Einleitung
Simple Oracle Document Access oder kurz SODA ist ein NoSQL-Abfrage-Sprache für das Speichern, Bearbeiten und Löschen von JSON-Dokumenten. Dieser Artikel beschreibt den schnellen und praktischen Einstieg und weniger tiefgründige Einblicke in die Funktionsweise von SODA. Wer an den Hintergründen von SODA/JSON-Document Store interessiert ist, findet im Blog-Eintrag “JSON, SODA und Oracle Autonomous JSON Database” Antworten auf viele Fragen.
Voraussetzungen für das Verwenden von SODA ist eine Oracle Datenbank in der Cloud oder eine On-Premises-Installation. SODA wird ab der DB Version 12.1.0.2 unterstützt, für die Durchführung der hier gezeigten Beispiele empfehlen wir eine DB Version ab 18.1.
Folgende Voraussetzungen müssen gegeben sein: Der verwendete Datenbank Benutzer muss Rechte auf die Rolle SODA_APP besitzt. In unserem Fall haben wir uns in einer bestehenden pluggable Datenbank mit Namen PDB mit folgendem SQL-Snippet den neuen Benutzer SODABENUTZER angelegt. Einfach nur das Skript mit dem eigenen Datenbank Namen und User anpassen und ausführen. Und schon kann es losgehen.
CONN / AS SYSDBA
ALTER SESSION SET CONTAINER=pdb;
DROP USER sodabenutzer CASCADE;
CREATE USER sodabenutzer IDENTIFIED BY sodabenutzer1 DEFAULT TABLESPACE users QUOTA UNLIMITED ON users;
GRANT CREATE SESSION, CREATE TABLE TO sodabenutzer;
GRANT SODA_APP TO sodabenutzer;Oracle SODA unterstützt folgende Schnittstellen:
- REST
- Java
- Python
- PL/SQL
- C
- Node.js
SQL*Plus oder z.B. SQL*Plus Instant-Client werden nicht direkt unterstützt! Aus den aufgezählten Schnittstellen werden im Artikel folgende behandelt:
- SQL Developer Web
Es wird eine Verbindung mit dem SQL Developer Web zu einer Autonomen Datenbank hergestellt und mit Testobjekten gearbeitet. - SQLcl
Mittels SQLcl wird eine Verbindung zu einer On-Premises Datenbank hergestellt und einige Testobjekte erzeugt/gelöscht. - Python
Mit einem kurzen Python-Programm wird die Verbindung zu einer On-Premises Datenbank herstellt und Testobjekte erstellt und manipuliert. - PL/SQL
Mit PL/SQL werden Testobjekte angelegt, gesucht und gelöscht.
Die Wahl fiel auf diese vier Schnittstellen, da sie einfach einzurichten und zu nutzen sind. Die Beispiele beschränken sich auf wenigen Zeilen und es bleibt viel Spielraum fürs Ausprobieren und Spielen.
Oracle SQL Developer Web
Für dieses Beispiel verwenden wir eine Instanz einer Autonomous Datenbank in der Oracle Cloud – eine Autonomous Data Warehouse Datenbank (ADW). Diese Variante wurde gewählt, da bei dieser Art der Datenbanken, der Oracle REST Data Service (ORDS) out-of-the-Box eingerichtet ist und man nur noch auf den Oracle SQL Developer Web zugreifen muss. Autonomous Online Transaction Processing (ATP) oder natürlich auch Autonomous JSON Datenbank (AJD) besitzen die gleiche out-of-the-box Funktionalität. Selbstverständlich kann auch in einer Oracle On-Premises Datenbank dieser Service eingerichtet und verwendet werden. Der Download des aktuellen ORDS findet sich hier.
Ruft man aus der Service Console von ADW auf und klickt auf Menü “Development” den SQL Developer Web, kann man direkt in dem Eingabefenster den Befehl SODA aufrufen und erhält eine Beschreibung der Befehls-Optionen.
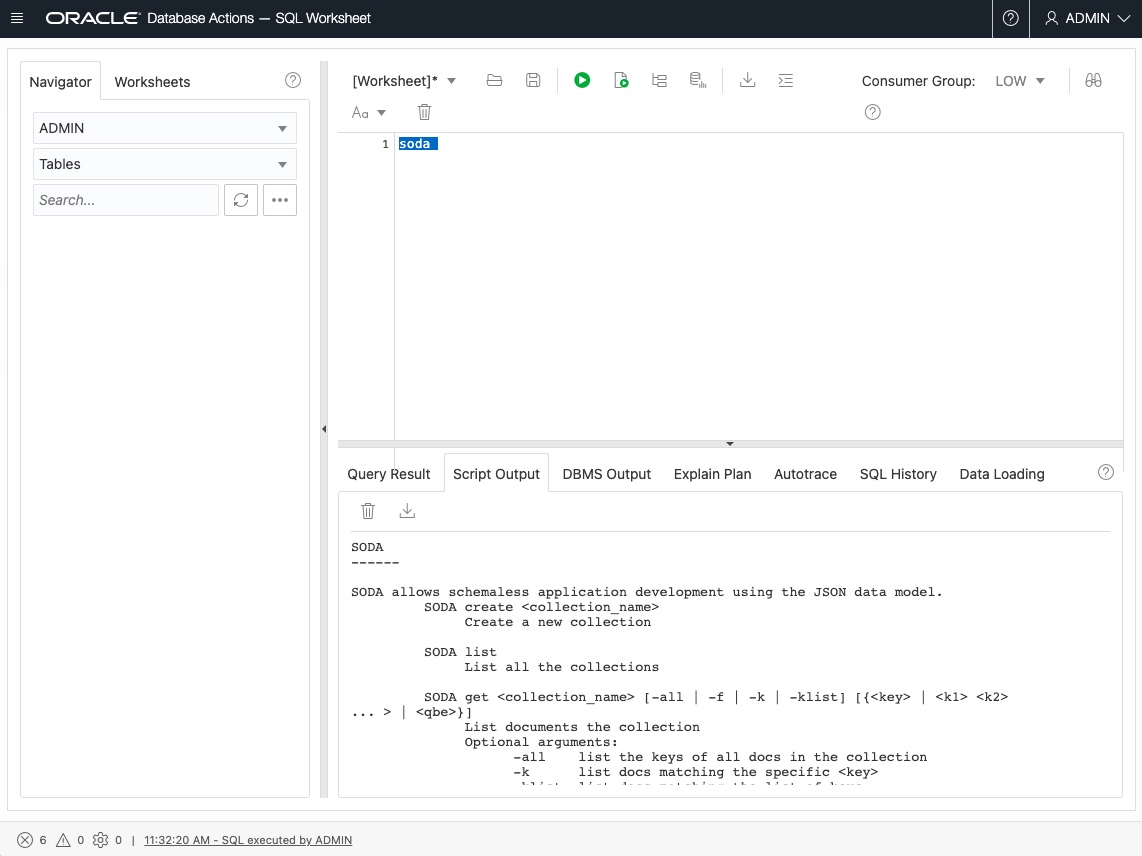
Bild 1: Aufruf des SODA-Befehls in der SQL Developer Web Konsole
Nachfolgend werden folgende grundlegende SODA-Operationen durchgeführt:
- Auflisten bestehender Collections – Collections sind Tabellen/Objekte in der die JSON-Dokumente abgelegt werden
- Anlegen einer Collection
- Speichern eines JSON-Dokuments in der Collection
- Suchen innerhalb der JSON-Dokumente
- Löschen eines JSON-Dokuments
- Löschen der Collection
Das Auflisten bestehender Collection erfolgt mit dem Befehl:
SODA listIn unserem Fall kommt selbstverständlich eine leere Ergebnis-Menge zurück, da wir noch keine Collection angelegt haben. Das Anlegen einer Collection erfolgt mit dem Befehl
SODA create <collection-name> oder in unserem konkreten Beispiel
SODA create mycollectionNachdem die Collection angelegt wurde, speichern wir einige JSON Dokumente in der Collection. Dies erfolgt mit dem Befehl:
SODA insert <collection_name> <json_str | filename>
In unserem Fall verwenden wir keine Datei, sondern geben ein JSON-Objekt direkt an:
SODA insert mycollection { "name" : "Alexander", "address" : "1234 Main Street", "city" : "Anytown", "state" : "CA", "zip" : "12345" }Wir können mehrere JSON-Dokumente einfügen und die Parameter ändern, so haben wir mehrere JSON-Dokumente in der Collection. In unserem Fall können wir zum Beispiel den Namen ändern und den Befehl erneut ausführen.
Um die Collection und deren Inhalte abfragen zu können, verwenden wir folgenden Befehl:
SODA get <collection_name> [Optionen]Bei den Optionen gibt es folgende Schalter:
- -all – Zeigt die Collection an. In diesem Fall wird der primäre Schlüssel angezeigt der für das jeweilige JSON-Dokument erzeugt wurde und die Zeit. Es wird nicht der Inhalt der JSON-Dokumente angezeigt.
- -k/klist – Listet die Dokumente auf, die den primären Schlüssel entsprechen. Mit k erhält man ein Dokument zurück mit klist mehrere Dokumente.
- -f – Mit dieser Option kann innerhalb der Collection nach Dokumenten gesucht werden. Ein Beispiel für die Suche nach allen Einträgen mit dem “name” : “Alexander” würde als Befehl folgendermaßen aussehen:
SODA get mycollection -f {"name":"Alexander"}Dieser Befehl listet alle diejenigen Dokumente auf, die “name”/Alexander als Key/Value verwenden. Es können natürlich auch Teilbegriffe gesucht werden, wie zum Beispiel alle Werte des Keys “name” die mit A anfangen:
SODA get mycollection -f {"name":{"$startsWith" : "A"}}Diese Abfragen nennen sich Query-by-Example kurz QBE. Es gibt eine Reihe von Möglichkeiten nach bestimmten Begriffen, Bereichen (größer, kleiner, etc.) und anderen Suchparametern innerhalb der JSON-Dokumente zu suchen. Eine Auflistung aller Möglichkeiten findet man hier in der Syntax-Beschreibung.
Das Löschen von JSON-Dokumenten erfolgt mit dem Befehl:
SODA remove mycollection -f {"name" : "Alexander"}Das Löschen von einzelnen Dokumenten erfolgt mittels Identifizierung über Key/Value oder einer oder mehreren (Primär-)Schlüsseln der Dokumente. Die gesamte Collection kann durch den Befehl:
SODA drop mycollection erfolgen.
Man erkennt schnell, das SODA eine einfache Möglichkeit darstellt CRUD (create, read, update, delete) Operationen mit JSON-Dokumenten durchzuführen. Der Entwickler benötigt keine SQL-Kenntnisse und kann schnell und effizient arbeiten. Selbstverständlich kann auf die Daten auch mittels gewohnter SQL-Syntax zugegriffen werden, einer der großen Vorteile der Nutzung von JSON in der Oracle Datenbank. Es sind Szenarien denkbar, in den zum Beispiel der Entwickler mittels SODA in einer Applikationen Daten erzeugt, manipuliert etc. und anschließend analytische Abfragen mittels SQL auf die Collection durchgeführt werden.
Um mit SQL auf eine Collection zuzugreifen, reicht zum Beispiel der Befehl:
select * from mycollection;Dadurch erhält man eine Darstellung der gesamten Tabelle. Die JSON-Dokumente werden in einer BLOB-Spalte abgespeichert und sind nicht direkt sichtbar. In der folgenden Datenbank-Version (>19c) gibt es einen neuen, eigenen Datentyp JSON, der in unserem Beispiel, das auf einer 19c Datenbank erstellt wurde, noch nicht verfügbar ist. Über den neuen Datentyp hat mein Kollege Marcel Boermann-Pfeifer einen eigenen Blog-Artikel verfasst, siehe JSON nativ auch mit Oracle JDBC 20c.
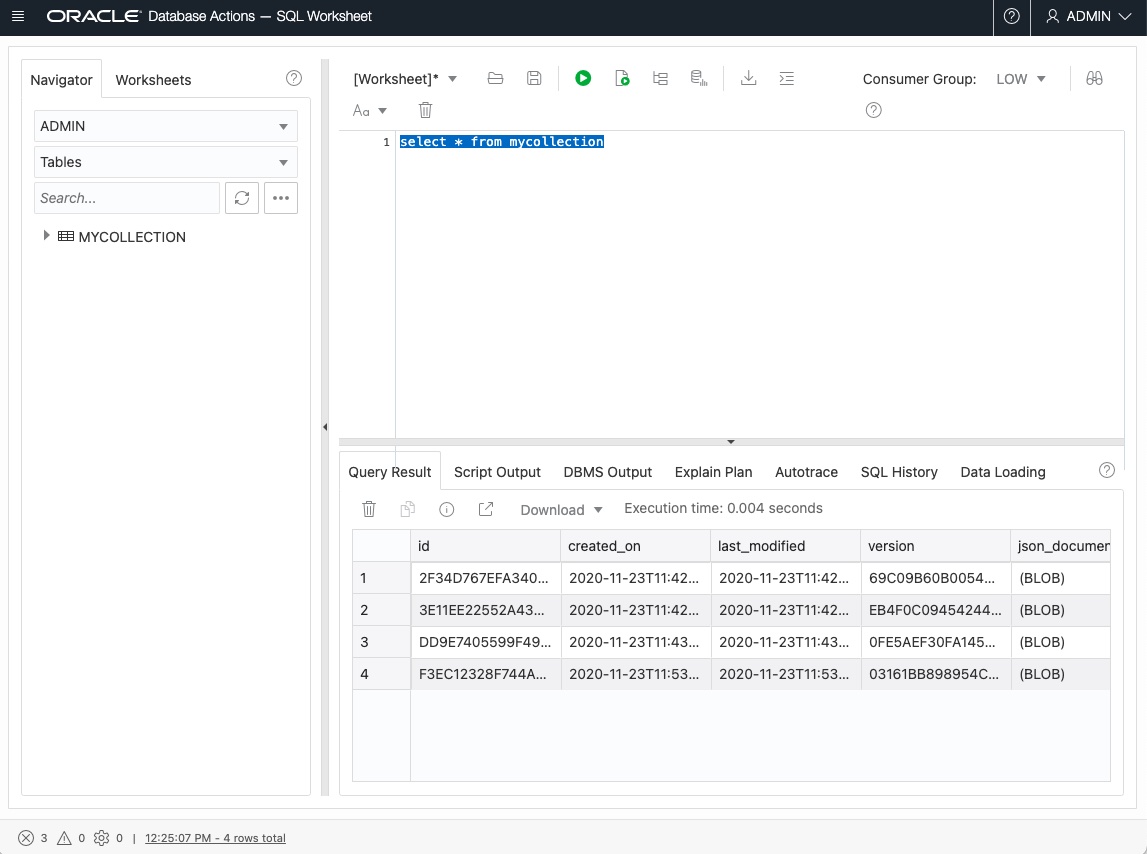
Bild 2: Anzeige der Collection mittels SQL-Befehl
SQLcl
Die SQL Developer Command Line oder kurz SQLcl ist ein Java-basierendes Command-Line-Tool für die Ausführung von Befehlen und Skripten. Es werden eine Reihe von Kommandos und verschiedene Skriptsprachen unterstützt wie zum Beispiel SQL und natürlich auch SODA. SQLcl kann man sich hier herunterladen und die nur wenige MB große Installation erfolgt einfach durch Entzippen. SQLcl verwendet einen eigenen JDBC Treiber um sich mit einer Oracle DB zu verbinden. Man kann jedoch auch einen Fat/Instant Client verwenden. Um sich mit einer Datenbank zu verbinden, navigiert man in das ./bin Verzeichnis der entpackten Datei und startet mit folgendem Befehl die Session:
./sql sodabenutzer/passwort@<Hostname>:<DB_Port>/service_name_der_pdbAnschließend ist man an der gewünschten Datenbank angemeldet und kann die gleichen SODA-Operationen durchführen, wie in dem vorangegangenen Beispiel:

Bild 3: Anmeldung mittels SQLcl und Aufruf der SODA Hilfe
Diese Methode des Testens von SODA ist die Schnellste, wenn man sich auf einer On-Premises Datenbank anmeldet hat bzw. kein SQL Developer Web zur Verfügung steht.
Python
Nach den zeilen- bzw. scriptorientierten Beispielen kommen wir jetzt zu der SODA-Schnittstelle in Python. Die Umsetzung der Schnittstelle erfolgt im Python Modul cx_Oracle, das man an dieser Stelle herunterladen kann. Das Modul ist in der Version 8.0 vorhanden und verwendet die Python Database API 2.0. Sie wurde mit den Python Versionen 3.5 und 3.8 getestet und verwendet die Oracle Client Libraries 11.2, 12, 18 und 19. Das bedeutet, man kann einen Oracle Full-Client verwenden oder einen Instant Client installieren und über die Umgebungsvariablen verfügbar machen.
Das hier verwendete Beispiel-Skript stammt aus dem cx_Oracle Example GitHub Folder und ist mit wenigen Anpassungen sofort verwendbar. Das Skript initiiert eine Datenbank-Verbindung, legt eine Collection an und erzeugt einige JSON-Dokumente. Anschließend werden die Dokumente durchsucht, gezählt und am Ende werden die Dokumente und die Collection gelöscht. Das Beispiel-Skript SodaBasic.py kann hier heruntergeladen werden und muss folgendermaßen angepasst werden:
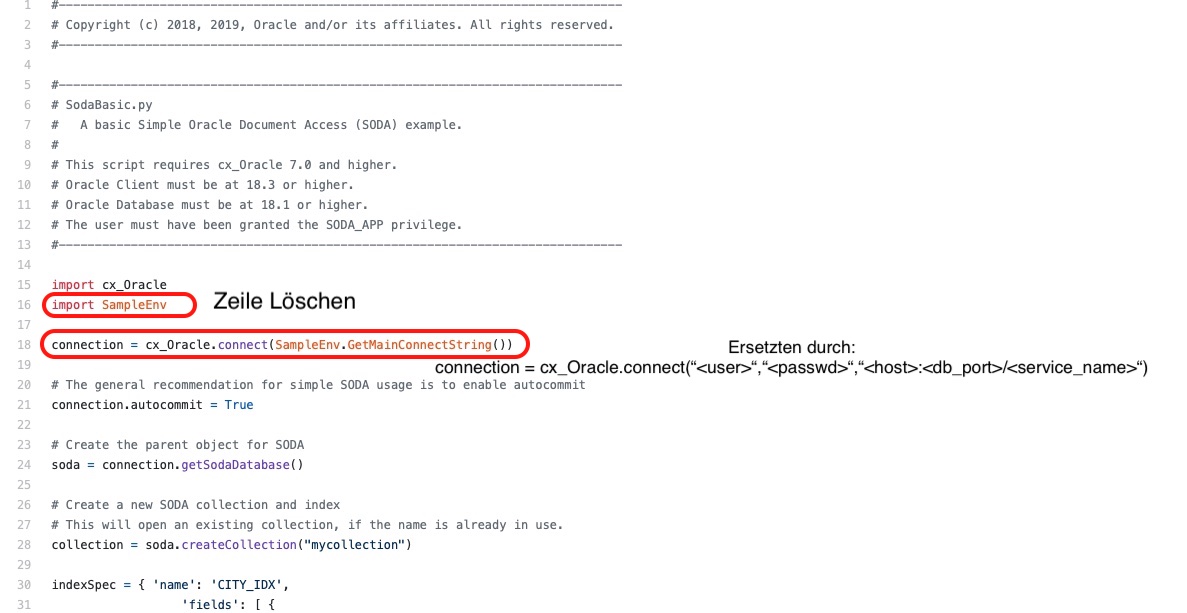
Bild 4: Änderung des Programm-Listings
Im folgenden werden einige einzelne Zeilen aus dem Programm-Code erklärt und kommentiert.
connection.autocommit = TrueDas Autocommit ist an dieser Stelle sehr wichtig, um die Operationen in der Datenbank festzuschreiben (auch COMMIT-Operation genannt). Ansonsten werden alle Befehle in der Datenbank wieder zurückgerollt bzw. nicht festgeschrieben (auch ROLLBACK-Operation genannt).
collection = soda.createCollection("mycollection")Die Programmzeile erzeugt eine neue Collection mit dem Namen “mycollection”, sollte diese Collection bereits vorhanden sein, wird sie geöffnet.
content = {'name': 'Matilda', 'address': {'city': 'Melbourne'}}
doc = collection.insertOneAndGet(content)
key = doc.keyMit diesen drei Zeilen wird ein neues JSON-Dokument in der Collection erzeugt. Die erste Zeile erstellt ein Content-Objekt mit einem JSON-Objekt. In der zweiten Zeile wird dieses Objekt in die Collection eingefügt und im Rückgabe Objekt wird die Ausgabe gespeichert. In der dritten Zeile wird aus dem Ausgabe Objekt der Primärschlüssel ausgelesen und in der key Variablen gespeichert.
content = {'name': 'Matilda', 'address': {'city': 'Sydney'}}
collection.find().key(key).replaceOne(content)Mit diesen zwei Zeilen wird ein Dokument ersetzt. Für das Ersetzen benötigt die Replace Funktion den im obigen Code ermittelten Primärschlüssel.
Anschließend kann das Skript mittels
python SodaBasic.pyausgeführt werden.
Ein paar Anmerkungen: Bitte achten Sie darauf, dass eine Python Version größer 3.5 verwendet wird und auch entsprechend gelinkt ist. Die verwendete Version sehen Sie mit dem Aufruf:
python -VWeiterhin sollte die Umgebungsvariable LD_LIBRARY_PATH gesetzt werden, damit das Programm auf die entsprechenden Oracle Libraries zugreifen kann. Der Aufruf/Output beim Starten des Programms sieht folgendermaßen aus:
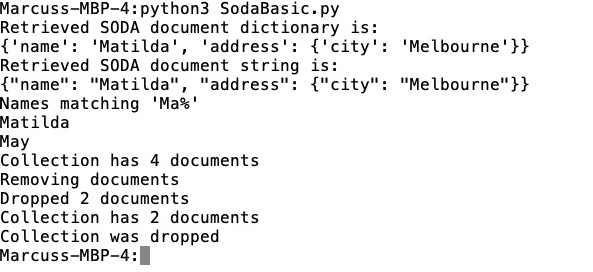
Bild 5: Bildschirmausgabe beim Durchlaufen des Programms SodaBasic.py
Dieses Beispiel zeigt, wie der Entwickler in einem kleinen Python-Programm CRUD-Operationen mit JSON-Dokumenten ohne eine SQL-Anweisung durchführen kann. Man kann das Programm beliebig verändern und erweitern.
PL/SQL
Sind die Vorausetzungen für die Verwendung von SODA erfüllt – ein Datenbankuser, der die Rolle SODA_APP besitzt mit Zugriff auf eine Datenbank ab der Version 18c – kann man sofort mit PL/SQL und SODA loslegen. Eine wichtige Schnittstelle stellt dabei das Package DBMS_SODA dar. Zusätzlich werden Objekttypen wie z.B. SODA_COLLECTION_T verwendet um mit speziellen vorgegebenen Methoden arbeiten zu können. Das Package DBMS_SODA stellt beispielsweise Funktionen zum Erzeugen und Löschen von Collections zur Verfügung. Die Funktionalität lässt sich mit dem DESCRIBE Kommando anzeigen. Hier wird ein Ausschnitt angezeigt.
SQL> describe dbms_soda
FUNCTION CREATE_COLLECTION RETURNS SODA_COLLECTION_T
Argument Name Type In/Out Default?
------------------------------ ----------------------- ------ --------
COLLECTION_NAME NVARCHAR2 IN
METADATA VARCHAR2 IN DEFAULT
CREATE_MODE BINARY_INTEGER IN DEFAULT
FUNCTION DROP_COLLECTION RETURNS NUMBER
Argument Name Type In/Out Default?
------------------------------ ----------------------- ------ --------
COLLECTION_NAME NVARCHAR2 IN
FUNCTION LIST_COLLECTION_NAMES RETURNS SODA_COLLNAME_LIST_T
FUNCTION OPEN_COLLECTION RETURNS SODA_COLLECTION_T
Argument Name Type In/Out Default?
------------------------------ ----------------------- ------ --------
COLLECTION_NAME NVARCHAR2 IN
Kennt man sich mit PL/SQL Coding und Objekttypen aus, lässt sich die Verwendung des Frameworks anhand von Code-Beispiele gut erklären.
Im ersten Beispiel legen wir die Collection mycollection an.
DECLARE
collection SODA_Collection_T;
BEGIN
collection := DBMS_SODA.create_collection('mycollection');
END;
/
COMMIT;Um ein Dokument einzufügen, werden die Objekttypen SODA_DOCUMENT_T und SODA_COLLECTION_T mit ihren Funktionen und Methoden wie z.B. INSERT_ONE verwendet. Die Metadaten wie Key usw. werden dabei automatisch erstellt.
DECLARE
collection SODA_COLLECTION_T;
document SODA_DOCUMENT_T;
status number;
BEGIN
collection := DBMS_SODA.open_collection('mycollection');
document := SODA_DOCUMENT_T(b_content => utl_raw.cast_to_raw('{"name" : "Alexander"}'));
status := collection.insert_one(document);
END;
/
COMMIT;Möchte man einen Überblick über die Objekttypen und ihre Methoden erhalten, kann man auch diese mit einem DESCRIBE Kommando im SQL*Plus auflisten. Ein Auschnitt aus dem Listing sieht dann folgendermaßen aus:
SQL> describe soda_document_t
METHOD
------
FINAL CONSTRUCTOR FUNCTION SODA_DOCUMENT_T RETURNS SELF AS RESULT
Argument Name Type In/Out Default?
------------------------------ ----------------------- ------ --------
KEY VARCHAR2 IN DEFAULT
B_CONTENT BLOB IN
MEDIA_TYPE VARCHAR2 IN DEFAULT
Im nächsten Beispiel sollen alle diejenigen Dokumente gefunden werden, die “name”/Alexander als Key/Value verwenden. Hierzu werden die Methoden und Funktionen von SODA_COLLECTION_T, SODA_DOCUMENT_T und SODA_OPERATION_T verwendet.
set serveroutput on
DECLARE
collection SODA_COLLECTION_T;
document SODA_DOCUMENT_T;
cur SODA_CURSOR_T;
status BOOLEAN;
qbe VARCHAR2(128);
BEGIN
collection := DBMS_SODA.open_collection('mycollection');
qbe := '{"name" : "Alexander"}';
cur := collection.find().filter(qbe).get_cursor;
WHILE cur.has_next
LOOP
document := cur.next;
IF document IS NOT NULL THEN
DBMS_OUTPUT.put_line('Key: ' || document.get_key);
DBMS_OUTPUT.put_line('Content: ' || JSON_QUERY(document.get_blob, '$' PRETTY));
DBMS_OUTPUT.put_line('Creation timestamp: ' || document.get_created_on);
DBMS_OUTPUT.put_line('Last modified timestamp: ' || document.get_last_modified);
DBMS_OUTPUT.put_line('Version: ' || document.get_version);
END IF;
END LOOP;
status := cur.close;
END;
/
Key: B911B70045994FA7BF7149A2DC27DC45
Content:
"name" : "Alexander"
}
Creation timestamp: 2020-11-27T12:19:55.458892Z
Last modified timestamp: 2020-11-27T12:19:55.458892Z
Version: FD69FB6ACE73FA735EC7922CA4A02DDE0690462583F9EA2AF754D7E342B3EE78
Ändert man die Variable qbe wie in folgendem Beispiel ab, können natürlich auch Teilbegriffe werden, wie zum Beispiel alle Werte des Keys “name” die mit A anfangen:
qbe := '{"$query" : {"name":{"$startsWith" : "A"}}}';Das Löschen einer Zeile funktioniert dann mit folgendem PL/SQL Code.
DECLARE
collection SODA_COLLECTION_T;
document SODA_DOCUMENT_T;
status NUMBER;
BEGIN
collection := DBMS_SODA.open_collection('mycollection');
status := collection.find().key('B911B70045994FA7BF7149A2DC27DC45').remove;
IF status = 1 THEN
DBMS_OUTPUT.put_line('Geloescht!');
END IF;
END;
/
Geloescht!
COMMIT; Die Collection selbst wird folgendermassen gelöscht.
DECLARE
status NUMBER := 0;
BEGIN
status := DBMS_SODA.drop_collection('mycollection');
END;
/
COMMIT;Wichtig zu wissen: Man sollte unbedingt bei der Verwendung auf die exakte Schreibweise (Groß- und Kleinschreibung) der Collection oder des JSON Inhalts achten.
Wie in PL/SQL und natürlich auch in SQL üblich, können mehrere SODA-Lese- und Schreiboperationen als eine Transaktion behandelt werden. Um eine Transaktion abzuschließen, verwendet man eine COMMIT-Anweisung. Wenn Änderungen rückgängig gemacht werden sollen, wollen, verwendet man eine ROLLBACK-Anweisung.
Beschäftigt man sich genauer mit den Objekttypen, wird man feststellen, dass noch viel mehr erreicht werden kann. So gibt es beispielsweise GETTER Methoden um Inhalte anzeigen zu lassen. Man kann aber auch einen Search Index, dynamisch einen Dataguide und Views mit den Methoden von SODA_Collection_t anlegen.
Gute Beispiele auch zum Starten mit SODA und PL/SQL finden sich im Handbuch Using SODA for PL/SQL oder auch im LiveSQL Tutorial.
Zusammenfassung
Es ist ganz einfach auf JSON-Dokumenten in der Oracle Datenbank zuzugreifen und diese zu verarbeiten. Der Entwickler kann auch ohne Kenntnisse von SQL Syntax schnell und direkt CRUD-Operationen mit JSON-Dokumenten durchführen und in den eigenen Programm-Code integrieren. Dabei gibt es SODA-APIs für alle modernen Programmiersprachen und Interfaces. Die gezeigten Beispiele sind bewusst einfach gehalten, um einen schnellen Start zu gewährleisten und um einen Eindruck zu gewinnen, was alles mit SODA möglich ist.
Weitere Informationen
- Weitere Blog-Einträge zu aktuellen Themen rund um die Oracle Cloud Infrastructure und der Oracle Datenbank
- Dokumentation zu Oracle SODA
- Git-Hub Beispiele rund um das Thema cx_Oracle
- Allgemeiner Artikel zum Thema SODA und JSON in der Oracle Datenbank>
- Blog-Eintrag zu Python mit der Oracle Datenbank
- Blog-Eintrag zu SQL Developer Web und Autonomous DB
- Blog-Eintrag zu SQLcl
