Möchten Sie, dass Ihre Java Programme ohne Fehler weiterlaufen, wenn Ihre RAC Datenbank kurzfristig nicht verfügbar ist, wenn gewollt oder ungewollt ein Knoten ausfällt? Möchten Sie das unkompliziert und ohne aufwändigen, eigenen Code zur Fehlerbehandlung ? Für lesende und schreibende Transaktionen, die mittendrin abgebrochen wurden ? Für lokale und verteilte Transaktionen ? Dann verwenden Sie den JDBC Treiber 21c und den Universal Connection Pool (UCP) von Oracle. Wir zeigen Ihnen an einem Beispiel mit aktuellen Frameworks, wie das aussehen könnte.
Es hat sich vieles getan in den Oracle Clients, seit Oracle RAC mit Datenbank Version 10 verfügbar wurde. Oracle FAN und FCF, später mit AC in Version 12c und TAC in 18c (mit weiteren Features in Version 19c und 21c) stellten jeweils den aktuellen Stand der Entwicklung dar und boten immer mehr Möglichkeiten und Automatismen, immer mehr Transparenz im Falle eines Problems im Cluster. TAC bietet rundum-Schutz mit schneller Notifikation eines Oracle Connection Pools, der ungültige unbenutzte Connections aufräumt. Bei Connections, die gerade vom Programm in Verwendung sind werden nicht nur lesende, sondern auch schreibende offene Transaktionen transparent übernommen und auf dem überlebenden Datenbank-Knoten nachgespielt bis zum letzten Kommando kurz vor dem hoffentlich gewollten Ausfall.
Nicht nur auf der Seite der Oracle Datenbank, sondern auch im JDBC bzw Java Client hat sich vieles getan. So werden stets neueste APIs unterstützt und Frameworks wie SpringBoot und Applikationsserver wie WildFly mit Plugins und Howtos bedacht.
Unser Beispiel verwendet neben Java 17 die Java Microprofile 5.0 Spezifikation, was unter anderem den Einsatz von Jakarta EE 9.1 Bibliotheken bedeutet für verteilte Transaktionen und für die Java Persistence API, hier mit EclipseLink Implementation. Alles zusammen wurde gegossen in den OpenSource Framework Helidon 3.1 des Oracle Enterprise Java Teams. Wir gehen an entsprechenden Stellen auf Unterschiede bei Benutzung von SpringBoot oder WildFly ein. Das gesamte lauffähige Helidon-Beispielprojekt mit Konfigurationsdateien und vollständigem Java Code liegt zum Download oder per “git clone” auf github.com/ilfur/tac_helidon_jpa.
Vorbereitung von Oracle RAC für Transparent Application Continuity
Die einzelnen Schritte und Erklärungen für TAC und dessen Einrichtung sind bereits umfassend erklärt in einem Blog unseres geschätzten Kollegen Sinan Petrus Toma: Datenbankausfall? Mir doch egal, dank Application Continuity.
Für unser Java Beispiel haben wir eine Datenbank-Umgebung 19c mit SCAN Listener und Transaction Guard sowie Oracle Notification Service(ONS) auf Port 6200 verwendet.
Das Datenbank-Cluster erhielt einen neuen Service, der einige Parameter für den Einsatz mit TAC auf den Weg bekommt:
srvctl add service -db cdb19a -service TACSERVICE -pdb WKAA -preferred cdb19a1,cdb19a2 -available cdb19a3,cdb19a4 -failover_restore AUTO -commit_outcome TRUE -failovertype AUTO -replay_init_time 600 -retention 86400 -notification TRUE -drain_timeout 120 -stopoption IMMEDIATE -role PRIMARY
Der Parameter “-failovertype AUTO” aktiviert TAC, Parameter “-notification TRUE” aktiviert Notifikationen/ONS für diesen Service, und “-commit_outcome TRUE” nutzt Transaction Guard.
Um sich mit diesem Service per Java zu verbinden wurde ein Connect String gewählt, der einige für Failover-Szenarien und Load Balancing typische Parameter enthält:
jdbc:oracle:thin:@(DESCRIPTION = (CONNECT_TIMEOUT= 3)(RETRY_COUNT=4)(RETRY_DELAY=2)(TRANSPORT_CONNECT_TIMEOUT=3) (ADDRESS_LIST = (LOAD_BALANCE=on) (ADDRESS = (PROTOCOL = TCP)(HOST=hpcexa-scan.de.oracle.com)(PORT=1521))) (CONNECT_DATA=(SERVICE_NAME = tacservice.de.oracle.com)))
Der CONNECT_TIMEOUT Wert ist vorzugsweise relativ klein mit 3 Sekunden gewählt. Schlägt ein Connect-Versuch nach 3 Sekunden fehl, wird nach einem RETRY_DELAY von 2 Sekunden erneut ein Connect Versuch gestartet, maximal RETRY_COUNT mal. Mit TRANSPORT_CONNECT_TIMEOUT wird der Timeout rein auf TCP/IP Ebene eingestellt, ohne das Warten auf Rückmeldung der Datenbank-Instanz wie bei CONNECT_TIMEOUT. Der Default ist hier bei 60 Sekunden recht lang.
Vorbereitung des Java Projektes für TAC: Einbinden des UCP
Um alle Features von TAC voll auszuschöpfen und auch Treiber und Plugins für SpringBoot und WildFly bereitzustellen sollte der neueste JDBC 21c Treiber benutzt werden (zur Zeit dieses Artikels Version 21.8.0.0), der auch mit einer Oracle Datenbank 19c zertifiziert ist. Zusätzlich sollte der Oracle Universal Connection Pool (UCP) benutzt werden, welcher zahlreiche Features im Hochverfügbarkeits-Umfeld bietet. Zum Beispiel reagiert dieser auf Ereignisse des Notification Service (ONS) der Datenbank wie einem Instanz-Ausfall oder der Service-Migration auf einen anderen Host automatisch und transparent. Andere Connection Pool Implementierungen wie Hikari haben diese Oracle-spezifischen Features nicht inne, so daß Fehlermeldungen bei Instanz-Ausfall nicht vermeidbar sind und im eigenen Code abgefangen werden müssen.
Zur Einbindung des aktuellsten Oracle JDBC Treibers und Universal Connection Pools (UCP) in ein Maven-Projekt sind diese beiden Dependencies in der Projektbeschreibung “pom.xml” notwendig:
<dependency>
<groupId>com.oracle.database.jdbc</groupId>
<artifactId>ojdbc11</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.oracle.database.jdbc</groupId>
<artifactId>ucp11</artifactId>
<scope>runtime</scope>
</dependency>
Der Universal Connection Pool wird im Helidon-Framework mit einer eigenen Bibliothek bedacht, die als Maven dependency eingebunden wird. Die Nutzung des UCP ist dann über Dependency Injection (CDI) möglich. Weiterhin gibt es für Helidon pom.xml Dependencies nicht nur für den UCP, sondern auch für die JTA Transaktions-API und auch für die JPA Persistence-API:
<dependency>
<groupId>io.helidon.integrations.cdi</groupId>
<artifactId>helidon-integrations-cdi-datasource-ucp</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>io.helidon.integrations.cdi</groupId>
<artifactId>helidon-integrations-cdi-jta-weld</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>io.helidon.integrations.cdi</groupId>
<artifactId>helidon-integrations-cdi-jpa</artifactId>
<scope>runtime</scope>
</dependency>
Der UCP ließe sich alternativ per Java Code in einer selbstgeschriebenen Java Klasse laden, instanziieren und konfigurieren und danach z.B. per JNDI API registrieren, so daß sich die Instanz von überallher im gleichen Java Prozess heranholen ließe. Ein einfacher Beispiel-Code ist Teil der Oracle JDBC Dokumentation. Mancher Applikationsserver wie z.B. IBM WebSphere ermöglicht die Registrierung von Datasource-Klassen per Konfiguration.
Es existiert für WildFly bzw. für den JBoss Applikationsserver eine im Oracle JDBC Treiber enthaltene ServletFilter-Klasse, die den UCP beim Laden von Servlets, z.B. REST Services, lädt und konfiguriert. Sie trägt den Namen oracle.ucp.jdbc.UCPServletContextListener ; ihre Verwendung mit einem Beispiel wird in einem PDF What’s in Oracle Database 21c for Java Developers?beschrieben.
Das gleiche Dokument erklärt auch eine Einbindungsmöglichkeit des UCP in SpringBoot Applikationen. Dort ist lediglich nach Einbinden des Oracle JDBC Treibers der Name, Java-Klasse und nötige Parameter des UCP direkt in die dort typische application.properties Datei einzubinden. Der UCP wird dann beim Start geladen, konfiguriert und mit einem suchbaren Namen versehen. Das liegt an der SpringBoot DataSource Klasse “oracle.ucp.jdbc.UCPDataSource“, die im JDBC Treiber enthalten ist und vom Spring Framework beim Start geladen wird, sobald sie sich im Classpath befindet. Ein funktionierendes Code-Beispiel für die Verwendung des UCP, mit und ohne TAC, aber ohne Nutzung der JPA (nur spring-jdbc) liegt auf github.com im Bereich der Oracle-Samples für JDBC. Die application.properties-Datei sieht dort wie folgt aus:
# For connecting to Autonomous Database (ATP) refer https://www.oracle.com/database/technologies/getting-started-using-jdbc.html # Provide the database URL, database username and database password spring.datasource.url=jdbc:oracle:thin:@dbname_alias?TNS_ADMIN=/Users/test/wallet/wallet_dbname_alias spring.datasource.username=<your-db-user> spring.datasource.password=<your-db-password> # Properties for using Universal Connection Pool (UCP) # Note: These properties require Spring Boot version greater than 2.4.0 spring.datasource.driver-class-name=oracle.jdbc.OracleDriver spring.datasource.type=oracle.ucp.jdbc.PoolDataSource # If you are using Replay datasource (=TAC) spring.datasource.oracleucp.connection-factory-class-name=oracle.jdbc.replay.OracleDataSourceImpl # Use this if you are not using Replay datasource # spring.datasource.oracleucp.connection-factory-class-name=oracle.jdbc.pool.OracleDataSource spring.datasource.oracleucp.sql-for-validate-connection=select * from dual spring.datasource.oracleucp.connection-pool-name=connectionPoolName1 spring.datasource.oracleucp.initial-pool-size=15 spring.datasource.oracleucp.min-pool-size=10 spring.datasource.oracleucp.max-pool-size=30 spring.datasource.oracleucp.fast-connection-fail-over-enabled=true
Ganz egal ob SpringBoot, Helidon oder JBoss:
Der Unterschied zwischen dem Einsatz oder Wegfall von TAC liegt in der verwendeten Connection Factory Klasse (bzw. Interface) oracle.jdbc.pool.OracleDataSource bzw. oracle.jdbc.replay.OracleDataSourceImpl. Letztere Klasse wird auch der “replay Treiber” genannt und ist in der Lage, offene Transaktionen auf einem überlebenden Datenbank-Knoten nachzufahren. Falls lokale bzw. “einfache”, benutzerdefinierte Transaktionen gefahren werden ist dies die richtige Klasse. Geht es um verteilte Transaktionen, gesteuert durch die Java Transaction API und mit zu berücksichtigendem XA Protokoll (z.B. bei mehreren beteiligten Ressourcen an einer Transaktion), so sollte die Klasse oracle.jdbc.replay.OracleXADataSourceImpl benutzt werden. Meist ist in Projekten die Verwendung von JTA beschränkt auf lokale Transaktionen, so daß der Treiber den “database replay” wie beschrieben durchführen kann. Sollte die benutzte Datenbank Connection aber tatsächlich Teil einer echten verteilten Transaktion sein und das XA Protokoll muß verwendet werden so wird dies erkannt und der “database replay” findet zugunsten des Transaktions-Sync des XA Protokolls nicht statt. Damit werden doppelte Operationen vermieden: das (leider im Test sehr langsame) XA Protokoll hat Vorrang gegenüber dem Replay-Treiber. Die restlichen TAC Features wie der transparente Connection Failover und die Wiederherstellung der Datenbank Session erfolgen dennoch.
Ähnlich wie bei SpringBoot verhält es sich auch bei Java Microprofile bzw. bei unserem Helidon-Beispiel. Nach Einbinden des JDBC Treibers und des CDI-Plugins für den UCP kann die für Java Microprofile typische Konfigurationsdatei microprofile-config.properties mit Klassennamen, Parametern und einem suchbaren (JNDI) Namen versehen werden. Beim Start der Applikation wird auch hier der UCP geladen und konfiguriert. In unserem Beispiel sieht die Datei microprofile-config.properties wie folgt aus:
oracle.ucp.jdbc.PoolDataSource.DeptEmpDataSource.URL=jdbc:oracle:thin:@(DESCRIPTION = (CONNECT_TIMEOUT= 3)(RETRY_COUNT=4)(RETRY_DELAY=2)(TRANSPORT_CONNECT_TIMEOUT=3) (ADDRESS_LIST = (LOAD_BALANCE=on) (ADDRESS = (PROTOCOL = TCP)(HOST=hpcexa-scan.de.oracle.com)(PORT=1521))) (CONNECT_DATA=(SERVICE_NAME = tacservice.de.oracle.com))) oracle.ucp.jdbc.PoolDataSource.DeptEmpDataSource.connectionFactoryClassName=oracle.jdbc.replay.OracleDataSourceImpl oracle.ucp.jdbc.PoolDataSource.DeptEmpDataSource.password=tiger oracle.ucp.jdbc.PoolDataSource.DeptEmpDataSource.user=scott oracle.ucp.jdbc.PoolDataSource.DeptEmpDataSource.fastConnectionFailoverEnabled=true # Checks if a connection is still valid before handing it out. Relatively slow on short-lived operations # oracle.ucp.jdbc.PoolDataSource.DeptEmpDataSource.validateConnectionOnBorrow=true # Checks is a connection is still valid after an idle timeout - bit more unsafe but dow not slow down as much # oracle.ucp.jdbc.PoolDataSource.DeptEmpDataSource.secondsToTrustIdleConnection=20 # If You need a custom ONS configuration, normally not required since part of TNS communication # oracle.ucp.jdbc.PoolDataSource.DeptEmpDataSource.onsConfiguration=true
Vorbereitung des Java Projektes für TAC: Verknüpfung der JPA Persistence Unit mit dem UCP
Auf Ebene der Java Persistence API kommen alle darunterliegenden Frameworks wie SpringBoot, Helidon und JBoss/WildFly wieder zusammen. Nach eben erfolgter Einbindung des UCP gilt es nun, die JPA Konfigurationsdatei “persistence.xml” mit dem UCP zu verbinden, damit ein JPA EntityManager die richtigen Klassen und Connections abrufen kann. Dieser Moment ist auch gut dazu geeignet zu überlegen, ob denn verteilte Transaktionen mit mehreren Teilnehmern (“transaction_type=JTA”) wirklich benötigt werden, oder ob es nicht ausreicht, einfache Datenbank-Transaktionen mit genau einer Datenbank-Connection zu verwenden (“transaction_type=RESOURCE_LOCAL”). Entsprechend wäre der bisher konfigurierte Replay Treiber durch denjenigen zu ersetzen, der auch XA Transaktionen beherrscht.
Die Konfigurationsdatei persistence.xml (per Standard im gleichen Unterverzeichnis anzulegen wie miroprofile-config.properties, nämlich “META-INF”) in unserem Helidon-Beispiel sieht wie folgt aus, wenn verteilte bzw. JTA/XA Transaktionen verwendet werden sollen:
<?xml version="1.0" encoding="UTF-8"?>
<persistence xmlns="https://jakarta.ee/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://jakarta.ee/xml/ns/persistence
https://jakarta.ee/xml/ns/persistence/persistence_3_0.xsd"
version="3.0">
<persistence-unit name="DeptEmpUnit" transaction-type="JTA">
<description>The TAC Dept/Emp database.</description>
<!-- EclipseLink as default provider in Helidon, could have been Hibernate -->
<provider>org.eclipse.persistence.jpa.PersistenceProvider</provider>
<exclude-unlisted-classes>true</exclude-unlisted-classes>
<!-- JNDI name of Connection Pool / Data Source to use -->
<jta-data-source>DeptEmpDataSource</jta-data-source>
<class>com.oracle.tac.pushData.Department</class>
<class>com.oracle.tac.pushData.Employee</class>
<properties>
<!-- EclipseLink Properties -->
<property name="eclipselink.weaving" value="false" />
<property name="eclipselink.deploy-on-startup" value="true"/>
<property name="eclipselink.jdbc.native-sql" value="true"/>
<property name="eclipselink.logging.logger" value="JavaLogger"/>
<property name="eclipselink.logging.parameters" value="true"/>
<property name="eclipselink.target-database" value="org.eclipse.persistence.platform.database.OraclePlatform"/>
<property name="eclipselink.target-server" value="io.helidon.integrations.cdi.eclipselink.CDISEPlatform"/>
<!-- Tuning parameters for JDBC Batching -->
<property name="eclipselink.jdbc.batch-writing" value="JDBC"/>
<property name="eclipselink.jdbc.batch-writing.size" value="100"/>
</properties>
</persistence-unit>
</persistence>
Die wichtigsten Unterschiede zur non-XA bzw non-JTA Konfiguration sind:
- transaction-type = “JTA” in der persistence-unit “DeptEmpUnit” anstelle von transaction-type = “RESOURCE_LOCAL”
- jta-data-source mit JNDI Namen des UCP darin anstelle einer non-jta-data-source
Der Java Code für lokale und verteilte Transaktionen
Das gesamte lauffähige Helidon-Beispielprojekt mit Konfigurationsdateien und vollständigem Java Code liegt zum Download oder per “git clone” auf github.com/ilfur/tac_helidon_jpa. Wir möchten hier auszugsweise einige Zeilen wiedergeben, um den Unterschied zwischen lokalen und verteilten Transaktionen aufzuzeigen. Der gezeigte Java Code dürfte sich zwischen WildFly, SpringBoot und Helidon auch nicht besonders unterscheiden. Lediglich die Java Importe müßten unterschiedlich lauten, so verwendet Helidon bereits vollständig die jakarta-Bibliotheken, während SpringBoot und WildFly an mancher Stelle noch Java EE Bibliotheken nutzen mit Klassen-Imports aus dem “javax” Namespace.
In dem Beispiel bietet eine Java Klasse “DbConnect.java” einen REST-Service, der Daten aus einer Datenbank-Tabelle “EMP” liest, einfügt und löscht. Einfügen und Löschen erfolgen in jeweils einer eigenen Transaktion.
Im Falle einer (verteilten) Transaktion, in unserem Beispiel eine Container Managed Transaction (das Framework verwaltet Transaktionen, nicht der eigene Code) mit dem XA-Replay Treiber und einer jta-datasource, muß die Klasse mit dem Beispiel-REST-Service zunächst einen PersistenceContext laden und auf die PersistenceUnit verweisen, die im vorigen Abschnitt in der persistence.xml Datei definiert wurde:
@PersistenceContext(unitName="DeptEmpUnit") private EntityManager em;
Eine Beispiel-Methode zum Einfügen neuer Angestellter/Employees muß eine Transaktion eben nicht manuell öffnen und schließen, sondern markiert lediglich über eine Annotation @Transactional, daß sie Teil einer neuen oder bestehenden Transaktion sein würde. Ein einfacher “em.persist(…)” genügt, der Framework entscheidet dann wann tatsächlich der Datensatz zur Datenbank gelangt und wann die Transaktion abgeschlossen wrd:
@GET
@Path("/addEmps")
@Produces(MediaType.APPLICATION_JSON)
@Transactional
public Response addEmps() {
try {
Employee e = null;
LOGGER.info("Adding Employees....");
for (int i=10000 ; i<11000; i++) {
e = new Employee();
e.setDepartmentNo ( Long.valueOf(30) );
e.setEName ( "BOERMANN" );
e.setEmpNo (Long.valueOf(i));
e.setJob ("ENGINEER");
em.persist(e);
}
} catch (RuntimeException e) {
LOGGER.error(e.getMessage());
return Response.status(500).build();
}
return Response.ok(Json.createObjectBuilder().add("action","ok").build(), MediaType.APPLICATION_JSON).build();
}
Bei einer lokalen Transaktion mit “RESOURCE_LOCAL” Konfiguration in persistence.xml sollte der Java Code statt einer JTA Transaktion eine Datenbank-Transaktion verwenden, die beim eingebundenen Entity Manager abgerufen werden kann. Doch zunächst muß auch diese Java Klasse einen Entity Manager finden. Dies geht nun nicht über eine PersistenceContext Annotation welche direkt einen EntityManager liefert. Zuerst muß eine PersistenceUnit angegeben werden, die eine EntityManagerFactory liefert. Daraus lassen sich dann bei Bedarf EntityManager und Datenbank-Transaktion holen.
@PersistenceUnit(unitName="DeptEmpUnit") private EntityManagerFactory emf;
Die gleiche Methode wie im JTA/XA Fall ruft nun aus der EntityManagerFactory einen EntityManager ab, beginnt eine Datenbank-Transaktion (eben keine JTA/XA-Transaktion) und schließt diese auch wieder selbst ab:
@GET
@Path("/addEmps")
@Produces(MediaType.APPLICATION_JSON)
public Response addEmps() {
try {
EntityManager em = emf.createEntityManager();
EntityTransaction entityTransaction = em.getTransaction();
entityTransaction.begin();
Employee e = null;
LOGGER.info("Adding Employees....");
for (int i=10000 ; i<11000; i++) {
e = new Employee();
e.setDepartmentNo ( Long.valueOf(30) );
e.setEName ( "BOERMANN" );
e.setEmpNo (Long.valueOf(i));
e.setJob ("ENGINEER");
em.persist(e);
}
entityTransaction.commit();
em.close();
} catch (RuntimeException e) {
LOGGER.error(e.getMessage());
e.printStackTrace();
return Response.status(500).build();
}
return Response.ok(Json.createObjectBuilder().add("action","ok").build(), MediaType.APPLICATION_JSON).build();
}
Warum wird im einen Fall ein PersistenceContext geladen, im anderen eine PersistenceUnit ? Der Unterschied liegt darin, daß beim Laden des PersistenceContexts nicht nur die PersistenceUnit geladen wird, sondern dem PersistenceContext im Hintergrund auch ein Transaktionsmanager angehängt wird. Es ließe sich nachträglich einem EntityManager mitteilen, daß er Teil einer globalen Transaktion ist, aber das verlängert und verkompliziert eventuell den Code und hat bei uns auch nicht so recht funktioniert… vielleicht haben Sie ja mehr Erfolg dabei als wir, und wir würden uns sehr über Rückmeldungen von Ihnen freuen !
Die Ausfall-Tests und die Test-Erkenntnisse
Das Einfügen neuer Employee-Objekte verlief dank Batching Operationen zu schnell für Failover-Tests. So bauten wir einen umständlichen Weg, Employee-Objekte wieder zu löschen: Jedes Objekt wird zunächst anhand seiner Angestellten-ID gesucht und eingelesen, dann gelöscht. Diese Operation dauerte bei 1000 Angestellten und einer DSL-VPN Leitung mit hoher Latenz (25ms) zwischen 20 und 40 Sekunden. Genug Zeit, um währenddessen einen Absturz zu simulieren und zu sehen, wie die Frameworks reagieren.
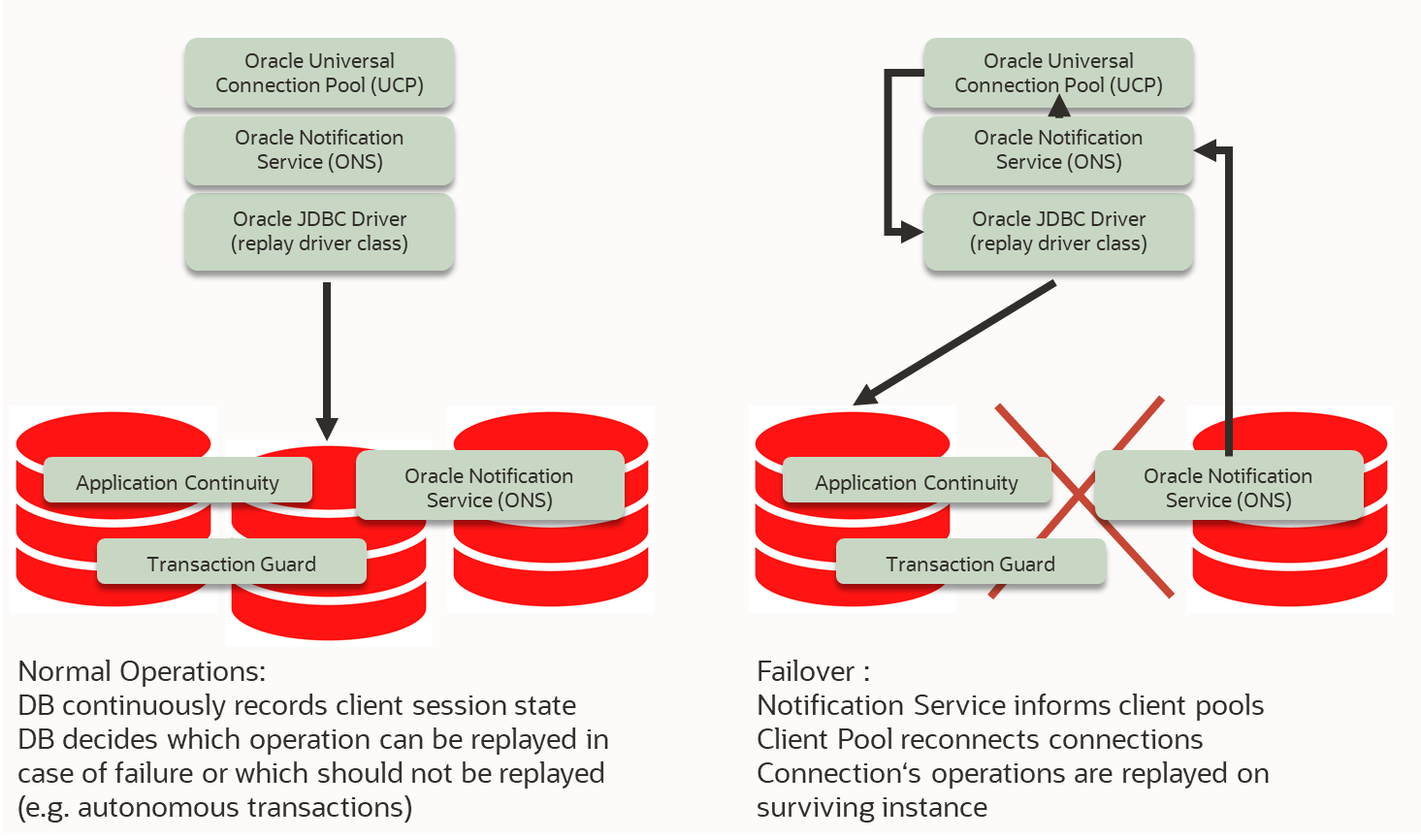
Die Datenbank speichert Session-Zustände der Clients, d.h. merkt sich nachfahrbare SQL Operationen.
Fällt ein Knoten aus, informiert ONS die Client Connection Pools. Diese bauen neue Verbindungen auf.
Noch offene Transaktionen werden in der Datenbank nachgefahren.
Geplanter Ausfall: Service-Umzug auf neuen Knoten
Ungeplanter Ausfall: Service-Abbruch bzw. Listener Shutdown
Um einen geplanten Ausfall zu simulieren, z.B. um einen Datenbank-Knoten zu Patchen und rollierende Updates zu ermöglichen, wird der Datenbank-Service, mit dem sich das Java Programm verbunden hatte, umgezogen. Das Kommando für den Service-Umzug unserer Beispiel-Umgebung lautete wie folgt:
srvctl relocate service -db cdb19a -service tacservice -oldinst cdb19a1 -newinst cdb19a2 -force -stopoption IMMEDIATE
Das Java Programm mit lokalen Transaktionen ohne Nutzung von JTA und XA lief ohne Fehlermeldung sauber durch und benötigte nur etwa eine Sekunde länger als ein Lauf ohne Datenbank-Unterbrechung. Die Employee-Objekte waren auch aus der Datenbank gelöscht worden. Das bedeutet, daß die Notifikation des Connection Pools durch den ONS zeitnah erfolgte, die offene Transaktion auf dem bereits hochgefahrenen Knoten nachgefahren und vollendet wurde. Es kam zu keinerlei Fehlermeldung im Log der Java Anwendung, es wurde lediglich eine neue Datenbank-Connection abgerufen als der Service ausgefallen war.
Das Java Programm mit JTA/XA Konfiguration stieß zunächst nach mehr als einer Minute auf Fehlermeldungen des Transaktions-Managers, welcher die Operation abbrach und dem Aufrufer des REST Service einen HTTP Fehler 500 (“internal server error”) lieferte. Die Datensätze waren auch nicht aus der Datenbank gelöscht worden. Nach Erhöhung des JTA/XA Transaktions-Timeouts des Java Programms auf 3 Minuten konnte auch hier der Failover sauber und ohne Fehlermeldung durchlaufen und alle Datensätze löschen. Die Operation benötigte mehr als 1:15 Minuten, um zum Ende zu kommen. Hier schlug das XA Protokoll zu: statt in einer “replay” Operation alle von der Datenbank vorgemerkten Kommandos erneut auszuführen wurden -Operation für Operation- alle Kommandos zwischen Transaktionsserver und Datenbank abgeglichen (gesynced) und dann mit einer neuen Datenbank-Connection aber in derselben verteilten Transaktion fortgeführt. Diese Sync-Operationen verlängerten die Ausführung sehr stark, vor allem bei Verbindungen mit hoher Latenz wie der unseren (DSL-VPN mit 25ms Latenz). Aber auch hier wurden letztlich alle Datensätze sauber verarbeitet, d.h. gelöscht.
Kleiner Hinweis: der Helidon-Framework wie auch andere Jakarta EE 9.1-konforme Frameworks nutzen als Transaktionsmanager sicherlich “Arjuna”. Um dort den Transaktions-Timeout zu konfigurieren genügt eine kleine System Property beim Start des Java Programms wie diese:
-Dcom.arjuna.ats.arjuna.coordinator.defaultTimeout=180
Der ungeplante Ausfall bzw. “shutdown abort” testet das Verhalten des Notification Service und dessen Zusammenarbeit mit den Java Clients: fehlt die Datenbank ganz plötzlich, müssen alle Clients mit ihren laufenden Operationen dies mitbekommen. Ein Standard TCP-Timeout liegt bei einer laufenden Netzwerk-Operation (Daten holen, SQL an Datenbank schicken,…) oftmals bei 3 Minuten. Der ONS soll diese Zeitspanne auf ein Minimum reduzieren, indem die sehr kurzen Wartezeiten innerhalb des RAC an die Clients und deren UCPs weitergegeben werden. Diese Tests haben auch wie erwartet funktioniert, laufende Operationen wie das Löschen der Angestellten dauerten (dank knapper Timeouts im RAC) nun etwa 3 Sekunden länger bei simuliertem Ausfall gegenüber einem normalen Lauf ohne Datenbank-Unterbrechung. Das gilt wieder für non-XA und XA Transaktionen, wobei die ohnehin lange Laufzeit einer XA-Recovery kaum meßbar verlängert wurde, 3 Sekunden lagen da im Rahmen einer duldbaren Meßungenauigkeit.
Fazit:
Der JDBC Replay-Treiber in Kombination mit dem Universal Connection Pool ermöglicht aus unserer Sicht einen reibungsfreien Betrieb ohne abzufangende Fehlermeldung und kaum meßbaren Wartezeiten beim Ausfall eines RAC Datenbank-Knotens. Moderne Java Frameworks wie SpringBoot, Helidon, Micronaut, WildFly werden entweder direkt unterstützt oder sollten dennoch leicht verknüpfbar sein mit dem Oracle UCP, um einen Knoten-Ausfall sanft und transparent zu unterstützen. Es ist auf jeden Fall eine Überlegung wert, ob bisher genutzte JTA Transaktionen aus Versehen zu XA Transaktionen mutieren oder ob man fallbezogen nicht ganz auf JTA Transaktionen verzichten sollte. Egal welchen Betrieb man wählt, es kommt dennoch zu keinem Abbruch. Es bleibt nur die Frage der (Latenz-)Zeit und der Performance.
Links:
Erklärung und Set-Up von Transparent Application Continuity
Vortrags-PDF “Application Continuity explained”
Quellcode des Beispiel-Programms mit Helidon, UCP, JPA, TAC
Beispielprogramm mit UCP, SpringBoot und spring-jdbc
Beispielprogramm mit UCP, Spring Boot, GraphQL, JPA
Whitepaper “Whats in database 21c for Developers” ?