![]() Per Knopfdruck eine Testumgebung bereitstellen, um Analysten und Entwickler die nötigen SQL Abfragen, AI Prompts und Visualisierungen erforschen zu lassen. Mit eigenen Daten und mit GIT Anbindung, um gewonnene Erkenntnisse abzulegen und versioniert wiederzuverwenden. Und das Ganze On Premises und cloud-portabel? Kubernetes, Container und Helm Charts machen es möglich. Hier am Beispiel des Oracle Graph Servers mit UI, verknüpften Jupyter Notebooks sowie sqlplus Kommandozeile und Test-Daten.
Per Knopfdruck eine Testumgebung bereitstellen, um Analysten und Entwickler die nötigen SQL Abfragen, AI Prompts und Visualisierungen erforschen zu lassen. Mit eigenen Daten und mit GIT Anbindung, um gewonnene Erkenntnisse abzulegen und versioniert wiederzuverwenden. Und das Ganze On Premises und cloud-portabel? Kubernetes, Container und Helm Charts machen es möglich. Hier am Beispiel des Oracle Graph Servers mit UI, verknüpften Jupyter Notebooks sowie sqlplus Kommandozeile und Test-Daten.
Aus der Blog-Reihe “will it blend?” bzw. “paßt das in den Mixer?” wollte ich mich dieses Mal daran begeben, den Oracle Graph Server zur Visualisierung und Analyse von Property- und RDF-Graphen unter Kubernetes zu betreiben. Der Graph Server allein macht jedoch wenig Sinn, denn viele im Internet verfügbare Beispiele und Demos basieren auf Jupyter oder Zeppelin Notebooks. Die UI des Graph Server bietet auch nicht die Möglichkeit, Abfragen und Diagramme abzulegen oder zu dokumentieren. Also sollte besser gleich eine Runtime für Notebooks mitverpackt werden. Natürlich mit Anbindung an eine bestehende Oracle Datenbank und an ein wählbares GIT repository, um Notebooks live herunterzuladen und auch zu pflegen. Selbstverständlich gibt es solche Pakete bereits als Lösung in der Oracle Cloud: jeder Autonomous Database Service kommt mit Analyse-Tools und jeweils eigenem Graph Server daher. Auch der Data Science Cloud Service bietet versionierbare Analyse Umgebungen per Knopfdruck. Dieser Blog behandelt daher einen on Premises Aspekt, ein Kubernetes Software-Paket mit nötigen Tools, mit Anbindungsmöglichkeiten und obendrein portabel in andere z.B. cloud-basierte Kubernetes Umgebungen.
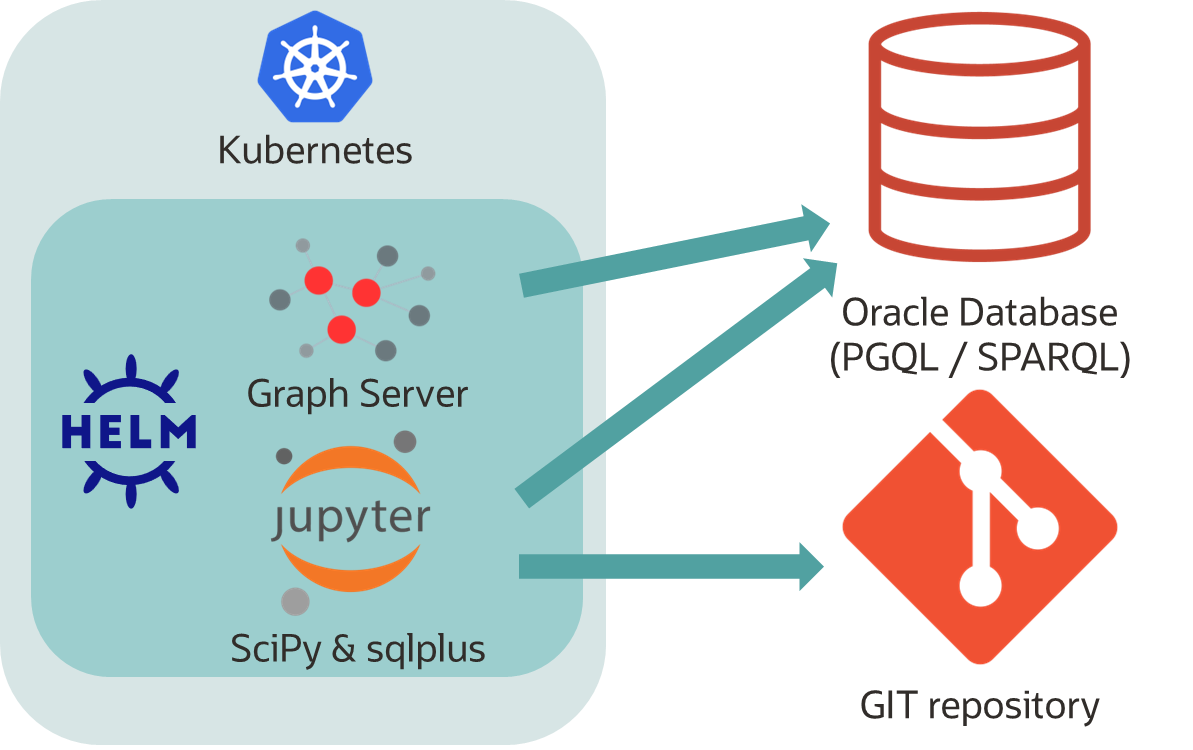
Gehen wir gleich in medias res ! Folgende Punkte sind zu behandeln:
Erzeugung eines Container Image für den Oracle Graph Server
Erklärung zum automatisierten Customizing des Jupyter Standard-images “scipy”
Vorbedingungen für die Einrichtung unter Kubernetes
Einrichtung des Helm Charts per Kommandozeile
Feature Beschreibung und Lösungs-Clickthrough
Erzeugung eines Container Image für den Oracle Graph Server
Anders als bei vielen anderen Oracle Komponenten gibt es den Oracle Graph Server nicht als Standard-image auf container-registry.oracle.com. Das bedeutet wir müssen selbst ein Image erzeugen. Es gibt auch kein Standard-Skript zur Erzeugung eines Graph Server Image auf github.com/oracle/docker-images. Doch es existiert eine Beschreibung in Form eines zweiteiligen Blogs unseres Graph Product Managements darüber, wie man ein Container Image erzeugen kann:
https://medium.com/oracledevs/build-oracle-graph-on-docker-part-1-2-5fcacaca430e
https://medium.com/oracledevs/build-oracle-graph-on-docker-part-2-2-407827b0b93
Der Blog beschreibt, wie man die Software von edelivery.oracle.com herunterladen und per docker build Kommando ein Image erzeugt, das den Graph Server mit self-signed Zertifikaten darin einrichtet. Ein dafür notwendiges Dockerfile wird dort ebenfalls bereitgestellt. Auch wird eine bestehende Oracle Datenbank vorbereitet mit Testdaten und einem Datenbank-Benutzer mit notwendigen Berechtigungen, z.B. der GRAPH_DEVELOPER Rolle.
Das im Blog beschriebene Image wird leider als root-Benutzer gestartet und erfordert, dass der Datenbank-Connect von Hand in die Konfigurationsdateien eingetragen wird. Daher habe ich das Dockerfile ein wenig optimiert und einen oracle Benutzer verwendet, um den Graph Server zu starten. Das Start-Kommando im späteren Helm Chart fügt die Datenbank-Verbindung selbsttätig ein.
Hier zu Dokumentationszwecken das angepaßte Dockerfile:
FROM oraclelinux:8
ARG VERSION_JDK
ARG VERSION_OPG
COPY ./jdk-${VERSION_JDK}_linux-x64_bin.rpm /tmp
COPY ./oracle-graph-${VERSION_OPG}.x86_64.rpm /tmp
RUN yum install -y unzip zip numactl gcc libgfortran python3.8 \
&& yum clean all \
&& rm -rf /var/cache/yum/* \
&& rpm -ivh /tmp/jdk-${VERSION_JDK}_linux-x64_bin.rpm \
&& rpm -ivh /tmp/oracle-graph-${VERSION_OPG}.x86_64.rpm \
&& rm -f /usr/bin/python3 /usr/bin/pip3 \
&& ln /usr/bin/python3.8 /usr/bin/python3 \
&& ln /usr/bin/pip3.8 /usr/bin/pip3 \
&& pip3 install oracle-graph-client==24.4.0 \
&& groupadd -g 54322 dba \
&& useradd -u 54321 -d /home/oracle -g dba -m -s /bin/bash oracle \
&& chown oracle:dba /home/oracle \
&& chown -R oracle:dba /var/log/oracle/graph \
&& chown -R oracle:dba /etc/oracle/graph \
&& chown -R oracle:dba /opt/oracle/graph
ENV JAVA_HOME=/usr/lib/jvm/jdk-17.0.13-oracle-x64
ENV PATH=$PATH:/opt/oracle/graph/bin
ENV SSL_CERT_FILE=/etc/oracle/graph/ca_certificate.pem
ENV PGX_SERVER_KEYSTORE_PASSWORD=changeit
RUN keytool -importkeystore \
-srckeystore /etc/oracle/graph/server_keystore.jks \
-destkeystore $JAVA_HOME/lib/security/cacerts \
-deststorepass changeit \
-srcstorepass changeit \
-noprompt
COPY server_ssl.conf /etc/oracle/graph
USER oracle
ENV JAVA_HOME=/usr/lib/jvm/jdk-17.0.13-oracle-x64
ENV PATH=$PATH:/opt/oracle/graph/bin
ENV SSL_CERT_FILE=/etc/oracle/graph/ca_certificate.pem
ENV PGX_SERVER_KEYSTORE_PASSWORD=changeit
EXPOSE 7007
WORKDIR /opt/oracle/graph/bin
CMD ["sh", "/opt/oracle/graph/pgx/bin/start-server"]
Sie sehen, dass ohne weitere Anpassungen der Graph Server mit einem mitgelieferten self-signed Zertifikat eingerichtet und gestartet wird. Das später noch erklärte Helm Chart kann über geeignete Parameter Einfluß darauf nehmen, indem es den Graph Server mit von außen eingefügten Zertifikaten oder wahlweise ganz ohne Verschlüsselung startet, da diese meist durch ein vorangestelltes Gateway bzw. einen Ingress erfolgt, der SSL Terminierung an zentraler Stelle im Cluster durchführt.
A propos SSL, eine zusätzliche Konfigurations-Datei wird zur späteren optionalen Verwendung in das Image kopiert mit Angaben zu Zertifikaten, die durch Kubernetes-Mittel bereitgestellt werden. Die Datei trägt den Namen server_ssl.conf und sieht folgendermaßen aus:
{
"port": 7007,
"enable_tls": true,
"server_private_key": "/cert/tls.key",
"server_cert": "/cert/tls.crt",
"enable_client_authentication": false,
"working_dir": "/opt/oracle/graph/pgx/tmp_data"
}
Ein beispielhafter Aufruf zur Erzeugung eines Docker Image aus diesem Dockerfile heraus könnte wie folgt aussehen:
podman build . -f Dockerfile --tag graph-server:24.4.0 --build-arg VERSION_OPG=24.4.0 --build-arg VERSION_JDK=17.0.13 podman tag graph-server:24.4.0 fra.ocir.io/frul1g8cgfam/pub_graphserver:24.4.0 podman push fra.ocir.io/frul1g8cgfam/pub_graphserver:24.4.0
Statt eines docker Kommando nutze ich hier podman, und die Versionen des vorab von edelivery.oracle.com heruntergeladenen Graph Servers und des JDK sind 24.4.0 bzw. 17.0.13. Das Image wird in diesem Beispiel nach Erzeugung in die Oracle Cloud hochgeladen. Diese Schritte wurden Ihnen übrigens bereits abgenommen: Sie dürfen bitte nur zu Testzwecken ein vorab bereits erzeugtes Image gerne benutzen, es benötigt kein Kennwort für den Download. Die obige Image-URL ist bereits im Helm Chart eingetragen, d.h. Sie müssen sich hier nichts notieren.
Erklärung zum automatisierten Customizing des Jupyter Standard-images “scipy”
Gemeinsam mit dem Graph Server wird ein Jupyter-Container eingerichtet für die Ausführung und Erstellung von Notebooks, d.h. dokumentierten Skripten und deren Ausführungsergebnissen. Forschungsprotokolle wenn man so sagen möchte, meist mit Python Code und eingebettetem SQL oder REST Service Aufrufen. Beim verwendeten Container handelt es sich um einen von zahlreichen scipy Standard-Containern für verschiedene Umgebungen, zum Beispiel mit und ohne GPU, mit und ohne Java, JavaScript usw. Unterstützung. Der Quellcode und diverse Links zu vorbereiteten Containern finden Sie auf github: https://github.com/jupyter/docker-stacks. In unserer Beispiel-Umgebung wird ein relativ aktuelles scipy-image auf quay.io benutzt: quay.io/jupyter/scipy-notebook:2024-05-27. Es ist bereits im Helm Chart eingetragen, Sie müssen sich auch hier nichts notieren.
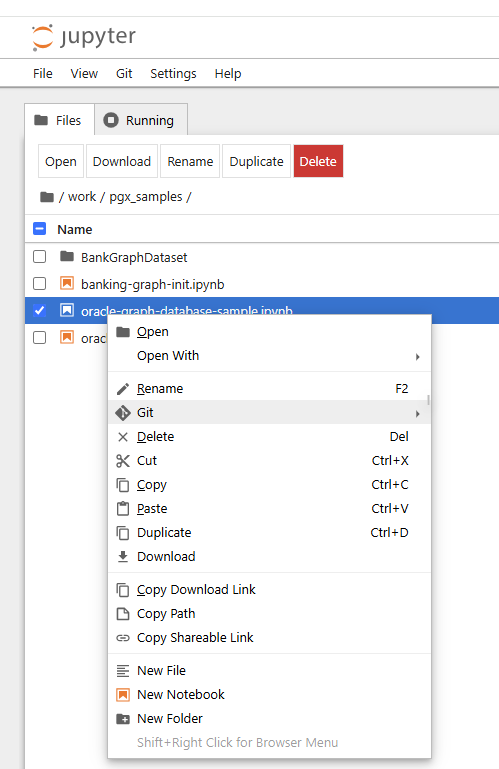 Jupyter Container haben von Haus aus eine integrierte git Unterstützung, d.h. auf der Terminal Oberfläche steht das Tool git zur Verfügung, auch die Menüs in den Notebooks bieten git Operationen an wie push, commit, usw. Beim Start des Containers wird ein Shell Skript ausgeführt welches das wählbare Kennwort für die Jupyter-Umgebung setzt (default hier: jupyter) und auch einige Notebooks aus einem öffentlichen git Repository lädt. Die dafür genutzte URL kann bei Einrichtung des Helm Charts frei gewählt werden, falls Sie lieber ein persönliches git Repostory nutzen möchten.
Jupyter Container haben von Haus aus eine integrierte git Unterstützung, d.h. auf der Terminal Oberfläche steht das Tool git zur Verfügung, auch die Menüs in den Notebooks bieten git Operationen an wie push, commit, usw. Beim Start des Containers wird ein Shell Skript ausgeführt welches das wählbare Kennwort für die Jupyter-Umgebung setzt (default hier: jupyter) und auch einige Notebooks aus einem öffentlichen git Repository lädt. Die dafür genutzte URL kann bei Einrichtung des Helm Charts frei gewählt werden, falls Sie lieber ein persönliches git Repostory nutzen möchten.
Das eben erwähnte Shell Skript wird in einem sogenannten initContainer ausgeführt. Es konfiguriert den eigentlichen Anwendungscontainer kurz vor dessen Start, so daß kein eigenes Image erzeugt werden muß. Das Skript ist in einer Kubernetes ConfigMap hinterlegt. Diese ConfigMap kann von Ihnen nachträglich geändert und angepaßt werden. Es ist nach Änderung lediglich der Kubernetes Pod durchzustarten, d.h. zu löschen – er wird von Kubernetes dann wieder nachgestartet.
Der Jupyter Container erhält per Umgebungsvariablen JDBC_URL und GRAPH_URL die Verbindungsinformationen zum Graph Server und zur verknüpften Datenbank. Die per git clone Kommando automatisch geladenen Beispiel-Notebooks lesen diese aus und verbinden sich so mit Datenbank und Graph Server.
Der Jupyter Container lädt zusätzlich beim Start den Oracle instant client sowie sqlplus herunter und richtet beide ein, damit Notebooks und das ebenfalls enthaltene Shell-Terminal sich mit Oracle Datenbanken verbinden können. Der in Python geschriebene Oracle Treiber oracledb kommt normalerweise ohne eine instant client Installation aus. Aber nicht in jedem Fall, z.B. wird bei bestimmten Verschlüsselungsmechanismen auf die shared libraries des instant client zurückgegriffen.
Je nach genutztem Jupyter Notebook wird der Oracle Treiber, ein Graph Server Client, Java Runtime und Visualisierungsbibliotheken (aktuell noch vis.js bzw. pyvis, nicht die Oracle Visualisation Libraries for JavaScript) nachinstalliert. Die automatisch heruntergeladenen Notebooks wurden angepaßt, aber basieren auf Beispielen des Oracle Graph Product Management auf github, z.B. den pgx Samples.
Vorbedingungen für die Einrichtung unter Kubernetes
Die meisten aufgeführten Vorbedingungen sind eher optional aber sicher sinnvoll:
Installationstool:
Statt das Helm Chart per Kommandozeile zu installieren bietet eine grafische Browser-Oberfläche mehr Komfort und ermöglicht es Entwicklern und Analysten, schnell per self service und mit wenigen Clicks eine eigene Umgebung einzurichten. Legen Sie dafür vorab Kubernetes Benutzer-Accounts an mit Berechtigungen z.B. nur auf einen bestimmten vorgesehenen Namespace. Ein geeignetes Werkzeug für interaktive Deployments ist beispielsweise kubeapps. Es läßt sich sehr leicht per helm aus dem bitnami chart repository heraus installieren und wird auch von anderen Kubernetes Distributionen wie tanzu empfohlen. In diesem Blog erkläre ich die Installation jedoch über die Kommandozeile mittels helm. Dafür sollte das Werkzeug auf einem Rechner installiert sein, der bereits Zugang zu Ihrem Kubernetes cluster hat z.B. mittels kubectl. Das also eine gültige kubeconfig – Datei besitzt.
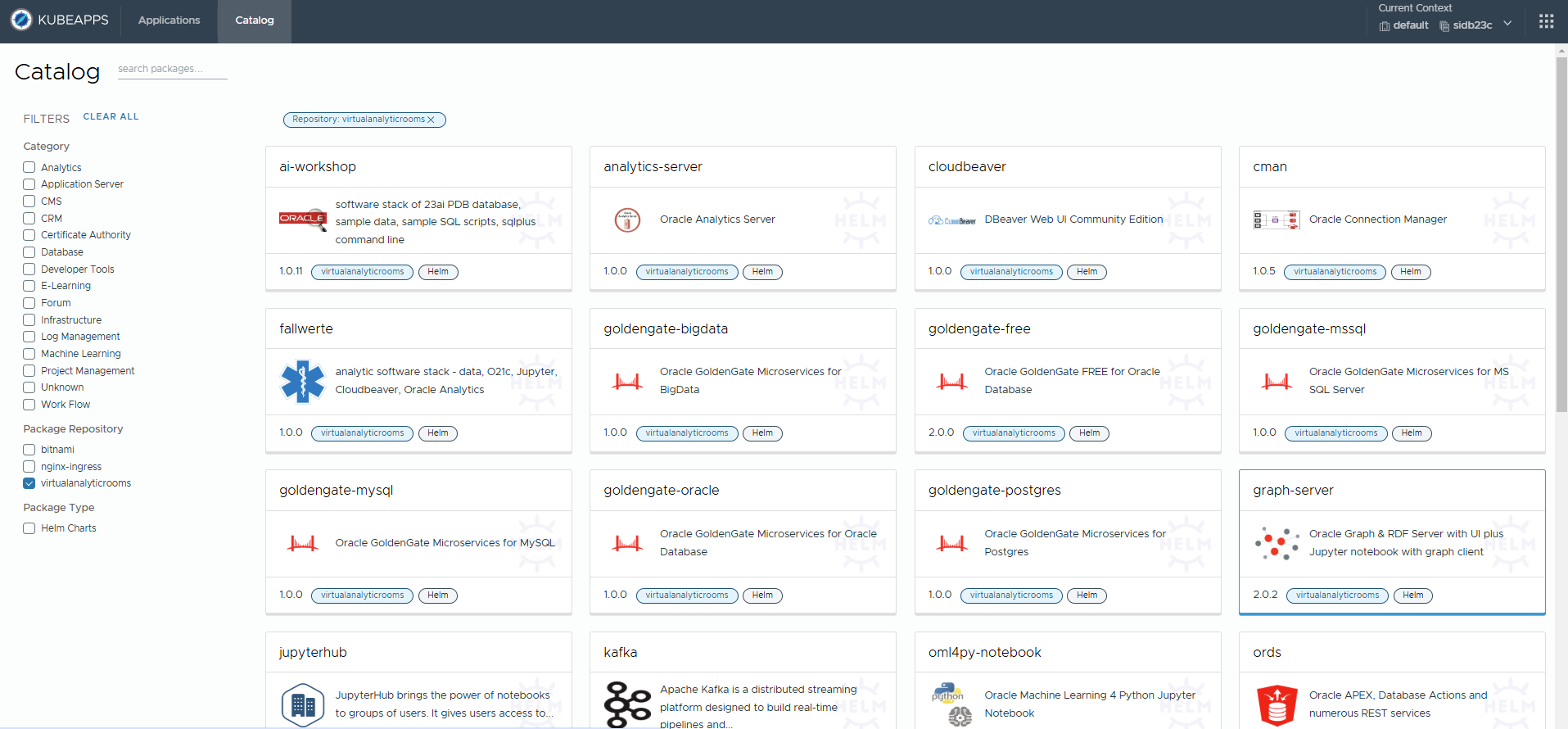
Internet-Zugang des Clusters:
Während der Installation und auch durch die Jupyter Notebooks selbst werden wenige zip-Dateien und zwei Container Images aus dem Internet heruntergeladen. Auch die Installationsroutine, d.h. das helm chart, wird heruntergeladen und ausgeführt. Das bedeutet daß Ihr Kubernetes Cluster einen Internet-Zugang haben sollte, sonst erschwert sich die Installation ein wenig. Denn Sie können bei der Installation den Ort der Container Images frei angeben und diese vor Installation in Ihr privates Repository kopieren. Nötige Python Bibliotheken wie der Oracle Graph Client, Oracle Datenbank Treiber, JDK 17 und dessen Installationsroutinen, die in den Notebooks nachgeladen werden, müßten Sie in den Notebooks selbst angeben und/oder per Browser in den Jupyter Container laden. Auch der Oracle instant client wäre in der bereitgestellten ConfigMap bzw. im Initialisierungsskript anderweitig zu beschaffen und dort einzutragen. Das angebundene git Repository für Jupyter Notebooks auf github.com sollte erreichbar sein – eine andere URL als der Default kann bei der Installation angegeben werden. Auch das helm chart selbst kann vorab heruntergeladen werden und laesst sich lokal nutzen.
Browser-Zugang zum Cluster:
Um die User Interfaces des Graph Server und des Jupyter Containers nutzen zu können, werden zunächst Kubernetes Services eingerichtet vom Typ ClusterIP. Sie haben die Wahl ob Sie eigene Kubernetes Ressourcen anhängen möchten um diese Services außerhalb des Kubernetes Clusters anzusprechen. Beispielsweise könnten Sie zu Testzwecken ein port-forwarding konfigurieren um zu sehen, ob die Dienste überhaupt funktionsfähig sind. Oder Sie ändern den Typ der Services von ClusterIP auf NodePort oder LoadBalancer, um direkt von außen mit den Containern zu sprechen. Jedoch werden unter Kubernetes Dienste meist über ein zentrales Gateway eingebunden, ein Ingress oder ein VirtualService entscheidet, an welchen Container ein Browser Request weitergeleitet wird. Das helm chart unterstützt zu diesem Zweck istio VirtualServices oder wahlweise einen kubernetes Ingress mit wählbarer IngressClass (z.B. nginx, traefik oder auch istio). Eine OpenShift Route wäre manuell zu definieren, dazu können Sie den Support für Gateways, Ingresses und VirtualServices gerne bei der Installation deaktivieren.
Storage und hausinterner Netzwerk Zugang des Clusters:
Die eingerichteten Container verwenden selbst keinerlei Persistent Storage, also keine Volumes und auch keine Persistent Volume Claims. Sie beziehen ihre Strukturen und Zustände aus einer externen Oracle Datenbank mit deren Daten und Graphen darin sowie aus einem git Repository mit Notebooks. Alle nicht im Container Image vorhandenen Komponenten werden beim Start nachgeladen und installiert. Als Storage gelten aber auch Kubernetes ConfigMaps und Secrets. ConfigMaps werden durch das Helm Chart angelegt. Secrets (Kennwörter, Zertifikate, ssh-keys) müssen vorab angelegt werden und werden durch das Helm Chart eingebunden. Secrets sind aber optional, d.h. sie werden per default nicht genutzt. Achten Sie bitte darauf daß die einzubindende Oracle Datenbank vom Kubernetes Cluster aus erreichbar ist (Firewall, Routing, Namensauflösung) sowie alle anderen Komponenten, die über das interne Netzwerk statt dem Internet zu erreichen sind wie git repository, container registry, download server des Instant Client, Python Bibliotheken und JDK.
Einrichtung des Helm Charts per Kommandozeile
Legen Sie bitte vor der Installation einen Namespace in Kubernetes an, in den Sie ungestört hinein installieren und testen können. Beispielsweise graph-server:
$ kubectl create namespace graph-server namespace graph-server created
Dann binden Sie ein helm chart Repository ein mit einem kreativen sprechenden Namen, vielleicht besser als das hier gewählte myorarepo. Das Repository wird über github bereitgestellt (https://ilfur.github.io/VirtualAnalyticRooms/) und enthält das graph-server chart. Dann listen Sie alle darin verfügbaren charts einmal testhalber auf:
$ helm repo add myorarepo https://ilfur.github.io/VirtualAnalyticRooms/ "myorarepo" has been added to your repositories $ helm repo list artifact-hub https://artifacthub.github.io/helm-charts/ argo-cd https://argoproj.github.io/argo-helm bitnami https://charts.bitnami.com/bitnami myorarepo https://ilfur.github.io/VirtualAnalyticRooms/ $ helm search repo myorarepo NAME CHART VERSION APP VERSION DESCRIPTION myorarepo/graph-server 2.0.2 24.4.0.0.0 Oracle Graph & RDF Server with UI plus Jupyter ... myorarepo/ai-workshop 1.0.11 23.4.0 software stack of 23ai PDB database, sample dat... myorarepo/cloudbeaver 1.0.0 21.3.3 DBeaver Web UI Community Edition myorarepo/cman 1.0.5 23.5.0.0 Oracle Connection Manager myorarepo/goldengate-free 2.0.0 23.4.0.0.0 Oracle GoldenGate FREE for Oracle Database myorarepo/ords 2.0.0 latest Oracle APEX, Database Actions and numerous REST... myorarepo/radlaufstellen 1.0.0 21.3.0 analytic software stack of machine learning dat... myorarepo/sqlcl-liquibase 1.0.0 21.3.0.0.0 Oracle sqlcl with liquibase integration myorarepo/varraddauerzaehlstellen 1.0.3 21.3.0 analytic software stack - data, O21c, Jupyter, ... ... ...
Das eingebundene Repository myorarepo enthält neben dem graph-server auch weitere charts für Oracle Komponenten wie Goldengate, ORDS, Connection Manager usw. Auch alle Chart Quellcodes liegen offen zur Anpassung an eigene Bedürfnisse auf https://github.com/ilfur/VirtualAnalyticRooms. Die meisten Charts verwenden im Moment noch ältere Container-Images und sind nicht ganz so flexibel aufgebaut. Sie sollten daher mehr nur als Quelle für eigene Ideen und Anpassungen dienen.
Jetzt laden Sie sich die Parameter-Datei für das graph-server chart herunter, um sie anzuschauen und an eigene Bedürfnisse anzupassen. Der Einfachheit halber empfehle ich zunächst ein setup ganz ohne SSL Verschlüsselung und ohne Ingress, einfach nur um zu prüfen ob die Einrichtung funktioniert. Danach können Sie gerne die Installation rückgängig machen (uninstall) und mit anderen Parametern erneut versuchen.
$ helm show values myorarepo/graph-server >myvalues.yaml $ cat myvalues.yaml image: pullPolicy: IfNotPresent graph: fra.ocir.io/frul1g8cgfam/pub_graphserver:24.4.0 jupyter: quay.io/jupyter/scipy-notebook:2024-05-27 services: ### a clusterIP type service will be created for graph and jupyter UIs. ### You can choose to create an istio virtualservice or an ingress in front of it ### with a virtual host name of <vhostName> external: ### set type to either ingress , virtualservice or none if You need something customized type: ingress ### typical ingressClasses are nginx and istio ingressClass: nginx ### ignored if type is not virtualservice vserviceGateway: istio-system/http-istio-gateway vhostName: 141.147.33.9.nip.io internal: graph: ### graph server can run with no ssl (ssl: "off") or with self-signed certificates (ssl: selfsigned) or with external certificates(ssl: secret). ssl: "off" ### should container tls.cert and tls.key entries, but is ignored when ssl is off or selfsigned. tlsSecretName: graph-tls jupyter: ### currently, only ssl: off and ssl: selfsigned are working, but will in the near future ssl: "off" ### should container tls.cert and tls.key entries, but is ignored when ssl is off or selfsigned. tlsSecretName: graph-tls database: ## The database user must have at least GRAPH_DEVELOPER role connection: "jdbc:oracle:thin:@db23c.sidb23c:1521/FREEPDB1" git: ## use this https repository for samples, better use ssh repositories for Your own purposes jupyterRepo: "https://github.com/ilfur/pgx_samples" type: public ## sshKey is ignored if repo type is public. no push possible then. sshKeySecretName: git-ssh jupyter: password: jupyter deployJupyter: true
Nun passen Sie einige Parameter an Ihre Gegebenheiten an. Typisch für YAML Dateiformate sind die Spalten, in denen die Parameter eingetragen werden. Bitte behalten Sie daher die Text-Einrückungen unbedingt bei !
Zumindest der Datenbank Connect (database.connection Parameter) sollte auf Ihre Datenbank verweisen, nicht auf meine Testdatenbank FREEPDB1. Version 23ai ist übrigens nicht unbedingt notwendig, aber Sie können gerne ein Oracle 23ai free Container Image für Tests nutzen. Ein Datenbank-Benutzer ist hier noch nicht anzugeben, denn der wird erst beim Login in das User Interface abgefragt. Ihre Test-Datenbank sollte einen vorab angelegten Benutzer anbieten, der neben typischen CONNECT, CREATE und SELECT Rechten auch eine GRAPH_DEVELOPER Rolle besitzt.
Auch der Parameter services.external.type sollte testweise vielleicht noch auf “off” gesetzt sein (mit den Gänsefüßchen bitte, damit der Parameter nicht aus Versehen als Datentyp boolean interpretiert wird !). Denn zunächst interessiert wahrscheinlich eher, ob die Container starten und sich einrichten können.
Interressiert Sie nur der Graph Server und nicht die Kombination mit Jupyter, so können Sie den Parameter jupyter.deployJupyter gerne auf false setzen. Das vereinfacht das Setup noch ein ganzes Stückchen, der Jupyter Container wird dann eben nicht eingerichtet.
Weitere, eher optionale Parameter:
Die beiden Container können entweder intern ganz ohne SSL kommunizieren, also in plain HTTP, und das Gateway sichert den Zugriff von außen per SSL. Oder Sie definieren im Parameter service.internal.graph.type bzw. service.internal.jupyter.type selfsigned Zertifikate für die interne Verschlüsselung, dann erzeugen die beiden Container eigene Zertifikate und lauschen verschlüsselt mit eigentlich ungültigen Zertifikaten. Diese werden übrigens vom Oracle Graph Client in Jupyter übelgenommen, ein Connect zum Graph Server funktioniert dann nur wenn das ebenfalls erzeugte root Zertifikat ins JDK des Jupyter Containers kopiert wird. Dies erfolgt noch nicht automatisch. Beim service.internal.graph.type secret sind Zertifikate in einem Kubernetes Secret zu hinterlegen. Die zu verwendenden Schlüssel lauten tls.key und tls.crt, eher absichtlich als zufällig die Standard-Bezeichnungen für Zertifikats-Secrets, die vom optionalen und komfortablen Kubernetes Tool cert-manager vergeben werden. Der Jupyter Container kann momentan noch nicht mit dem typ secret umgehen, das muß noch nachgereicht werden.
Das eingebundene öffentliche git Repository für die Demo Notebooks wird anonym per https angesprochen, nicht per ssh. Und ohne Angabe eines Kennwortes, weil es sich um ein public Repository handelt. Damit sind keine weiteren git Operationen in Jupyter möglich, aber die Notebooks können immerhin beim Start des Containers heruntergeladen werden. Wenn Sie ein eigenes git Repository haben, so tragen Sie gerne dessen ssh:… URL ein und hinterlegen Sie in einem Kubernetes Secret vom default Namen git-ssh die für SSH Zugriff nötigen Dateien. Diese Dateien werden in das .ssh Verzeichnis des Container-Benutzers kopiert und sollten die Namen id_rsa, known_hosts und config tragen. Den git.type Parameter setzen Sie dann bitte auf einen beliebigen anderen Wert als public, z.B. auf protected. Auf Wunsch kann ich Ihnen gerne ein Beispiel zusenden, im Moment ist das vielleicht noch zu früh.
Zuletzt noch als Parameter für die automatische Konfiguration des Jupyter Containers ein wählbares unverschlüsseltes Passwort für das User Interface im Parameter jupyter.password. Vielleicht wäre an dieser Stelle abermals ein Secret besser geeignet, aber es muß ja noch Platz für Verbesserungen und weitere Beratung geben.
Haben Sie nun die Parameter-Datei an Ihre Vorstellungen angepaßt ? Dann wagen wir uns an die Installation und schauen nach, ob die Einrichtung der Container funktioniert hat.
Folgendes helm Kommando installiert das Chart mit Angabe der Parameter Datei “myvalues.yaml” in den vorhin angelegten Namespace graph-server hinein. Bei erfolgter Installation erscheint ein Informationstext mit URLs und weiteren Angaben zur Nutzung.
$ helm install graph-test myorarepo/graph-server --values myvalues.yaml -n graph-server NAME: graph-test LAST DEPLOYED: Fri Jan 10 08:58:29 2025 NAMESPACE: graph-server STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: Final NOTES: The graph server is pointing to this database: jdbc:oracle:thin:@db23c.sidb23c:1521/FREEPDB1 When entering a database user and password, please be aware that this database user must have the GRAPH_DEVELOPER role granted plus standard roles to connect and select data. You decided not to have an ingress or virtualservice configured. So currently, Your graph server and jupyter are reachable only from within the kubernetes cluster, using these names and ports: http://graph-test-graph-server-svc:7007 http://graph-test-graph-server-jup-svc:8080 The Jupyter container uses environment variables JDBC_URL and GRAPH_URL, pointing to the database and the graph server: JDBC_URL=jdbc:oracle:thin:@db23c.sidb23c:1521/FREEPDB1 GRAPH_URL= http://graph-test-graph-server-svc:7007 In jupyter, the Oracle instant client and sqlplus are preinstalled, so You can open a shell in the Jupyter UI and try to connect to Your database with sqlplus too: (Menu File-> New -> Terminal) Then, in the terminal, cd into the directory /home/jovyan/.jupyter/instantclient_23_6 and run ./sqlplus Have fun !
Der Informationstext zeigt generierte URLs aus der Parameterdatei. Wenn Sie beispielsweise Ingress oder VirtualService Generierung abgeschaltet haben (services.external.type auf off) wie in meinem Fall, dann erscheint die Information dass die Container im Moment nur innerhalb des Kubernetes Clusters ansprechbar seien. Doch das schauen wir uns nun gemeinsam an.
Wurden die Container heruntergeladen und gestartet, sind Services angelegt worden und eine ConfigMap mit Start Skript darin ?
$ kubectl get pod -n graph-server NAME READY STATUS RESTARTS AGE graph-test-graph-server-graph-57cc896d66-vq6d8 1/1 Running 0 4m24s graph-test-graph-server-jupyter-857c67b68d-smj4w 1/1 Running 0 4m24s $ kubectl get service -n graph-server NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE graph-test-graph-server-jup-svc ClusterIP 10.109.167.233 <none> 8080/TCP 4m58s graph-test-graph-server-svc ClusterIP 10.101.53.38 <none> 7007/TCP 4m58s $ kubectl get configmap -n graph-server NAME DATA AGE graph-test-graph-server-config 2 5m23s
Die ConfigMap enthält neben einer shared library “libaio.so.1” für den Oracle instant client ein Shell Skript, das Sie gerne nachträglich anpassen können um Einfluß auf Start und Konfiguration des Jupyter Containers zu haben. Die instant client Installation können Sie gerne komplett entfernen. Hier ein Auszug aus der ConfigMap:
$ kubectl get configmap -n graph-server graph-test-graph-server-config -o yaml
...
data:
getfiles.sh: |-
echo "# my notebooks settings
c = get_config()
from jupyter_server.auth import passwd
password = passwd('jupyter')
c.NotebookApp.password = password
c.NotebookApp.base_url = '/jupyter/'
" >> /home/jovyan/.jupyter/jupyter_server_config.py
wget https://download.oracle.com/otn_software/linux/instantclient/2360000/instantclient-basic-linux.x64-23.6.0.24.10.zip
wget https://download.oracle.com/otn_software/linux/instantclient/2360000/instantclient-sqlplus-linux.x64-23.6.0.24.10.zip
unzip instantclient-basic-linux.x64-23.6.0.24.10.zip -d /home/jovyan/.jupyter
unzip instantclient-sqlplus-linux.x64-23.6.0.24.10.zip -d /home/jovyan/.jupyter
cp /scripts/libaio.so.1 /home/jovyan/.jupyter/instantclient_23_6
cd /home/jovyan/work
git clone https://github.com/ilfur/pgx_samples
kind: ConfigMap
...
Dann schauen wir in die Logs der beiden Container hinein. Startet der Graph Server ordentlich ?
$ kubectl logs graph-test-graph-server-graph-57cc896d66-vq6d8 -n graph-server starting Jan 10, 2025 9:20:06 AM org.apache.coyote.AbstractProtocol init INFO: Initializing ProtocolHandler ["http-nio-7007"] Jan 10, 2025 9:20:06 AM org.apache.catalina.core.StandardService startInternal INFO: Starting service [Tomcat] Jan 10, 2025 9:20:06 AM org.apache.catalina.core.StandardEngine startInternal INFO: Starting Servlet engine: [Apache Tomcat/9.0.90] Jan 10, 2025 9:20:11 AM org.apache.catalina.startup.ContextConfig getDefaultWebXmlFragment INFO: No global web.xml found Jan 10, 2025 9:20:12 AM org.apache.jasper.servlet.TldScanner scanJars INFO: At least one JAR was scanned for TLDs yet contained no TLDs. Enable debug logging for this logger for a complete list of JARs that were scanned but no TLDs were found in them. Skipping unneeded JARs during scanning can improve startup time and JSP compilation time. TeeFilter will be ACTIVE on this host [graph-test-graph-server-graph-57cc896d66-vq6d8] Jan 10, 2025 9:20:22 AM org.glassfish.jersey.server.wadl.WadlFeature configure WARNING: JAXBContext implementation could not be found. WADL feature is disabled. Jan 10, 2025 9:20:24 AM org.apache.coyote.AbstractProtocol start INFO: Starting ProtocolHandler ["http-nio-7007"]
Der Jupyter Pod besteht wie weiter oben beschrieben aus zwei Containern, einem initContainer namens get-config und einem Anwendungscontainer namens app. Beide erzeugen Logs, die wir wie folgt einsehen können – nur auszugsweise, weil der Datei Download viele Zeilen Log erzeugt:
$ kubectl logs graph-test-graph-server-jupyter-857c67b68d-smj4w -n graph-server get-config
--2025-01-10 09:20:06-- https://download.oracle.com/otn_software/linux/instantclient/2360000/instantclient-basic-linux.x64-23.6.0.24.10.z
ip
Resolving download.oracle.com (download.oracle.com)... 23.32.100.101
Connecting to download.oracle.com (download.oracle.com)|23.32.100.101|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 127839197 (122M) [application/zip]
Saving to: ‘instantclient-basic-linux.x64-23.6.0.24.10.zip’
0K .......... .......... .......... .......... .......... 0% 32.0M 4s
50K .......... .......... .......... .......... .......... 0% 7.24M 10s
100K .......... .......... .......... .......... .......... 0% 29.0M 8s
...
$ kubectl logs graph-test-graph-server-jupyter-857c67b68d-smj4w -n graph-server app
Entered start.sh with args: start-notebook.py
Running hooks in: /usr/local/bin/start-notebook.d as uid: 1000 gid: 100
Done running hooks in: /usr/local/bin/start-notebook.d
Running hooks in: /usr/local/bin/before-notebook.d as uid: 1000 gid: 100
Sourcing shell script: /usr/local/bin/before-notebook.d/10activate-conda-env.sh
Done running hooks in: /usr/local/bin/before-notebook.d
Executing the command: start-notebook.py
[I 2025-01-10 09:20:41.881 ServerApp] Extension package jupyterlab_git took 0.1680s to import
[W 2025-01-10 09:20:41.946 ServerApp] A `_jupyter_server_extension_points` function was not found in nbclassic. Instead, a `_jupyter_server_extension_paths` function was found and will be used for now. This function name will be deprecated in future releases of Jupyter Server.
[I 2025-01-10 09:20:41.958 ServerApp] jupyter_lsp | extension was successfully linked.
[I 2025-01-10 09:20:42.141 ServerApp] jupyter_server_mathjax | extension was successfully linked.
[I 2025-01-10 09:20:42.178 ServerApp] jupyter_server_terminals | extension was successfully linked.
[W 2025-01-10 09:20:42.587 LabApp] 'password' has moved from NotebookApp to ServerApp. This config will be passed to ServerApp. Be sure to update your config before our next release.
[W 2025-01-10 09:20:42.587 LabApp] 'base_url' has moved from NotebookApp to ServerApp. This config will be passed to ServerApp. Be sure to update your config before our next release.
[W 2025-01-10 09:20:42.598 ServerApp] ServerApp.password config is deprecated in 2.0. Use PasswordIdentityProvider.hashed_password.
[I 2025-01-10 09:20:42.598 ServerApp] jupyterlab | extension was successfully linked.
[I 2025-01-10 09:20:42.599 ServerApp] jupyterlab_git | extension was successfully linked.
[I 2025-01-10 09:20:42.612 ServerApp] nbclassic | extension was successfully linked.
[I 2025-01-10 09:20:42.612 ServerApp] nbdime | extension was successfully linked.
[I 2025-01-10 09:20:42.625 ServerApp] notebook | extension was successfully linked.
[I 2025-01-10 09:20:42.627 ServerApp] Writing Jupyter server cookie secret to /home/jovyan/.local/share/jupyter/runtime/jupyter_cookie_secret
[I 2025-01-10 09:20:45.384 ServerApp] notebook_shim | extension was successfully linked.
[I 2025-01-10 09:20:45.445 ServerApp] notebook_shim | extension was successfully loaded.
[I 2025-01-10 09:20:45.448 ServerApp] jupyter_lsp | extension was successfully loaded.
[I 2025-01-10 09:20:45.449 ServerApp] jupyter_server_mathjax | extension was successfully loaded.
[I 2025-01-10 09:20:45.450 ServerApp] jupyter_server_terminals | extension was successfully loaded.
[I 2025-01-10 09:20:45.453 LabApp] JupyterLab extension loaded from /opt/conda/lib/python3.11/site-packages/jupyterlab
[I 2025-01-10 09:20:45.453 LabApp] JupyterLab application directory is /opt/conda/share/jupyter/lab
[I 2025-01-10 09:20:45.454 LabApp] Extension Manager is 'pypi'.
[I 2025-01-10 09:20:45.475 ServerApp] jupyterlab | extension was successfully loaded.
[I 2025-01-10 09:20:45.482 ServerApp] jupyterlab_git | extension was successfully loaded.
[I 2025-01-10 09:20:45.486 ServerApp] nbclassic | extension was successfully loaded.
[I 2025-01-10 09:20:45.591 ServerApp] nbdime | extension was successfully loaded.
[I 2025-01-10 09:20:45.615 ServerApp] notebook | extension was successfully loaded.
[I 2025-01-10 09:20:45.615 ServerApp] Serving notebooks from local directory: /home/jovyan
[I 2025-01-10 09:20:45.615 ServerApp] Jupyter Server 2.14.0 is running at:
[I 2025-01-10 09:20:45.615 ServerApp] http://graph-test-graph-server-jupyter-857c67b68d-smj4w:8888/jupyter/tree
[I 2025-01-10 09:20:45.615 ServerApp] http://127.0.0.1:8888/jupyter/tree
[I 2025-01-10 09:20:45.615 ServerApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[I 2025-01-10 09:20:49.018 ServerApp] Skipped non-installed server(s): bash-language-server, dockerfile-language-server-nodejs, javascript-typescript-langserver, jedi-language-server, julia-language-server, pyright, python-language-server, python-lsp-server, r-languageserver, sql-language-server, texlab, typescript-language-server, unified-language-server, vscode-css-languageserver-bin, vscode-html-languageserver-bin, vscode-json-languageserver-bin, yaml-language-server
Dann bleibt noch ein kleiner Test, ob die Container per Netzwerk erreichbar sind. Entweder Sie ändern den Typ der angelegten Services von ClusterIP auf NodePort oder LoadBalancer und nutzen die dadurch erzeugten externen IP Adressen, oder wir Tunneln für einen einfachen Test die Ports der beiden Container auf den Rechner, von dem aus die Installation erfolgte. Letzteres funktioniert folgendermaßen:
$ kubectl port-forward graph-test-graph-server-graph-57cc896d66-vq6d8 -n graph-server 7007:7007 & Forwarding from 127.0.0.1:7007 -> 7007 Forwarding from [::1]:7007 -> 7007 $ curl http://127.0.0.1:7007/dash/ -v * Trying 127.0.0.1... * TCP_NODELAY set * Connected to 127.0.0.1 (127.0.0.1) port 7007 (#0) Handling connection for 7007 > GET /dash/ HTTP/1.1 > Host: 127.0.0.1:7007 > User-Agent: curl/7.61.1 > Accept: */* > < HTTP/1.1 200 < X-Content-Type-Options: nosniff < X-Frame-Options: SAMEORIGIN < X-XSS-Protection: 1 < Content-Type: text/html < Content-Length: 1266 < Date: Fri, 10 Jan 2025 09:56:49 GMT < <!doctype html><html lang="en-us"><head><title>Graph Dashboard</title><meta charset="UTF-8"/><meta name="viewport" content="viewport-fit=cover,width=device-width,initial-scale=1"/><meta name="description" content="Graph Dashboard"/><link rel="icon" href="styles/images/JET-Favicon-Red-32x32.png" type="image/x-icon"/><link rel="stylesheet" href="https://static.oracle.com/cdn/apex/21.2.4/libraries/font-apex/2.2.1/css/font-apex.min.css?v=21.2.5"><link rel="stylesheet" type="text/css" href="styles/redwood/16.1.6/web/redwood.min.css"> <link rel="stylesheet" type="text/css" href="styles/theme-redwood/16.1.6/web/theme.css"> ......
D.h. der interne Port 7007 des Containers wurde an den Port 7007 des lokalen Rechners weitergeleitet. Haben Sie hier eine grafische Oberfläche parat, können Sie den Graph Server nun auch über einen Browser ansprechen. Ganz ähnlich verhält es sich mit dem Jupyter Container, den Sie gleichzeitig auf einen anderen Port als 7007 hinzuschalten können. Wie wäre es mit 8888, dem gleichen Port wie der innerhalb des Jupyter Containers ?
$ kubectl port-forward graph-test-graph-server-jupyter-857c67b68d-smj4w -n graph-server 8888:8888 Forwarding from 127.0.0.1:8888 -> 8888 Forwarding from [::1]:8888 -> 8888 $ curl http://127.0.0.1:8888/jupyter -v * Trying 127.0.0.1... * TCP_NODELAY set * Connected to 127.0.0.1 (127.0.0.1) port 8888 (#0) > GET /jupyter HTTP/1.1 > Host: 127.0.0.1:8888 > User-Agent: curl/7.61.1 > Accept: */* > Handling connection for 8888 < HTTP/1.1 302 Found < Server: TornadoServer/6.4 < Content-Type: text/html; charset=UTF-8 < Date: Fri, 10 Jan 2025 10:04:55 GMT < Location: /jupyter/tree? < Content-Length: 0 < * Connection #0 to host 127.0.0.1 left intact
Das sollte als initialer Test genügen und die Umgebung sollte damit eigentlich funktionieren ! Bei Ingresses und SSL Verschlüsselung stehe ich gerne für Rückfragen zur Verfügung, ich denke im Moment sprengen sie nur den Rahmen dieses Blogs. Viel lieber möchte ich Ihnen im Folgenden die Oberflächen und die bereitgestellten Notebooks kurz zeigen und erklären.
Feature Beschreibung und Lösungs-Clickthrough
Das User Interface des Oracle Graph Server sollte nun auf unterschiedliche Weise per Browser erreichbar sein. Ich habe eine Konfiguration services.external.type virtualservice gewählt und als services.external.vhostName den Eintrag graph.test.141.147.33.9.nip.io, d.h. den Namen eines extern erreichbaren Gateways in meinem Kubernetes Cluster. Das Gateway verwendet SSL Verschlüsselung, der Graph Server und Jupyter nicht. In dieser Konfiguration ist das Graph Server UI und dessen REST Services erreichbar unter der Adresse https://graph.test.141.147.33.9.nip.io/dash , die Jupyter Oberfläche klinkt sich nahtlos ein über die URI /jupyter, oder auch vollständig https://graph.test.141.147.33.9.nip.io/jupyter. Beide UIs melden sich mit einem Login:
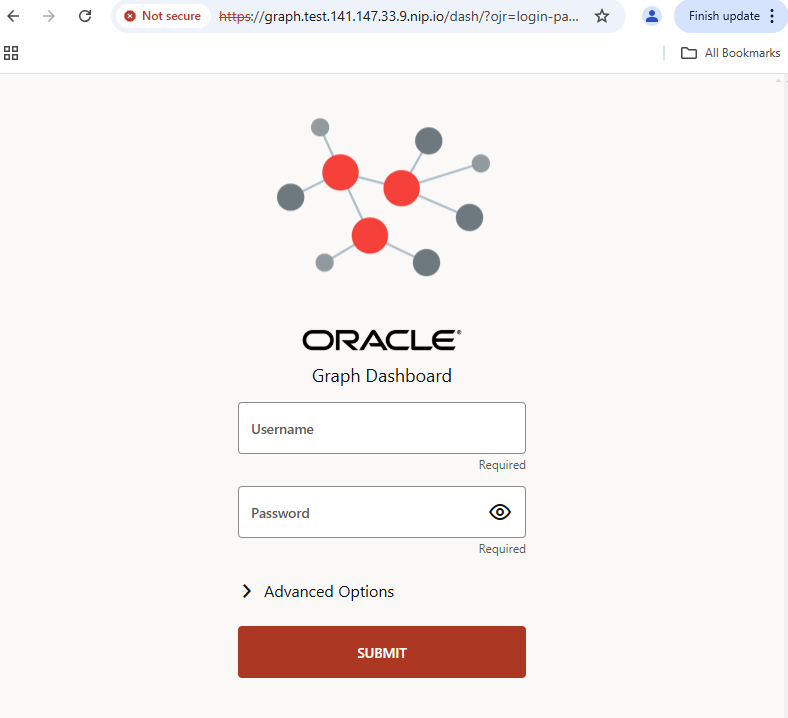
Der Graph Server und auch die angebundene Oracle Datenbank haben vermutlich noch keine Graphen geladen oder konfiguriert. Vielleicht existiert auch noch kein Datenbank-Benutzer in Ihrer Umgebung mit der GRAPH_DEVELOPER Rolle, um sich über den Graph Server bei der Oracle Datenbank anzumelden. Daher betrachten wir zunächst die Jupyter Umgebung, denn eines der geladenen Notebooks bietet installierbare Demo-Daten und Graph Strukturen an, den “banking graph” mit Banktransaktionen darin. Melden Sie sich in Jupyter bitte mit dem Kennwort an, das Sie bei der Installation vergeben haben. Wahrscheinlich lautet es jupyter . Dann starten Sie ein Terminal-Fenster und rufen darin sqlplus auf, um sich als berechtigter Benutzer (z.B. system) mit Ihrer Datenbank zu verbinden und einen bankgraph Benutzer anzulegen.
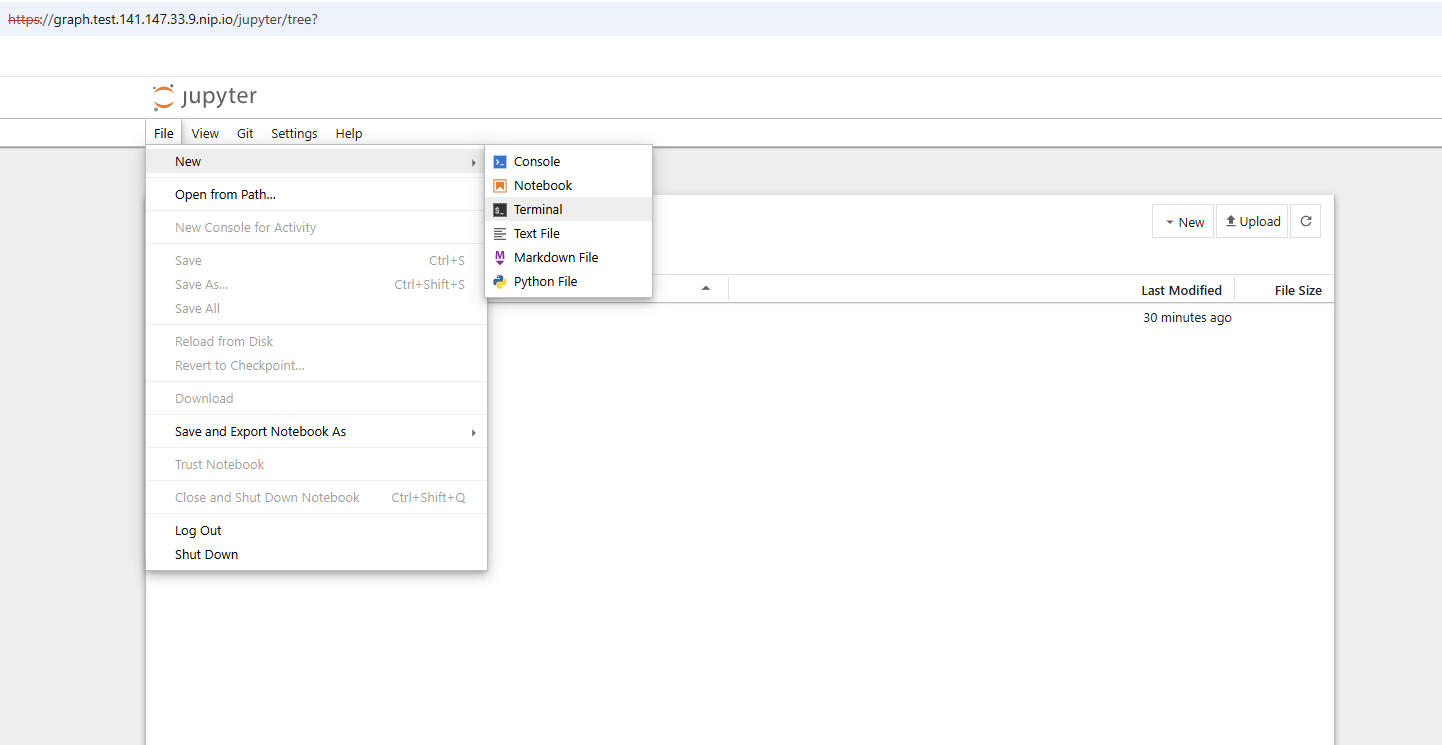
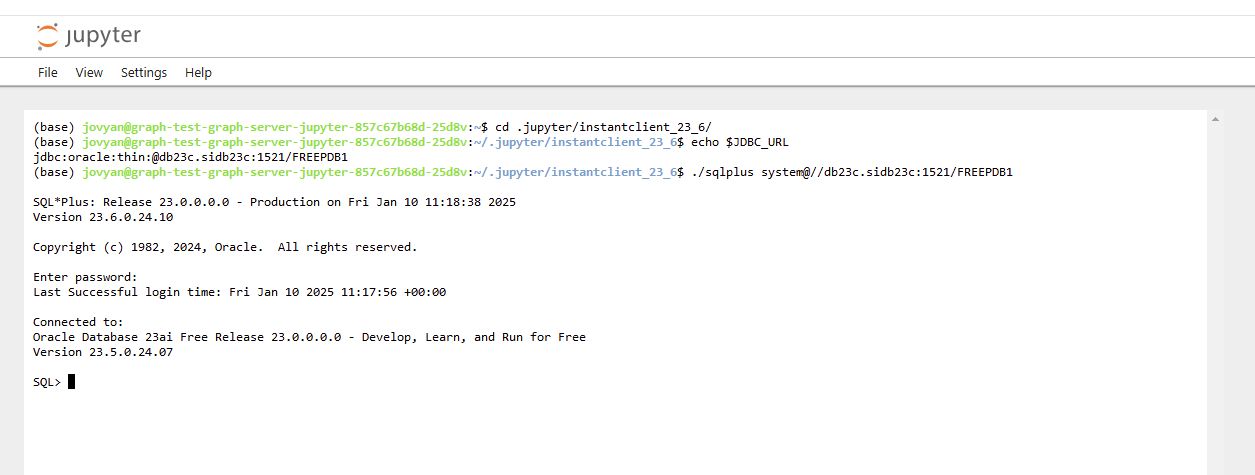
Das Verzeichnis der instant client Installation lautet hier ~/.jupyter/instantclient_23_6 , die Umgebungsvariable JDBC_URL enthält den Namen der noch einzurichtenden Datenbank. Mittels ./sqlplus (die PATH Variable ist hier nicht gesetzt!) kommen Sie an Ihre Datenbank heran. Den gleich noch nötigen bankgraph Benutzer legen Sie sinngemäß mit folgenden SQL Kommandos an:
CREATE USER bankgraph IDENTIFIED BY Welcome1 DEFAULT TABLESPACE users TEMPORARY TABLESPACE temp QUOTA UNLIMITED ON users; GRANT alter session , create procedure , create sequence , create session , create table , create trigger , create type , create view , graph_developer -- This role is required for using Graph Server TO bankgraph;
Es gibt keinen Zwang, sqlplus zu verwenden. Es ist ein wie ich finde zeigenswertes Feature dieser Umgebung, eine Kommandozeile im Browser zu haben. Und sogar mit sqlplus darin.
Also wenden wir uns lieber den Notebooks zu. Im Hintergrund wurden per git Kommando bereits einige Notebooks heruntergeladen. Das erste anzuschauende Notebook liegt im Verzeichnis work/pgx-samples/banking-graph-init.ipynb :
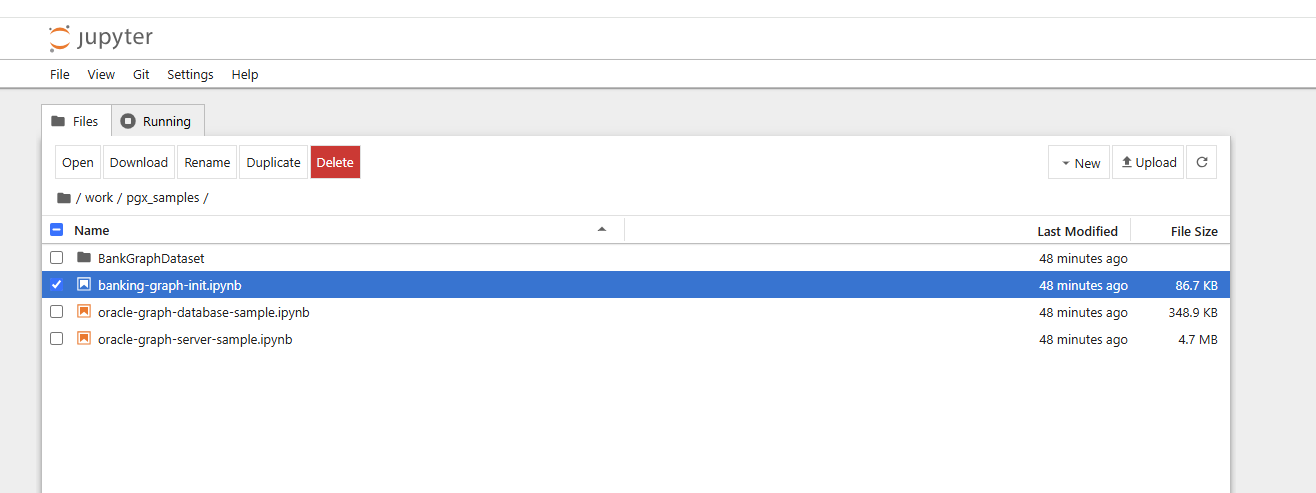
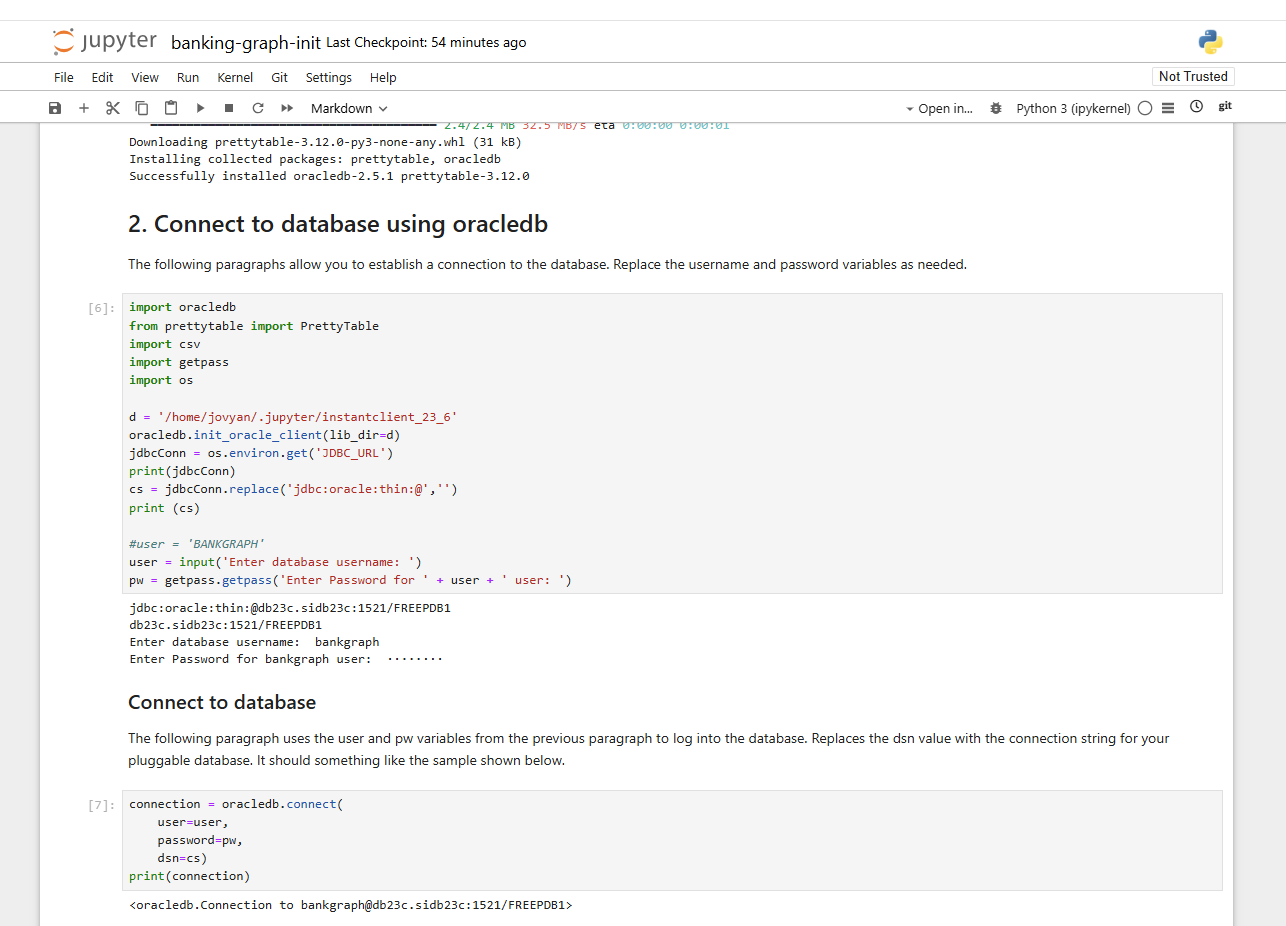
Das Notebook erzeugt Datenbank-Tabellen und legt einen Property Graphen an, den Sie zusätzlich mit dem Graph Server UI auslesen und visualisieren können. Andere Notebooks visualisieren und befragen wahlweise den Graph Server oder die Oracle Database mit SQL/PGQ. Sie sehen an dem gezeigten Notebook, daß der installierte Oracle instant client von Python aus benutzt wird und der Datenbank Connect aus der JDBC_URL Umgebungsvariable ausgelesen wird. Sie können nun Schritt um Schritt in dem Notebook ausführen lassen und mit dem Grahpen für Finanz-Transaktionen experimientieren.
Das zweite Jupyter Notebook oracle-graph-server-sample.ipynb verbindet sich mit dem Graph Server über die Umgebungsvariable GRAPH_URL. Das Notebook installiert zusätzlich den Oracle Graph Client für Python und das dafür notwendige JDK 17.
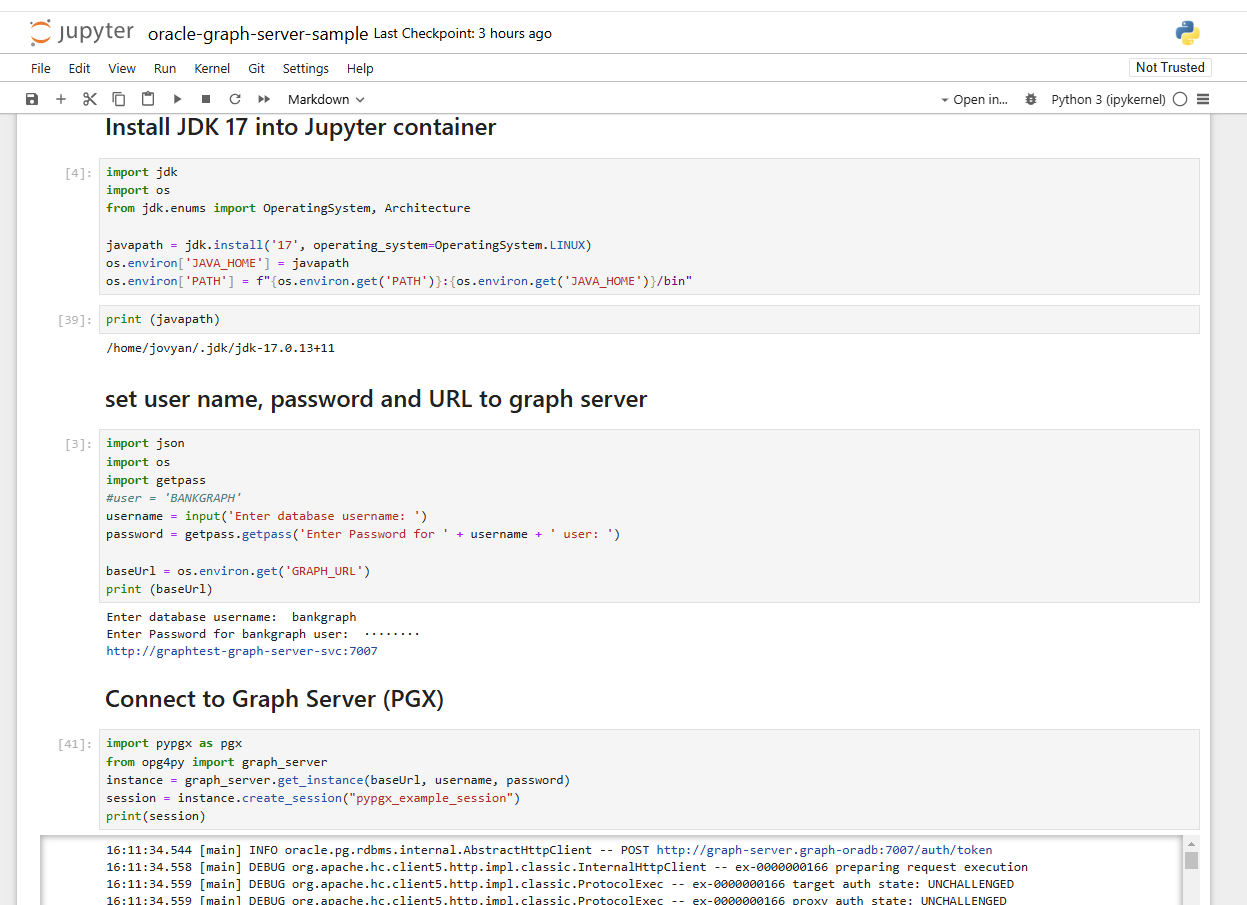
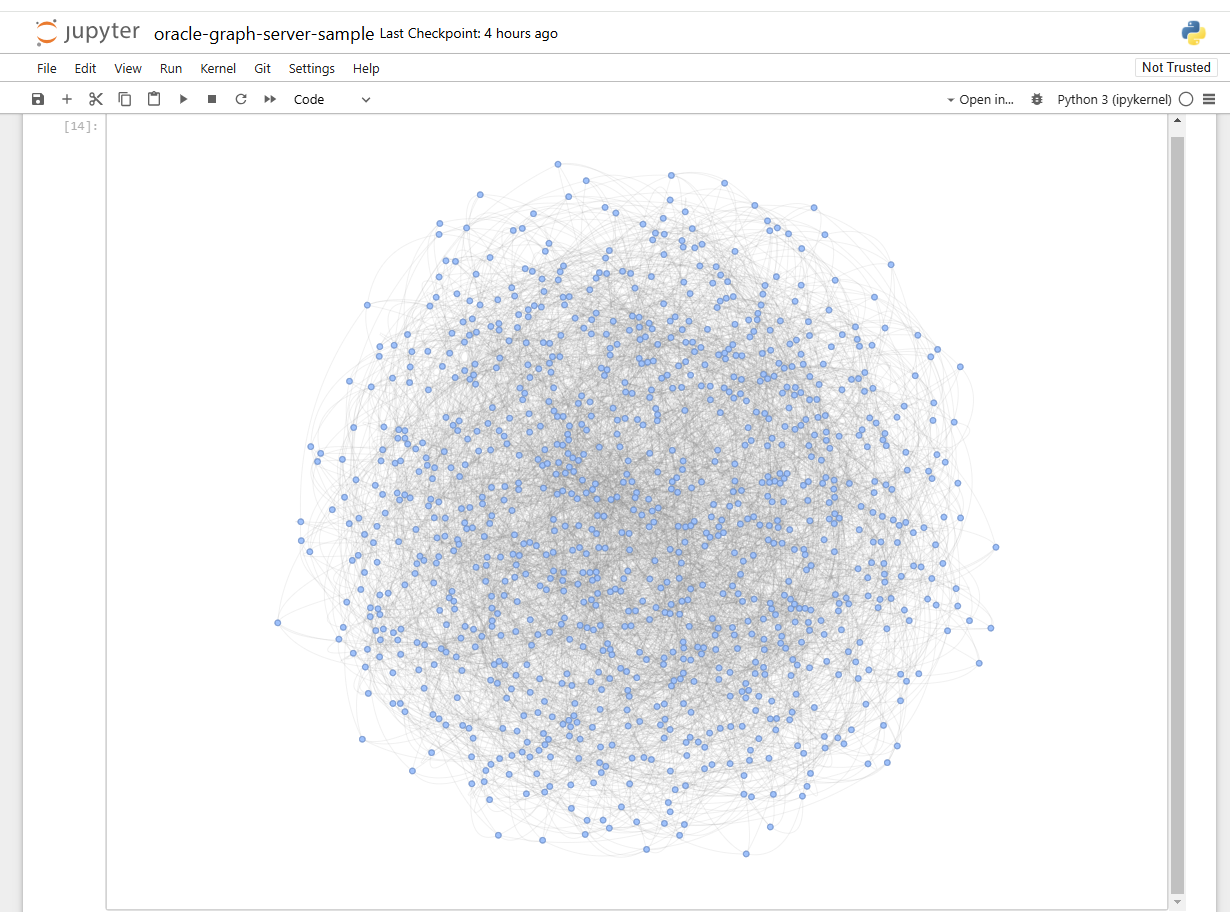
An späterer Stelle im gleichen Notebook wird der zuvor geladene Graph BANK_GRAPH aus der Datenbank in den Graph Server übertragen. Die Visualisierungsbibliothek vis.js lädt die etwa 5000 Knoten des Graphen und stellt sie nach einer Wartezeit von mehreren Minuten auch recht ansehnlich dar. Sie dürfen hier gerne mit Filtern und optimierter Rückgabemenge experimentieren, um die Wartezeit zukünftig zu verkürzen. Die wesentlich flottere Oracle Visualisation Library für JavaScript besitzt noch keine Unterstützung für Python bzw. kein Jupyter plugin, aber das stünde laut Product Management auf der Roadmap.
Wenden Sie sich nun wieder der Graph Server UI zu und melden Sie sich an als bankgraph Benutzer, der die geladenen Daten und Graphen aus den Jupyter Notebooks innehat.

Wechseln Sie von der Standard-Ansicht auf den Tab “Database (SQL Property Graphs)”.
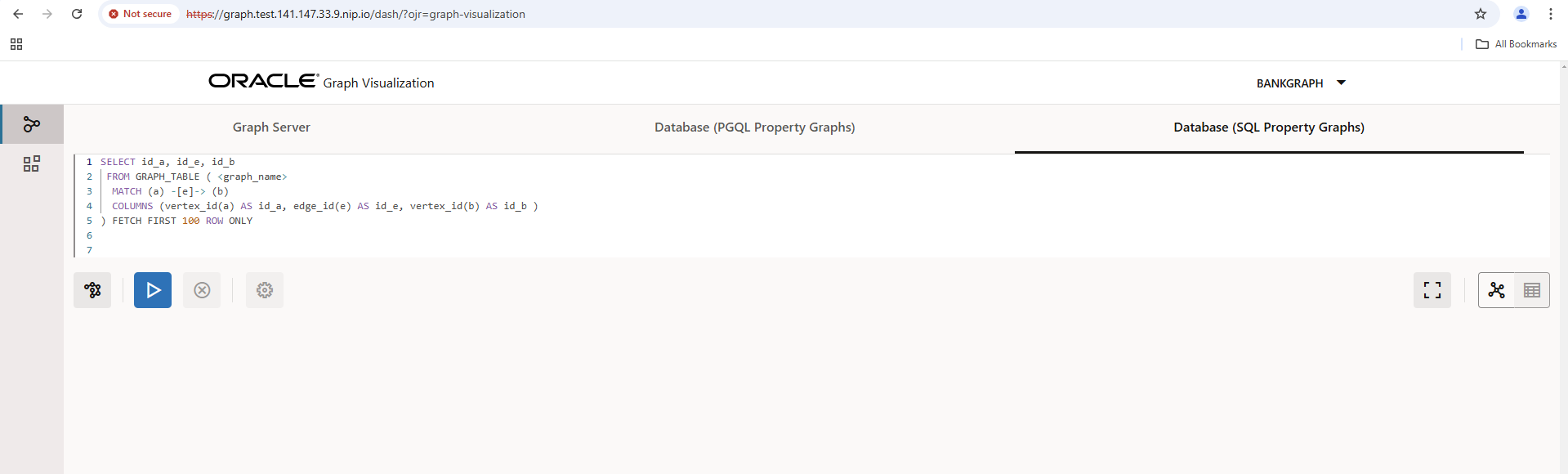
Klicken Sie dann zur Linken bitte auf das Netzwerk-Icon, um Graphen in Ihrer Datenbank zu selektieren, und prüfen Sie ob der BANK_GRAPH in der Liste steht.
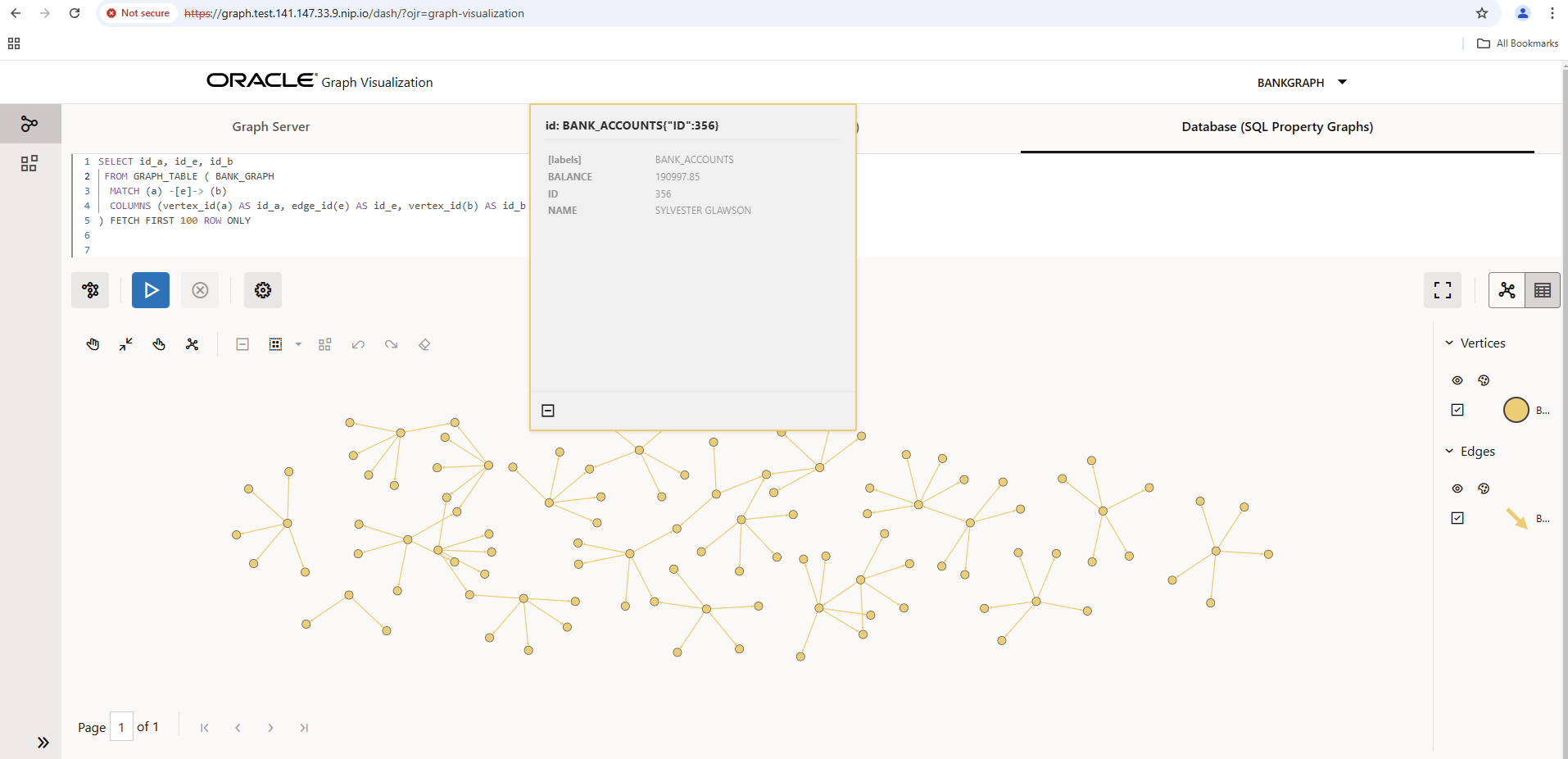
Tragen Sie den BANK_GRAPH oben in die SQL/PGQ Abfrage ein und führen Sie die Abfrage aus. Das resultierende Diagramm mit hier maximal 100 Knoten können Sie gerne noch optisch anpassen, die Daten hinter den Knoten einsehen usw.
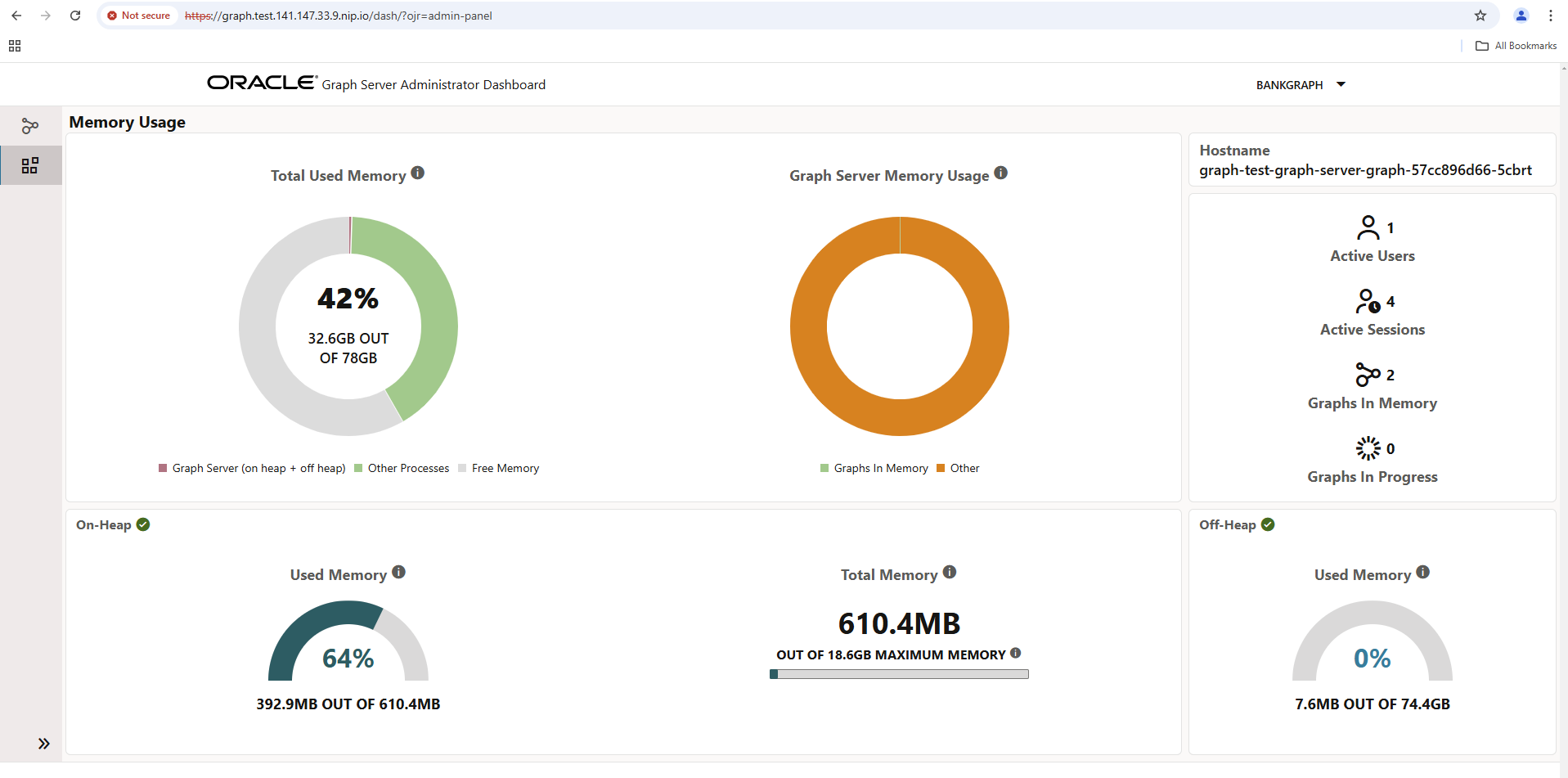
Die Server Statistiken des Graph Server sind wahrscheinlich ebenfalls interessant. Klicken Sie ganz am linken Seitenrand auf das Icon für das “Administrator Dashboard”:
Das beschließt vorerst diesen Artikel über den Einsatz des Graph Server unter Kubernetes. Es gibt sicherlich noch viele Dinge zu entdecken, Abfragen zu formulieren und auszuprobieren, vielleicht auch mit Ihren eigenen Daten. Aber genau zu diesem Zweck existieren solche kleinen und feinen Analyse-Umgebungen. Sie sind leicht einzurichten, optimalerweise per self-service User Interface, und jederzeit wieder verwerfbar.
Es gibt viele weiterführende Blogs zu Property Graphen und zum Graph Server selbst, einige davon habe ich in diesem Blog zum Nachschlagen verwendet. Vielleicht helfen Ihnen die gleichen Informationen auch auf Ihrem Weg, daher habe ich alle verwendeten Links nachfolgend aufgeführt. Zusätzlich die Links zum Quellcode für diesen und für weitere Helm Charts, damit Sie sie in Ihre Umgebung einbetten und gerne anpassen können.
Und nun wie immer: viel Spaß beim Testen !
In diesem Blog genutzte Links:
Anleitung zum Graph Server auf Docker Teil 1
Anleitung zum Graph Server auf Docker Teil 2
Diverse vorbereitete Jupyter Container (“scipy”) auf quay.io
Demo Notebooks und Daten zum Graph Server des Oracle Product Management (“pgx-samples”) auf github
Browser basiertes Installationstool für Helm Charts namens “kubeapps”
Quellcode des hier verwendeten Helm Charts und weiterer Oracle Komponenten-Charts auf github
Verwendete Helm Chart Repository URL auf github.io
Weiterführende Links zu Oracle Graph:
Der Oracle Graph learning path
Aktuelles Thema: Retrieval Augmented Generation (RAG) mit Graph Queries statt Volltext oder Relational
Graph Algorithmen in Jupyter ausführen: Nutzung des Graph Server
Graph Python Client mit Autonomous Database nutzen