 Mit der Unterstützung von GraphQL-Abfragen in den neuen Oracle REST Data Services (ORDS) 23.3 kommt eine weitere Graph-Engine zur Oracle Database hinzu. Sollte man aufgrund unterschiedlicher Herkünfte und Ansätze lieber keinen Vergleich zu Property Graphen oder zu RDF Graphen bzw. Ontologien anstellen, oder was genau macht die Engines so unvergleichlich ?
Mit der Unterstützung von GraphQL-Abfragen in den neuen Oracle REST Data Services (ORDS) 23.3 kommt eine weitere Graph-Engine zur Oracle Database hinzu. Sollte man aufgrund unterschiedlicher Herkünfte und Ansätze lieber keinen Vergleich zu Property Graphen oder zu RDF Graphen bzw. Ontologien anstellen, oder was genau macht die Engines so unvergleichlich ?
An kurzen Beispielen soll gezeigt werden, wie die neue GraphQL-Unterstützung mit ORDS 23.3 funktioniert und wo ihr Einsatzgebiet liegt im Vergleich zu Property Graphen in der Oracle Database.
Die Neuigkeiten in Kürze
Seit dem letzten Beitrag zu GraphQL mit WebLogic und der Google graphql-API, mit Spring oder mit Java Microprofile im Jahre 2021 haben sich einige Dinge getan. Die Zahl der GraphQL-Projekte bei Unternehmen aller Branchen ist deutlich in die Höhe gegangen. Oracle’s OpenSource Framework Helidon liegt nun in Version 4 vor und bietet neben Java Microprofile 6 Support deutlich bessere Performance für REST Services und damit auch für GraphQL. Dies geschieht dank eines noch weiter optimierten HTTP Servers “Nìma” (statt bisher Netty) und dessen Unterstützung für virtuelle Threads des JDK 21. Die verteilte Java InMemory Datenbank Coherence unterstützt ebenfalls virtuelle Threads und ist noch enger mit Helidon (und GraphQL) integriert.
Die Oracle Database 23c hat die Unterstützung für Property Graphen in den Kern der Datenbank integriert. Dies ist möglich geworden durch die Erweiterung des SQL Standards 2023 um Property Graph Queries. Verschiedene Hersteller von Graph Datenbanken haben an dieser Erweiterung des SQL Standards zusammengearbeitet. Die Oracle Datenbank 23c ist die erste Implementierung in einer kommerziellen und Open-Source Datenbank.SQL/PGQ ist Oracle´s bisheriger Abfragesprache PGQL für Property Graphen sehr ähnlich.
Die Unterstützung für Ontologien durch Speicherung und Abfrage von Triplet-Informationen per W3C-Standard SPARQL, eingebettet in Oracle SQL Funktionen, wurde durch bessere Visualisierungs-Werkzeuge und APEX-Plugins vertieft wie z.B. durch Graph Visualizer. Dieser unterstützt neben RDF Ontologien und SPARQL auch die Visualisierung von Property Graphen und Abfragen per SQL/PGQ.
Für REST Services, die aus Datenbank-Objekten erzeugt wurden, steht seit jüngstem mit Oracle REST Data Services (ORDS) Version 23.3 die Abfragesprache GraphQL zur Verfügung. Der ORDS Container erzeugt im laufenden Betrieb nutzbare GraphQL Strukturen aus Datenbank-Objekten, ganz ohne Programmierung. Diese können sofort in der mitgelieferten browser-basierten Oberfläche “graphiql” getestet und geskriptet werden.
Gibt es einen Gewinner-Standard, der alles kann und alles ersetzen wird ?
Nein. Alle drei Graph-Engines haben ihr bevorzugtes Einsatzgebiet, eigene Herkunft und dauerhaften Nutzen. Sie ließen sich jeweils ineinander einbetten oder klammern, zum Beispiel mit SQL Mitteln einer converged Database, die alle Standards beherrscht… oder letzten Endes könnte man sie als super-generische weltbeschreibende Ontologie über alles hinweg formulieren.
![]() GraphQL hat seinen Ursprung und sein Einsatzgebiet in der Entwicklung von REST Services und ist für Backend-Entwickler gedacht. Verschiedene REST Services und mittlerweile auch beliebige Datenquellen lassen sich zu einem übergreifenden Datenmodell und Service zusammenschalten. Ursprünglich disjunkte Services und Daten können miteinander in Relation gebracht, zu einem “Über-Graphen” zusammengeschaltet werden. Die GraphQL Engine entscheidet bei einer Anfrage, welche der zur Verfügung stehenden Dienste tatsächlich aufgerufen werden müssen und tut dies parallel. So können Performance und übertragene Datenmenge optimiert werden, “right-fetching” genannt. Das Ergebnis von Abfragen per GraphQL sind immer JSON Baum-Strukturen, dessen Attribute entweder “Skalare” sind, d.h. einfache Datentypen oder “Objekte”, Untertypen oder Unter-Graphen. In letzterem Fall steht der Name des Attributs für eine benannte Beziehung zu einem Unter-Graphen. , um sich ein wenig von objektorientierten Baum-Modellen zu lösen…
GraphQL hat seinen Ursprung und sein Einsatzgebiet in der Entwicklung von REST Services und ist für Backend-Entwickler gedacht. Verschiedene REST Services und mittlerweile auch beliebige Datenquellen lassen sich zu einem übergreifenden Datenmodell und Service zusammenschalten. Ursprünglich disjunkte Services und Daten können miteinander in Relation gebracht, zu einem “Über-Graphen” zusammengeschaltet werden. Die GraphQL Engine entscheidet bei einer Anfrage, welche der zur Verfügung stehenden Dienste tatsächlich aufgerufen werden müssen und tut dies parallel. So können Performance und übertragene Datenmenge optimiert werden, “right-fetching” genannt. Das Ergebnis von Abfragen per GraphQL sind immer JSON Baum-Strukturen, dessen Attribute entweder “Skalare” sind, d.h. einfache Datentypen oder “Objekte”, Untertypen oder Unter-Graphen. In letzterem Fall steht der Name des Attributs für eine benannte Beziehung zu einem Unter-Graphen. , um sich ein wenig von objektorientierten Baum-Modellen zu lösen…
![]() PGQL als auch das im SQL:2023 Standard enthaltene SQL/PGQ sind ähnlich wie GraphQL in der Lage, “Über-Graphen” auf bereits bestehende Strukturen zu definieren, hier jedoch ausschließlich Datenbank-Strukturen wie Tabellen und Views. Damit können beliebige Beziehungen frei benannt und definiert werden und sind nicht länger nur als “master-detail” sichtbar. Die Stärke von SQL/PGQ liegt in der Analyse der Metadaten, komplexer Beziehungen von Information. So können selbst tief hierarchische oder auch zyklische Beziehungen aufgelöst, kürzeste Pfade mit den wenigsten “hops” berechnet oder zirkulare Abhängigkeiten gefunden werden, um z.B. Geldwäsche durch Dreiecks- oder Vielecks-Buchungen aufzudecken. Weitergehende Analysen von Graphen sind durch die Nutzung von Graph Algorithmen und Graph Machine Learning möglich, die über Oracle´s Graph Server zur Verfügung stehen. Weiterführende Informationen dazu gibt es u.a. in der Dokumentation.
PGQL als auch das im SQL:2023 Standard enthaltene SQL/PGQ sind ähnlich wie GraphQL in der Lage, “Über-Graphen” auf bereits bestehende Strukturen zu definieren, hier jedoch ausschließlich Datenbank-Strukturen wie Tabellen und Views. Damit können beliebige Beziehungen frei benannt und definiert werden und sind nicht länger nur als “master-detail” sichtbar. Die Stärke von SQL/PGQ liegt in der Analyse der Metadaten, komplexer Beziehungen von Information. So können selbst tief hierarchische oder auch zyklische Beziehungen aufgelöst, kürzeste Pfade mit den wenigsten “hops” berechnet oder zirkulare Abhängigkeiten gefunden werden, um z.B. Geldwäsche durch Dreiecks- oder Vielecks-Buchungen aufzudecken. Weitergehende Analysen von Graphen sind durch die Nutzung von Graph Algorithmen und Graph Machine Learning möglich, die über Oracle´s Graph Server zur Verfügung stehen. Weiterführende Informationen dazu gibt es u.a. in der Dokumentation.
 SPARQL ist die Abfragesprache über Ontologien im RDF, OWL, Turtle Austausch-Format (und weiteren). Beziehungen und Nutzdaten vermischen sich, es wird inzwischen nicht länger zwischen Daten und Metadaten unterschieden. Ich persönlich habe Ontologien vorrangig zur Modellierung, Dokumentation komplexerer Systeme und für den Daten-Lookup in standardisierten Datenbeständen verwendet. Hier werden normalerweise keine Graph- und Beziehungs-Strukturen an bereits bestehende Tabellen oder REST Services “geflanscht”, sondern komplette Graphen mit allen Elementen gepflegt, ausgetauscht, angehängt bzw. verknüpft. Und, sehr sinnvoll, lassen sich u.a. Beziehungen (die Kanten in einem Graphen, die Prädikate in einem Triplet) standardisieren und können im Internet in Form von Vokabular-Bibliotheken abgerufen werden. Diese Bibliotheken sind ihrerseits dokumentierte Graphen, die man in die eigene Ontologie einbinden kann. So lassen sich gleichzeitig mehrere Beziehungs- und Format-modelle in einem Graphen unterbringen, z.B. ein generisches Organisations-Vokabular (memberOf, hasMember usw), eine erschöpfende Menge medizinischer Fachbegriffe, Diagnosen, Wirkstoffe (SNOMED CT) oder technisches Vokabular zum Aufbau von JSON Schema Strukturbeschreibungen. Und noch vieles, vieles mehr, sowohl (IT-)technisch als auch Fachbezogen.
SPARQL ist die Abfragesprache über Ontologien im RDF, OWL, Turtle Austausch-Format (und weiteren). Beziehungen und Nutzdaten vermischen sich, es wird inzwischen nicht länger zwischen Daten und Metadaten unterschieden. Ich persönlich habe Ontologien vorrangig zur Modellierung, Dokumentation komplexerer Systeme und für den Daten-Lookup in standardisierten Datenbeständen verwendet. Hier werden normalerweise keine Graph- und Beziehungs-Strukturen an bereits bestehende Tabellen oder REST Services “geflanscht”, sondern komplette Graphen mit allen Elementen gepflegt, ausgetauscht, angehängt bzw. verknüpft. Und, sehr sinnvoll, lassen sich u.a. Beziehungen (die Kanten in einem Graphen, die Prädikate in einem Triplet) standardisieren und können im Internet in Form von Vokabular-Bibliotheken abgerufen werden. Diese Bibliotheken sind ihrerseits dokumentierte Graphen, die man in die eigene Ontologie einbinden kann. So lassen sich gleichzeitig mehrere Beziehungs- und Format-modelle in einem Graphen unterbringen, z.B. ein generisches Organisations-Vokabular (memberOf, hasMember usw), eine erschöpfende Menge medizinischer Fachbegriffe, Diagnosen, Wirkstoffe (SNOMED CT) oder technisches Vokabular zum Aufbau von JSON Schema Strukturbeschreibungen. Und noch vieles, vieles mehr, sowohl (IT-)technisch als auch Fachbezogen.
Teil 1: GraphQL
Wie installiert man es ?
Erste Abfragen mit GraphQL
Weitere Beziehungen einbinden
Beziehungen zu JSON Dokumenten
Beziehungen zu REST Services
Visualisierung von GraphQL Graphen
Teil 2: SQL/PGQ
Vorbereitung
Definition eines Graphen
Einfache Abfragen
Abfragen auf Metadaten
Visualisierung von Property Graphen
Teil 1: GraphQL
GraphQL mit Oracle Database – wie installiert man es ?
In einem Blog Eintrag von Jeff Smith wird erklärt, wie man den neuen ORDS 23.3 mit GraphQL Unterstützung aufsetzt. Im Prinzip sind für erste Tests folgende Schritte sinnvoll:
- Die neueste Version von ORDS (23.3 oder höher) herunterladen.
- GraalVM EE für JDK 17 herunterladen und installieren, NICHT das OpenJDK oder Oracle JDK, auch nicht GraalVM Community Edition.
- JavaScript Unterstützung für GraalVM herunterladen und installieren: richtig, die GraphQL Engine wurde in server-seitigem JavaScript geschrieben.
bei freiem Internet-Zugang zu den GraalVM Downloads darf auch der “Graal Updater” seine Komponenten direkt nachladen:
gu install js
Oder in allen anderen Fällen wählen Sie auf der GraalVM Download Seite “JavaScript Runtime” aus, laden Sie herunter und installieren die Datei lokal:
gu -L install js-installable-svm-svmee-java17-windows-amd64-22.3.1.jar (oder andere Versionsnummer)
- ORDS mit einer bestehenden Oracle Database 19c oder höher verknüpfen.
<graalvm_home>/bin/java -jar ords.war install
Nun sind diverse Fragen zu beantworten, z.B. alle Features sind zu installieren sowie Datenbank-Benutzer und Connect Informationen anzugeben. Dann:
<graalvm_home>/bin/java -jar ords.war serve
Dies startet den lokalen ORDS Server bei default-Angaben auf http Port 8080.
- Einen Datenbank Demo-Benutzer anlegen und für REST Zugriffe aktivieren.
Falls nicht bereits vorhanden ist zu empfehlen, das HR Demo-Schema zu erzeugen und dann zu verwenden. Die nötigen SQL Skripte um den Benutzer mit seinen Tabellen anzulegen befinden sich einerseits im ORACLE_HOME Ihrer Datenbank im Unterverzeichnis /demo/schema/human_resources, oder seit wenigen Jahren auch auf github zum Download.
Bitte verwenden Sie dafür einen privilegierten Benutzer wie SYS oder SYSTEM und ein Tool Ihrer Wahl, z.B. SQLcl oder SQL*Plus.
Wurde der Benutzer angelegt können Sie ihn auch gleich mit folgendem SQL sowohl für REST Zugriffe als auch für das Browser Tool “SQL Developer Web” bzw. die “Database Actions” Tool-Palette freischalten.
BEGIN ORDS.ENABLE_SCHEMA(p_enabled => TRUE, p_schema => 'HR' ); END; / - Aktivieren Sie nun die HR Demo-Tabellen für REST Zugriffe.
Wir werden später noch Views und eine JSON Tabelle hinzufügen um Features zu vertiefen. Fürs Erste genügt als Benutzer “HR” unter SQL*Plus oder SQLcl:BEGIN ORDS.enable_object ( p_schema => 'HR', p_object => 'EMPLOYEES', p_object_alias => 'employees'); ORDS.enable_object ( p_schema => 'HR', p_object => 'DEPARTMENTS', p_object_alias => 'departments'); ORDS.enable_object ( p_schema => 'HR', p_object => 'LOCATIONS', p_object_alias => 'locations'); COMMIT; END; /
- Bitte starten Sie den ORDS Container nun durch. Er erzeugt beim Start aus den publizierten Tabellen und Views eine GraphQL-Datenstruktur und hält sie für 8-24 Stunden (default Parameter) im Cache.
Die ORDS Parameter cache.metadata.graphql.expireAfterAccess und cache.metadata.graphql.expireAfterWrite könnten indes auch auf wenige Minuten gesetzt werden, rein zu Testzwecken um den ORDS nicht permanent mit dem Aufbau von GraphQL-Strukturen zu belasten.
- Die GraphQL-App “Graphiql” aufrufen und erste Queries formulieren. Mit einem Browser Ihrer Wahl müßte Sie ein Aufruf der URL http://127.0.0.1:8080/ords/hr/_/graphiql/
zur “graphiql” Oberfläche bringen, mit der Sie die Objekte als Benutzer “HR” einsehen und abfragen können, die gerade eben für REST Zugriffe freigegeben wurden: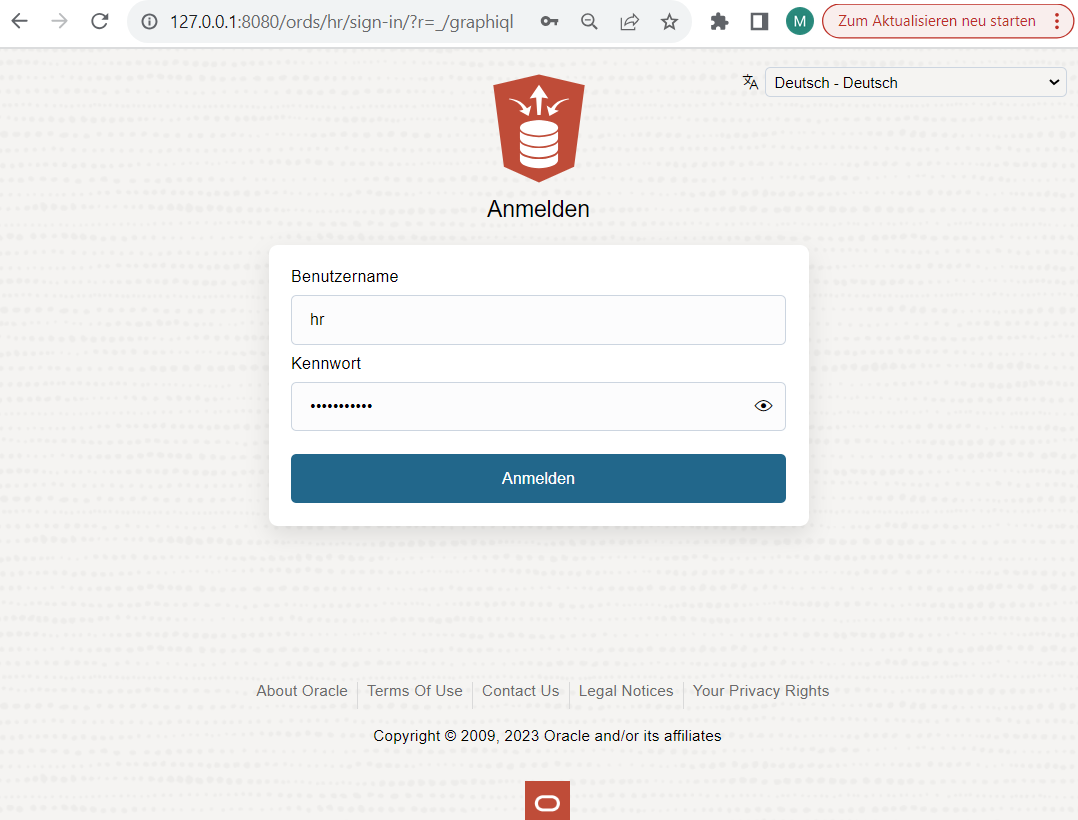

- Gratulation! Installation und erste Einrichtung sind erfolgt, schreiten wir nun zur Tat und schauen nach, was hier möglich ist.
Erste Abfragen mit GraphQL
Klicken Sie links im Fenster zunächst auf das Icon “Documentation Explorer” und lassen Sie sich dadurch anzeigen, welche Datentypen ORDS beim Start ausgelesen hat.
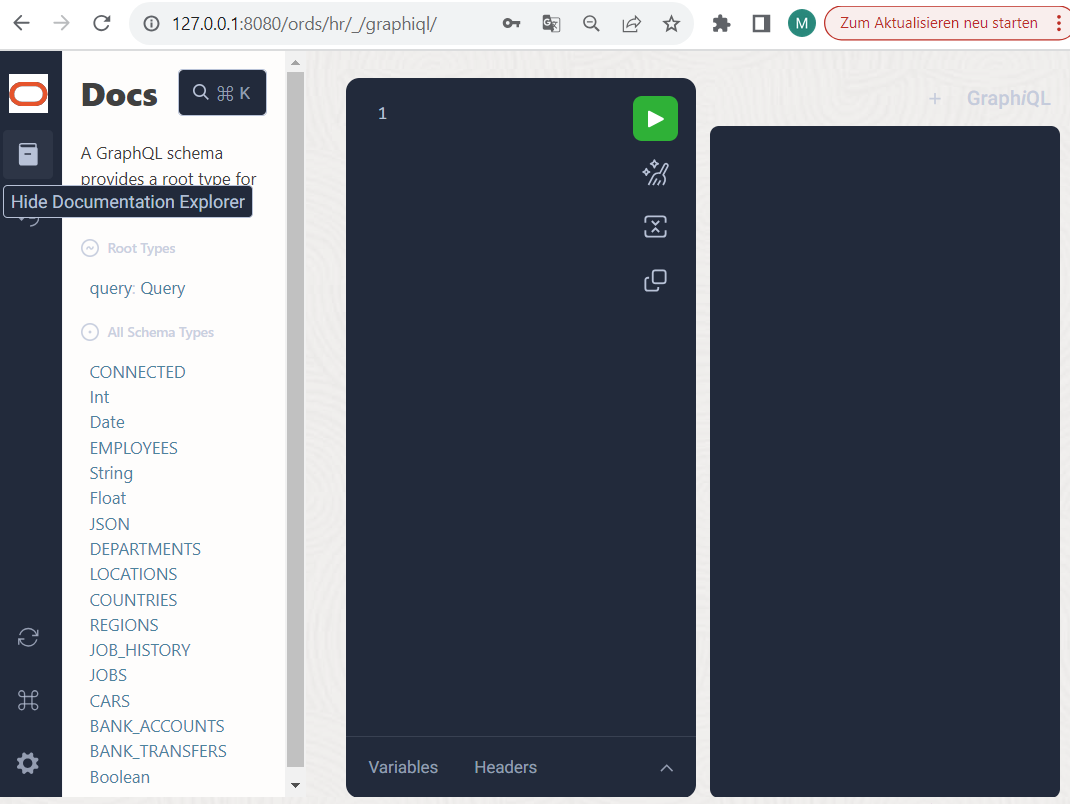
Als “Root Type” wird hier ausschließlich eine Query angeboten. Weitere mögliche Root Types in GraphQL wie Mutation (Datenänderung) und Subscription (“Abonnement” bzw. Mitteilung von Änderungen) werden aktuell noch nicht unterstützt. Aber bereits die Queries haben es in sich und bieten einige Features, die anderweitig erst aufwändig zu programmieren wären. Das werden wir uns gleich noch näher anschauen.
In unserer Beispiel-Umgebung sind bereits deutlich mehr Schema-Typen vorhanden als bei Ihnen vermutlich angezeigt werden. Neben einiger “Skalar” Datentypen wie String, Int, Date, Float, Boolean usw. müßten bei Ihnen einige “Objekt” Datentypen existieren wie DEPARTMENTS, EMPLOYEES und LOCATIONS. Die Datentypen sind anklickbar und bieten eine Beschreibung ihrer Struktur, d.h. einerseits Attribute mit skalaren Datentypen dahinter oder andererseits Beziehungs-Attribute, die auf Untertypen verweisen.
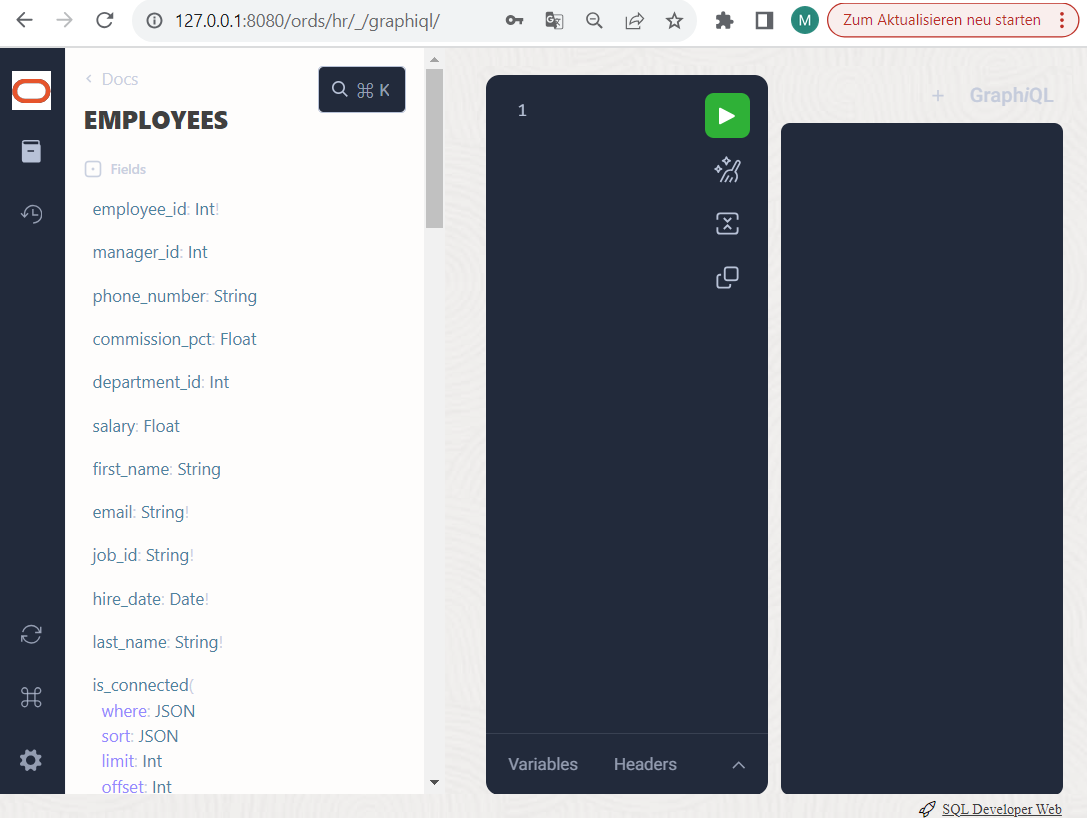
Zum Beispiel haben EMPLOYEES eine gerichtete Beziehung zu DEPARTMENTS über das Beziehungs-Attribut “departments_departments_id”. Dieses Attribut wurde automatisch aus dem Namen der zugrunde liegenden Zieltabelle erzeugt sowie aus dem Namen des dortigen Primärschlüssels. Das sind noch keine sehr sprechenden Namen für Beziehungen, aber wir können uns dabei in weiteren Beispielen über Datenbank-Views behelfen. Das aber später.
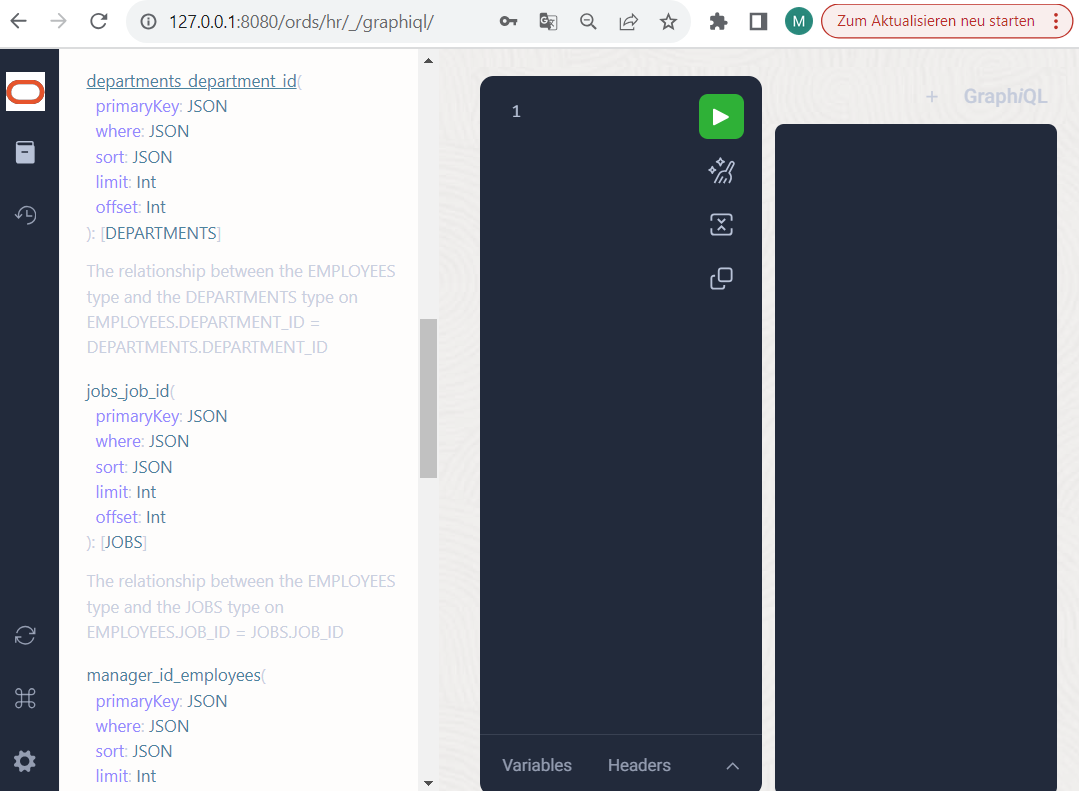
Wie Sie auch erkennen können, bieten Beziehungstypen immer die Möglichkeit Daten zu filtern, zu sortieren, zu limitieren oder auch zu “paginieren”, d.h. per Angabe von sort+offset+limit seitenweise zu überspringen. Beginnen wir mit einer einfachen Query auf das Einstiegs-Objekt EMPLOYEES, um uns daraus eine Baumstruktur erzeugen zu lassen.
Tippen Sie im Abfrage-Feld neben der “1” den Begriff “query“, gefolgt vom gewünschten Namen Ihrer Query (“myFirstQuery”) und einer geschweiften Klammer. Danach hilft Ihnen graphiql bei der Auswahl der von Ihnen gewünschten Attribute und Beziehungen durch Angabe der Tastenkombination <STRG>+<LEERTASTE>.
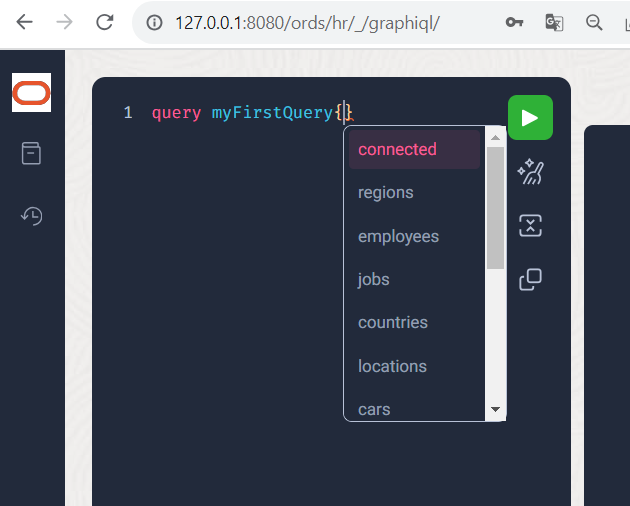
Wählen Sie nun das Query-Attribut “employees” (eine Beziehung zu allen Objekten vom Typ EMPLOYEES), gefolgt von einer geschweiften Klammer. Innerhalb der geschweiften Klammer drücken Sie erneut die Tastenkombination <STRG>+<LEERTASTE>, so daß Sie sich die Attribute first_name last_name salary (per Leerzeichen oder Komma getrennt) auswählen. Danach ein beherzter Klick auf das “Besen”-Symbol (Prettify Query) und Ihre Query wird ansehnlich aufbereitet.
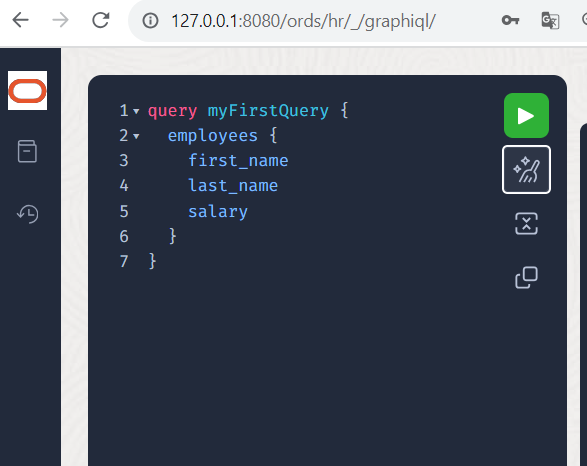
Klicken Sie nun auf das grün-weiße Pfeil-Symbol und führen Sie die Query damit aus.
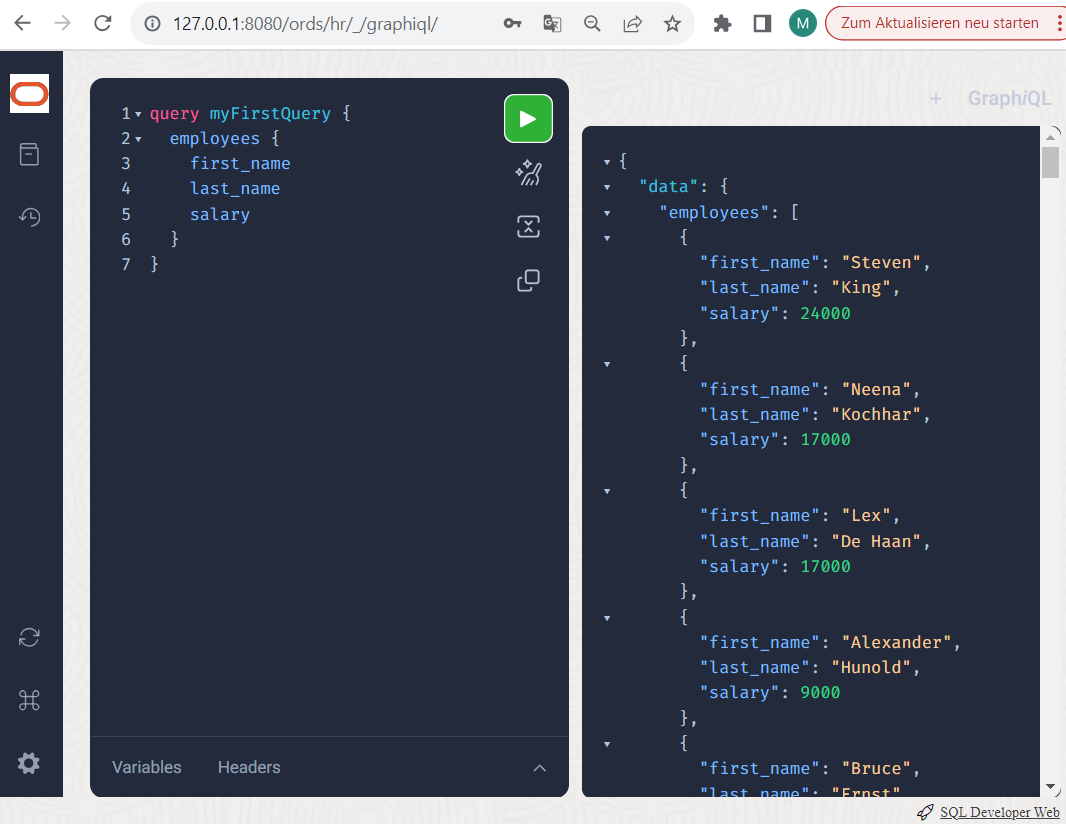
Spielen Sie nun ein wenig mit Filtern und Sortierung. Hängen Sie gleich hinter das “employees” Attribut eine runde Klammer auf und zu, dann geben Sie erneut <STRG>+<LEERTASTE> an um eine where-Bedingung auszuwählen und eine JSON Syntax anzugeben (diesmal leider ohne Hilfe) wie diese:

Die Filter lassen sich auch auf die jeweiligen Beziehungstypen bzw. Unterabfragen anwenden. Die Syntax für where-Filter ist sehr umfassend und darf sehr komplex geschachtelt sein, eine umfassendere Beschreibung finden Sie in der ORDS Dokumentation. Das eine oder andere weiterführende Beispiel finden Sie in den Blog Einträgen von Jeff Smith, unserem ORDS-“Papst”.
Ein etwas umfassenderes Beispiel mit Sortierung, Filterung und Pagination könnte wie folgt aussehen. Bitte beachten Sie, daß die Sortierungs-Kriterien in ein Array “[]” verpackt sind, weil es auch einmal mehrere Kriterien sein könnten.
employees(where: {first_name: {eq: "Steven"}},
sort: [{last_name: "asc"}],
limit: 1
offset: 1 ) {
first_name
last_name
salary
}
}
Eine weitere Beziehung anlegen und einbinden
Beliebige weitere Beziehungen mit sprechenderen Beziehungsnamen aber auch mit beliebig komplexer Logik zur Ermittlung der Beziehung können über relationale Views angelegt werden. Um zusätzliche Attribute zwischenzuspeichern oder ein “Mapping” zwischen Quell-Knoten und Ziel-Knoten herzustellen werden üblicherweise sogenannte N:M-Beziehungstabellen bemüht. Wenn als Beispiel nicht nur hierarchisch dargestellt werden soll, welcher Vorgesetzter mit welchen Angestellten eine Abteilung bildet, sondern viel eher welche der Angestellten sich untereinander persönlich kennen, so wäre nachfolgender Ansatz vielleicht sinnvoll. Zunächst einmal als Skript dargestellt und im “HR” Schema ausgeführt:
INSERT INTO FACEBOOK (from_id, to_id, since) values (102, 100, to_date('01.01.2010'));
INSERT INTO FACEBOOK (from_id, to_id, since) values (100, 102, to_date('01.01.2015'));
INSERT INTO FACEBOOK (from_id, to_id, since) values (102, 101, to_date('01.01.2005'));
INSERT INTO FACEBOOK (from_id, to_id, since) values (101, 100, to_date('01.01.1999'));
COMMIT;
CREATE VIEW CONNECTED ("IS", "TO", SINCE) AS SELECT FROM_ID, TO_ID, SINCE FROM FACEBOOK;
ALTER VIEW CONNECTED
ADD CONSTRAINT FROM_FK FOREIGN KEY ( "IS" )
REFERENCES HR.EMPLOYEES ( EMPLOYEE_ID ) DISABLE ;
ALTER VIEW CONNECTED
ADD CONSTRAINT TO_FK FOREIGN KEY ( "TO" )
REFERENCES HR.EMPLOYEES ( EMPLOYEE_ID ) DISABLE ;
BEGIN
ORDS.enable_object ( p_schema => 'HR', p_object => 'CONNECTED', p_object_type => 'VIEW', p_object_alias => 'connected');
END;
Zur Erklärung: wir legen zunächst eine Tabelle “FACEBOOK” an und tragen ein, welche Person aktiv andere Personen kennt, und seit wann.
Nun erzeugen wir eine View darüber mit sprechenderen Namen für die spätere GraphQL-Abfrage. Und wir stellen noch zwei relationale Beziehungen her zwischen FACEBOOK und EMPLOYEES. Diese sind aber deaktiviert und sollen keine Auswirkungen haben, sie dienen nur dazu daß die GraphQL-Engine diese Beziehungen erkennt und seinerseits Beziehungstypen erzeugt. Eventuelle andere Beziehungen der Basis-Tabelle “FACEBOOK” bleiben davon unberührt. Es wird auch nur die View CONNECTED für den Zugriff per GraphQL freigeschaltet, die FACEBOOK Tabelle soll verborgen bleiben.
Starten Sie nun bitte zunächst den ORDS Container durch, damit der Neuzugang im Datenmodell auch erkannt wird. Lesen Sie dann das Schema in graphiql neu ein durch Klick auf das Refetch-Symbol links unten am Bildrand.
Nun läßt sich sehr schön die freie Beziehung zwischen den Angestellten und dem “who-knows-who” in GraphQL darstellen und abfragen. Legen Sie hierfür eine zweite Query an und gehen Sie ein wenig durch die Hierarchie hindurch: Der Angestellte mit der ID 100 hat welchen Namen und kennt welche anderen Personen und seit wann ?
employees(where: {employee_id: {eq: 100}}) {
first_name
last_name
is_connected {
since
connected_to {
first_name
last_name
}
}
}
}
Zur Ausführung der Query können Sie durch Klick auf den grünen Knopf aus einer Liste der definierten “named” Queries wählen:
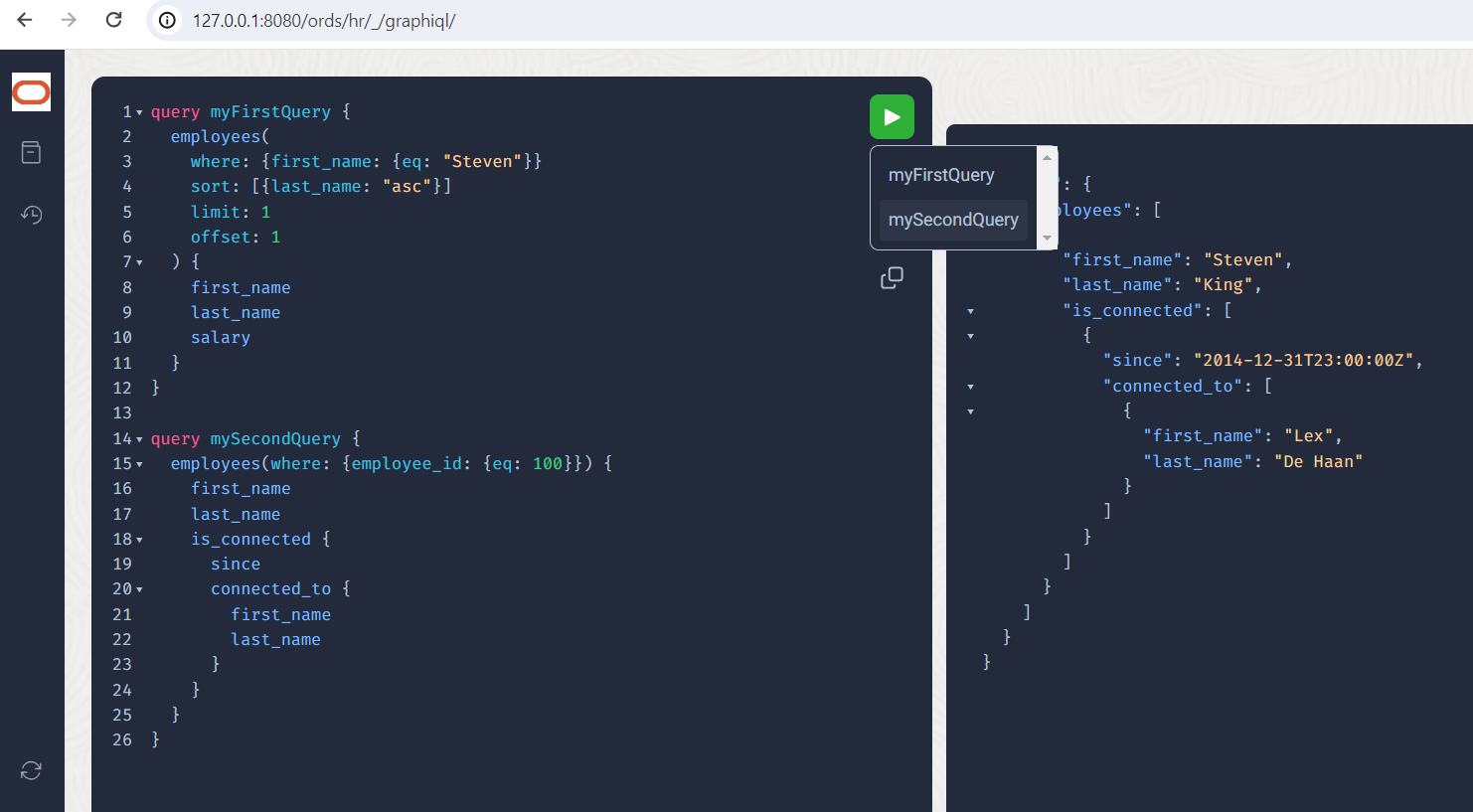
Kommen wir zu einer absichtlichen Limitierung der Schachtelungstiefe, um tief-zyklische Abfragen zu vermeiden und vielleicht DoS-Attacken abzuwenden. Wen kennt Herr King, und wen kennen wiederum diese Menschen ?
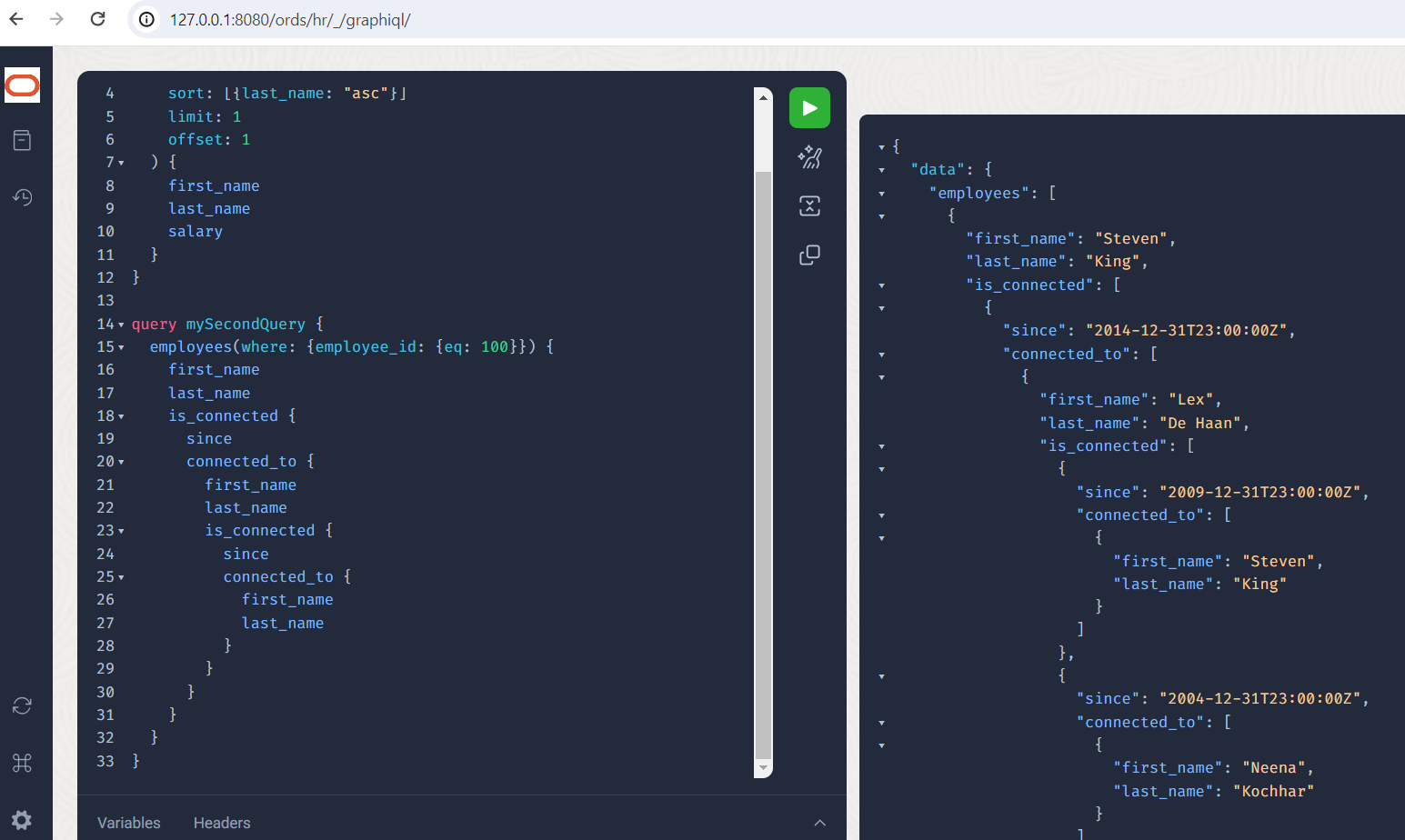
Sieh an, Herr King kennt Herrn De Haan, und der kennt Herrn King ebenso, aber aus einer anderen Zeit.
Filtern wir uns diese Beziehungsdaten heraus und schauen, wie tief wir hier verketten könnten:
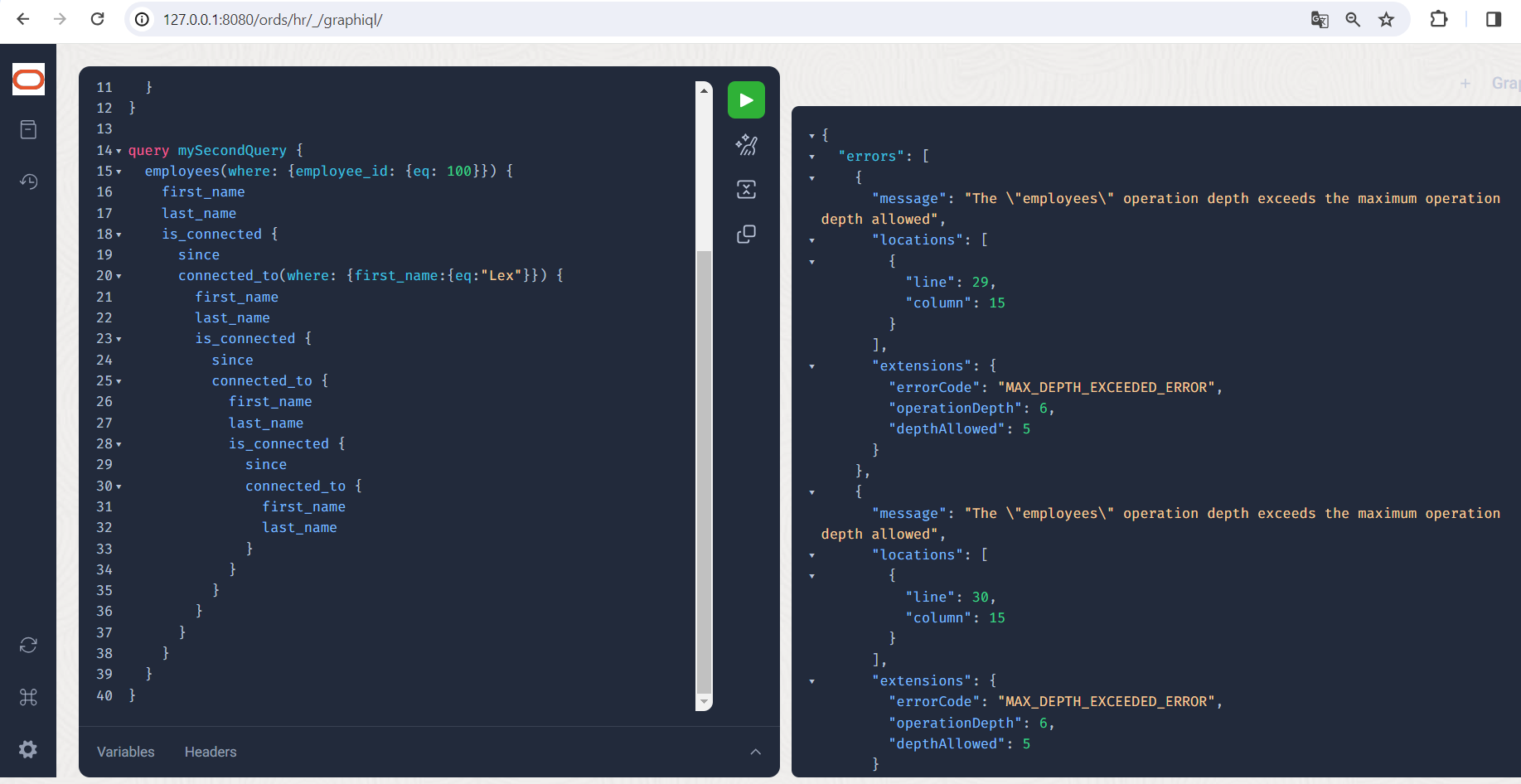
Leider kommen wir nicht sehr weit, es kommt zur Fehlermeldung “MAX_DEPTH_EXCEEDED_ERROR”. Abfragen dürfen per Default nicht tiefer rekursieren als 5 Ebenen: employees->is_connected->connected_to->is_connected->connected_to sind gewissermaßen 5 “hops”, mehr sollte lieber nicht sein. Durch einen Parameter in der Konfigurationsdatei pools.xml bzw. settings.xml läßt sich diese Grenze jedoch verschieben. Der Parameter hierfür lautet feature.grahpql.max.nesting.depth und ist selbstverständlich dokumentiert.
An dieser Stelle sei erwähnt, daß SQL/PGQ seine Stärken hier ganz besonders ausleben könnte. Abfragen auf die Beziehungs- bzw. Rekursionstiefe und Beziehungs-Metadaten sind möglich, auch ohne jede einzelne Beziehungsart angeben zu müssen. Beispielsweise eine Abfrage der Art “Zeige an, über wieviele Hops Angestellter A mit B bekannt ist, sortiere nach der Zahl der Hops” ermittelt die direkten und indirekten Bekanntschaften, den kürzesten Pfad zwischen zwei Personen. Dies aber später im Teil 2 über SQL/PGQ.
Beziehungen zu JSON Dokumenten definieren
GraphQL war dazu gedacht, Beziehungen zwischen REST Services und den daraus resultierenden Daten herzustellen. Ein übergeordnetes Datenmodell, ein Graph, beschreibt die gesamte Datenstruktur über alle relevanten Services hinweg. Gerät eine GraphQL Query an einen Beziehungstyp, so wird im GraphQL Server ein sogenannter “Resolver” aufgerufen. Das ist ein Stück Code, etwas Logik, die auf beliebige und meist noch zu programmierende Weise die Daten für den angeforderten Datentyp herbeiholt und (möglichst kaum) aufbereitet. In ORDS entfällt die händische Programmierung dieser Resolver, denn ORDS kommt mit eigenen Resolvern mit, die aus publizierten Datenbank-Tabellen und Views GraphQL Strukturen (hinterlegt per “SDL”, Schema Definition Language) erzeugen und diese Datenbank-Strukturen auslesen bzw. einbinden. Aber dank der Oracle “converged database” Features könnten Tabellen und Views auf JSON Dokumente per REST calls verweisen (modernes Beispiel: Aufruf einer generative AI mit Zusatzinformationen z.B. zu den “Locations” der Angestellten) oder sie direkt enthalten und verwalten. Und das jeweils sicher und performant, probieren Sie es gerne aus !
Legen wir also zunächst eine JSON Key-Value Tabelle an, auch “Collection” genannt in der SODA und MongoDB API. Ich verwende hier aus Bequemlichkeit die SODA API, es hätte auch eine mit reinem SQL angelegte Tabelle mit einer JSON Spalte sein können. Lassen Sie folgendes SQL bitte wieder als HR-Benutzer laufen:
DECLARE
collection SODA_Collection_T;
metadata VARCHAR2(4000) :=
'{"keyColumn" : {"name" : "ID", "assignmentMethod": "UUID" },
"contentColumn" : { "name" : "DATA", "sqlType": "BLOB" } }';
doc1 SODA_DOCUMENT_T;
doc2 SODA_DOCUMENT_T;
doc3 SODA_DOCUMENT_T;
status number;
BEGIN
collection := DBMS_SODA.create_collection('CompanyCars', metadata);
doc1 := SODA_DOCUMENT_T(b_content => utl_raw.cast_to_raw('{"licensePlate":"M-P-1234","vendor":"Skoda","model":"Kodiaq","fuel":"Diesel","gearbox":"automatic","displacement":"2.0l","leaseStart":"2017-01-06","leaseEnd":"2019-01-15","employeeID":102}'));
doc2 := SODA_DOCUMENT_T(b_content => utl_raw.cast_to_raw('{"licensePlate":"M-O-7182","vendor":"Peugeot","model":"5008","fuel":"Diesel","gearbox":"automatic","displacement":"2.0l","leaseStart":"2019-01-16","leaseEnd":"2023-01-15","employeeID":102}'));
doc3 := SODA_DOCUMENT_T(b_content => utl_raw.cast_to_raw('{"licensePlate":"M-B-5678","vendor":"Mini","model":"Countryman","fuel":"Benzin","gearbox":"automatic","displacement":"1.8l","leaseStart":"2023-01-16","leaseEnd":"2026-01-16","employeeID":100}'));
status := collection.insert_one(doc1);
status := collection.insert_one(doc2);
status := collection.insert_one(doc3);
END;
/
Legen wir nun eine sprechendere View “CARS” darüber, verknüpfen sie per Foreign Key mit der Angestellten Tabelle “Employees” und publizieren die View für REST Zugriffe und für GraphQL:
CREATE OR REPLACE VIEW CARS AS
select id, json_value(data, '$.employeeID' returning number) owned,
json_value(data, '$.model' ) model,
json_value(data, '$.vendor' ) vendor,
json_value(data, '$.licensePlate' ) licensePlate,
json_value(data, '$.displacement' ) displacement,
json_value(data, '$.leaseStart' returning date ) leaseStart,
json_value(data, '$.leaseEnd' returning date ) leaseEnd
from "CompanyCars" ;
/
ALTER VIEW CARS
ADD CONSTRAINT CARS_EMP_FK FOREIGN KEY ( owned ) REFERENCES EMPLOYEES ( EMPLOYEE_ID ) DISABLE ;
/
ALTER VIEW CARS
ADD CONSTRAINT CARS_PK PRIMARY KEY (id) DISABLE;
/
BEGIN
ORDS.enable_object (p_schema => 'HR', p_object => 'CARS', p_object_type => 'VIEW', p_object_alias => 'cars');
END;
/
Starten Sie nun bitte zunächst den ORDS Container durch, damit der Neuzugang im Datenmodell schneller erkannt wird. Lesen Sie dann das Schema in graphiql neu ein durch Klick auf das Refetch-Symbol links unten am Bildrand.
Nun können Sie bequem auflisten, welche Firmen-Fahrzeuge der Angestellte mit der ID 102 besaß oder noch schöner, welches Firmen-KFZ er aktuell besitzt.
Ein kleiner Bug: bei sort und where Angaben dürfen die abgefragten Datenbank-Objekte keine “lowercase” oder “MixedCase” Bezeichnungen haben. Üblicherweise werden in der Datenbank ohnehin nur großgeschriebene Namen verwendet.
Ebenfalls zu beachten: limit Angaben benötigen am besten einen Primary Key auf dem abgefragten Objekt, andernfalls wird die interne ROWID Spalte benutzt. Und die gibt es bei Views nicht, nur bei Tabellen.
query myThirdQuery {
employees(where: {employee_id: {eq: 102}}) {
first_name
last_name
owned_cars(sort:[{leaseend: "DESC"}]
limit:1) {
leaseend
vendor
model
}
}
}
Das Ergebnis sollte wie folgt aussehen:
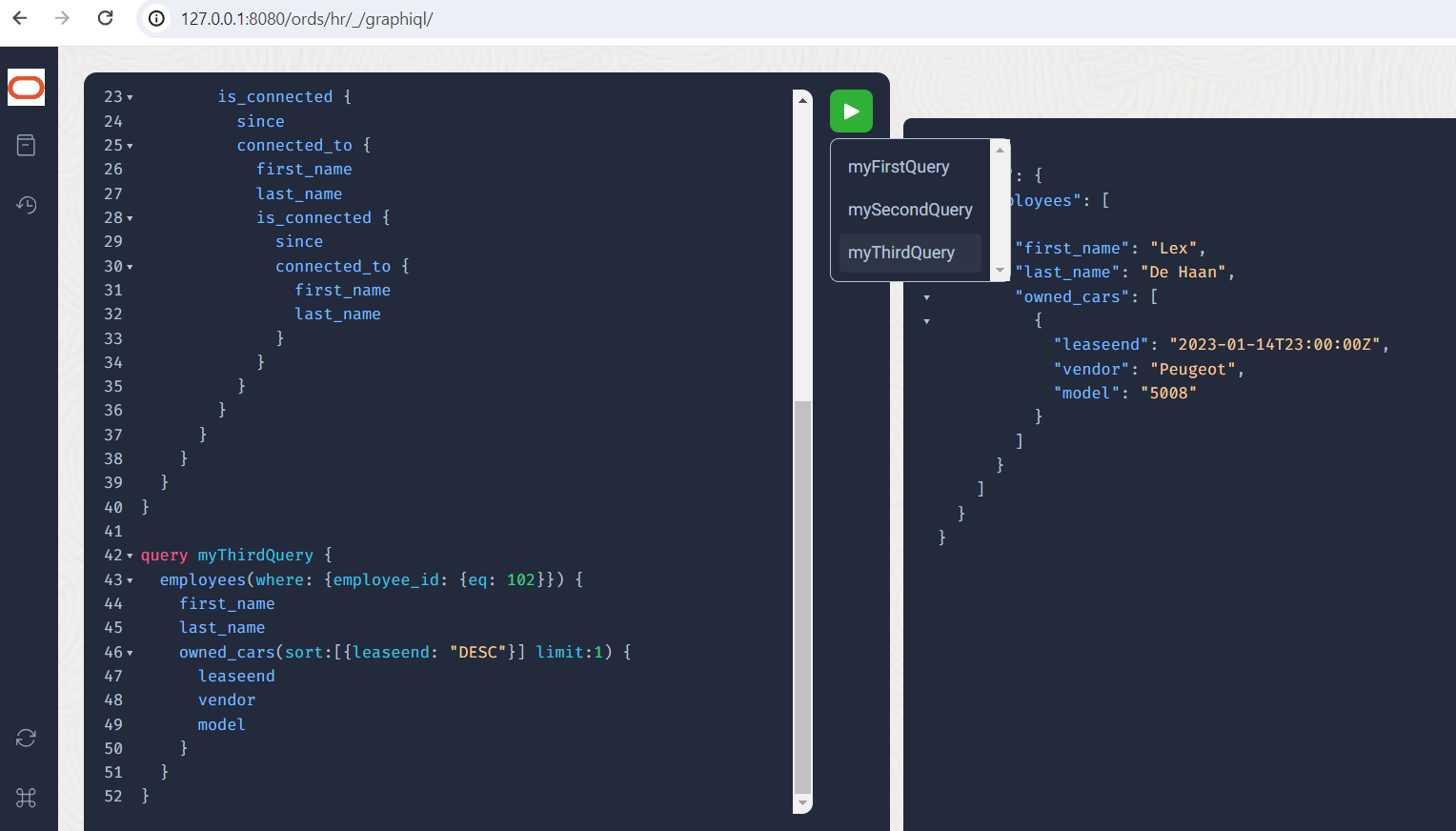
Selbstverständlich sind wir nicht gezwungen, in den Graphen nur über die Angestellten einzusteigen. So könnte man auch die Tiefen-Limitierung bei Rekursionen beibehalten indem man an tiefergelegener Stelle mit der Abfrage einsteigt. Eine Liste aller Firmen-KFZ mit deren Besitzern wäre über folgende Abfrage möglich:
query myFourthQuery {
cars {
vendor
model
displacement
cars_owned {
first_name
last_name
}
}
}
Beziehungen zu REST Services definieren
Herkömmlicherweise werden eigene Resolver in Java oder JavaScript programmiert, die entfernte REST Services aufrufen um ihre Daten und Logik einzubeziehen. Hier jedoch können wir innerhalb der Oracle Database die bestehenden, in ORDS enthaltenen Resolver nutzen, um über Views und Funktionsaufrufe das gleiche Ziel zu erreichen. In unserem Beispiel möchten wir die KFZ Daten ein wenig um zusätzliche Informationen zum Modell und einem Link zum Bild des jeweiligen Fahrzeugtyps anreichern. Dazu verpacken wir einen REST Service Aufruf in eine Funktion, diese binden wir in eine View ein und bringen sie über einen Fremdschlüssel in Beziehung zu der bestehenden “CompanyCars” JSON Tabelle.
Es besteht immer die gleiche Vorgehensweise: eine View die beliebig komplexe Dinge tut und damit eine komplexe Beziehung zu anderen Objekten implementiert wird über Fremdschlüssel in Beziehung zu anderen Objekten gebracht. Das funktioniert übrigens mit SQL/PGQ recht ähnlich.
Beginnen wir damit, daß wir unserem “HR” Benutzer die Berechtigung erteilen, auf einen REST Service der Wikipedia Bibliothek zuzugreifen. Als privilegierter Benuzer, z.B. “SYS“, fügen Sie bitte die öffentliche Wikipedia Bibltiohek einer ACL-Liste für HTTP-Zugriffe hinzu:
BEGIN
DBMS_NETWORK_ACL_ADMIN.APPEND_HOST_ACE(
host => 'en.wikipedia.org',
ace => xs$ace_type(
privilege_list => xs$name_list('http'),
principal_name => 'HR',
principal_type => xs_acl.ptype_db
)
);
END;
/
Nun erzeugen wir als Benutzer HR eine Funktion, die den REST Service aufruft sowie eine View, die später in GraphQL durch eine WHERE Klausel so limitiert wird, daß nicht immer gleich alle Fahrzeugdaten aller Fahrzeuge abgerufen werden. Die Funktion hätte man in Version 23c auch in JavaScript schreiben können, aber ich wollte nicht zu ausschweifend werden:
CREATE OR REPLACE FUNCTION CARDETAILS( brand_model in varchar2) return varchar2
AS
l_url VARCHAR2(400) := 'https://en.wikipedia.org/api/rest_v1/page/summary/';
req utl_http.req;
resp utl_http.resp;
buffer VARCHAR2(32767);
BEGIN
l_url := l_url || brand_model;
-- in case you are behind a proxy, please uncomment the following line after setting the correct proxy address
-- utl_http.set_proxy('http://username:passwd@192.168.22.33:5678');
req := utl_http.begin_request(url => l_url, method => 'GET');
utl_http.set_header(req, 'Accept', 'application/json');
resp := utl_http.get_response(req);
BEGIN
utl_http.read_text(resp, buffer);
EXCEPTION
WHEN utl_http.end_of_body THEN
utl_http.end_response(resp);
END;
return buffer;
END;
/
CREATE OR REPLACE VIEW CARINFO AS SELECT
id AS avail,
json_value(cardetails(vendor||'_'||model), '$.extract') extract,
json_value(cardetails(vendor||'_'||model), '$.thumbnail.source') image
FROM CARS;
/
ALTER VIEW CARINFO ADD CONSTRAINT carinfo_car_fk FOREIGN KEY (avail) REFERENCES CARS (id) DISABLE;
/
BEGIN
ORDS.enable_object (p_schema => 'HR', p_object => 'CARINFO', p_object_type => 'VIEW', p_object_alias => 'carinfo');
END;
/
Starten Sie nun bitte zunächst den ORDS Container durch, damit der Neuzugang im Datenmodell schneller erkannt wird. Lesen Sie dann das Schema in graphiql neu ein durch Klick auf das Refetch-Symbol links unten am Bildrand.
Nun können Sie zu jedem Firmenfahrzeug, das auch auf Wikipedia eingetragen ist, eine Kurzbeschreibung und ein Bildchen abrufen. Bitte beachten Sie hier, daß der REST Service aus Gründen der Einfachheit mehrfach aufgerufen wird, wenn auch parallel und nicht seriell. Dennoch sollte man sich im “wahren Leben” eine bessere Ergebnis-Struktur überlegen, z.B. könnte die aufgerufene Funktion lieber eine pipelined Function werden und die Elemente des JSON-Ergebnisses als Spalten zurückgeben.oder es ließe sich etwas mit den recht neuen SQL Macros anstellen.
Bitte beachten Sie auch, daß es aus gleichem Grund zu Fehlermeldungen kommen kann, wenn Sie mehrere Attribute aus der CARINFO-View abfragen: Zu viele gleichzeitige HTTP Requests aus der Datenbank heraus werden angemahnt. Aber folgende GraphQL Query auf ein Attribut müßte auch bei Ihnen funktionieren:
query myFifthQuery {
cars(where: {vendor: {eq: "Mini"}}) {
vendor
model
avail_carinfo {
extract
}
}
}
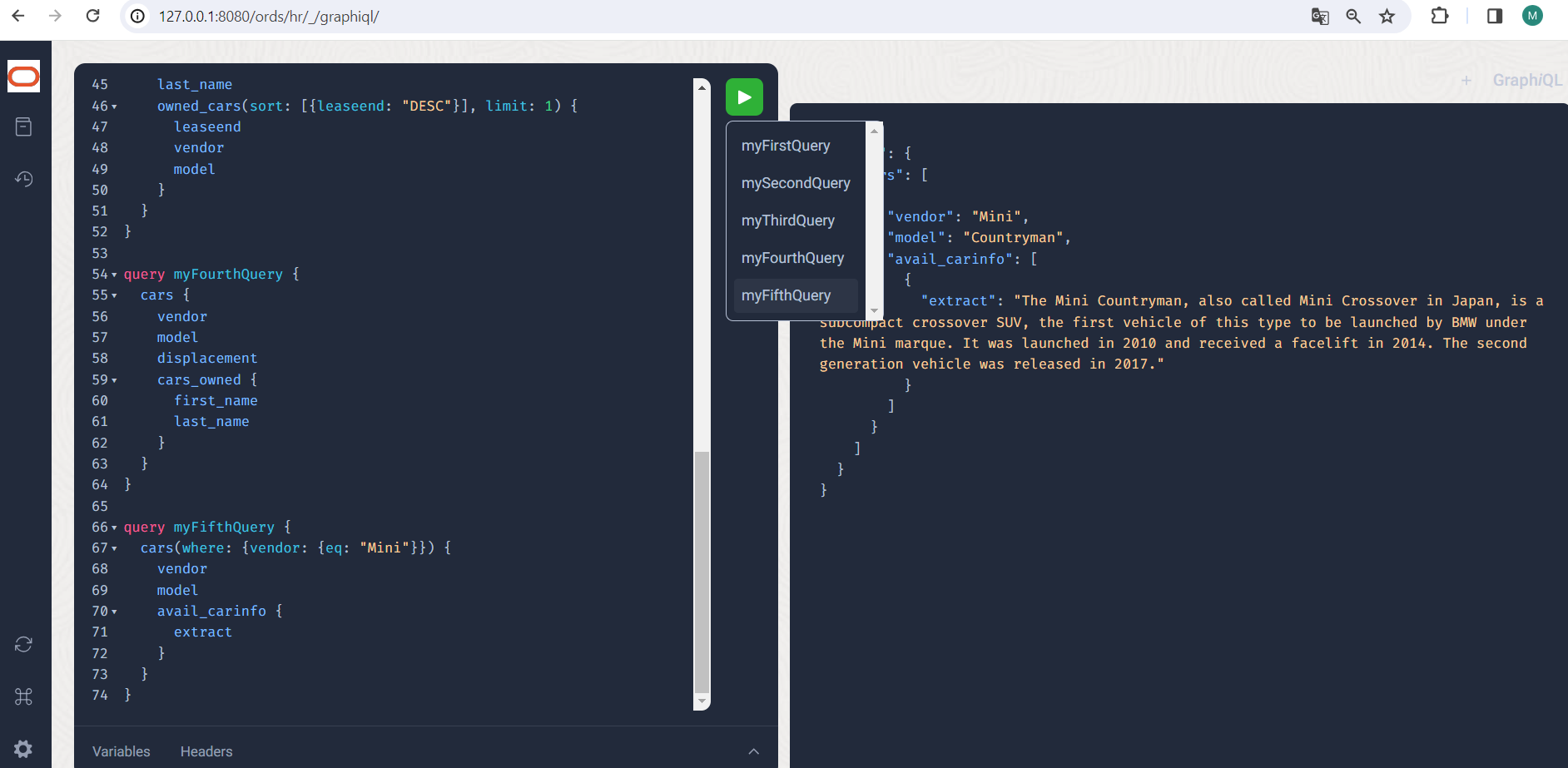
So viel zu den grundsätzlichen Features und Prinzipien in GraphQL innerhalb ORDS. Bestehen weitere Wünsche und Ideen, was noch eingebaut werden könnte, so freut sich unser Jeff Smith auf Rückmeldungen und Eingaben! Persönlich finde ich die Query-Unterstützung schon sehr gelungen auch wenn ich mir wünschte, Beziehungsnamen frei benennen zu dürfen. Über Views geht schon so Manches. Eine direkte Unterstützung für JSON Datentypen und JSON Duality Views würden sehr helfen, aktuell werden Felder vom Typ JSON als MIME-encoded Inhalte wiedergegeben. Mutations und Subscriptions würde ich mir sehr wünschen, erstere würden sehr schön mit JSON Duality Views harmonieren und letztere könnte man als Continuous Queries implementieren, so lange sie nicht zu komplex werden. Die GraphQL Unterstützung für Variablen und Fragmente ist hier gegeben, weil unabhängig von der sonstigen Implementation und von Resolvern.
Visualisierung von GraphQL Graphen
Die Ergebnisse aus GraphQL-Abfragen darzustellen und auszuwerten ist mit Analyse-Werkzeugen wie Oracle Analytics Cloud bzw. Analytics Server komfortabel möglich. Oracle Analytics akzeptiert REST Services als Datenquellen und kann mit Daten in JSON Strukturen umgehen. Erlaubt sind mittlerweile komplexe JSON Strukturen mit tiefer Verschachtelung, der aufgerufene REST Service, in unserem Fall GraphQL im ORDS Container, muß nicht zwingend an das ODATA JSON Format gebunden sein – beide Varianten werden unterstützt.
Der besonders umfassende OpenSource Framework Oracle JET (JavaScript Extension Toolkit) bietet eine bis ins Detail anpassbare Visualisierung von Graphen. Diese Visualisierung trägt den schlichten Namen “Diagram” und ist komplett anpaßbar bezüglich Knoten-Darstellung und Inhalten, Animationen und Farben, Drag&Drop Events und vieles mehr. TypeScript Kenntnisse sowie Kenntnisse in JavaScript Frameworks zur Datenaufbereitung sind hier nötig, aber sicherlich lohnenswert.
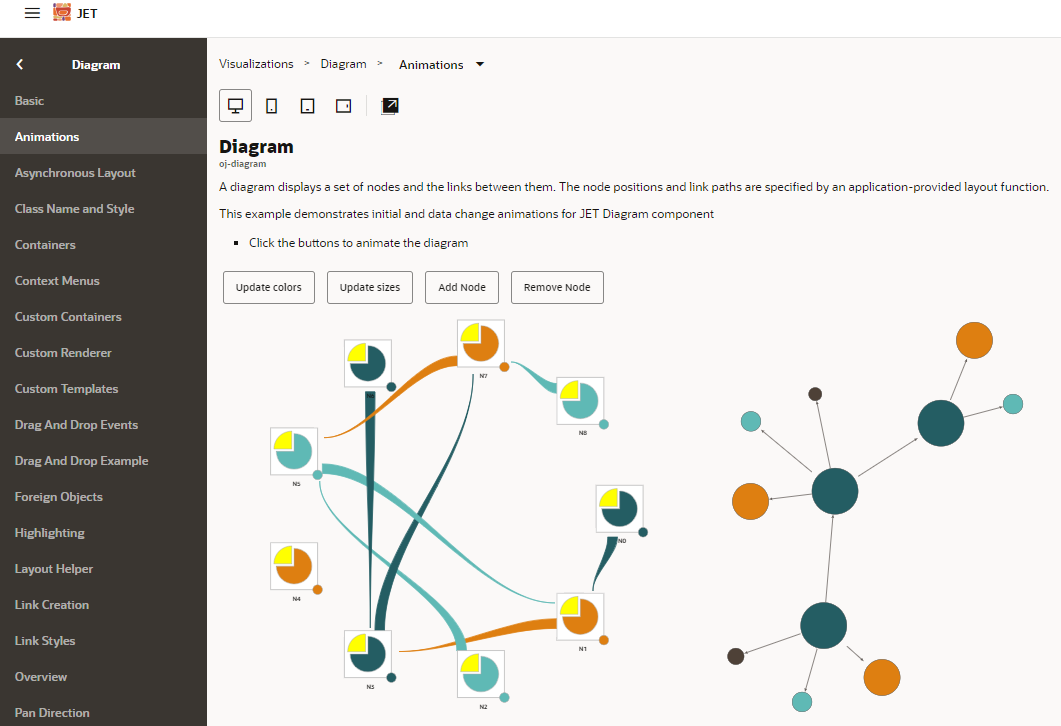
Ist mehr eine grafische Darstellung der Graph-Struktur bzw. der Metadaten gewünscht, so gibt es hier inzwischen erste ansprechende Oberflächen. Es war nicht gerade GraphQLs Stärke, Analysen auf Beziehungen und Verknüpfungen zu machen, sondern allein um Beziehungen zu definieren und optimal und performant aufzulösen. Ein ansprechendes Tool ist beispielsweise der graphql Voyager. Er bereitet eine GraphQL Metadaten Query vor die alle Strukturen und Komponenten als Ergebnis ausgibt. Das Ergebnis kopiert man danach in das Tool hinein und kann die Datenstrukturen und Beziehungen schön visualisieren und unter die Lupe nehmen.
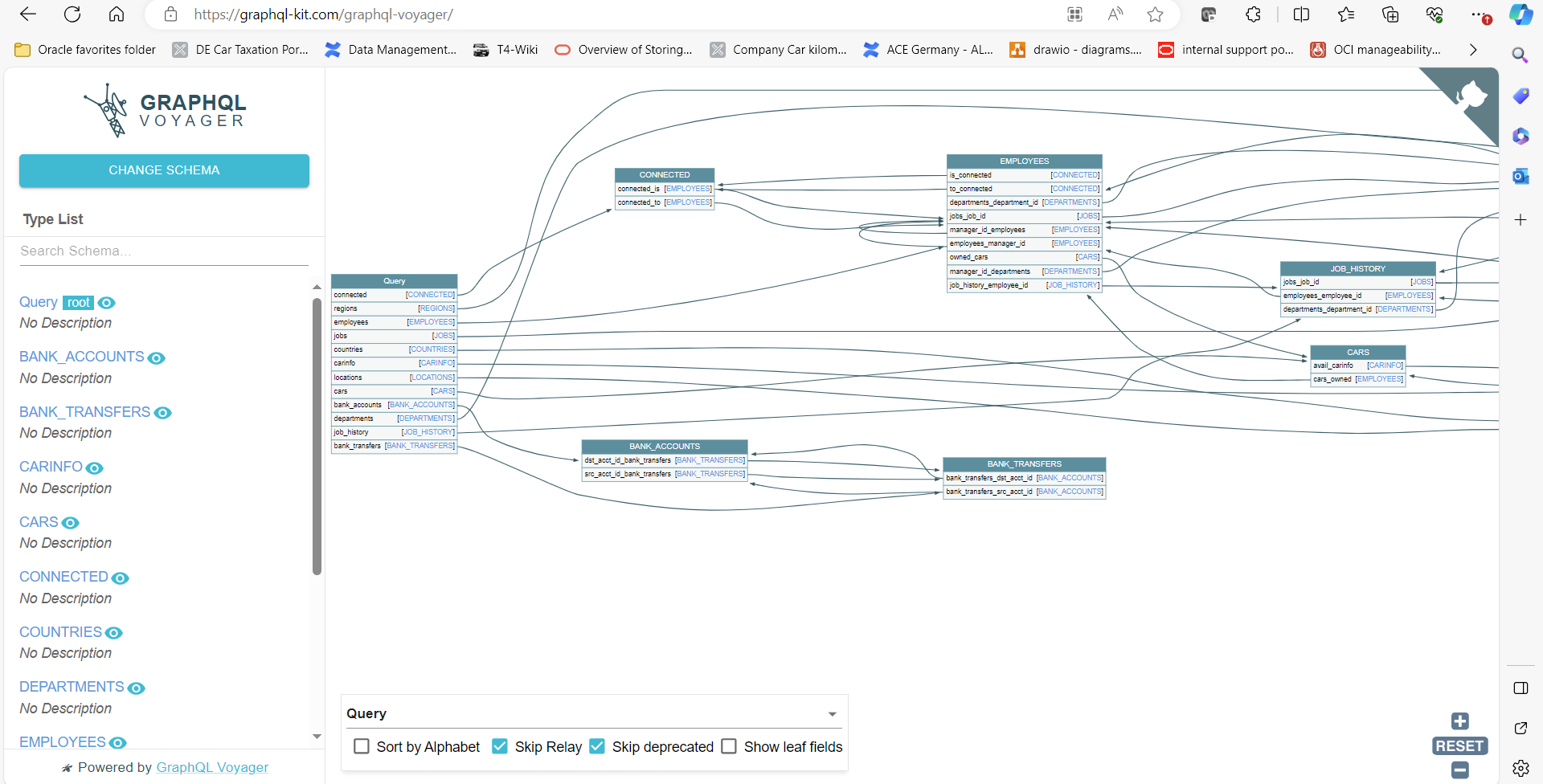
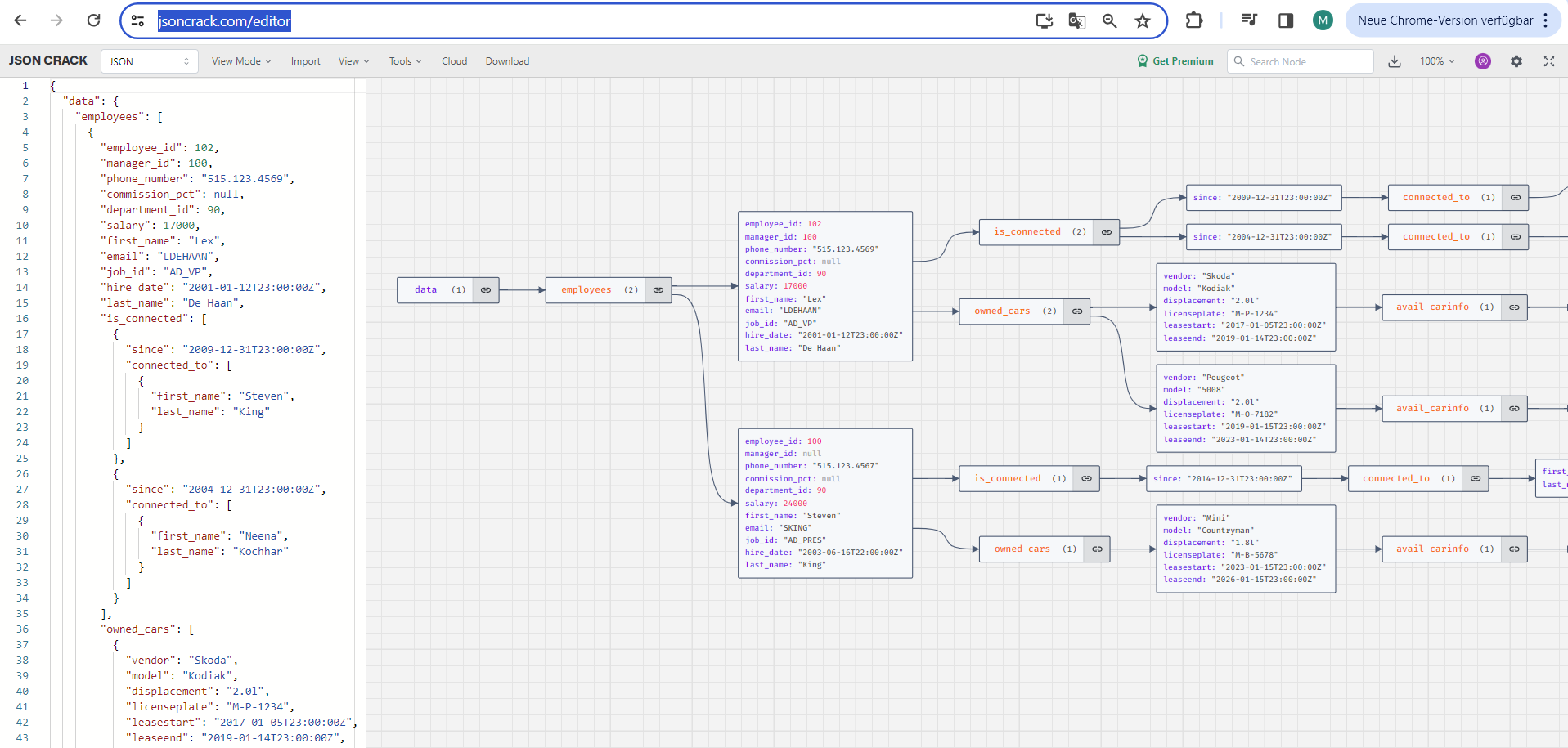
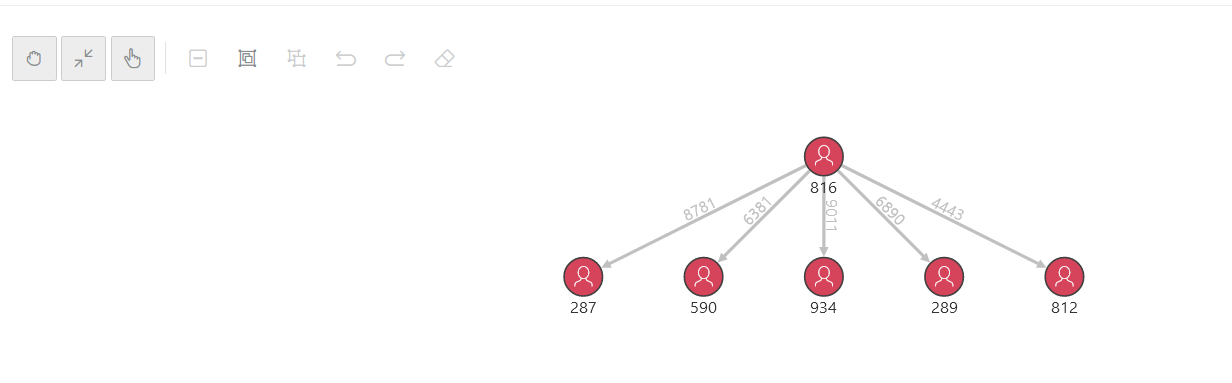
Hier läßt sich sehr schön erkennen, daß eine GraphQL-Query bei jedem beliebigen Knoten des Graphen (employees, cars,…) einsteigen könnte und wie man von dort aus auf die anderen verknüpften Knoten navigiert. Ist mehr eine Darstellung der Ergebnisdaten einer GraphQL Query als Graph gefragt, so könnte dieses Tool interessant sein: der jsonCrack JSON Editor.
Er gibt zwar nur die Strukturen wieder, die in einer GraphQL-Query angefragt wurden, aber zeigt Knoten und Daten sehr schön auf, wählt man statt der standardmäßigen “Tree”-Darstellung einen “Graph”.
Die Möglichkeiten zur Visualisierung und auch Verschönerung der Darstellungsweise sind mit SQL/PGQ Graphen verständlicherweise viel umfassender. Widmen wir uns zu einem kurzen Vergleich nun den SQL/PGQ Graphen. Übrigens, einen noch besseren Einblick zu SQL/PGQ finden Sie in einem aktuellen Blog Eintrag meiner Kollegin Karin Patenge.
Teil 2: SQL/PGQ
Stellen wir nun einen kurzen Vergleich zu SQL/PGQ an um seine Stärken aufzuzeigen. Daten zum Abfragen haben wir bereits in Teil 1 geladen, also müssen wir nur noch einen Graphen darüber legen und die Art von Abfragen formulieren, die in GraphQL eher schwierig zu implementieren sind. Oder beinahe zumindest. Denn so ein Property Graph mag nur Tabellen und Materialized Views als Grundlage für seine Knoten (Vertexes) und Kanten (Edges), keine Views. Also müssen wir zunächst aus der “CARS” View eine Materialized View machen (am besten mit automatischem Refresh) oder die “CompanyCars” Tabelle um einige Spalten anreichern, die als Primär- und Fremdschlüssel gebraucht werden. Ich habe mich für die Materialized View entschieden. Bitte lassen Sie nun folgendes SQL als HR Benutzer laufen:
create materialized view cars_mv as
select json_value(json_document, '$.employeeID' returning number) empid,
json_value(json_document, '$.model' returning varchar2(50)) model,
json_value(json_document, '$.vendor' returning varchar2(100)) vendor,
json_value(json_document, '$.licensePlate' returning varchar2(100)) licensePlate,
json_value(json_document, '$.displacement' returning varchar2(10)) displacement,
json_value(json_document, '$.leaseStart' returning date ) leaseStart,
json_value(json_document, '$.leaseEnd' returning date ) leaseEnd
from "CompanyCars" ;
/
Die CARINFO View müßte ebenso materialisiert werden, d.h. alle Daten aus REST Calls an Wikipedia zu den in Frage kommenden Fahrzeugen wären zwischenzuspeichern und hin und wieder zu aktualisieren. SQL/PGQ ist nunmal vorrangig für Analysen geeignet, und die sollten möglichst schnell sein. Ersparen wir uns diesen Teil denn ich denke, Zweck und Nutzen werden auch so deutlich.
Definition eines Graphen über ein bestehendes Datenmodell
Bei GraphQL wurden für REST Zugriffe publizierte Tabellen, Views und deren Fremdschlüssel für die Generierung eines Graphen benutzt. Dessen Dokumentation liegt als SDL (Schema Definition Language) Dokument vor und ist per REST abrufbar. Für die Erstellung von Property Graphen gibt es eine SQL/PGQ Syntax welche die Basistabellen für Knoten und Kanten/Beziehungen festlegt und den Beziehungen eigene Namen erteilen kann. Diese Informationen werden in internen Datenbank-Tabellen abgelegt und bei Abfragen benutzt, um aus SQL/PGQ Syntax mehr oder weniger komplexe SQL Abfragen zu machen. Lassen Sie bitte folgendes Kommando mit einem SQL Tool wie SQLcl, Jupyter Notebook oder SQL*Developer gegen Ihre Oracle Datenbank laufen, wie eigentlich immer als Benutzer HR. Verwenden Sie Oracle 23c als Datenbank, so ist der SQL/PGQ Parser dort integriert und Sie können ein beliebiges Tool verwenden. Ansonsten wird der meist im Tool enthaltene PGQL Parser genutzt, der noch leichte Unterschiede zu SQL/PGQ aufweisen kann. Daher sollte dann das Tool möglichst aktuell sein, um alle SQL/PGQ Features abzudecken.
CREATE PROPERTY GRAPH employee_network
VERTEX TABLES(
employees
KEY ( employee_id )
PROPERTIES all columns
LABEL employee,
cars_mv
KEY ( empid, licenseplate )
PROPERTIES all columns
LABEL cars
)
EDGE TABLES(
facebook as connected
key (from_id, to_id)
SOURCE KEY ( from_id ) REFERENCES employees (employee_id)
DESTINATION KEY ( to_id ) REFERENCES employees (employee_id)
PROPERTIES (since),
cars_mv as owned
key (empid, licenseplate)
SOURCE KEY ( empid ) REFERENCES employees ( employee_id )
DESTINATION KEY ( empid, licenseplate ) REFERENCES cars_mv ( empid, licenseplate )
);
/
Einfache Abfragen
Durch den eben definierten Graphen stehen die Knoten EMPLOYEE und CARS zur Verfügung sowie die Kanten/Beziehungen CONNECTED und OWNED. Die Daten bzw. Schlüssel der OWNED Beziehung stehen gleich in der Knoten-Tabelle CARS_MV zur Verfügung, aufgrund der existierenden 1:N Beziehung wurde keine N:M Beziehungstabelle verwendet.
Mit Hilfe von SQL/PGQ können wir nun wählen, über welche Beziehung(OWNED) und in welcher Richtung(->) wir herausfinden möchten, welche Firmen-Fahrzeuge der Angestellte mit der ID 102 besaß.
select *
from graph_table (employee_network
match
(e is employee) - [is owned] -> (o is cars)
where e.employee_id = 102
columns (e.employee_id as owner_id,
o.model as model,
o.vendor as vendor)
)
order by 1;
Ergebnis:
OWNER_ID MODEL VENDOR 102 Kodiaq Skoda 102 5008 Peugeot
Um wie in GraphQL zu erfahren, welche Personen der Angestellte mit der ID 100 direkt kennt, kommt folgende Query in Frage. Auch die Beziehung CONNECTED darf Attribute besitzen, die sich abfragen lassen:
select *
from graph_table (employee_network
match
(e1 is employee) - [c is connected] -> (e2 is employee)
where e1.employee_id = 102
columns (e1.first_name as is_first_name,
e1.last_name as is_last_name,
e2.first_name as knows_first_name,
e2.last_name as knows_last_name,
c.since as since,
e2.employee_id as knows_id)
)
order by 1;
Ergebnis:
IS_FIRST_NAME IS_LAST_NAME KNOWS_FIRST_NAME KNOWS_LAST_NAME SINCE KNOWS_ID Lex De Haan Neena Kochhar 2005-01-01 00:00:00 101 Lex De Haan Steven King 2010-01-01 00:00:00 100
Abfragen auf Metadaten
Kommen wir nun zu besonderen Stärken von SQL/PGQ. Wenn unbekannt ist, über welche Beziehungen oder über wieviele Hops bzw. Rekursionen ein Knoten mit einem anderen Knoten verbunden ist, so müssen wir uns nicht manuell durch eine Pfad-/Baumstruktur hindurchklicken, sondern man kann bestimmte Angaben wie Pfade einfach weglassen, oder man kann die maximale Rekursionstiefe selbst und in Kurzform bestimmen. Um beispielsweise zu prüfen, ob jemand (aus Versehen?) direkt mit sich selbst verbunden wurde, könnte man folgende Abfrage formulieren:
select *
from graph_table (employee_network
match
(p1 is employees) - [is connected] -> (p1)
columns (p1.employee_id as from_id,
p1.first_name as first_name,
p1.last_name as last_name,
p1.employee_id as to_id)
)
order by 1;
Die Ergebnismenge sollte hier leer sein, nichts gefunden. Aber um zwei Ecken herum müßte das der Fall sein, das hatten wir in GraphQL doch auch entdeckt – hier das Pendant in SQL/PGQ mit Angabe einer Zahl von Hops:
select *
from graph_table (employee_network
match
(p1 is employees) - [is connected] -> {2}(p1)
columns (p1.employee_id as from_id,
p1.first_name as first_name,
p1.last_name as last_name)
)
order by 1;
Das Ergebnis besagt ja, das gilt sowohl für Herrn De Haan als auch für Herrn King:
FROM_ID FIRST_NAME LAST_NAME 100 Steven King 102 Lex De Haan
Ein kleiner Hinweis: sollte bei Angabe einer Quantifizierung bzw. Zahl der Hops kein Ergebnis kommen, so verwenden Sie wahrscheinlich ein Werkzeug mit einem etwas veralteten integrierten PGQL Parser, der diese Angabe ignoriert. Mit dem im ORDS 23.3 enthaltenen Tool “Database Actions” ist dies der Fall. Arbeiten Sie mit einer Oracle Database 23c, so können Sie den Parser im Tool umgehen, indem Sie die SQL/PGQ Abfrage in eine View verpacken und dann die View abrufen. Ansonsten hilft ein Upgrade oder ein Wechsel Ihres Tools. Es gibt separate PGQL Parser zum Download, die sich z.B. in SQLcl integrieren.
Nun eine kurze “Ranking”-Abfrage: welche Employees kennen sich selbst über jegliche Art von Beziehung und mit möglichst wenigen Hops, maximal 3 Hops sind erlaubt ?
select from_id, first_name, last_name, count(1) as num_hops
from graph_table (employee_network
match
(p1 is employees) - [] -> {1,3}(p1)
columns (p1.employee_id as from_id,
p1.first_name as first_name,
p1.last_name as last_name)
)
group by from_id, first_name, last_name order by num_hops;
Ergebnis:
FROM_ID FIRST_NAME LAST_NAME NUM_HOPS 101 Neena Kochhar 1 100 Steven King 2 102 Lex De Haan 2
Dieses Beispiel sollte ein wenig den Umgang mit SQL/PGQ zeigen. Das verwendete Szenario mag eher trivial sein, aber stellen Sie sich bitte vor, es handele sich bei den Abfragen nicht um Personen sondern um Bankkonten, und Sie hätten soeben Dreiecks-Buchungen gefunden, um Steuerhinterziehung oder Geldwäsche durchzuführen… und genau diese Art von Beispiel mit einigen Abfragen mehr finden Sie auf einem Beispiel-Repository für PGQL (und auch SQL/PGQ) auf github. Dort finden Sie auch weiterführende Beispiele, welche die Eingangs angesprochenen vorbereiteten Property Graph Algorithmen nutzen, die im separat herunterladbaren Graph Server anwendbar sind.
Visualisierung von Property Graphen
Selbstverständlich lassen sich die rein relationalen Ergebnisdaten aus SQL/PGQ Abfragen in beliebigen Analyse-Werkzeugen aufbereiten, ganz wie bei GraphQL-Abfragen in der Oracle Analytics Cloud bzw. dem Analytics Server. Darüberhinaus gibt es mehrere Plugins und Tools, die sich speziell der Darstellung von Property Graphen gewidmet haben:
Das Oracle Analytics Cloud Plugin “Graph Network Viz” oder auch nur Property Graph Plugin genannt kann über die Oracle Analytics Extension Library nachinstalliert werden. Eine genauere Beschreibung zur Einrichtung finden Sie unter anderem im Blog unserer Analytics Kollegen. Das Plugin bietet einige Standard-Analysen auf Property Graphen, zum Beispiel Shortest Path oder Node Ranking, ohne einen zusätzlichen Graph Server.

Das in dem separat herunterladbaren Graph Server enthaltene User Interface “Graph Visualisation Application” visualisiert SQL/PGQ Abfragen als Graphen. Zahlreiche Anpassungen der Darstellung sind möglich und dokumentiert. Ein kleines Youtube Video zeigt, wie das aussehen könnte.
Ein Property Graph plugin für Jupyter Notebooks ermöglicht das Arbeiten mit Graphen wie z.B. Anlegen, Beladen und Abfragen, aber es können auch einfache Visualisierungen erzeugt werden.
Ein neues Plugin für Application Express (APEX), genannt Graph Visualization, befindet sich noch im Preview-Status, aber es läßt sich schon jetzt erkennen, daß es sehr viele Anpassungsmöglichkeiten bieten wird. Es darf natürlich bereits jetzt in Ihre APEX Umgebung eingebunden werden, denn es steht im APEX GitHub Repository zum Download zur Verfügung. Eine kurze Anleitung zu der Einbindung finden Sie im Developer’s Guide for Property Graphs.
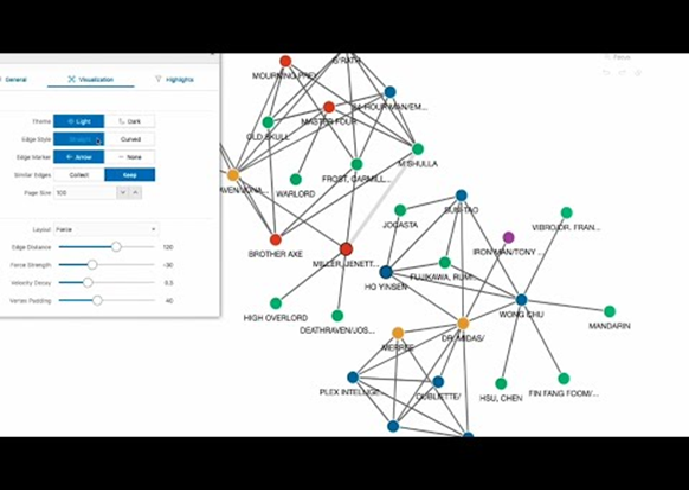
Die Autonomous Database in der Oracle Cloud Infrastructure in den Ausprägungen Autonomous Warehouse und Autonomous Transaction Processing kommen mit dem sehr umfassenden Tool Graph Studio um Property Graphen und auch RDF Graphen zu verwalten und Abfragen umfassend zu visualisieren. Graph Studio basiert ursprünglich auf der Graph Visualisation Application und dem Jupyter Notebook plugin, das dieses Tools beträchtlich erweitert.
Fazit
Verschiedene Graph-Standards haben ihren eigenen Anwendungszweck. Dient SQL/PGQ mehr der Analyse komplex verknüpfter Daten lassen sich mit GraphQL ursprünglich disjunkte Datenquellen in Zusammenhang bringen und so aufrufen bzw. abfragen, daß nur benötigte Daten abgerufen werden und nur die dafür nötigen Backend-Services angestoßen werden. Die automatische Erzeugung von GraphQL-Strukturen und Filtern aus relationalen Daten heraus vereinfacht die Bereitstellung von GraphQL-Graphen. Der Automatismus ist nutzbar, um auch externe Datenquellen und REST Services in die generierten Graphen einzubinden, bieten einen guten Einstieg von Datenbank-Entwicklern in die GraphQL-Welt und sicherlich noch mehr als das.
Links
PGQL Spec Seite (der Vollständigkeit halber)
GraphQL mit ORDS 23.3 Dokumentation
SQL/PGQ mit Database 23c Dokumentation
Ideen und Verbesserungvorschläge zu GraphQL bitte an Jeff Smith
Database 23c SQL/PGQ Beispiele auf github
