We are thrilled to announce the availability of Exadata Exascale, the world’s only intelligent data architecture for the cloud. Exadata Exascale is a revolutionary leap that combines the best of Exadata and the best of the cloud. This next-generation, hyper-elastic, multi-tenant software architecture is designed to handle mission-critical, analytics, AI vector, JSON, and mixed Oracle Database workloads.
Exascale reimagines how compute and storage resources are managed on Exadata platforms by decoupling and simplifying storage management, paving the way for innovative new capabilities. It ensures industry-leading database performance, availability, and security standards that organizations expect from Exadata.
One of Exascale’s ground-breaking features is its reimagined approach to database snapshots and clones on Exadata. It enables space-efficient thin clones from any read/write database or pluggable database, significantly boosting developer productivity. Exascale seamlessly integrates with development, test, and deployment pipeline requirements while providing native Exadata performance.
Databases on Exascale are automatically distributed across all available storage in the Exascale storage cloud, providing ultra-low latency RDMA for I/O and database-aware intelligent Smart Scan with up to thousands of cores available to all workloads. Automatic data replication across multiple storage servers ensures fault tolerance and reliability.
In Oracle Cloud, the Exascale Database Service on Exadata Infrastructure offers a fully elastic and pay-per-use model. Customers can specify the cores and storage capacity needed, slashing the entry-level infrastructure costs for Exadata Database Service by up to 95 percent. This model provides flexible, granular, and online resource scaling, aligning costs with actual usage.
Exascale is engineered to coexist with existing Exadata deployments, allowing our customers to choose when to take advantage of its capabilities.
Technical Architecture

Exadata utilizes a direct I/O path architecture to enable Oracle Database 23ai to send intelligent data requests directly to storage, eliminating the need for intermediary storage management tiers typical of cloud storage environments and making communication much faster. Most importantly, the direct I/O architecture is required for Oracle Database to use the unique RDMA-enabled memory cache in Exadata storage known as Exadata RDMA Memory (XRMEM), which enables as low as 171 microseconds latency and millions of IOPS of OLTP and AI throughput.
This architecture also enables Exadata Smart Scan, whereby the database offloads SQL processing to the storage rather than moving data to the database servers. This powerful and unique network optimization results in extraordinary analytics scan throughput.
Exascale changes how server resources are managed and allocated, strengthening Exadata’s mission–to be the ideal platform for running all Oracle Database workloads.
Exascale reimagines how databases and Exadata virtual machines use storage to further incorporate cloud attributes–hyper-elasticity, multi-tenancy, and resource pooling—into Exadata. Ultimately, this means evolving away from the siloed storage approach of separate database clusters managing their storage to a pooled storage approach where database clusters can easily access the aggregate storage capacity and the aggregate performance potential of all the storage servers, regardless of the database size or criticality.
Exascale moves the management of storage resources from the database server to the storage server. Several benefits arise from this:
- Storage servers take control of storage management, simplifying software architecture and operational management
- Increased storage capacity utilization and efficiency
- New native features, including file snapshots and clones, and block volumes
- Loosely coupled architecture enables hyper-scale
- All of Exadata’s current performance, availability, manageability, and security features are automatically and transparently available to databases deployed on Exascale
The Exascale architecture decouples compute and storage, moving storage management from the database servers to intelligent storage servers, where it can be utilized more effectively and managed more simply. Intelligent Exadata storage servers consist of CPUs, RDMA-accessible memory, flash storage, hard disk, and intelligent software to automatically cache data in the most advantageous media for the workload. With the incorporation of Exascale, the intelligent software also manages the files and extents within the storage servers, enabling new features and capabilities on Exadata.
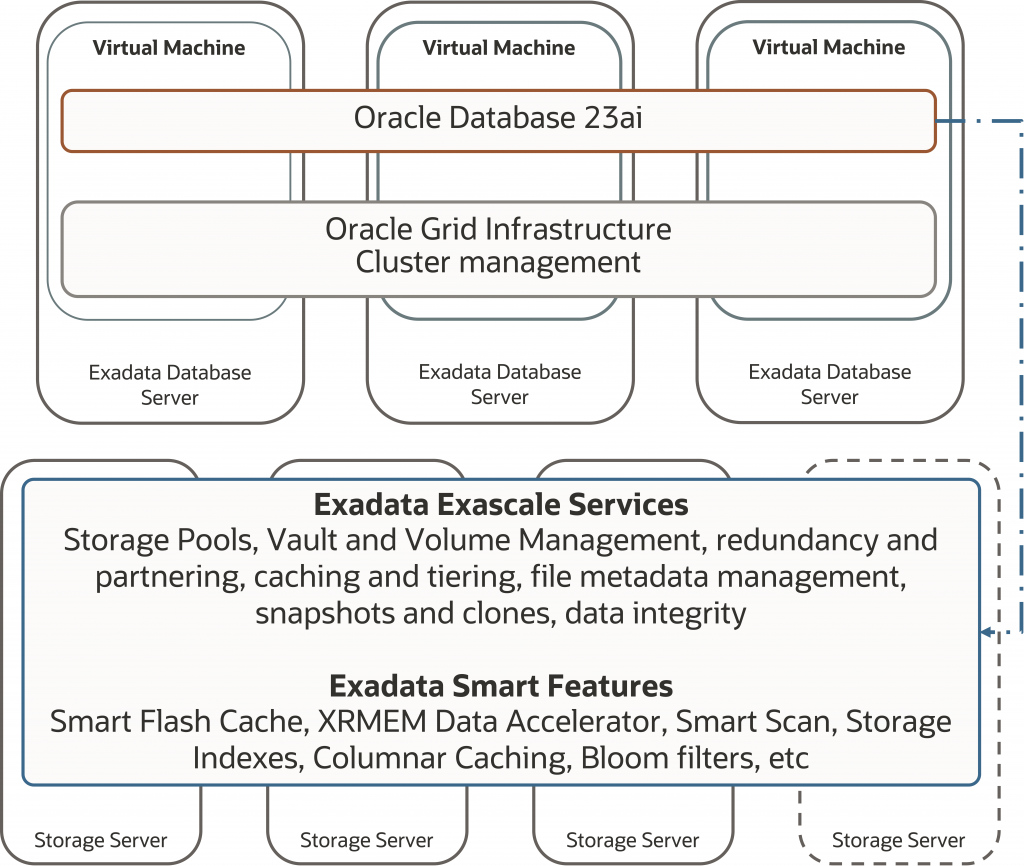
Exadata Exascale Architecture
We’ll now look deeper into some of the technical changes Exascale introduces.
Exascale Storage Pools
Exascale groups the storage capacity and I/O capabilities of the persistent disk, Flash Cache, and XRMEM into storage pools. A storage pool is a collection of pool disks (grid disks designated for storage pools) allocated from the physical disks in the storage servers, and it is the resting place for extents managed by Exascale. If we inspect an individual HDD in Exadata, with Exascale, each physical disk has a logical representation (LUN) in the storage server OS. A cell disk is created as a container for all Exadata-related partitions within the LUN. Partitions in a cell disk are designated as pool disks or grid disks.
Storage pools aggregate the pool disks among multiple storage servers, creating a simple and flexible way of allocating storage capacity and I/O. Exascale can incorporate thousands of storage servers to create truly cloud-scale storage resources–as in the new Exadata Database on Exascale Infrastructure Service (ExaDB-XS).
Exascale Files
Everything in Exascale is represented as a file, whether an actual database data file, a redo log, a snapshot or thin-clone of a set of data files, or a block volume for a virtual machine. Files, in turn, are divided into extents that are mirrored and distributed across multiple storage servers. In Exascale, an 8 MB extent size is used as this is large enough to get the excellent I/O throughput from Smart Scan that users of Exadata are familiar with, and it’s small enough to spread (stripe) files across as many physical disks as are available. This enables all databases to leverage all the CPUs, memory, and I/O capabilities of the storage server fleet.
Unlike ASM, where a disk group’s settings determine file attributes, Exascale sets key attributes (such as content type) at the file type level. This lets files within the same Exascale storage pool use different attribute settings. Files in Exascale all utilize High Redundancy to ensure the highest data protection.
File templates are used to define the many attributes of any given file, such as its content type – if the file is a ‘data’ (e.g., data files) or ‘recovery’ object (e.g., redo and archive logs, backup pieces, etc.). Exascale understands the different file types the Oracle database uses (and many other non-database-related files). This knowledge ensures that data and recovery extents are not co-located on the same disk. Exascale’s disk partnering strategy also ensures that mirrors are not co-located on the same storage servers as the primary extent. In ASM, this same requirement was implemented using two separate disk groups, typically called DATA and RECO, to physically separate the data files and recovery files on separate grid disks with separate partner disks.
Exascale Vaults

Exadata Exascale enabled storage
A vault is a logical storage container that uses the physical resources provided by storage pools and makes them available to the database clusters. Somewhat analogous to ASM disk groups, vaults define how much storage capacity and I/O resources are allocated to a database cluster from the storage pools.
Exascale Vaults are the most visible of the new Exascale concepts, as they are used directly by the Oracle database in place of the ASM disk groups. When working on a database that uses Exascale for storage, the spfile parameters db_create_file_dest and recovery_create_file_dest will show an Exascale vault as a destination starting with the ‘@‘ symbol. For example, db_create_file_dest = '@vault_name'. Databases will use the same vault for the data and recovery files associated with a database. The content type is associated with the file itself in Exascale, so administrators do not need to separate such files into different vaults, as the underlying storage is shared across all vaults.
Vaults implement user access controls and are secured with public and private key pairs to ensure that database clusters can only access files and extents for their databases. This prevents files belonging to a cluster from being accessed by another cluster on the same infrastructure.
Storage server resources, such as IOPS, Flash Cache, and XRMEM Cache allocations, can be managed at the vault in addition to the existing resource management features of Exadata and Oracle Database.
Exascale Volumes

Exascale introduces unique RDMA-enabled block volumes to Exadata, enabling non-database files and file systems to be placed on shared storage. Exadata virtual machines can use Exascale volumes rather than local storage in the database servers. Moving Exadata virtual machine image files onto Exascale volumes will enable simple, fast online migrations between physical database servers for Exadata’s unique RDMA-enabled database workloads. This will significantly reduce virtual machine downtime and performance brownouts during planned physical server maintenance in the short term, ending with online virtual machine migration and eliminating virtual machine downtime for physical server maintenance in the longer term2.
As the Exascale Volumes are RDMA-enabled, they deliver extremely low latency and extremely high throughput compared to conventional block I/O. In addition, they can be attached to virtual machines as block devices for Oracle Advanced Cluster File System (ACFS—formerly known as ASM Cluster File System) or other Linux-based filesystems such as XFS.
Exascale Volumes are represented as files on disk. They are also spread across the entire pool of storage servers, taking advantage of the I/O, redundancy, and snapshot and clone capabilities (see below). These high-performance and space-efficient volume copies enable easy backup and restoration of virtual machines and filesystems.
Database access
Exascale manages file extents for a database cluster from the storage servers. Exascale tracks every extent it manages in a cluster-wide mapping table, which is then cached by each database server and instance to enable any database to locate its file extents. Oracle Database takes advantage of Exadata’s direct I/O architecture, issuing I/O directly to the storage server where the data is located. When a database using Exascale wants to read an extent, it already knows where the primary extent is located and issues the required I/O (RDMA read to XRMEM or SQL offloaded with Smart Scan).
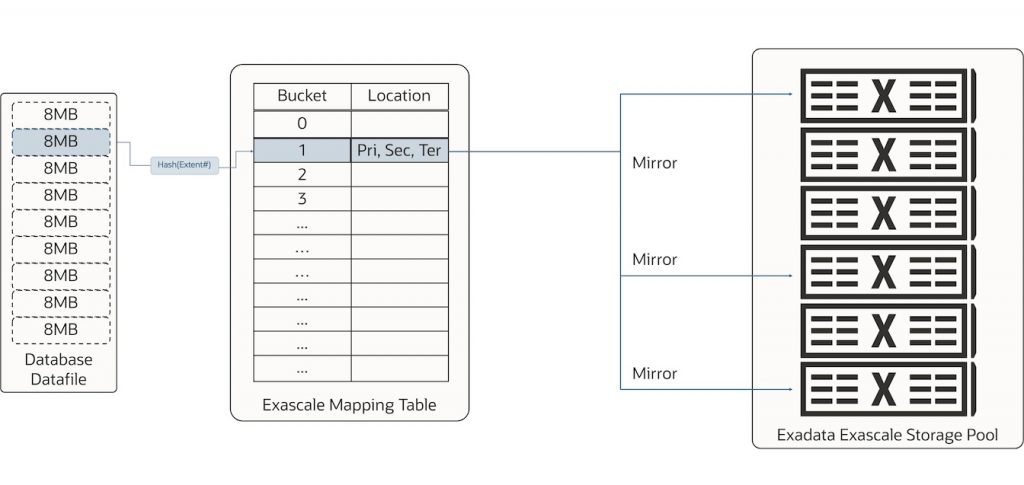
Each file extent is mapped (hashed) to a bucket in the mapping table, which provides the location for the extent’s primary and mirror copies. The mapping table is simultaneously large enough to support up to thousands of storage servers and small enough to cache on the database servers. As databases grow – data files are extended, new data files are added, new pluggable databases, etc – or as more data or storage servers are added, more file extents will be mapped to the same bucket in the mapping table. The mapping table is automatically and transparently managed on the storage servers and cached by the database servers and instances, eliminating the need for administration.
To access data, the database uses its cached copy of the mapping table to determine the location of the extent needed and issues I/O directly to the required storage server. For smart scans, the offloaded SQL is sent to the storage servers involved (generally all storage servers, as the extents from all databases are distributed across all storage servers).
A database’s mapping table is a cached copy that will become stale over time as storage servers are added or removed from a cluster, files are rebalanced, or for other necessary (but esoteric) reasons. The mapping table does not change size when the storage servers are added or removed. Unlike ASM, it does not require distributed locking when such operations are performed, ensuring that the mapping table on the storage servers is always available. If a database issues an I/O request to a location where the expected extent no longer resides, the I/O is rejected, and the cached mapping table is refreshed, enabling the I/O to be re-issued.
Snapshots and Clones
Exascale introduces new native redirect-on-write file snapshot and clone (including thin clone) capabilities to Exadata. Building on Exascale’s extent management, file snapshots and clones are created and managed within the storage servers, removing the responsibility of clone/snapshot file management from the database servers and enabling the storage servers to locally manage the out-of-place (redirect-on-write) creation and ongoing I/O of these files.
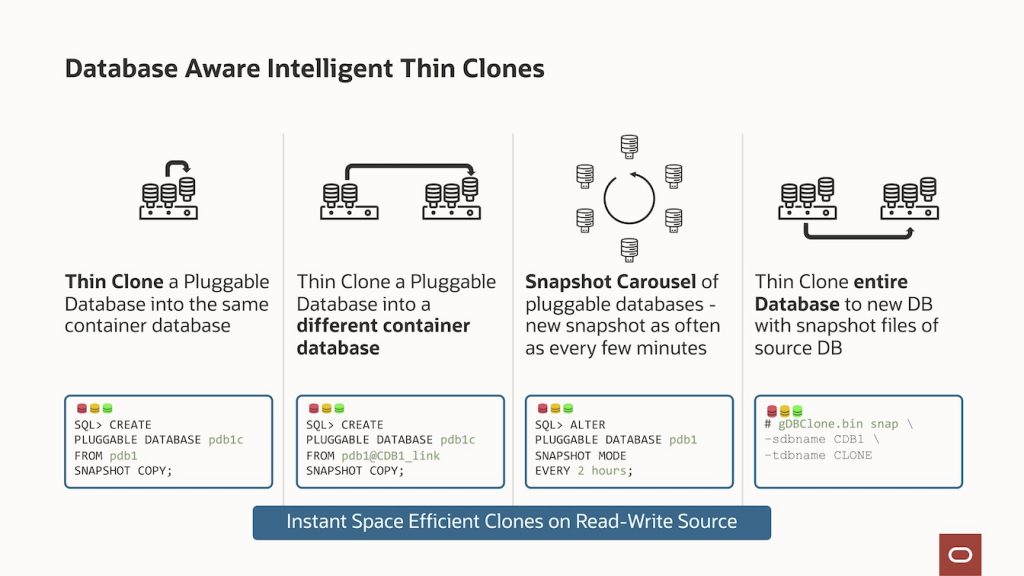
Exascale instantly creates database and pluggable database clones for development, testing, and many other everyday use cases, and may be either a complete clone or a space-efficient thin clone. The clone can be created from any “live” read-write or read-only database in both cases. There are no complex prerequisites, such as requiring an ongoing static read-only source to clone from. Any database may be cloned; in turn, any clone may also be cloned. Every database on Exascale – including clones – benefits from all the performance Exadata offers, regardless of the database’s purpose. The combination of Exascale space-efficient cloning and the inherent Exadata performance capabilities positions Exadata Exascale for all workloads and all lifecycle stages for all organizations, significantly increasing the value derived from consolidating more databases.
The file snapshot and clone capabilities for creating pluggable database clones are exposed using the existing ‘CREATE PLUGGABLE DATABASE <CLONE_NAME> FROM <SOURCE_PDB>;‘ for full clones and ‘CREATE PLUGGABLE DATABASE <CLONE_NAME> FROM <SOURCE_PDB> SNAPSHOT COPY;‘ for thin clones. This simplifies clones and snapshots’ creation (and destruction) as the container database coordinates all required activities with Exascale and within the database.
Pluggable database snapshots and the PDB Snapshot Carousel are read-only point-in-time file snapshots from which read-write clones can be created. Using similar syntax as above – ‘CREATE PLUGGABLE DATABASE <CLONE_NAME> FROM <SOURCE_PDB> SNAPSHOT‘ – or automatically using the PDB Snapshot Carousel – ‘ALTER PLUGGABLE DATABASE <PDB_NAME> SNAPSHOT MODE EVERY t seconds/minutes/hours‘, snapshots can be created for later use.
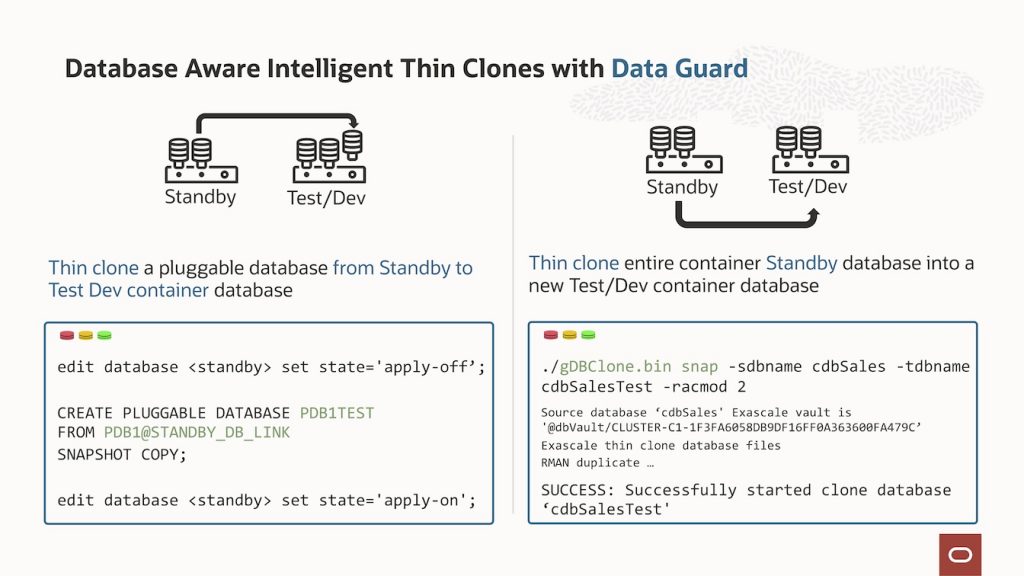
Pluggable database clones can be created within the same container database, between container databases using database links, from a standby database using database links, and from snapshots.
When cloning a container database and its pluggable databases, the gDBCLone utility (available on My Oracle Support) coordinates the file cloning in Exascale and the supporting database infrastructure, including password files, parameter files, instances, registration with CRS, and more. Container database clones can also be made from any live or standby database.
Performance
As Exascale aggregates storage into storage pools, databases, regardless of their size, are striped and mirrored across as many storage servers and, therefore, disks as are present in the Exascale storage cluster. This enables every database to access the I/O performance of all the storage servers, tapping into all the cores, memory, and intelligent software features.
Exascale is engineered with Exadata’s Smart System Software. It leverages all performance features and optimizations that are available and unique to Exadata. Oracle Database 23ai utilizes the hardware-based RDMA introduced in Exadata X8M to enable as low as 171 microseconds 8K OLTP Read I/O latency with Exadata RDMA Memory (XRMEM) in the storage servers. Exadata Smart System Software automatically caches data on disk into Exadata Smart Flash Cache and XRMEM, providing the exceptionally low latency of memory, the extremely high IOPS of flash, and the enormous capacity of HDDs for all Oracle Database workloads.
Exadata continues to be the best platform for running all Oracle Database workloads including AI Vector processing, Online Transaction Processing (OLTP), Analytics, and In-Memory Analytics. Exadata features a modern cloud-enabled architecture with scale-out high-performance database servers, scale-out intelligent storage servers with state-of-the-art PCIe flash, unique storage caching using RDMA accessible memory, and cloud-scale RDMA over Converged Ethernet (RoCE) internal fabric that connects all servers and storage. Intelligent software employing unique algorithms and protocols in Exadata implements database intelligence in storage, compute, and networking to deliver higher performance and capacity at lower costs than other database platforms.
Available now on Exadata Database Machine
With the recent availability of Oracle Database 23ai (23.5) for on-premises Exadata Database Machines, Exadata Exascale can now be configured for X8M and newer Exadata deployments. Exascale is designed to be deployed alongside existing deployments using the Oracle Exadata Deployment Assistant (OEDA) and enable customers to take advantage of the new capabilities such as space-efficient thin clones from any read/write database or pluggable database.
Customers deploying new virtual machines on existing environments can take advantage of Exascale Volumes, which hosts the image files used by the virtual machine onto shared Exadata storage servers. Virtual machine image files on Exascale Volumes is a foundational step towards cold and live virtual machine migration2 and increases the overall storage capacity for image files. For customers with X10M database servers wishing to create up to 50 virtual machines (up from 12), Exascale Volumes are the easiest way to provide sufficient capacity.
Available now in Oracle Cloud Infrastructure
Exadata Exascale is available now in OCI, underpinning the new Exadata Database Service on Exascale Infrastructure (ExaDB-XS). This multitenant (or shared) service enables any customer and database of any size to utilize the power of Exadata cost-effectively and efficiently. Comprised of a large pool of intelligent Exadata database and storage servers, Exadata Database Service on Exascale Infrastructure enables customers to create virtual machine clusters as small as 8 ECPUs, 22GB of memory per VM, and 300GB of database storage yet on a platform that unleashes the RDMA and I/O capacity of dozens or many more physical servers, and hundreds to thousands of CPU cores.
Exadata Database Service on Exascale Infrastructure enables customers to enjoy the Exadata Database Service benefits at a lower entry price for smaller but no less critical databases without subscribing to dedicated infrastructure. It bridges the gap between dedicated Exadata infrastructure and virtual machines on shared commodity infrastructure. It extends Exadata’s advantages to every organization in every industry, regardless of size or workload.
Benefits of Exadata Database Service on Exascale Infrastructure

- Powerful Exadata Performance, Reliability and Availability
Exascale Infrastructure inherits all the capabilities of Exadata that deliver extreme performance, reliability, availability, and security for business-critical Oracle databases. Exadata’s unique database-aware intelligence accelerates AI, analytics, and mission-critical OLTP workloads.
- Extreme Low Cost
With Exascale Infrastructure, you only pay for your database’s compute and storage resources, starting with a low, highly affordable minimum size.
- Scalable Pooled Resources on Demand
Running Exadata Database Service on Exascale Infrastructure with large pools of shared compute and storage allows databases to quickly scale over time without concern for server-based size limitations or disruptive migrations.
- Agile Development
Exascale Infrastructure features rapid and efficient database thin cloning capabilities, native Exadata performance, and lower storage costs that enhance developer agility.
Summary
Exascale is as exciting as it is extraordinary. It combines the best of the cloud and Exadata and reimagines Exadata’s software architecture to produce the world’s only intelligent data architecture designed for the cloud. Building on the direct I/O architecture, Exascale delivers the same extreme performance Exadata is renowned for and expands these capabilities to any size database, workload, criticality or lifecycle stage, and any Oracle Database customer. Exascale delivers simpler operations, streamlined development pipelines, and increased developer productivity, and puts Exadata into the hands of all our customers with the new Exadata Database Service on Exascale Infrastructure.
And that’s just the beginning.
Getting started with Exadata Exascale
For more information on Exadata Exascale and the Exadata Database Service on Exascale Infrastructure, take a look at the following resources:
- Exadata Database Service on Exascale Infrastructure Blog
- Exadata Database Service on Exascale Infrastructure Technical Documentation
- Exadata Database Service Webpage
- Oracle Database 23ai GA Announcement
Updates
| Date | Change |
| July 22 2024 | Add availability of Exascale on Exadata Database Machine |
| December 8 2025 | Miscellaneous updates |
Updated –
Footnotes
- 17 microseconds on X10M. 19 microseconds on X8M/X9M
- Available in a future release




