MySQL HeatWave Lakehouse is now available on AWS.
MySQL HeatWave is the only cloud database offering that provides an online transactional processing (OLTP) database, a real-time in-memory data warehouse, and in-database automated machine learning capabilities in a single MySQL database service—without the complexity, latency, risks, and cost of ETL duplication.
With the addition of the Lakehouse capability in MySQL HeatWave, AWS customers can now run transaction processing, real-time analytics across data warehouses and data lakes, and machine learning in one cloud database service. They can replace five AWS services with one, reducing complexity and obtaining the best price-performance in the industry for analytics.
With HeatWave Lakehouse, AWS customers can query hundreds of terabytes of data in Amazon S3 object storage in a variety of file formats including CSV, Parquet, Avro, and export from other databases without copying the S3 data to the database. The query processing is done entirely in the HeatWave engine, enabling customers to take advantage of HeatWave for both non-MySQL and MySQL-compatible workloads. They can continue to run applications on AWS with no changes and without incurring unreasonably high AWS data egress fees. Customers can also run AutoML on HeatWave Lakehouse, which provides them with the ability to automatically train machine learning models, run inference and explanations on files stored in S3, and run various kinds of machine learning analysis from the interactive MySQL HeatWave console. MySQL HeatWave Lakehouse on AWS is now in limited availability.
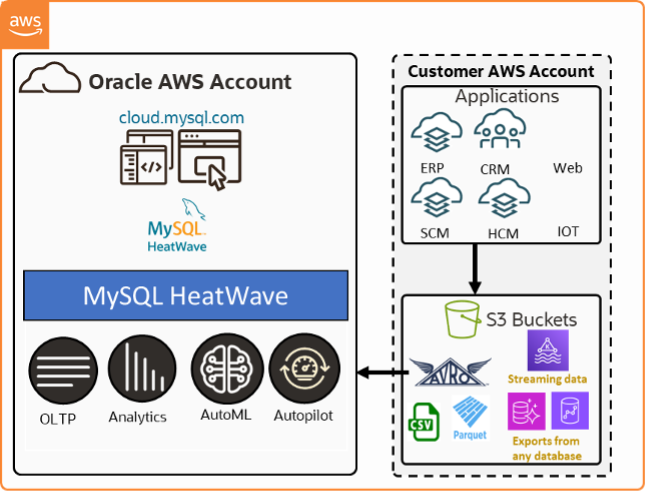
HeatWave Lakehouse in AWS
With HeatWave Lakehouse, users can use standard MySQL syntax to query data that combines the hundreds of terabytes of data from S3 with transactional data stored in the MySQL database. Loading hundreds of terabytes of data can be challenging and time-consuming for a variety of reasons, such as accurately defining the schema on files that may not have a pre-defined schema, like CSV files. MySQL HeatWave Lakehouse uses adaptive, MySQL Autopilot ML-driven techniques that minimize the amount of data loading and optimize network transfers to increase aggregate network bandwidth for the S3 data load, resulting in industry-leading data load performance.
Why do you need a Lakehouse?
There has been exponential data growth over the past several years. Most of this data is generated outside of traditional OLTP applications. IoT sensors, connected devices and vehicles, Web applications, telemetry endpoints, etc… generate massive amounts of data that is typically stored in object storage. It is neither practical nor cost-effective to ETL this data to a database for analysis.
This data is generally stored in CSV, Parquet, Avro, and other file formats. In many cases, it is semi-structured or unstructured. It’s time-consuming to infer the schema of this data, even more so when the schema changes.
Analyzing this data often requires combining it with data from OLTP systems and combining data from these two storage systems can be daunting.
Businesses want to learn about usage patterns and make predictions about, for example, customer adoption, likelihood of part or machine failure, new feature uptake, or customer retention. They also want to identify upsell and cross-sell opportunities using the data in object storage. This often requires them to use another service for machine learning.
With massive amounts of data, businesses also want the flexibility of scaling up or down their lakehouse system based on data volume and usage frequency.
To use all these capabilities, customers don’t want to learn another query language or write custom scripts. The most common and popular data query language is SQL and customers want to continue using existing analytics applications that understand SQL with this object storage data.
Why choose HeatWave Lakehouse?
- HeatWave Lakehouse does not require customers to move data into a database. Data from object storage is read and loaded into the HeatWave cluster memory in a highly optimized format that is conducive to extremely fast performance over massive amounts of data.
- HeatWave Lakehouse can read and load data in CSV, Parquet, Avro, and other database export files without having to convert them. MySQL Autopilot is a feature of HeatWave and makes use of machine learning to automate and streamline several tasks such as adaptive sampling and schema inference, capacity estimation, fast loading of data in parallel, optimizing query execution, etc…
- In a single MySQL HeatWave instance, users can not only query data from the OLTP database and from object storage, but they can also combine data from both sources in a single query using standard MySQL syntax. The underlying data structure and physical representation are abstracted out to users.
- Machine learning is available on both OLTP data and object storage data loaded into HeatWave using standard functions. With HeatWave AutoML, users employ a common set of APIs to train, predict, and explain classification, regression, time-series forecasting, and recommendation systems, irrespective of whether the data is in object storage or the database. This greatly simplifies ML tasks.
- HeatWave Lakehouse employs a highly partitioned architecture to process data from S3 without moving data out of AWS. This can avoid substantial data egress charges customers would otherwise incur on AWS.
- A user-friendly interface allows customers to easily connect MySQL HeatWave to the data residing in S3.
- Secure access to customer data buckets using AWS IAM (Identity and Access Management) roles provides customers with complete control over what data is shared with the MySQL HeatWave on AWS service.
- Customers can provision large clusters (with hundreds of nodes) in minutes.
Using HeatWave Lakehouse on AWS in four simple steps
Let us look at how users can start querying data in S3 with HeatWave Lakehouse in four simple steps.
Step 1: Launch a HeatWave Cluster
Login to your MySQL HeatWave on AWS console from https://cloud.mysql.com/ and create a DB System (minimum MySQL version is 8.1.0). If you already have a DB System and intend to use the Lakehouse feature, you can upgrade your DB System to a MySQL version that supports Lakehouse.
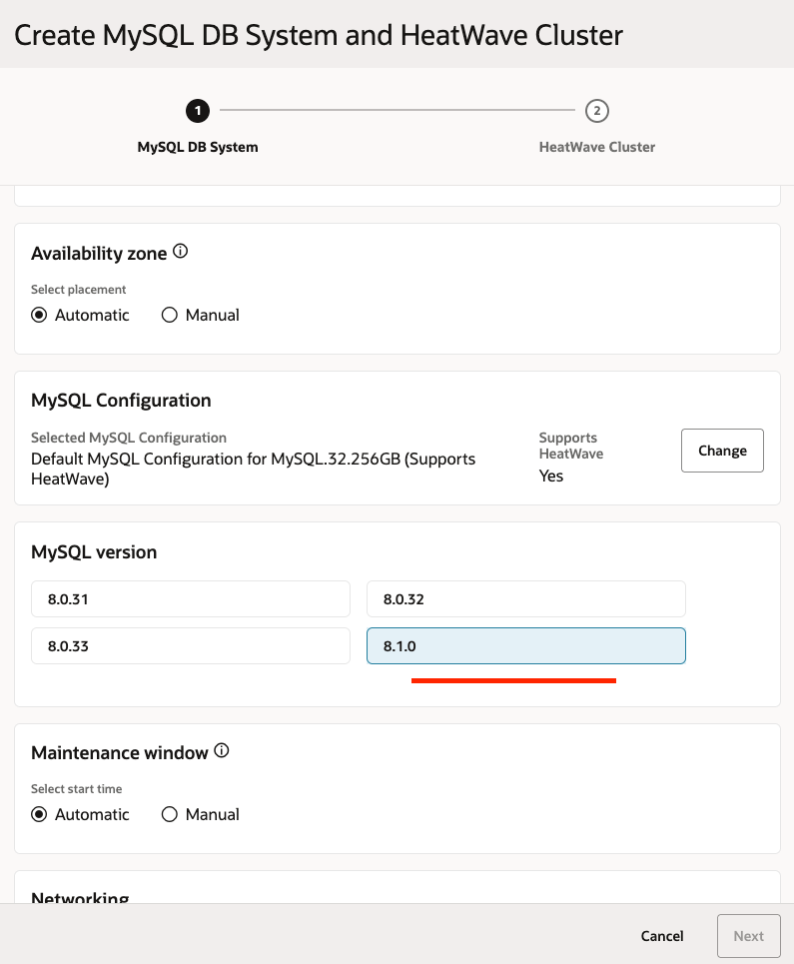
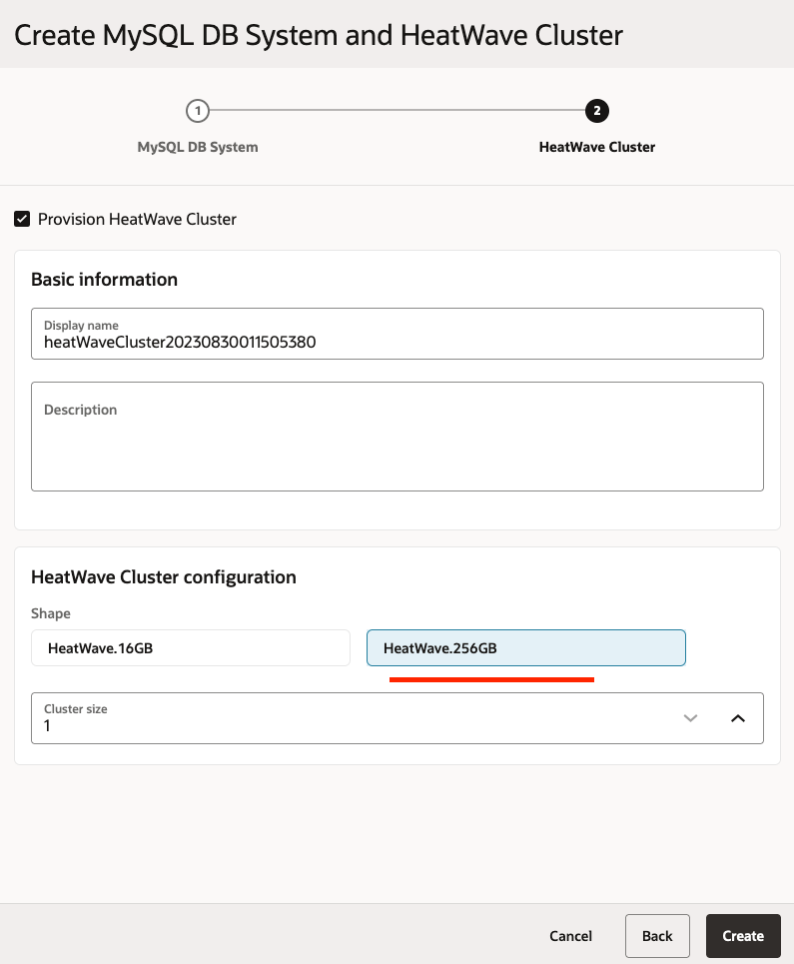
Add a HeatWave Cluster with the “HeatWave.256GB” shape to your DB System (you need to select the HeatWave.256GB shape if you want to use the Lakehouse features). This will automatically enable the Lakehouse feature on your HeatWave cluster.
Step 2: Give your HeatWave system access to S3
HeatWave Lakehouse requires that the database system has permissions to access data in the S3 bucket in your AWS account. For this, you will need to create an IAM role with the right permissions. This means creating policies that grant necessary S3 permissions to the specified buckets and attaching these policies to the IAM role mentioned above. This allows customers to provide access to their buckets securely and maintain full control of the access policy.
You can find the assigned “LakehouseRoleARN” on the MySQL details page for the selected instance.
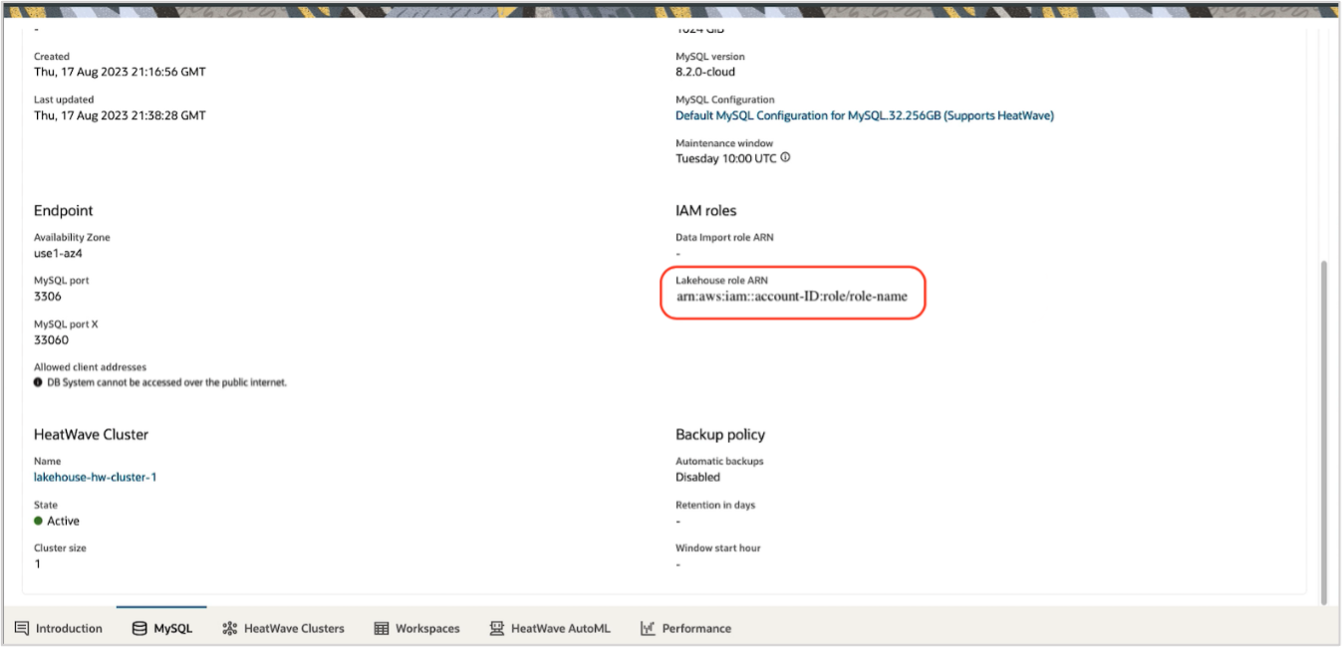
Step 3: Create Lakehouse Mapping
Once you have enabled access to S3 by creating the required role ARN, you connect to your DB system. From the “Manage Data in HeatWave” tab, you then create a Lakehouse mapping by providing the required details: the S3 URI address of the file, the file format (Parquet, CSV, Avro,…), schema, and the name of the table you want to load this data into.
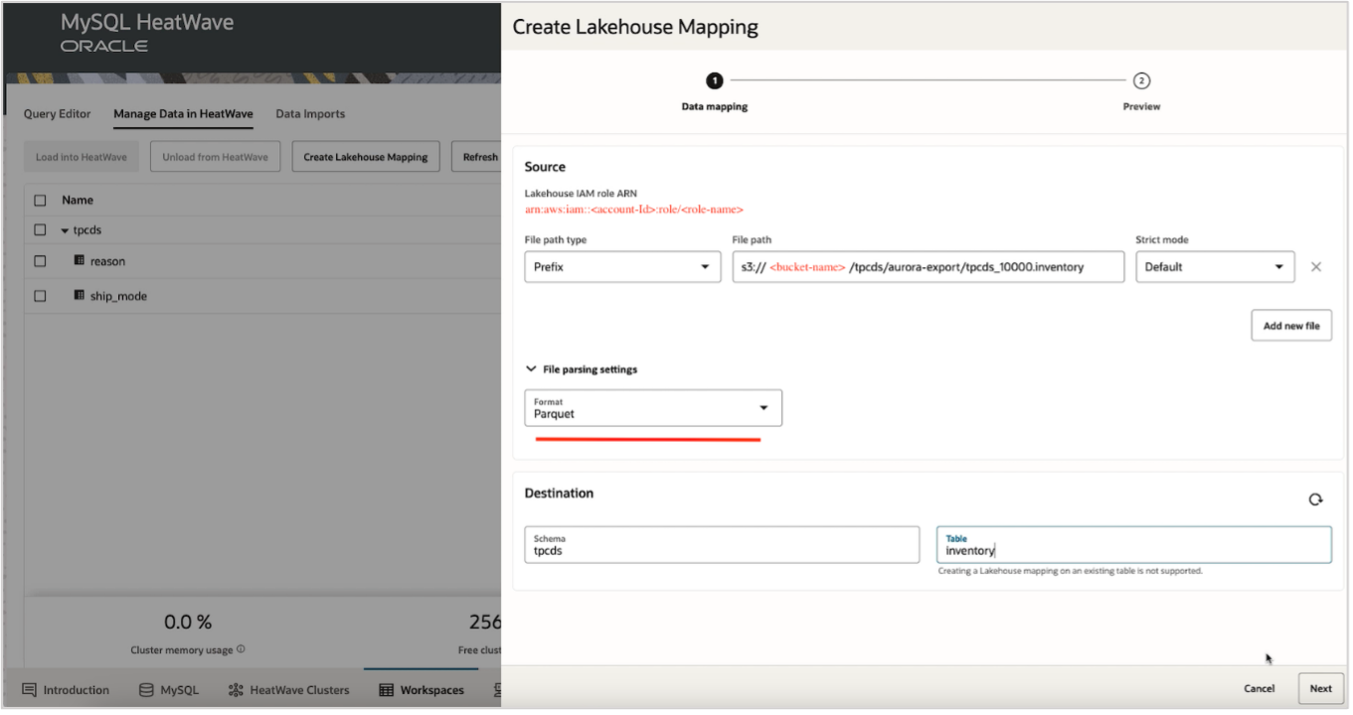
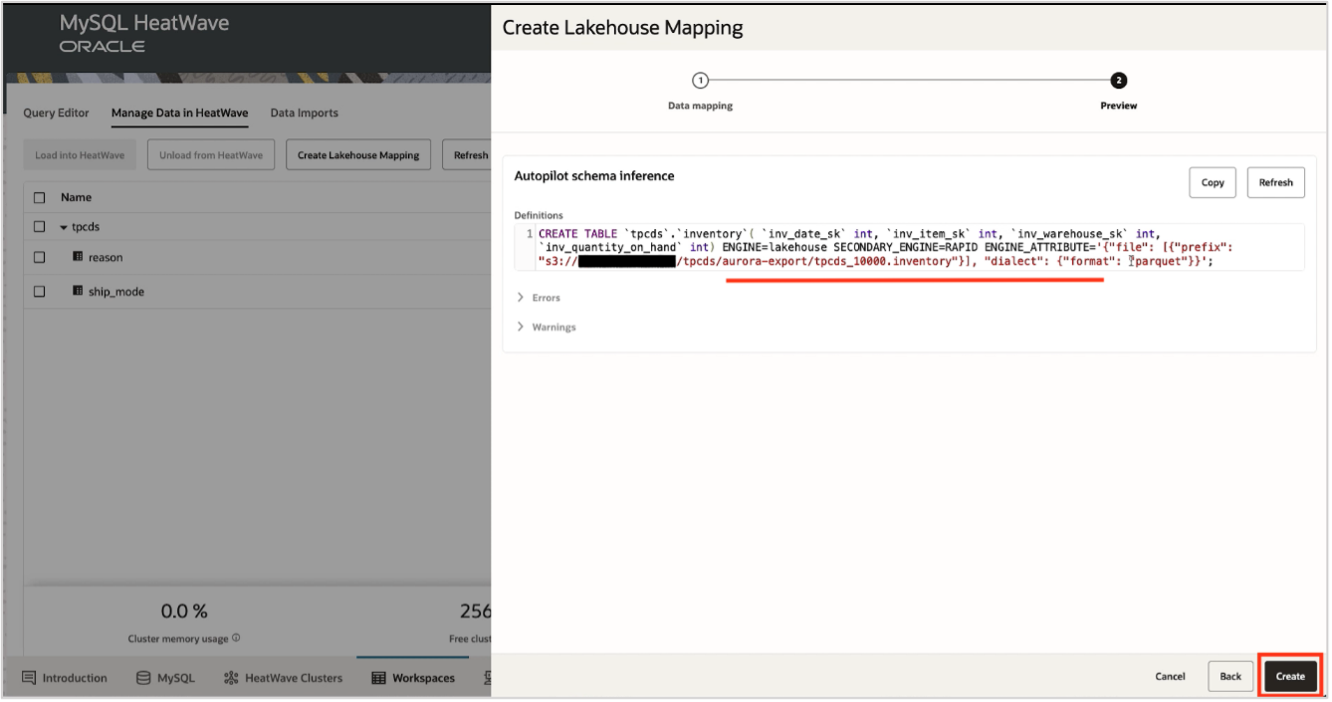
MySQL Autopilot infers the schema, estimates the capacity required, and generates the scripts required to create the table and load this data into HeatWave Lakehouse. Review the generated SQL according to the provided information, addressing any errors or warnings. Once the review is complete, proceed by clicking the Create button.
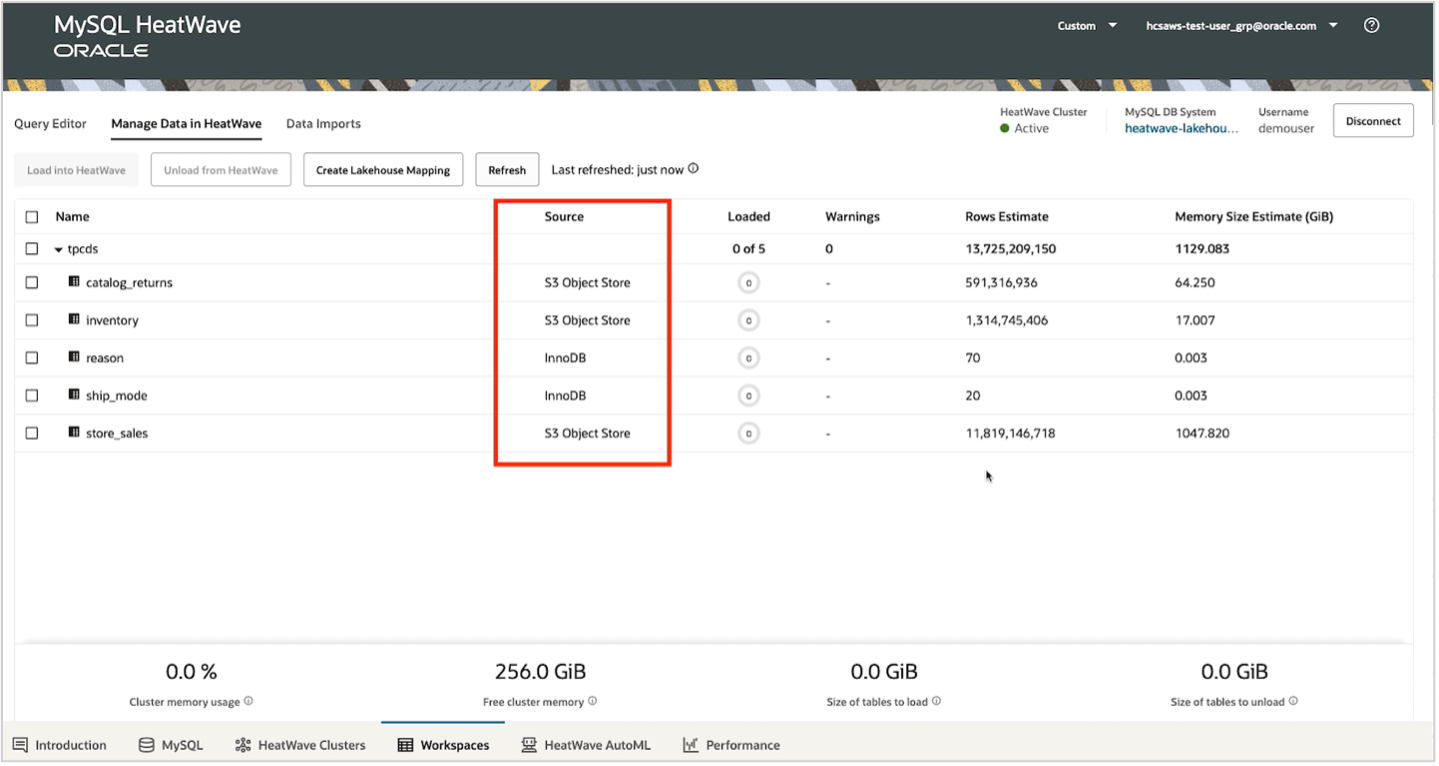
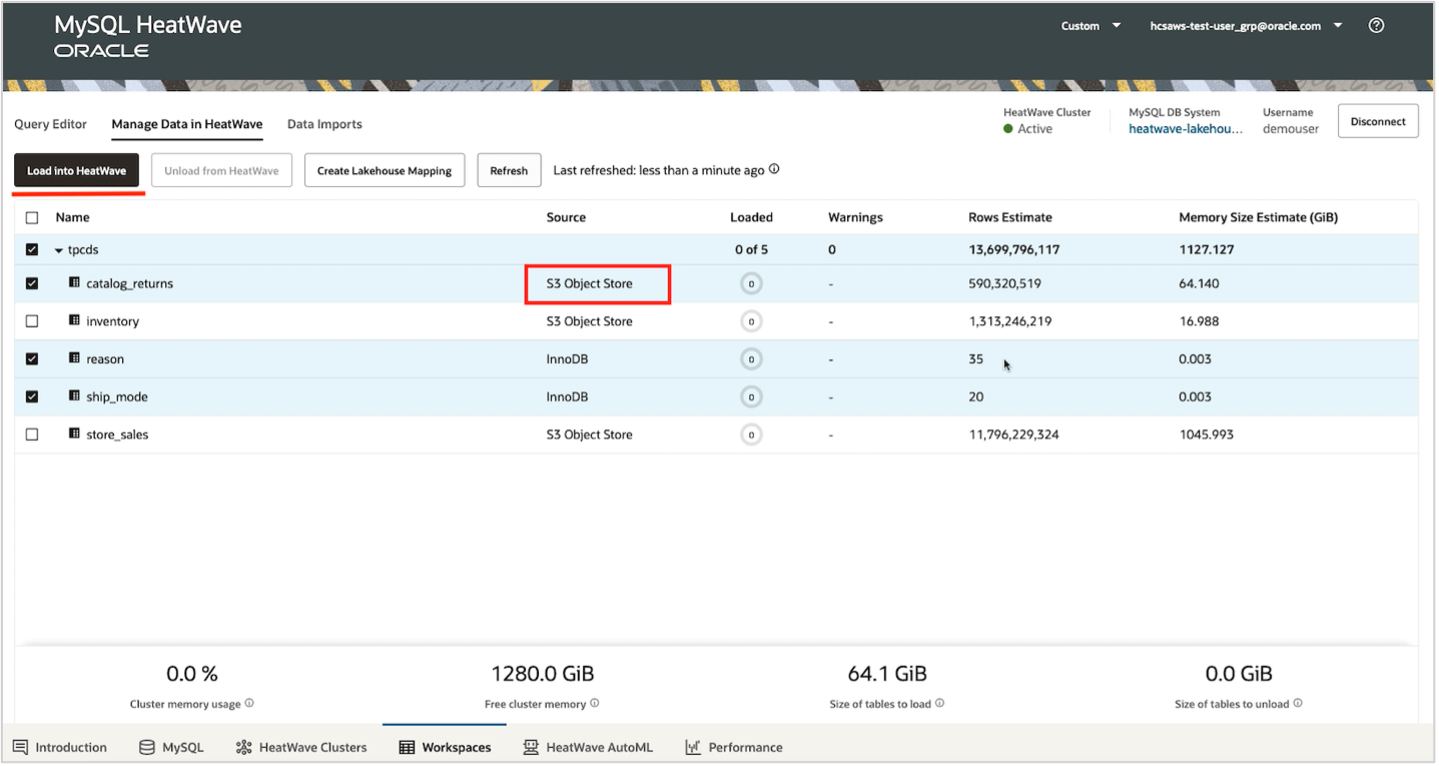
Once you have created mappings for all your tables, you can view them under the ‘Manage Data in HeatWave’ tab. You can also see the source for all these tables, whether they have been loaded or not, the estimated row count and estimated memory estimate (computed by MySQL Autopilot).
Users can also use the auto-provisioning feature by selecting Estimate cluster size. MySQL Autopilot will provide all the necessary details, including the required memory and number of nodes needed to load the above tables into HeatWave.
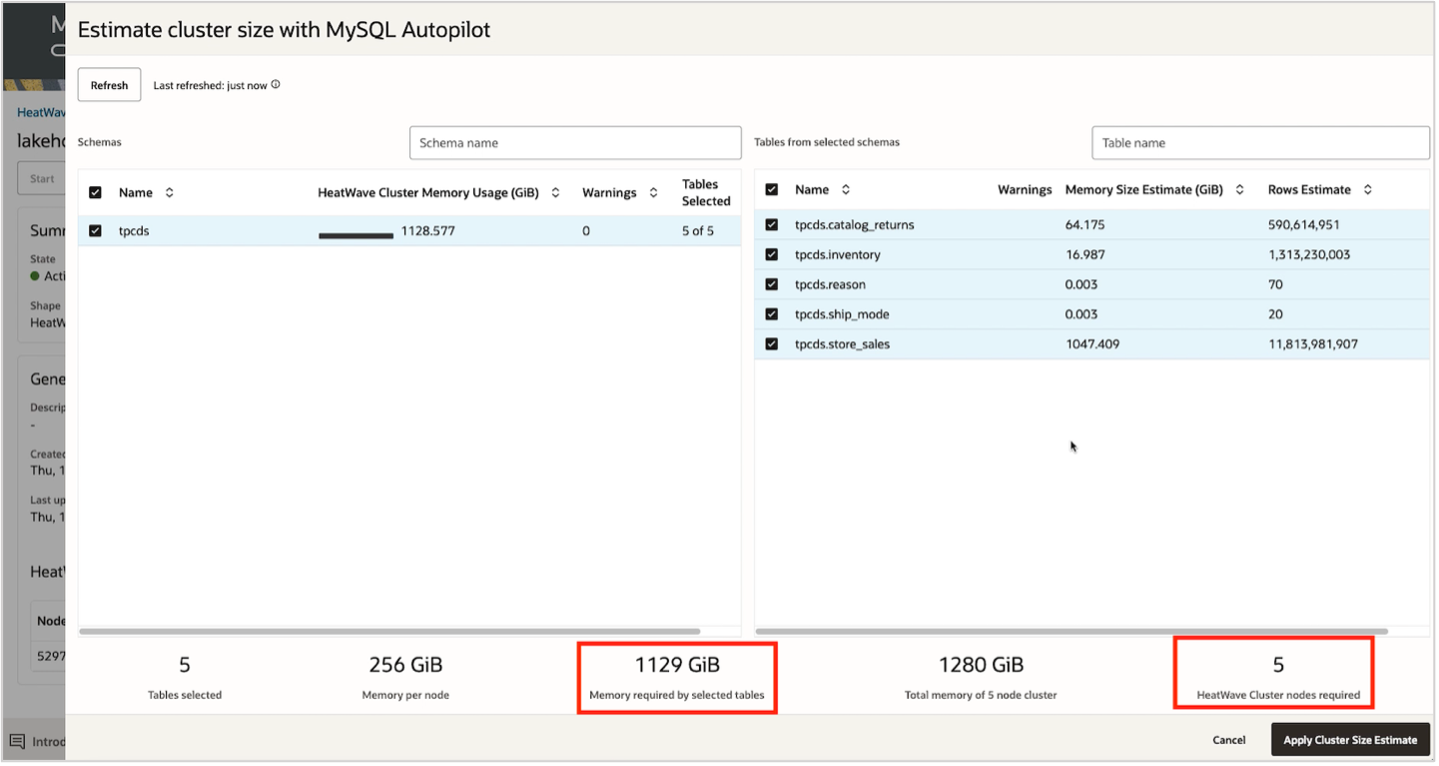
Apply the update to modify the HeatWave cluster size. Once the cluster becomes Active, it is ready to be used.
Step 4: Load and start querying data from S3
Use the “Manage Data in HeatWave” tab to load your tables, including those from an S3 bucket, into HeatWave by clicking on “Load into HeatWave“.
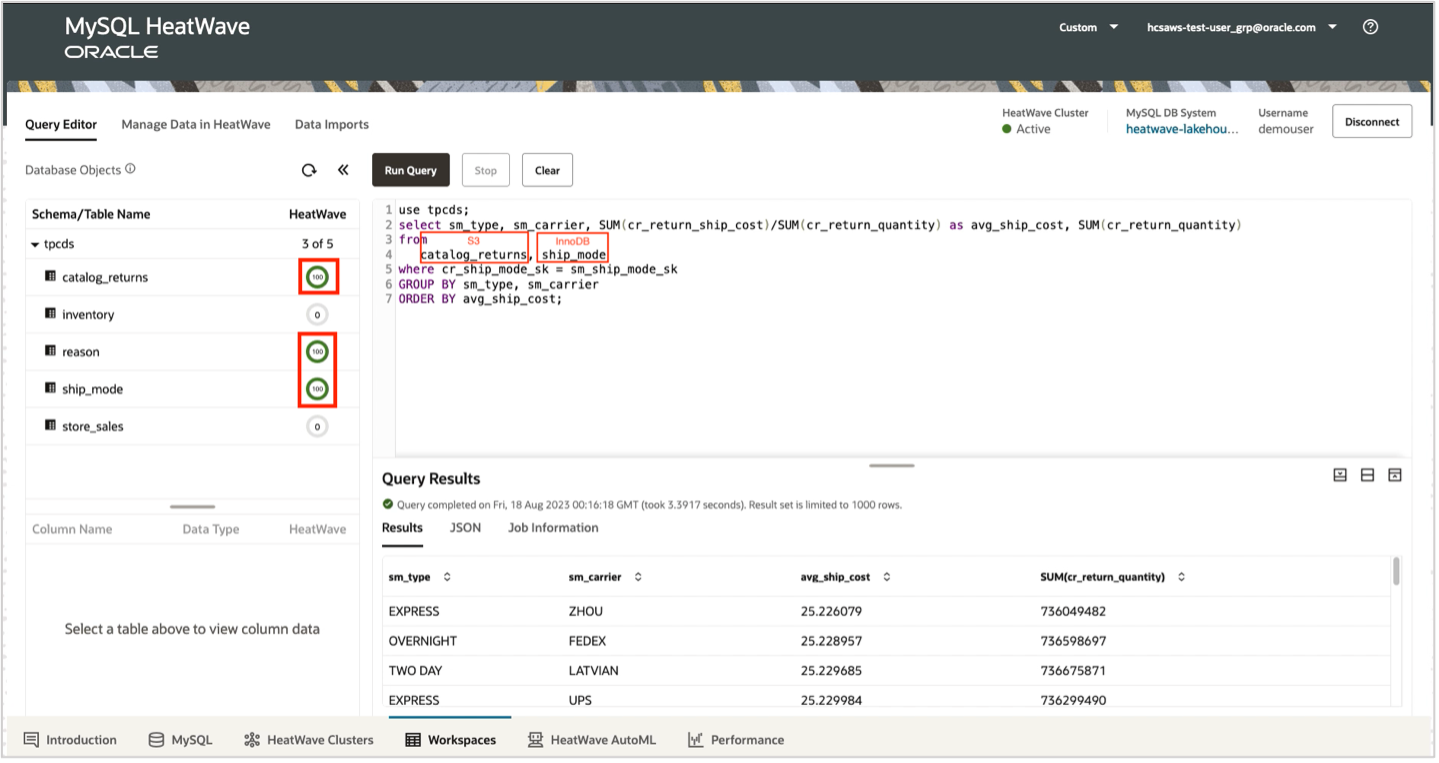
Navigate to the “Query Editor” tab. On the left side, you’ll find the displayed percentage of data loaded into HeatWave. Use the query editor to execute your queries on tables from different data sources such as InnoDB and S3.
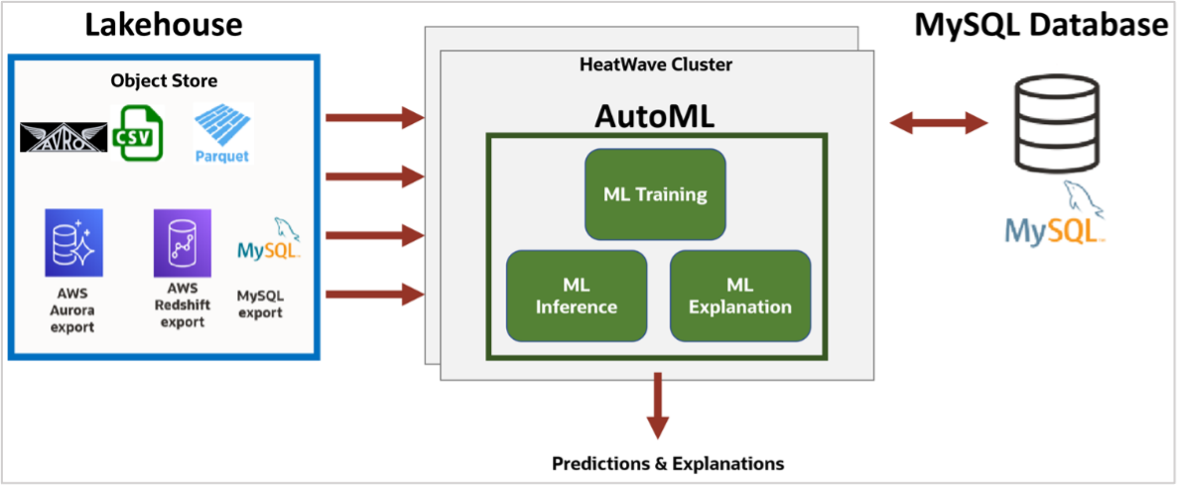
Machine Learning with HeatWave AutoML
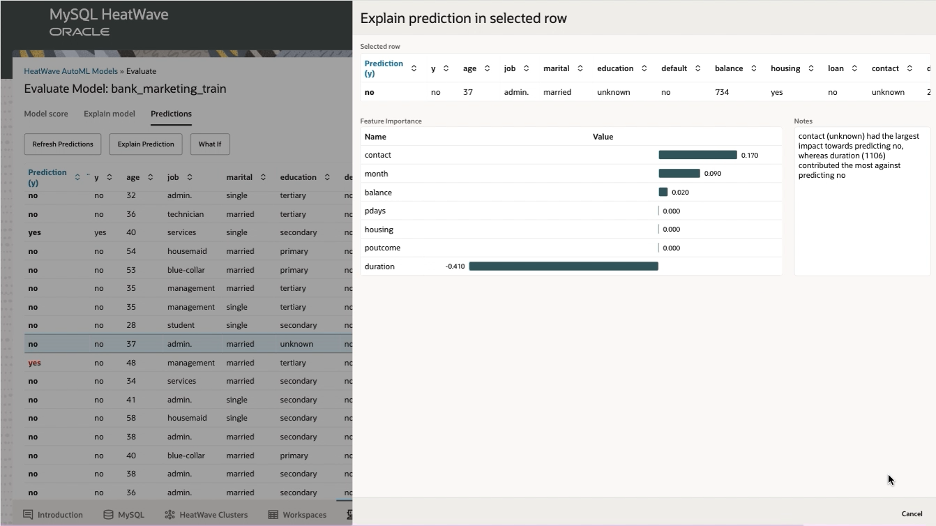
Customers can now train, predict, and explain their machine learning models on data loaded from S3. HeatWave AutoML uses a common set of APIs to train, predict, and explain a model, irrespective of whether the data is in the lakehouse or is in the database. Once loaded into HeatWave from S3, users can create a model, train the model, and use this trained model to make predictions. The interactive console simplifies the process of creating models, explaining them, deriving inferences, and performing scenario analysis so that even a non-technical user can easily use machine learning.
Machine learning with HeatWave Lakehouse
HeatWave Lakehouse offers a single service for processing and querying data in a transactional database, object storage, and for running machine learning models to make predictions on data—using standard MySQL syntax and without having to move data from object storage to the database nor needing ETL processes.
