※ 本記事は、Egor Pushkin, Pradeep Vincentによる”First Principles: Exploring the depths of OCI Generative AI Service“を翻訳したものです。
2024年4月22日
Generative AIは、すでに人間の生産性と自動化に大きな影響を与えています。業界全体で常に新しいアプリケーションが登場しています。ただし、効果的なGenerative AIソリューションの実装と導入には、多くの特別な労力が必要になる場合があります。企業は、機械学習(ML)モデルのチューニングとデータキュレーションを行い、特定の業界やアプリケーションを解決するためにモデル出力を評価する方法を学ぶ必要があります。また、GPUや非常に高性能なネットワークなどの特殊なインフラストラクチャのインストールと継続的な管理にも投資する必要があります。
OCIは、その特殊なAIインフラストラクチャを提供します。OCI Generative AI Serviceの導入により、OCIはGen AIモデルのチューニングとホスティングのためのフルマネージド・フレームワークを提供するようになりました。これにより、カスタマイズされたGen AIソリューションを導入するための顧客の労力とリード・タイムが、数か月ではなく数日または数週間に短縮されます。
このブログ投稿では、OCI Generative AIサービスの内部動作について説明します。サービスのAIモデルの容易なカスタマイズ、複数のFine-tunedモデルのためのコスト効率の高いホスティング、および企業の採用のための重要な機能の詳細を説明します。
Generative AI
Generative AIは、人間が理解できるクエリに応えて、テキスト、画像、ビデオなど、コンテンツを個別に生成できるMLアルゴリズムのカテゴリを網羅しています。新しいコンテンツを作成する能力により、AIのリーチを超えた複雑な複雑な複雑なタスクが最近実現可能になりました。Generative AIは、書面によるテキストの作成、SQLクエリの策定、コードの開発、アートの生成、カスタマー・サポートやその他のタスクの支援を行うことができます。その主な利点は、構造化データと非構造化データの両方に簡単にアクセスできることです。
その中核となるGenerative AIは、多様な情報を大量に収集した複雑なニューラル・ネットワーク・アーキテクチャを使用しています。モデルは、学習したパターンに基づいて最も可能性の高い次の要素を予測することで、新しい出力を作成できます。ほとんどのGenerative AIモデルは、入力シーケンスを出力に変換することによって動作します。これらは、順序から順序へのMLタスクのファミリに属します。応用例としては、機械翻訳や音声合成などがあります。
2017年、セミナル・ペーパー『Attention is All You Need』は、sequence-to-sequenceタスクの分野に革命をもたらしました。transformers architectureをMLモデルに導入しました。
transformersの中心は自己アテンションのメカニズムです。自己アテンションにより、入力シーケンス内のコンテキスト関係を高い効率で理解できます。以前のモデルとは異なり、Transformersは、入力シーケンスを一度に全面的に処理できるため、並列化と効率性が大幅に向上します。これらのモデルは、複数のレイヤーで構成され、広範囲のデータセットに対して効果的なスケーリングとトレーニングを行うことができます。
transformerアーキテクチャの自己アテンション機能は、大型言語モデル(LLM)の誕生につながるモデルのサイズを拡大しました。 もともとテキスト合成に使用され、LLMは現在、スピーチ、ビジョン、ゲノム、ロボティクス、およびその他のデータ・モーダリティで広く使用されています。LLMは、オリジナルのtransformerアーキテクチャを非常に密接に模倣する大きなtransformerモデルです。

図1: Transformerモデルのアーキテクチャ
図1は、「Hello, how are…」という文を文の次の単語として「you doing?」と予測して完了できるtransformerモデルの例を示しています。transformerアーキテクチャには、エンコーダとデコーダの2つの主要部分があります。エンコーダ部は、入力シーケンスを高度にコンテキスト化された一連の埋め込みに変換するtransformer層のスタックによって表されます。デコーダ部は、これらの埋め込みを入力として受け取り、一度に1つのトークンを生成するトークンの出力シーケンスを繰り返し生成します。以前に生成された出力シーケンスの要素も、各ステップでデコーダに戻されます。このようにコンテンツを生成する方法は、自動進行と呼ばれます。
LLMの革新的な機能により、さまざまなアプリケーションに対して非常に効果的です。エンタープライズ・アプリケーションは、通常、誤りや創造性の誤りに対する許容度がほとんどありません。企業はカスタマイズを要求し、AIアプリケーションを厳しい精度基準に保ちます。これらのシナリオでは、必要なモデルの精度を達成するには、結果の正確さだけでなく、その安全性と説明責任も含まれます。
Fine-tuningでLLMを調整し、専門的なトレーニングデータを使用すると、LLMの推論結果の精度と妥当性が向上します。Oracleでは、人材管理(HCM)、サプライチェーン管理、カスタマー・エクスペリエンスなどのアプリケーション向けに、基本的なジェネレーティブAIモデルをFine-tunedしました。ユース・ケースの例として、ジョブ摘要の作成、候補者エクスペリエンスの要約、チャットの要約、営業会議での支援などがあります。これらの用途では、系統的なデータ・キュレーション方法によるFine-tuningを採用することで、アプリケーションの精度が明らかに向上しました。
Generative AIアプリケーション・ワークフロー
Generative AIアプリの成功の鍵は、強力なベース・モデルと、さまざまなアプリケーションに合わせてカスタマイズする機能を組み合わせることにあります。このカスタマイズには、キュレートされたトレーニング・データを使用したベース・モデルの反復的なFine-tuningが含まれます。図2は、候補者の評価サマリーを作成するためのGenerative AIの使用方法を示しています。このシナリオでは、顧客がLLMで実行できるタスクを策定します。このステップは、関連する入力データで使用するモデルの入力プロンプトの定義から始まります。
図2は、候補者の評価サマリーを生成するためのタスクの詳細なプロンプトを示しています。プロンプトには、タスクの概要、注意を払う履歴書のセクションに関するモデルの指示、および出力での入力の表示方法に関するオプションのいくつかの例が表示されます。最後に、候補者の履歴書がランタイム・システムによってプロンプトに追加されます。
図2: Generative AI候補の評価サマリー
図3は、Generative AIアプリケーションの高レベルのワークフローを示しています。タスクが策定されると、顧客はベース・モデルの初期評価を実行します。このプロセスでは、モデルを介して一連の既知の入力を実行し、モデル・レスポンスとground truthの正解を比較します。たとえば、履歴書の分析における有効性についてモデルを評価する場合、一連の履歴書を顧客が繰り返し処理し、その要約を手作業で作成したものと比較します。このフェーズには通常、ベース・モデルの精度を向上させることができるプロンプト・チューニングが組み込まれます。

図3: Generative AIアプリケーション・ワークフロー
ベース・モデルが定義済の基準に基づいて十分に正確な結果を得られない場合は、Fine-tuningが必要になる場合があります。Fine-tuningでは、少量のトレーニング・データを収集して、特定のドメインに対するモデルの必要な動作を示します。図4は、Fine-tuningに必要なステップを示しています。

図4: Fine-tuningによるGenerative AIアプリケーション・ワークフロー
モデルが評価に合格すると、実際の本番トラフィックに対応できる推論エンドポイントの形式で推論用にデプロイできます。図5は、推論サービスの設定に関連するステップを示しています。

図5: 推論を伴うGenerative AIアプリケーション・ワークフロー
OCI Generative AI
Oracleの最新のGenerative AI製品は、包括的なマネージド・サービスです。これは、Oracleテクノロジ・スタック全体にわたる様々なGenerative AI機能の基盤を形成します。OCI Generative AIは、ビジネス用途、顧客重視の包括的な戦略、データ・プライバシーと管理に重点を置いた主要なモデルを備えており、ヘルプの記述、コンテンツの要約、会話型インタフェースなどの幅広いビジネスAIアプリケーションの促進に際立っています。
このサービスにより、特定のタスクのベース・モデルのカスタマイズとFine-tuningが可能になり、実際のエンタープライズ・ユース・ケースでより効果的になります。このFine-tuningプロセスには、専門知識とコラボレーションが必要です。OracleはCohereと提携し、エンタープライズ・アプリケーションにLLMを適応させ、調整しました。お客様は、Cohereモデル、そのFine-tuning戦略、およびMeta’s Llama 2などの他のモデルを使用できるようになりました。
OCI Generative AIサービスでは、モデルと推論のFine-tuningに使用される顧客データは、顧客のアプリケーションの外では使用されません。データはプライベートのままです。Generative AIサービスは、カスタマイズされた複数のモデルをコスト効率の高い方法でホストでき、基盤となるスタックを使用して、NetSuite、Fusion Apps、Healthcareなど、多くのOracle ApplicationsにGenerative AI機能を提供しています。
Generative AIは、超高性能を実現するために、クラスタ・ネットワークと相互接続されたGPUで構成される特殊なインフラストラクチャを必要とします。OCIは、2マイクロ秒以下のネットワーク・レイテンシを実現できる、業界をリードするRDMAスーパー・クラスタ・ネットワークを誇っています。お客様がOCI Generative AIサービスのインフラストラクチャを設定すると、専用GPUとGPUを接続するための専用RDMAクラスタ・ネットワークを含む専用のAIクラスタが自動的に確立されます。図6に示すように、顧客のGenerative AIタスクに割り当てられたGPUは、他のGPUから分離され、この専用AIクラスタは顧客のFine-tuningおよび推論ワークロードをホストします。

図6: 専用AIクラスタGPUプール
OCIでは、顧客ワークロードのセキュリティとプライバシーが重要な設計方針です。お客様は、Generative AIモデルのFine-tuningや推論時にデータを使用できます。図7に示すように、顧客のデータ・アクセスは顧客のテナンシ内で制限されるため、ある顧客のデータが別の顧客に表示されません。顧客のテナンシ内から作成およびホストされたカスタム・モデルには、顧客のアプリケーションのみがアクセスできます。

図7: 顧客データとモデルの分離
強力なデータ・プライバシとセキュリティをさらに促進するために、専用のGPUクラスタは、1つの顧客のFine-tunedモデルのみを処理します。
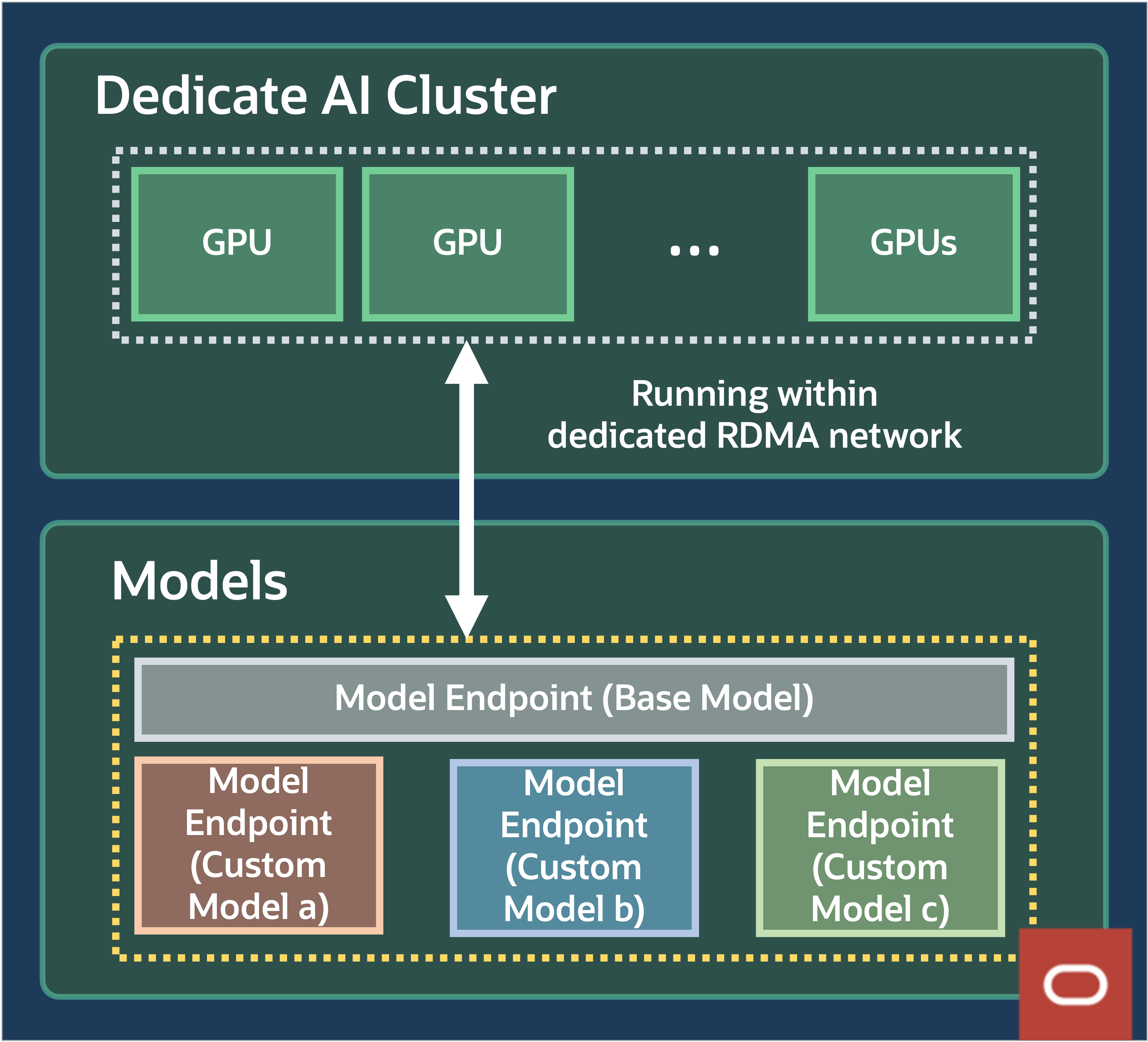
図8: モデル・エンドポイントの例
例として、図8では、同じベース・モデルから作成された3つのFine-tunedモデルを持つベース・モデルがあり、顧客は4つのモデルのそれぞれにモデル・エンドポイントを作成します。4つのエンドポイントすべてが同じクラスタ・リソースを共有し、専用のGPUクラスタで基礎となるGPUを最も効率的に利用します。お客様は、ビジネス・ニーズに基づいて、数十または数百の微調整モデルを作成して、単一の専用AIクラスタにデプロイできます。
このサービスは、OCIエコシステムを利用して、データ・ガバナンスを提供します。図9に、高レベルのアーキテクチャが表示されます。OCIのIdentity and Access Management (IAM)サービスと完全に統合されており、お客様のデータ・アクセスに対する適切な認証と認可を確保できます。OCI Key Managementは、基本モデル・キーを安全に格納します。Fine-tuned顧客モデルは、デフォルトで暗号化されてObject Storageに格納されます。

図9: OCI Generative AIセキュリティ・アーキテクチャ
Fine-tuning
従来、MLモデルのFine-tuningでは、元のベース・モデル内のほとんどのパラメータを変更して、その機能を変更し、特定のアプリケーションやタスクに合わせて調整することが容易になりました。OCI Generative AIサービスの領域では、この手法がサポートされ、Vanilla Fine-tuningと呼ばれます。このFine-tuningプロセスは優れた品質を提供しますが、時間がかかり、大量のリソースが必要となり、反復サイクルが長くなります。さらに、この方法を使用して作成されたすべての洗練されたモデルに特定のGPUリソースを割り当てることで、顧客に多額の費用がかかる可能性があります。
この課題を克服するために、OCI Generative AIサービスでは、パラメータ効率の高いFine-tuning(モデルの重みの一部のみを更新)に、T-Fewと呼ばれるメソッドを採用しています。この手法は、2022年の論文「Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning」で概説されています。従来のFine-tuning方法と比較して必要なトレーニング時間と計算リソースの両方を削減しながら、高精度を維持します。OCIはCohereと協力して、よりコスト効率の高いFine-tuningソリューションをクライアントに提供しています。このFine-tuning戦略を採用することで、お客様はコストを大幅に削減し、必要な高い精度を実現できます。

図10: T-few fine-tuning
図10に示すように、T-Few Fine-tuningプロセスは、基本モデルの初期重みと注釈付きトレーニング・データセットを利用することから始まります。この注釈付きデータは、T-Fewで実施される監視付きトレーニングで使用される入出力ペアで構成されます。このトレーニング・プロセスを通じて、モデル・ウェイトの補足セットが生成され、モデル・デプロイメント中にベース・モデルと組み合せて使用されます。
T-Few Fine-tuningは、ベースライン・モデルのサイズの約0.01%で構成される、より多くの重みを挿入する付加的なパラメータ効率の高いFine-tuning手法です。
さらに、Fine-tuningフェーズでは、重みの更新は、図11で境界が設定されているT-Few transformer層と呼ばれるtransformer層の特定のグループに限定されます。モデルのほとんどのレイヤーで更新を行うのではなく、更新はT-Fewレイヤーのみに限定されるため、トレーニングにかかる時間とコストを大幅に削減できます。
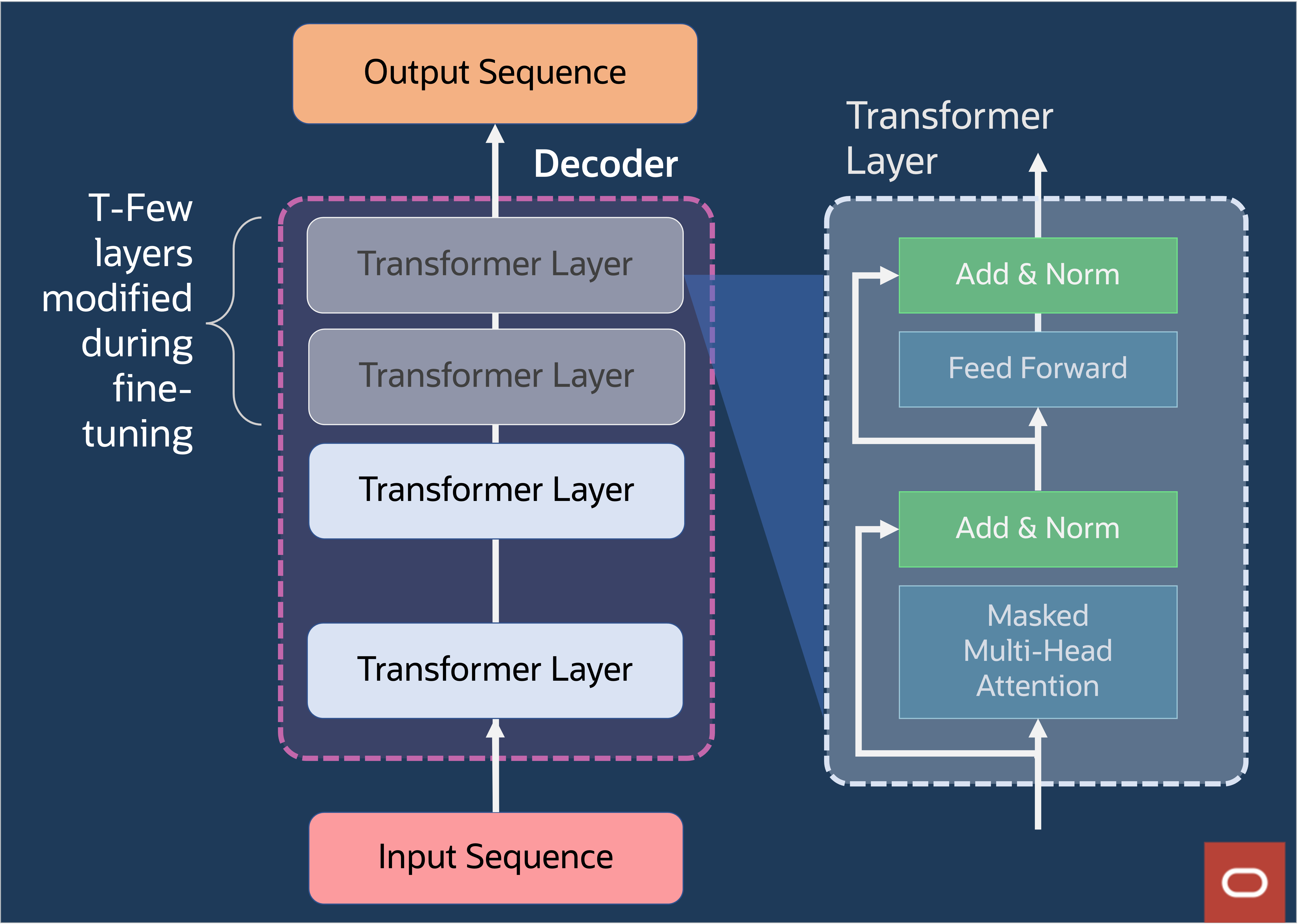
図11: Transformer層内部
図11は、transformer層の内部を示しています。transformer層は、transformerを通過する入力データに対して順番に実行される一連の操作で構成されます。具体的には、マルチヘッド・アテンションとレイヤーの正規化、フィード・フォワード・ネットワークが含まれます。これらの各操作は、本質的に高度にパラレル化できるため、推論時にモデルのパフォーマンスが向上します。
マルチヘッド・アテンション・ステップにより、transformerモデルがよりコンテキストに即した性質を持つようになります。注意ブロックの後に、残存接続とレイヤーの正規化を組み合わせたステップが続きます。レイヤーの正規化は、中間レイヤーの分布を正規化するために追加されます。よりスムーズなグラデーション、より高速なトレーニング、より優れた一般化精度を実現します。
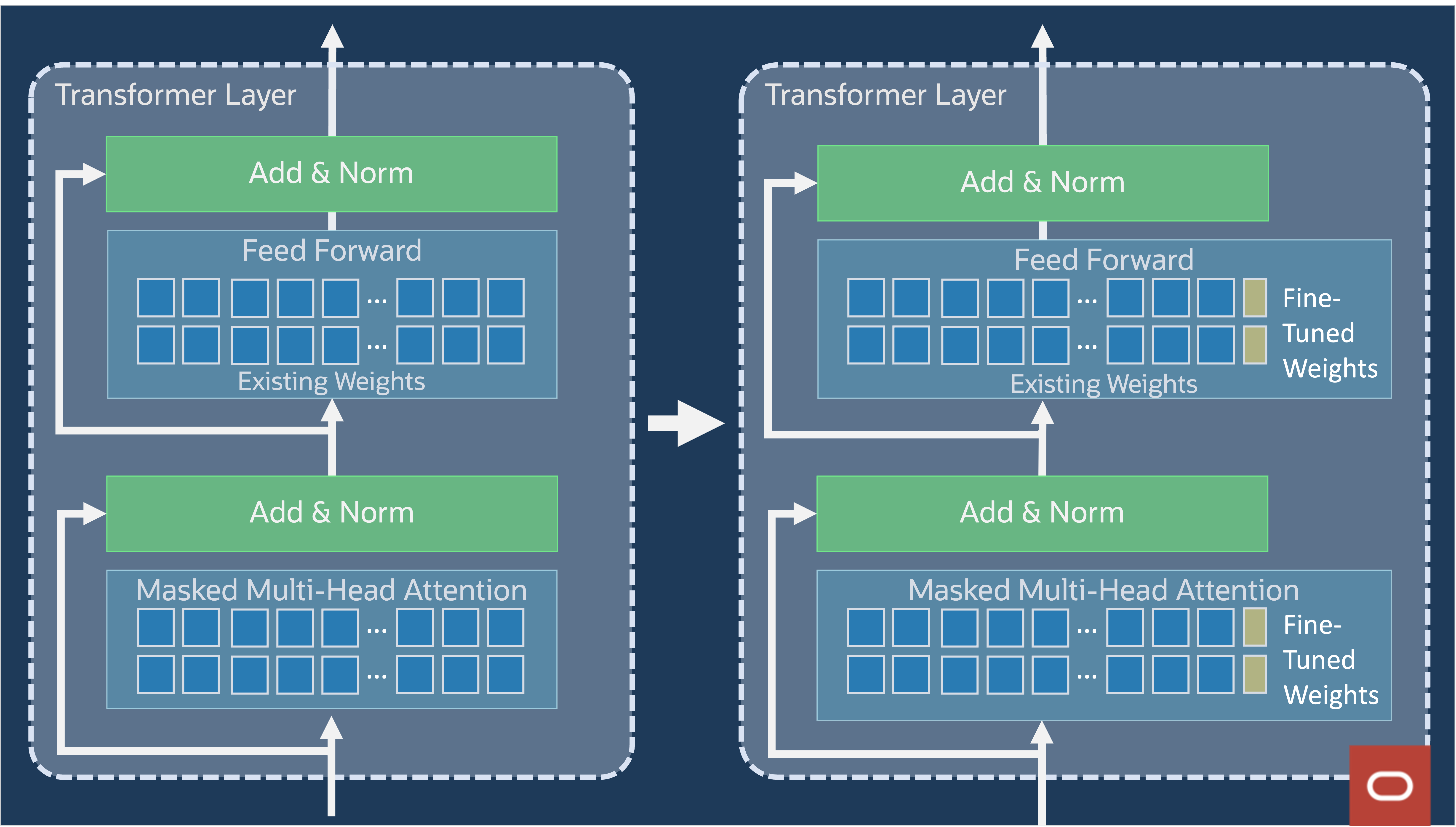
図12: transformer層内により多くのT-Fewウェイトの配置
Fine-tuning中は、図12に示すように、フィード・フォワードおよびマークされたマルチヘッド・アテンション・セクションに、非常に少数のウェイトが追加されます。図13に詳細を示します。具体的には、推論中にK、V、およびフィードフォワード・ウェイトを乗算した1DベクトルLK、LV、およびLFFを追加します。学習した重み、問合せ(Q)、キー(K)および値(V)のマトリックスは、自己アテンション・メカニズム内で個別の機能を提供します。問合せマトリックスはターゲット語に集中し、キー・マトリックスは単語間の関連性を評価し、値マトリックスはマージするコンテキストを提供し、ターゲット語の最終的なコンテキスト表現を形成します。これらの3つのマトリックスを並行して使用することで、セルフアテンション・メカニズムは、文内の単語間の接続と依存関係を効率的に把握します。
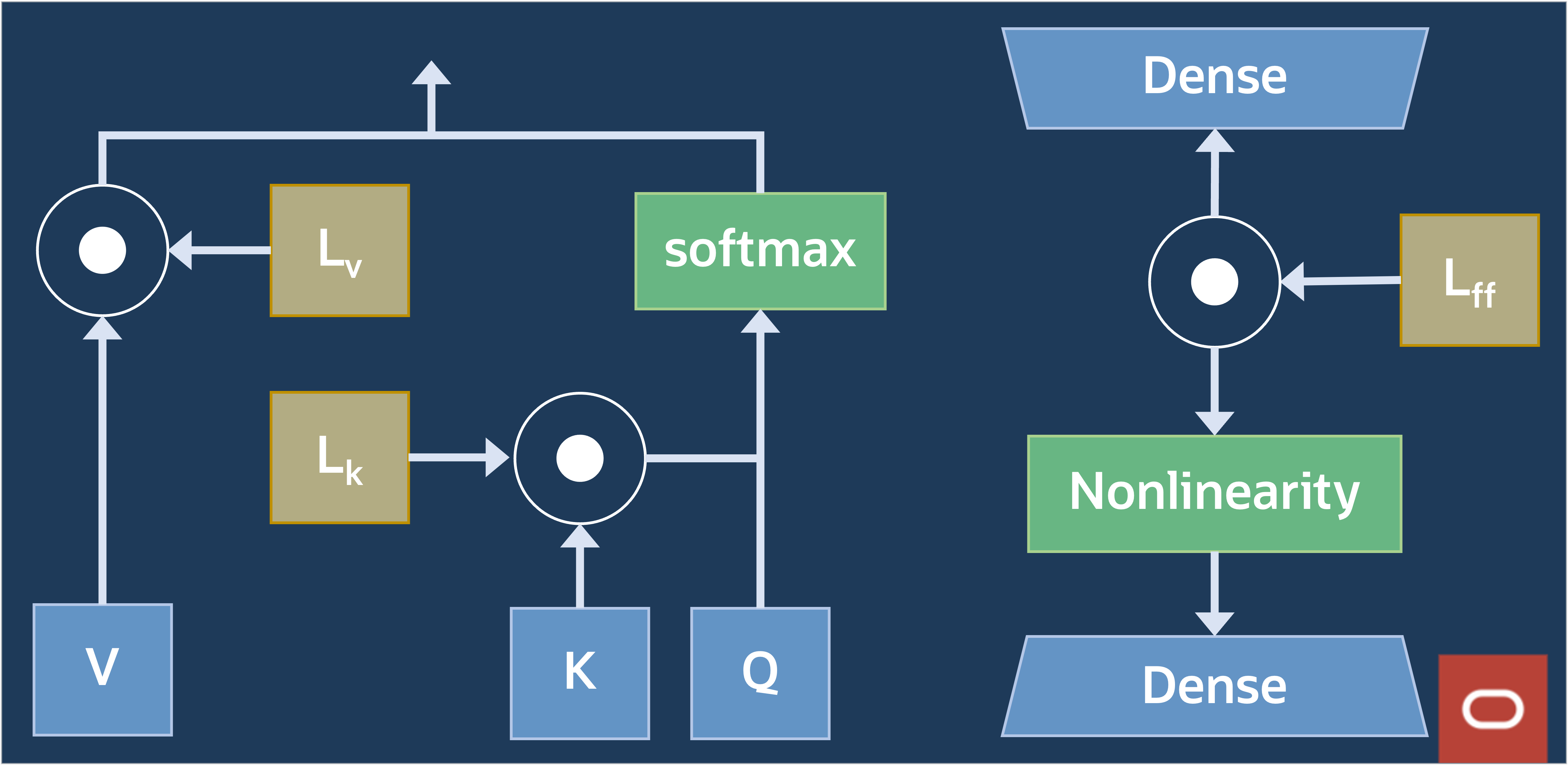
図13: セルフアテンション・ブロック内のT-Fewウェイト
実質的に言えば、T-Few Fine-tuningの構成により、15GBモデルでは約1MB、100GBモデルでは4MBのモデルのウェイトが増えます。
Generative AIヒンジの普及は、推論のコスト効率にかかっています。通常、エンタープライズ・クライアントは様々なユース・ケースを採用しており、それぞれがきわめてFine-tunedモデルでサポートされています。目標は、プライベートRDMAクラスタ・ネットワークによって促進される単一のプライベートGPUクラスタ内に、いくつかのFine-tunedモデルを収容することです。このマルチテナンシのアプローチにより、推論に関連する費用が削減されます。
GPUメモリーは、Generative AIモデルの推論のための限られたリソースであり、モデル・スワップ操作でGPUメモリーを完全にリロードする必要がある場合、様々なモデルを切り替えると、大きなオーバーヘッドが発生します。T-FewによるFine-tunedモデルは、重みの大部分を共有し、Fine-tunedモデル間で最小限の重みのみが異なります。その結果、同じベース・モデルから導出されたFine-tunedモデルを変更するためのオーバーヘッドを最小限に抑えながら、専用GPUクラスタ内の同じGPUグループに多数のFine-tunedモデルを効果的にデプロイできます。

図14: リクエスト処理
まとめ
OCI Generative AIには、すぐに使える消費とカスタマイズが可能な、リアルタイムのユースケースでテスト済みの一連の先進モデルが付属しています。この柔軟性により、顧客は、コンテキストに応じた学習能力とLLMの出現能力を使用するアプリケーションにGenerative AI機能を追加できます。このステップは私たちの旅の始まりにすぎません。Generative AIサービスとGenerative AI Agentsサービスの一環として、この後のリリースは、エンドユーザーがシームレスかつ効率的に「データとチャット」できるようにすることを目的として、LLMの能力とエンタープライズ・データとの組み合わせをさらに簡単にすることに重点を置いています。
次の重要なポイントを考えてみます:
- OCI Generative AIは、業界をリードするGenerative AIモデルのFine-tuningとホスティングのためのフルマネージド・サービスです。
- OCI Generative AIは、厳しいデータ・セキュリティとプライバシー要件を持つエンタープライズ顧客向けに設計されています。
- OCI Generative AIは、T-Few Fine-tuning技術を使用して、業界をリードするGenerative AIベースモデルへの迅速かつ効率的なカスタマイズを可能にします。
- OCI Generative AIは、基礎となる同じプライベートGPUクラスタ内の同じ顧客に属する多くのFine-tunedモデルを積み重ねることで、複数のFine-tunedモデルをホストするコスト効率の高い方法を提供します。
Generative AI Agents Serviceは、企業がシステム内で管理される独自のデータをより簡単に利用できるようにすることを目的としてベータ版で開始されました。後続のFirst Principlesブログ記事では、OCI Generative AI AgentsとRetrieval Augmented Generationについて説明します。
Oracle Cloud Infrastructure Engineeringは、エンタープライズ顧客にとって最も要求の厳しいワークロードを処理するため、クラウド・プラットフォームの設計について異なる考え方をするようになりました。Pradeep VincentとOracleのその他の経験豊富なエンジニアが主催する、このFirst Principlesシリーズの一部として、これらのエンジニアリングについて詳しく説明します。
詳細は、次のリソースを参照してください:
