle specific tasks based on your data.
We know that fine-tuning helps but doesn’t solve the well-known LLM hallucination problem. LLMs aren’t designed to store precise facts or objective data that you want to retrieve later. LLMs are trained on limited, albeit very large, datasets at a time point. They aren’t, however, trained with private data or data that is and remains current.
Then how can we produce more reliable and accurate answers using LLMs? Retrieval-augmented generation (RAG) combines the power of LLMs and knowledge bases that leverage proprietary, up-to-date data that the model has never seen before. Grounded by facts retrieved from knowledge bases, the LLMs can therefore produce more accurate answers.
As tech leads with over a decade of experience in building large-scale AI applications, we often apply a RAG-like approach to our jobs. The brain is trained with years of learnings and experience. When handling a new problem, we retrieve information from various sources (documents and people), and the brain then generates the tech design and execution plan, based on both the accumulated expertise and recent learnings.
In this blog post, we delve into our journey of building a RAG solution using the Generative AI Agent service. Customers can integrate their existing knowledge bases and launch domain-aware chat applications.
What is RAG?
As developers and builders, we’re energized to apply the latest AI advancements to concrete customer use cases. One of the most promising early areas of enterprise focus is the use of a chatbot to engage with customers who have questions about a company’s products or services.
While modern LLMs have strong language and reasoning capabilities, they need more contextual understanding to be effective. We can build an RAG-empowered AI assistant leveraging a company’s private data to better tailor the assistant to the use case. By tapping into private knowledge stores, the AI assistant’s output will be more up-to-date, contextually relevant, and accurate that the LLM out of the box. This will help enrich the experience for customers and drive better outcomes.

Figure 1: RAG overview
Let’s look at an example use case of RAG in OCI.
OCI support use case
At OCI, we launched AI-based Oracle Support Digital Assistant, which can conduct human-like conversation with customers to address their technical support problems. It helps users find what they’re looking for faster, summarizing multiple documents into a simplified response relevant for the customer and reducing the need to create and handle tickets.
In the following screenshot, Support Digital Assistant gets the following user request: “My compute VM is unreachable. How can I troubleshoot it?” The digital assistant then provides a list of steps for the customer to follow.
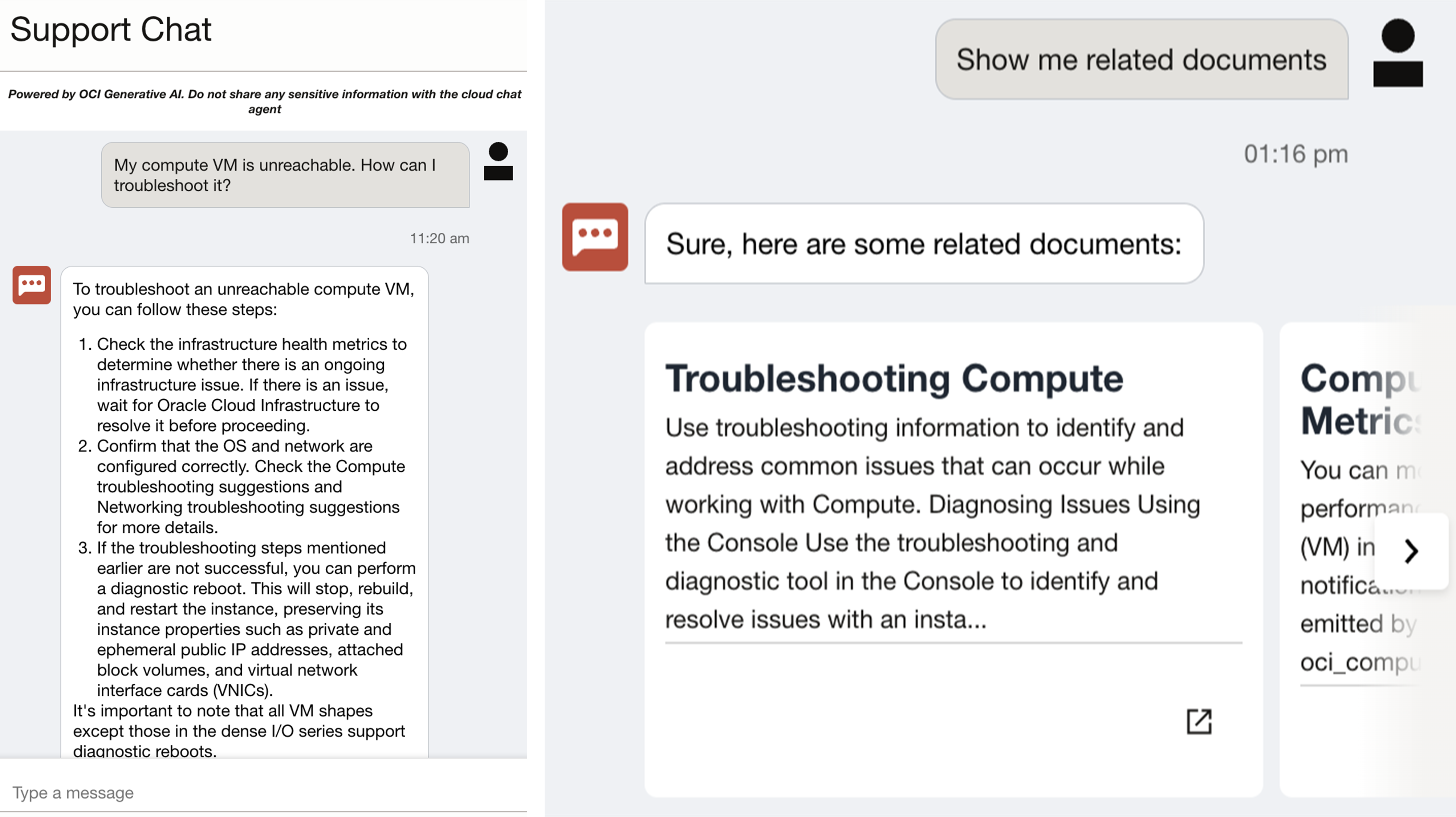
Figure 2: OCI support use case example chat interface
The related documents are linked for the customer to examine.
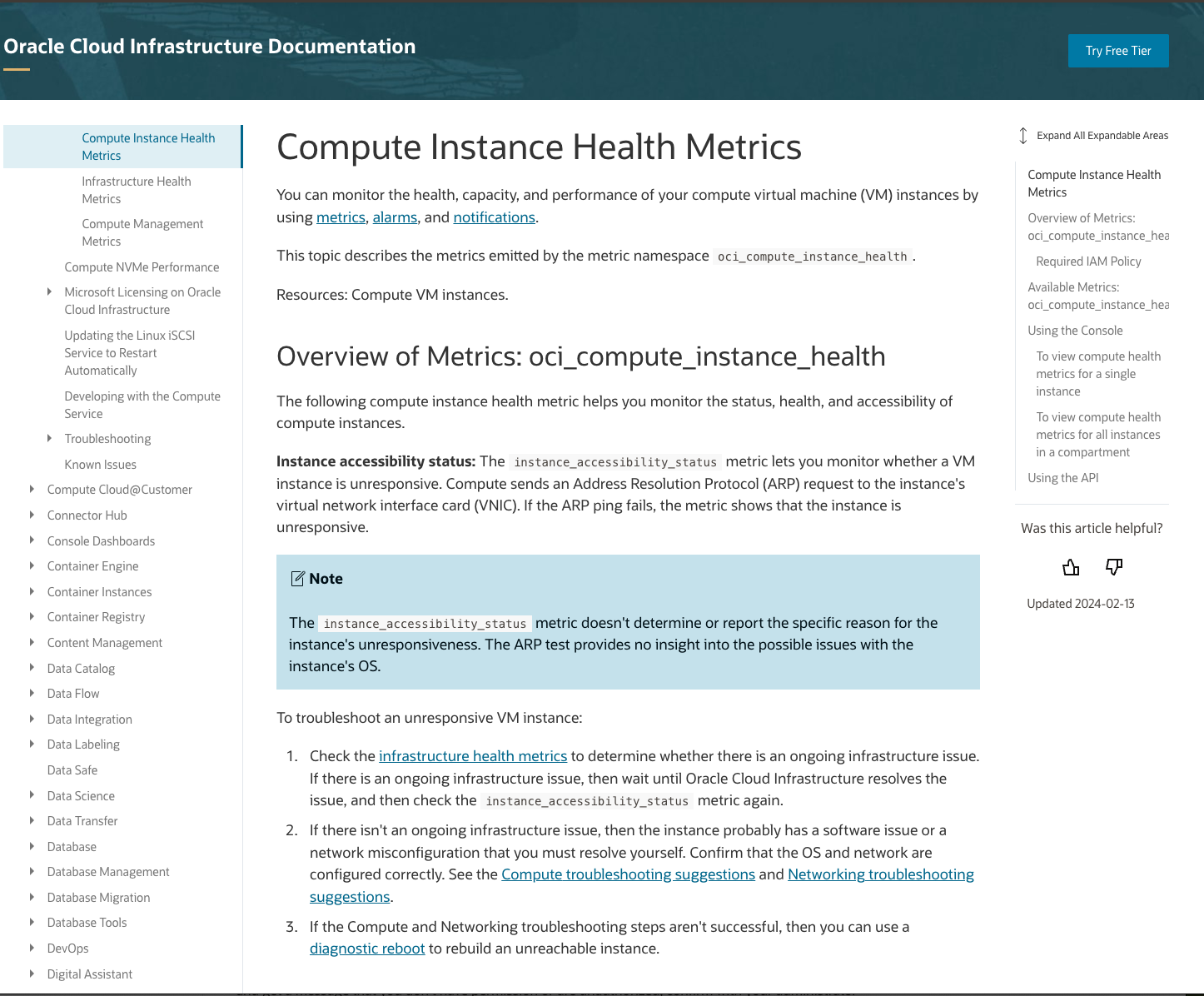
Figure 3: OCI example use case related documents
Behind the scenes, the RAG system pulls relevant contents from a repository of OCI public documentations.
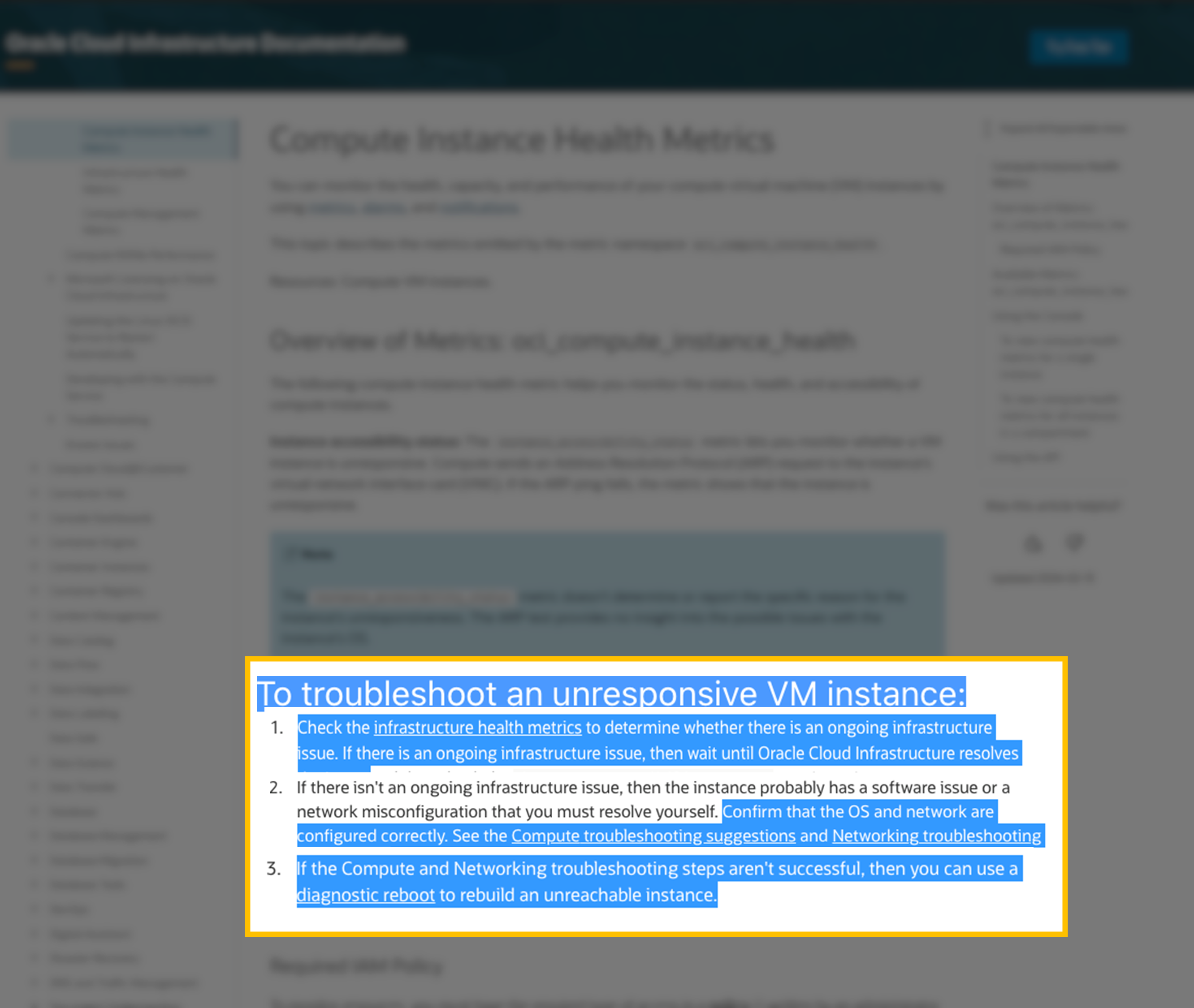
Figure 4: Relevant content snippet
Together with the input query, those content snippets and context from previous conversation are fed into the LLM to generate meaningful response to present to the user.
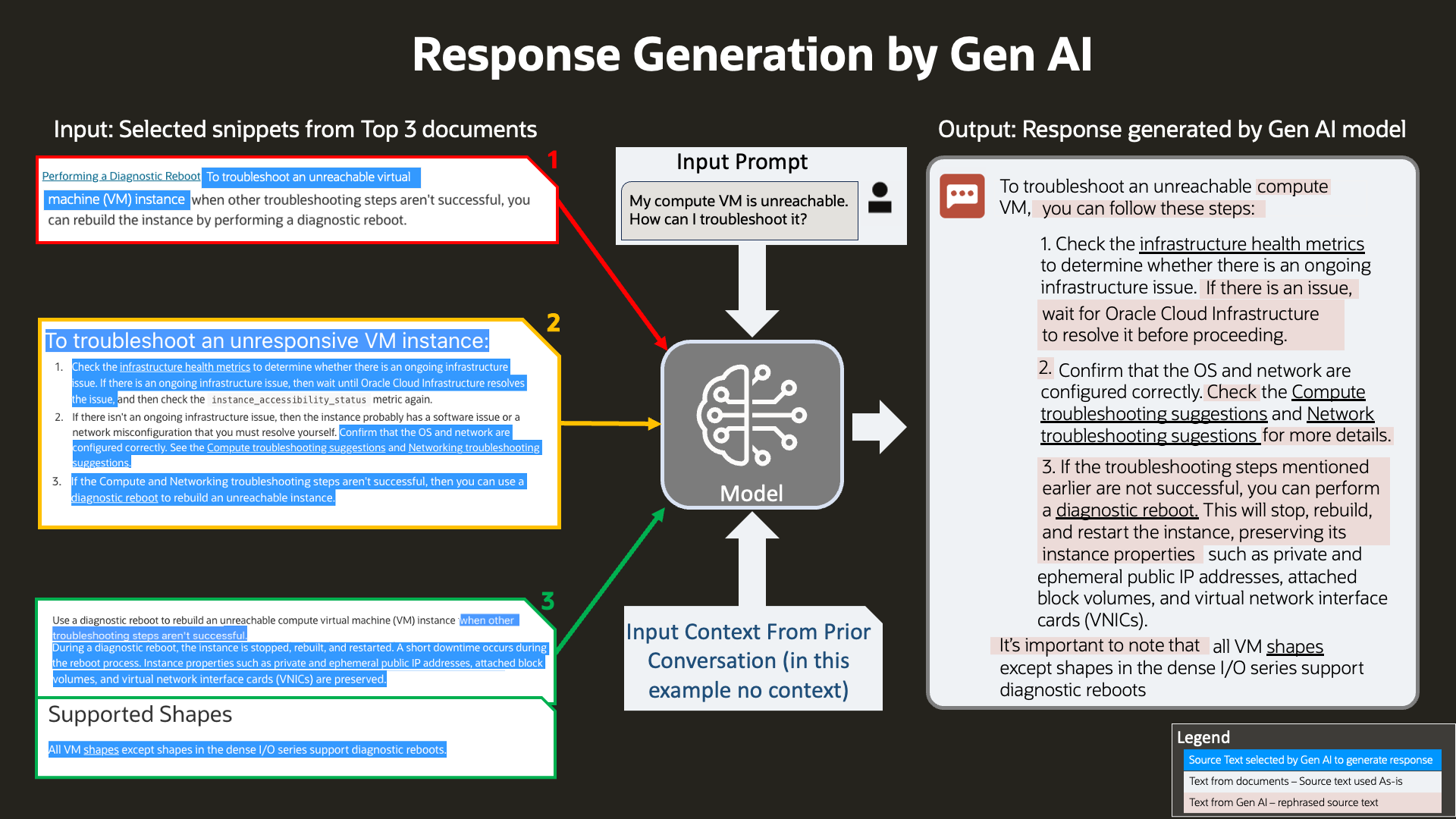
Figure 5: Response generation
You can see that the system excels at consuming long documents, condensing the information, and generating summarized responses tailored to the customer’s specific questions. This intelligent summarization saves potentially significant time and effort for the OCI Customer Support team, as well as for the end customers. In coming sections of this blog, we will also dive deep into technical details for this use case, such as how multi-turn is achieved.
The magic of this system is powered by OCI GenAI Agent RAG. The OCI Support team didn’t have to train any of the GenAI models. In fact, they didn’t have to be involved in selecting the model or deploying LLMs. They indexed their vast set of documents with OCI with OpenSearch, and with a few clicks, they were able to launch the digital assistant using OCI GenAI Agent.
Intelligent agents
How did we implement RAG? We started by building a simple RAG prototype with predefined two-step processes: Retrieval and generation. That solution proved to be limiting and failed to address various situations given the potential variety of incoming questions. For example, some questions don’t require knowledge retrieval that the LLM can directly handle, some questions require several retrievals, and some questions need the help of other tools, such as a calculator.
How do we solve the RAG problem in a flexible way that can handle the multitude of real-world possibilities? After extensive discussions and research, the concept of “intelligent agents” arrived. As engineers entrenched in the fascinating world of intelligent agents, we often pondered the incredible potential these technologies hold. The genesis of our interest in building an intelligent agent platform wasn’t sudden. It evolved from a keen awareness of the vast, untapped potential that lies dormant within the massive volumes of data we accumulate.
Coming from a data science background, we’ve experienced firsthand the arduous process of data handling and analysis. It’s time-consuming and, honestly, overwhelming. Despite our advancements, we barely scratch the surface of the possibilities locked within the data. Imagine a future where intelligent agents and autonomous workers seamlessly integrate into our daily tasks, revolutionizing our interactions with computer systems and unlocking the true value of the data we possess.
This vision of a future where technology and human effort coexist in a more synchronized and productive manner is what drives my passion for developing an intelligent agent platform. By automating routine data processing and enabling more sophisticated interactions, these agents promise not only to streamline our workflows, but also to illuminate insights that were previously obscured by the sheer scale of the data.
What is an agent?
An LLM-powered agent is a system that uses an LLM to work through a problem, create a plan to solve the problem, and run the plan with the help of a set of tools. This process allows agents to follow complex instructions and perform various activities in response to simple and concise commands received from users. RAG is one type of agent that involves fetching data from connected knowledge bases.
The following agent high-level workflow shows the steps of a generic agent:
- You provide simple instructions in natural language.
- The LLM-powered agent analyzes the conversation to create a plan that consists of steps.
- The LLM-powered agent finds which tool to use for each step and how to use it.
- Results from each step are fed back to the agent to either replan, continue the process, generate the response, or request customer input.
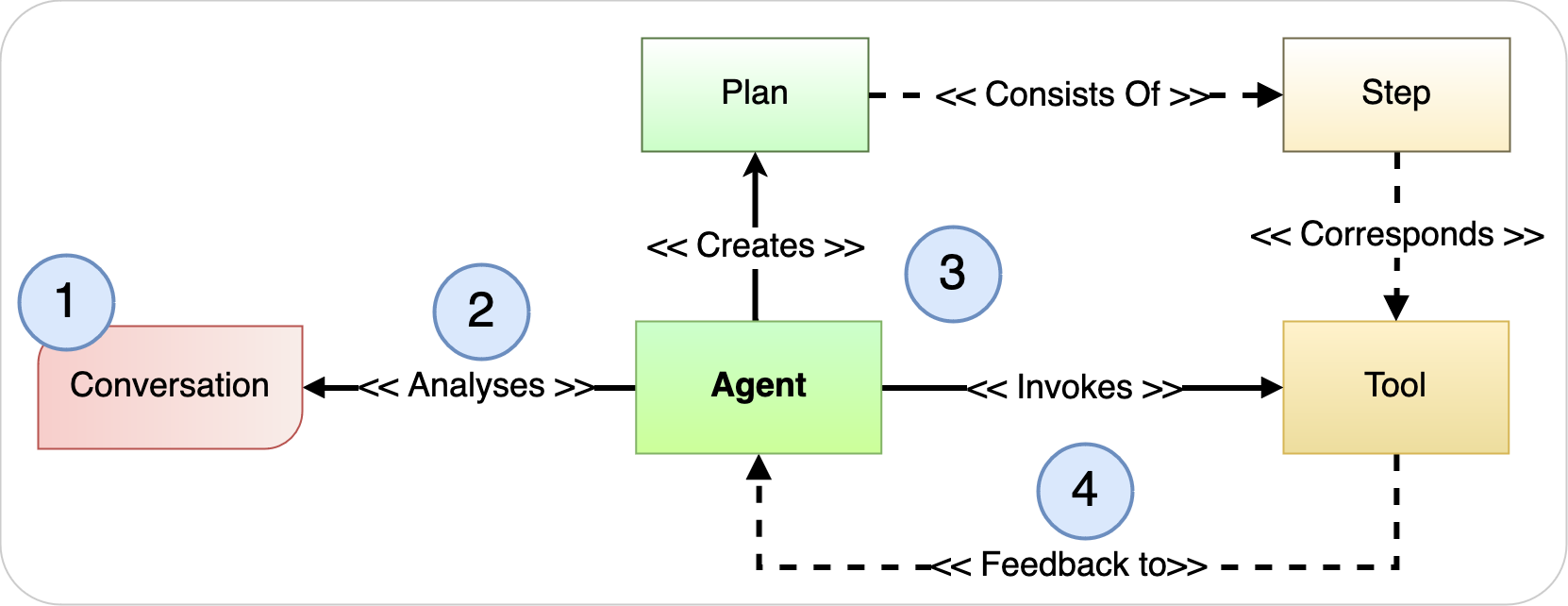
Figure 6: Agent paradigm overview
Next, let’s look at how we achieved this conceptual paradigm.
OCI Generative AI Agent service
Our aim was to build a generic GenAI agent service that not only delivers the RAG solution in a flexible way, but also enables future agents with diverse functionalities, such as SQL and code.
Before we started, we thought about the key tenets on which to base our design. Among other tenets, we identified top goals, including:
- Security: Enterprise data has real value, and it requires strong security and governance.
- Agility: We’re launching a service in a high pace, highly innovative space. Its success depends on our ability to quickly iterate on its capabilities.
We chose to follow the SOLID design paradigm with the following concepts:
- The system should be composed of single-responsibility modules, each with clear functionalities.
- The system should be extensible over time without having to make dramatic modifications to the existing framework.
- The system and its subcomponents should define formal, precise, and verifiable contracts on how to use, without the need to understand the internal implementations.
- The system and its subcomponents should be loosely coupled.
Compared to traditional software system development, a unique challenge we’re facing in the AI field today is the much faster pace of scientific developments. New technologies emerge seemingly every week, and technologies created months ago will have capabilities that pale in comparison! So, it’s crucial for the system to be extendible and easy to iterate on.
To achieve these tenets and design principles, we broke down the service into the following building blocks that are extensible and pluggable:
- Agent core: The “brain” of our LLM agent is responsible for generating concepts, creating plans, choosing which course to take, parsing responses, and ultimately generating the final response back to the user.
- Memory: Think of this as our agent’s personal diary, but way cooler! It’s a storage system for chat histories, thoughts and plans, and the outcomes of actions.
- Knowledge base: Our secret stash of knowledge! These are external, private sources of information where our LLMs go to enhance their responses with more and better data tailored to our use case. This data source is often used to ground the model.
- Tools: These are like our agent’s superpowers! They’re extra functionalities that enhance the agent’s capabilities, allowing it to perform tasks beyond standard text generation, such as function calls for real-time information, running Python code, or accessing specific databases for up-to-date or specialized information.
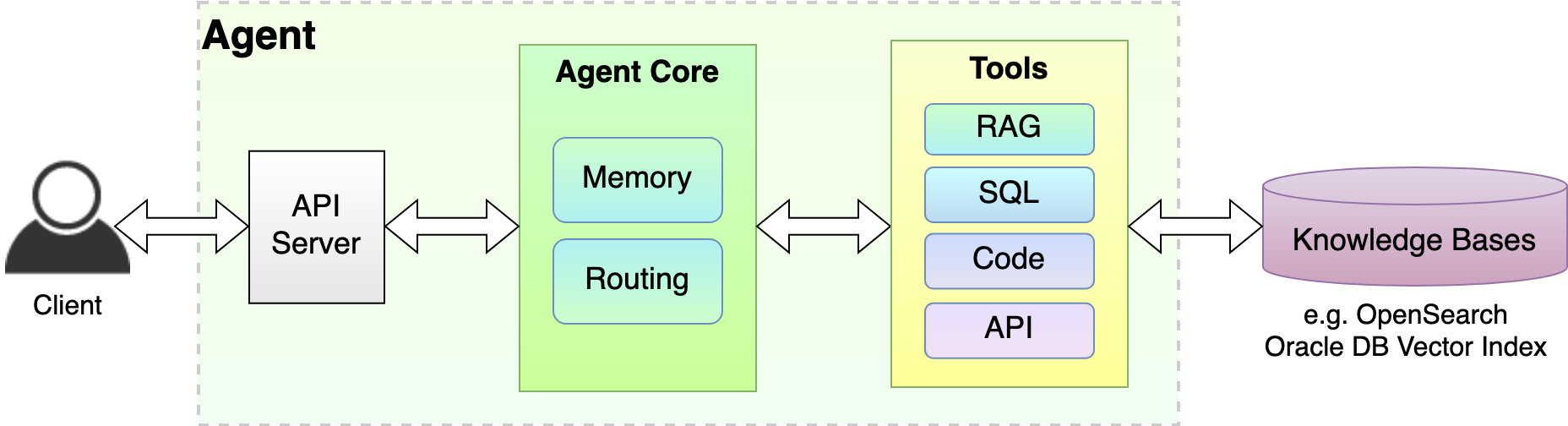
Figure 7: Agent service high-level architecture
Next, let’s look at the inner workings of the agent core and RAG retrieval tool.
Agent core internals
Agent core is the “brain” of this machinery. It must be highly customizable to accommodate various agent types. Here, the engineers and scientists collaborate closely to iterate the design and learn from each other. The engineers focus on system extensibility, scalability, observability, and latency, and the scientists focus on model choices, addressing long-tail business scenarios, model-level and end-to-end accuracy.
The following figure demonstrates how the agent core works internally:
- The orchestration loop is a continuous cycle where an agent observes its environment, decides on an action based on its observations and internal logic, performs the action, and then updates its understanding based on the outcome of the action and any new observations.
- The action router decides the process path and routes the request to corresponding component based on the action plan from the previous step.
- The action response parser parses the response from the action and feeds the information into the agent core for it to prepare for next iteration.
- The agent message generator creates the response back to the user and completes the current conversation turn.
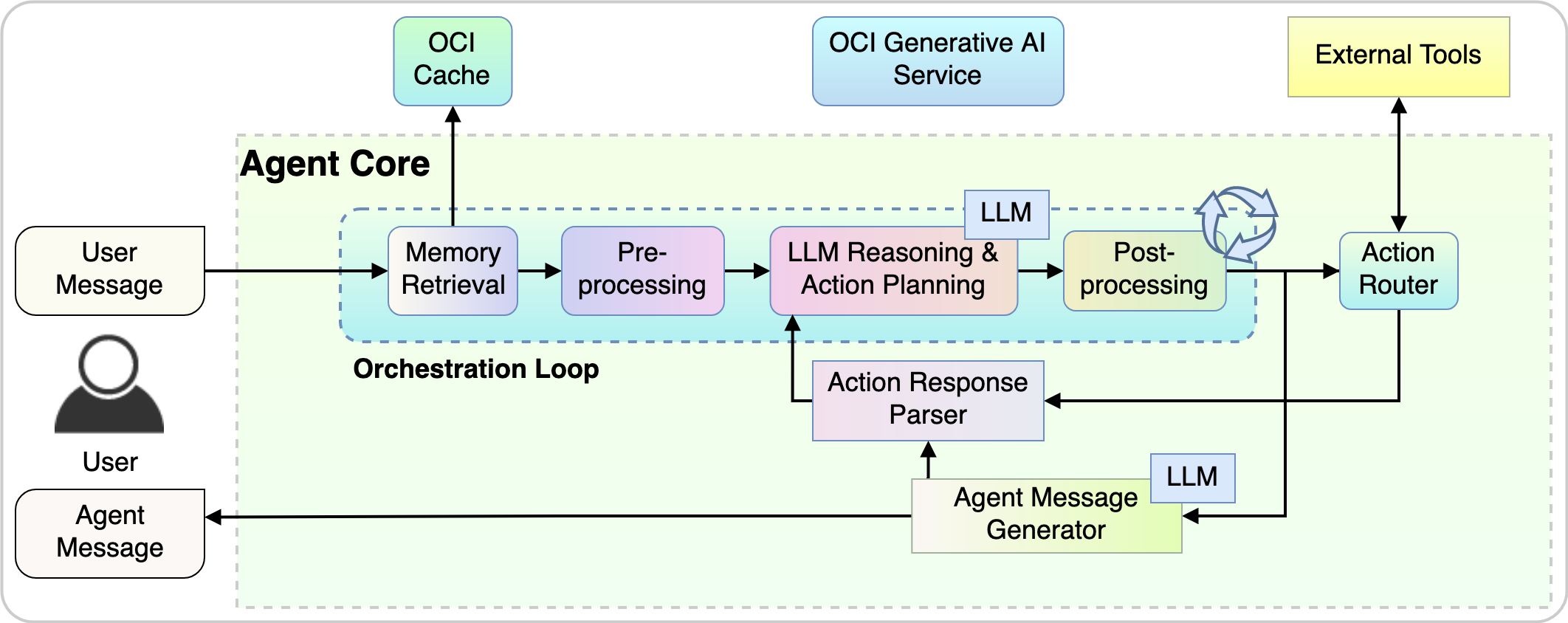
Figure 8: Agent core internal process
RAG retrieval tool Internals
A RAG agent’s agent core typically plans zero or multiple retrieval steps, optional tool processes, and a final generation step. The RAG retrieval tool is responsible for retrieving the relevant information from various data sources and serving it up for our RAG agent to work on. A generation LLM later uses this information to generate response to the user query.
We realized that RAG retrieval is the most critical portion to boost performance in terms of correctly answering a customer’s question. Knowledge retrieval isn’t a new problem; it has been well-studied and solved in the search engine field.
So, we borrowed the following key techniques from traditional search engines and applied them in our RAG Retrieval Tool:
- Query Rewriting: It takes the user’s query and converts it to make it just right for search. For example, reformatting and optimizing the user input query for OpenSearch search. Now, the queries are ready for the search showdown!
- Query Execution: Our RAG retrieval tool sends the prepared query to one or multiple knowledge bases to retrieve top-N relevant documents. It’s like sending out our search squad on a mission to find what it needs.
- Document reranking: After our search squad comes back with their findings, it’s time to polish the search results, ensuring that they’re sorted according to some complementary criteria.
- Knowledge bases: Customers can bring their own OCI with OpenSearch instance where all documents are already indexed and ready. They can also hook their data in an Object Storage bucket, which is automatically ingested into a service managed knowledge base.
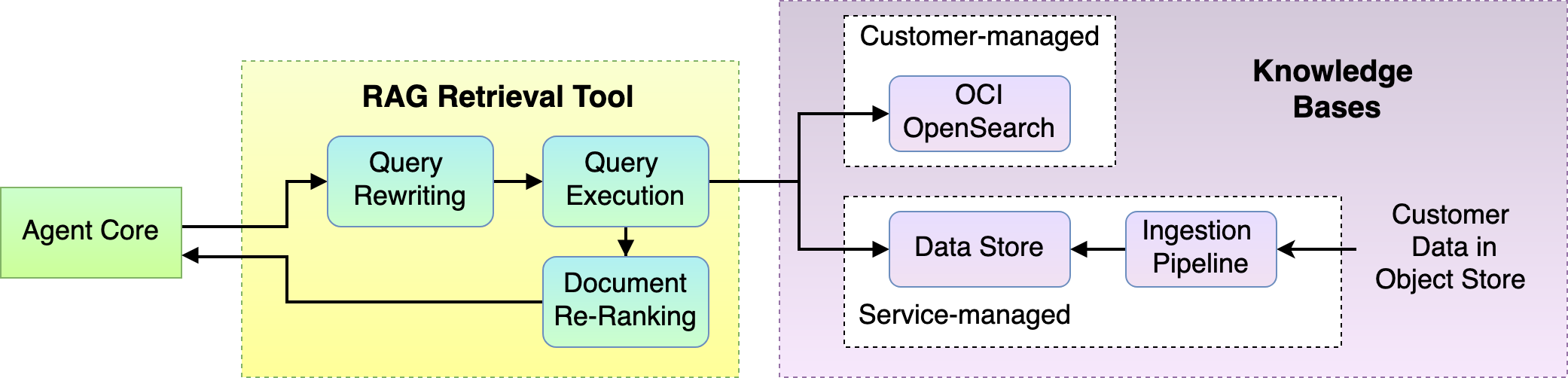
Figure 9: Internal RAG retrieval tool process
Gen AI Agent with RAG enables conversation fidelity
What are some of the areas that customers deeply care about? We learned that multiturn conversation, data processing and protection, correctness, and safety are among the top priorities. As a result, we invest heavily in those areas to help ensure that the GenAI Agent service performs satisfactorily.
Multiturn conversation
We designed the RAG agent to handle higher fidelity for multiturn conversations. Each turn’s input and output are stored in the memory. The agent in the query rewriting step takes current the user query and the preceding conversation as input and produces a search query relevant to the entire conversation.
In our example OCI Support use case, the following list shows how each turn’s input query was rewritten. Turn 2 and 3 rewrites include important information from previous steps (both requests and responses) that are critically needed for generating subsequent queries.
- Turn 1: “My compute VM is unreachable. Please help.” becomes “Compute VM is unreachable.”
- Turn 2: “Ok, I am not familiar with step 1, can you help with that?” becomes “Check infrastructure health metrics Oracle Cloud.”
- Turn 3: “Wow, there are a lot of metrics here. Which ones can help for my issue?” becomes “Important metrics for unreachable VM”
The conversation flows seamlessly with each turn building on the last.
The following diagrams shows how Turn 2 in this example works inside the RAG agent:
- The original user query is written to a system-generated search query, which is sent to knowledge base to retrieve relevant documents. The query rewriting step incorporates awareness of preceding conversations into the search term.
- The retrieved documents are reranked, taking inputs of both the embeddings of those documents, the embeddings of user query, and the rewritten query.
- After reranking, the top three documents and all the context information are fed into the response generation LLM.
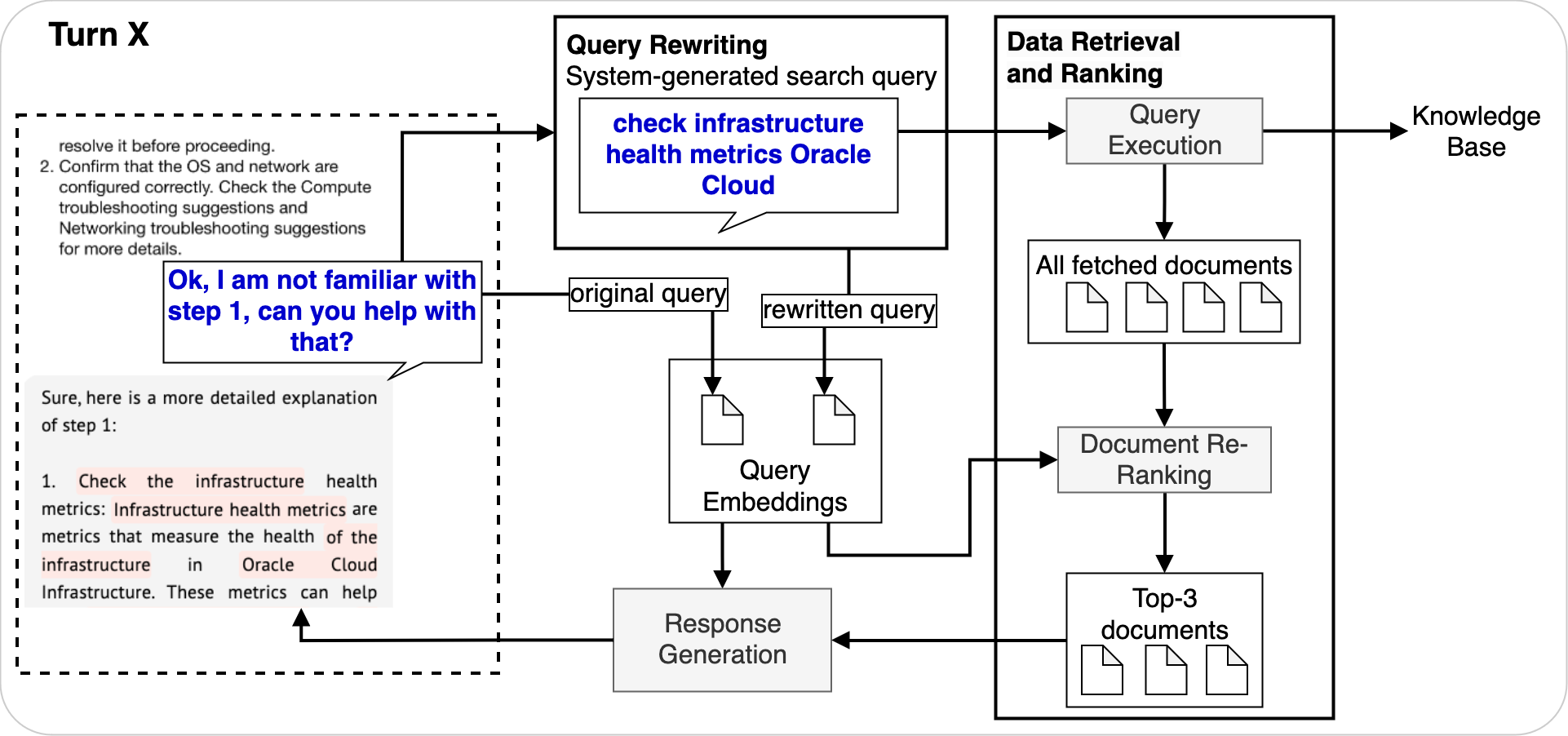
Figure 10: Multiturn RAG retrieval and generation
Data processing and protection
Using OCI with OpenSearch, our agent service indexes and stores unstructured data, providing swifter and more accurate retrieval capabilities. With OCI with OpenSearch’s granular access control, a customer has strong control over its data from a management perspective at both indexing and query time.
Customers have choices with their data. They can choose to link the RAG agent to their existing unstructured data in OCI with OpenSearch Cluster or in Object Storage. Their data will be processed in isolated workloads, and the service only retrieves data based on queries and context during a real-time conversation.
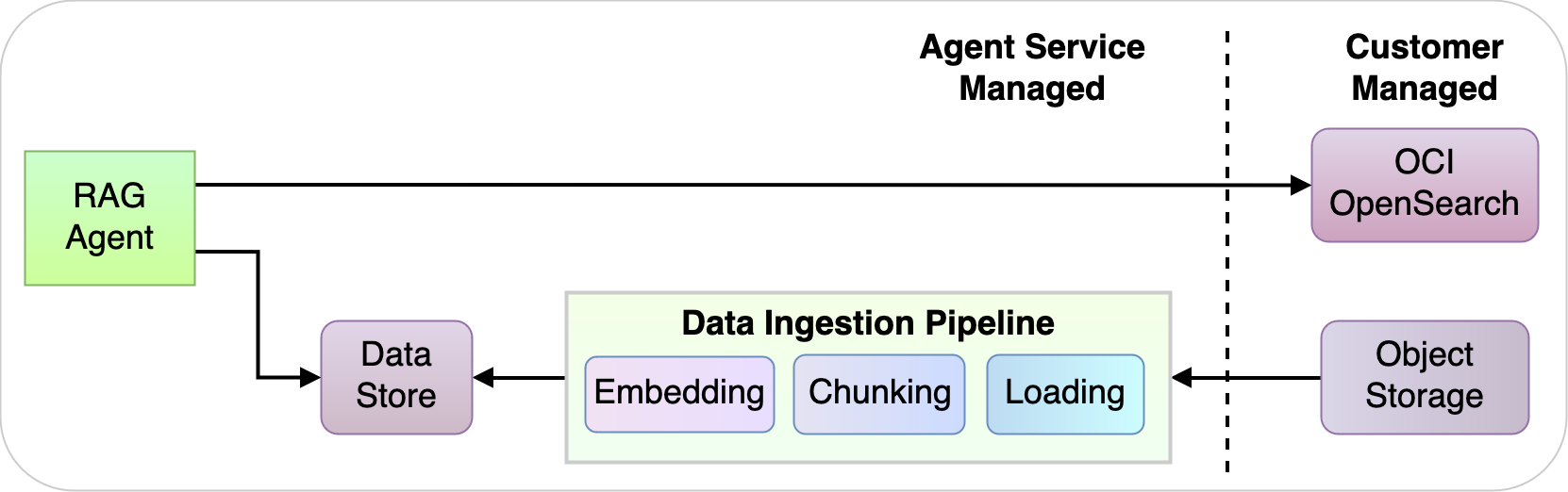
Figure 11: RAG agent data ingestion and retrieval
Model accuracy
No LLM will ever have full accuracy. However, to promote enterprise adoption, improved accuracy can be achieved through a variety of techniques, including RAG. Our GenAI RAG agent implements data-grounded generation to help reduce hallucinations. We also included an output guardrail to help with the following validations:
- Takes the input of the user query, the retrieved supporting contents, the generated response
- Produces scores to indicate the quality of the generated response in multiple dimensions, such as helpfulness, groundedness, and accuracy.
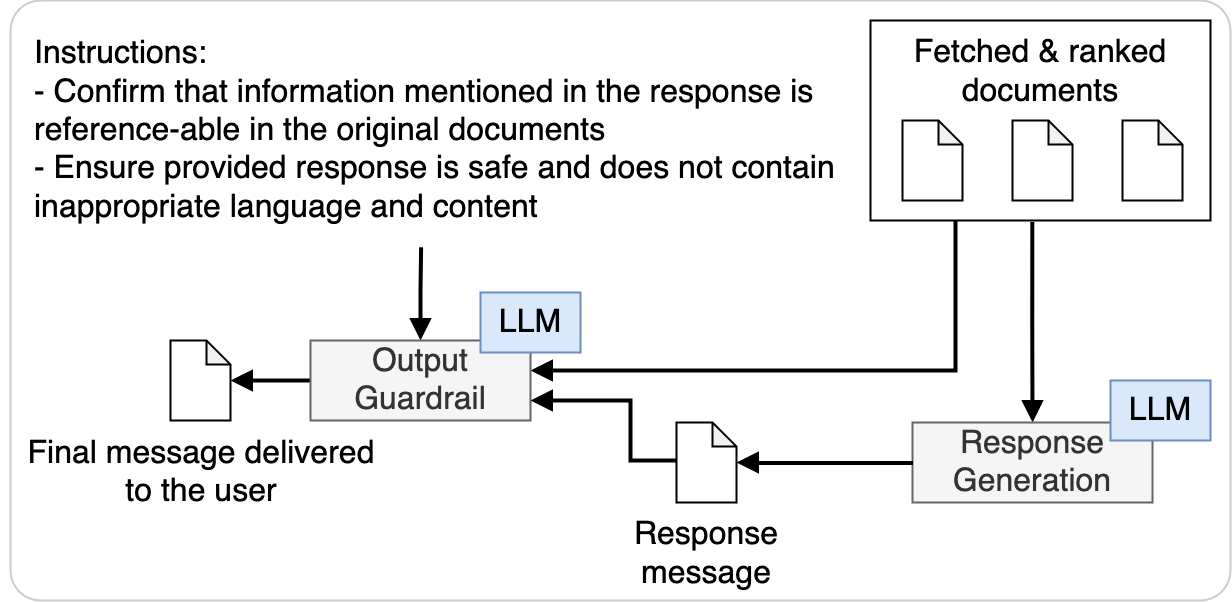
Figure 12: RAG agent output validation
The GenAI Agent framework can also use tools to provide transparent ways to course-correct the behavior, leading to even more seamless interactions.
The following example shows an agent with SQL functionalities, including SQL generation, correction, SQL execution, and response generation.
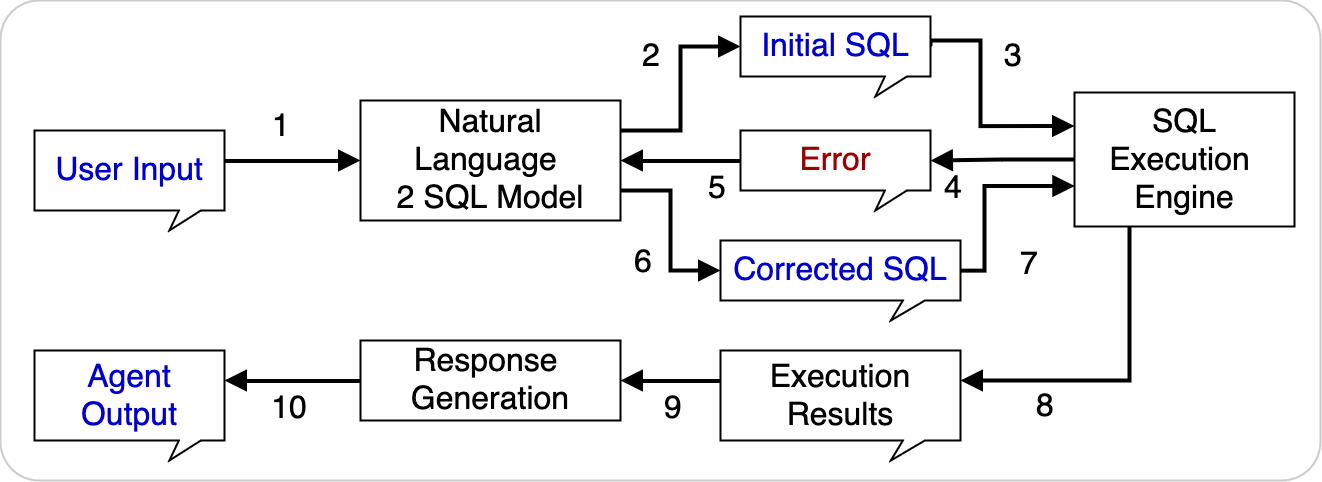
Figure 13: Agent with SQL functionalities
Extensibility and next steps
Looking forward, we’re excited to further extend the GenAI Agent framework to solve business use cases beyond RAG.
The first extensibility point is tools. We can use more types of tools to achieve various business goals.
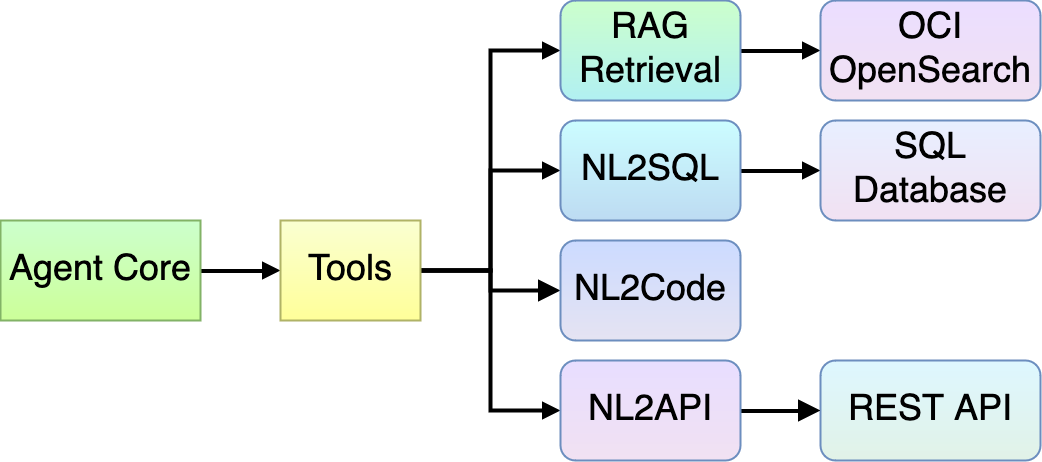
Figure 14: Agent extension — Tools
The second extensibility point is knowledge bases. RAG capabilities can be improved with more and better knowledge bases, including from unstructured, semistructured, and structured data to multimodality data. You can use various indexing and retrieval techniques, such as hybrid search, combining the benefits of keyword and semantic search, and various embedding models.
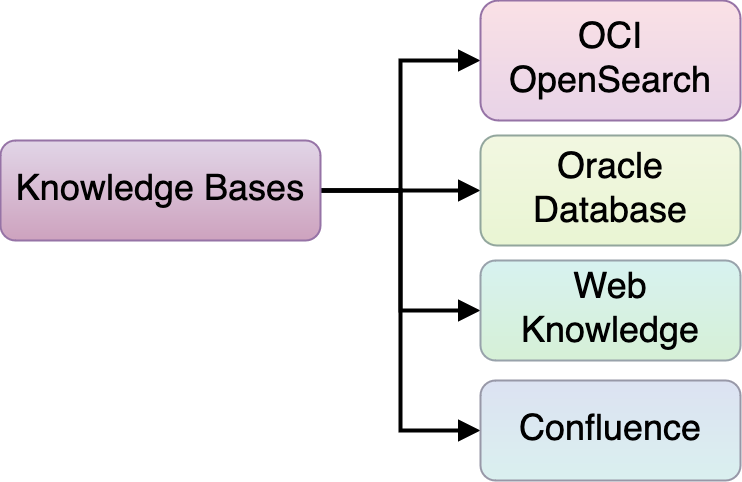
Figure 15: Agent extension — Knowledge bases
Conclusion
Our implementation of the intelligent agents paradigm in the OCI Generative AI service represents a transformative step forward in how technology can autonomously interact with and understand its environment to deliver more precise, efficient, and personalized solutions. By utilizing the capabilities of intelligent agents, our service enhances the user experience through dynamic and adaptive responses and sets a new standard for efficiency when it comes to dealing with large amounts of data. The potential for growth and innovation within this framework is immense.
As we continue to refine our algorithms and expand our service’s capabilities, we remain committed to pushing the boundaries of what intelligent agents can achieve, ensuring our service remains at the forefront of technological excellence. This journey into the realm of intelligent agents isn’t just about improving a service, but about reshaping how we think about and interact with technology.
Generative AI Agent enables customers with the following capabilities:
- The RAG paradigm combines the power of conversational AI to “chat with the data,” using up-to-date and contextually rich data.
- GenAI Agents reduce complexity to launch AI applications by configuring and connecting the service to knowledge bases.
- GenAI Agents implement several techniques like query rewriting, semantic reranking, and output guardrails to enable high-fidelity, multi-turn conversations that have improved contextual accuracy.
What are some problems that you’re currently solving that can use an OCI Generative AI RAG agent or other agent types? Feel free to reach out to us for discussions. For more information, see the following resources:

