Generative AI has already had a profound impact on human productivity and automation. New applications are coming out across industries all the time. However, implementing and deploying effective generative AI solutions can require a lot of special effort. Enterprises have to take on machine learning (ML) model tuning and data curation, and learn to evaluate model outputs to solve their specific industry or application. They also must invest in the installation and ongoing management of specialized infrastructure such as GPUs and very high performance networking.
OCI offers that specialized AI infrastructure. With the introduction of the OCI Generative AI Service, OCI now provides a fully managed framework for Gen AI model tuning and hosting on top of it. This reduces the customer effort and lead time to deploy a customized Gen AI solution down to days or weeks instead of months.
This blog post explores the inner workings of OCI Generative AI service. It details the service’s easy customization of AI models, cost-efficient hosting for multiple fine-tuned models, and critical functionality for enterprise adoption.
Generative AI
Generative AI encompasses a category of ML algorithms capable of independently generating content, including but not limited to text, images, and videos, in response to queries that are understandable by humans. Because of its ability to produce novel content, complex intricate tasks that were beyond AI’s reach until recently are now feasible. Generative AI can produce written text, formulate SQL queries, develop code, generate art, and aid in customer support and other tasks. Its key advantage is the simplified access to both structured and unstructured data for users.
At its core, generative AI uses complex neural network architectures trained on a massive corpus of diverse information. The models can create novel outputs by predicting the most likely next elements based on learned patterns. Most generative AI models operate by converting an input sequence into an output. They belong to the family of sequence-to-sequence ML tasks. Example applications include machine translation and speech synthesis.
In 2017, a seminal paper, Attention is All You Need, revolutionized the field of sequence-to-sequence tasks. It introduced the transformers architecture into ML models.
The core of transformers is the self-attention mechanism. Self-attention enables them to understand the contextual relationships within input sequences with high efficiency. Distinct from earlier models, Transformers have the capability to handle input sequences in their entirety at once, which significantly enhances their parallelization and efficiency. These models are composed of several layers, which allow for effective scaling and training on extensive datasets.
The self-attention feature of transformer architecture expanded the model size leading to the birth of large language models (LLMs). Originally used for text synthesis, LLMs are now widely used across speech, vision, genome, robotics, and other data modalities efficiently. LLMs are large transformer models that mimic the original transformer architecture very closely.

Figure 1: Transformer model architecture
Figure 1 illustrates an example of a transformer model that can complete the sentence, “Hello, how are…” with predicting “you doing?” as the next words in the sentence. At a high level, the transformer architecture contains two main parts, encoder and decoder. The encoder part is represented by a stack of transformer layers that convert the input sequence into a set of highly contextualized embeddings. The decoder part takes these embeddings as input and iteratively produces an output sequence of tokens generating a single token at a time. Previously generated elements of the output sequence are also fed back into the decoder at each step. This way of producing content is referred to as autoregression.
LLMs’ innovative capabilities make them highly effective for various applications. Enterprise applications usually have little tolerance for mistakes and misplaced creativity. Businesses demand customization and hold their AI applications to stringent accuracy standards. In these scenarios, achieving the required model precision involves not only the correctness of the results, but also their safety and accountability.
Adjusting LLMs with fine-tuning and the use of specialized training data enhances the precision and pertinence of the LLM inference results. At Oracle, basic generative AI models were fine-tuned for applications like human capital management (HCM), supply chain management, and customer experience. Example use cases include creating job descriptions, summarizing candidate experiences, summarizing chats, and assisting in sales meetings. For these applications, employing fine-tuning with a systematic data curation method resulted in tangible enhancements in the applications’ accuracy.
Generative AI application workflow
The key to success of generative AI apps lies in using the combination of a powerful base model and the ability to customize it for various applications. This customization involves iteratively fine-tuning base model using curated training data. Figure 2 demonstrates use of generative AI for creating candidate evaluation summaries. In this scenario, a customer formulates a task that can be executed by an LLM. This step begins with defining the input prompt for the model to use with the associated input data.
Figure 2 shows a detailed prompt of a task to generate an evaluation summary of a candidate. The prompt contains an overview of the task, the instructions for the model regarding sections of a resume to pay attention to, and a few optional examples of how the input can be represented in the output. Finally, the candidate resume is appended to the prompt by a runtime system.
Figure 2: Generative AI candidate evaluation summary
Figure 3 shows a high-level workflow of a generative AI application. When a task is formulated, the customer runs an initial evaluation of the base model. This process involves running a set of known inputs through the model and comparing the model responses with the ground truth answers. As an example, when evaluating a model for effectiveness in analyzing resumes, a customer cycles through a set of resumes, and their summaries are compared to handcrafted ones. This phase usually incorporates prompt-tuning that can improve the accuracy of a base model.
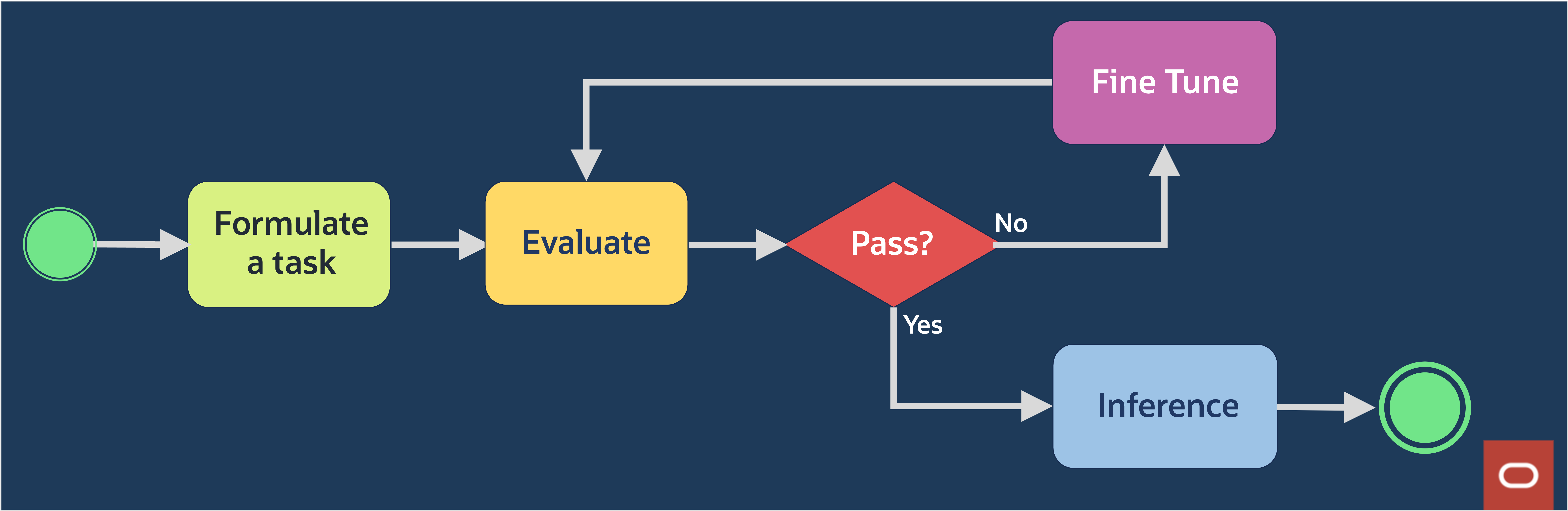
Figure 3: Generative AI application worklow
Fine-tuning might be required if the base model doesn’t yield sufficiently accurate results based on defined criteria. Fine-tuning involves gathering a small amount of training data to demonstrate the required behavior of a model for specific domains. Figure 4 illustrates the steps required in fine-tuning.
Figure 4: Generative AI application workflow with fine-tuning
When the model passes the evaluation, it’s ready to deploy for inference in the form of an inference endpoint ready to serve live production traffic. Figure 5 provides the steps involved in setting up the inference service.
Figure 5: Generative AI application workflow with inference
OCI Generative AI
Oracle’s latest Generative AI offering is a comprehensively managed service. It forms the foundation for a range of generative AI features across the full Oracle technology stack. Equipped with leading models tailored for business use, a customer-focused holistic strategy, and an emphasis on data privacy and management, OCI Generative AI stands out in facilitating a wide array of business AI applications, such as writing help, content summarization, conversational interfaces, and beyond.
The service allows for customization and fine-tuning of the base models for specific tasks to make them more effective for real-world enterprise use cases. This fine-tuning process requires expertise and collaboration. Oracle partnered with Cohere to adapt and tailor their LLMs to enterprise applications. Customers can now use the Cohere models, their fine-tuning strategy, and other models, such as Meta’s Llama 2.
With OCI Generative AI service, the customer data used for fine-tuning the models and inference purposes isn’t used outside the customer’s application. Data stays private. The Generative AI service can host multiple customized models in a cost-effective way, and we have been using the underlying stack to deliver generative AI functionality for many Oracle applications, including NetSuite, Fusion Apps, and Healthcare.
Generative AI necessitates a specialized infrastructure comprising GPUs interconnected with a cluster network to achieve ultra-high performance. OCI boasts an industry-leading RDMA super cluster network capable of providing network latency as low as two microseconds. When customers set up infrastructure for the OCI Generative AI service, the service automatically establishes a dedicated AI cluster, which includes dedicated GPUs and an exclusive RDMA cluster network for connecting the GPUs. The GPUs allocated for a customer’s generative AI tasks are isolated from other GPUs as demonstrated in figure 6, and this dedicated AI cluster hosts the customer’s fine-tuning and inference workloads.

Figure 6: Dedicated AI cluster GPU pool
At OCI, security and privacy of customer workloads is an essential design tenet. Customers can use data in fine-tuning generative AI models, and during inferencing. Customer data access is restricted within the customer’s tenancy, so that one customer’s data can’t be seen by another customer as shown in figure 7. Only a customer’s application can access custom models created and hosted from within that customer’s tenancy.
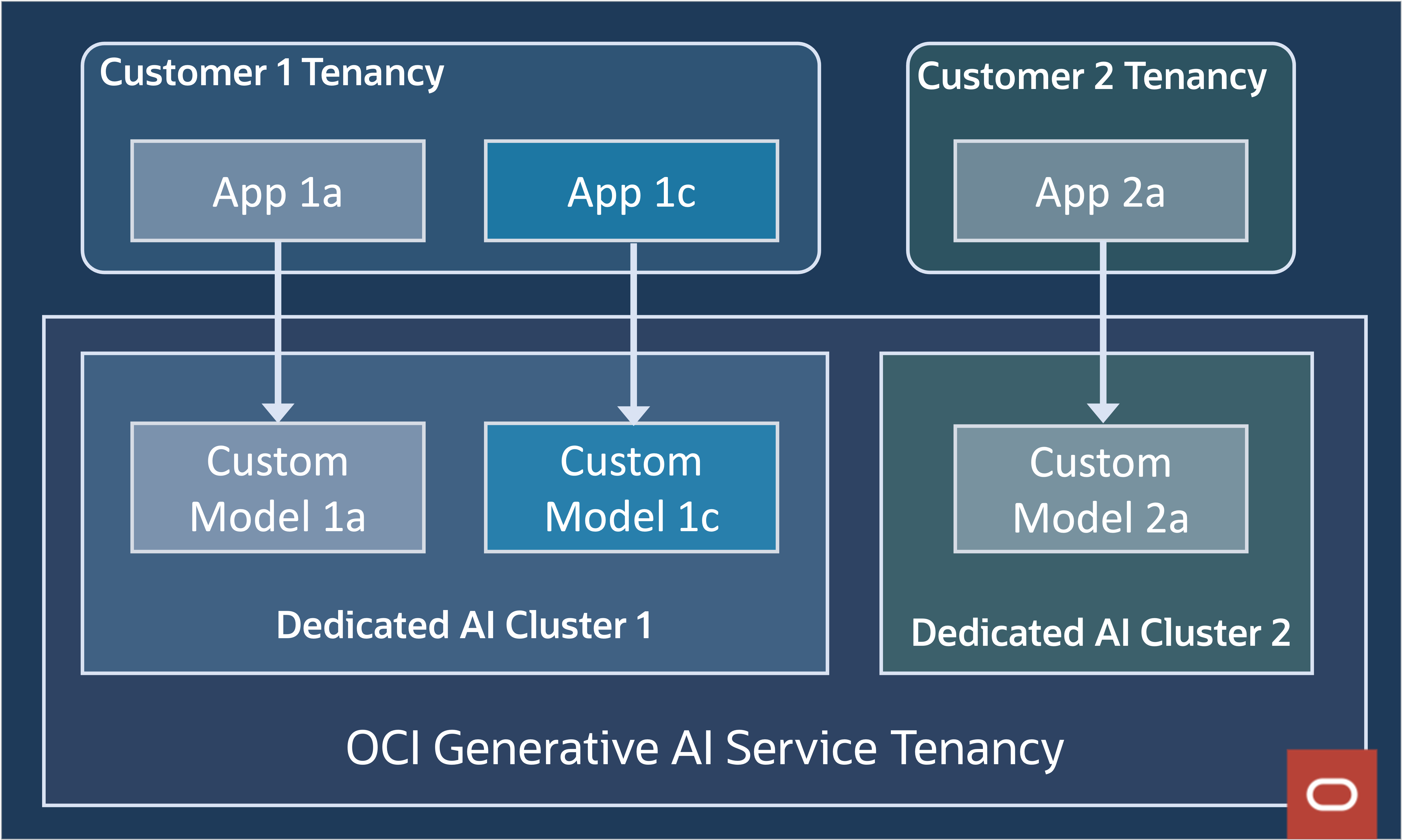
Figure 7: Customer data and model isolation
To further promote strong data privacy and security, a dedicated GPU cluster only handles fine-tuned models of a single customer.

Figure 8: Model endpoint examples
As an example, in figure 8, we have a base model with three fine-tuned models that are created off the same base model, and a customer creates a model endpoint for each of the four models. All four endpoints share the same cluster resources for the most efficient utilization of underlying GPUs in the dedicated GPU cluster. Customers can create dozens or even hundreds of fine-tuned models to deploy on a single dedicated AI cluster, based on the business needs.
The service utilizes the OCI ecosystem to deliver its data governance. A high-level architecture is displayed in figure 9. It’s fully integrated with OCI’s Identity and Access Management (IAM) service to help ensure proper authentication and authorization for customer data access. OCI Key Management stores base model keys securely. The fine-tuned customer models are stored in Object Storage encrypted by default.
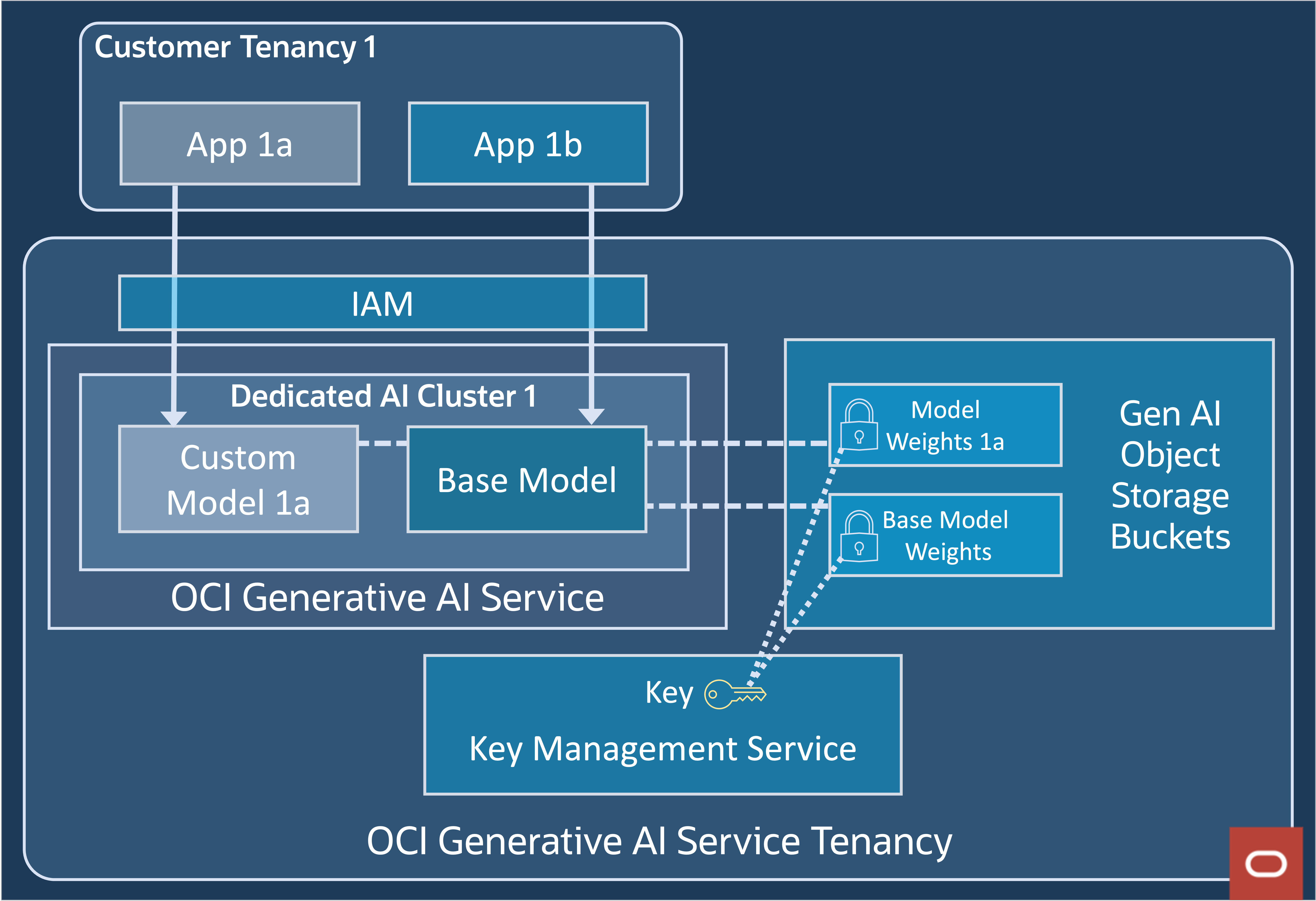
Figure 9: OCI Generative AI security architecture
Fine-tuning
Historically, fine-tuning of ML models entailed modifying most of the parameters within the original base model to alter its functionality and better tailor it to a particular application or task. Within the realm of the OCI Generative AI service, this technique is supported and termed vanilla fine-tuning. While this fine-tuning process delivers superior quality, it’s time-consuming and demands considerable resources, leading to prolonged cycles of iteration. Moreover, allocating a specific GPU resource for every refined model created using this method can impose substantial expenses on customers.
To overcome this challenge, the OCI Generative AI service employs a method, known as T-Few, for parameter-efficient fine-tuning, which updates merely a portion of the model’s weights. This technique is outlined in a 2022 paper, Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning. It diminishes both the training duration and the computational resources needed in comparison to conventional fine-tuning methods, while still maintaining high accuracy. OCI has collaborated with Cohere to deliver a more cost-effective fine-tuning solution to their clients. By adopting this fine-tuning strategy, customers can better achieve the required higher accuracy at a significantly reduced expense.
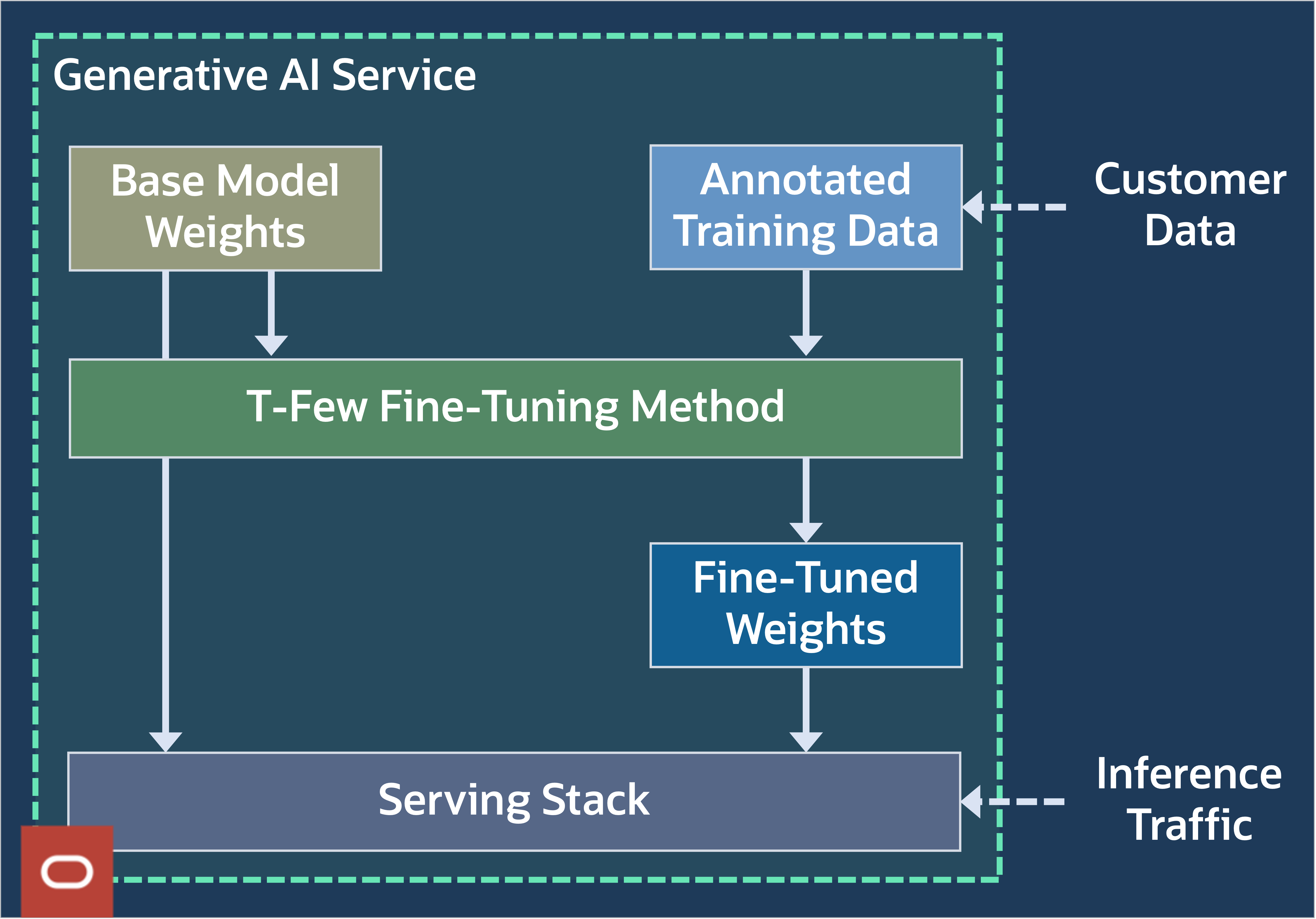
Figure 10: T-few fine-tuning
As seen in figure 10, the T-Few fine-tuning process begins by utilizing the initial weights of the base model and an annotated training dataset. This annotated data comprises of input-output pairs that are employed in supervised training conducted with T-Few. Through this training process, a supplementary set of model weights is generated, which is utilized in conjunction with the base model during model deployment.
T-Few fine-tuning is an additive parameter-efficient, fine-tuning technique that inserts more weights, comprising approximately 0.01% of the baseline model’s size.
Furthermore, during the fine-tuning phase, the updates to the weights are confined to a specific group of transformer layers, known as T-Few transformer layers as demarcated in figure 11. Instead of making updates across most of the model’s layers, updates are limited to only the T-Few layers, saving substantial training time and cost.

Figure 11: Transformer layer internals
Figure 11 exposes the internals of the transformer layer. The transformer layer consists of a set of operations performed sequentially on the input data flowing through it. Specifically, it contains a multi-head attention and a layer normalization, followed by a feed forward network. Each of those operations individually are highly parallelizable in nature, leading to higher performance of the model at inference time.
The multi-head attention step can make a transformer model more contextual in nature. The attention block is followed by a step combining the residual connection with layer normalization. The layer normalization is added to normalize the distributions of intermediate layers. It enables smoother gradients, faster training, and better generalization accuracy.
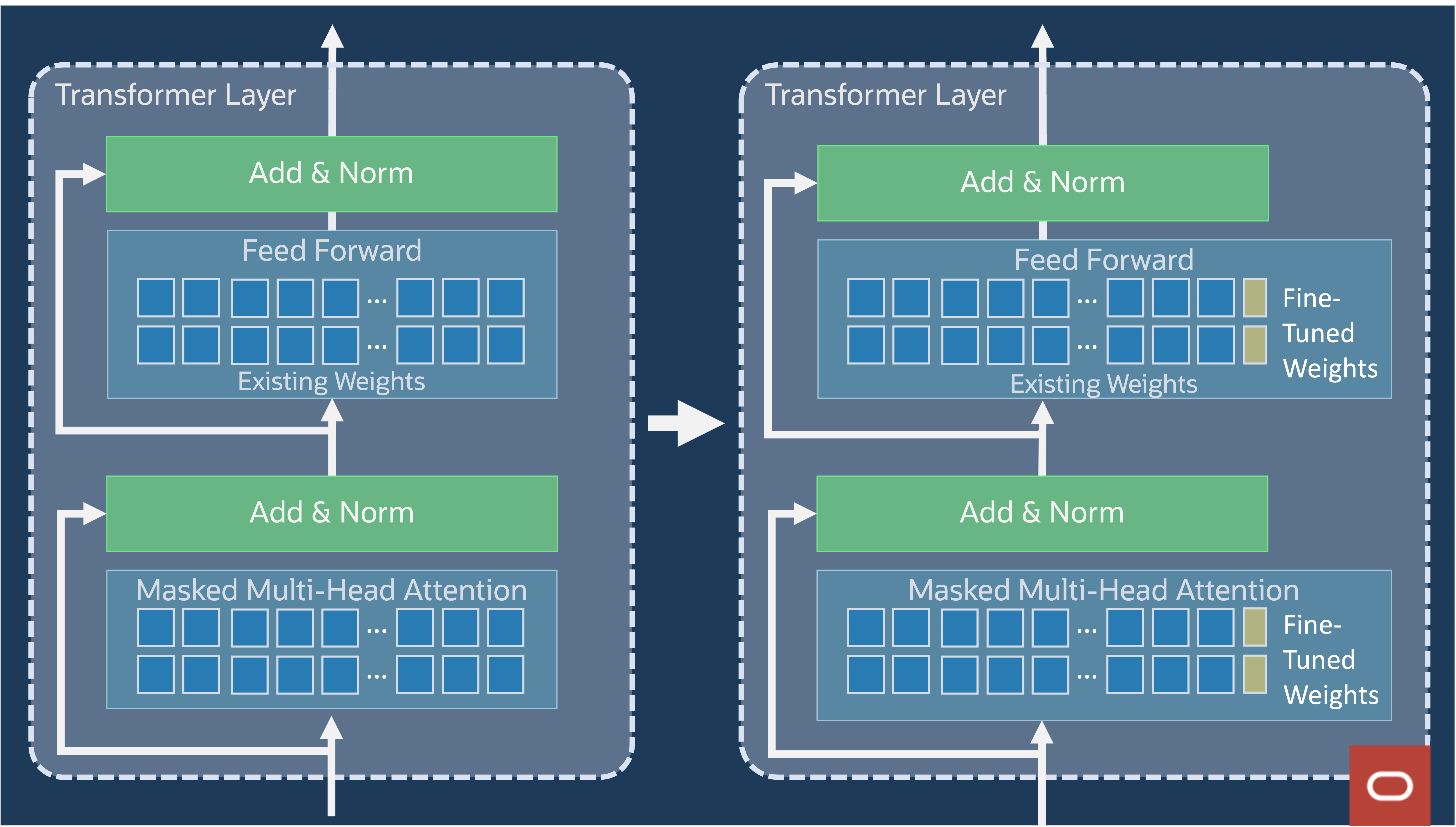
Figure 12: Placement of more T-Few weights within transformer layer
During fine-tuning, a very small number of weights are added to the feed forward and the marked multi-head attention sections as presented in figure 12. Figure 13 provides the details. Specifically, it adds 1D vectors LK, LV, and LFF that are multiplied with the K, V, and feed-forward weights during inference. The matrices of learned weights, Query (Q), Key (K), and Value (V), serve distinct functions within the self-attention mechanism. The Query matrix assists in concentrating on the target word, the Key matrix evaluates the relevance among words, and the Value matrix offers the context to be merged, forming the ultimate contextual depiction of the target word. By employing these three matrices in tandem, the self-attention mechanism efficiently grasps the connections and dependencies among words within a sentence.

Figure 13: T-Few weights wtihin self-attention block
Practically speaking, our configuration of T-Few fine-tuning creates more chunks of model weights of around 1 MB for 15-GB models, and 4 MB for 100-GB models.
The widespread adoption of generative AI hinges on the cost-effectiveness of inferencing. Commonly, enterprise clients employ various use cases, each supported by a specifically fine-tuned model. The goal is to accommodate several fine-tuned models within a single private GPU cluster, which is facilitated by a private RDMA cluster network. This approach of multitenancy reduces the expenses associated with inference.
GPU memory is a limited resource for generative AI model inferencing, and toggling between various models results in significant overhead when model swap operation requires GPU memory to be reloaded fully. Models fine-tuned with T-Few share most of the weights, with only a minimal amount of weights differing among the fine-tuned models. Consequently, we can effectively deploy numerous fine-tuned models on the same group of GPUs within the dedicated GPU cluster with minimal overhead for changing fine-tuned models derived from the same base model.
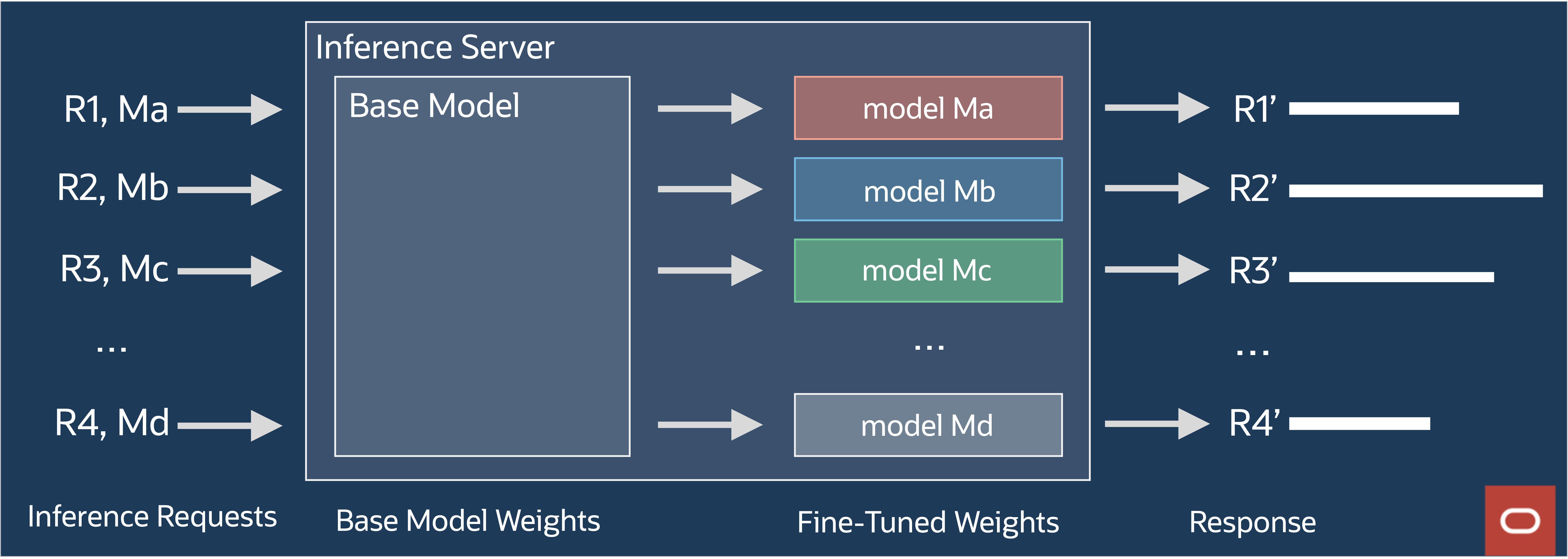
Figure 14: Request processing
Conclusion
OCI Generative AI comes with a set of leading, tested models in real world use-cases that are available for out-of-the-box consumption and customization. This flexibility enables customers to add generative AI capabilities to their applications that use in-context learning abilities and emergent abilities of LLMs. This step is only the beginning of our journey. As a part of Generative AI service and Generative AI Agents service, our subsequent launches focus on making it even easier to combine the abilities of LLMs with enterprise data, with the goal of allowing end users to “chat with the data” seamlessly and efficiently.
Consider the following key takeaways:
- OCI Generative AI is a fully managed service for fine-tuning and hosting industry leading generative AI models.
- OCI Generative AI is engineered for the enterprise customers with tight data security and privacy requirements.
- OCI Generative AI uses the T-Few fine-tuning techniques to enable fast and efficient customizations to industry leading generative AI base models.
- OCI Generative AI provides a cost-effective way to host multiple fine-tuned models by stacking many fine-tuned models belonging to the same customer in the same underlying private GPU cluster.
The Generative AI Agents Service launched in beta with the aim to make it easier for enterprises to tap into proprietary data managed within their systems. In a subsequent First Principles blog post, we will cover OCI Generative AI Agents and Retrieval Augmented Generation.
Oracle Cloud Infrastructure Engineering handles the most demanding workloads for enterprise customers, which has pushed us to think differently about designing our cloud platform. We have more of these engineering deep dives as part of this First Principles series, hosted by Pradeep Vincent and other experienced engineers at Oracle.
For more information, see the following resources:

