Introduction
MySQL HeatWave Lakehouse brings the power and speed and convenience of MySQL HeatWave to querying data in object storage. In our first blog post in the HeatWave Lakehouse series presented an overview of the new capabilities of HeatWave Lakehouse and how it extends the MySQL HeatWave portfolio by allowing users to process and query hundreds of terabytes of data in the object store—in variety of file formats, such as CSV, Parquet, and cloud database exports (e.g., Aurora and Redshift). In another blog post, we presented a walk-through on how to get started with MySQL HeatWave Lakehouse, including system setup, loading of data and then running queries on loaded data.
In this blog post, we continue our series, and we discuss how MySQL Autopilot’s new capabilities automate the data management tasks in HeatWave Lakehouse in particular, automating the process of ingesting data from external sources and enhancing the query execution. Before we dive into these new capabilities, let’s talk about Autopilot with a quick tour of its existing capabilities.
Background on MySQL Autopilot
MySQL Autopilot automates the most important and often challenging aspects of achieving high query performance at scale—including provisioning, loading, querying, and failure handling. In other words, it employs machine-learning-based automation to facilitate and enhance the three main stages of data management: system setup, data load, and query execution. It also facilitates the process of handling failures.
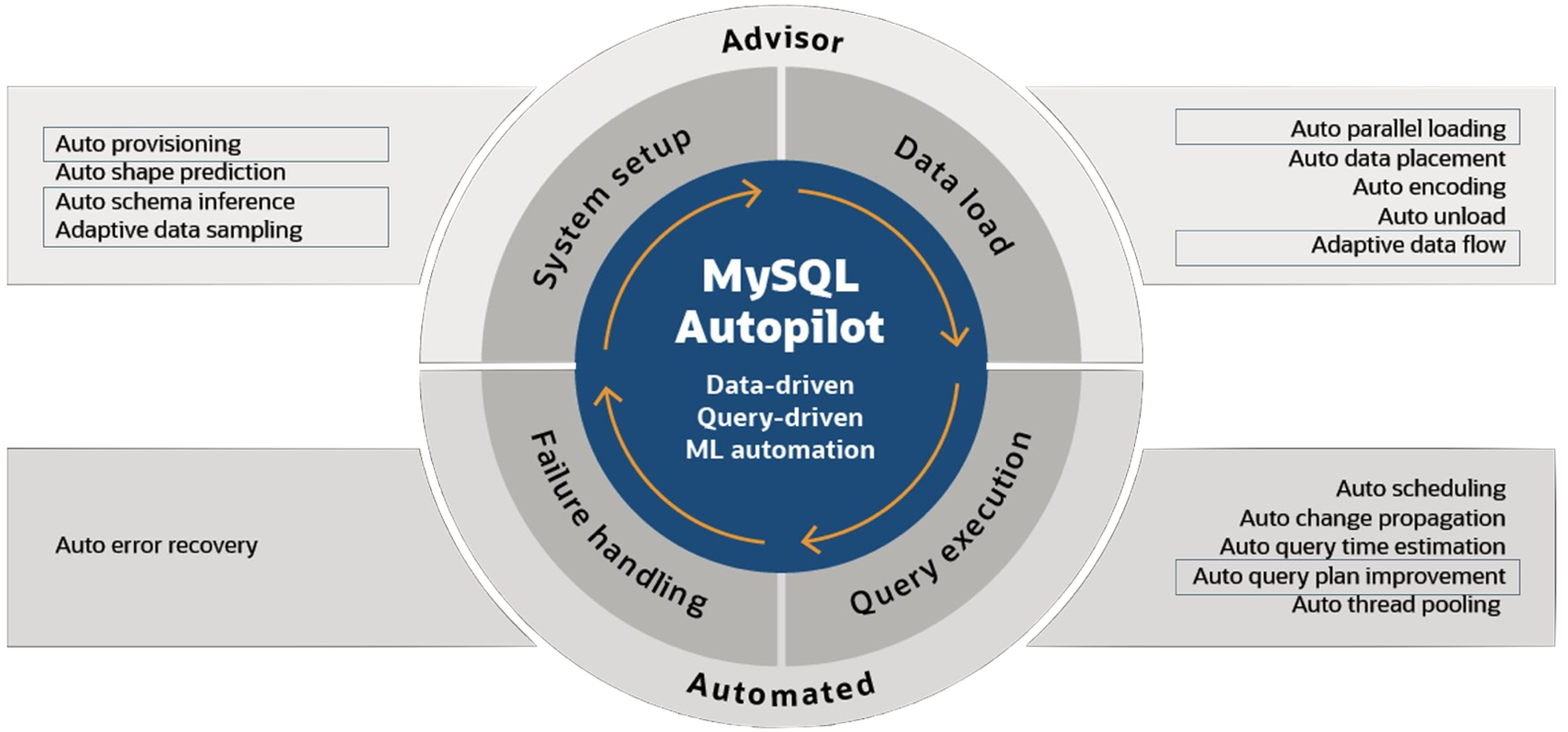
- System Setup: Auto Provisioning and Auto Shape Prediction capabilities help users allocate the right amount of resources that match their needs in analytical and transactional processing respectively.
- Data Load: Auto Encoding and Auto Data Placement determine the optimal representations and partitioning of data to achieve the best query performance, while minimizing the amount of resource needed (and hence the overall cost). Auto Parallel Load and Auto Unload automate and optimize the process of loading and unloading data into/from HeatWave by predicting the memory usage of the tables.
- Query Execution: Auto Query Plan Improvement and Time Estimation, Auto Scheduling, and Auto Thread Pooling, all together, enable the system to intelligently determine when and how queries should be processed to achieve optimal performance. Auto Change Propagation determines the optimal time to propagate changes from MySQL Database to HeatWave, maintaining the freshness of data without degrading the performance of running queries.
- Failure Handling: Auto Error Recovery automatically provisions new nodes and reloads necessary data in case of a failure.
In the subsequent part of this blog post, we will talk about the new capabilities of MySQL Autopilot in the context of MySQL HeatWave Lakehouse.
MySQL Autopilot for Lakehouse
System Setup: Adaptive Data Sampling and Auto Schema Inference
This section answers the following questions:
- How to know the schema and create one for files stored externally in the object store?
- How big of a cluster do I need?
- How long the load will take?
Autopilot’s Auto Provisioning capability provides recommendations on how many HeatWave nodes are needed to run a workload. For internal InnoDB tables, the data size is already known, the schema is already defined, and the system has table statistics/metadata, and more information can be further collected by Autopilot via data sampling. In the context of Lakehouse and its external tables, however, most of this information is missing and must be inferred from the external data files stored in the object store.
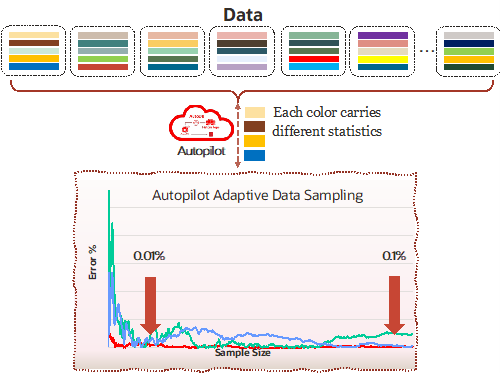
Autopilot’s two new capabilities come to the rescue and facilitate the process of ingesting data. Using Adaptive Data Sampling, Autopilot collects the needed statistics directly from the files stored in the object store. Using intelligent and adaptive sampling techniques, the process is quick and accurate. The collected information is then used by Auto Schema Inference to provide a schema definition for tables that are not defined yet, and by Auto Provisioning and Auto Parallel Load to estimate how many HeatWave nodes are needed and how long the load operation might take. The whole process is integrated into the already familiar Auto Parallel Load interface, allowing the users to ingest internal InnoDB tables together with external lakehouse tables in a single invocation.
The Auto Parallel Load interface (`sys.heatwave_load`) is now extended and accepts a new option `external_tables` that allows users to pass the required information about the external data they would like to load into HeatWave. More information on this new option is available on the documentation page. When this option is used, Auto Parallel Load will then employ Adaptive Data Sampling and Auto Schema Inference to collect some insights from the input data and uses them to generate a complete load script—including `CREATE DATABASE` and `CREATE TABLE` commands for non-created databases/tables based on the inferred schema— and predicts how much memory and time is needed to load the data. In the next section, we will demonstrate how it can also execute the generated script automatically to load the data. But before that, here are a few examples of using this new capability.
In a prior blog post, we explored how Auto Parallel Load eliminates the laborious and manual tasks related to loading data. Using the same syntax and interface we now load three tables of the `tpch` schema into HeatWave. The schema already contains an internal InnoDB table (`nation_int`) and we would like to create two new external lakehouse tables (`customer_ext` and `supplier_ext`). While it is possible to define the entire load command on a single line, for readability, the configuration is divided into option definitions using the SET command.
--Set the database name(s) to be loaded.
mysql> SET @db_list = '["tpch"]';
-- Set the external table parameters that provide information on how data is organized.
-- We can specify several databases and tables, with each table having its own options.
mysql> SET @ext_tables = '[{
"db_name": "tpch",
"tables": [{
"table_name": "customer_ext",
"dialect": {
"format": "parquet"
},
"file": [{
"par": "https://objectstorage.../customer.pq"
}]
},
{
"table_name": "supplier_ext",
"dialect": {
"format": "csv",
"field_delimiter": "|",
"record_delimiter": "|\\n"
},
"file": [{
"prefix": "src_data/tpch/supplier",
"bucket": "myBucket",
"namespace": "myNamespace",
"region": "myRegion"
}]
}]
}]';
-- Set the options and invoke Auto Parallel Load with the specified options.
mysql> SET @options = JSON_OBJECT('external_tables', CAST(@ext_tables AS JSON));
mysql> CALL sys.heatwave_load(@db_list, @options);
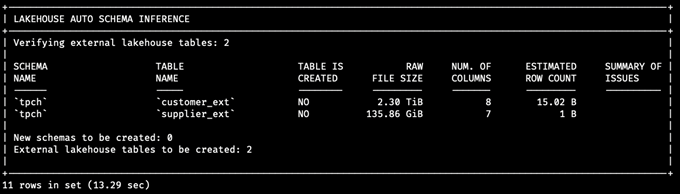
Upon applying the configuration commands as provided in this document, the user will be presented with a set of panels. The first panel, Lakehouse Auto Schema Inference, is a newly added panel that gives overall information, including the raw file size, number of inferred columns, estimated number of rows, and issues encountered during the process, for each of the external tables you wish to load. The panel will also show external tables that are already created in the input databases (but not loaded yet). Hence, the panel also indicates how many tables are to be created.
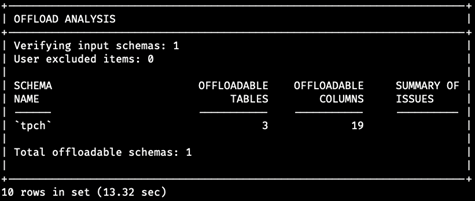
Next, the Offload Analysis panel shows information about input schema(s), whether there are unsupported tables/columns, and the total number of tables/columns that are being loaded to HeatWave.
The third panel, Capacity Estimation, provides information regarding Autopilot’s estimations on how much memory is required to load this data and how long this load operation might take. In this case, because our cluster has only one node, which is not enough to load all the data, Autopilot automatically switches to `dryrun` mode and only generates the load script.
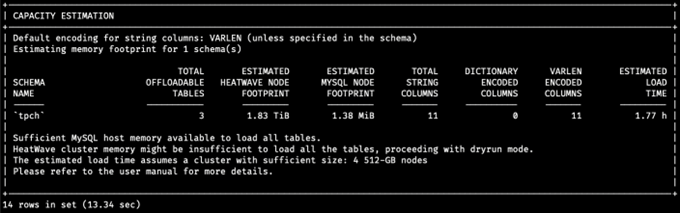
Users can also use the Auto Provisioning feature via the already familiar interface on the OCI Console to generate a node count estimate if a HeatWave cluster is already attached and all of their tables are already created (but not loaded yet). For more information on how to generate a node count estimate via the OCI Console, we refer the reader to the OCI documentation.
Finally, the last panel, Load Script Generation, displays information about the generated script and how to optain it. In the case of our example, the user needs to resize their cluster to make room for all the data and try retry loading the data into HeatWave.
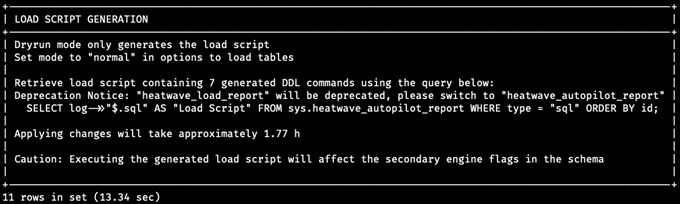
Auto Parallel Load supports two modes: a `dryrun` mode, which allows you to review information regarding the load without actually loading the data into HeatWave, and a `normal` mode, which automatically executes the generated load script assuming enough capacity is provided. In the example mentioned above, we used the `dryrun` mode (in our case, the system automatically switched to this mode due to lack of resources, but the users can also choose this mode as part of the input options), and Autopilot generated a complete load script based on its collected information:
As seen in the above code snippet, the generated script includes `CREATE TABLE` commands for the two non-created external tables, which is generated based on the result of Autopilot’s Auto Schema Inference capability. The script also includes the load commands (`ALTER TABLE … SECONDARY_LOAD`) for all the tables, including both internal InnoDB tables as well as external Lakehouse tables.
mysql> SELECT log->>"$.sql" AS "Load Script"
FROM sys.heatwave_autopilot_report
WHERE type = "sql" ORDER BY id;
+--------------------------------------------------------------------------------+
| Load Script |
+--------------------------------------------------------------------------------+
| CREATE TABLE `tpch`.`customer_ext`( |
| `col_1` bigint unsigned NOT NULL, |
| `col_2` varchar(20) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=VARLEN', |
| `col_3` varchar(40) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=VARLEN', |
| `col_4` tinyint unsigned NOT NULL, |
| `col_5` varchar(15) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=VARLEN', |
| `col_6` decimal(6,2) NOT NULL, |
| `col_7` varchar(10) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=VARLEN', |
| `col_8` varchar(116) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=VARLEN' |
| ) ENGINE=lakehouse SECONDARY_ENGINE=RAPID |
| ENGINE_ATTRIBUTE='{"file": [{"par": "https://objectstorage.../customer.pq"], |
| "dialect": {"format": "parquet"}}'; |
| ALTER TABLE `tpch`.`customer_ext` SECONDARY_LOAD; |
| SET SESSION innodb_parallel_read_threads = 1; |
| ALTER TABLE `tpch`.`nation` SECONDARY_ENGINE=RAPID; |
| ALTER TABLE `tpch`.`nation` SECONDARY_LOAD; |
| CREATE TABLE `tpch`.`supplier_ext`( |
| `col_1` int unsigned NOT NULL, |
| `col_2` varchar(20) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=VARLEN', |
| `col_3` varchar(40) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=VARLEN', |
| `col_4` tinyint unsigned NOT NULL, |
| `col_5` varchar(15) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=VARLEN', |
| `col_6` decimal(6,2) NOT NULL, |
| `col_7` varchar(100) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=VARLEN' |
| ) ENGINE=lakehouse SECONDARY_ENGINE=RAPID |
| ENGINE_ATTRIBUTE='{"file": [{"prefix": "src_data/tpch/supplier", |
| "bucket": "myBucket", "namespace": "myNamespace", |
| "region": "myRegion"}], |
| "dialect": {"format": "csv", "field_delimiter": "|", |
| "record_delimiter": "|\\n"}}'; |
| ALTER TABLE `tpch`.`supplier_ext` SECONDARY_LOAD; |
+--------------------------------------------------------------------------------+
Load script generated by Auto Parallel Load, which includes CREATE TABLE statements. The output above is displayed in a readable format. The actual CREATE TABLE output is generated on a single line.
As seen in the above code snippet, the generated script includes `CREATE TABLE` commands for the two non-created external tables, which is generated based on the result of Autopilot’s Auto Schema Inference capability. The script also includes the load commands (`ALTER TABLE … SECONDARY_LOAD`) for all the tables, including both internal InnoDB tables as well as external Lakehouse tables.
Data Load: Auto Parallel Load and Auto Data Flow
In the previous section, we showed how the same familiar Auto Parallel Load interface can be used to process external lakehouse tables together with internal InnoDB tables and prepare the system for loading data into HeatWave. The `dryrun` mode is useful if you want to get a quick idea of what the dataset looks like and how much resource you will need before attempting to load the data. You can also adjust the generated `CREATE TABLE` commands to change the column names or types if you would like to. Next, we will see how Auto Parallel Load can also execute the generated script. We also cover the Autopilot capabilities that are used for loading external lakehouse tables.
mysql> SET @db_list = '["tpch"]';
mysql> SET @ext_tables = '[{
"db_name": "tpch",
"tables": [{
"table_name": "supplier_ext",
"dialect": {
"format": "csv",
"field_delimiter": "|",
"record_delimiter": "|\\n"
},
"file": [{
"prefix": "src_data/tpch/supplier",
"bucket": "myBucket",
"namespace": "myNamespace",
"region": "myRegion"
}]
}]
}]';
mysql> SET @options = JSON_OBJECT('external_tables', CAST(@ext_tables AS JSON));
mysql> CALL sys.heatwave_load(@db_list, @options);
Retrying the load with fewer tables, requiring less amount of memory.
In this example, we will try to only load two of the previous tables which fit in our one-node HeatWave cluster.
When running in `normal` mode, we will see additional panels in the output that collectively give a report on the commands executed as part of the load script to load all the tables and how long each load operation took:
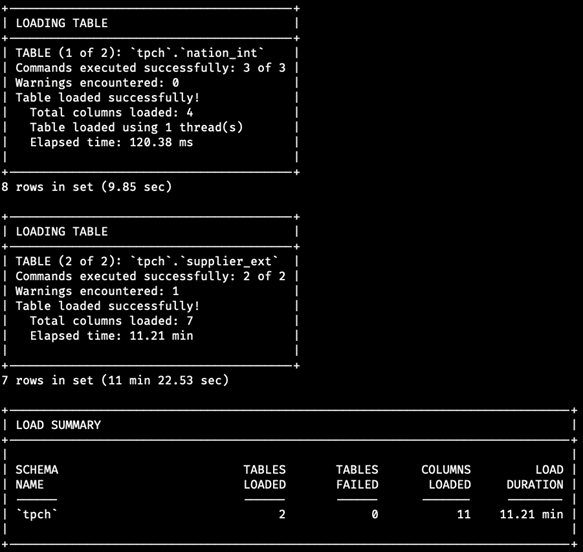
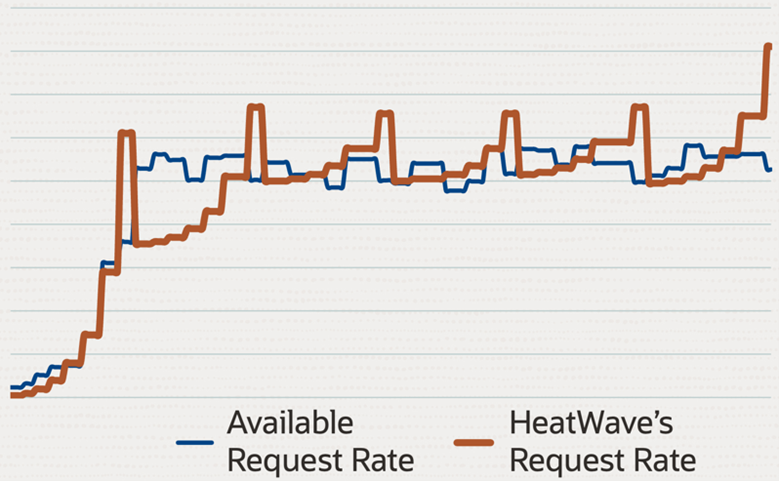
Autopilot includes a new Lakehouse-specific capability called Adaptive Data Flow, which controls and coordinates network bandwidth utilization to the object store across a large cluster of nodes. By adapting to the performance of the object store, Autopilot improves overall system performance and the reliability.
Loading of external tables also benefits from a smart scheduler that intelligently distributes the load operation across the entire cluster, which results in maximum performance by balancing the compute load across cluster nodes. The scheduler takes several factors such as the number of nodes, file types (i.e., Parquet or CSV), and file structures (i.e., number of files and how big each file is) into account to come up with the most efficient task distribution.
Query Execution
After loading the data, now it’s time to query the loaded data. Autopilot’s existing capabilities for query execution are enhanced to support external lakehouse tables the same way internal InnoDB tables were supported before. Autopilot continuously collects statistics while queries are running, which will then be used to improve the execution plan of future queries.
Similarly, Autopilot’s Advisor interface is also extended to process external lakehouse tables as well, and users can further optimize their workloads by leveraging Advisor’s capabilities such as Auto Data Placement, Query Insights and Unload.
Conclusion
MySQL HeatWave provides a single database for OLTP, OLAP, and machine learning applications, with compelling performance and cost advantages, and now with MySQL HeatWave Lakehouse, customers can leverage all the benefits of HeatWave on data residing in the object store. MySQL Autopilot provides machine learning automation that improves the performance, scalability, and ease of use of HeatWave. MySQL Autopilot’s Lakehouse extension simplifies and enhances the process of setting up the system, loading data, and executing queries for data stored externally in the object store. Users can benefit from MySQL Autopilot’s capabilities seamlessly when working with internal InnoDB tables and external lakehouse tables at the same time.
Additional Resources:
- MySQL HeatWave website
- MySQL HeatWave Lakehouse technical brief
- More information about MySQL Autopilot
- Login to Oracle Cloud to start using MySQL HeatWave Lakehouse (or sign-up here)
