Announcing Exadata System Software 25ai
The Exadata Product Management and Engineering teams are thrilled to announce that Exadata System Software 25ai, release 25.2, is now available. It is the latest data-intelligent software powering Exadata on-premises and in the cloud. This release includes powerful new capabilities and extends Exadata’s leadership as the premier platform for Oracle Database. Here’s a summary of what’s in focus in this release:
- Accelerated AI Smart Scan
- Extreme performance
- Exascale innovations
- Superior security, manageability, and observability
Unique accelerated AI Smart Scan
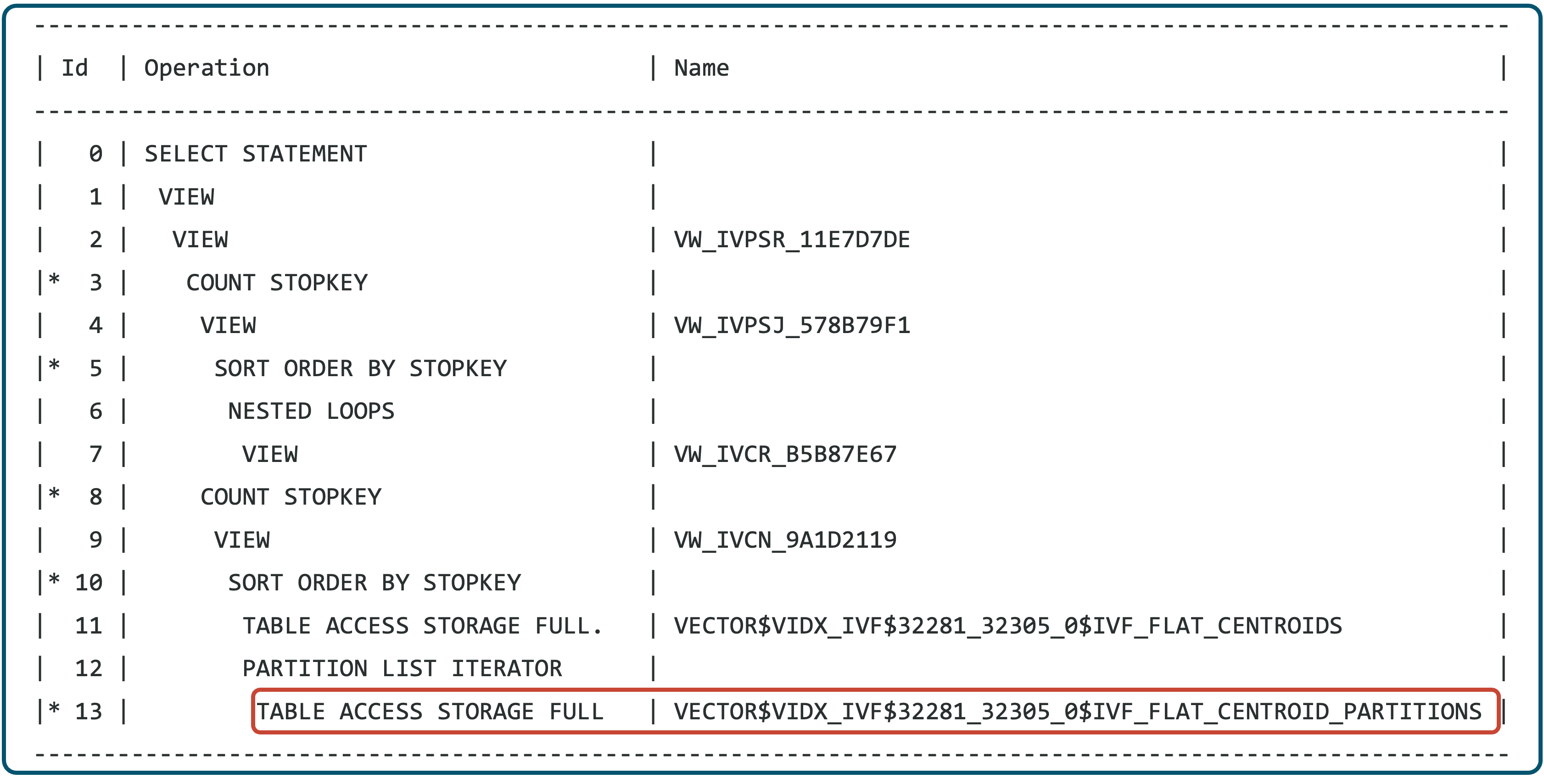
AI smart scans with neighbor partition vector indexes
Customers use AI Vector Search in Oracle Database 23ai on existing business data to make searches more contextual and relevant. For example, one might search for the top five houses most similar to a reference image of a house, as well as within a desired price range and at a particular location. With Oracle Database 23ai, all these attributes, including images of houses, could be stored as columns in the same table. Oracle Database enables creating a semantic representation of the image as a vector that encapsulates various attributes of the image and can then run a vector similarity search to find similar houses. Results can be filtered using relational attributes such as price and zip code to generate the top 5 desired houses.
For example, a query on the houses table that contains the vector representation of each house, along with the price and zipcode columns, could be written like this:
SELECT price FROM houses t
WHERE price < 2000000 AND zipcode = 94065
ORDER BY VECTOR_DISTANCE(description_vector, :query_vector)
FETCH APPROX FIRST 5 ROWS ONLY;Since the initial release of AI Vector Search, Oracle Database 23ai has supported indices on vector data to accelerate similarity searches. Oracle Database 23.7 optimizes vector search further by enabling the inclusion of non-vector columns within Neighbor Partition Vector Indexes (IVF indexes). Including these columns lets the database skip secondary ROWID-based lookups, reducing I/O, and speeding up the search. Continuing our example above, the Neighbor Partition Vector Index may now be created to include not only the vector used to determine similarity to the house image, but also the price and zipcode columns stored in the same table. For example, the index definition might be:
CREATE VECTOR INDEX house_idx ON houses(description_vector)
INCLUDE (price, zipcode)
ORGANIZATION NEIGHBOR PARTITIONS; With Exadata System Software 25.2, when the index contains all columns required for a query as included columns, data can be retrieved directly from the index, accelerating query performance. In addition, the filtering operation on price and zipcode is offloaded, along with the vector distance, in a highly parallelized manner to the storage servers, using only the vector index. This accelerates AI Vector Search queries by up to 3x compared to previous database releases.
Accelerating queries on sparse vector datatypes
AI Vector Search often utilizes space-efficient SPARSE vectors, which typically have a large number of dimensions but with only a few non-zero dimension values. These vectors are created using encoding models such as SPLADE or BM25 and generally outperform other vectors in keyword-based searches. Each dimension of a sparse vector corresponds to a keyword in a certain vocabulary. For each occurrence of a keyword in the document, its corresponding dimension receives a non-zero value. This value shows both the presence and frequency of the keyword in the document. Sparse vectors are very space-efficient because only the non-zero values are stored.
For example, the following example shows the creation of a table with sparse vector (incident_text) into which an insert shows the dimension positions a non-zero value will be specified:

With this new release, Oracle Database 23.7 seamlessly offloads the vector distance calculation of sparse vectors to accelerate queries.
Extreme performance
Unique optimization of Flash Cache for temporary data
Analytic queries use temporary (temp) data for joins, sorts, and aggregations, and this data is often written to flash.
Starting with Exadata System Software 25.2 and Oracle Database 23ai, Exadata uniquely reclaims the flash space that was occupied by prior temp I/O writes, without persisting this data to hard disk. This instant flash reuse capability eliminates hard disk writes and ensures efficient temp data caching, even as query workloads scale across many RAC instances and databases. As a result, analytics queries are up to 1.6x faster.
Delivering high I/O performance after storage server maintenance
Exadata automatically caches data in Flash Cache on multiple storage servers simultaneously for high availability. After maintenance, such as software updates or hardware replacement, the storage server, including the flash, must be resynchronized with other storage servers, and any additions to the working data set must be cached in flash (rewarmed). If a database query requests data from flash that has not yet been rewarmed, the storage server automatically repopulates the flash from disk.
With Exadata System Software 25.2 and Oracle Database 23ai, when a read from flash results in a flash miss and that flash has not been fully rewarmed, instead of reading from disk, the storage server attempts to fetch the data from the flash of the partner storage server. When the flash has been rewarmed, remote reads are no longer needed. Reading and transferring data from flash on a remote storage server is much faster than reading from local disks, ensuring consistently high performance before and after storage server downtime.
Prioritizing critical large writes for faster SQL
Smart Flash Cache plays a crucial role in delivering high performance for analytics, AI, and mission-critical workloads. With Exadata System Software 25.2, Exadata automatically prioritizes temporary I/O and flashback log writes above other types of large write I/O, such as I/O related to ASM resync and rebalance operations. This ensures active database queries are always given the highest priority access to Flash Cache resources. Other large writes are cached only if there is available flash capacity.
Exascale innovations
Exadata Exascale is the world’s only intelligent data architecture for the cloud. Exascale is a revolutionary leap that combines the best of Exadata and the best of the cloud. This next-generation, hyper-elastic, multi-tenant software architecture is designed to handle AI, analytics, mission-critical, JSON, and mixed Oracle Database workloads.
Exascale reimagines how compute and storage resources are managed on Exadata platforms by decoupling and simplifying storage management, paving the way for innovative new capabilities such as its reimagined, space-efficient approach to database snapshots and thin clones from any read/write database or pluggable database, and Exascale volumes, RDMA-enabled storage for virtual machines and filesystems such as ACFS. Exascale ensures industry-leading database performance, availability, and security standards that organizations expect from Exadata.
With Exadata System Software 25.2, Exascale has been further optimized to improve data durability, deliver intelligent storage pool free space management, and simplify virtual machine volume management and snapshots.
Unique rebuild with delta tracking to improve durability
Exascale protects your data at all times. By default, Exascale mirrors every file extent three times, placing each copy on a different disk and on a different storage server. This high-redundancy configuration protects your data even if a disk goes offline. In the event a disk goes offline, the Exascale delta tracking capability automatically writes changes for such offline disks to another disk, maintaining three copies at all times. When a disk returns to an online state, the system quickly applies the deltas to resync data.
Importantly, delta tracking writes only the individual database blocks that are modified. This means that storage used during delta tracking is typically very low. When disks are resynchronized, only the modified blocks in an extent need to be updated, not the entire 8 MB extent.
When a disk fails, Exascale takes two actions simultaneously to ensure high availability and data durability:
- New writes are tracked as deltas on the remaining online disks
- The system immediately begins rebuilding data redundancy on other available disks
If the failed disk is brought back online, Exascale automatically applies the deltas to quickly restore redundancy. Because Exascale takes these same two actions whenever a disk fails or is taken offline, the system can restore all data by bringing any failed disk online, even if multiple disks fail. This innovative approach improves data durability, even in the rare conditions when multiple disks fail, for example, due to firmware issues. Instead of being forced to revive the last failed disk to recover data, if any of the failed disks are revived, database blocks can be recovered from the delta tracking data.
Intelligent Exascale storage pool free space management
An Exascale storage pool must have enough free space to rebuild redundancy successfully if a disk fails. Starting with Exadata System Software 25.2, if available free space drops below the threshold, Exascale issues an alert like this:
Storage pool '<storage-pool-name>' has <X GB> of free space, but <Y GB> is required to rebuild redundancy if a disk fails.
This allows the administrator to take appropriate action, such as removing old files and freeing space so rebuilds can proceed.
In addition, if a disk fails while free space is low, Exascale pauses the rebalance action until enough space is freed, typically by deleting unnecessary files. Once enough free space is available, the rebalance process is automatically resumed.
Exascale virtual machine management
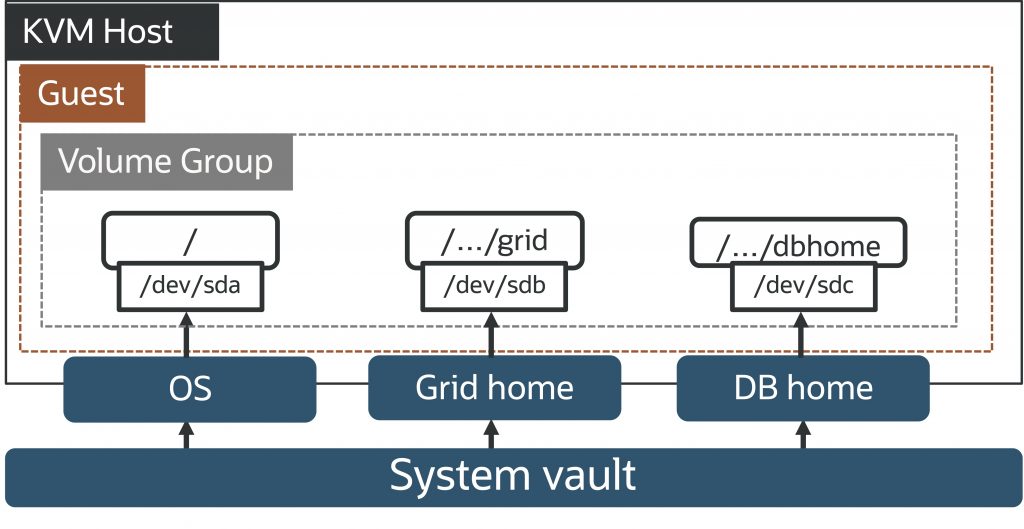
Exascale adds a powerful new capability to Exadata: using RDMA-enabled volumes on shared storage servers for database virtual machine (VM) images. By moving VM images from local storage to shared Exascale, customers have much more space available for VM images and can consolidate up to 50 VMs per KVM host on Exadata X10M and newer database servers and create additional or larger Linux filesystems in the VM image.
Volume group across volumes of a virtual machine
Volumes are Exascale files that can be attached to VMs and database servers as block devices via the RDMA-optimized Exascale Direct Volume (EDV) protocol.
Customers can now group Exascale volumes attached to a VM into a Volume Group to simplify management operations on that VM.
To create a volume group, run the escli mkvolumegroup command:
@> mkvolumegroup VolGroup
Created volume group with id volgrp0001_7797373fc4da4fefaa75c663bee932d7Then, add volumes to the group.
@> chvolumegroup volgrp0001_7797373fc4da4fefaa75c663bee932d7 --attributes volumes=+vol0108_3435ec82b67347479ac65108745bcdaf
@> chvolumegroup volgrp0001_7797373fc4da4fefaa75c663bee932d7 --attributes volumes=+vol0109_919f59aa8b1546959afea6c5f8f264e2
@> chvolumegroup volgrp0001_7797373fc4da4fefaa75c663bee932d7 --attributes volumes=+vol0110_a5f6bd18fa674d2c814626f9d575adcdUnique point-in-time consistent snapshot across related volumes
The ability to create volume groups enables the creation of point-in-time, consistent snapshots of all the volumes in the volume group. These snapshots can be used to create backups or thin clones easily for all the volumes, instead of volume-by-volume snapshots that are not consistent with one another.
To create a volume snapshot, add three volumes to your VolGroup as shown in the previous example.
@> lsvolume --filter volumeGroup=volgrp0001_7797373fc4da4fefaa75c663bee932d7 --attributes id,name,vault
id name vault
vol0108_3435ec82b67347479ac65108745bcdaf vol108 @vm08acfs
vol0109_919f59aa8b1546959afea6c5f8f264e2 vol109 @vm08acfs
vol0110_a5f6bd18fa674d2c814626f9d575adcd vol110 @vm08acfsYou can now take a consistent snapshot of all three volumes at the same time using the mkvolumegroupsnapshot command.
@> mkvolumegroupsnapshot volgrp0001_7797373fc4da4fefaa75c663bee932d7
Created volume group snapshot with id 1:7797373fc4da4fefaa75c663bee932d7_20250627T144849Listing the volume snapshots with the filter for the volume group snapshot above will show that all three volumes now have a snapshot.
@> lsvolumesnapshot --filter volumeGroupSnapshot="1:7797373fc4da4fefaa75c663bee932d7_20250627T144849"
id name
vol0108_3435ec82b67347479ac65108745bcdaf OS
vol0109_919f59aa8b1546959afea6c5f8f264e2 DB_HOME
vol0110_a5f6bd18fa674d2c814626f9d575adcd GI_HOMEJSON output for XSH
The Exascale Shell (XSH) is a useful utility to interact with Exascale storage from the database VMs. It provides a simple interface to view and change file properties and attributes and create and manipulate files stored in Exascale with commands like ls, dd, mv, and touch.
To enable better integration with common automation utilities, XSH is now able to produce output in JSON format by adding the –json switch. For example, xsh ls –detail –json command will provide detailed output of the xsh ls command in JSON.
# xsh ls --detail --json @exadpmvault/…/CDB1/…/DATAFILE/SYSTEM.OMF.60749038
{ "Result" :
{ "Output" : [
{
"name" : "@exadpmvault/…/CDB1/…/DATAFILE/SYSTEM.OMF.60749038",
"usedBy" : "82b1ca80638e4f86bf2e4b3eabc7b6e7:cdb1",
"blockSize" : 8192,
"fileType" : "DATAFILE",
"redundancy" : "high",
"contentType" : "DATA",
"media" : "HC"
}
],
"ErrorCode" : 0,
"errorMsg" : ""
}, …
}Secure, elastic, and observable infrastructure
SELinux is enabled by default
Data security remains a top priority in today’s rapidly evolving threat landscape. Security-Enhanced Linux (SELinux) is a Linux security module that enforces mandatory access controls to minimize the risk of unauthorized actions or damage if the system is compromised.
With Exadata System Software 25.2, SELinux is now enabled by default for new Exadata deployments. Pre-built Oracle Database and Exadata-specific SELinux policies eliminate the need for time-consuming creation, training, and reconfiguration, allowing customers to quickly strengthen their security posture without the burden of building policies from scratch.
By default, SELinux operates in permissive mode, recording any actions that would be blocked by security policies without interrupting your workload. This provides valuable visibility into potential security issues while ensuring operational continuity. Customers can further tailor their security by creating custom policies for 3rd party or environment-specific software. Monitoring policy violations is achieved using standard SELinux tools, making it easy to integrate with existing security monitoring and management tools and applications.
Optimized Linux increases security
Exadata uses an optimized Oracle Linux operating system with only the packages needed for Oracle Database. With Exadata System Software 25.2, Oracle continues to minimize the potential attack surface for malicious software or bad actors by further simplifying package dependencies. At the same time, Oracle continues to offer a repository of additional packages, allowing customers to install packages needed for specific requirements or third-party dependencies.
Elastic OEDA enables greater deployment flexibility
The Oracle Exadata Deployment Assistant (OEDA) has been significantly improved in this release. Starting with the March 2025 release of OEDA, you can more easily model and deploy infrastructure that matches your Exadata deployment. For example, the image below shows a single rack configuration with a mix of X9M, X10M, and X11M database servers, along with X9M Extreme Flash, X9M High Capacity, and X11M High Capacity storage servers.

With the latest OEDA, this more flexible, elastic approach gives you greater control and deployment agility, especially as more customers use Exascale to benefit from advanced capabilities, including storage pooling, volumes, and database snapshot and clone capabilities.
Unique highlighting of top smart scan SQL statements enhances observability
Smart Scan, a core capability of Exadata, reads data cached in ultra-fast flash and RDMA-enabled memory (XRMEM) to accelerate analytic and AI queries. This multi-tier caching strategy has been a mainstay of Exadata and enables up to 100 GB/s flash SQL scan throughput, as achieved with X11M.
CellSQLStat is a new utility that can be run on any storage server, which provides insight into how smart scan queries use flash, XRMEM, and other resources in real time in that storage server. This utility shows CPU and memory consumption, storage index, and columnar cache savings, Flash Cache, and XRMEM hits, and instantaneous scan rate. CellSQLStat is automatically included in ExaWatcher, ensuring that useful SQL-level statistics are available alongside OS and other data for historical analysis and simplifying data collection for Oracle support.
Final thoughts
Exadata System Software 25ai, release 25.2, delivers significant innovations, including the following:
- Accelerated AI Vector Search: Delivers faster AI smart scans by including non-vector columns in neighbor partition vector indexes and supporting sparse vectors.
- Extreme performance: Provides Flash Cache optimizations, prioritized I/O, and seamless high availability after storage maintenance.
- Exascale innovations: Improves data durability with delta tracking and smarter free space management, enables point-in-time volume group snapshots, and streamlines VM volume management.
- Superior security, manageability, and observability: Increases security by enabling SELinux by default; reduces the attack surface with an optimized Oracle Linux operating system; provides JSON output support in Exascale Shell (XSH) and expands deployment options with elastic Oracle Exadata Deployment Assistant (OEDA).
Together, these features ensure Exadata remains the best platform for Oracle Database workloads, delivering performance, scalability, availability, agility, and protection for mission-critical environments.
For more details, consult the Exadata documentation and download Exadata System Software 25ai from My Oracle Support.


