Introduction
Generative AI (GenAI) and Retrieval-Augmented Generation (RAG) are transforming industries by enabling advanced, context-aware automation and intelligent information retrieval. HeatWave, a fully managed database service, further enhances this landscape by offering real-time analytics, machine learning, and transactional processing within a single platform. Together, these technologies empower businesses to leverage data-driven insights and streamline complex processes.
In this blog post, we explore how effortlessly you can harness the capabilities of HeatWave GenAI—including the Vector Store and RAG—to craft personalized AI-driven Question/Answering (Q/A) applications. These applications adeptly respond to user queries across diverse domains, leveraging customized documents ingested to HeatWave GenAI with vector store. Presented in this blog are two compelling examples:
- HeatWave GenAI for Healthcare: A specialized tool tailored to address healthcare inquiries using specific, custom documents.
- Ask MySQL Expert (AskME): A tool that aids the MySQL and HeatWave support teams.
Background
Large Language Models (LLMs)
LLMs are advanced AI systems designed to understand and generate human-like text, revolutionizing natural language processing tasks. They enhance our interaction with technology by enabling natural communication, automating tasks, and making technology more user-friendly.
Retrieval-Augmented Generation (RAG)
By combining the power of LLMs with information retrieval techniques, RAG boosts LLMs’ boost capabilities, performance, and reliability and enables generating highly accurate and contextually relevant responses. RAG integrates external knowledge sources to enhance LLMs, making them more effective for tasks that require up-to-date or specialized information, enhancing accuracy, and preventing hallucinations.
Why HeatWave?
HeatWave efficiently manages OLTP and OLAP workloads while offering machine learning capabilities all in one place, eliminating the need for ETL or data migration. Additionally, HeatWave provides generative models, vector store, and RAG capabilities right beside your data. To create RAG-based applications, simply ingest your documents to HeatWave GenAI with vector store and utilize HeatWave GenAI `ML_RAG` routine to retrieve the relevant information from your documents and generate answers to the questions. You can also create your own custom generation pipeline and tweak the context to add more relevant information and obtain an even more customized generated response. In the two following two use cases, we will first demonstrate the automated RAG capability and then demonstrate how you can create your own RAG mechanism using HeatWave GenAI.
HeatWave GenAI For Healthcare
Before reading further, you can watch the demo
This section presents the healthcare use case and show:
- With HeatWave GenAI, users can obtain tailored answers based on relevant information digested from their documents.
- HeatWave GenAI delivers concise and accurate responses focused on the topic at hand.
- Generated answers from HeatWave GenAI can include references to support the information provided.
User Interface
The application’s UI is straightforward and is built using Streamlit. User can choose whether to utilize the vector store and RAG capabilities or go with a basic LLM. If the first option is selected, the app retrieves relevant documents from the vector store for each question to generate answers, listing the used documents as references. With the second option selected, the app uses the base LLMs in HeatWave without adding any additional context to the prompts. As illustrated in Figure 1, using the built-in vector store and RAG capabilities results in precise and concise answers derived from the ingested documents (with citations being provided as well), whereas the base LLM tends to generate more general responses to the questions.
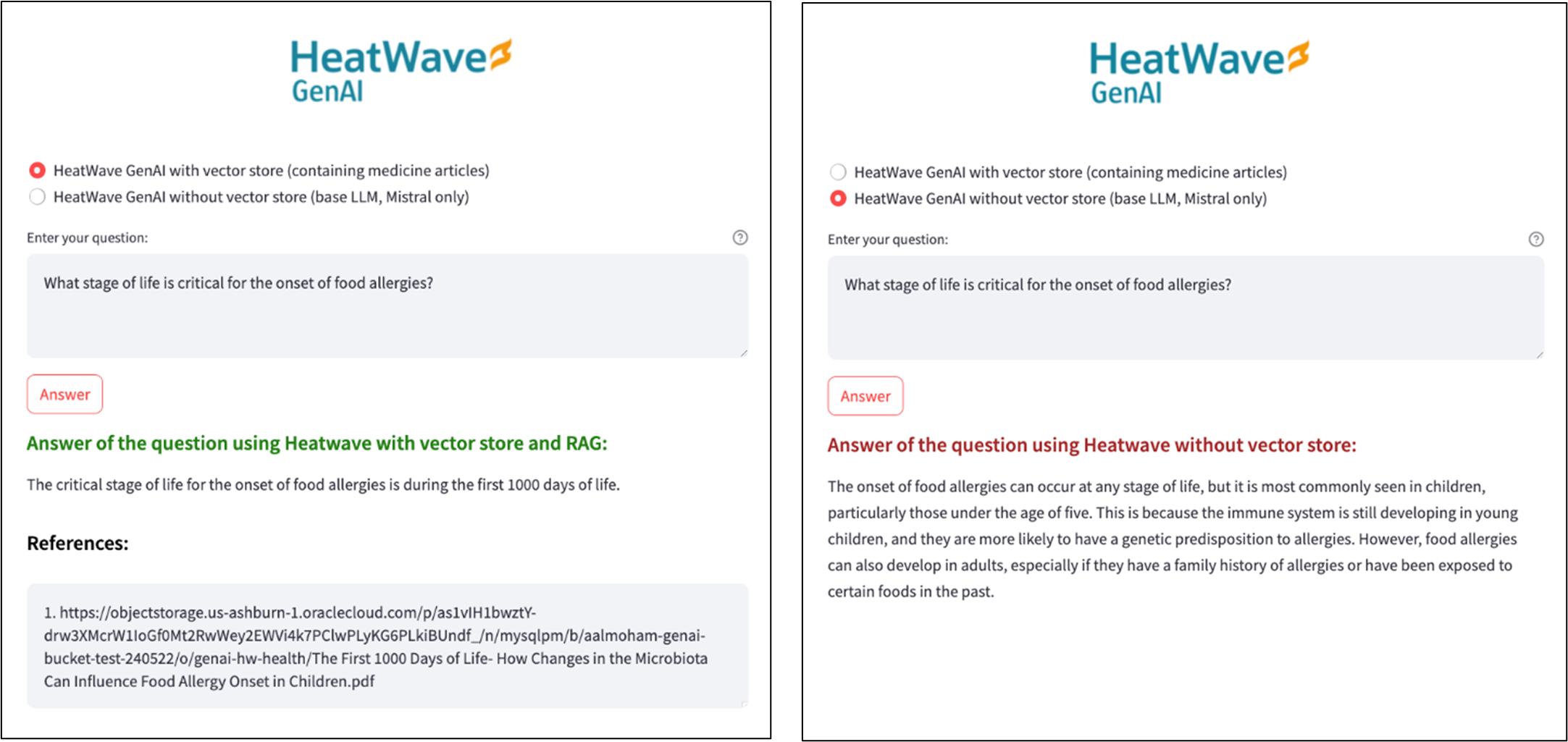
We now proceed with how to create an app like this and utilize HeatWave GenAI with vector store and RAG capabilities. The two main steps of are:
- System Setup: Ingest your documents into the vector store using Auto Parallel Load and load an LLM from the model catalog.
- Response Generation: Retrieve information needed from those documents and generate the answers using `ML_RAG`.
System Setup
HeatWave GenAI with vector store capability extends Autopilot’s Auto Parallel Load and Lakehouse features, allowing users to load and ingest unstructured data or documents stored in the object storage into HeatWave. Auto Parallel Load (`sys.heatwave_load`) facilitates the process of loading data into HeatWave. In particular, it creates relevant tables and then ingests documents into those tables by creating segments and embeddings for those segments. The table is maintained and can be queried by vector store.
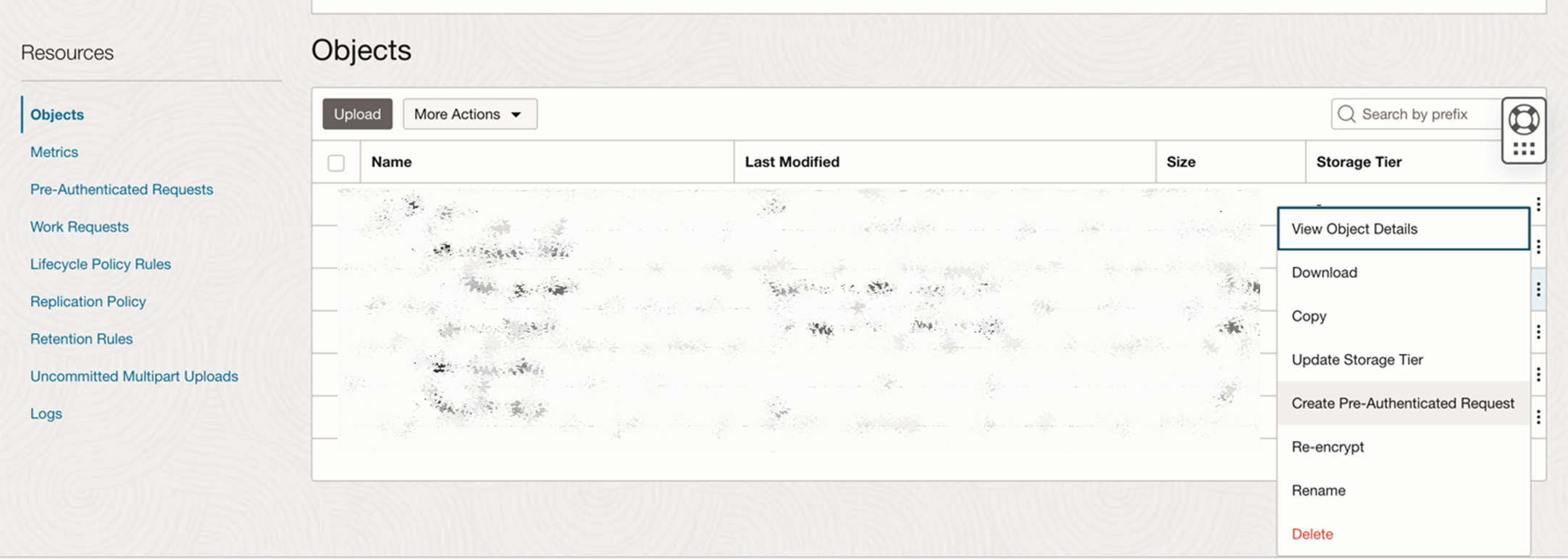
To use `heatwave_load`, you just need to pass the information on where the documents are stored along with other relevant information like table name and the document format. You first need to create a Pre-Authenticated Request (PAR) for your documents in the object storage as shown in Figure 2. You can then pass this to `heatwave_load` along with other information. More information on how to use Auto Parallel Load is available on the documentation page. After loading your documents, you need to load an LLM from HeatWave AutoML model catalog using `sys.ML_MODEL_LOAD`. Figure 3 depicts the SQL commands needed to perform these tasks.
-- Set the input parameters.
SET @input_list = '[{
"db_name": "vector_store_db_name",
"tables": [{
"table_name": "vector_store_table_name",
"engine_attribute": {
"dialect": {"format": "pdf"},
"file": ["par":" https://objectstorage.../docs"}]
}
}]
}]';
-- Set the options and invoke Auto Parallel Load with the specified options.
SET @options = JSON_OBJECT('mode', 'normal');
CALL sys.heatwave_load(@input_list, @options);
-- Load LLMs from the model catalog.
CALL sys.ML_MODEL_LOAD('cohere.command', NULL);
CALL sys.ML_MODEL_LOAD('mistral-7b-instruct-v1', NULL);
Figure 3: (a) Auto Parallel Load enables importing documents stored in the object storage, and (b) HeatWave ML contains a model catalog, from which you can load your prefered LLMs.
Response Generation
Now that you have your system set up and ready, you can use HeatWave GenAI with RAG capability to use your ingested documents and generate responses to given questions. The `ML_RAG` interface is your gateway to this capability. Users can choose from the various LLMs available in the model catalog. As shown in the figure, we used the `mistral-7b-instruct-v1` model for our usecase, which enables us to generate more concise ad right-to-the-point answers.
Upon invocation, the system will fetch the segments relevant to your question from the vector store and uses them to generate a context for the prompt to the LLM. It will then get the response and presents it to you in JSON format. The returned result not only contains the answer to the give question, but also it contains the citations referring to the segments from the documents loaded that were relevant to this question and were used to generate the answer.
-- Set the input parameters.
SET @model_info = '{
"vector_store": ["`vector_store_db_name`.`vector_store_table_name`"],
"n_citations": 5,
"distance_metric": "COSINE",
"model_options": {
"temperature": 0,
"repeat_penalty": 1,
"top_p": 0.2,
"max_tokens": 400,
"model_id": "mistral-7b-instruct-v1"
}
}';
-- Set your question.
SET @question = 'Your question here...';
-- Invoking HeatWave GenAI with RAG capability to get the answer to your question.
CALL sys.ML_RAG(@question, @output, @model_info);
-- Parsing out the answer from the generated JSON result.
SELECT JSON_UNQUOTE(JSON_EXTRACT(@output, '$.text')) AS answer;
-- You can also get the citations referring to segments from the loaded documents.
SELECT JSON_UNQUOTE(JSON_EXTRACT(@output, '$.citations')) AS citations;
Figure 4: Using HeatWave GenAI with ML_RAG interface to invoke the RAG capability and generate contextualized answers.
As demonstrated, you can effortlessly create a Q/A application using HeatWave GenAI with just a few commands. Now Let’s move to our second use case.
AskME: Ask MySQL Expert
Before reading further, you can watch the demo
AskME is another use case for HeatWave GenAI, designed to assist the MySQL and HeatWave support teams in resolving customer issues more efficiently. This tool leverages a comprehensive array of data sources to offer a Q&A and troubleshooting platform, aiding the support team in tackling high volume of customer questions and issues.
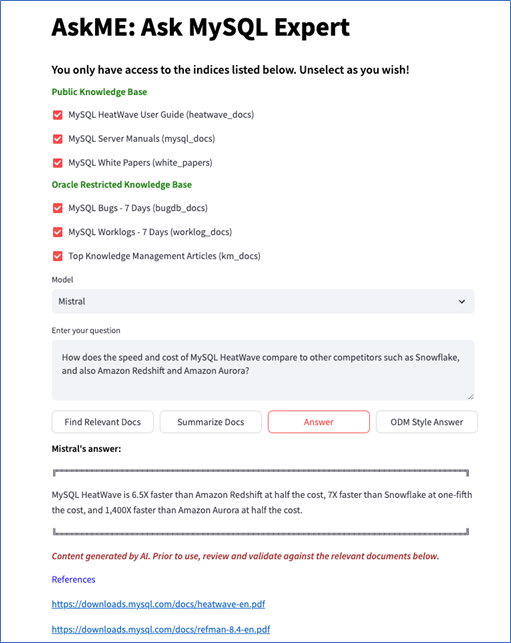
The objective of AskME is to provide specific and up-to-date answers to questions related to MySQL and HeatWave in natural language. AskME uses various sources of information, including MySQL reference manual and white papers, MySQL’s database of bugs, software specifications or worklogs, and articles written by the support team. As these data sources include internal documents that are not publicly accessible, none of the publicly-available LLMs have been trained on these data sources. This is one reason why RAG is important; AskME utilizes these internal documents to generate a detailed context which is then transmitted to an LLM within the same HeatWave cluster. This enables the MySQL support team to find the answers from the internal documents along with the intelligence provided by the LLMs. In summary, AskME provides the following key features:
- Question Answering:
- Retrieves several document segments related to the question.
- Summarizes the related segments and uses them to answer the question.
- It can additionally generate the answers and troubleshooting documents in various formats (e.g., Oracle Diagnostics Methodology), saving time of the support agents.
- References:
- Provides a list of documents/sources related to the question that contain more information about the given question and can be studied for further information.
We now continue with a brief overview of how to create an application like AskME, using HeatWave GenAI capabilities.
Response Generation
First, you need to ingest your documents into the HeatWave GenAI with vector store using Auto Parallel Load (`sys.heatwave_load`) to prepare your setup. This step is no different than previously explained document ingest, therefore, we skip this step here for the sake of brevity.
In this example, unlike the previous example and relying directly on `ML_RAG`, we create our own customized generation pipeline. Having a custom generation pipeline allows us to tweak the context by adding more relevant information to it and customize the format of the generated text even further. Hence, we first find segments relevant to the question and then use those segments as a context to ask the LLM for generating an answer.
To prepare a custom context, we first use the `sys.ML_EMBED_ROW` routine to create an embedding from the given question. We then use that embedding and with the help of built-in vector processing capabilities, retrieve top 10 similar segments to that question from our source corpus. This similarity search uses the cosine distance function, which is readily available using the `DISTANCE` function.
Once the similar segments are retrieved, we can further customize them by adding metadata to each one and merge all segments together with the question to create a collective customized context. You can further tune the context as you wish to ask the LLM to do your desired task and generate the answer in a format that you prefer. Finally, to generate the answer based on the given context, you can use the built-in `sys.ML_GENERATE` routine.
-- Load the embedding model from the model catalog.
CALL sys.ML_MODEL_LOAD('all_minilm_l12_v2', NULL);
-- Set the model information.
SET @model_info = '{"model_id": "all_minilm_l12_v2"}';
-- Set your question.
SET @question = 'Your question here...';
-- Create the embedding for the given question.
SELECT sys.ML_EMBED_ROW(@question, @model_info) INTO @question_embedding;
-- Retrieve 10 top similar segments to the question.
SELECT
document_name,
segment_number,
(1 - DISTANCE(segment_embedding, @question_embedding, 'COSINE')) AS similarity,
segment
FROM `vector_store_db_name`.`vector_store_table_name`
ORDER BY similarity DESC, document_name, segment_number
LIMIT 10;
-- Prepare the context using the extracted segments and the question.
SET @context = 'Your prepared context here...';
-- Set the model parameters.
SET @model_params = '{
"task": "generation",
"temperature": 0,
"repeat_penalty": 1,
"top_p": 0.2,
"max_tokens": 400,
"model_id": "mistral-7b-instruct-v1"
}';
-- Call the LLM to generate the answer with the new context.
SELECT sys.ML_GENERATE(@context, @model_params) INTO @gen_answer;
-- Parsing out the answer from the generated JSON result.
SELECT JSON_UNQUOTE(JSON_EXTRACT(@gen_answer, '$.text')) AS answer;
-- Getting the references based on which the answer was generated.
SELECT JSON_UNQUOTE(JSON_EXTRACT(@gen_answer, '$.citations')) AS references;
Conclusion
Creating AI-powered applications is now more accessible than ever with HeatWave GenAI suite of features. By utilizing HeatWave GenAI with vector store and RAG capabilities, you can develop advanced, customized AI solutions tailored to your specific requirements. The examples of HeatWave healthcare and AskME highlight the versatility and effectiveness of these tools in delivering natural language responses from custom documents across various domains. With HeatWave, the potential for innovation and enhanced user experiences is immense, making it an invaluable asset in your AI application development journey.
The links to demos covered in this post:
Explore other demos on our website & Try HeatWave GenAI out and let us know what applications you’re building with HeatWave GenAI!

