Accessibility Policy
Skip to content
Oracle
Oracle Linux Blog
Search
Exit Search Field
Clear Search Field
Menu
CATEGORIES
Oracle
Back
Oracle
Open Cloud Infrastructure
Oracle Linux
RELATED CONTENT
Hardware Cert. List
ISV Catalog
Developers
GitHub
Blogs Home
RSS
Oracle Linux Blog
Follow:
RSS
Facebook
Twitter
LinkedIn
YouTube
Instagram
4
Two Decades of Penguins: Oracle Linux turns 20
Greg Marsden
11 minute read
UEK 8.2 Delivers Advancements in Confidential Computing and System ...
Gursewak Sokhi
3 minute read
AI Assistant with Oracle Cloud Native Environment 2.3
Navya Rao
2 minute read
Oracle Linux 9.7 Now Generally Available
Gursewak Sokhi
4 minute read
Search Oracle Blogs
Search this site
Type your search term and press Enter.
Receive the latest blog updates
Subscribe to Oracle Linux and Virtualization email updates
Recent Posts
Inside Linux Packet Filtering: Netfilter and nftables
Shoily Rahman
15 minute read
Multipathing with Native NVMe Devices: What It is and Why It Matters
Rajan Shanmugavelu
7 minute read
A Novice’s Guide to Crafting a Linux Firewall with XDP and a ...
Partha Satapathy
19 minute read
A Novice’s Guide to Crafting a Linux Firewall with TC and ...
Partha Satapathy
13 minute read
Linux Memory Compaction: Internals and Debugging — Part 1: How ...
Imran Khan
50 minute read
Debugging Windows VirtIO: Live Logs, Crash Dumps, and Hangs
Annie Li
6 minute read
Why does my new XFS filesystem use so many blocks?
Mark Tinguely
20 minute read
Trace Kernel Function Return Values with trace-cmd
Jianfeng Wang
5 minute read
HugeTLB Gigantic Page Overcommit in Linux v6.19
Jane Chu
5 minute read
RPC transport-specific NFS mount options
Calum Mackay
6 minute read
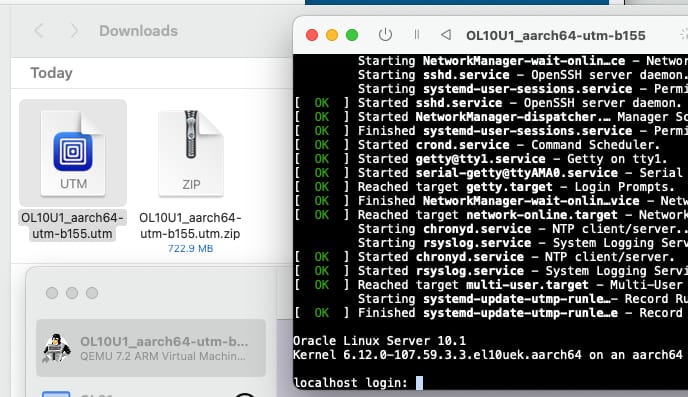
Oracle Linux on Apple Silicon with UTM
Greg Marsden
3 minute read
Recipes for Determinism: Helping Agents Follow Instructions
Greg Marsden
7 minute read
View more
Receive the latest blog updates
Subscribe to Oracle Linux and Virtualization email updates
Resources for
About
Careers
Developers
Investors
Partners
Startups
Why Oracle
Analyst Reports
Best CRM
Cloud Economics
Corporate Responsibility
Security Practices
Learn
What is Customer Service?
What is ERP?
What is Marketing Automation?
What is Procurement?
What is Talent Management?
What is VM?
What's New
Try Oracle Cloud Free Tier
Oracle Sustainability
Oracle COVID-19 Response
Oracle and SailGP
Oracle and Premier League
Oracle and Red Bull Racing Honda
Contact Us
US Sales 1.800.633.0738
How can we help?
Subscribe to Oracle Content
Try Oracle Cloud Free Tier
Events
News
© 2026 Oracle
Privacy
/
Do Not Sell My Info
Ad Choices
Careers