Overview
In the first part of this series—Introduction to VirtIO—we introduced VirtIO, a widely-used standard for efficient communication between guest VMs and their host. While a typical VirtIO configuration provides solid performance for general-purpose workloads, higher intensive workloads expose limitations in its data plane. More specifically, the overhead caused by Qemu’s involvement in the data plane.
In this document, we’re going to take a look at one of the fundamentals of VirtIO: vhost. Vhost is a key optimization to VirtIO that was created to offload data-plane processing from Qemu into more efficient components.
We’ll start off by taking a more in-depth look into the causes of overhead in the data plane of a pure VirtIO configuration. We’ll talk about the costly operations that are involved, such as VM exits, VM entries, context switches, and userspace processing by Qemu. Then we’ll introduce vhost and elaborate on how it addresses these issues by moving data-plane operations either into the kernel (kernel-based vhost) or into a specialized userspace process (via vhost-user).
We’ll then dive into both kernel-based vhost and vhost-user architectures, examining each in detail—including their advantages, drawbacks, typical use cases, and how they affect performance.
To illustrate the major sources of overhead clearly, we’ll use detailed labeled diagrams of pure VirtIO, kernel-based vhost, and vhost-user networking configurations. We’ll step through their transmit (Tx) and receive (Rx) execution paths, showing exactly where and when overhead occurs in each scenario.
To further reinforce understanding, we’ll summarize each configuration’s execution paths using approximate overhead equations for both the Tx and Rx paths. These overhead equations are intended to illustrate and compare the major sources of overhead for the particular configurations we’ll go over in this document. They’re simplified representations meant purely for explanatory purposes and not formal mathematical models.
In this document, we’ll use the term “Pure VirtIO” to refer to what is more precisely known as VMM-terminated VirtIO. This describes a configuration where both the VirtIO device emulation and the backend I/O logic are handled entirely within the Virtual Machine Monitor (VMM), such as Qemu. In other words, all data path operations are performed directly by the VMM in userspace.
A Terms & Definitions section is included at the end of this document that the reader is encouraged to reference while reading.
Context: VirtIO Data Plane Overhead
Before we start introducing what vhost is, it’s important to first understand the problem that vhost was meant to solve: overhead in the VirtIO data plane.
In the previous Introduction to VirtIO document, we briefly touched on VirtIO’s architecture but didn’t really elaborate on its data plane. More specifically, how data moves between the guest’s kernel, userspace, and the host’s kernel. Nor did we cover CPU execution overhead, KVM, or the role of notifications (e.g., kicks & interrupts) when processing data. We first need to understand these things in VirtIO in order to properly grasp the role that vhost would play.
Limitations of Pure VirtIO
The main motivation behind implementing vhost was to reduce the overhead cost of processing data in the VirtIO data plane for high-throughput workloads. For a VM with a pure VirtIO configuration (such as the one shown in Figure 1 below), everyday tasks involving relatively low I/O workloads—such as browsing the web or streaming videos—typically wouldn’t cause any noticeable overhead. However, as the throughput increases, overhead becomes more and more noticeable, eventually bottlenecking the system and causing degraded performance.
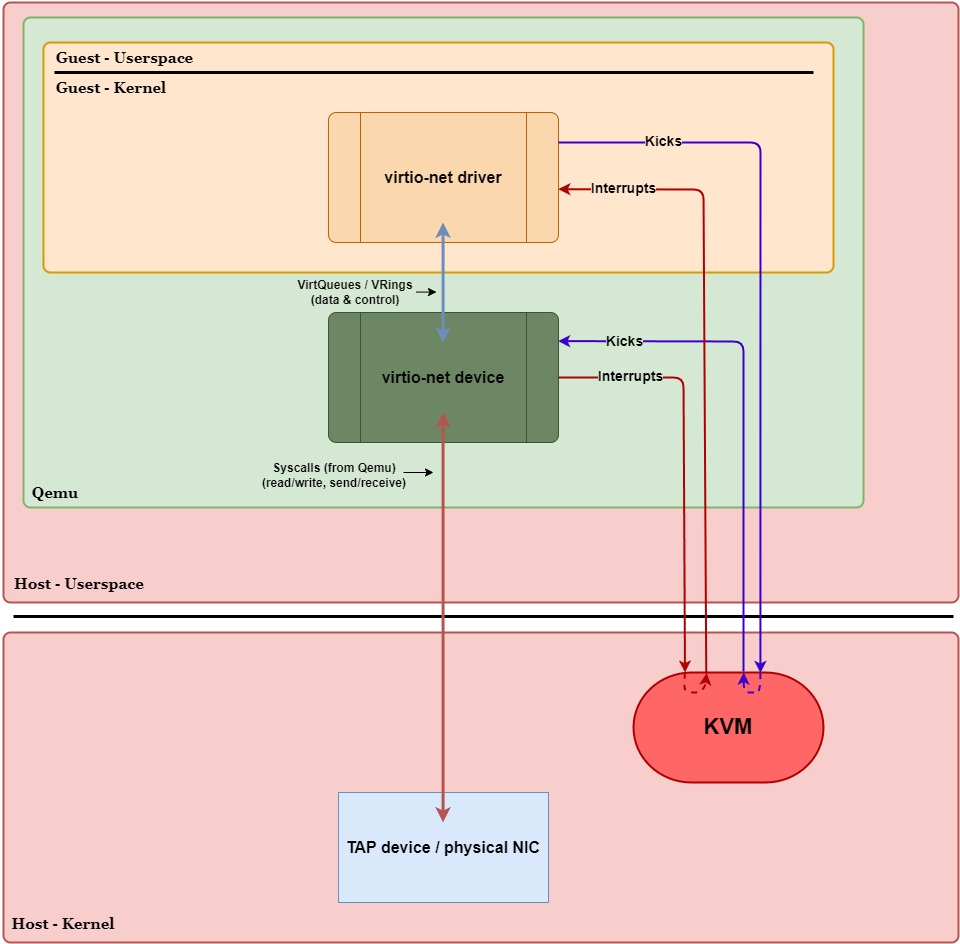
Recall that, in VirtIO, the guest and host exchange data via VirtQueues. In a pure VirtIO environment, this reading/writing to VirtQueues, handling interrupts, and forwarding packets (or I/O requests) is handled by Qemu in userspace. In other words, Qemu acts as a “middleman” between the guest and the host kernel, causing extra overhead in data-plane operations. The main culprits of overhead in a pure VirtIO configuration are context switches, VM exits/entries, and Qemu device emulation.
In Figure 1 above, we have a pure VirtIO configuration with a virtio-net device. Qemu is running device emulation in userspace, meaning packets will need to move between the guest’s kernel, Qemu, and the host’s kernel.
For now, let’s assume we’re not using any performance optimizations like ioeventfd, irqfd, VIRTIO_F_EVENT_IDX, or NAPI. For more information on these optimizations, see the Optimizations subsection under Terms & Definitions at the end of this document.
Under these conditions, for the guest to transmit a single packet, we’ll need to go through 1 context switch, 1 VM exit, and 1 VM entry:
- Guest ⇨ Host Kernel: VM exit into KVM
- Host Kernel ⇨ Qemu: Context switch from kernel to userspace (Qemu)
- Host Kernel ⇨ Guest: Eventual VM entry back into the guest
For receiving a single packet, 1 context switch, 1 VM entry, and 1 VM exit is required:
- Host Kernel ⇨ Qemu: Context switch from kernel to userspace
- Guest ⇨ Host Kernel: VM exit into KVM
- Host Kernel ⇨ Guest: Eventual VM entry back into the guest
So, without performance optimizations, a round trip for a single packet would invoke 2 context switches, 2 VM exits, and 2 VM entries. This is very expensive, especially when data rates start climbing to very high numbers.
Let’s take a closer look at the data plane execution paths for transmitting and receiving packets to see when these context switches and VM exits/entries occur. In Figure 2 below, we have the same diagram as Figure 1 except now we’ve labeled the generalized steps in the transmit (purple circles) and receive (red squares) paths. We’ll walk through these paths step-by-step and highlight when a VM exit/entry or context switch occurs. Assume no performance optimizations are being used:

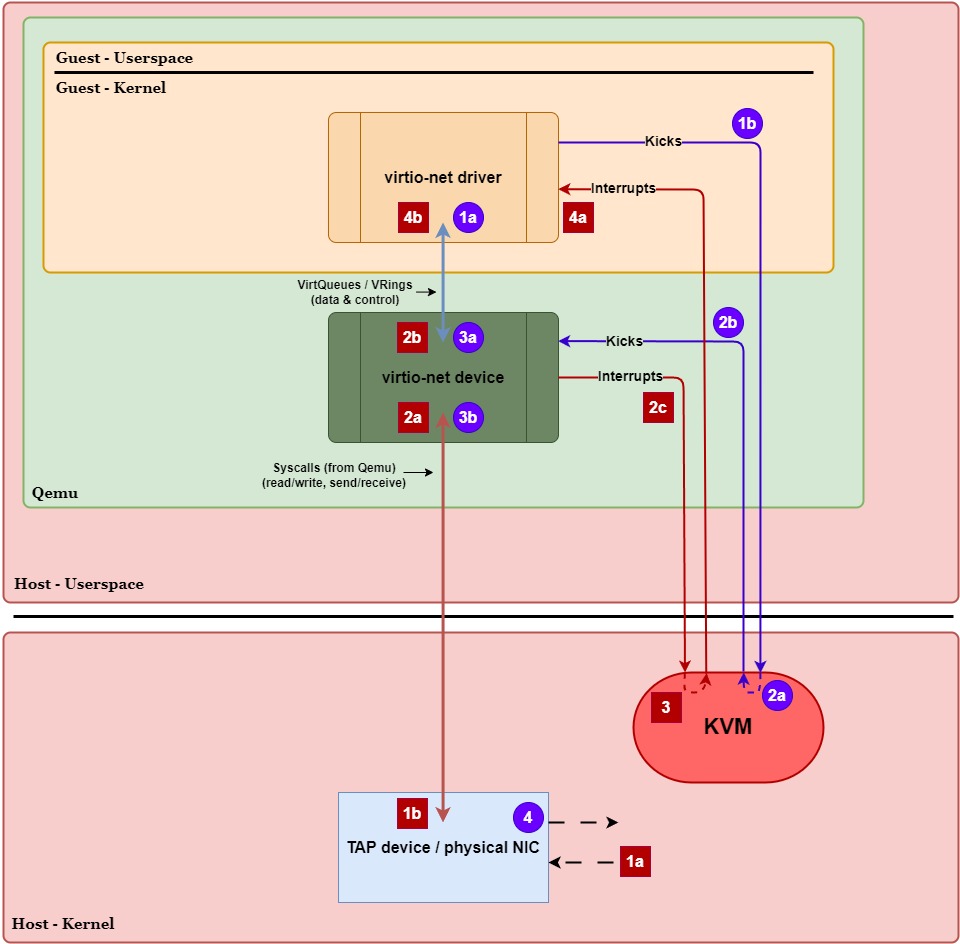
Transmit Path (Guest ⇨ Host):
- 1a.)
virtio-netdriver places data into thevirtio-netTx VirtQueue. - 1b.)
virtio-netdriver writes to a doorbell register to tell the host (KVM) to wake up (kick) thevirtio-netdevice.- VM Exit (Guest ⇨ Host Kernel) – Writing to the doorbell register causes the CPU to exit guest mode, trapping execution into KVM in the host kernel.
- 2a.) KVM intercepts the notification and knows the
virtio-netdevice (in Qemu) needs to wake up. - 2b.) KVM forwards the kick to Qemu so the
virtio-netdevice can process the new Tx VirtQueue data.- Context Switch (Host Kernel ⇨ Userspace) – Waking up Qemu means the CPU needs to switch execution to the Qemu process in userspace.
- 3a.)
virtio-netdevice retrieves the data from thevirtio-netTx VirtQueue. - 3b.) Qemu uses a syscall to copy the data to the host kernel’s networking stack (TAP device / physical NIC).
- This is a ring transition, not a context switch – the CPU remains in Qemu’s execution context while executing kernel code.
- 4.) TAP / physical NIC transmits the packet out of the network.
- VM Entry (Host ⇨ Guest) – Execution eventually returns to the guest once the host has finished what it needed to do.
Receive Path (Host ⇨ Guest):
- 1a.] TAP / physical NIC receives data from the network.
- 1b.] TAP / physical NIC queues the data in the host kernel’s networking stack and notifies Qemu via a file descriptor.
- Context Switch (Host Kernel ⇨ Userspace) – When data is ready, the kernel wakes up Qemu and CPU execution switches to the Qemu userspace process.
- 2a.] Qemu uses a syscall (e.g.,
read()/recvmsg()) to copy the data from the TAP device. - 2b.] Qemu writes the data to the
virtio-netRx VirtQueue for the guest. - 2c.] Qemu issues a syscall (
ioctl()) to KVM to request an interrupt injection to the guest.- This is a ring transition, not a context switch – the CPU remains in Qemu’s execution context while executing kernel code (to handle the interrupt).
- 3.] KVM manually injects a virtual interrupt into the guest, indicating the
virtio-netRx VirtQueue has new data.- VM Exit (Guest ⇨ Host Kernel) – If the guest is active (and normally it would be), the CPU needs to exit guest mode briefly to inject the interrupt.
- VM Entry (Host Kernel ⇨ Guest) – After injecting the interrupt into the guest, KVM causes the CPU to enter guest mode (resume the guest vCPU context).
- 4a.]
virtio-netdriver receives the interrupt and is notified of the new data in thevirtio-netRx VirtQueue. - 4b.]
virtio-netdriver reads the data from the Rx VirtQueue and hands it up to the guest’s kernel networking stack.
Overhead Cost:
To highlight the overhead costs of a pure VirtIO setup (specifically for networking with virtio-net), we’ll create generalized, approximate overhead equations for receiving and transmitting a single packet. Of course, context switches and VM exits/entries aren’t the only sources of overhead here. There are other sources of overhead like processing in the host’s kernel networking stack, Qemu processing, and data copying. However, it’s important to note that context switches and VM exit/entries are the dominant sources of overhead, so their overhead will have a higher weight compared to other overhead costs.
For the Tx path, our main sources of overhead are:
- VM exit to handle the kick from the guest in KVM.
- Context switch when Qemu wakes up (assuming it was sleeping) to handle the new Tx data from the guest.
- Qemu processing, including device emulation logic, syscalls, and other related tasks.
- Data copying by Qemu from the Tx VirtQueue into shared memory accessible by the TAP device.
- Host kernel networking stack processing for forwarding data to the physical NIC.
- The eventual VM entry back into the guest.
For the Rx path, our main sources of overhead are:
- Host kernel networking stack processing for getting data from the NIC and preparing it to be retrieved by Qemu.
- Context switch when Qemu wakes up to handle the new Rx data from the TAP device / physical NIC.
- Data copying by Qemu from shared memory to the Rx VirtQueue.
- Qemu processing, including device emulation logic, syscalls, and other smaller related tasks.
- VM exit (assuming the guest is active) to inject the interrupt to the guest.
- VM entry to handle the interrupt and process the Rx VirtQueue in the guest.
Our approximate overhead cost equations for this pure VirtIO networking configuration would look like the following (assuming no optimizations):


What is Vhost?
Formally, vhost is a protocol that allows the VirtIO data plane to be offloaded to another element—such as a dedicated kernel driver or a separate userspace process—to enhance performance. In Layman’s terms, it’s essentially a “way” to cut out the middleman (Qemu), to make processing data for VirtIO devices much more efficient.
The “way” in which this is accomplished depends on whether we’re using kernel-based vhost (e.g., vhost-scsi, vhost-net) or a separate userspace process (e.g., DPDK via vhost-user). Both replace Qemu in the main data path, but one moves it into the kernel and the other to another userspace process. Of the two, the most commonly used implementation by far is kernel-based vhost.
Kernel-based Vhost
Kernel-based vhost improves VirtIO performance by moving the data-plane VirtQueue processing directly into the kernel. More specifically, the VirtQueue processing is moved from Qemu (e.g., virtio-net device emulation) into a dedicated kernel driver (e.g., vhost-net). Each vhost driver can spawn one or more kernel threads to handle VirtQueue processing.
In Figure 2, we saw that when Qemu is in the data path, execution must flow like this for transmission (and vice versa for receiving):
Guest ⇨ VirtIO Driver ⇨ Host Kernel ⇨ Qemu (userspace) ⇨ Host Kernel ⇨ TAP Device / Physical NIC
Now, by moving the data path into the kernel and enabling a couple optimizations, we remove the back-and-forth bouncing into Qemu:
Guest ⇨ VirtIO Driver ⇨ Host Kernel (vhost-net) ⇨ TAP Device / Physical NIC
By doing this, we eliminate the need for context switches between the host kernel and Qemu in userspace, lowering CPU overhead and latency. On top of that, with the data path in the kernel, we can leverage kernel-level optimizations such as network offloads, batching, and zero-copy techniques, resulting in significant performance gains for network and storage I/O.
Today, there are several kernel-based vhost drivers that improve the performance of their respective VirtIO devices:
vhost-net– Optimizes VirtIO network (virtio-net) devices.vhost-scsi– Optimizes VirtIO SCSI (virtio-scsi) devices.vhost-blk– Optimizes VirtIO block (virtio-blk) devices.vhost-vsock– Optimizes VirtIO socket-based (virtio-vsock) devices.vhost-vdpa– Provides a framework for hardware acceleration for any VirtIO devices using the vDPA (VirtIO Data Path Acceleration) framework, enabling direct guest-to-hardware interaction through a vhost-compatible interface.
The vhost-vdpa driver is a bit more of a special case of vhost. Unlike the other vhost drivers—which directly implement a kernel-based data path—vhost-vdpa acts as a framework that offloads the data path of any compatible VirtIO device directly to hardware. Due to the uniqueness of vhost-vdpa, we’ll leave it out of our discussions for now and revisit it in a future document.
Userspace-based Vhost (vhost-user)
Userspace-based vhost (or vhost-user) optimizes VirtIO data-path efficiency by offloading VirtQueue processing to a separate userspace process (e.g., DPDK, SPDK). More specifically, vhost-user is a protocol that enables these separate userspace processes to act as backend VirtIO devices.
Unlike kernel-based vhost, vhost-user does not have dedicated kernel drivers (such as “vhost-user-net” or “vhost-user-scsi”). In fact, vhost-user itself isn’t even a process or thread. Instead, it’s essentially a feature within Qemu that tells Qemu to offload its VirtIO data plane to a separate userspace process for that particular device.
But wait—if the data plane remains in userspace, won’t performance still suffer from context switches like we saw in a pure VirtIO configuration? The answer is yes—but vhost-user is can also be used in conjunction with other guest-side optimizations such as NUMA pinning and polling (incl. NAPI polling, busy polling, epoll(), or guest poll mode drivers (PMDs)). By using these optimizations, we significantly reduce or even eliminate overhead from VM exits/entries, interrupts, and context switching.
It should be noted here that these other guest-side optimizations are independent to any host-side optimizations. In other words, they are not specific to the vhost-user case.
Traditionally, network and storage devices operate using an event-driven model, where threads wake up only once new data arrives. However, in high-performance environments, this event-driven approach introduces latency due to the overhead of processing interrupts and waking up threads.
In contrast, polling, for example, is often used alongside vhost-user. With polling, we need to dedicate a CPU core to continuously check (in a tight loop) for new data. Normally, in low-throughput workloads, polling is often wasteful since the CPU would spend more time checking for new data than actually processing it.
However, when the workloads are consistently high (and/or low latency is paramount), polling becomes a much more viable option. That is, by continuously polling for new data, we eliminate the overhead of constantly waking a thread—it’s already awake and continuously checking if there’s any work to do. Even if the workload is not consistently high, NUMA pinning and polling can still be used when low latency is critical (e.g., financial trading, real-time analytics), since it’d remove the extra jitter or delay from interrupts and context switches.
There are even more optimizations that can be made with vhost-user to further improve performance, such as the userspace process managing a NIC via VFIO (PCIe passthrough) to skip the kernel’s networking stack, eliminating kernel network stack processing overhead that would otherwise occur when sending & receiving packets.
In summary, vhost-user is powerful and, in some scenarios, even more performant than kernel-based vhost. This userspace-centric approach allows for advanced optimizations like poll mode drivers, zero-copying, custom scheduling, etc., without constantly incurring context switch overhead.
Why (or why not) Vhost?
Essentially we have three different VirtIO configurations to choose from: pure VirtIO, kernel-based vhost, and vhost-user. Which scenarios are best for each, what are their strengths, and what are their drawbacks?
Pure VirtIO
A pure VirtIO configuration is the simplest of the three and is often suitable for most scenarios and workloads. Some examples where pure VirtIO would be used would be:
- General-purpose VMs.
- Small to medium business applications, like web hosting, modest database servers, and application servers.
- Environments with limited host support (e.g., unable to load kernel drivers or run separate userspace processes on the host).
Pros:
- Easy setup: Works “out of the box” with most Linux distributions—no extra kernel modules or userspace daemons required.
- Broad compatibility: Fully supported by standard Qemu/KVM environments, cloud providers, and hypervisors.
- Good all-around performance: While not ultra-high throughput or ultra-low latency like vhost, it comfortably meets the performance needs of typical workloads.
Cons:
- Higher CPU overhead: Increased context switches that lead to high CPU usage under heavy workloads, particularly due to Qemu’s involvement in the data plane.
- Limited peak throughput & higher latency: Most default pure VirtIO implementations act as relatively simple packet mediators. High-bandwidth or latency-sensitive workloads may still experience bottlenecks unless explicitly tuned or paired with optimized I/O mechanisms (e.g.,
io_uring,AF_XDP). - Lacks specialized optimizations: Lacks optimizations like zero-copy or poll mode drivers and wouldn’t meet strict requirements in fields like high-frequency trading or telecom NVF that need ultra-low-latency and high I/O rates.
- Scalability issues: Not ideal for large-scale environments as per-host overhead would eventually become unsustainable.
When and why to choose pure VirtIO:
- You prefer simplicity and low complexity: If you want a straightforward setup without any extra kernel modules or userspace daemons. Suitable for development, testing, or environments without high performance requirements.
- You’re running light to moderate workloads: Pure VirtIO provides sufficient I/O performance for smaller applications, basic servers, test VMs, etc.
- You need broad compatibility & portability: Works out of the box in most hypervisors or OS distributions without needing special kernel features.
Kernel-based Vhost
A kernel-based vhost configuration is a bit more involved in regards to getting setup and working, vhost-net being an exception. It’s typically used in scenarios with specialized or demanding performance requirements, such as:
- Cloud providers hosting VMs running high I/O-intensive databases (e.g., MySQL, PostgreSQL) or caching services (e.g., Redis, Memcached) for enterprise clients.
- IaaS clouds environment running many VMs that communicate heavily within the same data center (east-west traffic).
- Large scale CI/CD pipeline spinning up many short-lived VMs that need fast and reliable network and storage I/O.
Pros:
- Minimized userspace overhead: Keeping the data path in the kernel and removing Qemu from the data plane frees up CPU cycles that would’ve been spent on Qemu-related tasks.
- Mature & Stable: Kernel-based vhost has been supported for a long time with widespread production use and is generally well-tested.
- Kernel integration: Vhost drivers align with their corresponding kernel subsystem, allowing users to leverage kernel-level tools and utilities (e.g.,
sysctl, cgroups, I/O schedulers) to manage or optimize I/O paths. - High-throughput capabilities: Excels with high workloads, handles higher throughput and lower latency where pure VirtIO configurations could not.
- Scalability: Enables higher VM denisty, allowing hosts to support more VMs effectively—crucial for large-scale cloud and data-center environments.
Cons:
- Moderate setup complexity: Requires loading kernel modules and extra configuration steps,
vhost-netbeing an exception. - Limited flexibility: Customizing data-path logic is less straightforward, often requiring kernel modifications or specific APIs.
- Potential security risks: Moving the data plane into the kernel increases the kernel’s attack surface. Kernel vulnerabilities can compromise hosts more severely.
When and why to choose kernel-based vhost:
- You need higher performance than pure VirtIO: If you need higher throughput and lower latency without using separate userspace frameworks.
- You need scalability: Offloading data-plane tasks to the kernel frees up CPU cycles, which could be used to run additional VMs. Useful in large-scale or multi-tenant host platforms where efficiency is key.
- You want to leverage standard kernel features: Integrates with kernel subsystems to make it easier to apply kernel tuning, firewalls, traffic shaping, etc. without needing userspace logic.
Vhost-user
A vhost-user configuration is the most complex of the three when it comes to getting things up and running. It’s commonly found in environments requiring fine-tuned customization, control, and flexibility in ways kernel-based vhost isn’t able to provide. For example:
- Virtual switches or custom userspace packet-processing pipelines that need direct, kernel-bypass access to vNICs.
- Security appliances or VM-based services doing DPI (deep packet inspection) or custom packet modification on-the-fly.
- Userspace storage engines (e.g., SPDK) providing high-performance storage interfaces directly to VMs.
Pros:
- Flexibility: Supports custom logic (packet filtering, encryption, advanced caching, etc.) entirely in userspace.
- Superior performance (with optimized frameworks): Userspace networking or storage can be heavily optimized and outperform kernel-based vhost in certain scenarios with very high packet rates or ultra-low latency requirements.
- Kernel isolation: The data path is handled by a separate userspace process making it easier to upgrade userspace services without rebooting or updating the host’s kernel.
- Resource allocation control: Allows running multiple
vhost-userbackends, each pinned to specific CPUs or NUMA nodes. Explicit CPU/memory affinity leads to better performance tuning for different workloads.
Cons:
- High setup complexity: Requires managing a separate userspace process and proper coordination between Qemu, the userspace backend, and the guest, including configuration of UNIX domain sockets, shared memory, and inter-process communication (IPC).
- Requires extra resources and fine-tuning: High-performance
vhost-userbackends, like those built on DPDK, rely on busy-polling, often requiring dedicated physical CPUs. Achieving optimal performance can involve non-trivial setup and tuning. - Broader attack surface:
vhost-userbackends typically run outside of the Qemu process yet require full access to guest memory. This increases the risk that vulnerabilities in the backend could compromise guest data or host integrity.
When and why to choose vhost-user:
- You need complex or custom data-plane logic: If your primary goals are flexibility, custom packet processing, or specialized I/O handling that go beyond the capabilities of kernel-based vhost.
- You have a multi-OS environment: Kernel-based vhost support would be inconsistent in a multi-OS environment.
vhost-userwould help unify the data plane across those different platforms.
In summary, pure VirtIO is still very performant and suitable for almost all workloads. Kernel-based vhost provides a balanced upgrade for high-performance use cases, while vhost-user is for specialized, ultra-demanding workloads where every microsecond counts.
Vhost Architecture
The architecture of vhost still includes the three key parts that we saw in our previous article: a front-end, a backend, and VirtQueues & VRings.
In a pure VirtIO configuration, the front-end driver exists in the guest’s kernel, the backend device exists in Qemu (userspace), and the communication between them is handled by their VirtQueues & VRings in shared memory.
When we switch to a vhost configuration, the biggest change is to the backend. For kernel-based vhost, the backend moves into the host’s kernel as a dedicated kernel driver (e.g., vhost-net). For userspace-based vhost (vhost-user), this backend moves into a separate userspace process on the host.
In the example vhost diagrams below, you’ll notice that there still exists this VirtIO device in Qemu, except now it includes the label “model”. In virtualization, a device model is something that presents a virtual device interface to the guest but doesn’t necessarily implement the full functionality. With vhost, the data plane is moved out of Qemu, but the control plane, in part, still exists between the driver and the VirtIO device in Qemu. Since Qemu now only maintains the configuration and state of the device, but it no longer processes data, it’s best described as a device model rather than an active backend.
Kernel-based Vhost Architecture
Figure 4 below shows how the data and control planes change when we switch from a pure VirtIO configuration to a kernel-based vhost configuration for networking (compared to Figure 1 earlier).
In this example, we’re going to assume that the following optimizations are enabled:
ioeventfd: Avoids extra context switches between the kernel and userspace (Qemu) when notifying the backend of new Tx data.- Without it, we’d need to context switch to Qemu to handle the notification and then context switch back to the kernel to start processing the new Tx data.
- With it,
vhost-netis able to handle the notification directly and immediately start processing the data.
irqfd: Avoids an extra context switch from the kernel to userspace (Qemu) when notifying the guest of new Rx data.- Without it, we’d need to context switch to Qemu to handle the notification and then do a ring transition back to the kernel to inject the interrupt to the guest.
- With it, we’re able to stay in the kernel and set the interrupt as pending for the guest.

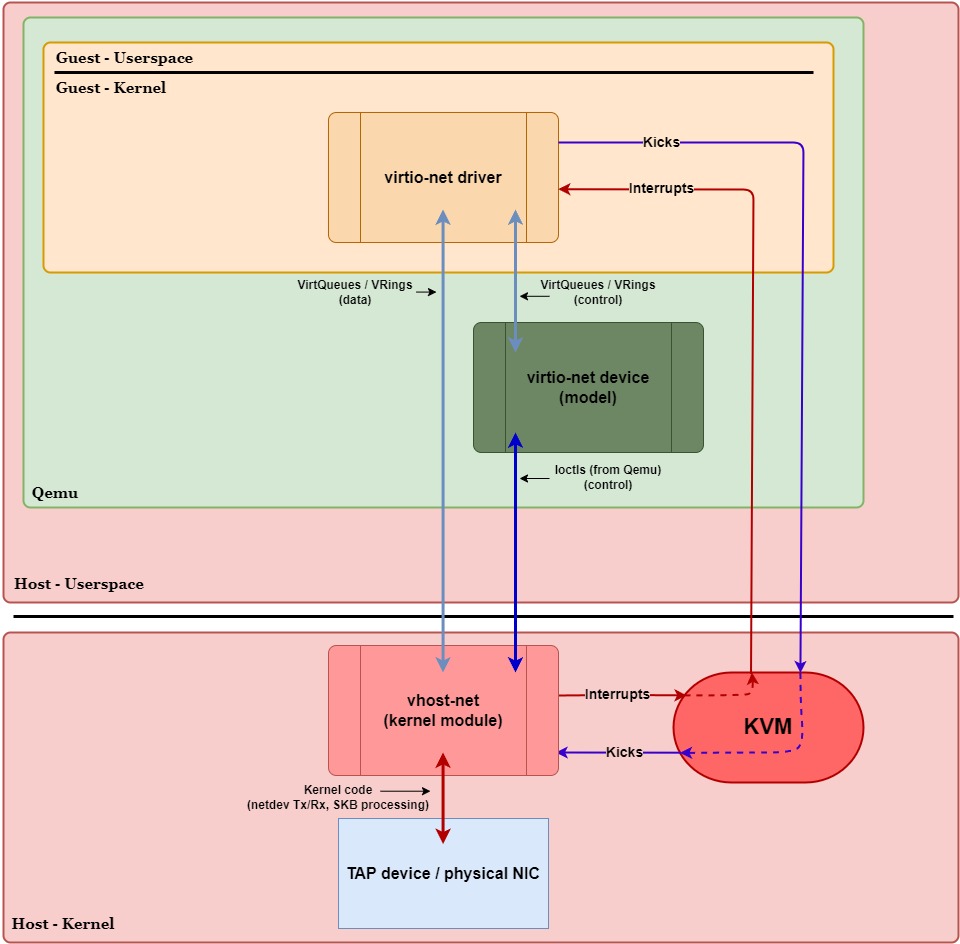
Overview:
First and foremost, we can see that the virtio-net device in Qemu has “stepped aside” to allow virtio-net’s data-plane VirtQueues to be shared directly between the driver and vhost-net in the kernel. Since the virtio-net device in Qemu no longer processes data, it’s now labeled as a device model. It’s only job now is related to control plane operations.
It’s also worth noting that, for control plane operations, the virtio-net device (model) in Qemu uses ioctl() calls to communicate with the vhost-net kernel module, e.g., ioctl(fd, VHOST_SET_MEM_TABLE, mem). These calls are meant to inform vhost-net of things like:
- Guest memory regions: which parts of guest memory hold the VirtQueues.
- VirtQueue configuration: addresses, sizes, and
eventfds (for interrupts & kicks) for each data-plane VirtQueue. - Feature / Offload configuration: enabling or disabling specific offloads (e.g., TSO, checksum offload) that the guest negotiated.
- Runtime changes & teardown: updating VRing addresses, starting/stoping VirtQueues, free resources during teardown, live migration management, etc.
Second, we can see that the notifications to the guest (interrupts) are no longer routed through Qemu in userspace, thanks to the irqfd optimization. Likewise, notifications from the guest (kicks) also no longer pass through Qemu in userspace, thanks to the ioeventfd optimization. Instead, they both stay within the host & guest kernel space. This change is significant because it eliminates context switches to and from Qemu during data-plane operations, effectively removing Qemu entirely from the data plane.
Lastly, we can see that the communication method between the backend (vhost-net) and the network device (TAP device / physical NIC) has changed. In a pure VirtIO configuration, the virtio-net device had to use syscalls to read, write, send, and receive packets through the TAP device / physical NIC. Now, with vhost-net operating in the kernel and having direct access to VirtQueues, we can take advantage of the kernel’s networking stack. This allows the kernel to efficiently handle data plane operations using its built-in optimizations, reducing overhead and improving performance.
Let’s now take a closer look at the execution paths for transmitting and receiving network packets in this kernel-based vhost networking configuration. Similar to Figure 2, Figure 5 below illustrates the transmit (purple circles) and receive (red squares) execution paths but for a vhost-net setup. We’ll walk through these paths step-by-step and highlight when a VM exit/entry or context switch occurs:

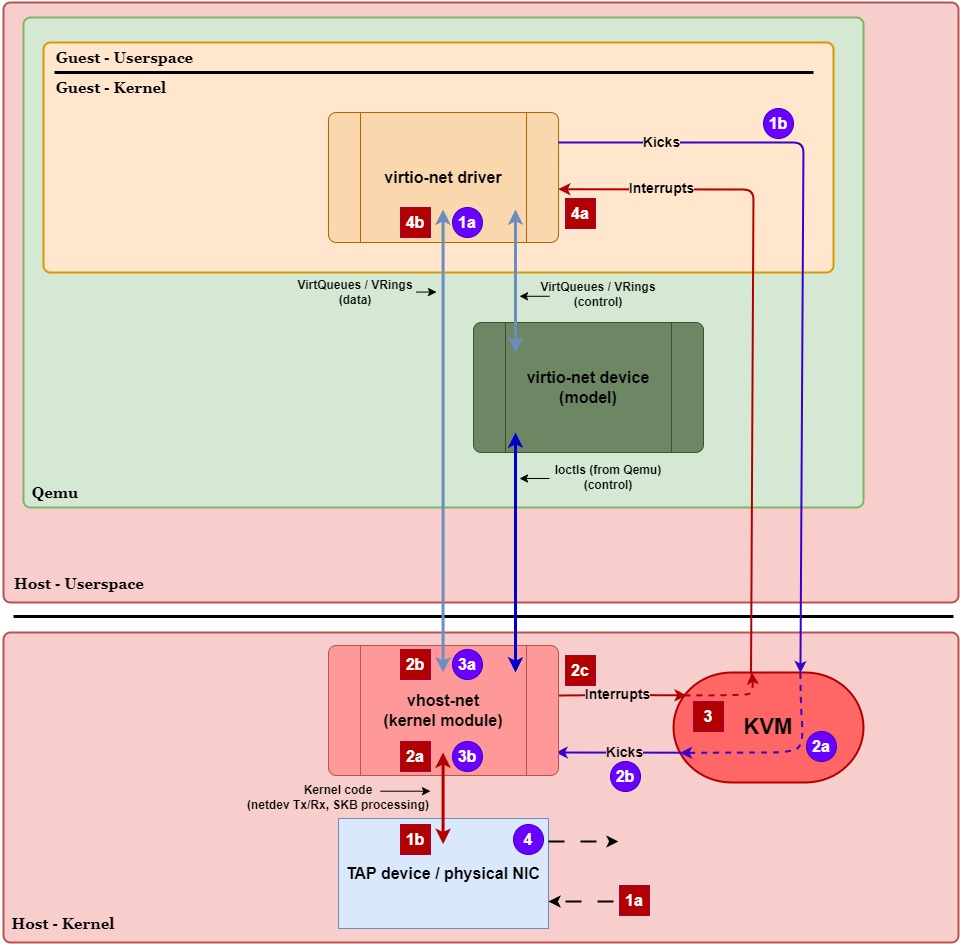
Transmit Path (Guest ⇨ Host):
- 1a.)
virtio-netdriver places data into thevirtio-netTx VirtQueue. - 1b.)
virtio-netdriver writes to the doorbell register to tell the host (KVM) to kickvhost-net.- VM Exit (Guest ⇨ Host Kernel) – Writing to the doorbell register causes the CPU to exit guest mode, trapping execution into KVM in the host kernel.
- 2a.) KVM intercepts the notification and sees the doorbell address is tied directly to an
eventfd. - 2b.) KVM immediately signals that
eventfdinside the kernel, effectively notifying and waking thevhost-netkernel thread immediately.- With
ioeventfd, we don’t need Qemu to send anioctl()to notifyvhost-net, avoiding costly context switches.
- With
- 3a.)
vhost-netdevice retrieves the data from thevirtio-netTx VirtQueue. - 3b.)
vhost-netcopies the data into an SKB (sk_buff) and hands it off to the host kernel’s networking stack (TAP device / physical NIC). - 4.) TAP / physical NIC transmits the packet out of the network.
- VM Entry (Host ⇨ Guest) – Execution eventually returns to the guest once the host has finished what it needed to do.
Receive Path (Host ⇨ Guest):
- 1a.] TAP / physical NIC receives data from the network.
- 1b.] TAP / physical NIC creates an SKB and queues the data in the host kernel’s networking stack.
- 2a.] Kernel networking stack routes the packet to
vhost-netby invoking its callback hook in the networking stack. - 2b.]
vhost-netcopies the data to thevirtio-netRx VirtQueue for the guest. - 2c.]
vhost-netwrites to theirqfd, notifying KVM that an interrupt needs to be delivered to the guest. - 3.] KVM marks the virtual interrupt as pending and waits for the guest to naturally VM exit before injecting it.
- Due to
irqfd, KVM does not immediately cause a VM exit to inject the interrupt and instead marks the interrupt as pending. - VM Exit (Guest ⇨ Host Kernel) – The guest naturally VM exits due to a periodic timer interrupt or some other event. When it does, KVM sees the pending interrupt.
- VM Entry (Host Kernel ⇨ Guest) – KVM injects the pending interrupt and the CPU to enters guest mode (resume the guest vCPU context).
- Due to
- 4a.] The guest sees the interrupt and is notified of the new data in the
virtio-netRx VirtQueue. - 4b.]
virtio-netdriver reads the data from the Rx VirtQueue and hands it up to the guest kernel’s networking stack.
In this example with vhost-net, we can see that neither the Tx nor Rx execution paths incur any context switches, thanks to the ioeventfd and irqfd optimizations. The only major source of overhead is the VM exits and VM entries we saw earlier in the pure VirtIO networking example. This is because the data plane stays inside the host’s kernel—avoiding unnecessary trips into Qemu when moving packets between the VirtQueues and the TAP device / physical NIC. This kernel-only data path is the main advantage of kernel-based vhost.
Overhead Cost:
For the Tx path, our main sources of overhead are:
- VM exit for KVM to handle the kick from the guest.
- Data copying by
vhost-netfrom the Tx VirtQueue into host kernel networking buffers (e.g., SKBs). - Host kernel networking stack processing to forward data to the NIC.
- The eventual VM entry back into the guest.
For the Rx path, our main sources of overhead are:
- Host kernel networking stack processing for getting data from the NIC and preparing it to be retrieved by
vhost-net. - Data copying by
vhost-netfrom host kernel networking buffers into the Rx VirtQueue. - VM exit for KVM to detect and inject the pending interrupt into the guest.
- VM entry to handle the interrupt and process the Rx VirtQueue in the guest.
Our approximate overhead cost equations for this kernel-based vhost networking configuration would look like the following (assuming only the ioeventfd and irqfd optimizations):


With these generalized equations, it’s clear to see how removing the userspace context switches and bypassing Qemu in the data path results in a significant reduction in overhead compared to the pure VirtIO setup, especially under high packet rates.
We also need to give credit to the ioeventfd and irqfd optimizations, which saves us the cost of a context switches in the Tx & Rx paths when we need to go to notify vhost-net or the guest.
Vhost-user Architecture
When describing the architecture of userspace-based vhost, things tend to get a bit more complicated. Kernel-based vhost typically appears simpler in design since most functionality is handled directly by the kernel, resulting in fewer moving parts. Of course, kernel-based vhost has its own complexities, but architecturally, it’s generally more straightforward and static.
In contrast, vhost-user has a more modular design, involving multiple layers and the flexibility to use different userspace backends—each with their own unique architectures, configurations, and host interactions. Examples of these userspace backends include:
- DPDK with Poll Mode Drivers (PMDs) for direct NIC access.
- Open vSwitch (OVS-DPDK) with high-performance userspace switching.
- SPDK for high-performance userspace storage processing.
In other words, vhost-user is more complex due to its wide range of possible configurations and the additional components involved.
However, even though there are many different kinds of configurations, there are several fundamental components that most vhost-user setups share:
- VirtQueues / VRings shared between the guest’s VirtIO driver and the userspace backend.
- Qemu is used for control-plane communication only. Control commands are sent via UNIX domain sockets using the
vhost-userprotocol. - A separate userspace process is used as the backend.
- Kicks and interrupts are routed through KVM.
In this document, we’ll look at one example of a vhost-user configuration: DPDK backend with direct NIC access via DPDK PMD. In this example, we’re also going to assume that the irqfd optimization is enabled to avoid context switch overhead associated with relying on Qemu when notifying the guest:

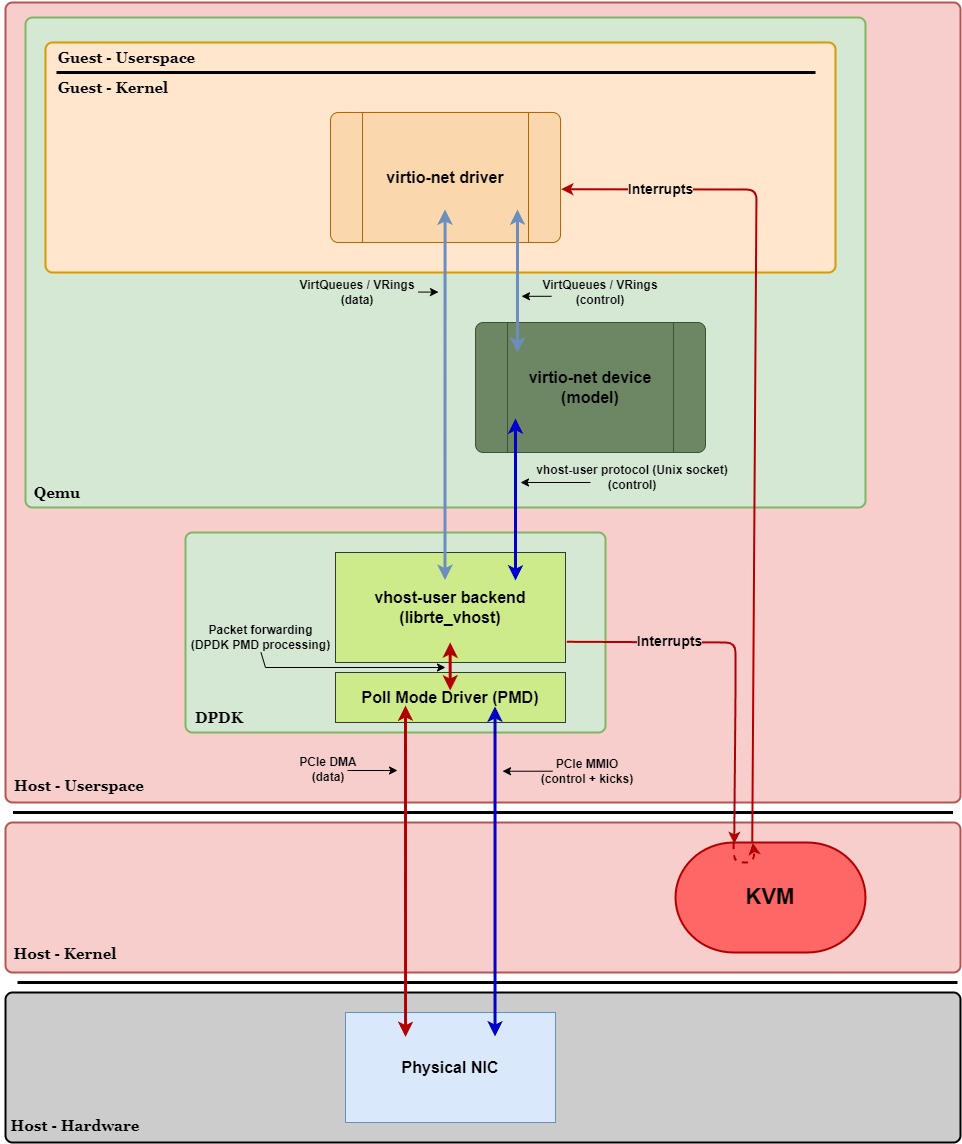
Overview:
In Figure 7, similar to kernel-based vhost, we see that the virtio-net device in Qemu has also “stepped aside” and turned into a virtio-net device (model). However, instead of having virtio-net’s data-plane VirtQueues shared with vhost-net in the kernel, they’re shared directly with a separate userspace process. In this example, it’s DPDK.
The device model’s role is still handling control plane operations, except now it communicates with the backend via a UNIX domain socket using Qemu’s vhost-user protocol. The control plane operations are similar to kernel-based vhost’s in the sense of initialization, setup tasks, runtime changes, and teardown for the backend. The main difference is the method of communication: ioctl() for kernel-based vhost and a UNIX domain socket for userspace-based vhost.
Now, let’s take a look at this DPDK userspace process block in Figure 7. Inside of this block we have two other blocks: vhost-user backend (librte_vhost) & Poll Mode Driver (PMD).
Vhost-user Backend (librte_vhost):
First, vhost-user backend (librte_vhost) is essentially DPDK’s “VirtIO adapter” and is the way in which DPDK is able to integrate with Qemu. In other words, it allows DPDK to handle VirtIO-related tasks such as initialization, runtime management, teardown, data processing (packet handling), and notifications. This is illustrated in Figure 7 above with the data VirtQueue / VRings and control commands arrows going to and from the backend.
The librte_vhost library is specifically part of DPDK’s userspace libraries. It provides the DPDK application with functions and APIs that it uses to interact with Qemu and manage its VirtIO operations. Without it, Qemu wouldn’t be able to offload its backend functionality into the DPDK process.
You can think of the DPDK process as your phone, librte_vhost as your phone’s Bluetooth adapter, and Qemu as your wireless headphones. Without the phone’s Bluetooth adapter, your wireless headphones wouldn’t be able to connect to your phone and allow audio to come out of them.
You’ll also notice, unlike the previous VirtIO configurations, the backend does not have the “kicks” notification arrow originating from the guest’s virtio-net driver. This is because DPDK has it’s Poll Mode Driver (PMD)—meaning the DPDK process is always active and thus does not need a kick to wake it up.
DPDK’s Poll Mode Driver (PMD):
DPDK’s Poll Mode Driver (PMD) essentially handles the data between the DPDK process itself and the physical NIC in hardware. That is, once DPDK (with the help of librte_vhost) retrieves the new Tx data from virtio-net’s Tx VirtQueue, it’s the PMD’s job to send that data directly to the NIC. Conversely, once the NIC has new Rx data for the guest, it’s the PMD’s job to retrieve and deliver that data to the guest (also with the help of librte_vhost) via virtio-net’s Rx VirtQueue.
One important thing to note here is that DPDK’s PMD continuously polls for:
- New Rx data from the NIC to forward to the guest.
- New Tx data coming from the guest to send out via the NIC.
Because of this constant polling, the virtio-net driver doesn’t need to kick DPDK for it to start processing the new Tx data, nor does the NIC need to explicitly notify DPDK of new incoming Rx data. The DPDK process is always awake and actively checking for new data in both directions. Thus, we eliminate the need for a context switch that would normally be incurred when attempting to wake up the process in userspace.
Also, notice how, unlike Figure 5 in kernel-based vhost, the backend (DPDK) bypasses the kernel networking stack entirely when transmitting or receiving data directly to and from the physical NIC. This is also important, as it’s one of the key advantages vhost-user (in this configuration) has not just over a pure VirtIO networking setup, but for kernel-based vhost networking setups as well.
Bypassing the Kernel Networking Stack:
In both the pure VirtIO (Figures 1 & 2) and kernel-based vhost (Figures 3 & 4) configurations, data still had to travel up and down the kernel networking stack, adding additional overhead and latency, which we labeled as Kernel_NetStack_Overhead in our overhead equations. However, one does not “simply” bypass the kernel networking stack. That is, bypassing the kernel networking stack comes with serious trade-offs, especially in regards to security and reliability (since the kernel was handling things like this before), and also for hardware support.
To bypass the kernel networking stack, the physical NIC must have specialized in-hardware Tx/Rx descriptor rings—VRings but actual, real, physical descriptor rings built into the NIC’s firmware. NICs that have this feature are typically high-performance, enterprise-class NICs, not generic onboard or consumer-grade NICs. Examples include Mellanox’s CX-5, Intel’s i40e, or Marvell’s ThunderX NICs. On top of that, each vendor has their own implementations of in-hardware Tx/Rx descriptor rings, meaning DPDK’s PMD must also have vendor-specific support for each NIC model.
Another trade-off also includes having to fully dedicate the physical NIC to the DPDK process to keep its PMD actively polling. In other words, we need to unbind it from the kernel, meaning the kernel will no longer see the NIC as a network device (and thus it cannot be used for other networking tasks). Workarounds for this like exist (such as SR-IOV or multi-queue NICs), but at the cost of added complexity to the setup.
DPDK’s Poll Mode Driver (PMD) – Continued:
Pivoting back to DPDK’s PMD, since we cannot exchange data with the physical NIC in hardware via the kernel, we need use a different method. The primary method that’s used is PCIe DMA (Direct Memory Access over PCI Express).
Essentially, it works like this:
- DPDK allocates large, contiguous blocks of hugepage memory in userspace.
- This memory region acts as shared memory (like a “mailbox”) between the NIC and the DPDK process.
- The NIC hardware uses PCIe DMA to directly access this userspace memory region, reading and writing packets and their descriptors without involving the CPU.
Since the NIC operates entirely within hardware space, it must use PCIe DMA to access this shared memory in userspace. And, as a bonus, since the hardware itself is actually doing the work, there’s no need for the CPU to be involved. This makes data transfers significantly faster compared to kernel-based vhost networking.
Additionally, DPDK’s PMD uses PCIe MMIO (Memory-Mapped I/O over PCI Express) for notifications and control operations (e.g., notifying the NIC about new Tx data). Lastly, there’s no equivalent “interrupt” coming from the NIC’s side since DPDK’s PMD is continuously polling for new Rx data, so it doesn’t need to be notified.
To simplify, we can summarize these mechanisms as:
- PCIe DMA – Efficiently moves data directly between hardware (NIC) and shared userspace memory without CPU involvement (hardware does the actual work).
- PCIe MMIO – Allows the userspace process (DPDK) to send control commands and notifications directly to hardware (NIC).
In this DPDK-based vhost-user example, we introduced several new concepts (PCIe DMA/MMIO, poll mode drivers, DPDK, hugepages, etc.), which can be overwhelming at first. To summarize clearly, these are the key points to understand about this vhost-user configuration:
- The backend is the DPDK userspace process:
librte_vhostis DPDK’s “VirtIO adapter” which helps it work with Qemu and perform VirtIO-related tasks.- Sends interrupts to the
virtio-netdriver when new Rx data arrives (viawrite()syscall to the guest’sirqfd). - DPDK’s PMD moves data between the VirtQueues and the physical NIC, continuously polling for new Tx data (from the guest) and Rx data (from the NIC in hardware).
- Continuous polling eliminates the need for kicks to the backend, avoiding context switches or VM exists associated with guest ⇨ backend notifications.
- Kernel networking stack bypass:
- DPDK’s PMD allows us to bypass the kernel networking stack and communicate directly with the NIC in hardware.
- Let’s hardware do a lot of the heavy lifting, no kernel networking stack overhead.
- Shared userspace memory:
- DPDK and the physical NIC in hardware share memory in userspace, using it as a “mailbox” to move data between userspace and hardware space.
- Physical NIC uses PCIe DMA to read/write to this shared memory in userspace.
- Interrupt optimization (
irqfd):- DPDK ⇨ guest interrupt overhead (on new Rx VirtQueue data) is minimized via
irqfd. - Similar to what we did with our vhost-net example earlier, we enabled
irqfdto avoid the context switch overhead we’d incur without it. - Without it, we’d have to wake up the Qemu process (context switch) and have it send an
ioctl()to KVM to notify the guest.
- DPDK ⇨ guest interrupt overhead (on new Rx VirtQueue data) is minimized via
Let’s take a closer look at the data plane execution path for transmitting and receiving packets to see when these context switches and VM exits/entries occur. In Figure 8 below, we have the same diagram as Figure 7 except now we’ve labeled the generalized steps in the transmit (purple circles) and receive (red squares) paths. Let’s walk through these paths step-by-step and highlight when a VM exit/entry or context switch occurs:

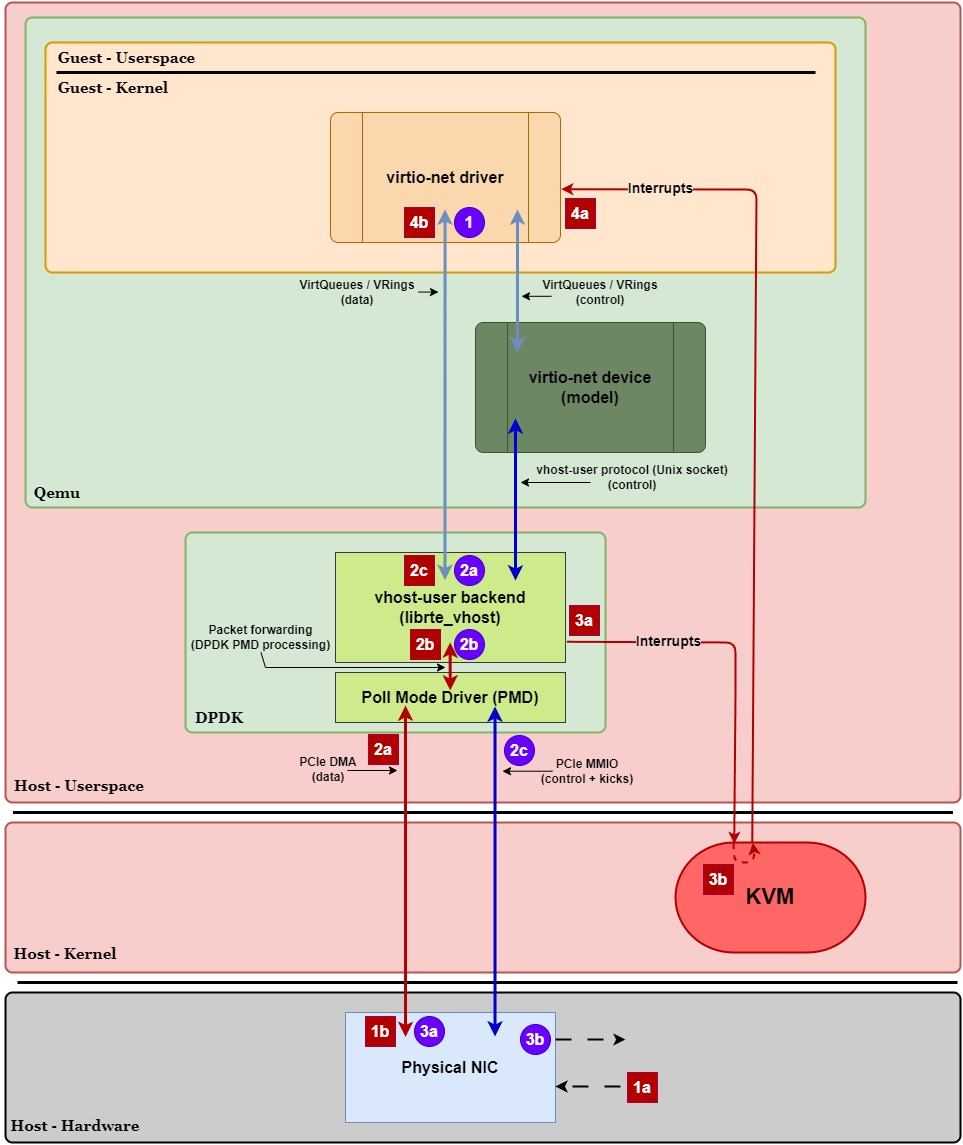
Transmit Path (Guest ⇨ NIC):
- 1.)
virtio-netdriver places data intovirtio-net’s Tx VirtQueue.- There’s no need to send a “kick” to DPDK since its PMD is actively polling for new data, avoiding a VM exit.
- 2a.) DPDK’s PMD is actively polling and sees the new data on the Tx VirtQueue.
- 2b.) DPDK’s PMD prepares the data for the physical NIC
- E.g., Tx buffer descriptor setup, copy packet data (if no zero-copy configured), update NIC’s Tx ring with packet data – all in shared hugepage memory.
- Allows physical NIC to properly access this data via PCIe DMA.
- 2c.) DPDK’s PMD kicks the physical NIC (via PCIe MMIO) in hardware to notify it of new Tx data.
- 3a.) NIC sees updated Tx HW ring and retrieves the new data in shared hugepage memory in userspace via PCIe DMA.
- 3b.) NIC transmits the data out of the network.
Receive Path (NIC ⇨ Guest):
- 1a.] Physical NIC receives data from the network.
- 1b.] NIC copies the data to the Rx ring in shared hugepage memory via PCIe DMA.
- 2a.] DPDK’s PMD is actively polling and sees the new data on the NIC’s Rx ring.
- 2b.] DPDK’s PMD prepares the Rx data in a format that VirtIO requires.
- 2c.] DPDK’s PMD copies the packet into
virtio-net’s Rx VirtQueue. - 3a.] DPDK writes to the
irqfd, notifying KVM that an interrupt needs to be delivered to the guest.- The syscall (
write()) is a ring transition from userspace (DPDK) to kernel space. - Not a context switch because the CPU remains in DPDK’s execution context while executing kernel code.
- DPDK’s PMD immediately returns to polling after the syscall.
- The syscall (
- 3b.] KVM marks the virtual interrupt as pending and waits for the guest to naturally VM exit before injecting it.
- Due to
irqfd, KVM does not immediately cause a VM exit to inject the interrupt and instead marks the interrupt as pending. - VM Exit (Guest ⇨ Host Kernel) – The guest naturally VM exits due to a periodic timer interrupt or some other event. When it does, KVM sees the pending interrupt.
- VM Entry (Host Kernel ⇨ Guest) – KVM injects the pending interrupt and the CPU to enters guest mode (resume the guest vCPU context).
- Due to
- 4a.]
virtio-netdriver receives the interrupt and is notified of the new data invirtio-net’s Rx VirtQueue. - 4b.]
virtio-netdriver reads the data from the Rx VirtQueue and hands it up to the guest kernel’s networking stack.
In this example with vhost-user—specifically a DPDK + DPDK PMD configuration with direct NIC access and irqfd enabled—there are no context switches that occur in either the Tx or Rx execution paths. The only major source of overhead lies within the Rx execution path, which incurs a VM exit & VM entry when handling the interrupt to the guest.
However, recall that with NAPI we can bring this incurred overhead down to near zero. NAPI operates by switching the guest’s driver into polling mode under high throughput, temporarily disabling interrupts. This means we’d no longer incur frequent VM exits/entries for Rx notifications. But it’s important to note that NAPI only shines under continuously high packet rates—at low or inconsistent rates, it re-enables interrupts to save CPU cycles.
In a consistently high-traffic scenario, we can see why this would outperform the kernel-based vhost networking configuration. Since the primary overhead (interrupt-induced VM exit/entry) would be minimized with NAPI, we’d be able to achieve ultra-low latency and ultimately better performance.
Overhead Cost:
For the Tx path, our main sources of overhead are:
- Data copied from Tx VirtQueue to shared hugepage memory.
- Overhead impact depends on packet size and CPU cache efficiency.
- PCIe MMIO notification to NIC.
For the Rx path, our main sources of overhead are (assuming no NAPI polling):
- Data copied from shared hugepage memory to Rx VirtQueue.
- Overhead impact depends on packet size & CPU cache efficiency.
- Interrupt signaling (
write()syscall toirqfd). - VM Exit + VM Entry for interrupt injection to guest.
Our approximate overhead cost equations for this vhost-user + DPDK + DPDK PMD configuration would look like the following:


With NAPI polling, and assuming consistently high Rx packet rates, we’d essentially eliminate the VM exit, VM entry, and signaling overhead. Technically it wouldn’t completely eliminate all of the VM exits and VM entries, some would still occur occasionally, but for the most part the data copying overhead would be more dominant in a consistently high throughput scenario:

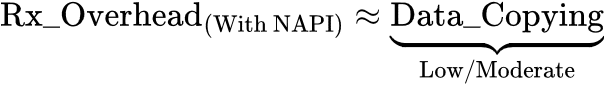
Vhost Summary
In this article, we’ve taken an in-depth look at how VirtIO’s data plane can experience significant overhead at high workloads due to Qemu’s involvement in it. We’ve explored how vhost solves these challenges by offloading data-plane processing to more efficient kernel-based or specialized userspace processes. Through diagrams and step-by-step walkthroughs, we’ve shown how overhead can differ between various configurations and how additional optimizations affect incurred overhead.
We’ve also created approximate overhead equations to further reinforce the impact each of our specific configurations has on performance. Figure 11 summarizes these equations in the table below.


It should be reiterated that these equations are not formal mathematical models intended for general application. They are simplified equations intended to illustrate and compare the major sources of overhead only between the simplified configurations discussed in this document.
And although our examples focused specifically on networking configurations, the key concepts and principles discussed here can be generally applied to other VirtIO device types, such as storage or virtual sockets. Keep in mind that specific device implementations may introduce slight variations in overhead and overall execution.
Terms & Definitions
Below is a list of key terms and definitions that you’ll want to know. Please use this section as a reference while reading this document.
Architecture Components
- Pure VirtIO – A VirtIO setup with a VirtIO driver in the guest and a fully-fledged VirtIO device implemented in Qemu, without vhost acceleration.
- This is the common VirtIO setup we saw in part 1, e.g., without vhost or any other type of acceleration.
- More precisely known as VMM-terminated VirtIO, where all data path operations are performed directly by the Virtual Machine Monitor (VMM) (Qemu).
- KVM (Kernel-based Virtual Machine) – A kernel module that enables hardware-assisted virtualization.
- Allows the kernel to function as a hypervisor and run VMs with near-native performance.
- Handles intercepting MMIO/PIO writes and injecting virtual interrupts (VIRQ) into the guest.
- Protocols – A formal set of rules and conventions that define how data is transmitted and received between devices, processes, or systems.
- Ensures different components (e.g.,
virtio-netdriver andvhost-net) can communicate in a structured and predictable way, regardless of implementation details. - Vhost protocol: Allows a guest VM to offload data processing to a backend running on the host. It establishes:
- How commands and responses are structured.
- How memory regions are shared.
- How event notifications are sent.
- Ensures different components (e.g.,
- DPDK (Data Plane Development Kit) – A set of libraries and drivers designed for high-performance packet processing in userspace applications.
- Allows fast packet processing by bypassing the kernel networking stack, using poll mode drivers (PMDs), and hardware acceleration (e.g., PCIe DMA) to significantly reduce processing overhead.
- Commonly used in cloud networking and telecommunications for achieving ultra-low-latency and high-throughput performance.
Optimizations
- Ioeventfd – An event notification mechanism that allows the guest to notify the backend (e.g., Qemu,
vhost-net, etc.) without involving a full round-trip to Qemu every time.- Optimizes guest ⇨ backend notifications (kicks).
- Guest writes to the doorbell register and triggers a VM exit, but instead of immediately context switching to Qemu to handle the kick, KVM directly signals an
eventfdin the host kernel and returns to guest execution (VM entry). - With kernel-based vhost, the
eventfdwakeup notifies the vhost thread immediately, and it can begin processing data as soon as it’s scheduled. - With
vhost-userscenarios, Qemu forwards theseeventfdnotifications to the separate userspace process and avoids extra overhead by not requiring Qemu to trap every doorbell write. - Also known as
kickfd.
- Irqfd – An event notification mechanism that allows the backend (e.g., Qemu,
vhost-net, etc.) to notify the guest more efficiently.- Optimizes backend ⇨ guest notifications (interrupts).
- Instead of Qemu issuing an
ioctl()to have KVM manually inject the interrupt to the guest, the backend writes to anirqfd(a specialeventfd) which KVM detects and marks the interrupt as pending for the guest. - A natural VM exit (e.g., via kernel timer interrupt, I/O request, etc.) must occur before the interrupt can be injected (hence it’s marked as a “pending” interrupt).
- Reduces extra processing by Qemu and KVM when the backend is notifying the guest of new data.
VIRTIO_F_EVENT_IDX– A feature in VirtIO that allows the guest to specify when it wants to receive an interrupt (instead of receiving one for every VirtQueue update).- The guest can specify an “event index” (a threshold value that tells the host when to notify the guest) such that the host will only send an interrupt when necessary, reducing the number of VM exits/entries when notifying the guest.
- NAPI (New API) – Kernel networking optimization that disables interrupts and switches to polling mode when packet rates are consistently high.
- Instead of waiting for interrupts, the
virtio-netdriver polls the Rx VirtQueue for new data. - Eliminates the VM exit + VM entry overhead since the driver doesn’t need to be notified.
- Re-enables interrupts when packet rates are low (to avoid wasting CPU cycles).
- The de-facto API for network device drivers.
- Instead of waiting for interrupts, the
- NUMA (Non-Uniform Memory Access) Pinning – Assigns (or “pins”) a process/VM to specific CPU cores and to the memory bank (NUMA node) closest to those cores.
- Broader than just CPU pinning – involves pinning both CPU and memory allocations to a specific NUMA node (more effective for memory-intensive and latency-sensitive applications).
- Reduces latency, improves cache efficiency, and optimizes memory bandwidth.
- Useful in virtualization where memory access patterns significantly impact performance.
- Zero-copying – A technique that avoids unnecessary memory copies in the data path by keeping data in the same memory region rather than copying it between buffers or separate memory locations.
- Enables direct access between guest memory and the host backend (requires memory pinning).
- Reduces CPU overhead, leading to lower latency and higher throughput.
- Not supported in a pure VirtIO configuration, only in vhost configurations.
- May require hardware and driver support.
Notifications
- Doorbell Register – A memory-mapped register (MMIO or PCI BAR) that the guest writes to when it wants to notify (kick) the backend.
- With pure VirtIO – guest writes to the doorbell register, which is processed directly by Qemu.
- With vhost – guest writes to the doorbell register, Qemu traps the write and signals the vhost backend via
eventfd. - The backend typically notifies the guest of completed processing via MSI-X interrupts or an
eventfd-based interrupt mechanism.
eventfd– A mechanism that provides a lightweight way to signal events between processes or the kernel & userspace.- Acts as a counter that’s incremented by writing to it and decremented by reading from it.
- Avoids frequent polling and unnecessary CPU overhead by providing an event-driven notification system.
- Qemu creates
eventfds and shares them with the kernel vhost driver or avhost-userprocess. - When the guest writes to a “doorbell register”, Qemu writes to the corresponding
eventfdto notify the backend of new data.
- Kicks – A notification from the guest to signal that it has placed new descriptors in a VirtQueue for the backend to process.
- Without vhost (pure VirtIO): Guest ⇨ Qemu kick, notifies the VirtIO device in Qemu that it needs to process its VirtQueue.
- With kernel-based vhost: Guest ⇨ Host kick, notifies the vhost device module in the host that it needs to process its VirtQueue.
- With vhost-user: Guest ⇨ Userspace process kick, notifies the userspace application (e.g., DPDK) that it needs to process its VirtQueue.
- Unless
ioeventfdis being used, kicks cause a VM exit to occur.
- Interrupts – A notification from the host to signal that it has placed new descriptors in a VirtQueue for the guest (e.g., the VirtIO driver) to process.
- Without vhost (pure VirtIO): Qemu ⇨ Guest interrupt.
- With kernel-based vhost: Host ⇨ Guest interrupt.
- With vhost-user: Userspace process ⇨ Guest interrupt.
- Unless the
VIRTIO_F_EVENT_IDXfeature, or NAPI, is enabled, every descriptor put in the VirtQueue will incur a VM exit + VM entry.
Overhead Sources
- Context Switch – When the host CPU switches from executing one process (or thread) to another.
- Each context switch involves:
- CPU saving the current process’ registers and execution state.
- CPU loading the incoming process’ registers and execution state.
- Potentially flush or invalidate caches (cache misses) and TLBs (Translation Lookaside Buffer).
- Significant source of overhead, especially in high-throughput scenarios or when it involves frequent cache misses & TLB flushes.
- Each context switch involves:
- Ring Transitions – When the host CPU switches between different privilege levels (rings) within the same execution context (process or virtual CPU).
- Often confused with context switches.
- Very low overhead compared to context switches.
- Key point: The process/thread does not change, only the privilege level.
- E.g., Qemu calls the syscall
ioctl(), the CPU then:- 1.) Jumps from Ring 3 (User) to Ring 0 (Kernel)
- 2.) Executes the kernel code.
- 3.) Returns back to Ring 3 when the syscall completes.
- VM Exit / Entry – When the host CPU transitions between guest execution and host execution, controlled by the hypervisor.
- A VM Exit occurs when the CPU stops executing guest code and transfers control to the hypervisor (e.g., KVM in the host kernel).
- A VM Entry occurs when the CPU resumes executing guest code and transfers control to the guest.
- Significant source of overhead, especially in high-throughput scenarios.
- Qemu Userspace Processing – When Qemu is part of the data path (no vhost), it’s responsible for moving packets between the guest and the host’s kernel networking stack.
- Introduces extra processing overhead, e.g., syscalls, memory copying, event loop delays, etc.
- Moderate source of overhead, becomes a significant bottleneck at higher packet rates (e.g., 500Kpps+).
- Kernel Networking Stack – A collection of subsystems in the Linux kernel responsible for handling network traffic.
- Processes incoming & outgoing packets, applies networking policies, and interacts with network interfaces (incl. physical NICs, TAP devices, and VirtIO devices).
- Low to moderate overhead, depends on factors like packet size, data rate, and the specific operations performed on each packet.