Accessibility Policy
Skip to content
Oracle
Database & Cloud Technology Blog
Search
Exit Search Field
Clear Search Field
Menu
CATEGORIES
26ai
Advisor
Autonomous Database
Cloud
Database Management
Development
English Content
JSON
Security
Spatial & Graph
SQL & PL/SQL
Blogs Home
RSS
Database & Cloud Technology Blog
Follow:
RSS
Facebook
Twitter
LinkedIn
YouTube
Instagram
4
Oracle API for MongoDB: Building and Scaling On-Premises Deployments
Witold Swierzy
8 minute read
Hands-On Hybrid Vector Search with Oracle Database 26ai
Ulrike Schwinn
9 minute read
Accessing and Using OCI: From API Keys to Workload Identity Federation
Michael Fischer
11 minute read
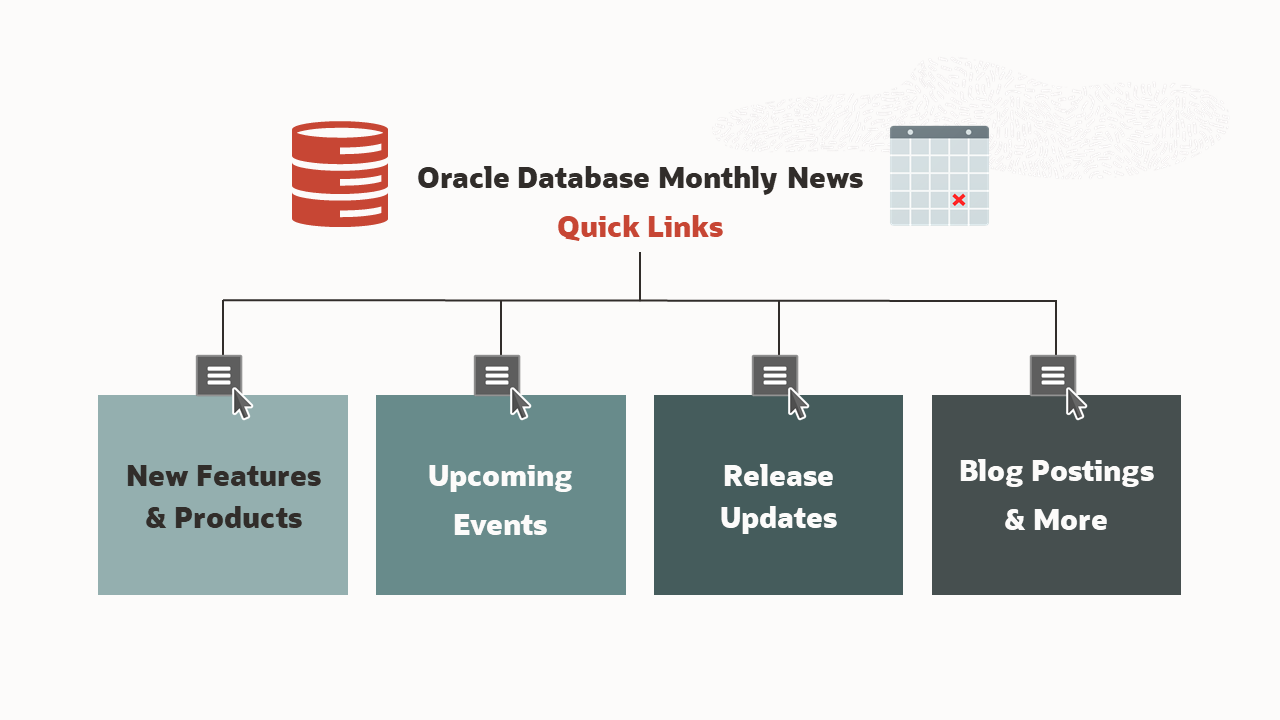
Oracle Database Monthly News – June 2026 – Quick Links
Ulrike Schwinn
Marcus Schroeder
5 minute read
Search Oracle Blogs
Search this site
Type your search term and press Enter.
Receive the latest blog updates
Subscribe to Oracle Connect email updates
Recent Posts
Oracle Datenbanken – Monthly News – Juni 2026 Ausgabe
Marcus Schroeder
1 minute read
Validating Fusion–IAM Trust for API Integrations
Michael Fischer
11 minute read
OCI Workload Identity Federation (WIF) with Microsoft Entra ID ...
Michael Fischer
8 minute read
Making Select AI Smarter with Database Annotations
Ulrike Schwinn
11 minute read
Oracle Datenbanken – Monthly News – Mai 2026 Ausgabe
Ulrike Schwinn
1 minute read
Oracle Database Monthly News – May 2026 – Quick Links
Sinan Petrus Toma
4 minute read
Behaviour of OCI IDP Policies in different IAM Domains
Michael Fischer
7 minute read
Automation of Oracle databases in the cloud – a selection
Marcel Boermann-Pfeifer
13 minute read
Automatisierung von Oracle Datenbanken in Clouds – eine Auswahl
Marcel Boermann-Pfeifer
13 minute read
Oracle Datenbanken – Monthly News – April 2026 Ausgabe
Ulrike Schwinn
1 minute read
Oracle Database Monthly News – April 2026 – Quick Links
Ulrike Schwinn
5 minute read
JSON_TABLE Meets 26ai: Metadata, Ubiquitous Search, and Hybrid Vector ...
Ulrike Schwinn
10 minute read
View more
Receive the latest blog updates
Subscribe to Oracle Connect email updates
Resources for
About
Careers
Developers
Investors
Partners
Startups
Why Oracle
Analyst Reports
Best CRM
Cloud Economics
Corporate Responsibility
Security Practices
Learn
What is Customer Service?
What is ERP?
What is Marketing Automation?
What is Procurement?
What is Talent Management?
What is VM?
What's New
Try Oracle Cloud Free Tier
Oracle Sustainability
Oracle COVID-19 Response
Oracle and SailGP
Oracle and Premier League
Oracle and Red Bull Racing Honda
Contact Us
US Sales 1.800.633.0738
How can we help?
Subscribe to Oracle Content
Try Oracle Cloud Free Tier
Events
News
© 2026 Oracle
Privacy
/
Do Not Sell My Info
Ad Choices
Careers