Accessibility Policy
Skip to content
Oracle
Exadata Database Machine
Search
Exit Search Field
Clear Search Field
Menu
CATEGORIES
Exadata Product & Ecosystem
Exadata Technical Series
Exascale
Exadata Updates
Blogs Home
RSS
Exadata Database Machine
Follow:
RSS
Facebook
Twitter
LinkedIn
YouTube
Instagram
4
Announcing Exadata System Software 26ai, release 26.1!
Alex Blyth
11 minute read
Exadata in 2025: Innovations and Insights Across the Product Family
Alex Blyth
12 minute read
Announcing Exadata System Software 25ai Release 25.2
Alex Blyth
Chris Craft
Ashish Ray
12 minute read
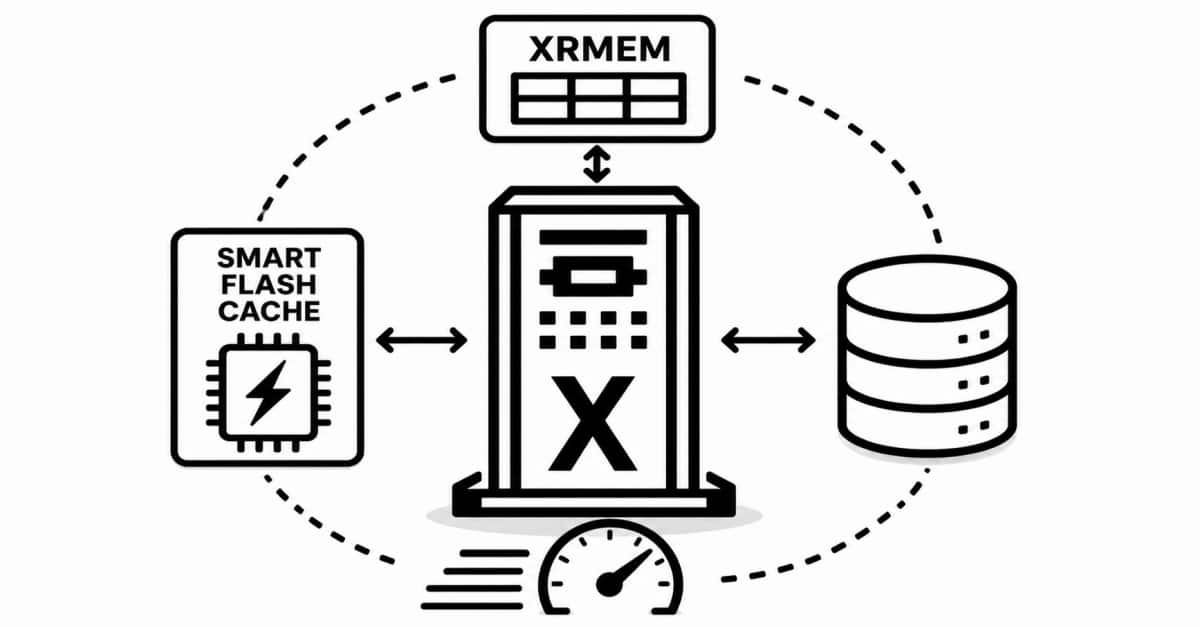
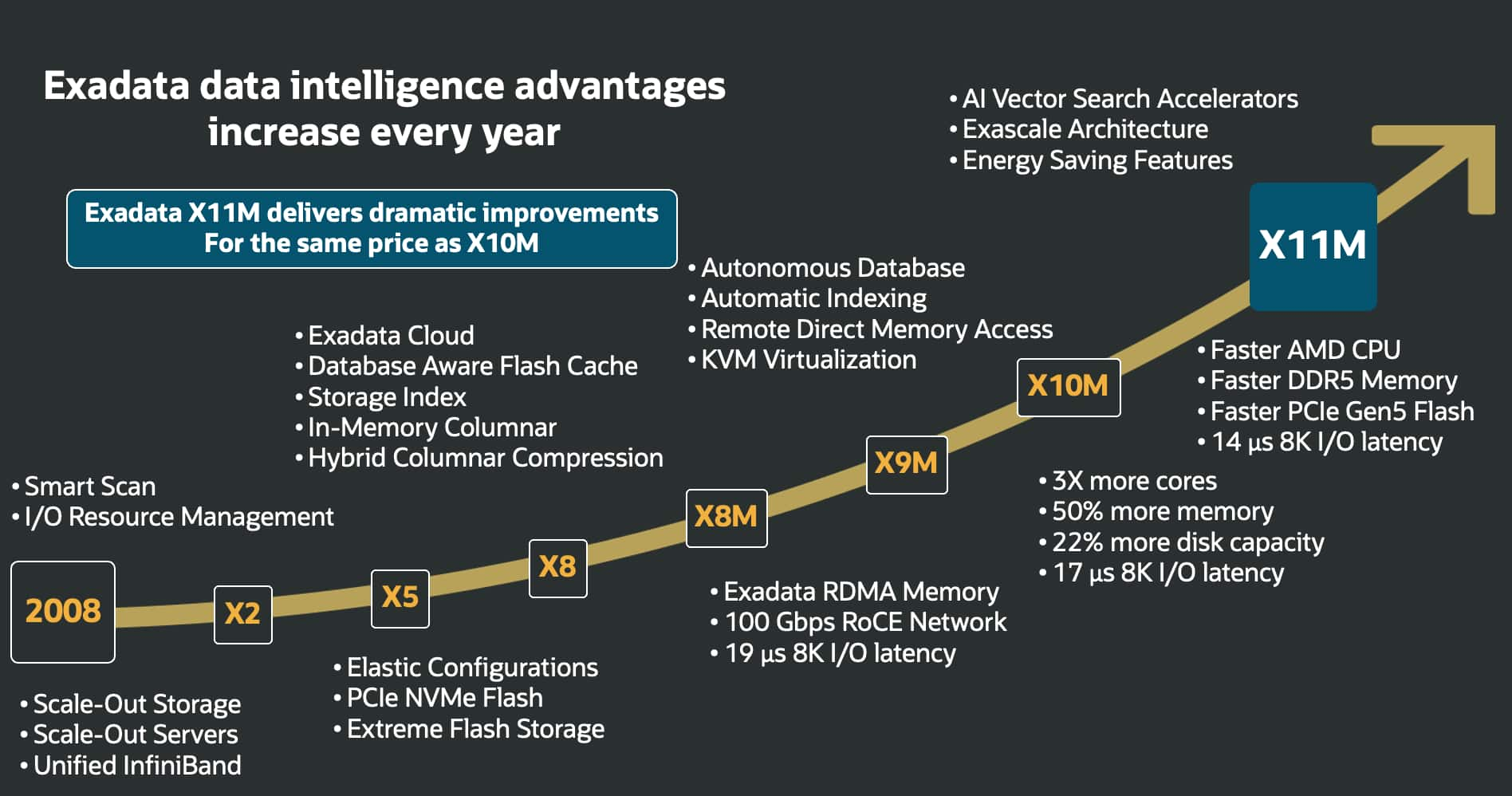
Introducing Exadata X11M: Next Generation Intelligent Data ...
Alex Blyth
Chris Craft
Ashish Ray
11 minute read
Search Oracle Blogs
Search this site
Type your search term and press Enter.
Receive the latest blog updates
Subscribe to Oracle Connect email updates
Exadata Product & Ecosystem
See all
Announcing Oracle Exadata X11 Storage Servers and Zero Data Loss ...
Bob Thome
Tim Chien
Alex Blyth
7 minute read
Exadata Continues to Drive Exceptional Value for Oracle Database ...
Bob Thome
7 minute read
Announcing Exadata System Software 26ai, release 26.1!
Alex Blyth
11 minute read
Modern Oracle Database Workloads Need More Than General-Purpose ...
Natarajan Shankar
9 minute read
Oracle Exadata: 18 Years of Innovation for Mission Critical Workloads
Bob Thome
8 minute read
Exadata in 2025: Innovations and Insights Across the Product Family
Alex Blyth
12 minute read
Exadata and Recovery Appliance help Customers align with Digital ...
Maruti Sharma
13 minute read
Oracle Database In-Memory and Exadata are meant for Agentic AI ...
Alex Blyth
Nathan Fuzi
9 minute read
Exadata Technical Series
See all
How to Maintain a Strong Exadata Security Posture as AI-Enabled Cyber ...
Natarajan Shankar
2 minute read
Advanced Intrusion Detection Environment (AIDE) enhances Exadata ...
Natarajan Shankar
2 minute read
Sizing Database SGA for Migration to Exadata
Chris Craft
7 minute read
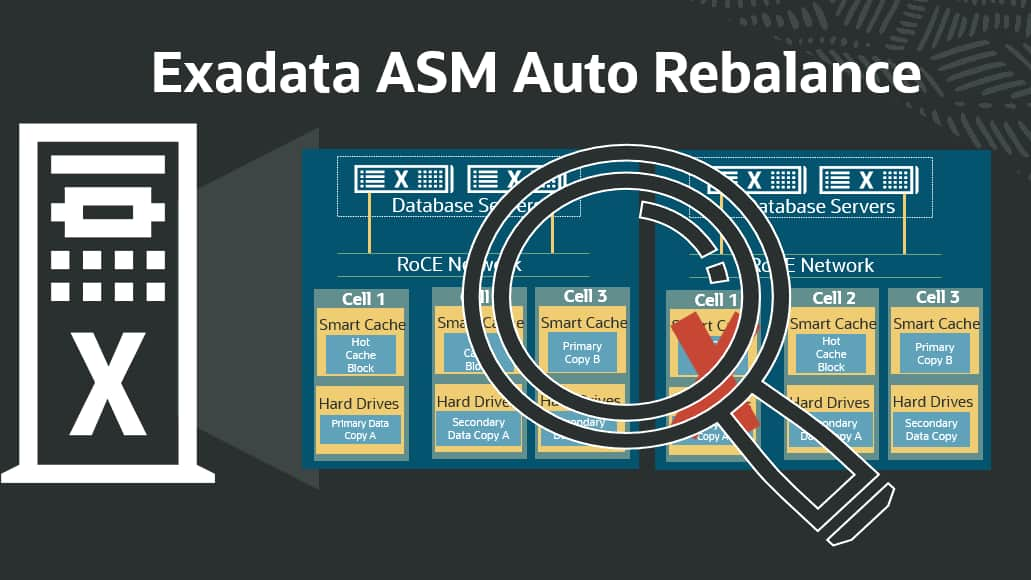
Exadata and ASM Auto Rebalance
Maruti Sharma
10 minute read
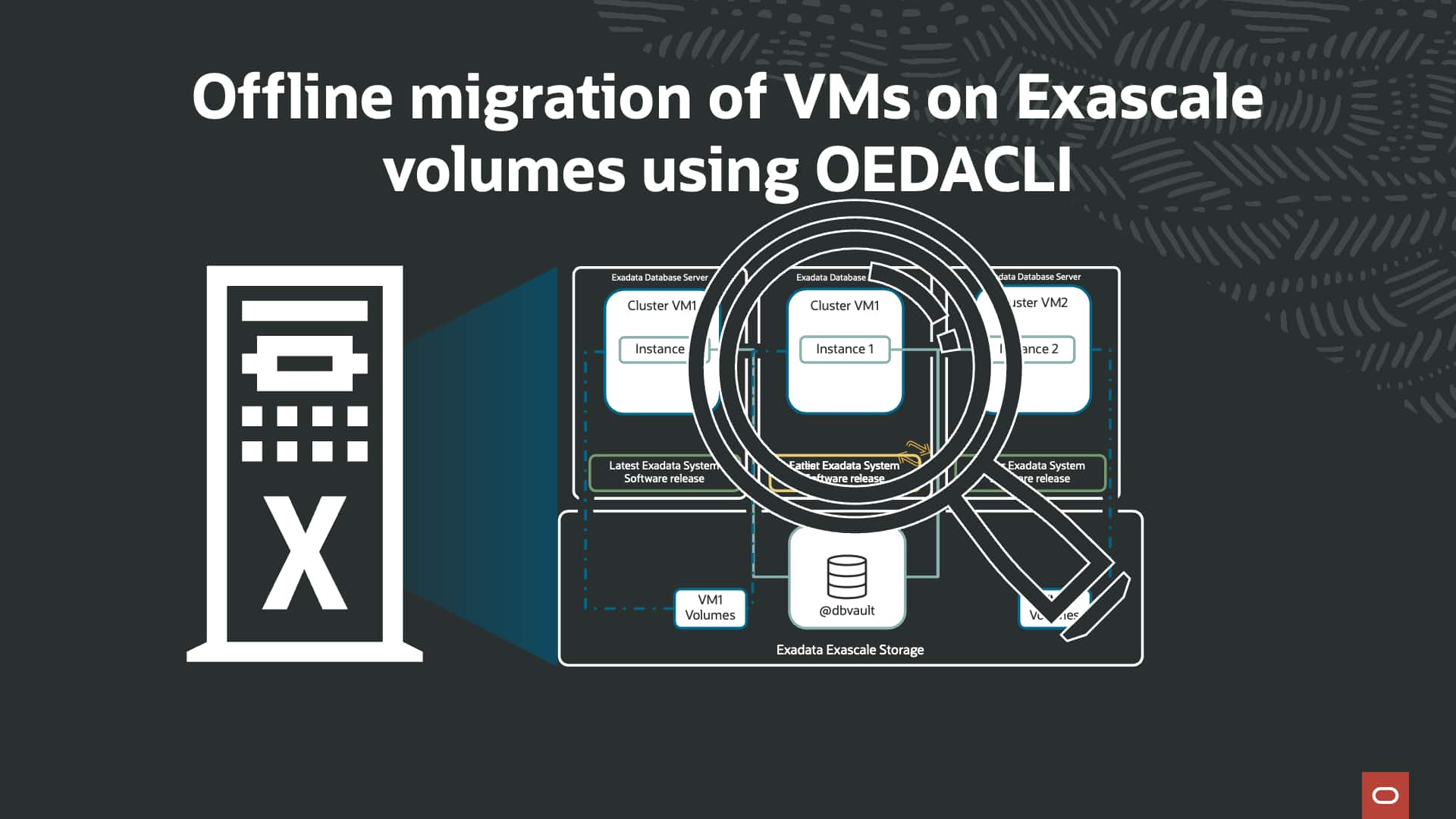
Using OEDACLI for offline migration of Exadata VMs between KVM hosts
Alex Blyth
7 minute read
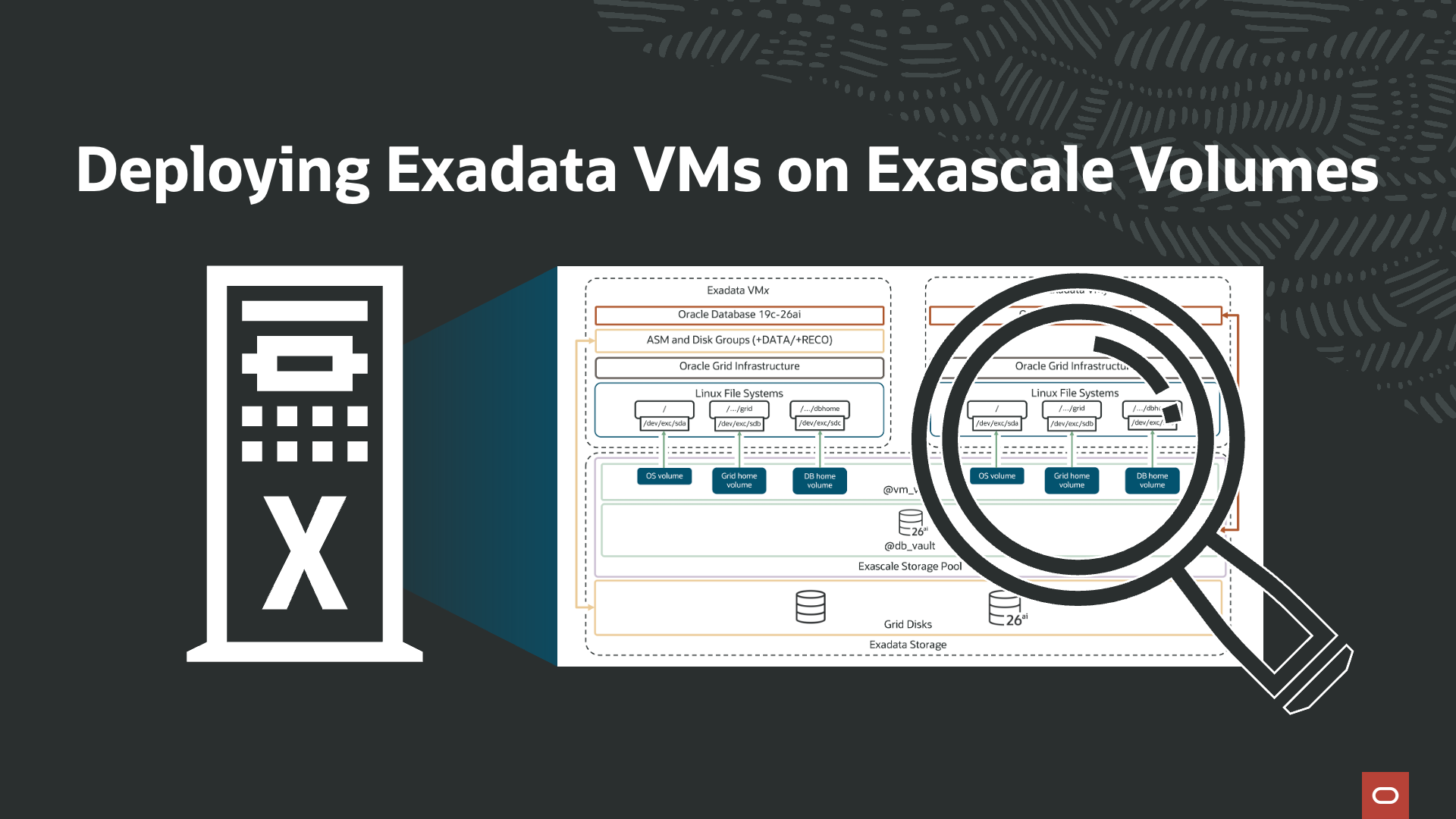
Deploying VMs on Exadata with Exascale volumes
Peter Fusek
Alex Blyth
6 minute read
Monitoring Oracle Exadata MOS Notes
Alex Blyth
3 minute read
Exadata Software Update: Tips and Best Practices
Natarajan Shankar
13 minute read
Exascale
See all
Exascale Snapshots and Clones: Core Concepts
Alex Blyth
8 minute read
Exadata Exascale – Why Database Cloning Needed Reimagining
Alex Blyth
7 minute read
Adding a Shared ACFS Filesystem to an Existing Exadata VM Cluster ...
Alex Blyth
9 minute read
Using OEDACLI for offline migration of Exadata VMs between KVM hosts
Alex Blyth
7 minute read
Deploying VMs on Exadata with Exascale volumes
Peter Fusek
Alex Blyth
6 minute read
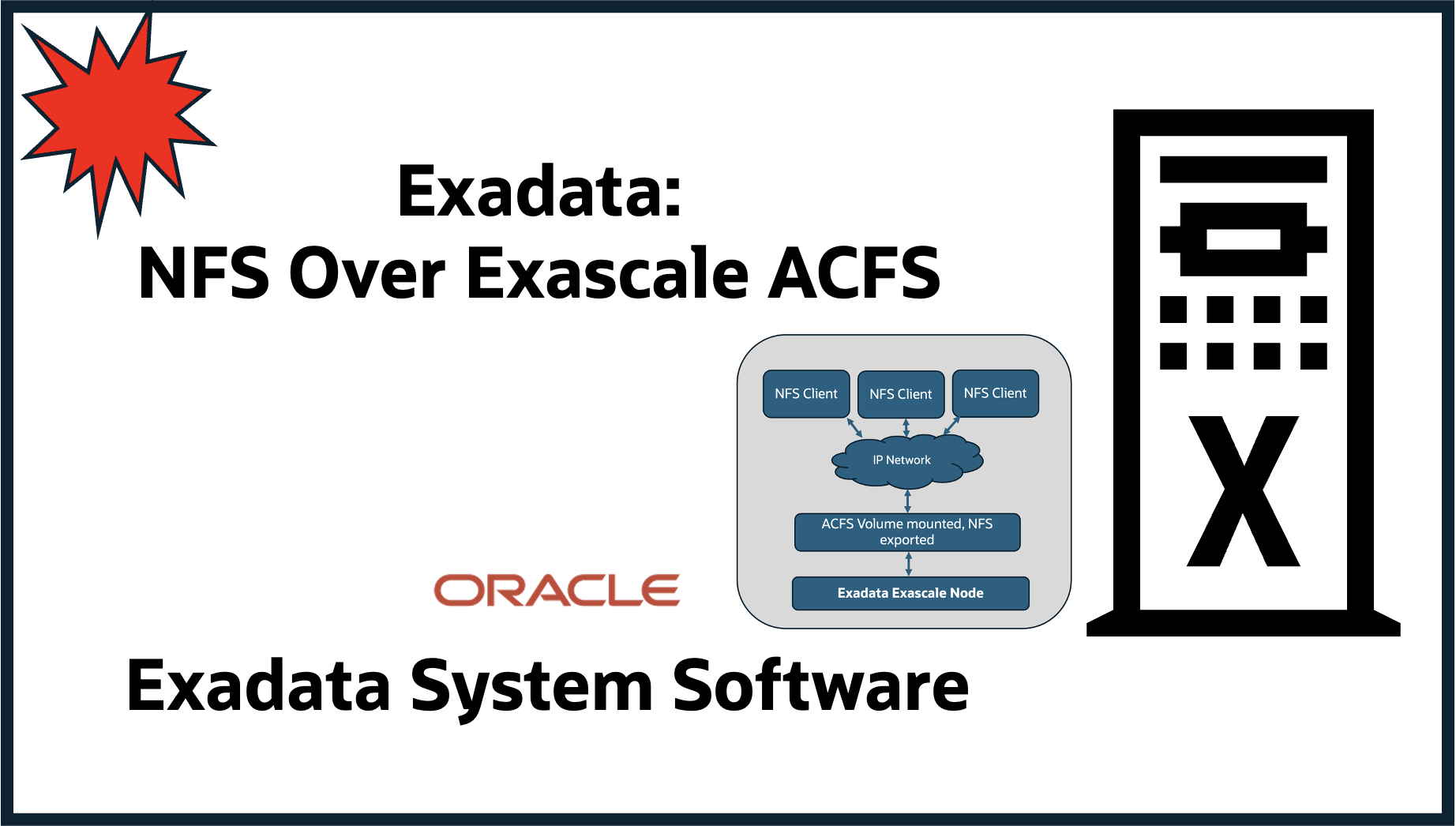
Exadata Versatility: NFS on Exascale ACFS for Scalable, Shared File ...
Allan Graves
Natarajan Shankar
13 minute read
Advantages of Exadata Exascale
Chris Craft
4 minute read
Exascale Storage Fundamentals
Seth Miller
8 minute read
Exadata Updates
See all
Exadata System Software Updates – June 2026
Alex Blyth
2 minute read
Announcing Exadata System Software 26ai, release 26.1!
Alex Blyth
11 minute read
Exadata System Software Updates – May 2026
Alex Blyth
2 minute read
Exadata System Software Updates – April 2026
Alex Blyth
2 minute read
Exadata System Software Updates – March 2026
Alex Blyth
2 minute read
Exadata System Software Updates – February 2026
Alex Blyth
2 minute read
Exadata System Software Updates – January 2026
Alex Blyth
2 minute read
Exadata System Software Updates – December 2025
Alex Blyth
2 minute read
Receive the latest blog updates
Subscribe to Oracle Connect email updates
Resources for
About
Careers
Developers
Investors
Partners
Startups
Why Oracle
Analyst Reports
Best CRM
Cloud Economics
Corporate Responsibility
Security Practices
Learn
What is Customer Service?
What is ERP?
What is Marketing Automation?
What is Procurement?
What is Talent Management?
What is VM?
What's New
Try Oracle Cloud Free Tier
Oracle Sustainability
Oracle COVID-19 Response
Oracle and SailGP
Oracle and Premier League
Oracle and Red Bull Racing Honda
Contact Us
US Sales 1.800.633.0738
How can we help?
Subscribe to Oracle Content
Try Oracle Cloud Free Tier
Events
News
© 2026 Oracle
Privacy
/
Do Not Sell My Info
Ad Choices
Careers