Anomaly detection is a technique for finding abnormalities in data. It has multiple applications, such as fraud detection, network intrusion, detecting life-threatening medical conditions, quality control, preventive maintenance, and root cause analysis, among others.
Here are two examples:
The first example involves detecting credit card fraud. If a customer typically uses their card within their home country and suddenly makes several large purchases abroad, this deviation from their normal spending pattern could indicate that the card has been stolen and is being used without their knowledge.
The second example highlights business disruption caused by critical application failures. Application logs often contain early warning signs—anomalous events that precede a failure. By detecting these anomalies in real time, businesses can take preventive action to avoid downtime and maintain uninterrupted operations.
In the above examples, anomaly detection techniques can sense abnormal behavior and flag a warning so that corrective actions can be taken.
Anomaly detection challenges
Anomaly detection is particularly challenging because of issues such as a lack of labeled data, rare occurrences of anomalies, and an inability to address various types of anomalies with one solution.
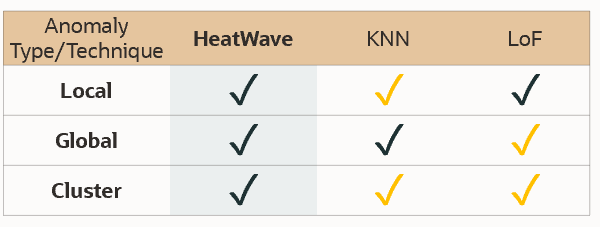
Anomaly detection literature has multiple distance-based machine learning algorithms, which use nearest-neighbor distances to detect anomalies, however, these algorithms are often designed to detect specific anomaly types, so choosing an algorithm can be problematic if the user does not know which anomaly types are in the dataset. Some of the anomaly types are, global anomaly which are far from all normal points e.g. a credit card transaction happening in a distant country, local anomaly e.g. a $100 charge at a gas station by a user whose gas purchases are usually under $60, cluster anomaly e.g. multiple consecutive maximum-allowed cash withdrawals from an ATM on the same day.
How does HeatWave AutoML addresses the Anomaly Detection challenges?
Support for multiple types of anomalies
HeatWave AutoML detects anomalies in unlabeled data in an automated fashion using a novel and patented technique called Generalized kth Nearest Neighbors (GkNN) which is based on an ensemble algorithm that does not require tuning of hyperparameters. It identifies common types of anomalies such as local, global, and clustered which typically requires separate algorithms to detect. This algorithm provides high performance on a set of anomaly detection data sets, out-performing some of the most widely utilized algorithms such as k-th Nearest Neighbor (kNN) and Local Outlier Factor (LOF).
Support for semi-supervised learning
Labeling all training samples can be costly, but often a subset of the data is already labeled. For example, in fraud detection, a bank employee may identify some fraudulent transactions based on experience. In such cases, semi-supervised learning can be used to leverage the partially labeled data to improve model performance.
HeatWave AutoML supports semi-supervised learning, allowing results from unsupervised models to be enhanced using supervised learning on labeled data. Users can assign the target variable as 1 or 0 for known outcomes and use NULL for unlabeled records.
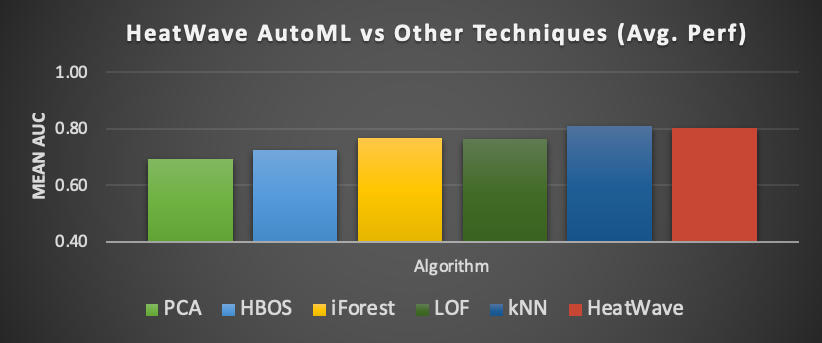
HeatWave AutoML offers the best AUC score
HeatWave AutoML offer one of the best AUC (Area under the ROC Curve) score compared to other anomaly detection techniques. AUC score is a measure of model efficiency. The higher the AUC, the better the model’s performance at distinguishing between the positive and negative classes.
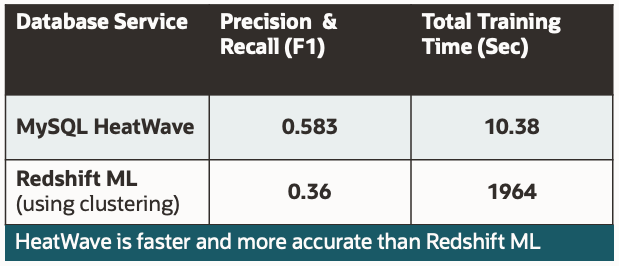
HeatWave AutoML Anomaly Detection – Fully automated, fast and accurate
Unlike competing products such as Google BigQuery ML, Redshift ML, or Snowflake, HeatWave AutoML offers a fully automated anomaly detection solution. In benchmark tests on multiple anomaly detection datasets, HeatWave demonstrated significantly higher speed and accuracy compared to Redshift ML.
In addition to Generalized kth Nearest Neighbors (GkNN) HeatWave, HeatWave AutoML also supports Principal Component Analysis (PCA) model and internally developed Generalized Local Outlier Factor (GLOF) model.
Heatwave AutoML customer use cases – Anomaly detection
Money muling – Money muling is a form of money laundering in which fraudsters deceive individuals into transferring stolen funds on their behalf. Anomaly detection helped identify such activity by analyzing unusual patterns—such as deviations in transaction history, sudden international transfers, frequent or high-value transactions, and erratic account behavior.
Healthcare insurance fraud – Examples of this type of fraud include unusual patterns in medical service usage or billing codes, sudden spikes in high-cost procedures, excessive or frequent claims, and incompatible treatments. Anomaly detection helped identify such outliers for further investigation and fraud prevention.
Manufacturing – By applying anomaly detection to sensor data strategically collected along the assembly line, the customer was able to anticipate potential jams. This allowed for timely repositioning of parts, preventing production disruptions and ensuring continuous operation.
Telecommunications – Leverage anomaly detection techniques to proactively detect performance issues and hardware malfunctions in telecom networks, enabling preventive maintenance and reducing downtime and customer disruptions.
Loyalty points fraud – This type of fraud includes loyalty account takeovers, points laundering, and employees manually crediting points to fake accounts. An anomaly detection model is trained using features such as account balance spikes, sudden increases in redeemed points, abnormal redemption frequency, and excessive promotion usage to trigger alerts or automatically lock suspicious accounts.
Casino fraud – Leverage anomaly detection to help casino operators proactively guard against fraud, insider betting, and operational irregularities by automatically learning normal patterns across large-scale betting data. Detected anomalies can be used to fine-tune betting limits, dynamically adjust odds, and investigate high-risk users—without the need for manual rule tuning.
How to implement anomaly detection using HeatWave?
HeatWave AutoML can be used for any of the above mentioned or similar anomaly detection use cases by invoking the routines to train a model and to make predictions as illustrated in the examples below.
The ML_TRAIN routine on training dataset produces a trained machine learning model.
mysql>CALL sys.ML_TRAIN(‘mlcorpus_anomaly_detection.volcanoes-b3_anomaly_train’,
NULL, JSON_OBJECT(‘task’, ‘anomaly_detection’,
‘exclude_column_list’, JSON_ARRAY(‘target’)),
@anomaly);
Query OK, 0 rows affected (46.59 sec)
The ML_MODEL_LOAD routine loads a model from the model catalog.
mysql>CALL sys.ML_MODEL_LOAD(@anomaly, NULL);
Query OK, 0 rows affected (3.23 sec)
The ML_SCORE scores a model by generating predictions using the feature columns in a labeled dataset as input and comparing the predictions to ground truth values in the target column of the labeled dataset.
mysql>CALL sys.ML_SCORE(‘mlcorpus_anomaly_detection.volcanoes-b3_anomaly_test’,
‘target’, @anomaly, ‘roc_auc’, @score, NULL);
Query OK, 0 rows affected (5.84 sec)
mysql>SELECT @score;
+——————–+
| @score |
+——————–+
| 0.7465642094612122 |
+——————–+
1 row in set (0.00 sec)
The ML_PREDICT_TABLE generates predictions for an entire table of data and saves the results to an output table.
mysql>CALL sys.ML_PREDICT_TABLE(‘mlcorpus_anomaly_detection.volcanoes-b3_anomaly_train’,
@anomaly, ‘mlcorpus_anomaly_detection.volcanoes-predictions’,NULL);
Query OK, 0 rows affected (10.28 sec)
mysql>SELECT * FROM mlcorpus_anomaly_detection.volcanoes–predictions LIMIT 5;
+——————-+——+——+———-+——–+—————————————————————————————-+
| _4aad19ca6e_pk_id | V1 | V2 | V3 | target | ml_results |
+——————-+——+——+———-+——–+—————————————————————————————-+
| 1 | 128 | 802 | 0.47255 | 0 | {‘predictions’: {‘is_anomaly’: 0}, ‘probabilities’: {‘normal’: 0.95, ‘anomaly’: 0.05}} |
| 2 | 631 | 642 | 0.387302 | 0 | {‘predictions’: {‘is_anomaly’: 0}, ‘probabilities’: {‘normal’: 0.96, ‘anomaly’: 0.04}} |
| 3 | 438 | 959 | 0.556034 | 0 | {‘predictions’: {‘is_anomaly’: 0}, ‘probabilities’: {‘normal’: 0.74, ‘anomaly’: 0.26}} |
| 4 | 473 | 779 | 0.407626 | 0 | {‘predictions’: {‘is_anomaly’: 0}, ‘probabilities’: {‘normal’: 0.87, ‘anomaly’: 0.13}} |
| 5 | 67 | 933 | 0.383843 | 0 | {‘predictions’: {‘is_anomaly’: 0}, ‘probabilities’: {‘normal’: 0.95, ‘anomaly’: 0.05}} |
+—–+——+——+———-+——–+—————————————————————————————-+
5 rows in set (0.00 sec)
The ML_PREDICT_ROW generates predictions for one or more rows of data.
mysql>SELECT sys.ML_PREDICT_ROW(‘{“V1”: 438.0, “V2”: 959.0, “V3”: 0.556034}’, @anomaly, NULL);
+—————————————————————————————————————————————————-+
| sys.ML_PREDICT_ROW(‘{“V1”: 438.0, “V2”: 959.0, “V3”: 0.556034}’, @anomaly, NULL) |
+—————————————————————————————————————————————————-+
| {“V1”: 438.0, “V2”: 959.0, “V3”: 0.556034, “ml_results”: “{‘predictions’: {‘is_anomaly’: 0}, ‘probabilities’: {‘normal’: 0.74, ‘anomaly’: 0.26}}”} |
+—————————————————————————————————————————————————-+
1 row in set (5.35 sec)
In summary, anomaly detection is an effective technique for finding abnormalities in data. HeatWave AutoML offers an automated machine learning pipeline for anomaly detection based on patented algorithm that can detect various types of anomalies and provides better accuracy compared to other anomaly detection techniques. It also supports semi-supervised learning, Principal Component Analysis (PCA) and internally developed technique called Generalized Local Outlier Factor (GLOF).
For more details, please refer to the HeatWave AutoML documentation and HeatWave AutoML page. You can also try HeatWave for free. Using the free service, build a predictive ML model using the lab, Getting started with HeatWave AutoML to try HeatWave AutoML firsthand. Also checkout videos that demonstrate how to build anomaly detection model using unsupervised learning and how to use Principal Component Analysis (PCA) for anomaly detection.
