この記事は”Ludovico Caldara“による”In-database AI inference on Oracle Active Data Guard: A practical walkthrough“の日本語翻訳版記事です。
2025年11月21日
前回の記事「Oracle Active Data Guardで実現するアプリケーションとAIのスケーラビリティ」では、Oracle Active Data Guardが提供するオフロード機能について解説しました。
AI推論処理をOracle Active Data Guardにオフロードすることで、エンタープライズ・アプリケーションにおいて、より安全かつコスト効率の高い運用が可能になります。
本記事では、考えられるユースケースを紹介し、実際に試せるコードも掲載しています。さらに、画像とテキストの埋め込みを組み合わせたマルチモーダルモデルも利用し、より実践的な内容にしています。
なぜAI推論をデータベース内で実行するのか?
AI推論をサードパーティのAPIやパブリック・エンドポイントではなく、Oracle AI Database内で直接実行することで、プライバシーや効率性が向上し、システムの複雑さやコストも多くの場合で削減できます。
💰 コスト削減:
外部APIやGPUクラウドサービスは、データ量が増えるにつれて非常に高額になることがあります。GPUの供給が安定しない場合もあり、未使用のGPUリソースはコスト効率が悪くなります。一方、データベース内での推論は、既存のハードウェアを活用し、最適化されたONNXモデルをデータベースエンジン内で実行できます。
👮 セキュリティとガバナンスの強化:
データはデータベース内から外部に出ることがありません。ネットワーク経由の通信や大量のデータ転送(オンプレミス内も含む)を排除でき、データ漏えいのリスクを低減できます。
🏄♂️ 運用のシンプル化:
外部ネットワークへの通信やAPIキー管理、ETL作業が不要です。AIパイプラインをデータの近くで実行でき、通常はSQLクエリに直接AI処理を組み込むことも可能です。これにより、Oracleの高度なセキュリティや監査機能も活用できます。
コストとパフォーマンスのバランス
確かに、大規模モデルの処理にはGPUが高速ですが、GPUは高価で専門的な管理も必要となります。そして、すべてのケースで必ずしもGPUが必要とは限りません。多くの人気ONNXモデルは、CPU上でも十分に効率良く動作します。
AI推論のスケーリングとActive Data Guardへのオフロード
AI推論はCPU負荷の高い処理のため、適切なキャパシティ管理が重要です。CPUが逼迫した場合は、Oracle Real Application Clusters(RAC)を利用することで、CPUリソースを大幅に拡張できます。また、AIワークロード専用のクラスタサービスを実行したり、CPU要件に合わせてサービスを再配置したりできます。
以下のような場合は、Oracle RACによるスケールアウトが効果的です:
- リアルタイム推論が必要な場合
- Exadata Database Servicesなど、スケーラブルなインフラ上にデプロイしている場合(Base Database Servicesは非対応)
- 書き込み負荷の高いデータパイプラインを運用している場合
- Active Data Guardで利用できない特殊な機能やPL/SQLパッケージ(例:DBMS_SCHEDULERやDBMS_PARALLEL_EXECUTEなど)を使用する場合
リアルタイムトランザクションの場合はプライマリデータベース上でモデルを実行できますが、バルク処理やベクトル検索、非同期推論などのワークロードは、Active Data Guardのスタンバイデータベースで実行するのが最適です。スタンバイデータベースをAI推論に活用できると、ニーズに応じた最適なバランスを取ることができます。
Active Data Guardへのオフロードが適しているケース:
- すでに参照専用ワークロードのオフロード戦略がある場合
- スタンバイデータベースが未利用または利用率が低い場合
- RACインフラがスケールできない(ODA、BaseDB など)場合や、コストや承認の問題でシステム拡張が難しい場合(例:1/2ラックからフルラックへ移行できない)
- プライマリが高パフォーマンスを要し、負荷の影響を避けたい場合
スタンバイデータベースへAIワークロードをオフロードすると、AI処理はプライマリのリソースと競合しません:
🚀 本番システムの高速性と安全性を維持
📊 AIモデルは引き続きデータの近くで実行
🔄 スタンバイリソースを最大限活用
実践ガイド:Active Data Guardを使ったセマンティック検索による画像検索
この例では、Active Data Guard構成のOracle AI Databaseがあり、プラガブルデータベースやロールベースサービスがすでに適切に設定されていることを前提としています。
ステップ1:アプリケーションユーザー(ADGVEC)の作成
-- run this script as a DBA on the primary PDB
create user adgvec identified by &adgvecpass;
create role vec_role not identified;
-- most developer require these grants:
grant db_developer_role to vec_role;
-- usage of ONNX models:
grant create mining model to vec_role;
-- optional: grants for Application Continuity:
grant keep date time to vec_role;
grant keep sysguid to vec_role;
grant vec_role to adgvec;
alter user adgvec quota unlimited on users;
ステップ2:画像とベクトル用のスキーマを作成する
-- run this script as the user (ADGVEC) on the primary PDB
-- contains the images
create table if not exists pictures (
id number primary key,
img_size number,
img blob
);
-- contains vector embeddings (1:1 relation with pictures)
create table if not exists picture_embeddings (
id number,
embedding vector,
constraint picture_embeddings_pk primary key ( id ),
constraint picture_embeddings_fk foreign key ( id ) references pictures ( id )
);
ステップ3:ONNXモデルの準備とロード
OML4Pyを使って、あらかじめ設定されたClipモデルをエクスポートし、ロードします。
from dotenv import load_dotenv
from oml.utils import ONNXPipeline
import oml
db_user = os.getenv('DB_USER')
db_password = os.getenv('DB_PASSWORD')
db_dsn = os.getenv('DB_DSN') # Use the DSN of the primary PDB
pipeline = ONNXPipeline("openai/clip-vit-large-patch14")
oml.connect(db_user, db_password, dsn=db_dsn)
pipeline.export2db("clip")
完全なサンプルコードやドキュメントは、以下からご覧いただけます:
https://docs.oracle.com/en/database/oracle/oracle-database/23/vecse/onnx-pipeline-models-multi-modal-embedding.html
これにより、ユーザーは2つのONNXモデルを利用できるようになります。
select model_name, mining_function, algorithm, model_size from user_mining_models;
MODEL_NAME MINING_FUNCTION ALGORITHM MODEL_SIZE ---------- --------------- --------- ---------- CLIPIMG EMBEDDING ONNX 306374876 CLIPTXT EMBEDDING ONNX 125759349
ステップ4:画像データをpicturesテーブルにロードする
プライマリPDBのDSNを使用します。
'''
This python script inserts all the images as blobs into the pictures table using the oracledb driver.
'''
import os
import oracledb
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
# Database connection parameters and image directory
db_user = os.getenv('DB_USER')
db_password = os.getenv('DB_PASSWORD')
db_dsn = os.getenv('DB_DSN')
image_directory = os.getenv('IMAGE_DIRECTORY')
oracle_home = os.getenv('ORACLE_HOME')
oracledb.init_oracle_client(lib_dir=oracle_home)
# Establish a database connection
with oracledb.connect(user=db_user, password=db_password, dsn=db_dsn) as connection:
with connection.cursor() as cursor:
for filename in os.listdir(image_directory):
if filename.endswith('.jpg'):
image_id = int(os.path.splitext(filename)[0])
image_path = os.path.join(image_directory, filename)
with open(image_path, 'rb') as image_file:
image_data = image_file.read()
image_size = len(image_data)
try:
# Insert the image data into the 'pictures' table
cursor.execute("""
INSERT INTO pictures (id, img_size, img)
VALUES (:id, :img_size, :img)""",
{'id': image_id, 'img_size': image_size, 'img': image_data})
except oracledb.IntegrityError as e:
error_obj, = e.args
if error_obj.code == 1: # ORA-00001: unique constraint violated
print(f"Skipping image {filename}: ID {image_id} already exists.")
else:
raise
print(image_id)
# Commit the transaction
connection.commit()
本番環境では、業務プロセスの一環としてドキュメントがデータベースに格納されていることが前提となります。
ステップ5:process_embeddingプロシージャの作成
プライマリPDB上でプロシージャ定義を作成します。
/*
This script creates a procedure that process the embeddings of the images in the pictures table and insert them via DML redirection.
*/
CREATE OR REPLACE PROCEDURE process_embeddings (
p_batch_size IN PLS_INTEGER,
p_iterations IN PLS_INTEGER
) AS
TYPE t_embedding IS RECORD (
id pictures.id%TYPE,
embed_vector picture_embeddings.embedding%TYPE
);
TYPE t_embedding_table IS TABLE OF t_embedding;
v_embeddings t_embedding_table;
v_batch_count PLS_INTEGER := 0;
v_total_processed PLS_INTEGER := 0;
v_continue BOOLEAN := TRUE;
CURSOR c_embeddings IS
SELECT c.id,
vector_embedding(clipimg USING img AS data) AS embed_vector
FROM pictures c
LEFT OUTER JOIN picture_embeddings v ON c.id = v.id
WHERE v.id IS NULL AND c.img IS NOT NULL and c.id IS NOT NULL;
BEGIN
OPEN c_embeddings;
EXECUTE IMMEDIATE 'ALTER SESSION ENABLE ADG_REDIRECT_DML';
LOOP
FETCH c_embeddings BULK COLLECT INTO v_embeddings LIMIT p_batch_size;
EXIT WHEN v_embeddings.COUNT = 0;
FOR i IN v_embeddings.FIRST .. v_embeddings.LAST LOOP
DBMS_OUTPUT.PUT_LINE('Processing ID: ' || v_embeddings(i).id);
INSERT INTO picture_embeddings (id, embedding)
VALUES (v_embeddings(i).id, v_embeddings(i).embed_vector);
END LOOP;
COMMIT;
v_total_processed := v_total_processed + v_embeddings.COUNT;
v_batch_count := v_batch_count + 1;
IF p_iterations > 0 AND v_batch_count >= p_iterations THEN
v_continue := FALSE;
END IF;
EXIT WHEN NOT v_continue;
END LOOP;
CLOSE c_embeddings;
END process_embeddings;
/
このプロシージャでは、「ALTER SESSION ENABLE ADG_REDIRECT_DML」を使用してDMLリダイレクトを有効にしています。
セッションでDMLリダイレクトが有効になると、VECTOR_EMBEDDING()による埋め込み生成を含むすべてのSELECT文はスタンバイデータベース上で実行され、DML文(この例ではINSERT)はプライマリデータベース上で実行されます。
ステップ6:Active Data Guard上でプロシージャを実行する
この手順はActive Data Guardスタンバイデータベースから実行します。
EXECUTE process_embeddings(p_batch_size => 10, p_iterations => 100);
これにより、CPU負荷の高い埋め込み生成処理をスタンバイデータベース側にオフロードすることで、プライマリ側は基幹業務やトランザクション処理用のリソースを確保できます。
また、埋め込み生成処理は、スタンバイデータベースの数に応じてリニアにスケールできます。
以下の2つの画像は、シングルスレッドでバッチ実行した際のプライマリおよびスタンバイデータベースの負荷を示しています。
プライマリのワークロード例:
スタンバイのワークロード例: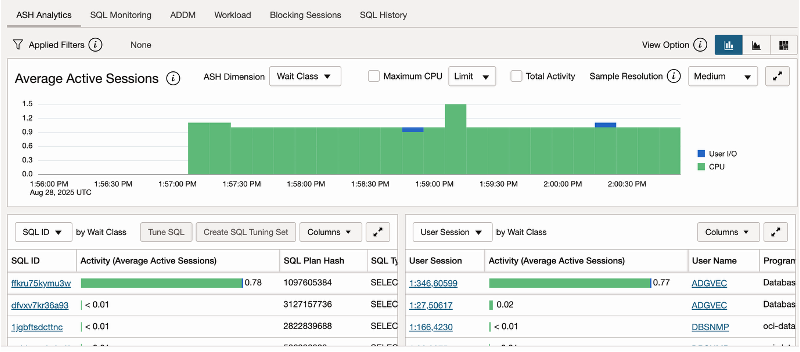
ステップ7:Active Data Guardでセマンティック検索を実行する
スタンバイデータベース上で、テキストの説明に合致する画像をセマンティック検索で探します。
SELECT c.id, c.img, VECTOR_DISTANCE( v.embedding, VECTOR_EMBEDDING(cliptxt USING 'a blue bird' AS data), COSINE ) AS distance FROM pictures c JOIN picture_embeddings v ON c.id = v.id ORDER BY distance FETCH FIRST 10 ROWS ONLY;VECTOR_EMBEDDING(cliptxt USING 'a blue bird' AS data)は、検索クエリ(この例では “a blue bird”)を画像の埋め込みベクトルと同じ空間にエンコードします。VECTOR_DISTANCEは、セマンティック的に最も近い画像を検索します。
AIベクトル検索は、スタンバイデータベース内で安全に実行されます。外部APIを使用せず、プライバシーリスクもありません。
アプリケーションのバックエンドは、同様のSQLクエリを使ってスタンバイデータベースから画像を取得でき、外部エンドポイントや別の言語を使う必要はありません。シンプルですね。
アプリケーションのフロントエンドは、バックエンドAPIを利用して画像の検索や表示を行います。
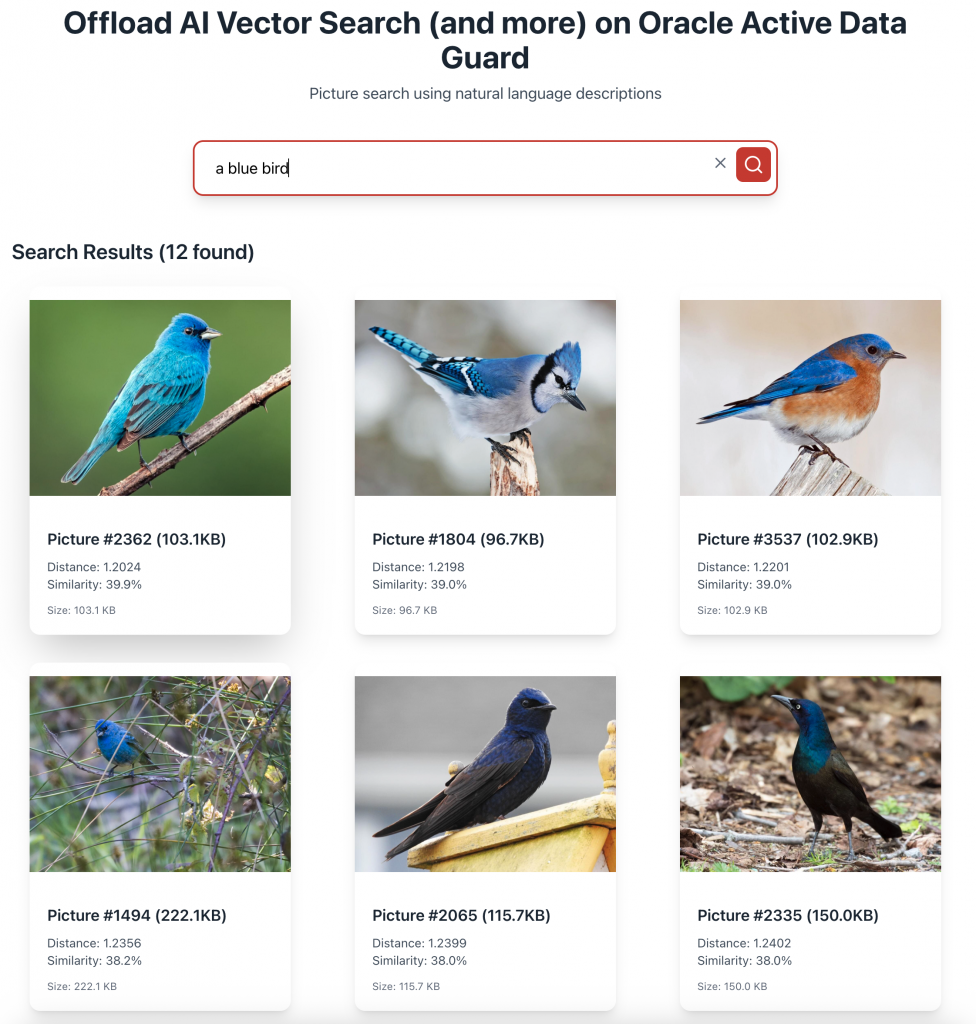
さあ、構築を始めましょう
ここまでで、Oracle AI Database、ONNX Runtime、そしてActive Data Guardを組み合わせることで、データベース内でマルチモーダルAIを実現できる強力な環境が構築できることをご紹介しました。主なメリットは次の通りです。
- 外部通信なしでインライン推論を実行
- プライマリデータベースへ影響を与えずリソースを最大限活用
- シンプルなアーキテクチャによるコスト削減の可能性
- セキュリティとガバナンスの強化
詳細なサンプルコードやReactアプリの例は、adg-vector GitHubリポジトリでご覧いただけます。
