For native integration and recurring tasks in the setup and operation of software components in Kubernetes clusters, so-called “operators” have become established. Three of these operators from Oracle take care of the lifecycle of Oracle databases – and much more. Because not only from Oracle’s point of view do operators represent a link between application containers in a Kubernetes cluster and database containers in the same cluster or outside of it. This is because existing databases often have to be connected or they are hosted away from Kubernetes as separate server installations or as a cloud service. In this context, the operators presented here support both the integration of the Oracle database via Docker containers and via pluggable databases or PDBs, the database’s own container infrastructure, also called multitenant architecture. Since Oracle databases are operated as containers within the framework of the modern multitenant architecture, with provisioning times in the single-digit minute range, a central professional database operation is very compatible with the processes in DevOps organizations.
The three operators responsible for Oracle databases are:
- Oracle OCI Service Operator for Kubernetes (OSOK)
- Oracle Database Operator for Kubernetes (OraOperator)
- Kubernetes Operator for Oracle Cloud Management Pack (OracleCMP)
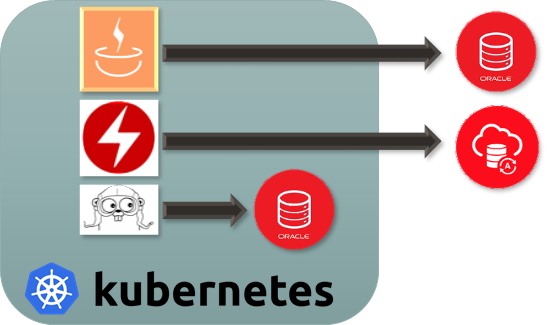
external on-premise & cloud, external as autonomous service and internal as container
with different operators and frameworks
About Kubernetes resources and operators in general
If one repeatedly needs components of the same type in a Kubernetes cluster, such as passwords, network services, file systems or configuration files, these can be made available using Kubernetes resources of the respective type. For example, if one needs a new repository for passwords, a new Kubernetes “secret” is created in the form of deployment information, often via a file in YAML format, which contains unrecognizable data and can be included and used by other resources, such as application containers. In addition to numerous predefined resources, Kubernetes is of course extensible with so-called “Custom Resources”. The programs and components integrated as custom resources act as a natural part of the Kubernetes cluster, even if they run outside of it and are merely referenced. This is an ideal way to include, for example, enterprise databases such as Oracle Database on external servers such as Exadata and on surrounding cloud environments. But of course, native integration of Oracle Databases is also possible via containers in the very same Kubernetes cluster.
In order to define new custom resources and also to operate them in the form of logic and code, two parts are usually required:
1) A custom resource definition must be stored in Kubernetes, i.e., as is often the case, a new type of resource is defined with the help of a file in YAML format and registered in the Kubernetes cluster. The definition includes the name of the new resource type (also called “child”) and usually two data structure descriptions. One data structure (“spec”) is used for parameterization when creating, modifying and also deleting a resource, the second data structure (“state”) is used for storing and retrieving state information and any other metadata.
2) An application container (“deployment”) must be defined that registers with the Kubernetes cluster as a so-called operator for the newly defined resource type and reacts to its target states such as new creation, modification and also deletion. The task of registering and accepting the events sent by Kubernetes is usually taken over by convenient frameworks and Kubernetes client APIs, it is usually just a matter of connecting your own logic with it.
Such operators can perform a wide variety of tasks based on the simple events Create, Update, Delete. For example, when a resource is created, not only can entire databases be recreated or even installed, but configurational steps are also possible, such as setting up clusters and network access, triggering database backups, booting and shutting down, sometimes also patching, e.g. by replacing containers with new versions, and finally also deleting databases that are no longer required.
In very general terms, operators take over and automate recurring tasks for the life cycle and operational running of the components or resources for which they are responsible.
About operators from Oracle
Several operators for different products such as WebLogic, Coherence, MySQL, Verrazzano and some more now come from Oracle. Thus, in addition to standard resources such as Services, Deployments, Secrets, WebLogicCluster, CoherenceCluster, SingleInstanceDatabase, InnoDBCluster and so on now exist. Each of these operators is a free open source extension to existing products and is viewable and downloadable on github.com. Support for these components is also available via github.com by creating new issues; the contributors behind the issues are the authors of the components and are part of the larger Oracle Development Team.
The Oracle database, as a particularly important component, was given three operators at once, which have different approaches. I would like to briefly introduce you to the three operators responsible for Oracle databases, what they are suitable for and what possibilities they offer.
1) Oracle OCI Service Operator for Kubernetes (OSOK)
This operator is available at https://github.com/oracle/oci-service-operator, was built using the Operator Framework for Go and the Controller runtime Library, and currently supports three Oracle Cloud Infrastructure (OCI) cloud services, including the MySQL Cloud Service, the Streaming Cloud Service, and the Autonomous Database Service.
The OSOK operator covers the following tasks specifically for Autonomous Databases:
- Creation of new Autonomous Service instances by defining them as a Custom Resource of the type “AutonomousDatabases”. Typical specifications for the cloud service in question must be made, e.g. the type of autonomous database such as OLTP or warehouse, database version such as 19c, number of cores to be used and storage size in terabytes.
- Connecting existing Autonomous Service instances by also defining them as a Custom Resource of type “AutonomousDatabases”. However, less information is required than for the creation of a new Autonomous Service; the so-called OCID of the existing Autonomous Instance and the specification of a Kubernetes Secret for connect information to the database are sufficient.
- Modification of framework parameters for Autonomous Service instances, e.g. number of cores, storage size or activation and deactivation of autoscaling
by a simple change in the YAML resource definition. - Filling a Kubernetes “Secret” for created or connected Autonomous Service instances with admin password, connect information and wallet with certificates contained therein. This Secret can then be easily used in other application containers, can be mounted as a virtual drive or via environment variables.
- Deletion of the cloud service instance when the resource is deleted is not currently provided for.
- The Autonomous Database Service comes as a fully managed service with cluster functionality, automatic backup and patching, so that an operator does not have to perform these functions himself.
An example YAML file for creating a new Autonomous Database instance looks like this:
#
# Copyright (c) 2021, Oracle and/or its affiliates. All rights reserved.
# Licensed under the Universal Permissive License v 1.0
# as shown at http://oss.oracle.com/licenses/upl.
#
apiVersion: oci.oracle.com/v1beta1
kind: AutonomousDatabases
metadata:
name: autonomousdatabases-sample
spec:
# Id: ocid1.autonomousdatabase.oc1.<region-code>.aaaaXXXXXXXXXXXXXXXXXXXX
compartmentId: ocid1.compartment.oc1..aaaaaaaaXXXXXXXXXXXXXXXXXXXXXXXXXXX
displayName: SampleADB
dbName: sampleadb
dbWorkload: OLTP
isDedicated: false
dbVersion: 19c
dataStorageSizeInTBs: 2
cpuCoreCount: 1
adminPassword:
secret:
secretName: admin-password
isAutoScalingEnabled: true
isFreeTier: false
licenseModel: BRING_YOUR_OWN_LICENSE
wallet:
walletName: sampleadb-wallet
walletPassword:
secret:
secretName: wallet-password
freeformTags:
key1: value1
# definedTags:
# test:
# key1: value1
2) Oracle Database Operator for Kubernetes (OraOperator)

Operator Framework for Go
+ Database
This operator was initially announced in summer 2021 (see blog announcement by Kuassi Mensah) and has since experienced several updates with added functionality, like support for pluggable databases. It is available for download on https://github.com/oracle/oracle-database-operator. It is written with the Kubernetes client for Go and supports multiple database constellations for on-premises installations and clouds. It is the most comprehensive operator with the most features and flexibility. The OraOperator communicates with autonomous databases in the Oracle Cloud Infrastructure(OCI), with single instance databases running as containers in the Kubernetes cluster as well as with a sharded database configuration, also running as a container in the Kubernetes cluster. In one of the next code drops, external Oracle databases can also be connected via the Oracle REST Data Management interface (Oracle REST Data Services).
The OraOperator covers the following tasks for Oracle Databases:
For “Autonomous Databases”:
- Creation of new Autonomous Service instances by defining them as Custom Resource of the type “AutonomousDatabase”. Similar specifications as for the OSOK operator must be made for the cloud service addressed.
- Binding of existing Autonomous instances (bind) similar to OSOK by specifying the OCID of the database to be bound.
- In addition, autonomous services can be started up and shut down, scaled, admin passwords can be changed, manual backups can be created in addition to the usual automatic backups
For “Database Cloud Service”:
- Provisioning new as well as binding to existing databases
- Scale Databases Up/Down
- Perform Liveness Probes
- Create Manual Backups
For “Single Instance Databases”:
- Creation of new Oracle Database Enterprise and Standard Edition instances by defining them as a custom resource of type “SingleInstanceDatabase”. The database instance is provisioned from an available Docker image and understands information about main memory, CPU and storage sizes, whether Flashback should be enabled and more.
- Creation of databases via cloning
- Patching of databases by specifying a container image with a newer patch version. Patches can also be rolled back.
For “Multitenant Databases”:
- Bind to a Container Database (CDB)
- Creation and Deletion of new pluggable databases (PDB),
- Cloning of PDBs,
- Plugging and unplugging PDBs,
- Opening and Closing PDBs
For “Sharded Databases”:
- Roll out a sharded database configuration by defining it as a custom resource of the type “ProvShard”. A Catalog Database, the Oracle Grid Infrastructure and any number of shards with specification of storage sizes, the number of which may also be varied subsequently for the purpose of scaling, are then created, in each case via container images.
- Add or remove shards
An example YAML file for creating a new Oracle Database as a container in a Kubernetes cluster would look like the following:
#
# Copyright (c) 2021, Oracle and/or its affiliates.
# Licensed under the Universal Permissive License v 1.0
# as shown at http://oss.oracle.com/licenses/upl.
#
apiVersion: database.oracle.com/v1alpha1
kind: SingleInstanceDatabase
metadata:
name: singleinstancedatabase-sample
namespace: default
spec:
## Use only alphanumeric characters for sid
sid: ORCL1
## A source database ref to clone from,
## leave empty to create a fresh database
cloneFrom: ""
## NA if cloning from a SourceDB (cloneFrom is set)
edition: enterprise
## Should refer to SourceDB secret if cloning from a SourceDB (cloneFrom is set)
## Secret containing SIDB password mapped to secretKey
## This secret will be deleted after creation of the database
## unless keepSecret is set to true
adminPassword:
secretName:
secretKey:
keepSecret: false
## NA if cloning from a SourceDB (cloneFrom is set)
charset: AL32UTF8
## NA if cloning from a SourceDB (cloneFrom is set)
pdbName: orclpdb1
## Enable/Disable Flashback
flashBack: false
## Enable/Disable ArchiveLog
archiveLog: false
## Enable/Disable ForceLogging
forceLog: false
## NA if cloning from a SourceDB (cloneFrom is set)
## Specify both sgaSize and pgaSize (in MB) or dont specify both
## Specify Non-Zero value to use
initParams:
cpuCount: 0
processes: 0
sgaTarget: 0
pgaAggregateTarget: 0
## Database image details
## Database can be patched by updating the RU version/image
## Major version changes are not supported
image:
pullFrom:
pullSecrets:
## size : Minimum size of pvc | class : PVC storage Class
## AccessMode can only accept one of ReadWriteOnce, ReadWriteMany
persistence:
size: 100Gi
storageClass: ""
accessMode: "ReadWriteMany"
## Type of service . Applicable on cloud enviroments only
## if loadBalService : false, service type = "NodePort". else "LoadBalancer"
loadBalancer: false
## Deploy only on nodes having required labels.
## Format label_name : label_value
## Leave empty if there is no such requirement.
## Uncomment to use
# nodeSelector:
# failure-domain.beta.kubernetes.io/zone: bVCG:PHX-AD-1
# pool: sidb
## Count of Database Pods. Applicable only for "ReadWriteMany" AccessMode
replicas: 1
3) Kubernetes Operator for Oracle Cloud Management Pack (OracleCMP)
This operator is an example implementation and can be extended for your own purposes. It is available at https://github.com/ilfur/k8s_operator_cloudmgmtpack and was written with the Java Operator SDK, which is based on the fabric8 Kubernetes Client API.
With the Oracle Cloud Management Pack, an extension package to Oracle Enterprise Manager Cloud Control 13c, you can set up your own “private” database cloud in your own data center, where Oracle databases in the form of “pluggable databases” (PDB) can be created, used and also deleted again via self service. Quotas provide a framework for end users within which resources can be used.
On the server side, servers (whether virtual or real) are organized into zones. In these zones, Oracle container databases (CDB) are prepared, which serve as an operating platform for the PDBs. Monitoring, backup processes and compliance checks are configured at the CDB level.
Groups of uniform CDBs are organized into pools. Templates are then used to formulate a service offering that describes the size, form and initial content of a PDB, as well as in which pool the new PDB is created.
Fleet Management and Fleet Patching are also part of the Cloud Management Pack, but will not be discussed further here.
In addition to a self-service web application provided by Oracle Enterprise Manager, there is also a REST API for using your own database cloud. With this REST API, centrally operated databases can be requested and created from Kubernetes via operator. The advantage of this approach is that these databases are automatically visible in Oracle Enterprise Manager, monitored and integrated into existing backup concepts.
As part of the Cloud Management Pack, it is also possible to calculate costs that can be charged to users of the private database cloud.
A Kubernetes operator for the Cloud Management Pack must of course cover the entire lifecycle of the database, including, for example, starting, stopping and deleting.
The OracleCMP operator supports the following options for Oracle Databases:
- Creation of new Pluggable Databases by defining them as Custom Resource of the type “OracleCMP”.
A few details have to be entered, such as the name of the database, the name of the workload type used to define the CPU and memory requirements, the name of a tablespace to be created, and the name of the database template, which can, for example, contain some predefined database objects or which also executes the corresponding SQL Create scripts when the database is created. - Storage of connection information (Connect String) and administration password in a Kubernetes ConfigMap and a Kubernetes Secret. The OracleCMP operator obtains this information through corresponding REST calls to the Cloud Management Pack. Both ConfigMap and Secret can be made available to other application containers as a virtual drive or as environment variables.
- Deletion of the pluggable database when the OracleCMP resource is removed. This is done in the same way as creating the database via a REST call to the Cloud Management Pack. A request ID generated by the Cloud Management Pack is stored in the “state” of the OracleCMP resource and is used to uniquely identify the Pluggable Database.
- The Cloud Management Pack still understands as a possible operation the startup and shutdown of databases as well as the triggering of unscheduled backups. These functions are not yet supported in the OracleCMP operator. This also applies to binding to an already existing pluggable database, which was created in advance by the Cloud Management Pack. In one of the next code drops these functions will be implemented.
An example YAML file for creating a new Oracle Database via the Cloud Management Pack would look like this:
apiVersion: "sample.database.oracle/v1" kind: OracleCMP metadata: name: k8spdb namespace: oraclecmp-operator spec: pdbaas_zone: "K8Szone" pdbaas_template: "K8Stemplate" pdbaas_workload: "DefaultWorkload" pdbaas_service: "k8spdb" pdbaas_tbs: "pdb_tbs1" department: "Development" comment: "Operator on k8s Testing"
Conclusion
Several Kubernetes operators for Oracle Databases have emerged in the recent past. The operator with the most attention from the Oracle Development Team and with the most supported features is the OraOperator. It will support even more database constellations in the future and already offers more features in dealing with Autonomous Databases than others.
I will be happy to support you with the integration of one of the operators or mediation in case of problems and requests.
Good luck with testing !