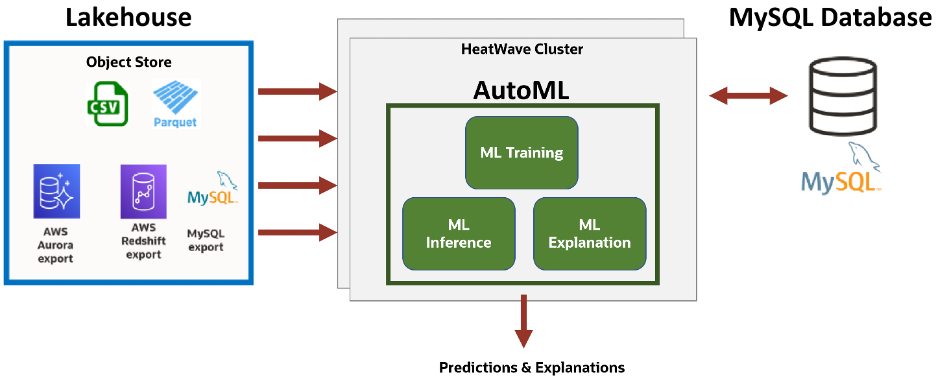
MySQL HeatWave Lakehouse enables users to query up to half a petabyte of data in object storage in a variety of file formats, such as CSV, Parquet, Avro, and export files from other databases (e.g., Amazon Aurora, Redshift, MySQL, etc…). Customers can query data in various formats in object storage, transactional data in MySQL databases, or a combination of both using standard MySQL syntax. The query processing is done entirely in the HeatWave engine, enabling customers to take advantage of HeatWave for non-MySQL workloads in addition to MySQL-compatible workloads. Querying the data in object storage is as fast as querying the database, an industry first.
Using HeatWave AutoML, users can now build machine learning models on a blend of data, either sourced from an object store, the database, or both. This provides a consistent approach to building ML models using data from both MySQL and non-MySQL workloads. ML capabilities are included at no additional cost for MySQL HeatWave users.
Machine Learning with MySQL HeatWave Lakehouse
MySQL HeatWave Lakehouse supercharges MySQL HeatWave AutoML by enabling machine learning operations – such as training, prediction, and explanation – to be performed on data stored in an object store or inside the database. All machine learning tasks can be performed on content maintained as collections of files that are easy to organize, visualize, and understand. This ability to use content from varied sources simplifies machine learning tasks, paralleling the ease of working on the data warehouse.
HeatWave AutoML enables MySQL users to train a model and generate inferences and explanations, without using other ML tools/services. It provides several advantages:
- Fully Automated: HeatWave AutoML fully automates the creation of tuned models, thus eliminating the need for the user to be an expert data scientist.
- SQL Interface: Provides the familiar MySQL interface for invoking machine learning capabilities.
- Performance and Scalability: The performance of HeatWave AutoML is higher at a lower cost than competing services such as Redshift ML. Furthermore, HeatWave AutoML scales with the size of the cluster.
- Explanations: All models created by HeatWave AutoML can be explained. Organizations have a growing need to explain the predictions of machine learning models to build trust, demonstrate fairness, and comply with regulatory requirements.
- Easy Upgrades: HeatWave AutoML leverages state-of-the-art open-source Python ML packages that enable continual and swift uptake of newer (and improved) versions.
- Cost Efficiency: The advanced features of MySQL HeatWave AutoML are included at no additional cost.
HeatWave AutoML replaces the laborious and time-consuming tasks that a data scientist typically performs, as listed below:
- Preprocess the data
- Select an algorithm from a set of candidates to create a model
- Select only the relevant features to speed up the pipeline and reduce overfitting
- Select an optimized representative sample of data
- Tune the hyperparameters of the algorithm selected in step 2
- Ensure the model performs well on unseen data (also called generalization)

HeatWave AutoML leverages Oracle AutoML, which has a scalable design, minimizes the number of trials by extensive use of meta-learning, and provides an optimal model given a time budget. This proven technology has been integrated into various Oracle products, including the OCI Data Science Service and the Oracle Database.
MySQL HeatWave AutoML uses a common set of APIs to train, predict, and explain a model, irrespective of whether the data is in the object store or in the database, greatly simplifying ML tasks for the user.
Using HeatWave AutoML with HeatWave Lakehouse: Example
For this example, we are using a bank marketing data set. The data is related to a direct marketing campaign (phone calls) from a Portuguese banking institution. The goal of the machine learning model is to predict if the client will subscribe to a term deposit or not (classification use case).
Load data in object storage
The data resides in the object store and the first step is to load the training data. To do so, we can use HeatWave AutoSchema and AutoLoad to automatically determine the table schema. We must specify the object store location of the file in question and the CSV parsing parameters they wish to use.
When using the console, the data can be loaded directly from the object store using HeatWave Lakehouse by clicking ‘Create Lakehouse Mapping’ and setting the location and parsing parameters:
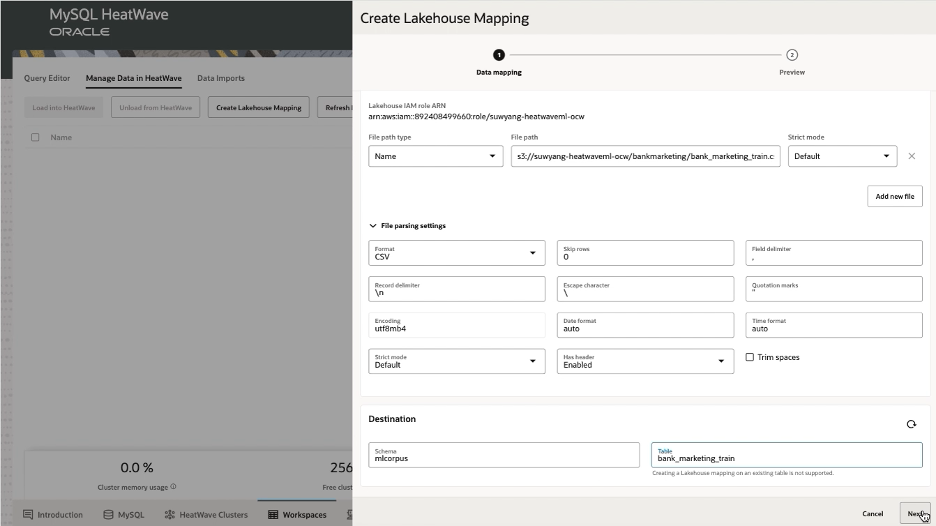
This will automatically generate a schema for the table, which is shown on the next screen:
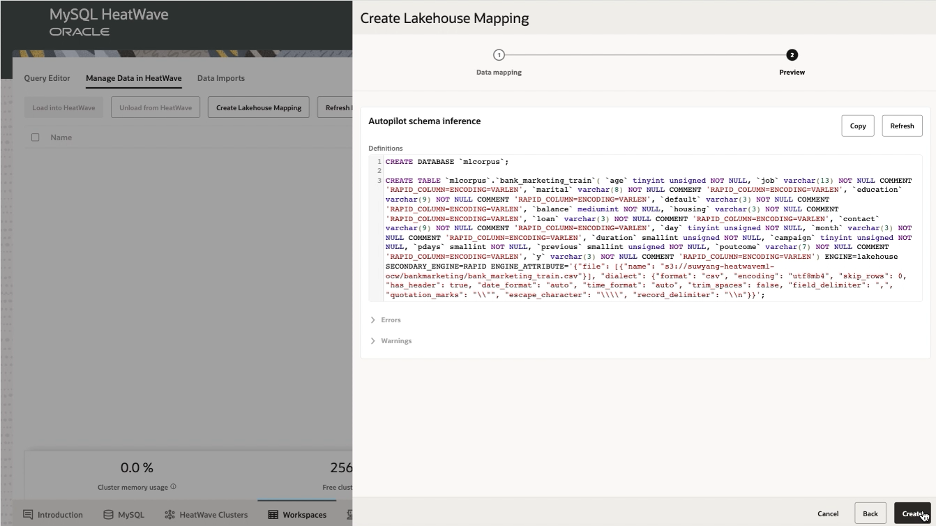
Next click ‘Create’ to create the table.
To load this data, click ‘Refresh Estimates’ and wait for the table to appear in the list. Once the table appears, select it and click ‘Load into HeatWave’, then ‘Load Tables’:
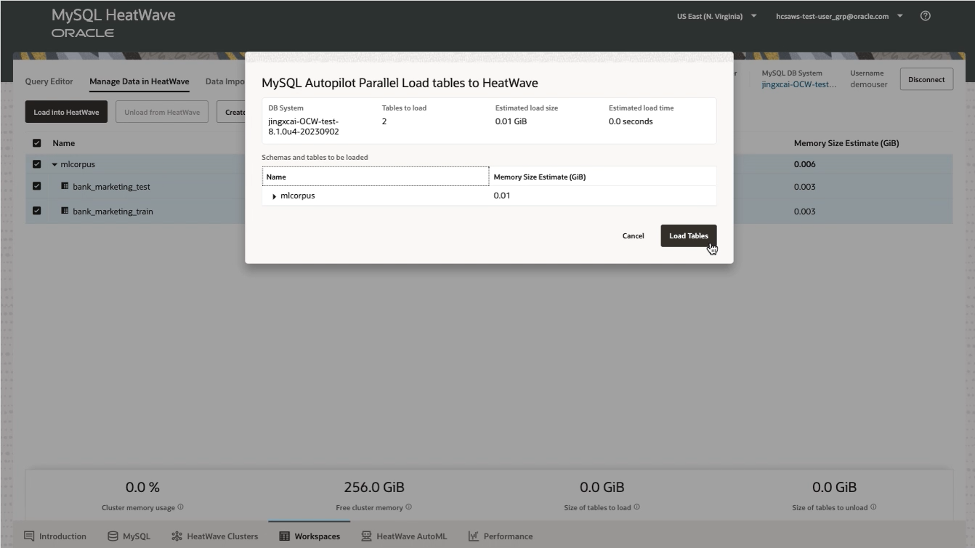
Once the load is complete, the loaded data can be verified by clicking the ‘HeatWave AutoML’ tab at the bottom. Then click ‘Create Model’, select the training table, and check that the columns are present:
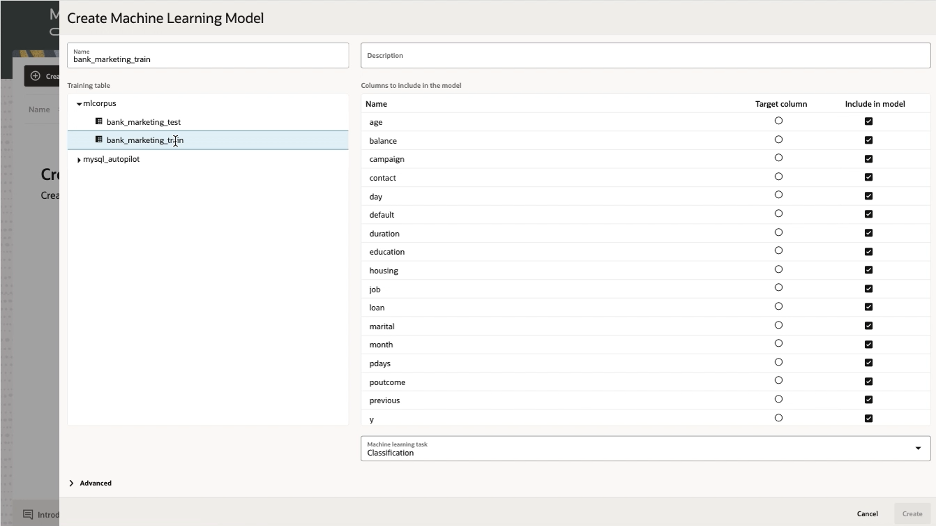
Use HeatWave AutoML to train a model using the data loaded
With the bank marketing data set loaded into the HeatWave cluster, we can now use HeatWave AutoML to train a classification model to predict whether the marketing calls successfully led to term deposit subscriptions. The target column in this dataset, which indicates whether the marketing call was successful, is named as ‘y’.
To train a model in the console, first click the ‘HeatWave AutoML’ tab at the bottom, then ‘Create Model’, then select the training table and finally select the target column to make predictions on.
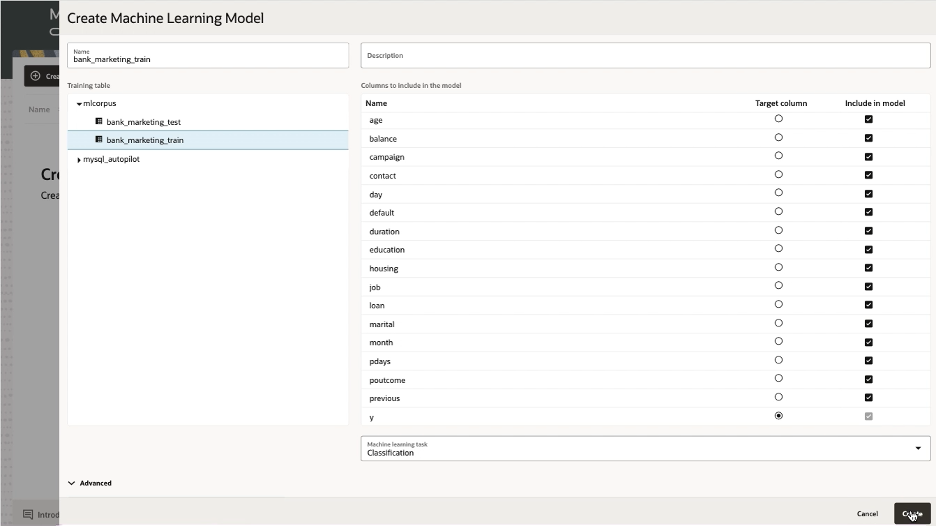
Then click ‘Create’ to train the ML model on that table with the selected target column:
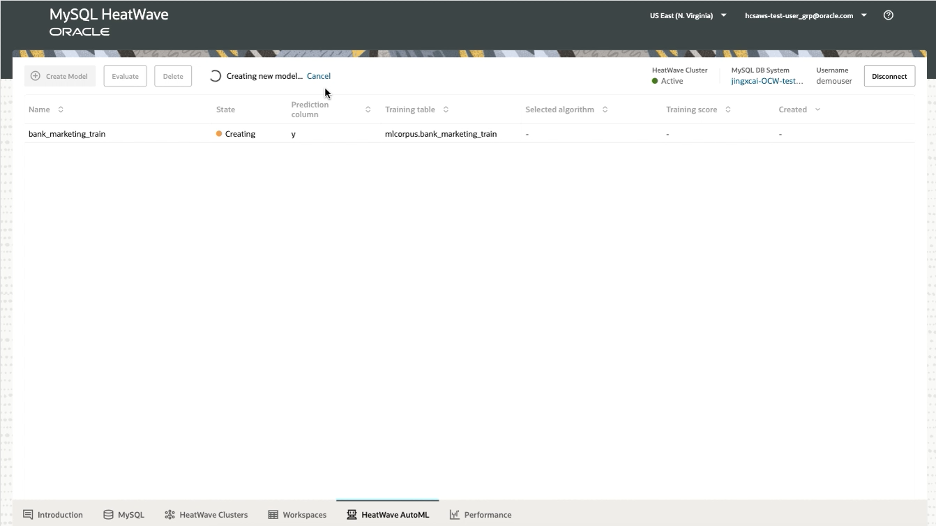
Once complete, the model will show a state of ‘Active’ meaning that it is loaded and ready to use:
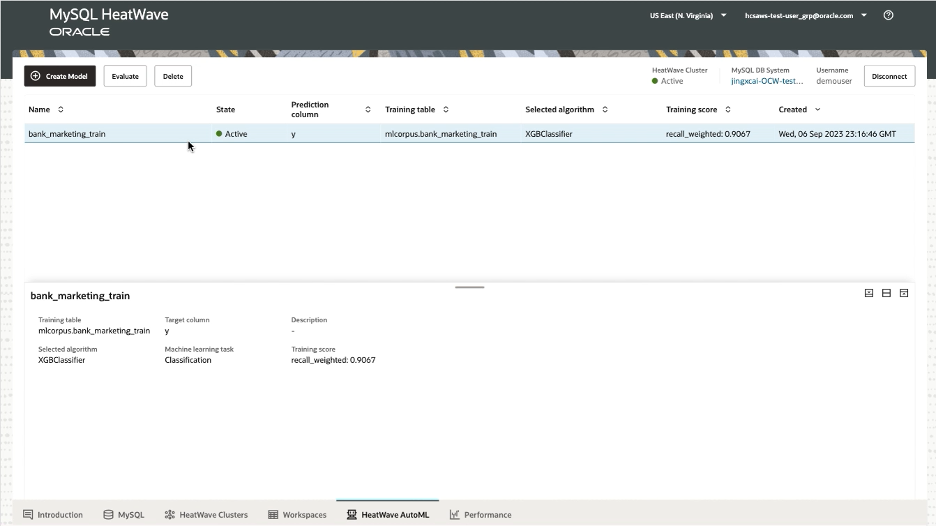
Use the trained model to make predictions
Using the model we just trained, we can make predictions using another test table. This is done by selecting the model that was trained, clicking ‘Evaluate’, selecting the table to make evaluations on, and clicking the ‘Predictions’ tab:
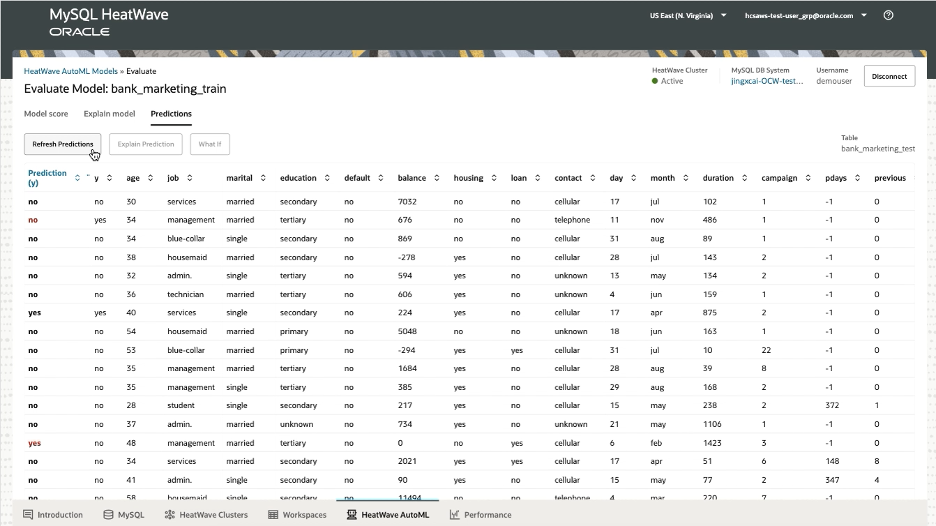
Click ‘Refresh Predictions’ to show the predictions for the selected table.
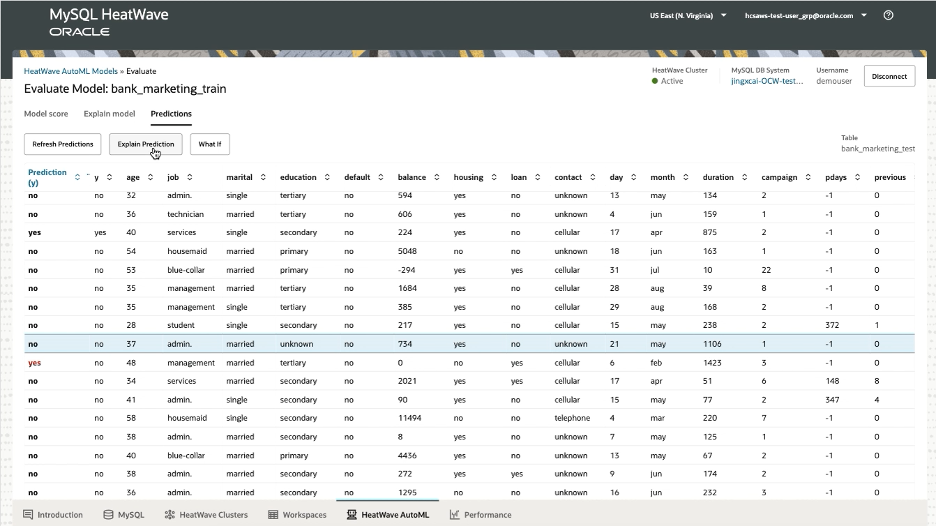
Explain the prediction
To further understand a prediction, click ‘Explain Prediction’:
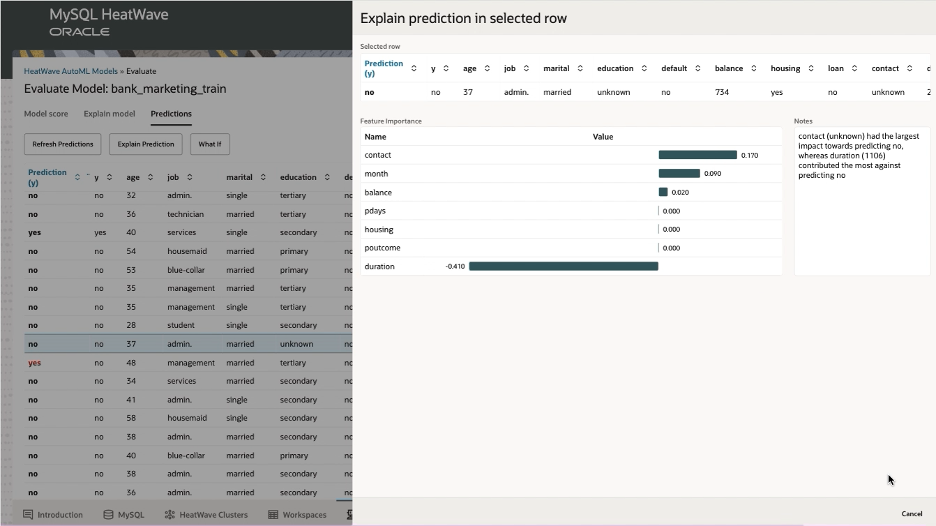
This shows both a plain text explanation and an array of attributions to understand what attributes were the most impactful in making the prediction.
We can see here that the ‘duration’ of the call had the largest impact to predict a ‘no’, and that ‘contact’ also had a large impact. However, we can also notice that the ‘month’ in which the call was made significantly impacted the customer’s decision. Calling a different month may have swayed this customer to a ‘yes’ to sign up for a term deposit.
In summary, users can very easily build ML models with HeatWave AutoML, using data in the object store, the database, or both. This provides a consistent approach to an automated machine pipeline for both MySQL and non-MySQL workloads. The interactive console simplifies the process of creating models, explaining them, deriving inferences, and performing scenario analysis, allowing even non-technical users to easily use machine learning.
Additional Resources:
