HeatWave is the only fully managed MySQL database service that combines transactions, analytics, machine learning, and GenAI services, without ETL duplication. HeatWave also includes HeatWave Lakehouse, allowing users to query data stored in object storage, MySQL databases, or a combination of both. Users can deploy HeatWave MySQL–powered apps on a choice of public clouds: Oracle Cloud Infrastructure (OCI), Amazon Web Services (AWS), and Microsoft Azure.
When loading data from object storage, HeatWave Lakehouse adaptively samples the files and infers the schema, including the columns, data types, precision, and estimates both the number of HeatWave nodes required and the time required to load the data. With CSV files, however, the user still had to provide information on how the columns are separated and how the records are delimited. With HeatWave version 9.2.0, this aspect of detecting delimiters has also been automated.
In this blog we will see, with the help of examples, how HeatWave automates the detection of dialects when working with CSV (Comma Separated Value) files in object storage. HeatWave auto-detects the field and record-delimiters when you specify “dialect”: {“format”: “csv”, “field_delimiter”: “auto”, “record_delimiter”: “auto” }” in the options parameter to heatwave_load(). You no longer have to specify “field_delimiter” and “record-delimiter“, or you can specify them as “auto” and HeatWave Auto Parallel Load does the rest.
A CSV dialect is the set of parameters that specify the characteristics of a CSV file. Some examples of common field delimiters in CSV files are:
- comma (,)
- semi-colon (;)
- pipe (|)
- tab (\t)
Additionally, how the records are separated can vary based on whether the file was generated on a Windows or a Unix/Linux system. For instance, Windows uses two characters for the end of a line in a text file (CRLF: Carriage Return and Line Feed), while Unix and Linux systems use a single character (LF).
HeatWave Auto Parallel Load can now automatically infer the dialect and then use those delimiters (for field and record) to ingest data into HeatWave. This can both save time and improve accuracy, especially when datasets are large or there are many columns, and visually scanning files to identify the correct delimiters may not always be practical.
Field delimiters automatically detected are comma (,), semi-colon (;), pipe (|), or tab (\t). Record delimiters automatically detected are \n (LF: line feed), \r (CR: carriage return), and \r\n (CR + LF: carriage return and line feed).
Let us look at a few examples to see how HeatWave’s auto dialect detection feature works.
Example 1—auto detection in ‘normal’ mode
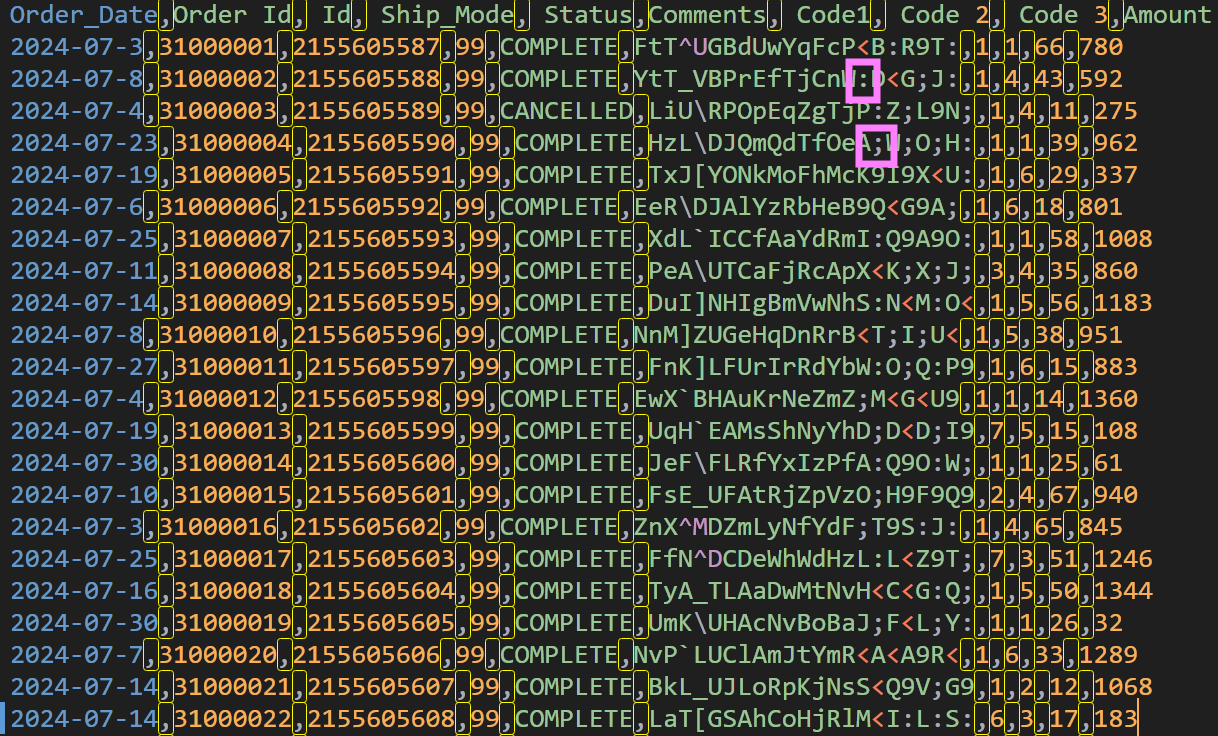
In the first example, we will use a file named test-1.csv that has a header row for column names, followed by several rows of data (Fig. 1). While it is easy to identify comma as the field delimiter, if we scan a few rows and inspect the ‘Comments’ column, we notice it is a freeform text field and contains potential delimiter candidates like semi-colon and colon.
We can make use of HeatWave Lakehouse’s auto dialect detection feature to take the guesswork out.
To load a single file into a table named mydata, we will use the following Auto Parallel Load syntax. Note that for both the field and record delimiter options, we have specified a value of “auto”, telling Auto Parallel Load that we want it to automatically detect these delimiters.
SET @input_list = '[
{
"db_name": "analytics",
"tables":
[{
"table_name": "mydata",
"engine_attribute":
{
"dialect": {"format": "csv"},
"file": [{"region": "us-ashburn-1",
"namespace": "mytenancy",
"bucket": "mybucket",
"prefix": "my-data/test-1.csv"
}]
}
}]
}]';
CALL sys.heatwave_load(CAST(@input_list AS JSON), NULL);
Since we did not specify the delimiters above (field_delimiter and record_delimiter), Auto Parallel Load knows it has to detect the dialect.
Auto Parallel Load runs in ‘normal‘ mode, where it infers the schema, generates the scripts to create the schema (if not already present), table(s), loads the data, and then executes these commands.
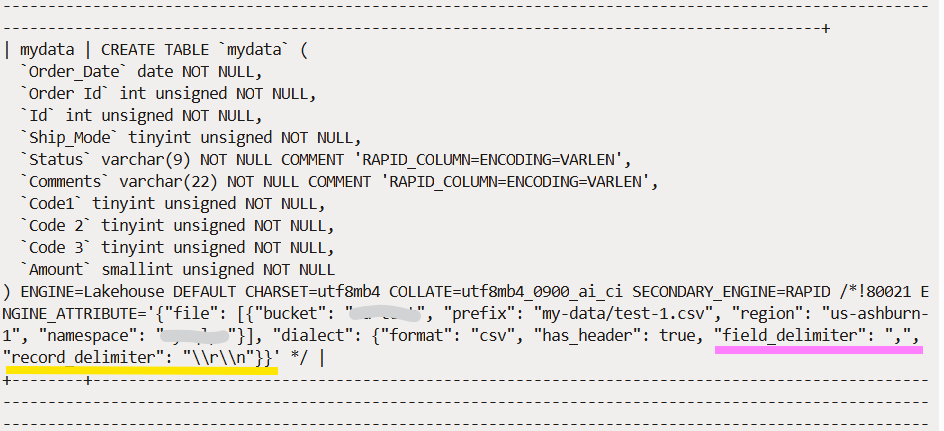
In this case, Auto Parallel Load runs successfully, the table is created, and data loaded into the table. If we now run the ‘SHOW CREATE TABLE mydata;’ command (Fig. 2), we see that the correct field delimiter (“,”) and record delimiter (“\\r\\n”) values have been inferred and included in the table definition.
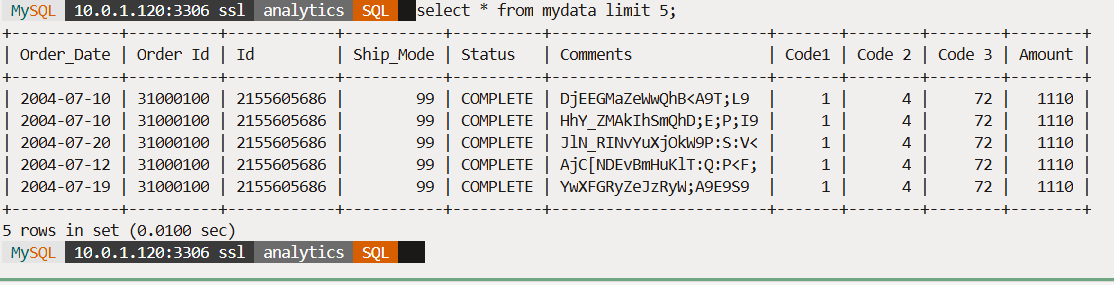
We can run a ‘select * from mydata limit 5;’ command to view the data loaded (Fig. 3).
Subsequently, when we want to refresh this table or load data afresh, these delimiter values will be used.
Example 2—auto detection in ‘dryrun’ mode
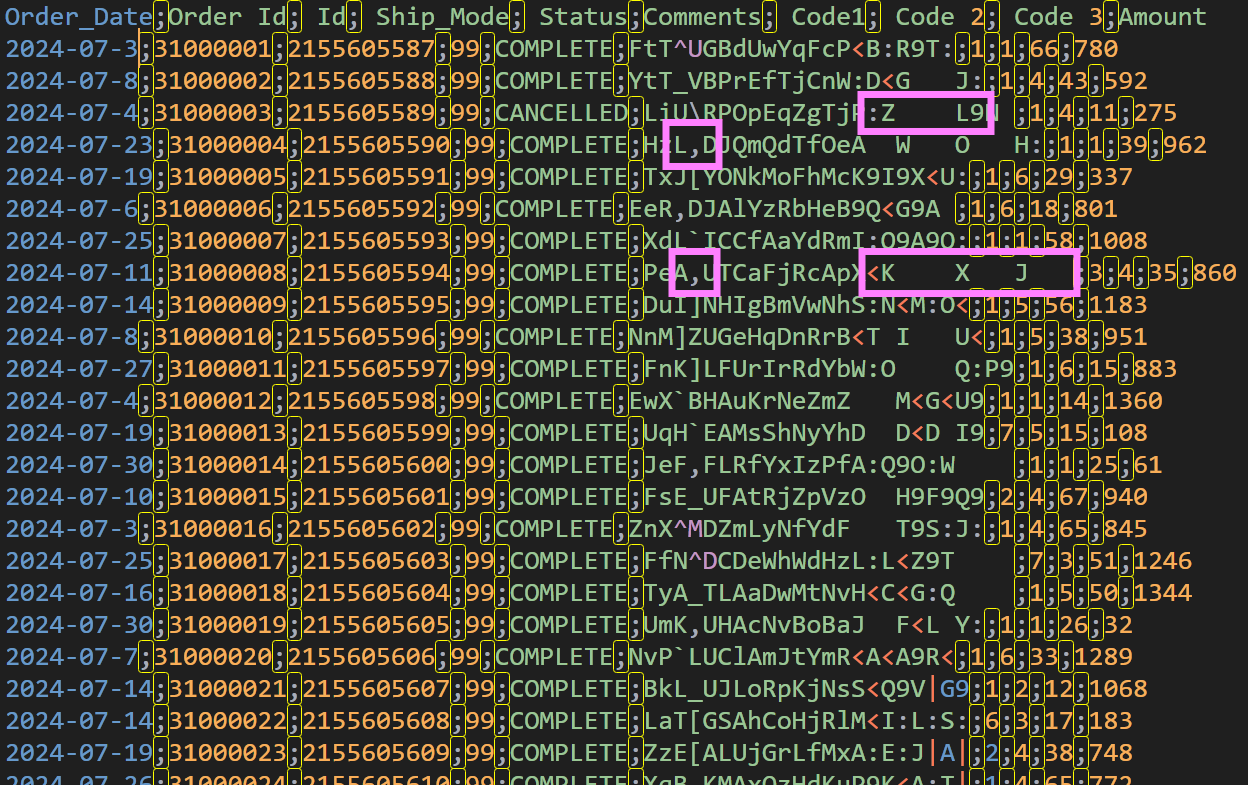
In this second example, we will use a different CSV file, where the field delimiter is semicolon (;) (Fig. 4). Note that the ‘Comments’ column has characters that can add ambiguity when determining the field delimiter—some rows have a comma and a tab in them, and both could be considered as delimiters.
We will run Auto Parallel Load, like in the previous example, but in dryrun mode. This mode does everything the ‘normal’ mode does but does not run the generated scripts. This mode is useful when you are starting out on loading data but need to verify and validate the schema generated before loading the full table.
SET @input_list = '[
{
"db_name": "analytics",
"tables":
[{
"table_name": "mydata2",
"engine_attribute":
{
"dialect": {"format": "csv"},
"file": [{"region": "us-ashburn-1",
"namespace": "mytenancy",
"bucket": "mybucket",
"prefix": "my-data/test-2.csv"
}]
}
}]
}]';
SET @options = JSON_OBJECT('mode', 'dryrun');
CALL sys.heatwave_load(CAST(@input_list AS JSON), @options);
Upon successfully running, Auto Parallel Load generates the scripts and provides the SQL command to obtain the generated script (Fig. 5).
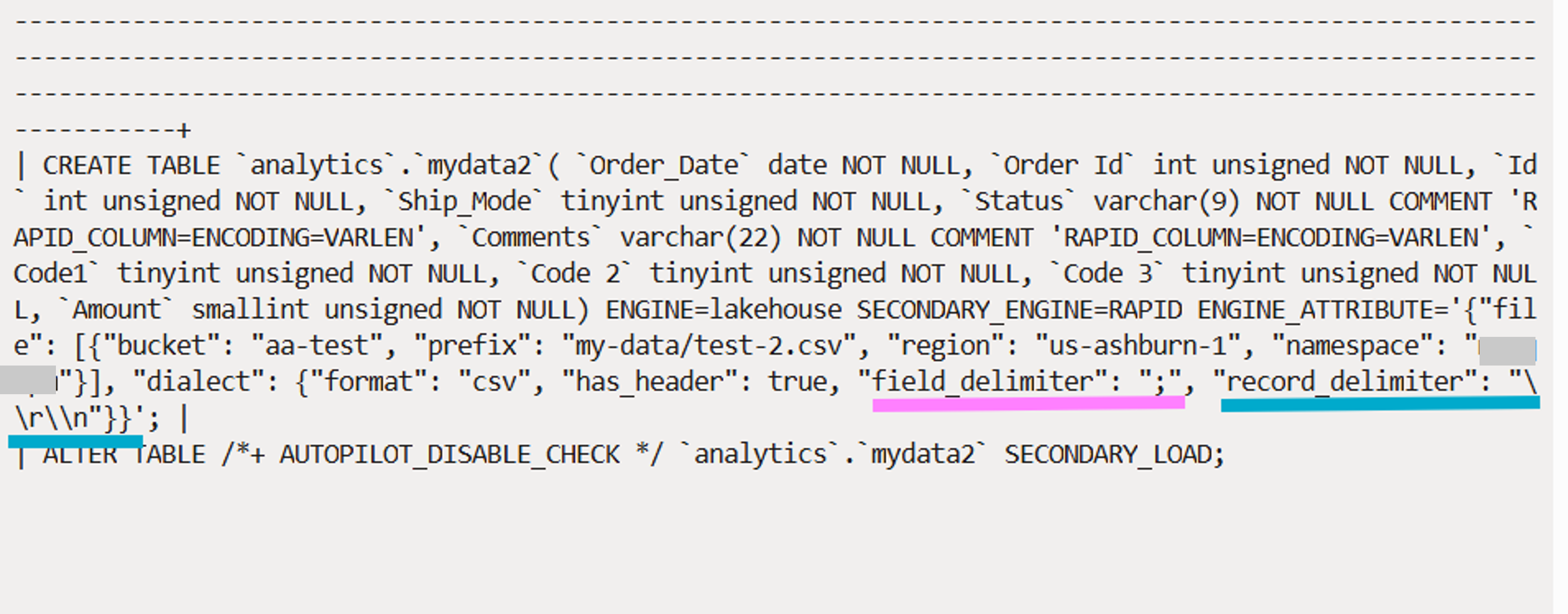
The script generated contains two commands: the CREATE TABLE statement and the statement to load data into the table (Fig. 6). The CREATE TABLE statement has a section called ENGINE_ATTRIBUTE where options and attributes for the primary and secondary engines are specified. You can see that Auto Parallel Load has correctly identified the field and column delimiters and included them as part of the engine attribute.
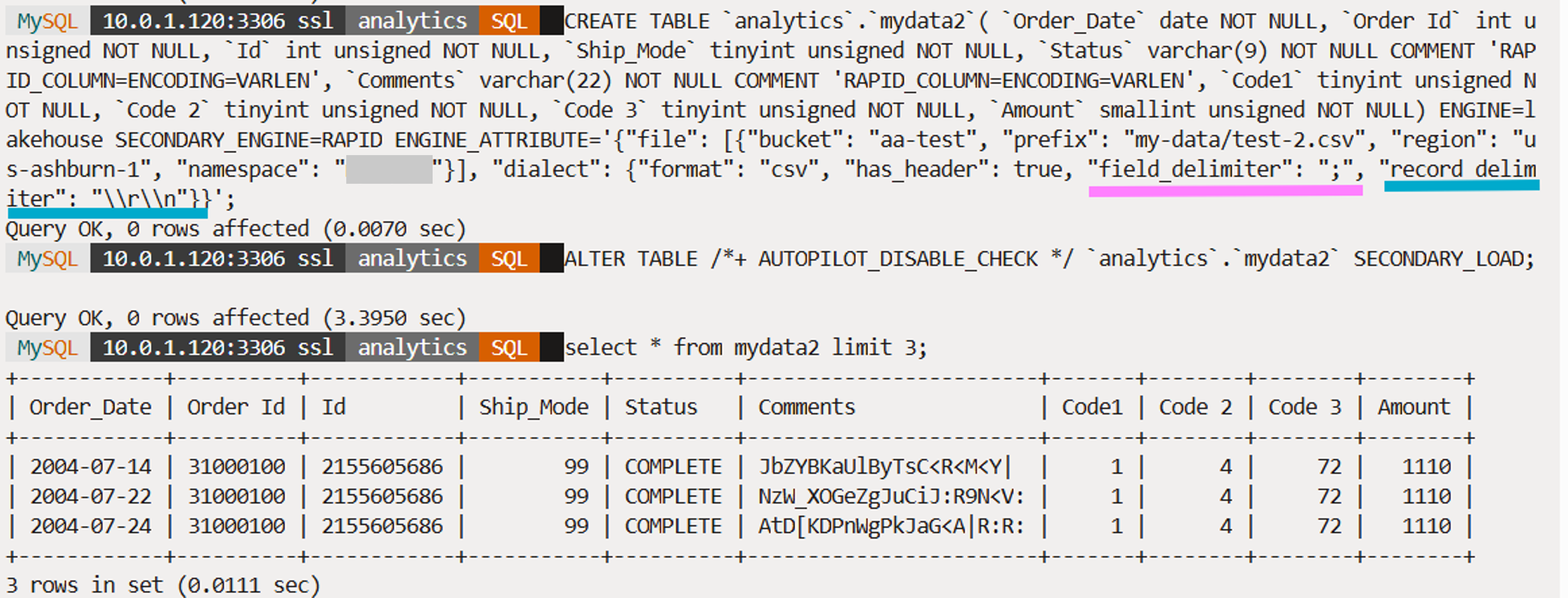
If we now run the command to load data into this table (SECONDARY_LOAD), these delimiters will be used to load data correctly into columns and rows of the table (Fig. 6).
Example 3—auto detection when manually creating tables
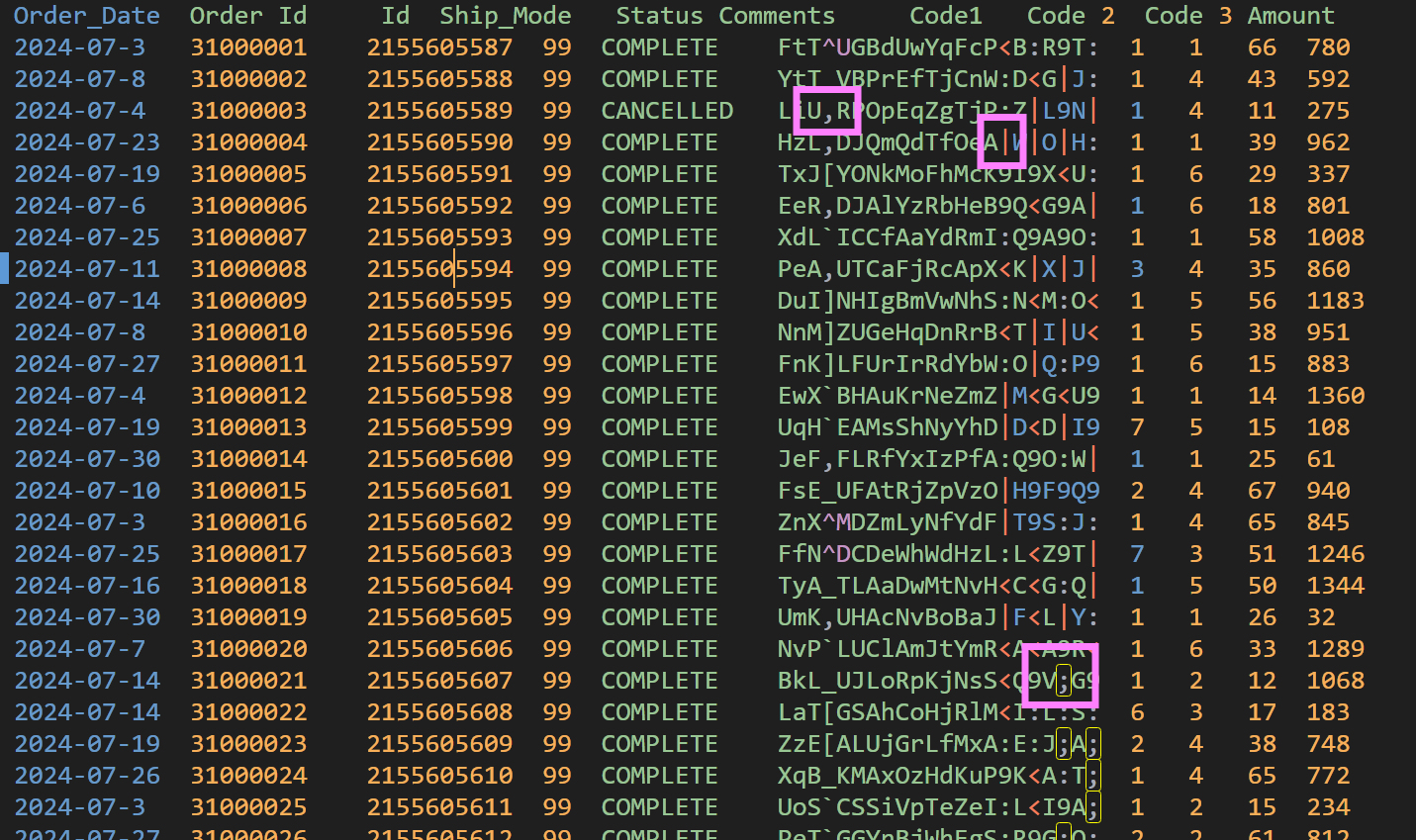
In this final example, we will not call Auto Parallel Load, but manually create the table and then load data into it. We will use a different file with tab as the field delimiter (Fig. 7). The ‘Comments’ column again has characters that can be interpreted as field delimiters—comma, pipe, semi-colon.
When manually creating the table using the CREATE TABLE statement, we may know the column names, their data types, how many columns, and so on, but the field and record delimiters may not be known. Therefore, we can specify “auto” as the values for both parameters. Alternatively, like in the example above, we could choose to not provide any value and completely omit these two attributes. Therefore, the two lines for the field_delimiter and record_delimiter could be completely omitted from the table definition.
CREATE TABLE `analytics`.`mydata3`
( `Order_Date` date NOT NULL,
`Order Id` int unsigned NOT NULL,
`Id` int unsigned NOT NULL,
`Ship_Mode` tinyint unsigned NOT NULL,
`Status` varchar(9) NOT NULL,
`Comments` varchar(22) NOT NULL,
`Code1` tinyint unsigned NOT NULL,
`Code 2` tinyint unsigned NOT NULL,
`Code 3` tinyint unsigned NOT NULL,
`Amount` smallint unsigned NOT NULL
)
ENGINE=lakehouse
SECONDARY_ENGINE=RAPID
ENGINE_ATTRIBUTE='{"file":
[{"region": "us-ashburn-1",
"namespace": "mytenancy",
"bucket": "mybucket",
"prefix": "my-data/test-3.csv",
}],
"dialect": {"format": "csv",
"has_header": true}}';
Once the table is created, we can inspect the table definition (Fig. 8). You will see that the field and record delimiter values are still “auto”. This is because we have not yet loaded any data into the table.
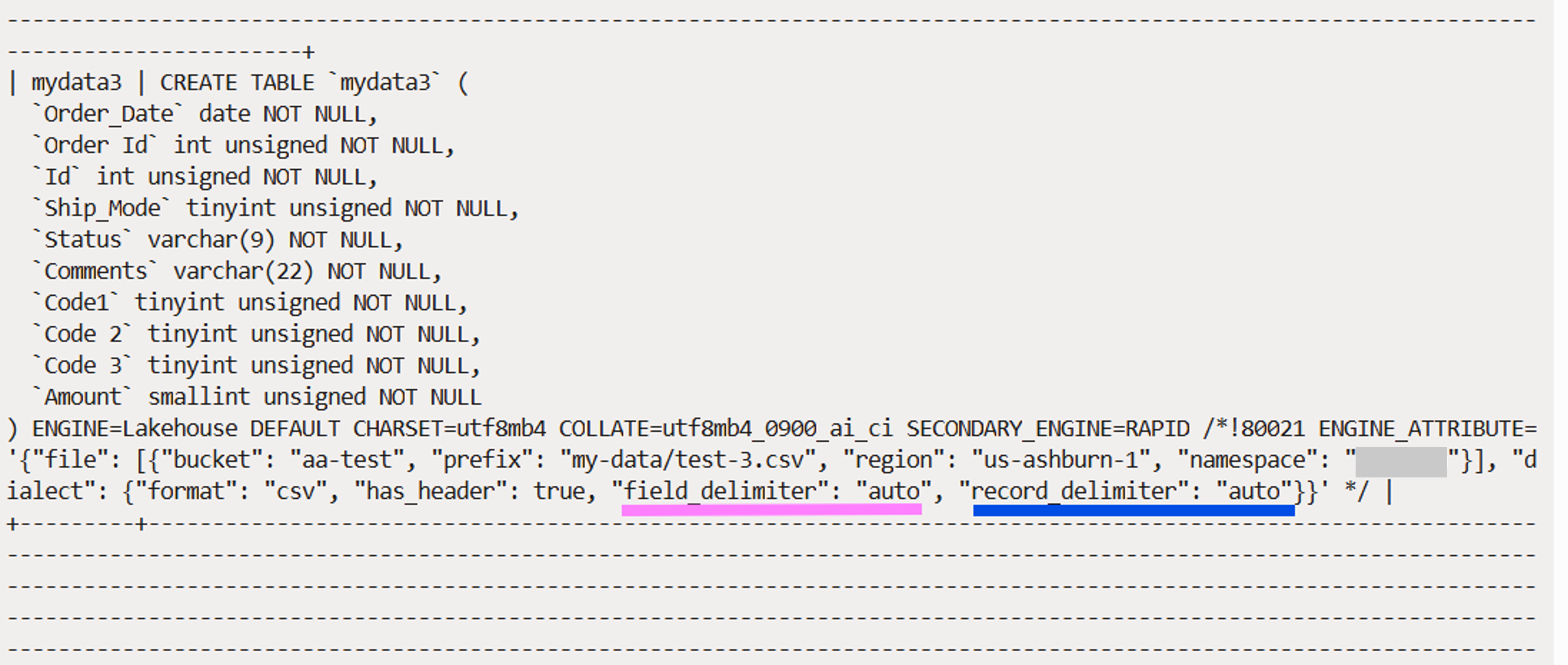
When data is loaded for the first time into the table, by running the SECONDARY_LOAD command, the dialect detection pipeline is automatically invoked internally, dialect inference is performed, and the inferred delimiters are inserted into the table definition (Fig. 9). All this is shown as messages during the load operation.

The data load operation then proceeds to load data into the table (Fig. 10).

As you have seen in the above examples, auto dialect detection for CSV files can greatly simplify the data load process and reduce errors.
Give HeatWave’s auto dialect detection feature and the rest of the service a try on OCI or AWS and let us know your feedback!
More Information
You can find more information about HeatWave at:
General Information
- Get started with HeatWave for free (link)
- Try HeatWave on AWS (link)
- HeatWave Lakehouse website (link)
- Technical brief (PDF)
- Documentation (link)
- Live Labs (link)
- Learn and get certified (link)
Blog posts
- Getting started with HeatWave Lakehouse (link)
- Configuring Resource Principals for HeatWave Lakehouse (link)
- Exporting to object storage with HeatWave (link)
- HeatWave Lakehouse on AWS (link)
- Oracle ClouldWorld Keynote: The Future of Scale-out Data Processing with HeatWave Lakehouse (link)
Videos and demos

