MySQL 9.7 コミュニティ版では、従来の結合オプティマイザに代わる選択肢として、ハイパーグラフ・オプティマイザが含まれるようになりました。これにより、この機能は MySQL のすべてのエディションで利用可能になります。これは単なる見た目上の変更ではありません。
ハイパーグラフ・オプティマイザは、新しい結合の実行計画フレームワークを使用します。これは、実行計画の形が実際に大きな違いを生むクエリを対象としたものです。特に、複数テーブルの結合、複数の結合方式が競合するワークロード、そして実行計画のある部分で生成された行の順序が後続処理のコストに影響するケースに有効です。
すでに多くのクエリで改善が見られています。一方で、ハイパーグラフ・オプティマイザはまだ進化中です。場合によっては、特に行数見積もりが不正確なとき、従来のオプティマイザのほうが優れた実行計画を選ぶこともあります。そのため、MySQL コミュニティからのフィードバックを求めています。ハイパーグラフ・オプティマイザを試してパフォーマンス向上が見られた場合は、ぜひ知らせてください。
もしリグレッションに遭遇した場合は、再現可能なテストケース、スキーマ、インデックス、可能であれば EXPLAIN ANALYZE の出力を含めて、バグレポートを提出してください。こうしたフィードバックは、実行計画の品質をより速く改善する助けになります。
有効化する方法
ハイパーグラフ・オプティマイザは、MySQL 9.7 コミュニティ版ではデフォルトで有効になっていません。
セッション単位で有効化:
SET optimizer_switch='hypergraph_optimizer=on';再び無効化する:
SET optimizer_switch='hypergraph_optimizer=off';単一の文だけで有効化するには、SET_VAR ヒントを使用:
SELECT /*+ SET_VAR(optimizer_switch='hypergraph_optimizer=on') */ ...;これにより、ワークロード全体を変更することなく、クエリを 1 つずつ実用的にテストできます。
何が違うのか
従来の MySQL 結合オプティマイザは、長年使われてきた left-deep 探索フレームワークを基礎としています。このフレームワークは何度も改善されてきましたが、基本的な形のため、いくつか難しい点があります。
- 主に left-deep な結合ツリーを前提に考える
- 単純な内部結合以外の並べ替えへの対応が限定的
- 行の順序を探索の第一級の要素ではなく、後からの調整として扱う
- ハッシュ結合を主要な結合戦略としてではなく、後段で適用する
- 大きく異なる物理戦略の間で、完全にコストベースに選択させることが歴史的に難しかった
ハイパーグラフ・オプティマイザは、異なるモデルからスタートしています。クエリを結合すべきテーブルの並びとして扱うのではなく、グラフとして扱います。
- 各テーブルはノード
- 各結合述語はエッジ
- 複数テーブルに関わる述語も直接表現可能
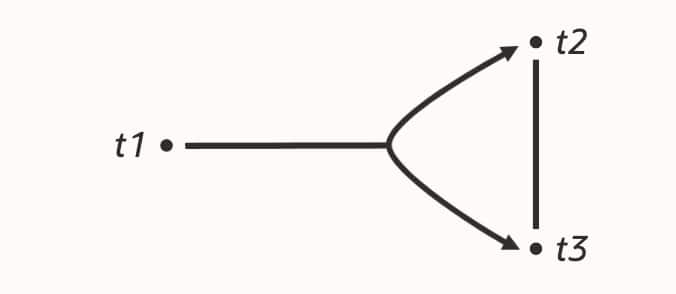
t1 LEFT JOIN (t2 JOIN t3)そこから、動的計画法を使って、接続されたサブプランを列挙します。これにより、すぐに 2 つの利点が得られます。
- オプティマイザは、固定された 1 つの「結合順序」の形で考える必要がない
- 結合制約と合法的な並べ替えを、従来のフレームワークより自然に捉えられる
これが、この名称の背後にある理論的基盤です。探索空間はハイパーグラフとして表現され、オプティマイザはそのハイパーグラフの有効な接続分割を列挙します。この研究の元になった論文は、SIGMOD 2008 で発表された Guido Moerkotte と Thomas Neumann による “Dynamic Programming Strikes Back” です。
実務上なぜ重要なのか
ハイパーグラフ・オプティマイザが有用なのは、いくつかの重要な選択を、後付けではなく最適化の第一級の要素として扱えるようにするからです。
1. Interesting order が探索の一部になる
アクセスパスは、局所的には少し高コストであっても、後で価値を持つ順序で行を返すなら、保持する価値があります。
典型的な例は次のとおりです。
ORDER BY ... LIMITでソートを回避できるインデックス順序GROUP BYにとって有用な順序で入力を渡せるアクセスパス- 後続の filesort や一時テーブルを不要にできる程度に順序を保持する結合計画
従来のオプティマイザも順序付きアクセスパスを利用できますが、探索の早い段階から広くそれを考慮するわけではありません。ハイパーグラフ・オプティマイザは、代替案を比較する際にこうした “interesting order” を意識するため、少し高価なサブプランであっても、それによって後でより大きな作業を節約できるなら採用できます。
2. ネステッドループ結合とハッシュ結合が、本当の意味でコストベースの選択になる
従来のオプティマイザは、内側で利用できるインデックスがある場合、全体としてはハッシュテーブルを構築したほうが安くても、ネステッドループ結合を選び続けることがよくあります。
ハイパーグラフ・オプティマイザは、同じ探索フレームワークとコストモデルを使って、ネステッドループ結合とハッシュ結合を比較します。そのため、インデックス付きネステッドループが自動的に勝者になるわけではありません。
これは分析系クエリで重要です。インデックス単体では魅力的に見えても、何度もインデックスを探査するより、一度スキャンしてハッシュ化するほうが有利になることがあるためです。
3. Bushy な結合計画をサポートする
left-deep オプティマイザは、次のような計画を作る傾向があります。
ハイパーグラフ・オプティマイザは、bushy plan も検討できます。
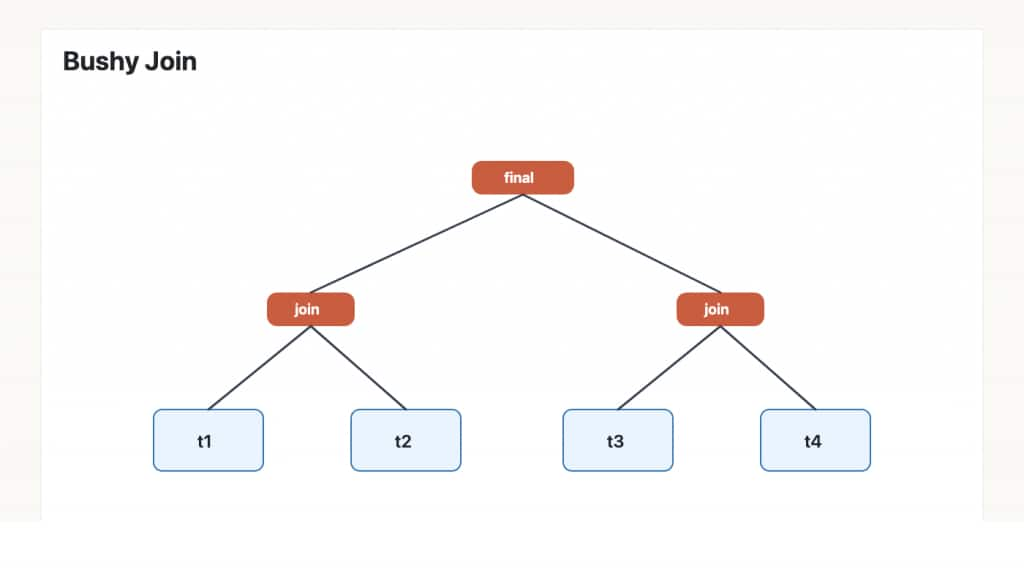
これは抽象的に聞こえるかもしれませんが、多くの場合、まさに求めているものです。たとえば、t1 JOIN t2 が選択的で、t3 JOIN t4 も選択的である場合、4 つのテーブルを 1 本の長い left-deep チェーンで引き回すよりも、まず両方の縮小された中間結果を作り、最後にそれらを結合するほうが安くなることがあります。
4. コストモデルは測定値に基づいて調整されている
ハイパーグラフ・オプティマイザは、マイクロベンチマークから得られた時間測定に基づくコストモデルを使用します。目的は、すべての見積もりを完璧にすることではありません。アクセスパスや結合方式の選択が、観測されたコストをよりよく反映するようにすることです。
これは、次のような判断に表れます。
- テーブルスキャンとセカンダリインデックススキャンの比較
- ハッシュ結合とネステッドループ結合の比較
- 計画の早い段階で少し余分なコストを払ってでも、順序を保持する価値があるかどうか
TPC-DS による暫定的な効果
具体的なデータポイントとして、スケールファクター 1、約 1 GB のデータ、ワーキングセットが完全にメモリ上にある状態で、TPC-DS クエリセットを実行しました。
この実行における 101 個のクエリ種全体では、次の結果になりました。
- 77 個はハイパーグラフ・オプティマイザのほうが高速
- 24 個は低速
- 幾何平均での実行時間改善は 22.45%
これは有望な結果ですが、「完了した」という意味ではありません。同じデータセットには大きな性能劣化も含まれており、コミュニティ版でこの機能がデフォルトではオフのままになっている理由の一つです。
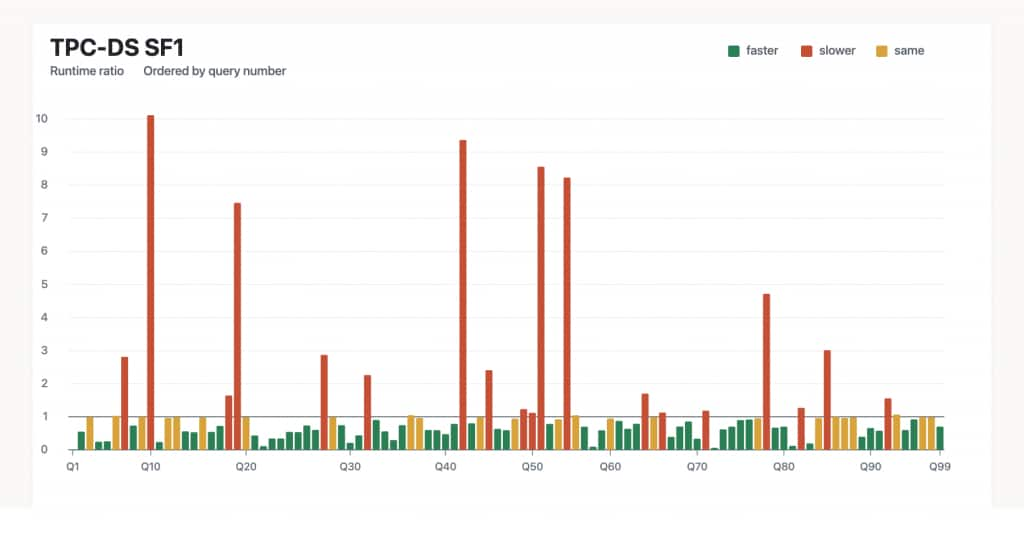
ここから得られた考察は次のとおりです。:
- グラフは TPC-DS のクエリ番号順に並べられ、実行時間比を示している。1.0 未満は性能改善、1.0 超は性能劣化を意味する
- ほぼ半数のクエリで少なくとも 25% 改善
- 19 個のクエリで少なくとも 50% 改善
- 一方で、14 個の文では少なくとも 50% 劣化
つまり、現在の状況は「どこでも小さく改善する」ではありません。「多くの大きな改善があり、同時に、現在積極的に取り組んでいる少数の大きな悪化もある」という状態です。
我々の検証以外からの 2 つの例
Sysbench:順序付き読み取りと選択的読み取りに対するより良い実行計画
MySQL 9.7.0 に関する最近のsysbenchを使った テストで、Mark Callaghan 氏は、ハイパーグラフ・オプティマイザを有効にした場合、read-only-distinct で 26%、read-only_range=10000 で 15% の改善を報告しました。
read-only-distinct の結果は、新しいオプティマイザが支援しようとしていることのよい例です。つまり、DISTINCT や ORDER BY にとって有用な順序で行を生成する計画を、オプティマイザが適切に評価することで効果が出ます。順序要件を「後で直すもの」として扱うのではありません。
read-only_range=10000 ワークロードは複数のクエリを実行しており、その中には read-only-distinct で使われるクエリも含まれているため、同じより良い計画の恩恵を受けています。
厳密な最良の実行計画は、スキーマ、インデックス、データ分布に依存します。しかし、これらの結果は、新しいフレームワークの強み、すなわち interesting order、より広い計画探索、より正確なコスト比較と整合しています。
実際のオプティマイザ異常が解消される例
Shattered Silicon は最近、結合、ORDER BY、LIMIT を含むクエリで、MySQL がはるかに悪い実行計画を選んだケースを紹介しました。結合の同値性を通じて、優れたインデックス順の実行計画が利用可能だったにもかかわらずです。
これはまさに、ハイパーグラフ・オプティマイザが対処するために設計された種類の問題です。順序の性質が計画探索の一部として扱われる場合、オプティマイザは、本来なら早すぎる段階で枝刈りされてしまう代替案を保持し、比較できます。MySQL 9.7 では、この種の問題はハイパーグラフ・オプティマイザによって正しく処理されます。
試す価値が最も高い場所
計画品質は、スキーマ、インデックス、データ分布、行数見積もりの精度に依存します。最初からアプリケーション全体を分類する必要はありません。プロファイリングする価値のある文から始め、クエリを 1 つずつテストしてください。
良い候補は次のようなものです。
- 複数のテーブルを結合する 1 つの
SELECTが原因になっている、遅いページ、レポート、ダッシュボード、バッチジョブ ORDER BY ... LIMIT、GROUP BY、DISTINCTを含むクエリ。特に、EXPLAIN ANALYZEでソート、一時テーブル、または小さな結果を返す前に多数の行を調べていることが示される場合- 最終結果は小さいにもかかわらず、はるかに多数の行をスキャンする結合
- 大きな履歴、イベント、注文、トランザクションテーブルと、ルックアップテーブルを組み合わせるレポート系クエリ
- 従来の実行計画が、同じテーブルに対して多数の繰り返しインデックス・ルックアップを行うクエリ
単一テーブルのクエリ、主キー検索、非常に小さな結合では、ほとんど違いがないかもしれません。また、非常に短いクエリでは、クエリ最適化時間が全体レイテンシの中で目に見える割合を占めるため、従来のオプティマイザのほうが良い選択になることもあります。さらに、ハイパーグラフ・オプティマイザがまだ考慮していない実行戦略を従来のオプティマイザが使える場合にも、従来のオプティマイザが勝つ可能性があります。
不正確な見積もりは、どちらのオプティマイザにも悪い実行計画を選ばせる可能性があります。まれに、2 つの見積もり誤差が偶然打ち消し合うことで、従来のオプティマイザのほうが良い結果になることもあります。
評価方法
自分のワークロードでハイパーグラフ・オプティマイザを試したい場合は、まずは小規模から始めてください。アプリケーション開発者の場合、通常はワークロード全体を一度に変更するのではなく、アプリケーション・トレースから見つかった遅いクエリやばらつきの大きいクエリから始めます。DBA の場合は、候補クエリを見つける出発点として、スロークエリログや Performance Schema の statement summary テーブルが有効です。
- 遅いクエリ、または代表的なレポートクエリを 1 つ選ぶ
-
hypergraph_optimizer=offとhypergraph_optimizer=onの両方で実行する - 実行時間と
EXPLAIN ANALYZEの両方を比較する - 結合順序、結合方式、調査行数、ソートや一時テーブルが消えるかどうかに注目する
次に期待すること
ハイパーグラフ・オプティマイザをコミュニティ版で利用可能にする目的は、完成であることを宣言することではありません。この機能がまだ進化中であるうちに、より幅広いテストと、より良いバグレポートを得ることです。
すでに明確な利点が見えています。
- interesting order のより良い扱い
- ネステッドループ結合とハッシュ結合の真のコストベース比較
- bushy な結合計画のサポート
- 測定された実行コストとよりよく整合するコストモデル
一方で、さらなる作業が必要な領域も分かっています。
- ベーステーブル・フィルタの選択率見積もり
- 結合結果のカーディナリティ見積もり
- 従来のオプティマイザがまだより良い実行計画を見つける=リグレッション
この機能を試して、そうしたリグレッションを見つけた場合は、ぜひご報告ください。明確な改善の報告も有用です。特に、クエリの形と実行計画の違いが含まれている場合は役立ちます。どちらの種類のフィードバックも、より広い MySQL コミュニティに向けて実行計画の品質を改善する助けになります。
この記事では、全体像だけを扱いました。今後の記事では、結合列挙、interesting order、コストモデリング、そして改善やリグレッションの背後にある具体的な実行計画の変更について、さらに深く掘り下げていきます。

