The rapid proliferation of ML technology, explosive data growth, and shortage of data science expertise have caused the industry to face increasingly challenging demands to keep up with fast-paced develop-and-deploy model lifecycles. The increase in volume and velocity of data generated by various applications, devices, sensors etc., as well as need for real-time decision making has necessitated frequent changes in the machine learning models that are built using this data. Models with high accuracy need to be generated and kept up to date on changing data to manage drifts between trained and inference data. Such rapid model development cycles require an efficient and automated ML pipeline to accurately generate predictions akin to a manually generated model.
Identifying the right model for a given dataset, involves selecting the best algorithm, the best set of rows and features, and the best algorithm hyperparameters. There are hundreds or thousands of potential combinations. Conventional solutions have addressed this problem by optimizing various pipeline configuration parameters to effectively capture dependency among such parameters. This approach tends to be iterative and needs to evaluate a large number of pipeline permutations which takes longer time, making iterative pipelines impractical.
The training time for MySQL HeatWave ML is on an average 25X faster that competing products such as Redshift ML. In case of some datasets, it is hundreds of times faster than Redshift ML. MySQL HeatWave ML scales much better with increased cluster size compared to Redshift ML. In addition, The ML functionality in HeatWave is accomplished by incorporating it within the database. By taking this approach, the data does not have to be extracted from the database, but instead it stays within, and the training, inference and explanation activities are performed without moving the data or the model. For customers of MySQL HeatWave, there is no charge for using HeatWave ML.
How does MySQL HeatWave ML achieve this fast model training performance? Based on years of research at Oracle Labs, MySQL HeatWave ML presents a novel iteration-free machine learning pipeline designed to not only provide accurate models, but also in a shorter runtime and parallelize across servers. It achieves these objectives by eliminating the need to iterate over various pipeline configurations. MySQL HeatWave ML implements a feed-forward approach, where each pipeline stage makes decisions based on metalearned proxy models that can predict candidate pipeline configuration performances before building the final model.
The innovations listed below are the key to the superior model training performance and accuracy of MySQL HeatWave ML.
Innovations
Proxy Models
Proxy models are developed using a set of datasets from publicly available datasets. We leverage metalearning to create these proxy models by observing each algorithm’s behavior on a wide variety of datasets and hyperparameters. A single proxy models per ML algorithm is generated such that it is predictive for any never-before-seen data. Proxy models are performance predictors that are used in all the pipeline stages to make the ML pipeline iteration-free.
Iteration-free optimizer
Iteration-free sequence of ML pipeline stages, consisting of algorithm selection, adaptive data reduction, and hyperparameter optimization, is first of its kind. Each pipeline stage optimization outcome is final and only affects the downstream stages.
Adaptive Data Reduction
Selects a representative sample of a dataset, along both the row and feature dimensions, optimized for a selected algorithm. Adaptive data reduction speeds up hyperparameter optimization with minimal impact on predictive performance of models.
HyperGD
Highly parallel gradient-based hyperparameter optimizer that performs asynchronous optimization across different hyperparameter dimensions in parallel.
Pipeline Stages
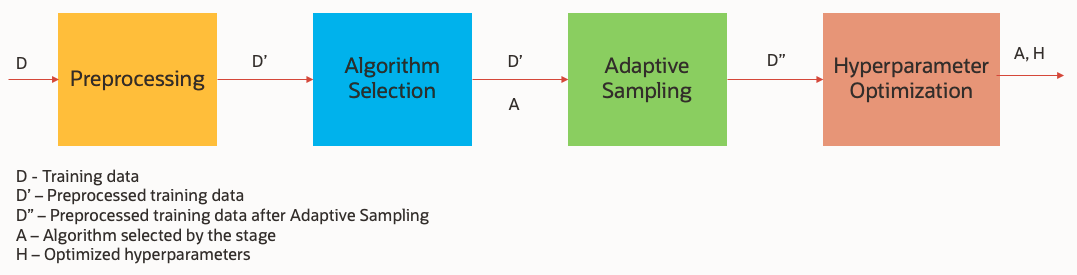
Figure 1: Oracle MySQL HeatWave ML non-iterative pipeline
MySQL HeatWave ML pipeline consists of predefined set of stages shown in Figure 1. Proxy models are used in these stages to generate a fast and accurate model.
Data Preprocessing
It implements commonly utilized preprocessing steps, including missing value imputation, label encoding, and normalization.
Algorithm Selection
This stage consists of algorithm selection, which determines the best algorithm for the given dataset. Algorithm selection is pivotal to the performance of the entire pipeline.
MySQL HeatWave ML relies on proxy models to select the best algorithm for the dataset. Proxy models act as indicators of how well a given algorithm will perform on the dataset of interest. Their highly predictive nature helps mitigate score degradation, which would normally be associated with a non-iterative pipeline.
Algorithm selection in pipeline results in an advantage of ~4.5X over in runtime over exhaustive algorithm selection where pipeline tries all algorithms on a given dataset.
Adaptive Sampling
This stage uses Adaptive Data Reduction and aims to reduce the number of dataset rows and select a subset of features without compromising model performance. Imbalance aware sampling provided by this stage speeds up the subsequent stages. Both, row sampling and feature selection rely on proxy models to score samples and subsets.
Row Sampling – The goal is to find the smallest sample size of a dataset, for use in subsequent pipeline stages, without sacrificing model quality.
Feature Selection – The goal of feature selection is to find a subset of dataset features that are representative of the original dataset and remove irrelevant features.
Adaptive Data Reduction reduces pipeline’s average runtime by more than 8.73%, while providing an average score improvement of 1.80%. This score improvement and speedup are much more pronounced for large datasets with greater than 3m cells, with 35.98% speedup and 3.65% score improvement.
Hyperparameter Optimization
This is the final stage of the pipeline, and it aims to fine tune the selected algorithm’s hyperparameters. This stage tends to be the most expensive stage in a machine learning pipeline.
A typical hyperparameter optimizer selects and evaluates a batch of hyperparameters, waits for all the evaluations to complete, before selecting the next batch of hyperparameter values based on the results of the current batch. Each of these evaluations is called a trial, and each trial takes arbitrarily long, depending on the dataset and choice of hyperparameters.
HyperGD is a highly parallel and asynchronous algorithm that parallelizes trials during search of a given hyperparameter as well as trials across other hyperparameters. It achieves this high degree of parallelism by asynchronously gathering and using the best hyperparameters from all completed trials whenever launching any new trial. Further, it does not wait for all the results to complete from a batch of model evaluations. Both optimizations are possible because of the novel Gradient-based Search Space Reduction (GrSSR) in HyperGD.
The test score improves by 5.8% on average over the proxy models due to HyperGD.
In summary, MySQL HeatWave ML provides a fast and accurate machine learning pipeline. Model training for MySQL HeatWave ML is on an average 25X faster than Redshift ML. The speed and accuracy of MySQL HeatWave ML pipeline is achieved through the innovations such as Proxy Models, Interaction-free optimizer, Adaptive Data Reduction and HyperGD.
References:
