MySQL 9.7 Community Edition now includes the hypergraph optimizer as an alternative to the classic join optimizer, making this capability available across all MySQL editions. This is not a cosmetic change. The hypergraph optimizer uses a new join-planning framework aimed at queries where plan shape can make a real difference, particularly for multi-table joins, workloads with competing join methods, and cases where the row order produced by one part of the plan affects the cost of later operations.
We already see many queries improve. At the same time, the hypergraph optimizer is still evolving. In some cases, especially when row-count estimates are inaccurate, the classic optimizer may still choose a better plan. That is why we are seeking feedback from the MySQL community. If you test the hypergraph optimizer and see improved performance, we would like to hear about it. If you encounter a regression, please file a bug report and include a reproducible test case, schema, indexes, and EXPLAIN ANALYZE output if possible. Such feedback will help us improve plan quality faster.
How to enable it
The hypergraph optimizer is not enabled by default in MySQL 9.7 Community Edition.
To enable it for a session:
SET optimizer_switch='hypergraph_optimizer=on';To disable it again:
SET optimizer_switch='hypergraph_optimizer=off';To enable it for a single statement, use a SET_VAR hint:
SELECT /*+ SET_VAR(optimizer_switch='hypergraph_optimizer=on') */ ...;That makes it practical to test one query at a time without changing the rest of the workload.
What is different about it?
The classic MySQL join optimizer is based on a long-standing left-deep search framework. That framework has been improved many times, but its basic shape makes some things hard:
- it mostly reasons about left-deep join trees,
- it has limited support for reorderings beyond simple inner-join cases,
- it treats row ordering as a refinement instead of a first-class part of search,
- it applies hash join late rather than treating it as a primary join strategy,
- and it has historically been difficult to make it choose between very different physical strategies in a fully cost-based way.
The hypergraph optimizer starts from a different model. Instead of treating a query as a sequence of tables to join, it treats it as a graph:
- each table is a node,
- each join predicate is an edge,
- and predicates that involve multiple tables can be represented directly.
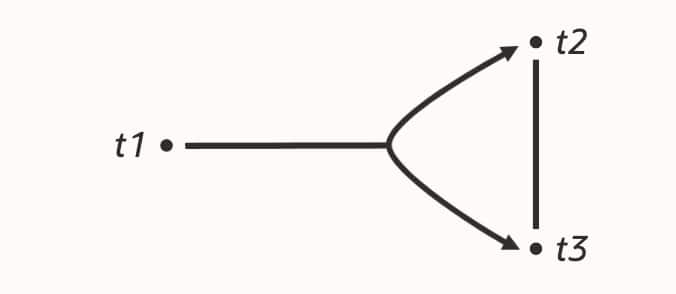
t1 LEFT JOIN (t2 JOIN t3)From there, it uses dynamic programming to enumerate connected subplans. That gives two immediate benefits:
- The optimizer does not need to think in terms of one fixed “join order” shape.
- Join constraints and legal reorderings are captured more naturally than in the classic framework.
This is the theoretical basis behind the name. The search space is represented as a hypergraph, and the optimizer enumerates valid connected partitions of that hypergraph. The original paper behind this line of work is “Dynamic Programming Strikes Back” by Guido Moerkotte and Thomas Neumann, published at SIGMOD 2008.
Why this matters in practice
The hypergraph optimizer is useful because it makes several important choices first-class parts of optimization instead of afterthoughts.
1. Interesting orders are part of the search
An access path can be worth keeping even if it is slightly more expensive locally, because it returns rows in an order that becomes valuable later.
Typical examples are:
- an index order that lets
ORDER BY ... LIMITavoid a sort, - an access path that feeds
GROUP BYin a useful order, - or a join plan that preserves ordering long enough that a later filesort or temporary table is not needed.
The classic optimizer can use ordered access paths, but it does not reason about them as broadly or as early in the search. The hypergraph optimizer keeps these “interesting orders” in mind while comparing alternatives, so it can accept a slightly more expensive subplan when that saves much more work later.
2. Nested-loop join versus hash join is a real cost-based choice
The classic optimizer will often stay with nested-loop join when there is an index it can use on the inner side, even if building a hash table would be cheaper overall. The hypergraph optimizer compares nested-loop joins and hash joins using the same search framework and cost model, so indexed nested loops are no longer the automatic winner.
That matters for analytic queries where probing an index many times can lose to scanning and hashing once, even when the index looks attractive in isolation.
3. Bushy join plans are supported
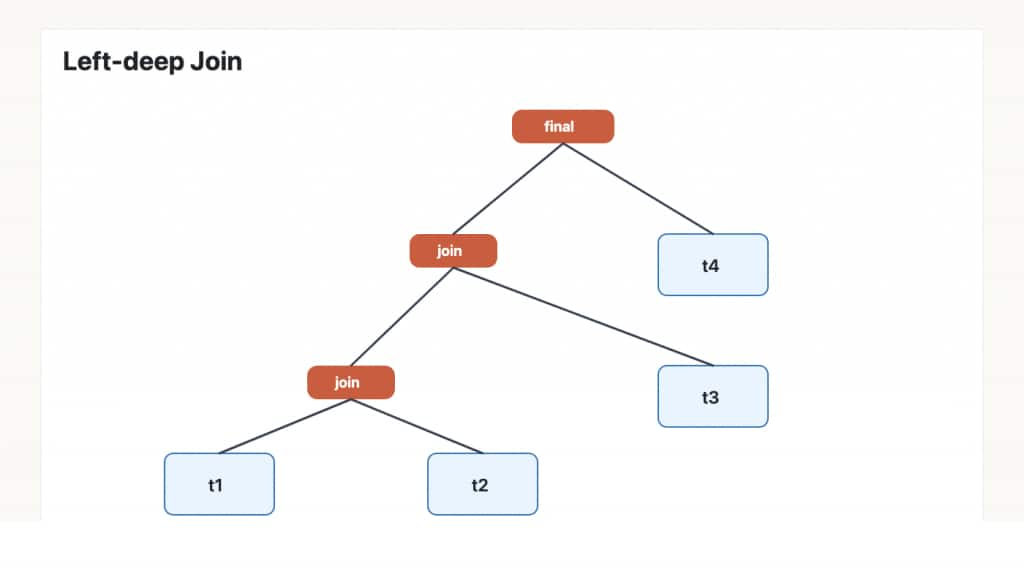
A left-deep optimizer tends to build plans like this:
The hypergraph optimizer can also consider bushy plans:
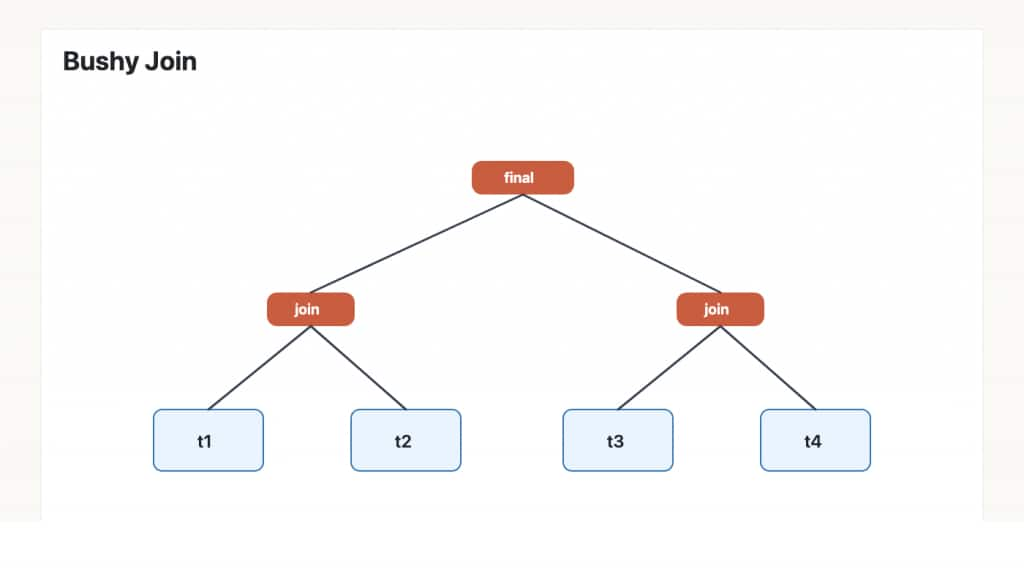
That sounds abstract, but it is often exactly what you want. If t1 JOIN t2 is selective and t3 JOIN t4 is selective, it can be cheaper to build both reduced subresults first and join them later, instead of dragging all four tables through one long left-deep chain.
4. The cost model is calibrated from measurements
The hypergraph optimizer uses a cost model based on time measurements from microbenchmarks. The goal is not to make every estimate perfect, but to make choices between access paths and join methods reflect observed cost more closely.
That shows up in decisions such as:
- table scan versus secondary-index scan,
- hash join versus nested-loop join,
- and whether preserving order is worth paying a little more earlier in the plan.
Early results from TPC-DS
For one concrete data point, we ran the TPC-DS query set at scale factor 1, with approximately 1 GB of data and the working set fully in memory.
Across the 101 query variants in this run:
- 77 were faster with the hypergraph optimizer,
- 24 were slower,
- and the geomean runtime improvement was 22.45%.
That is encouraging, but it is not the same thing as “done”. The same dataset also contains some large regressions, which is one reason the feature remains off by default in Community Edition.
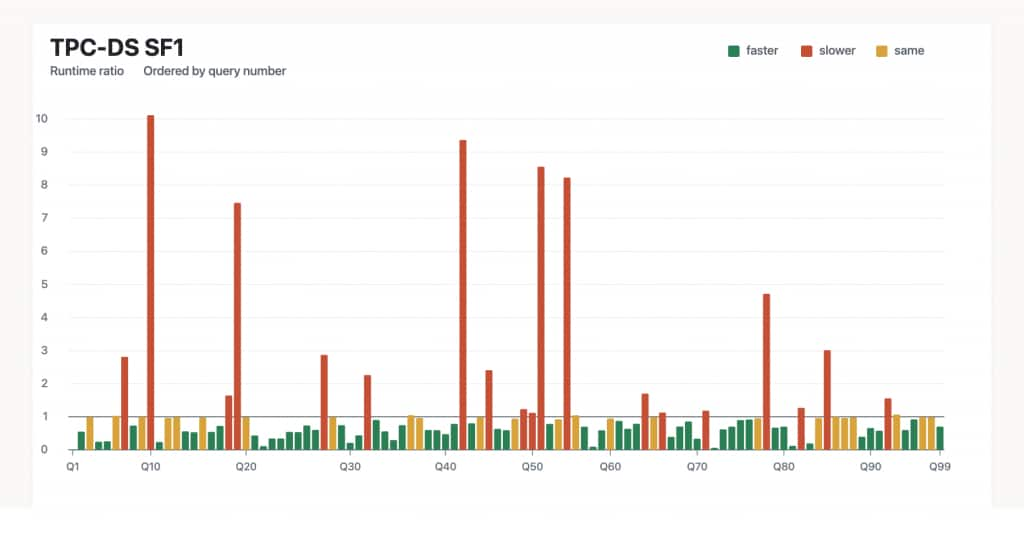
Some observations from this run:
- the chart is ordered by TPC-DS query number and shows runtime ratio, so values below 1.0 are improvements and values above 1.0 are regressions,
- almost half of the statements improved by at least 25%,
- 19 statements improved by at least 50%,
- but 14 statements regressed by at least 50%.
So the current picture is not “small gains everywhere”. It is “many significant wins, plus a smaller number of significant losses that we are actively working through”.
Two examples from outside our lab
Sysbench: better plans for ordered and selective reads
In recent public sysbench tests on MySQL 9.7.0, Mark Callaghan reported a 26% improvement for read-only-distinct and a 15% improvement for read-only_range=10000 with the hypergraph optimizer enabled.
The read-only-distinct result is a good example of what the new optimizer is meant to help with: it benefits when the optimizer gives proper weight to plans that produce rows in a useful order for DISTINCT and ORDER BY, instead of treating the ordering requirement as something to fix later. The read-only_range=10000 workload runs several queries, including the query used by read-only-distinct, so it benefits from the same better plan.
The exact best plan still depends on schema, indexes, and data distribution, but these results are consistent with the strengths of the new framework: interesting orders, broader plan search, and more accurate cost comparisons.
A real optimizer anomaly that disappears
Shattered Silicon recently described a case where MySQL chose a much worse plan for a query with joins, ORDER BY, and LIMIT, even though a good index-ordered plan was available through join equivalences.
This is exactly the kind of problem the hypergraph optimizer is designed to attack. When order properties are treated as part of plan search, the optimizer can keep and compare alternatives that would otherwise be pruned too early. In MySQL 9.7, that class of problem is handled correctly by the hypergraph optimizer.
Where it is most worth trying
Plan quality depends on schema, indexes, data distribution, and the accuracy of row-count estimates. You do not need to classify the whole application first; test one query at a time, starting with statements that are worth profiling.
Good candidates are:
- slow pages, reports, dashboards, or batch jobs where one
SELECTjoins several tables, - queries with
ORDER BY ... LIMIT,GROUP BY, orDISTINCT, especially whenEXPLAIN ANALYZEshows a sort, a temporary table, or many rows examined before a small result is returned, - joins that scan many rows, even though the final result is much smaller,
- reporting queries that combine large history, event, order, or transaction tables with lookup tables,
- queries where the classic plan does many repeated index lookups into the same table.
For single-table queries, primary-key lookups, and very small joins, there may be little difference. The classic optimizer can also still be the better choice for very short queries, where query optimization time is a visible part of total latency. It may also win in cases where the hypergraph optimizer does not yet consider an execution strategy the classic optimizer can use. Finally, inaccurate estimates can make either optimizer choose a poor plan; occasionally the classic optimizer gets the better result because two estimation errors happen to cancel each other out.
How to evaluate it
If you want to test the hypergraph optimizer on your own workload, start small. For application developers, this usually means starting with slow or high-variance statements from application traces, not changing a whole workload at once. For DBAs, the slow query log and Performance Schema statement summary tables are good starting points for finding candidate queries.
- Pick a slow query or a representative reporting query.
- Run it with
hypergraph_optimizer=offandhypergraph_optimizer=on. - Compare both runtime and
EXPLAIN ANALYZE. - Pay attention to join order, join method, rows examined, and whether sorts or temporary tables disappear.
What to expect next
The goal of making the hypergraph optimizer available in Community Edition is not to declare victory. The goal is to get broader testing and better bug reports while the feature is still evolving.
We already see clear upside:
- better handling of interesting orders,
- real cost-based comparison of nested-loop and hash joins,
- support for bushy join plans,
- and a cost model that is better aligned with measured execution cost.
But we also know where more work is needed:
- selectivity estimation for base-table filters,
- cardinality estimation for join results,
- and regressions where the classic optimizer still finds a better plan.
If you test the feature and find one of those regressions, please report it. Reports of clear wins are useful too, especially when they include the query shape and the plan difference. Both kinds of feedback help us improve plan quality for the broader MySQL community.
This post only covers the high-level picture. In later posts, we will go deeper into join enumeration, interesting orders, cost modeling, and concrete plan changes behind some of the wins and regressions.
