We’re pleased to announce the general availability of the Oracle Cloud Infrastructure (OCI) Generative AI service.
We’ve been working on many new features and models since the OCI Generative AI service was released in beta in September. Most notably, the service now supports Meta’s Llama 2 model, Cohere’s models, and a multilingual capabilities with over 100 languages. After listening to customer feedback from the beta release, we’ve also made improvements to the GPU cluster management experience. As always, we remain committed to offering flexible fine-tuning for models so customers can tailor their models for their specific business objectives.
The following overview highlights the key features offered in the general availability release.
Text generation and embeddings models
The following large language models (LLMs) are available for text generation use cases:
- Cohere Command in 52-billion and 6-billion parameter sizes (the XL and light models)
- Meta Llama 2 70-billion parameter model
These models can perform various tasks by following user prompting instructions. Both models support a maximum context length of 4096 tokens, where one token is approximately four characters in English. Token conversion varies by language.
The following Cohere Embed V3.0 models are available for text representation use cases, such as embeddings generation:
- Embed English and English Light V3
- Embed Multilingual and Multilingual Light V3
Light models are smaller, but faster at generating shorter vector representations. For example, English Light V3 generates vectors of 384 dimensions, while English V3 produces vectors of 1024 dimensions. All text generation and representation models are available for on-demand, pay-as-you-go consumption and can be hosted in dedicated AI clusters.
On-demand versus dedicated AI clusters
All foundational models hosted in OCI Generative AI can be consumed on-demand through the Oracle Cloud Console playground feature, OCI CLI, software developer kits (SDKs), API, and our LangChain integration. For on-demand models, you only pay for what you consume, on a per-character basis, for each input processed by the model and response generated by the model. For the Embeddings models, you only pay for the characters processed by the model. You have no minimum commitment for the on-demand features, and the underlying infrastructure serving requests for the on-demand models is shared across all customers calling that model in a particular region.
In contrast, dedicated AI clusters enable you to deploy a replica of foundational and fine-tuned custom models on a dedicated set of GPUs. A dedicated AI cluster is effectively a single-tenant deployment where the GPUs in the cluster only host your models. Because the model endpoint isn’t shared, the model throughput is consistent, and the minimum cluster size is easier to estimate based on the expected volume call.
Pricing is also easier to predict for dedicated AI clusters: You pay per hour based on the type and number of cluster units you select when you create the cluster. You don’t pay per character processed for inference or fine-tuning.
Customize the models to meet your business needs
OCI Generative AI also allows you to optimize the foundational models for a particular task through model fine-tuning in dedicated AI clusters. Two fine-tuning strategies are offered for Cohere’s Command XL and Command light models: t-few and vanilla. Default fine-tuning hyperparameters, including number of training epochs, learning rate, training batch size, early stopping patience, early stopping threshold, and the interval in steps at which model metrics are logged, are set by default; however, you can modify the parameters before a fine-tuning job starts. For vanilla fine-tuning, another hyperparameter specifies the number of layers to optimize, as shown in the following image:
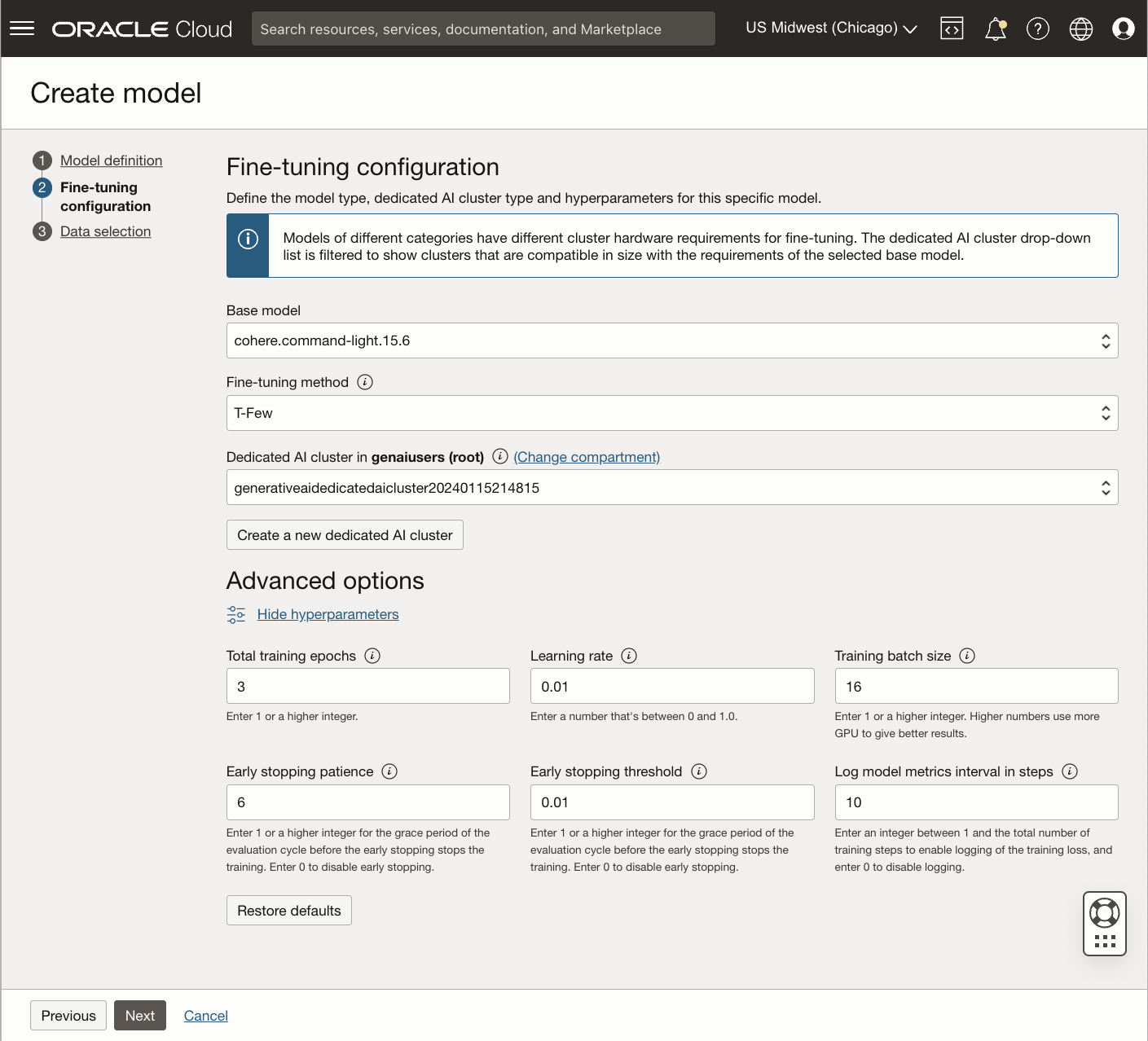
Fine-tuning jobs require a labeled training dataset consisting of a single file in jsonl format. Each training example has two keys: prompt and completion. Prompt contains the series of instructions that the model must follow to generate the response, while completion is the expected response from the model. A minimum of 32 examples is necessary for fine-tuning, though we recommend using more than 100 whenever possible.
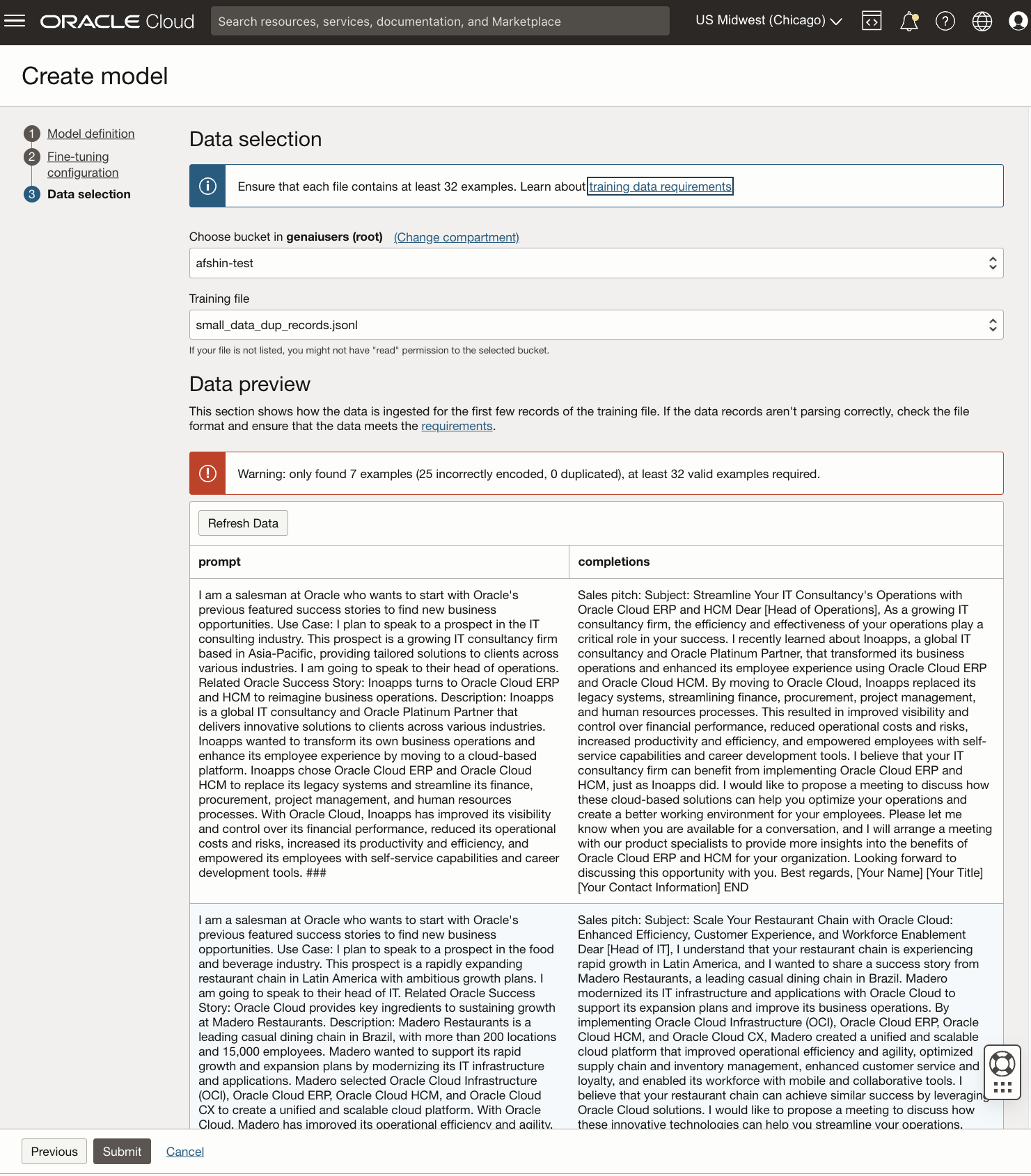
Hosting custom, optimized models in dedicated AI clusters
You can create an endpoint to host a model on a hosting cluster and host up to 50 custom models optimized with the t-few strategy on a single dedicated AI cluster as long as all the models share the same base model and model version. This method can lead to cost reductions because the same cluster can host multiple fine-tuned models (meaning you don’t need to create separate clusters for separate fine-tuned models).
For models optimized through vanilla fine-tuning, you can host a single custom model on a hosting cluster. You can create multiple endpoints that direct traffic to the same model while monitoring metrics, such as number of calls, total number of input and output tokens, and client error counts, are computed at the endpoint level. This feature enables you to separate and monitor different clients accessing the same model, and to create each endpoint in a different compartment to control access.
For a full technical deep-dive into how our flexible fine-tuning and improved GPU cluster management works, check out the blog First Principles: Exploring the Depths of OCI Generative Al Service where OCI Chief Technical Architect, Pradeep Vincent, walks through the efficiency advantages.
Conclusion
The Oracle Cloud Infrastructure Generative AI service is now generally available, on-demand and through dedicated AI clusters, with the ability to use pre-built or fine-tuned for your business needs.
For more information, see the following resources:
- Read the press release
- Access the Gen AI service documentation
- Read through the description of the GenAI service API
- Read about key features on the Gen AI product tour
- Check out the First Principles blog on exploring the depths of OCI Generative AI Service
