Em nosso primeiro artigo sobre busca semântica em bases documentais complexas como SEI, demonstramos que uma estratégia eficaz de recuperação precisa evoluir para além da identificação de conteúdo relevante, passando a incorporar a reconstrução de contexto por meio da navegação em um grafo de conhecimento.
Essa evolução amplia significativamente o potencial das soluções de recuperação aplicadas ao SEI, permitindo respostas mais completas, contextualizadas e próximas da forma como os processos administrativos realmente se organizam. No entanto, esse mesmo ganho de capacidade traz consigo um novo desafio estrutural: à medida que expandimos o contexto recuperado, aumentamos também a superfície de exposição a informações sensíveis.
Em outras palavras, quanto maior a capacidade de reconstrução de contexto, maior a necessidade de garantir que apenas informações autorizadas participem desse processo. Mais do que isso, torna-se essencial assegurar que nenhuma informação não autorizada influencie a resposta, seja de forma direta ou indireta, inclusive por meio de inferências geradas durante a navegação no grafo.
É exatamente nesse ponto que a discussão sobre busca semântica se conecta, de forma inevitável, com o tema de segurança e controle de acesso, que será explorado nesta parte do artigo em profundidade.
Antes de avançarmos para as implicações arquiteturais desse desafio, é necessário compreender como o controle de acesso é efetivamente estruturado no SEI.
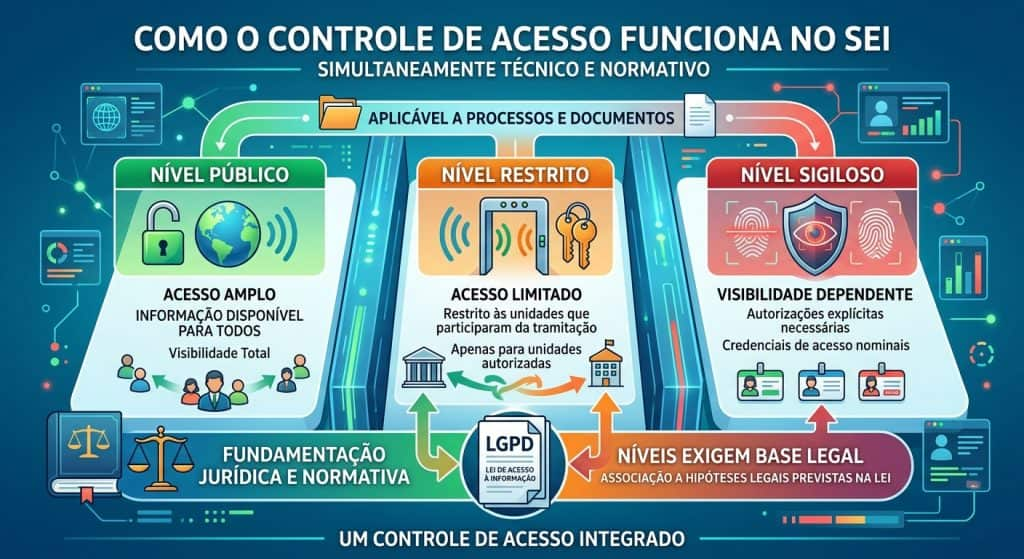
Como o controle de acesso funciona no SEI
No SEI, o acesso à informação é estruturado a partir de três níveis de sigilo, aplicáveis tanto a processos quanto a documentos. No nível público, a informação possui acesso amplo. No nível restrito, o acesso é limitado às unidades que participaram da tramitação do processo. Já no nível sigiloso, a visibilidade depende de autorizações explícitas, geralmente associadas a credenciais de acesso nominalmente atribuídas.
Esses níveis de sigilo, contudo, não se restringem a um aspecto técnico. A definição de níveis restritos ou sigilosos exige fundamentação jurídica, por meio da associação a hipóteses legais previstas na Lei de Acesso à Informação (LGPD). O controle de acesso, portanto, é simultaneamente técnico e normativo.
Além disso, o modelo opera em duas dimensões complementares. A primeira refere-se ao nível atribuído ao processo, que define um comportamento padrão e pode ser herdado pelos documentos a ele vinculados. Já a segunda corresponde à classificação atribuída aos documentos de forma independente. O uso conjunto dessas duas dimensões permite que um mesmo processo reúna documentos com diferentes níveis de sigilo, refletindo de maneira mais fiel a complexidade da administração pública.
Essa complexidade torna o modelo intrinsecamente dinâmico. Processos podem mudar de unidade, documentos podem ter seu nível de sigilo alterado e permissões podem ser concedidas ou revogadas ao longo do tempo. Como consequência disso, o controle de acesso deve ser entendido como uma avaliação contínua dependente do estado do sistema.
Esse dinamismo inerente à administração pública é o que torna a integração do SEI com qualquer mecanismo de busca semântica um desafio de segurança que não deve ser subestimado.
Limitações da validação de acesso em tempo de execução
Diante deste cenário, uma abordagem intuitiva seria delegar toda a validação ao próprio SEI no momento da consulta, validando cada fragmento recuperado antes de utilizá-lo na construção da resposta.
À primeira vista, essa estratégia parece adequada, pois mantém o SEI como o último bastião. No entanto, quando analisada sob a ótica da busca semântica, ela apresenta limitações importantes.
Como discutimos na parte 1 deste artigo, o processo de busca semântica retorna um conjunto limitado de fragmentos — o Top K — considerados mais relevantes para a consulta. Quando esse conjunto inclui fragmentos não autorizados, esses itens ocupam posições no ranking inicial, deslocando potenciais fragmentos visíveis para fora do ranking. Após a validação pelo SEI, esses fragmentos são descartados, mas já influenciaram a seleção dos demais resultados.
Vamos revisitar o exemplo da parte 1 para ilustrar esse risco. Considere uma consulta sobre os motivos de cancelamento de um processo administrativo. O ranking inicial pode incluir fragmentos de pareceres jurídicos inacessíveis ao usuário. Após a validação do SEI, esses fragmentos são removidos, mas já influenciaram a escolha de outros fragmentos relevantes visíveis. Deste modo, o sistema passa a operar com um contexto parcial, potencialmente inconsistente, e o resultado pode se tornar superficial ou impreciso.
Além disso, o impacto na latência é significativo, uma vez que cada fragmento exige validação adicional, criando uma sobrecarga no SEI, além de comprometer a experiência do usuário final.
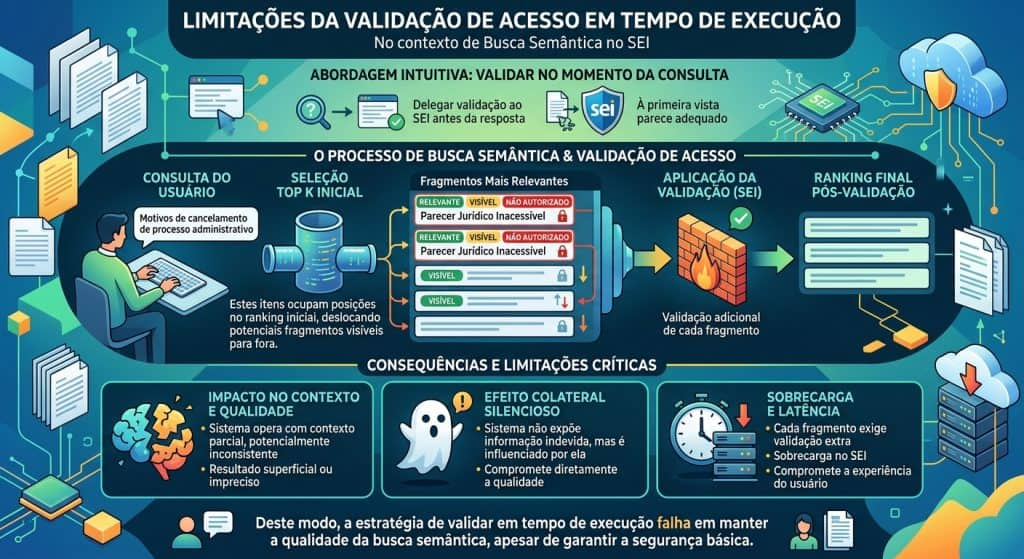
Mais importante, emerge um efeito colateral silencioso: o sistema pode não expor informação indevida, mas ainda assim ser influenciado por ela, comprometendo diretamente a qualidade das respostas.
Eventualmente, esse efeito colateral pode gerar respostas vazias, caso todos os fragmentos do Top K sejam rejeitados pelo controle de acesso do SEI.
Controle de acesso como parte integrante da recuperação
Diante destas limitações, torna-se necessário integrar o controle de acesso ao próprio processo de recuperação. Ele não deve ser tratado como uma estrutura lateral.
Uma abordagem eficaz consiste na utilização de rótulos de acesso associados a cada fragmento vetorizado. Esses rótulos representam uma projeção do modelo de segurança do SEI, incorporando nível de sigilo, escopo organizacional e credenciais de acesso.
Isso permite que a recuperação opere sobre um espaço previamente filtrado, garantindo que apenas fragmentos potencialmente autorizados participem da construção do ranking.
No entanto, os rótulos constituem apenas uma aproximação do estado real do sistema. Como o SEI é dinâmico, inconsistências podem surgir em decorrência de mudanças como alteração de nível de sigilo, movimentação de processos entre unidades ou concessão e revogação de permissões.
Sem um mecanismo adequado de atualização, essa defasagem pode resultar tanto na exposição indevida de conteúdos quanto na exclusão de informações que já deveriam estar acessíveis.
Para mitigar esse risco, é necessário adotar uma estratégia de sincronização contínua entre o SEI e os rótulos associados aos fragmentos utilizados na busca semântica.
Uma abordagem eficaz consiste na utilização de uma arquitetura orientada a eventos, na qual o próprio SEI emite eventos relevantes. Alterações no estado dos processos, como reclassificação de sigilo, movimentação entre unidades ou atualização de permissões, passam a gerar eventos que são consumidos por um fluxo de processamento (pipeline) responsável por atualizar os rótulos de acesso associados aos fragmentos vetorizados.
Essa estratégia é análoga à adotada para a atualização do conteúdo documental discutida na parte 1, na qual eventos do SEI são utilizados para manter sincronizadas as representações textuais, vetoriais e o grafo de conhecimento composto por vértices e arestas.
Isso demonstra a versatilidade da arquitetura orientada a eventos dentro do SEI, permitindo que o mesmo evento possa ser consumido por diferentes pipelines.
Ainda assim, mesmo com sincronização orientada a eventos, a possibilidade de inconsistências transitórias não pode ser completamente eliminada.
Por essa razão, a arquitetura mais robusta continua a combinar duas etapas complementares: uma filtragem antecipada baseada em rótulos, continuamente atualizados por eventos, e uma validação final realizada diretamente no SEI.
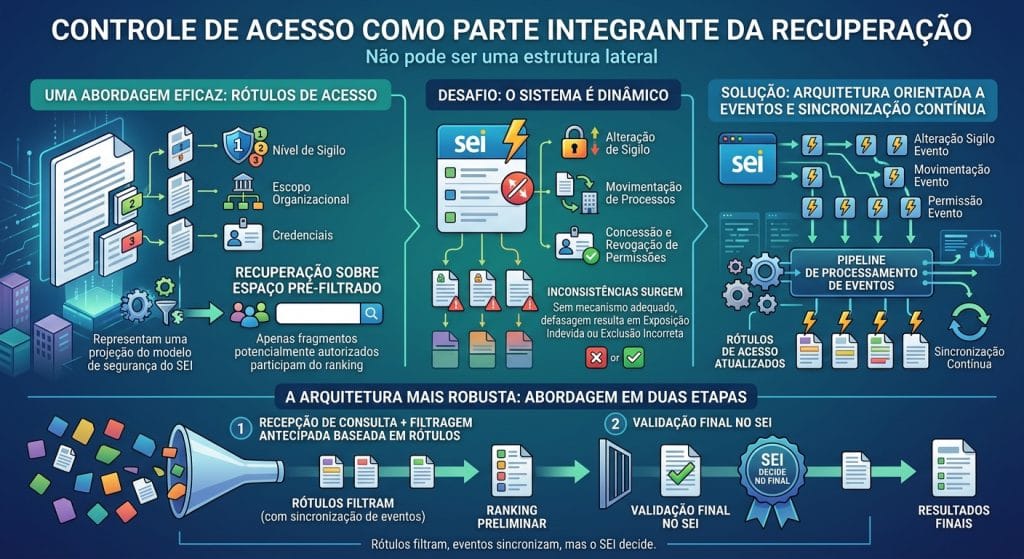
Nessa abordagem, os rótulos filtram, os eventos sincronizam, mas quem decide no final continua sendo o SEI.
Tratamento de documentos sigilosos.
Embora os rótulos permitam controlar a participação dos fragmentos no processo de recuperação, documentos sigilosos exigem decisões adicionais de natureza arquitetural.
Uma abordagem conservadora consiste em excluí-los da indexação semântica, reduzindo o risco de exposição indireta. Essa estratégia pode ser aplicada somente aos tipos de processos mais críticos, a critério de cada órgão.
Alternativamente, pode-se adotar estratégias de isolamento lógico mais sofisticadas, com controles adicionais sobre o comportamento da busca semântica.
Nesse caso, a proteção dos processos sigilosos acessíveis via busca semântica não ocorre somente por meio dos rótulos, mas pela introdução de regras mais restritivas baseadas no contexto de execução da pesquisa, no papel do usuário e nas condições operacionais sob as quais a interação ocorre.
Um bom exemplo dessa abordagem é o SEI-Atos, módulo do SEI, desenvolvido pela Presidência da República, que é responsável pela tramitação de atos do primeiro escalão do governo federal.
Grafos de conhecimento e ampliação do risco de inferência
A reconstrução de contexto por meio da navegação pelo grafo de conhecimento potencializa um tipo de risco que não se manifesta na mesma intensidade em mecanismos tradicionais de busca: a inferência.
Embora extremamente eficazes para enriquecer a busca semântica e revelar relações entre entidades, esses grafos também ampliam a superfície de exposição quando não há controles adequados.
O problema se torna mais evidente quando a navegação pelas arestas do grafo não respeita os níveis de sigilo associados a cada vértice. Nesse cenário, um usuário pode, a partir de informações às quais tem acesso legítimo, percorrer caminhos que conectam indiretamente a dados sensíveis, reconstruindo conhecimento que, isoladamente, estaria protegido.
Por exemplo, considere processos relacionados a afastamento médico de servidores públicos. Esses processos contêm documentos com dados pessoais sensíveis protegidos por normas legais. Mesmo sem acesso direto a esses documentos, um usuário pode consultar informações correlatas, como registros de ausência, substituições temporárias ou movimentações administrativas. Isoladamente, esses dados não revelam informação sensível. No entanto, quando combinados ao longo do tempo, podem permitir inferências sobre a existência, duração ou natureza do afastamento.
Assim, relações aparentemente inofensivas podem ser encadeadas de forma a permitir a inferência de informações não autorizadas, violando a premissa fundamental de controle de acesso. Esse tipo de risco é particularmente crítico em ambientes onde a estrutura do grafo de conhecimento expande a busca semântica, incluindo vínculos organizacionais, hierárquicos ou processuais.
Para contornar esse problema, é essencial implementar mecanismos que limitem a navegação pelo grafo com base em políticas de autorização, garantindo que tanto os vértices quanto as arestas respeitem o nível de acesso do usuário. Além disso, a própria lógica de resposta deve ser projetada para evitar que informações sensíveis influenciem o resultado, mesmo de forma indireta.
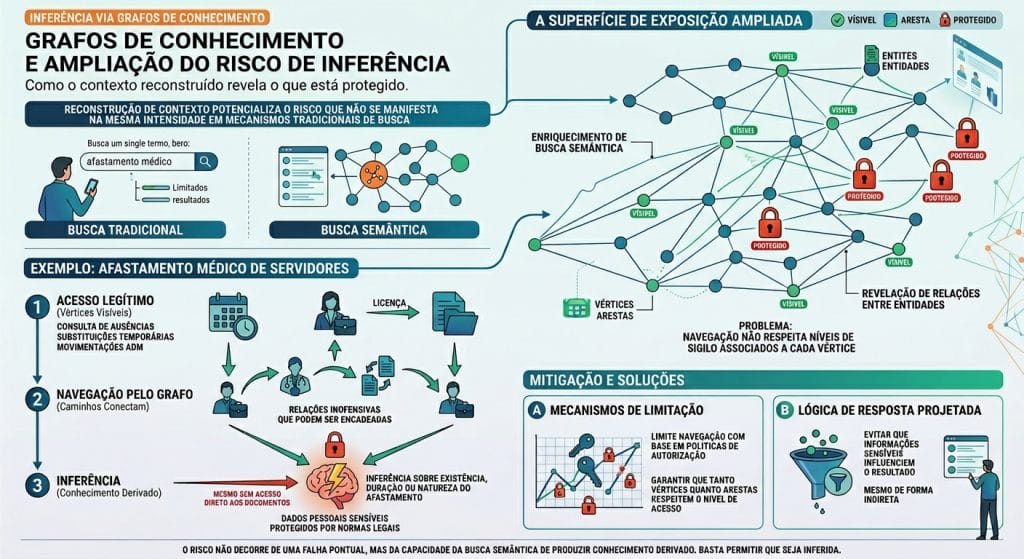
Nesse caso, o risco não decorre de uma falha pontual de autorização, mas da capacidade da busca semântica produzir conhecimento derivado a partir da navegação entre os vértices e arestas do grafo de conhecimento, ou seja, não é necessário acessar diretamente uma informação sensível para comprometer seu sigilo, basta permitir que ela seja inferida.
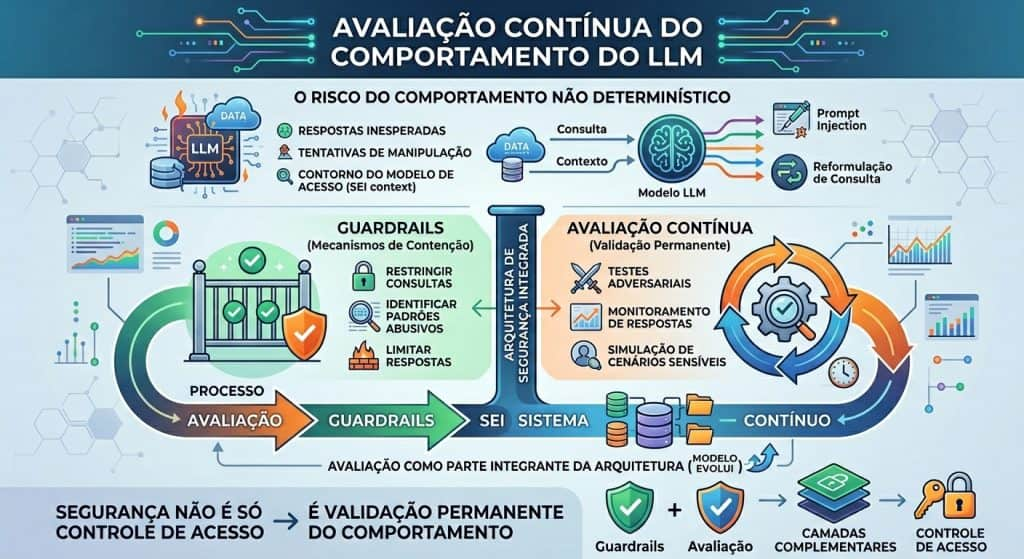
Avaliação contínua do comportamento do LLM
Mesmo com controles estruturais de acesso e mecanismos de proteção no nível da recuperação, permanece uma camada de risco associada ao comportamento dos modelos de linguagem. Sistemas baseados em busca semântica não são determinísticos, e sua resposta depende da interação entre consulta, contexto e inferência probabilística. Isso significa que, mesmo operando dentro de restrições formais, o sistema pode produzir respostas inesperadas ou indesejadas.
Nesse contexto, o risco decorre de tentativas deliberadas de manipulação do comportamento do modelo. Técnicas como prompt injection podem ser utilizadas para induzir o sistema a ignorar restrições, reinterpretar instruções ou tentar acessar informações fora do escopo autorizado. Em ambientes como o SEI, isso pode se manifestar na formulação de consultas que buscam contornar o modelo de acesso por meio de reformulações ou exploração do contexto.
Para mitigar esses riscos, é necessário combinar duas abordagens complementares. A primeira envolve o uso de barreiras de proteção (guardrails), que atuam como mecanismos de contenção no nível da interação. Eles permitem restringir tipos de consulta, identificar padrões de uso potencialmente abusivos e limitar respostas que possam extrapolar os limites estabelecidos.
A segunda envolve a adoção de um processo contínuo de avaliação do comportamento do sistema. Diferentemente de sistemas determinísticos, modelos de linguagem exigem validação constante por meio de testes adversariais (evaluation tests), monitoramento de respostas e simulação de cenários sensíveis. Isso inclui a construção de casos de teste que representem situações reais, como inferência de dados pessoais, reconstrução de contexto institucional ou tentativas de exfiltração de informação.
Essa avaliação deve ser tratada como parte integrante da arquitetura, e não como uma etapa pontual. À medida que o modelo evolui, seja por atualização de dados, ajuste de parâmetros ou mudança no padrão de uso, novos riscos podem emergir, exigindo reavaliação contínua, pois a segurança em sistemas baseados em busca semântica não é apenas uma questão de controle de acesso, mas de validação permanente do comportamento do sistema.
É importante destacar que nem os guardrails nem a avaliação substituem o controle de acesso. Ambos atuam como camadas complementares, voltadas à contenção de comportamento e à detecção de riscos.
Monitoramento e sensibilidade das interações
A adoção de estratégias de avaliação contínua e monitoramento do comportamento do sistema introduz uma camada adicional de complexidade do ponto de vista da segurança.
As interações entre usuários e sistemas baseados em busca semântica frequentemente contêm informações sensíveis, incluindo dados pessoais, contexto institucional e indícios de processos internos. Em muitos casos, essas conversas podem revelar não apenas o conteúdo acessado, mas também a intenção do usuário e o caminho percorrido na tentativa de obter determinada informação.
Isso implica que os próprios registros de interação utilizados para auditoria, monitoramento e avaliação contínua devem ser tratados como ativos sensíveis, uma vez que o log de interação pode conter informação tão crítica quanto os próprios documentos do SEI.
Esse cenário cria um paradoxo: mecanismos introduzidos para aumentar a segurança podem, se mal projetados, se tornar novos vetores de exposição de dados.
Para mitigar esse risco, torna-se necessário aplicar aos registros de interação os mesmos princípios de controle de acesso, classificação e proteção utilizados para os dados originais. Isso inclui a minimização de dados coletados, a anonimização de informações sensíveis, a restrição de acesso aos logs e a definição de políticas de retenção adequadas.
Dessa forma, a arquitetura de segurança deve considerar não apenas o acesso aos dados primários, mas também o tratamento das informações derivadas do uso do sistema.
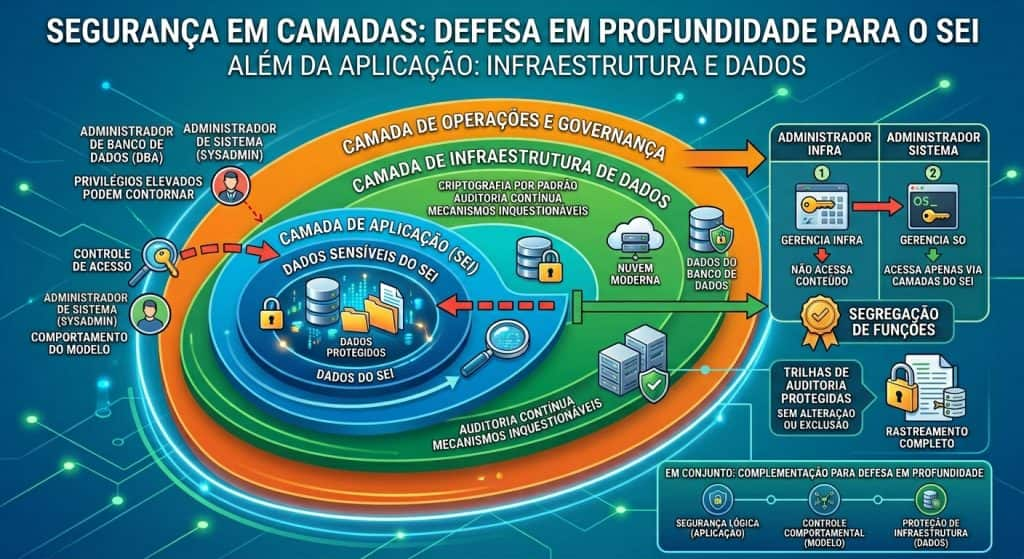
Segurança além da aplicação: proteção da infraestrutura e dos dados
Até este ponto, discutimos o controle de acesso no nível da busca semântica e do comportamento do modelo. No entanto, isso não é suficiente.
Usuários com privilégios elevados, como administradores de banco de dados ou de sistema operacional, podem acessar diretamente os dados e contornar a lógica de autorização do SEI. Um DBA pode consultar tabelas diretamente. Um administrador de sistema pode acessar arquivos, backups ou volumes de armazenamento.
Essa possibilidade evidencia que não basta garantir que o sistema respeite o controle de acesso, é necessário garantir que ele não possa ser contornado.
Para mitigar esse risco, a proteção deve se estender à própria infraestrutura de dados.
Nesse contexto, rodar o SEI em ambientes modernos de nuvem introduz vantagens adicionais, como criptografia habilitada por padrão, auditoria contínua e mecanismos de segurança que não podem ser facilmente desativados. Esses controles reduzem a dependência de configuração manual e aumentam a rastreabilidade das operações.
Ainda assim, a adoção de nuvem não elimina a necessidade de controles adicionais. Torna-se essencial adotar o princípio de segregação de funções, garantindo que nenhum ator isolado possua acesso completo ao SEI.
Além disso, trilhas de auditoria devem ser protegidas contra alteração ou exclusão indevida, garantindo rastreabilidade e conformidade regulatória.
Em conjunto, essas práticas estabelecem uma abordagem de defesa em profundidade, na qual segurança lógica, controle comportamental e proteção de infraestrutura atuam de forma complementar.
Para os leitores que desejarem ter uma visão mais profunda sobre a implementação do SEI em nuvem pública de forma segura, recomendo a leitura do artigo abaixo.
Saiba como rodar o SEI com segurança e flexibilidade na Oracle Cloud
Conclusão
A busca semântica em conjunto com a reconstrução de contexto via grafos de conhecimento amplifica o poder a recuperação dentro do SEI, mas torna a segurança um requisito estrutural, não acessório.
Ao longo do artigo, vimos que o controle de acesso não pode ser tratado apenas na etapa final da busca semântica. Ele precisa estar integrado à própria recuperação, por meio de filtragem antecipada com rótulos, sincronização contínua orientada a eventos e validação final no SEI. Discutimos ainda os riscos de inferência em grafos, o papel de guardrails e avaliação contínua, além da necessidade de proteger logs e a própria infraestrutura.
Em conjunto, essas estratégias formam uma abordagem em camadas, essencial para garantir não apenas quem pode acessar a informação, mas como ela influencia as respostas.
Porque não basta proteger o dado. É preciso proteger o contexto.
Na Parte 3, apresentaremos uma implementação prática de referência que concretiza esses princípios em uma arquitetura de busca semântica segura no SEI.
Referências
Busca Semântica em Bases Documentais Complexas como o SEI
https://blogs.oracle.com/oracle-brasil/busca-semantica-em-bases-documentais-complexas-como-o-sei
Saiba como rodar o SEI com segurança e flexibilidade na Oracle Cloud
SEI-Atos
https://wiki.processoeletronico.gov.br/pt-br/latest/PROJETO_SIDOF/index.html
What is LLM Observability and Monitoring?
