 Was tun, wenn man seine Daten nicht an eine Cloud-basierte KI übergeben möchte oder darf ? Ganz einfach, man holt die KI möglichst preisgünstig ins eigene Rechenzentrum. Ich möchte einige aktuelle Standard-Methoden aufzeigen, um Large Language Modelle (LLMs) mit einer Oracle Database zu verbinden. Auch einige zweckgebundene Large Language Modelle möchte ich beschreiben, und welche der Methoden mit einer Version 19c gut verträglich sind.
Was tun, wenn man seine Daten nicht an eine Cloud-basierte KI übergeben möchte oder darf ? Ganz einfach, man holt die KI möglichst preisgünstig ins eigene Rechenzentrum. Ich möchte einige aktuelle Standard-Methoden aufzeigen, um Large Language Modelle (LLMs) mit einer Oracle Database zu verbinden. Auch einige zweckgebundene Large Language Modelle möchte ich beschreiben, und welche der Methoden mit einer Version 19c gut verträglich sind.
Vor einigen Monaten beschrieb ich kurz umrissen, wie man für Test und Entwicklung eine Oracle Database 23ai Free Edition mit einer lokalen KI verbinden kann. Gut gewählt und auf die Lizenzform geachtet kann man die zugrunde liegenden Large Language Modelle auch produktiv nutzen, nicht nur zum Test. Die im Artikel beschriebene Umgebung diente dem Zweck, hochgeladene Dokumente so durchsuchbar zu machen, daß sie der KI als Wissensgrundlage dienen und sie in einer Chat Oberfläche dazu zu befragen. Die zu der Zeit allseits betonte Methode “Retrieval Augmented Generation“, kurz RAG, bietet noch heute die Grundlage, KIs um lokales und privates Wissen aus unstrukturierten und auch strukturierten Daten on-the-fly anzureichern, ohne ein eigenes Large Language Model mit eigenen Daten darin erzeugen zu müssen.
Inzwischen ging die Entwicklung der Large Language Modelle weiter, sie können nun auch lokal umfassender und komplexer genutzt werden: die Themen Tools-Support, Agenten und Model-Context-Protocol (MCP) sowie Mixture-of-Experts und -sehr wichtig- immer größere unterstützte Context Window Sizes hielten auch im Zusammenhang mit den APIs und Werkzeugen rund um die Oracle Database Einzug, weswegen ich sie jeweils kurz beschreiben möchte.
Ich möchte mich vorab für den außerordentlich großen Blog entschuldigen! Vielleicht lesen Sie nicht den gesamten Inhalt, sondern suchen sich die für Sie interessantesten Kapitel zuerst aus:
Aktuelle LLM Features, besonders für den lokalen Einsatz
- Viel Platz, viel Rechenleistung ?
- Platz sparen, Performanz erhöhen
- Platz und Last verteilen
- Schnelle Mini-Experten
- Schnelle Schubladen-Denker
- Nicht reden, sondern machen – Datenformate, Tools, Agenten und MCP
Features der Oracle Database, die lokale LLMs nutzen können
- SELECT AI / DBMS_CLOUD_AI (Database 19c und 26ai)
- UTL_HTTP (Database 19c und 26ai)
- Vector Store / Vector Search bzw. DBMS_VECTOR / DBMS_VECTOR_CHAIN (Database 26ai)
- Application Express Runtime und Design Time (Database 19c und 26ai)
- MCP Server for Oracle Database (Database 19c und 26ai
Zusammenfassung und Ausblick
Einige interessante Links
Möge jetzt und hier das Fest beginnen:
Aktuelle LLM Features, besonders für den lokalen Einsatz
Viel Platz, viel Rechenleistung ?
Möchte man ein Large Language Model (LLM) lokal bzw. in unmittelbarer Nähe zu den eigenen Servern und Datenbanken betreiben, so geht es vorrangig erst einmal um Speicherbedarf, Performance und dabei noch gut akzeptable Qualität der Ergebnisse. Die in Cloud Umgebungen betriebenen Large Language Modelle sind meist Alleskönner, die ihre inzwischen zahlreichen Fähigkeiten möglichst gut können, weswegen sie ordentlich viel GPU-Hauptspeicher und leistungsfähige GPUs mit vielen Rechenkernen benötigen. Solche LLMs basieren meist auf mehreren hundert Milliarden Parametern (200B, 400B, 600B,…) und verbrauchen allein für deren Betrieb aktuell bis zu 400GB teuren GPU Speicher – pro Instanz. Hinzu kommen noch etliche Context Windows, das sind Speicherbereiche für die aktuell laufenden Anfragen der Endbenutzer und Agenten mit deren jeweiliger Chat-Historie und Kontext-Informationen, die per RAG Mechanismus in immer größer werdende Prompts eingeflanscht werden. Das ist für den lokalen, nicht-generischen Einsatz in diesem Ausmaß wirklich nicht notwendig!
Platz sparen, Performanz erhöhen
Zunächst haben sich Strategien entwickelt, Large Language Modelle für den Betrieb auf schwächeren GPU Systemen so umzugestalten, daß sie weniger Platz benötigen. Durch Quantisierung wird die Genauigkeit der Parameter bzw. Vektoren in den LLMs reduziert, die Geschwindigkeit der Abarbeitung wird stark erhöht und auch der Platzbedarf deutlich reduziert. Die Ergebnisse wirken jedoch nicht mehr so filigran bzw. intelligent wie vorher, doch sie sind immer noch deutlich besser als LLMs mit einer entsprechend geringeren Anzahl an Parametern. Stellte man Vektoren bzw. Parameter ursprünglich möglichst präzise mit 64Bit Floating Point Zahlen dar, werden heutzutage üblicherweise nur noch 32bittige, 16bittige bis hinunter zu 4 bittigen Kommazahlen verwendet und zum Download angeboten. Das im Sommer 2025 erschienene gpt-oss LLM wurde zum Beispiel einer 4.25 bit (ca.) Quantisierungs-Methode (MXFP4) unterzogen.
Platz und Last verteilen


 Aktuelle inference Server, also Programme die LLMs verwalten, laden und ausführen, sind in der Lage große LLMs auf mehrere lokale GPU Devices zu verteilen. Das bringt leider keinen Performance Vorteil durch Parallelisierung, aber es reduziert den Nachteil drastisch, ein zu großes LLM nach und nach von Disk durch den GPU-Speicher reichen zu müssen. Der GPU Hersteller nvidia bietet für seine großen Lösungen ein netzwerk/infiniband/RDMA-taugliches Feature nvlink an, um aus den ohnehin schon großen GPUs gewissermaßen noch größere zu machen. Anders herum lassen sich auch mehrere kleinere LLMs gleichzeitig laden und betreiben, oder man verwendet mehrere inference Server mit jeweils einer eigenen kleineren GPU und koordiniert sie über einen Load Balancer. Der Vollständigkeit halber sei erwähnt dass die Oracle Database den Zugriff auf diverse (HuggingFace tgi, vLLM/triton, ollama) lokale inference Server entweder direkt oder über eine meist ohnehin vorhandene OpenAI kompatible REST API unterstützt.
Aktuelle inference Server, also Programme die LLMs verwalten, laden und ausführen, sind in der Lage große LLMs auf mehrere lokale GPU Devices zu verteilen. Das bringt leider keinen Performance Vorteil durch Parallelisierung, aber es reduziert den Nachteil drastisch, ein zu großes LLM nach und nach von Disk durch den GPU-Speicher reichen zu müssen. Der GPU Hersteller nvidia bietet für seine großen Lösungen ein netzwerk/infiniband/RDMA-taugliches Feature nvlink an, um aus den ohnehin schon großen GPUs gewissermaßen noch größere zu machen. Anders herum lassen sich auch mehrere kleinere LLMs gleichzeitig laden und betreiben, oder man verwendet mehrere inference Server mit jeweils einer eigenen kleineren GPU und koordiniert sie über einen Load Balancer. Der Vollständigkeit halber sei erwähnt dass die Oracle Database den Zugriff auf diverse (HuggingFace tgi, vLLM/triton, ollama) lokale inference Server entweder direkt oder über eine meist ohnehin vorhandene OpenAI kompatible REST API unterstützt.
Schnelle Mini-Experten
![]()
![]()
![]() Parallel zur Quantisierung entschied man sich, Large Language Modelle zu spezialisieren und nur für bestimmte Zwecke zu trainieren. Das resultierte in deutlich kleinere und schnellere LLMs. Solche kleinen Experten (von mir liebevoll Fachidioten genannt) sind besonders gut geeignet, um allgemein aber weniger tiefgründig in mehreren Sprachen zu chatten, Programmcode zu generieren (selbstverständlich auch SQL), Texte zusammenzufassen, Bilder zu beschreiben oder auch nur um Vektoren aus Texten zu generieren (Embeddings erzeugen) um sie mit anderen Vektoren zu vergleichen, z.B. solche aus Suchanfragen entstandenen. Die kleineren Experten-Modelle liefern bei etwa 7-12 Milliarden Parametern und etwa 5-10 GB Speicherbedarf sehr gute, wenn auch gewollt eher einseitige Ergebnisse. Zu Entwicklungszwecken oder besonders konkreten Anforderungen gibt es die gleichen Experten-LLMs in noch kleineren Ausprägungen, wobei ich unterhalb von 3 Milliarden Parametern nur noch simpelste Antworten oder wenig komplexe Entscheidungen bzw. Kategorisierungen erwarten konnte. Dies ging jedoch gefühlt pfeilschnell, auch hierfür gibt es sicherlich Anwendungsfälle.
Parallel zur Quantisierung entschied man sich, Large Language Modelle zu spezialisieren und nur für bestimmte Zwecke zu trainieren. Das resultierte in deutlich kleinere und schnellere LLMs. Solche kleinen Experten (von mir liebevoll Fachidioten genannt) sind besonders gut geeignet, um allgemein aber weniger tiefgründig in mehreren Sprachen zu chatten, Programmcode zu generieren (selbstverständlich auch SQL), Texte zusammenzufassen, Bilder zu beschreiben oder auch nur um Vektoren aus Texten zu generieren (Embeddings erzeugen) um sie mit anderen Vektoren zu vergleichen, z.B. solche aus Suchanfragen entstandenen. Die kleineren Experten-Modelle liefern bei etwa 7-12 Milliarden Parametern und etwa 5-10 GB Speicherbedarf sehr gute, wenn auch gewollt eher einseitige Ergebnisse. Zu Entwicklungszwecken oder besonders konkreten Anforderungen gibt es die gleichen Experten-LLMs in noch kleineren Ausprägungen, wobei ich unterhalb von 3 Milliarden Parametern nur noch simpelste Antworten oder wenig komplexe Entscheidungen bzw. Kategorisierungen erwarten konnte. Dies ging jedoch gefühlt pfeilschnell, auch hierfür gibt es sicherlich Anwendungsfälle.
Beispiele:
qwen3 (Alibaba OpenSource LLM) gibt es zum Download in Ausprägungen von 0.6 , 1.7, 4, 8, 14, 30 und 235 Milliarden Parametern.
gemma3 (OpenSource Variante von Google Gemini) gibt es zum Download in Ausprägungen von 1, 4, 12, 27 und 270 Milliarden Parametern.
deepseek-r1 (OpenSource Modell des gleichnamigen research lab) gibt es zum Download in Ausprägungen von 1.5, 7, 8, 14, 32, 70 und 671 Milliarden Parametern.
phi3 (OpenSource Modell von Microsoft) gibt es zum Download in Ausprägungen von 3.8 und 14 Milliarden Parametern, phi4 nur noch mit 14 Milliarden Parametern.
Jeweilige Experten LLMs können separat heruntergeladen werden, z.B. codegemma, shieldgemma, qwen2.5-math, deepseek-coder usw. mit teilweise mehreren Fähigkeiten wie vision, reasoning, coding usw.
Schnelle Schubladen-Denker
Inzwischen ist man dazu übergegangen, die häufigsten wiederkehrenden Anwendungsgebiete mit ihren spezifischen Experten-LLMs im Paket anzubieten. Daraus sind die Mixture-of-Experts LLMs entstanden. Dabei entscheidet oft ein kleiner generischer Unterbereich des LLM, welcher Experten-Unterbereich am besten die anstehende Aufgabe bewältigen kann und zieht diesen nach. Der Vorteil: selbst wenn das gesamte LLM zu groß für die GPU sein sollte, so können die am häufigsten genutzten Teil-Experten (Fachidioten…) im Hauptspeicher verbleiben, es muss nicht bei jeder Anfrage das gesamte LLM durch den Speicher geschickt werden. Die LLMs bzw. ihre Dateien sind nun wieder größer geworden, aber das macht nicht mehr so viel aus. Wenn Sie jedoch die Möglichkeit haben selbst zu entscheiden, welches Experten-LLM genutzt werden soll, dann tun Sie lieber das ! Es ist immer noch schneller, wenn die use cases ohnehin feststehen, ein LLM direkt zu beauftragen statt erst das eine zu befragen, welches andere letztlich genutzt werden soll. A propos befragen und nutzen – eine gute Überleitung zum Tools support, Agenten und MCP. Denn dort wird genau das getan, wovor ich eben noch warnte. Der Komfort und die Möglichkeiten sind dadurch enorm.
Kurze Beispiele:
- Eine gute Beschreibung zur Architektur von Mixture-of-Experts LLMs finden Sie in einem heise-Artikel über das neue chinesische GLM-4.5.
- Das aus ChatGPT bekannte GPT LLM der Firma OpenAI wurde jüngst per OpenSource Lizenz und verschlankt als gpt-oss zum Download angeboten. Auch gpt-oss umfasst mehrere Experten-LLMs nach dem gleichen Prinzip. Eine nähere Beschreibung von gpt-oss finden Sie im Ankündigungs-Blog von OpenAI.
- Ein recht hochwertiges LLM in unterschiedlichsten Größen ist das von Alibaba erzeugte qwen3. Nicht nur die unterschiedliche Anzahl von Parametern beeinflussen die größen, sondern auch die mögliche Wahl zwischen einem kompletten Mixture-of-Experts LLM und mehreren dense LLMs, also einzelnen Experten.
Nicht reden, sondern machen – Datenformate, Tools, Agenten und MCP
In den Anfängen standen möglichst präzise Prompts, d.h. Handlungsanweisungen an die KI, wie sie sich verhalten möge und in welcher Form sie zu Antworten habe. Generelle Anweisungen wurden im System-Prompt gleich beim Laden des LLM mit übergeben, sie konnten durch als solche gekennzeichneten Prompts in den Anfragen und Chat-Verläufen auch überschrieben order ergänzt werden. Gute Prompts reduzieren beispielsweise das Halluzinieren der KIs. Wenn es an Information und Kontext zur Beantwortung einer Frage fehlt solle die KI keine eigenen Rückschlüsse ziehen und womöglich noch als Fakt darstellen. Recht bald wurden Prompts fomuliert, um Ergebnisse und Entscheidungen in strukturierter Form, als CSV liste, XML oder JSON Dokument wiederzugeben. Das funktionierte oft am besten, indem man ein Beispiel für die gewünschte Ergebnis-Struktur mit auf den Weg gab.
Ein Beispiel für einen Prompt bzw. einen Aufruf an ein LLM, der anhand einer Beispiel-Struktur das gewünschte Ergebnis-Format beschreibt. Einfach per POST Operation an einen inference Server Ihrer Wahl senden and die URI /api/chat (ollama API) oder /v1/chat/completions (OpenAI kompatible API)
{"model": "llama3.2:1b","messages": [
{"role": "system", "content": "Which 5 keywords would You use in a google search to find best answers to the user's question?
Please respond with a JSON that best answers the given prompt.
Respond in the format {"keywords":[{keywords chosen}]}.
Do not use variables."},
{"role": "user", "content": "can men get breast cancer too ?" }
],
"stream": False, "options": {"use_mmap": True,"use_mlock": True,"num_thread": 8}}
Ein mögliches, strukturiertes Ergebnis des Aufrufs (Auszugsweise):
{
"model": "llama3.2:1b",
"message": {
"role": "assistant",
"content": "{\"keywords\":[\"male breast cancer\",\"common types of breast cancer\",\"causes of breast cancer in men\",\"statistics on male breast cancer\"]}"
},
...
Diese Art von Prompt wurde wohl häufig genutzt, jedenfalls wurde alsbald eine Standard-Syntax in die gängigen LLMs eingebaut, mit der man Datenstrukturen vorgeben konnte, die vom LLM als Antwort auf eine Anfrage zu befüllen sei. Die “Format API” war geboren, und ihr Nachfolger liess nicht lange auf sich warten.
Ein Beispiel für einen Prompt, der die Format API benutzt um Datenstrukturen zu beschreiben:
{
"model": "llama3.1",
"messages": [{"role": "user", "content": "Tell me about Canada."}],
"stream": False,
"format": {
"type": "object",
"properties": {
"name": {
"type": "string"
},
"capital": {
"type": "string"
},
"languages": {
"type": "array",
"items": {
"type": "string"
}
}
},
"required": [
"name",
"capital",
"languages"
]
}
}
Ein mögliches Ergebnis des Aufrufs (Auszugsweise). Das LLM füllt die Datenfelder, wenn man so sagen möchte, nach bestem Wissen und Gewissen selbst aus:
{
"model": "llama3.1",
"message": {
"role": "assistant",
"content": "{ \"name\": \"Canada\" , \"capital\": \"Ottawa\" , \"languages\": [\"English\", \"French\"] }"
},
...
Sehr bald schon wurde eine weitere Standard-Syntax in die gängigen LLMs eingebaut – und notwendigerweise auch in die betreibenden inference Server. Statt nur Datenstrukturen zu formulieren lassen sich inzwischen Funktionsdefinitionen und -Beschreibungen übergeben. Kann das LLM eine Frage nicht sicher selbst beantworten weil es an Kontext fehlt, so sucht sie sich aus einer Liste der zur Verfügung stehenden Funktionen die aus, die am geeignetsten scheint. Sie soll die Daten liefern, die zur Beantwortung der Anfrage passen. Das LLM füllt alle nötigen Parameter für den Funktionsaufruf so gut wie möglich aus und gibt die Aufruf-Struktur als Ergebnis zurück, und nicht das eigentliche Ergebnis. So in etwa funktioniert die “Tools API“. Das Programm, das die Anfrage an das LLM stellte, kann auf die Ergebnis-Struktur reagieren und die von dem LLM vorgeschlagenen Funktionen tatsächlich ausführen. Das Ergebnis der Funktionsaufrufe kann dann erneut an das LLM (oder ein anderes!) übergeben werden, idealerweise zusammen mit der bisherigen Chat- und Aufruf-Historie, und dann wird tatsächlich die ursprüngliche Anfrage beantwortet.
Ein Beispiel für einen Prompt, der die Tools API verwendet und zur Verfügung stehende Funktionen erklärend beschreibt. Das LLM entscheidet sich anhand der Anfrage des Endbenutzers, ob es diese selbst beantworten kann oder welche Funktion aufgerufen werden sollte um den noch nötigen Kontext herzustellen, also benötigte Daten zu beschaffen.
{"model": "llama3.1:latest",
"messages": [
{"role": "system", "content": "User birth date: January 20th, 1973."},
{"role": "user", "content": "Wie ist das Wetter in Aachen ?"}
],
"tools" : [
{ "type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
},
},
"required": ["location"],
},
}
},
{"type": "function",
"function": {
"name": "get_random_joke",
"description": "Get a random joke",
"parameters": {
"type": "object",
"properties": {},
"required": [],
},
}}
],
"stream": False, "options": {"use_mmap": True,"use_mlock": True,"num_thread": 8, "temperature": 0}}
Reicht also wie in diesem Beispiel der mitgegebene Kontext (das Geburtsdatum des Endbenutzers) nicht aus, um die Frage (“Wie ist das Wetter in Aachen ?”) zu beantworten füllt das LLM die Parameter der am ehesten in Frage kommenden Funktion aus und gibt die Aufruf-Syntax zurück. Das LLM kann recht gut entscheiden, ob es uns einen Witz erzählen oder das aktuelle Wetter von Aachen abrufen sollte.
{
"model": "llama3.1:latest",
"created_at": "2025-08-05T13:02:28.69570032Z",
"message": {
"role": "assistant",
"content": "",
"tool_calls": [
{
"function": {
"name": "get_current_weather",
"arguments": {
"location": "Aachen, Germany",
"unit": "celsius"
}
}
}
]
},
........
Der Code oder das Programm, das den ursprünglichen Prompt versandte könnte daraufhin die real existierende Funktion auf Wunsch des LLMs tatsächlich ausführen. Und noch weiter, das Ergebnis des Funktions-Aufrufes wird einfach an das bisherige JSON Dokument angehängt und abermals dem LLM übergeben, das dann die finale Antwort aus den Kontext-Informationen formulieren würde.
Auf diese Weise entstanden Agenten die dafür sorgen, daß zwischen einer vermeintlich unscheinbaren Chat-Anfrage und der KI-Antwort recht viel und auch in mehreren Iterationen geschieht. Agenten sind im Prinzip Programme und ganze Workflows, die auf Wunsch der KI Daten aus verschiedenen Quellen wie relationalen Datenbanken, Web-Inhalten, usw zusammensuchen, vielleicht noch formatieren, validieren oder zusammenfassen. Natürlich kann man solche Agenten auch direkt in einer Oracle Database in PL/SQL, Java oder APEX programmieren bzw. formulieren, eben da wo die nötigen Daten bereits vorliegen. Es muss nicht immer Python sein, aber auch das wird selbstverständlich von Oracle unterstützt mit top-aktuellen Treibern und API Plugins z.B. für die LangChain und LlamaIndex Frameworks. Die Ur-Ahnen BPEL , Service Bus und BPMN sind hier wohl außen vor und haben ihre Daseinsberechtigung in anderen, klassischeren Bereichen.
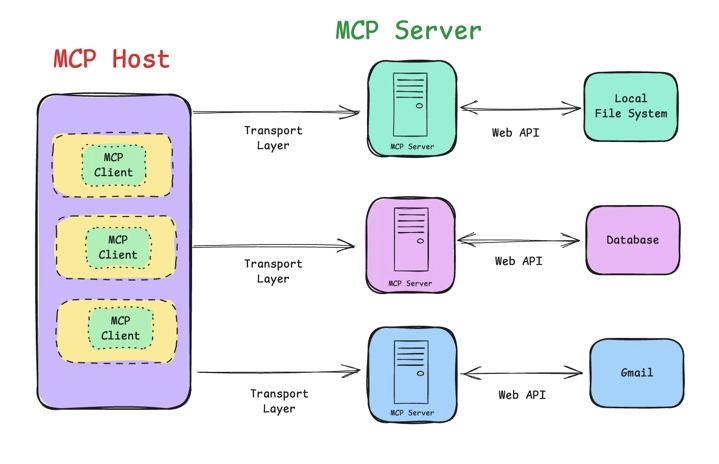
Eine weitere Erklärung finden Sie im Blog “Standardizing AI Tooling with MCP”
von Suman Debnath, ein detaillierteres zum Oracle MCP Server folgt weiter unten.
Und doch gibt es inzwischen wieder eine kleine u.a. lokale event-streaming basierte Middleware, um Agenten und Tools zu registrieren und zu koordinieren: die MCP Hosts. Um die eben erklärte Tools API standardisiert zu nutzen, neue Tools (und damit Agenten) zu registrieren und auszuführen, stehen den inference Servern und den verschiedenen Datentöpfen nun Kommunikationsserver zur Seite, die mehr können als nur zu chatten. Ein Chatbot kommuniziert nicht länger ausschließlich mit einem LLM bzw. inference Server, sondern steht als MCP Client in regem Austausch mit einem MCP Host. Dieser reichert eine Chat-Anfrage durch zur Verfügung stehende Tools an, führt im Bedarfsfall Tools sofort aus (ruft die MCP Server Programme auf, die hinter den Tool-Definitionen stecken) und gibt die Ergebnisse wieder in den zurück. Historie und Tool-Ergebnis wird im Paket an den inference Server gesandt, um eine bestmögliche endgültige Antwort zu erhalten. Ich mag hierbei das weiter oben erklärte Thema Context Window Size wieder ins Gedächtnis rufen, denn mehr Platz wird allmählich immer dringender benötigt.
Viele der bisherigen KI Features einer Oracle Database kamen noch ohne einen MCP Server und Tool support aus. Meist wurden in single-turn Aufrufen und per RAG ordentliche Prompts und vollständige Kontexte an die KI übergeben, zum Beispiel Tabellen-Metadaten, Kommentare und sehr strikte System-Anweisungen. Doch inzwischen kommen auch im direkten Zusammenhang mit der Oracle Database Erweiterungen heraus, die MCP unterstützen. Es sind ganze (freie) Software-Pakete und Teillösungen aus Oracle Database, inference Server und MCP Hosts in Vorbereitung und werden demnächst vorgestellt.
Features der Oracle Database, die lokale LLMs nutzen können
-
SELECT AI / DBMS_CLOUD_AI (Database 19c und 26ai)
-
UTL_HTTP (Database 19c und 26ai)
-
Vector Store / Vector Search bzw. DBMS_VECTOR / DBMS_VECTOR_CHAIN (Database 26ai)
-
Application Express Runtime und Design Time (Database 19c und 26ai)
-
MCP Server for Oracle Database (Database 19c und 26ai)
SELECT AI / DBMS_CLOUD_AI (Database 19c und 26ai)
Zur Datenbank-Struktur passende SQL Kommandos von einer KI erzeugen und auch gleich ausführen zu lassen, und das direkt innerhalb der Oracle Datenbank. Dieses Feature war zunächst nur in Autonomous Datenbanken verfügbar, es kann mittlerweile in Form einer PL/SQL Package namens DBMS_CLOUD_AI auch in Oracle Database Version 19c nachinstalliert und genutzt werden. Eine Support Notiz 2748362.1 und ein Blog Eintrag auf oracle-base.com erklären, wie das funktioniert.
Um mit DBMS_CLOUD_AI ein non-cloud LLM zu nutzen ist vorbereitend ein Zugriffsprofil in der Datenbank zu hinterlegen. In dieser Struktur werden die Zugangsdaten zu einem lokalen inference Server eingetragen, außerdem wird hinterlegt welche Datenbank-Objekte dem LLM bekannt gemacht werden sollen, damit das LLM sich darauf beziehen kann. Ein Beispiel für die Konfiguration des Zugriffs auf einen ollama inference Server könnte wie folgt aussehen:
-- Netzwerk-Zugriff des Demo-Benutzers SH auf den ollama server erlauben
BEGIN
DBMS_NETWORK_ACL_ADMIN.APPEND_HOST_ACE(
host => 'ollama.meinnetzwerk.com',
ace => xs$ace_type(privilege_list => xs$name_list('http'),
principal_name => 'SH',
principal_type => xs_acl.ptype_db)
);
END;
-- Dummy Credentials hinterlegen bei ungeschütztem Zugang auf den inference server
BEGIN
DBMS_CLOUD.CREATE_CREDENTIAL(
credential_name => 'OLLAMA_CRED',
username => 'OLLAMA',
password => 'OLLAMA'
);
END;
-- Zugriffs-Profil definieren - was ist erlaubt, welches LLM soll in ollama verwendet werden
-- Statt einer Liste einzelner Tabellen können auch nur Schema-Namen angegeben werden
-- das hier zu verwendende LLM lautet "codegemma:7b" und kann sehr gut Programmcode wie SQL erzeugen.
BEGIN
DBMS_CLOUD_AI.CREATE_PROFILE(
profile_name =>'OLLAMA',
attributes =>'{
"credential_name": "ollama_cred",
"comments": true,
"constraints": true,
"annotations": true,
"enforce_object_list": true,
"object_list": [{"owner": "SH", "name": "customers"},
{"owner": "SH", "name": "countries"},
{"owner": "SH", "name": "supplementary_demographics"},
{"owner": "SH", "name": "profits"},
{"owner": "SH", "name": "promotions"},
{"owner": "SH", "name": "sales"},
{"owner": "SH", "name": "products"}],
"model" : "codegemma:7b",
"provider_endpoint": "ollama.meinnetzwerk.com",
"conversation" : "true"
}');
END;
Eine kleine Warnung vorab: auch am Package DBMS_CLOUD_AI wird stetig weiterentwickelt. Der hier benutzte Parameter “provider_endpoint” für die Einbindung beliebiger inference Server über deren OpenAI kompatible REST API war im Package für “non-autonomous” Database 19c+26ai im Oktober 2025 noch NICHT bekannt. Sollten Sie hier auf noch unumstößliche Probleme treffen, empfehle ich Ihnen den neuen MCP Server for Oracle Database zu versuchen anstelle von DBMS_CLOUD_AI. Das Problem sollte bis zum Erscheinen eines neulich angekündigten “private AI containers” allerdings behoben sein.
Die Konfiguration des ollama inference servers wird hier nicht näher beschrieben. Aber bitte vergessen Sie nicht, das LLM codegemma:7b mit einem “ollama pull codegemma:7b” in den ollama server zu laden, bevor sie es benutzen bzw. aufrufen.
Ist einmal ein Profil definiert, können Sie es aktivieren und verschiedene Aufrufe an Ihre KI wagen. Bei der Aktivierung des Profils werden in der Datenbank die Metadaten der verfügbaren Objekte zusammengestellt und abgelegt, so daß ein Aufruf an das LLM einen vorgefertigten Prompt mit Anweisungen und allen Tabellenbeschreibungen erhält. Aktivierung und Testaufrufe könnten dann wie folgt aussehen:
-- Profil aktivieren
BEGIN
DBMS_CLOUD_AI.SET_PROFILE('OLLAMA');
END;
-- recht ungenaue Frage ans system, kommt die KI damit klar ?
SELECT DBMS_CLOUD_AI.GENERATE(prompt => 'how many customers',
profile_name => 'OLLAMA',
action => 'runsql') result
FROM dual;
RESULT
==================================
[{ "TOTAL_CUSTOMERS" : 55500 }]
-- statt das SQL direkt auszuführen, zeige das erzeugte SQL
SELECT DBMS_CLOUD_AI.GENERATE(prompt => 'how many customers',
profile_name => 'OLLAMA',
action => 'explainsql') explain
FROM dual;
EXPLAIN
==================================
sql
SELECT COUNT(*) AS total_customers
FROM SH.CUSTOMERS;
-- mit dem LLM allgemein chatten statt SQLs zu erzeugen
SELECT DBMS_CLOUD_AI.GENERATE(prompt => 'what is oracle autonomous database',
profile_name => 'OLLAMA',
action => 'chat') chat
FROM dual;
CHAT
===================================
**Oracle Autonomous Database**
Oracle Autonomous Database is a cloud-based, fully managed database service that eliminates the need for manual database administration. It is a self-service, pay-as-you-go database that provides a secure, scalable, and high-performance environment for applications.
-- etwas komplexere Abfrage
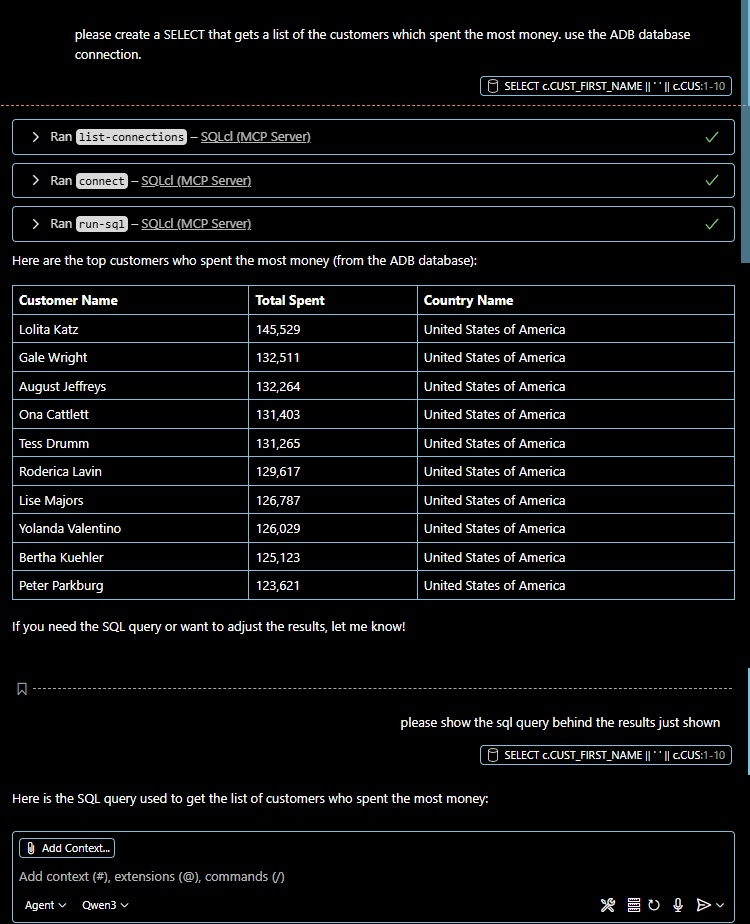
SELECT DBMS_CLOUD_AI.GENERATE(prompt => 'which 10 customers have spent the most money ? please also show the country name for each customer.',
profile_name => 'OLLAMA',
action => 'showsql') sql
FROM dual;
SQL
===================================
SELECT c.CUST_FIRST_NAME || ' ' || c.CUST_LAST_NAME AS customer_name,
SUM(s.AMOUNT_SOLD) AS total_spent,
co.COUNTRY_NAME
FROM SH.CUSTOMERS c
JOIN SH.SALES s ON c.CUST_ID = s.CUST_ID
JOIN SH.COUNTRIES co ON c.COUNTRY_ID = co.COUNTRY_ID
GROUP BY c.CUST_FIRST_NAME, c.CUST_LAST_NAME, co.COUNTRY_NAME
ORDER BY total_spent DESC
FETCH FIRST 10 ROWS ONLY
Das Schöne an einem lokalen inference server ist, daß man leichter Einblick erhält in die Daten, die durch den Äther an das LLM gesandt wurden. Die im Beispiel zuletzt formulierte Frage lautet “which 10 customers have spent the most money ? please also show the country name for each customer.” Der von der Datenbank erzeugte Prompt enthält viel mehr Details als nur die eigentliche Frage. Nämlich auch einen Kontext-Rahmen in Form von zahlreichen Metadaten und sehr genauen Anweisungen, wie das Ergebnis zu eruieren und zu formatieren sei. Das ist im Prinzip das ganze Geheimnis hinter dem Begriff RAG, retrieval augmented generation: man gibt der KI mit auf den Weg, worüber sie sprechen soll und was sie im Zusammenhang mit der Anfrage wissen darf. Dieses Wissen wurde vor der Anfrage an das LLM möglichst performant vorgefiltert, und aufbereitet, nur das Nötigste wiedergegeben. Ein vielleicht schräges Beispiel: ich gebe dem LLM nicht immer die gesamte Bibel mit auf den Weg, sondern nur relevante Verse. Schräg ist das Beispiel, weil gängige LLMs die Bibel eigentlich als Wissensbasis für ihr Allgemeinswissen bereits enthalten…
Der Größe wegen ist der nachfolgend aufgeführte Prompt hier nur auszugsweise dargestellt. Und auch hier sei darauf hingewiesen, dass das verwendete LLM ein angemessen grosses Context Window unterstützt. Denn je mehr Metadaten, Kommentare und Annotationen, desto besser das Verständnis der KI über das Datenmodell und desto besser das Ergebnis. Und leider auch desto langsamer der Aufruf an das LLM…
### Your task is to ALWAYS answer queries using ONLY the available tables provided in the context, no other tables and Oracle system views. If the context does not provide the necessary tables, respond by explaining the reason. Available Oracle SQL tables provided: --'facts table, without a primary key; all rows are uniquely identified by the combination of all foreign keys' # CREATE TABLE \"SH\".\"SALES\" (\"PROD_ID\" NUMBER 'FK to the products dimension ...... ................ --'dimension table' # CREATE TABLE \"SH\".\"CUSTOMERS\" (\"CUST_ID\" NUMBER 'primary key' , \"CUST_VALID\" VARCHAR2(1) , \"CUST_EFF_TO\" DATE , \"CUST_EFF_FROM\" DATE , \"CUST_SRC_ID\" NUMBER , \"CUST_TOTAL_ID\" NUMBER , \"CUST_TOTAL\" VARCHAR2(14) , \"CUST_EMAIL\" VARCHAR2(50) 'customer email id' , \"CUST_CREDIT_LIMIT\" NUMBER 'customer credit limit' , \"CUST_INCOME_LEVEL\" VARCHAR2(30) 'customer income level' , \"CUST_MAIN_PHONE_NUMBER\" VARCHAR2(25) 'customer main phone number' , \"COUNTRY_ID\" NUMBER 'foreign key to the countries table (snowflake)' , \"CUST_STATE_PROVINCE_ID\" NUMBER , \"CUST_STATE_PROVINCE\" VARCHAR2(40) 'customer geography: state or province' , \"CUST_CITY_ID\" NUMBER , \"CUST_CITY\" VARCHAR2(30) 'city where the customer lives' , \"CUST_POSTAL_CODE\" VARCHAR2(10) 'postal code of the customer' , \"CUST_STREET_ADDRESS\" VARCHAR2(40) 'customer street address' , \"CUST_MARITAL_STATUS\" VARCHAR2(20) 'customer marital status; low cardinality attribute' , \"CUST_YEAR_OF_BIRTH\" NUMBER(4,0) 'customer year of birth' , \"CUST_GENDER\" CHAR(1) 'gender; low cardinality attribute' , \"CUST_LAST_NAME\" VARCHAR2(40) 'last name of the customer' , \"CUST_FIRST_NAME\" VARCHAR2(20) 'first name of the customer') --'dimension table without a PK-FK relationship with the facts table, to show outer join functionality' # CREATE TABLE \"SH\".\"PROMOTIONS\" (\"PROMO_ID\" NUMBER(6,0) 'primary key column table' , \"AMOUNT_SOLD\" NUMBER(10,2) 'invoiced amount to the customer' , \"QUANTITY_SOLD\" NUMBER(10,2) 'product quantity sold with the transaction' , \"PROMO_ID\" NUMBER 'promotion identifier, without FK constraint (intentionally) to show outer join optimization' , \"CHANNEL_ID\" NUMBER 'FK to the channels dimension table' , \"TIME_ID\" DATE 'FK to the times dimension table' , \"CUST_ID\" NUMBER 'FK to the customers dimension table') ................... Given an input Question, create a syntactically correct Oracle SQL query to run. Pretty print the SQL query. - Pay attention to using only the column names that you can see in the schema description. - Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table. - Please double check that the SQL query you generate is valid for Oracle Database. - Consider table name, schema name and column name to be case sensitive and enclose in double quotes. - Only use the tables listed below. - If the table definition includes the table owner, you should include both the owner name and user-qualified table name in the Oracle SQL. - DO NOT keep empty lines in the middle of the Oracle SQL. - DO NOT write anything else except the Oracle SQL. - Always use table alias and easy to read column aliases. For string comparisons in WHERE clause, CAREFULLY check if any string in the question is in DOUBLE QUOTES, and follow the rules: - If a string is in DOUBLE QUOTES, use case SENSITIVE comparisons with NO UPPER() function. - If a string is not in DOUBLE QUOTES, use case INSENSITIVE comparisons by using UPPER() function around both operands of the string comparison. Note: These rules apply strictly to string comparisons in the WHERE clause and do not affect column names, table names, or other query components. Question: which 10 customers have spent the most money ? please also show the country name for each customer.
UTL_HTTP und JSON_OBJECT_T (Database 19c und 26ai)
Komfort-Funktionen wie die in DBMS_CLOUD_AI verwalten LLM Zugänge und erzeugen automatisch umfassende Prompts für datenbank-bezogene Anfragen. Dieser Komfort ist vielleicht nicht immer gewünscht und Sie möchten selbst die KI beauftragen, strukturierte Daten zu erzeugen oder Fragen auf Daten in Ihrer Datenbank zu beantworten. Dann können Sie die Aufrufe auch vollständig frei formulieren, denn die zugrunde liegende REST API gängiger inference server ist offengelegt und dokumentiert, Sie müssen lediglich verstärkt mit JSON Dokumenten und Datenstrukturen hantieren. In manchen Fällen verweist die Oracle Datenbank Dokumentation auf die Verwendung der UTL_HTTP Packages und den JSON Datentyp, wenn beispielsweise nicht direkt unterstützte REST APIs genutzt werden sollen. Hier ein kleines Beispiel für einen direkten Aufruf -mit vereinfachtem, weil hartcodiertem RAG- an ein lokales LLM, ohne große Umschweife:
-- Netzwerk-Zugriff des Demo-Benutzers SH auf den ollama server erlauben
BEGIN
DBMS_NETWORK_ACL_ADMIN.APPEND_HOST_ACE(
host => 'ollama.meinnetzwerk.com',
ace => xs$ace_type(privilege_list => xs$name_list('http'),
principal_name => 'SH',
principal_type => xs_acl.ptype_db)
);
END;
-- Folgende Funktion oder Prozedur bitte als SH Benutzer definieren. Sie ruft ein LLM auf und gestattet eine Benutzer-Anfrage.
-- Die Wissensbasis zur Beantwortung der Anfrage wird im Prompt mit übergeben, der Lesbarkeit hier hartcodiert
-- Die verwendete JSON Syntax ist typisch für Chat-Schnittstellen an inference server wie OpenAI, ollama und co
CREATE OR REPLACE FUNCTION rag_with_genai_function( rag_question in varchar2) return varchar2
AS
l_url VARCHAR2(400) := 'https://ollama.meinnetzwerk.com/api/chat';
req utl_http.req;
resp utl_http.resp;
body VARCHAR2(4000);
buffer VARCHAR2(8192);
BEGIN
-- den richtigen Prompt definieren: wie ist zu antworten und wie sehr soll sich die KI an die Wissensbasis halten
-- das zu verwendende LLM - llama3.1:latest ist generisch, klein und schnell
-- System-Anweisungen kommen in der Rolle "system", Benutzer-Anfragen in der Rolle "user"
body := '{"model": "llama3.1:latest","messages": [{"role": "system", "content": " '||
'Your answers should begin with the phrase ''According to the information found in my database''.' ||
'Please answer the following question only with information given in the provided DOCUMENTS"} ,' ||
-- Die Wissensbasis könnte aus Daten aus relationalen Tabellen bestehen oder Dokument-Fragmente, die per Volltextsuche gefunden wurden
-- Der Kürze halber hier hart codiert
'{"role": "system", "content": "DOCUMENTS: It has been proven that men can get breast cancer too "} , ' ||
'{"role": "system", "content": "DOCUMENTS: Male breast cancer is very rare "} , ' ||
-- hier wird die Endbenutzer-Frage in den Prompt eingeflanscht
'{"role": "user", "content": "'|| rag_question ||'"}],' ||
-- Tuning Parameter an den inference server, vorerst unbedingt auf streaming verzichten für eine vollständige Antwort
'"stream": false, "options": {"use_mmap": true,"use_mlock": true,"num_thread": 8}}';
-- Auch Datenbanken müssen manchmal über Proxies ins Internet, aber bei einem lokalen LLM eher nicht. Daher auskommentiert.
-- utl_http.set_proxy('http://username:passwd@192.168.22.33:5678');
-- der HTTP request wird konstruiert
req := utl_http.begin_request(l_url, 'POST', 'HTTP/1.1');
utl_http.set_header(req, 'Accept', '*/*');
utl_http.set_header(req, 'Content-Type', 'application/json');
utl_http.set_header(req, 'Content-Length', length(body));
utl_http.write_text(req, body);
-- nun wird der inference server aufgerufen und das Ergebnis ausgelesen
resp := utl_http.get_response(req);
BEGIN
utl_http.read_text(resp, buffer);
EXCEPTION
WHEN utl_http.end_of_body THEN
utl_http.end_response(resp);
END;
buffer := json_value (buffer, '$.message.content' returning varchar2);
return (buffer);
END;
Ein Aufruf der Funktion mit einer Frage, die zur übergebenen Knowledge Base passt, sollte eine knapp bemessene Antwort des LLM ergeben:
-- ebenfalls als Benutzer SH ausführen
select rag_with_genai('can men get breast cancer too?') as answer from dual;
ANSWER
============================
According to the information found in my database, yes, men can get breast cancer. However, it is considered relatively rare compared to breast cancer in women.
Vector Store / Vector Search bzw. DBMS_VECTOR / DBMS_VECTOR_CHAIN (Database 26ai)
Die eigentliche Ablage, Indizierung und Suche von vektorisierten Daten erfolgt mit eigenen Mitteln, es wird hierfür kein LLM verwendet. Um jedoch Vektoren aus Daten zu berechnen, zum Beispiel aus Textfragmenten, und diese dann zu speichern, können Datenbank-Funktionen genutzt werden aus den Packages DBMS_VECTOR und DBMS_VECTOR_CHAIN. Der Vorgang, aus beliebigen Daten mittels eines LLM Vektoren zu berechnen, wird auch das Erzeugen von Embeddings genannt. Ebenso sollte eine als Text formulierte Suchanfrage in Vektoren umgerechnet werden, damit sie mit bestehenden Vektoren in der Datenbank vergleichbar wird. Auch hier läßt sich das Package DBMS_VECTOR verwenden.
Die in den jeweiligen Packages enthaltenen Funktionen zur Erzeugung von Embeddings (TO_EMBEDDING bzw. TO_EMBEDDINGS, je nachdem ob Einzelwerte oder Arrays übergeben werden) lassen sich so parametrisieren, dass sie entweder ein in die Datenbank geladenes LLM zur Erzeugung von Embeddings bemühen oder einem separaten inference Server die Daten übergeben, um Embeddings berechnen zu lassen. Die LLMs innerhalb der Datenbank führen ihre Operationen auf der lokalen CPU aus, gerne parallelisiert wenn möglich, und die separaten inference Server haben vermutlich GPUs im Zugriff.
Interessanterweise benötigen die Netzwerk-Roundtrips bei externen Aufrufen an inference Server nennenswerte Zeit. Ohne Batching-Operationen, z.B. durch Übergabe ganzer Daten-Arrays anstelle von Einzelwerten, wären die Ergebnisse der Berechnungen kleinerer Datemengen (Suchanfragen, einzelne Tabellenspalten, einzelne Text-Chunks) auf der lokalen CPU und ohne Netzzugriff schneller als auf der GPU im (lokalen) Netzwerk.
Der Kunstgriff funktioniert nur dann besonders gut, wenn die Erzeugung der Embeddings besonders kleinen LLMs anvertraut wird, die nur zu dem Zweck existieren, Embeddings zu erzeugen. Um Embeddings aus Texten zu berechnen werden typische sentence-transformer LLMs genutzt. Solche LLMs sind nur noch wenige hundert Megabytes gross, eben nicht mehr Gigabytes wie die umfassenderen Textgeneratoren-Experten. Versuchen Sie es doch selbst einmal im Vergleich!
Versuch 1:
Lokales in-Database LLM laden und Embedding erzeugen
Bitte laden Sie zunächst ein sentence transformer LLM von huggingface herunter, zum Beispiel nomic-embed-text-v1.5 , bitte im ONNX (open neural network exchange) Format.
Dann laden wir die Datei in die Datenbank hinein und erzeugen ein Embedding, lokal auf CPU und ohne Netzwerk:
BEGIN
-- Die Datenbank kennt nun das Verzeichnis /tmp und nennt es MODEL_DIR
-- Dort sollte auch die heruntergeladene ONNX Datei liegen
CREATE OR REPLACE DIRECTORY MODEL_DIR AS '/tmp';
-- Wurde die ONNX Datei heruntergeladen unter dem Namen "model.onnx" ?
-- Gegebenenfalls bitte anpassen
DBMS_VECTOR.LOAD_ONNX_MODEL(
'MODEL_DIR',
'model.onnx',
'nomic_model',
JSON('{"function":"embedding","embeddingOutput":"embedding","input":{"input": ["DATA"]}}')
);
END;
SELECT TO_VECTOR(VECTOR_EMBEDDING(nomic_model USING 'can men get breast cancer too' AS DATA)) as VECTOR_DATA from dual;
VECTOR_DATA
=======================================
[-1.78362778E-003,-2.63432469E-002,9.18012578E-003,7.73889478E-003,2.33698897E-0
02,-3.50732245E-002,1.72414538E-002,-2.08509713E-003,-1.78824551E-002,1.553251E-
001,-6.05734661E-002,3.72434705E-002,-8.30145925E-003,3.46281789E-002,6.17512912
E-002,1.59628168E-002,4.11528721E-002,-4.06850036E-003,-3.26767527E-002,3.306468
2E-002,1.62407178E-002,-6.36792406E-002,-7.9902567E-002,-6.57038093E-002,-5.2594
0545E-002,-8.08598101E-002,1.15027493E-002,-1.02846622E-002,3.99888493E-002,-7.6
2334326E-003,-7.13080391E-002,6.25135154E-002,-6.12752996E-002,-5.82841132E-003,
5.41676134E-002,-3.1681329E-002,-2.57817637E-002,1.22085335E-002,1.16529651E-001
,-3.23723853E-002,2.40268558E-002,-3.10333222E-002,-3.51821259E-002,6.46591336E-
002,8.10852274E-002,-1.8553853E-002,-9.99582652E-003,-7.44895916E-003,-2.5479279
5E-002,-5.58673963E-002,2.54160687E-002,-9.53436568E-002,2.905301E-002,3.8869246
..........
Versuch 2:
Lokales LLM auf separatem inference Server – Embedding erzeugen
Bitte laden Sie zunächst das LLM in Ihren inference Server, zum Beispiel mit
ollama pull nomic-embed-text:v1.5
Dann konfigurieren Sie den Aufruf an den ollama inference server aus der Datenbank heraus und übergeben die zu berechnenden Daten dorthin:
-- in sqlplus, Ausgabe von dbms_output.put_line aktivieren
SET SERVEROUTPUT ON
-- statt Texte zu konkatinieren ließe sich auch der JSON_OBJECT_T verwenden
-- und mit PUT Anweisungen bzw. TO_STRING befüllen und konvertieren.
-- Dann hat das leidige Zählen von Klammern und Hochkommas ein Ende.
DECLARE
params CLOB;
BEGIN
params := '{"provider":"ollama",'||
'"host" :"local", '||
'"url" : "https://ollama.meinnetzwerk.com/api/embeddings", '||
'"model" : "nomic-embed-text:v1.5" '||
'}';
SELECT DBMS_VECTOR.UTL_TO_EMBEDDING('can men get breast cancer too ?',json(params)) INTO params FROM DUAL;
DBMS_OUTPUT.PUT_LINE(params);
END;
[1.2665236E+000,4.31505777E-002,-2.51287365E+000,3.40908289E-001,1.12592304E+000
,1.00485051E+000,-8.02193582E-001,4.95056152E-001,-9.54351187E-001,3.51342447E-0
02,-2.64354497E-001,2.23134851E+000,1.43077803E+000,2.17210397E-001,-6.58598244E
-001,1.1650943E-001,-8.25438738E-001,1.69692952E-002,-1.13289738E+000,5.9586221E
-001,-1.46188283E+000,-2.84991473E-001,-4.53325748E-001,-1.79109454E-001,6.32949
769E-001,1.62033951E+000,-1.28188342E-001,2.13365734E-001,-1.06601095E+000,1.294
62898E+000,2.10151625E+000,5.5099231E-001,-4.13231254E-001,-6.66427433E-001,3.92
9061E-001,-1.9384048E+000,1.16242099E+000,-3.98766786E-001,7.32743979E-001,-1.60
589129E-001,9.05524254E-001,-4.1949755E-001,-5.62686682E-001,-1.95476305E+000,4.
3672052E-001,8.93152207E-002,-3.96666795E-001,1.59904528E+000,4.78247344E-001,-5
.67765713E-001,1.24860215E+000,-1.45285594E+000,5.89506388E-001,-6.74407661E-001
,1.29194307E+000,-1.06768715E+000,3.25580627E-001,-5.31787932E-001,6.42485261E-0
..............................................
Stellen Sie sich vor, in Ihre Datenbank wird ein neues Dokument hochgeladen oder bekanntgemacht, indem eine Tabellenzeile eingefügt wird mit einem Verweis auf das Dokument.
Ein Datenbank Trigger könnte nun alle Text-Inhalte aus dem neuen Dokument ziehen, Embeddings intern oder extern erzeugen und zur weiteren Verarbeitung ablegen und indizieren. Ganz daten-nah und ohne externe Eventing-Mechanismen und aufwändige Frameworks. Text-Inhalte aus Dokumenten zu extrahieren und in verwertbare Chunks zu wandeln funktioniert ebenso in der Datenbank über die DBMS_VECTOR_CHAIN PL/SQL Package (z.B. Funktionen UTL_TO_CHUNKS und UTL_TO_TEXT), die ohne weitere Aufrufe an externe Frameworks auskommt.
Neben ollama werden einige weitere inference Server direkt unterstützt oder über deren OpenAI kompatibler REST API. Die aktuelle Liste unterstützter inference Server finden Sie in der Datenbank Dokumentation: https://docs.oracle.com/en/database/oracle/oracle-database/23/vecse/supported-third-party-provider-operations-and-endpoints.html
Der Vollständigkeit halber sei erwähnt, daß das DBMS_VECTOR_CHAIN Package noch weitere LLM Aufrufe unterstützt. Die Funktionen UTL_TO_GENERATE_TEXT und UTL_TO_SUMMARY funktionieren sehr ähnlich wie UTL_TO_EMBEDDING. Auch hier wäre im Falle von ollama als inference Server entweder “ollama” und die ollama URL anzugeben, oder “openai”, da ollama neben der eigenen REST API auch eine API versteht, die kompatibel zu OpenAI ist. Wünschen Sie eine Ausführung direkt in der Datenbank auf CPU, dann steht Ihnen jeweils der Provider “database” zur Verfügung. Dokumentiert ist das Package hier: https://docs.oracle.com/en/database/oracle/oracle-database/23/arpls/dbms_vector_chain1.html, die weiter oben aufgeführte Liste der verfügbaren Provider gilt für alle Funktionen im Package.
Application Express Runtime und Design Time (Database 19c und 26ai)
Oracle Application Express ist eine freie Low Code Entwicklungsumgebung und Runtime. Sie läßt sich in alle verfügbaren Datenbank-Editionen (FREE, Standard, Enterprise, Autonomous,..) und Versionen (19c, 23ai) installieren und nutzen. Seit einiger Zeit, d.h.ab APEX Version 24, wird die Entwicklung von KI-gestützten Anwendungen ermöglicht, und auch das gerne KI gestützt. Folgende Dinge sind aktuell möglich:
- Einfache Erzeugung von Chatbot-Oberflächen mit RAG oder Aufrufe an KIs um z.B. Texte zu generieren und Embeddings zu erzeugen, alternativ zu DBMS_CLOUD_AI und DBMS_VECTOR_CHAIN. Aber mit komfortablerer Verwaltung der Zugänge und verwendeter Modelle. Neben neuer Oberflächen Elemente wie “Chatbot” gibt es eine weitere PL/SQL API namens APEX_AI mit Methoden wie GENERATE, CHAT und GET_VECTOR_EMBEDDING. Da Ihre 19c Datenbank noch keinen VECTOR Datentyp kennt kann sie die verbleibenden Funktionen nutzen.
- Workflows im Sinne von konfigurierbaren Aufrufketten lassen sich dort definieren und z.B. per REST Service oder Shell Skript von außen aufrufbar machen. Es ist denkbar eigene KI Agenten mit APEX zu formulieren und als Tool einem MCP Host bekanntzumachen. Das wäre aber eher Inhalt eines separaten Blogs.
- Entwickler können in die Design Time integrierte Chatbots nutzen, um per Diskussion Datenstrukturen zu erzeugen, Demo-Daten zu generieren, SQL und PL/SQL vorzugenerieren und auch um Oberflächen-Elemente und sogar ganze Anwendungen zu definieren.
Alle genannten Funktionen können über ein lokales LLM genutzt werden. Oder sagen wir aus Performance-Gründen über mehrere spezialisierte, lokale LLMs. In der APEX Design Time Oberfläche können mehrere Verbindungen zu inference Servern mit jeweils einem einzubindenden LLM definiert werden. Ich empfehle daher, für Entwickler ein Code-Generierendes LLM einzubinden wie codegemma, codellama, qwen3, gtp-oss. Für Chatbot-Anwendungen oder Anwendungen, die eine KI basierte Entscheidung benötigen, kommt es auf den Anwendungsfall an. Generische LLMs, mit denen man sich gut und mehrsprachig unterhalten kann oder wieder spezielle LLMs mit Stärken in Mathematik oder sich erklärende LLMs mit reasoning Feature bzw thinking phase ?
Auf jeden Fall sind mindestens zwei lokale LLMs in APEX zu hinterlegen, eines für Entwickler und eines für Endanwender.
Um ein lokales LLM in APEX nutzen zu können sollten Sie zunächst in der Datenbank den Zugriff des APEX Datenbank Benutzers auf den inference Server erlauben.
Dieser APEX Benutzer trägt die genutzte APEX Versionsnummer in seinem Namen. Die Versionsnummer des betreibenden ORDS kann durchaus größer sein. Der Benutzer APEX_PUBLIC_USER wird nur als Proxy User verwendet, es bringt nichts ihn in die Netzwerk ACL einzutragen da der APEX Code nicht durch ihn ausgeführt wird.
-- Bitte APEX Versionsnummer anpassen und natuerlich den Host des ollama inference servers
BEGIN
DBMS_NETWORK_ACL_ADMIN.APPEND_HOST_ACE(
host => 'ollama.meinnetzwerk.com',
ace => xs$ace_type(privilege_list => xs$name_list('http'),
principal_name => 'APEX_240200',
principal_type => xs_acl.ptype_db) );
END;
Als brute force Methode können Sie gern den Host “*” verwenden, alle Hosts sind dann erlaubt.
Laden Sie sich in ihren lokalen inference server ein paar ansprechende LLMs für Codegenerierung und für Chats herunter, zum Beispiel:
ollama pull codegemma:7b
ollama pull qwen3:latest
Danach tragen Sie in der APEX Design Time Oberfläche die von ollama gehosteten LLMs ein. Melden Sie sich zuerst an einem Workspace Ihrer Wahl an:

Dann wechseln Sie z.B. über das App Builder Menü in die Workspace Utilities – All Workspace Utilities
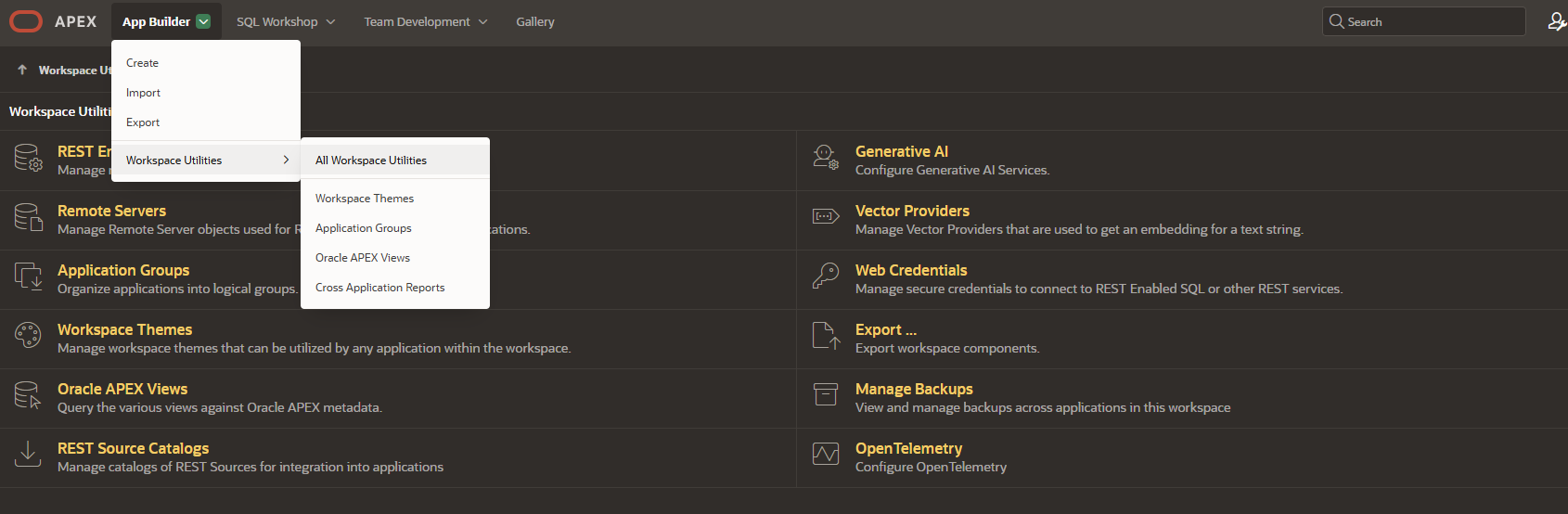
Dort sehen Sie den Bereich “Generative AI”, in dem Sie die Verbindungen zu KIs definieren können. Klicken Sie darauf, dann auf den grünen “create” Button auf der rechten Seite:

Tragen Sie dann in der Eingabemaske folgende Dinge ein, um hier im Beispiel einen ollama inference Server als Entwickler zu nutzen, d.h. um Code zu generieren:
Provider: Open AI Name: MyCodeGemma Static ID: codegemma Used by app builder: TRUE (aktivieren, diese eine Connection ist für Entwickler gedacht) Base URL: http://ollama.meinnetzwerk.com:11434/v1 (Port 11434 ist default bei ollama, die URI /v1 ist die Basis für die OpenAI kompatible REST API) Credential: -create new- und bitte irgendetwas als API key eintragen, z.B. OLLAMA , falls Ihr inference server noch ungeschützt sein sollte. AI Model: codegemma:7b

Ein Klick auf den “Test Connection” Button sollte dann ohne Fehlermeldung funktionieren. Vielleicht haben Sie sich ja vertippt und ein LLM angegeben, das in Ihrem inference Server nicht geladen ist. Oder Sie müssen APEX noch erlauben, die angelegten Credentials für die genannte Host URI zu verwenden – auch dafür gibt es eine Administrationsseite im Bedarfsfall, ebenfalls in den Workspace Utilities unter dem Punkt “Web Credentials”.
Nach gleichem Schema legen Sie bitte eine weitere Verbindung an, diesmal aber unter der static ID “qwen“, KEIN Häkchen bei “Used by App Builder” (es kann nur einen geben), und als AI Model das vorab in Ihren inference Server geladene “qwen3:latest“. Die Credentials aus dem vorigen Schritt können Sie gerne wiederverwenden. Jeweils eine der static IDs geben Sie dann später in Ihren KI tauglichen Anwendungs Widgets an, z.B. im Chatbot Fenster.
Testen wir das Codegenerierungs-LLM, indem wir uns ein paar SQLs erzeugen lassen mit einer Datenstruktur und Demo-Daten darin.
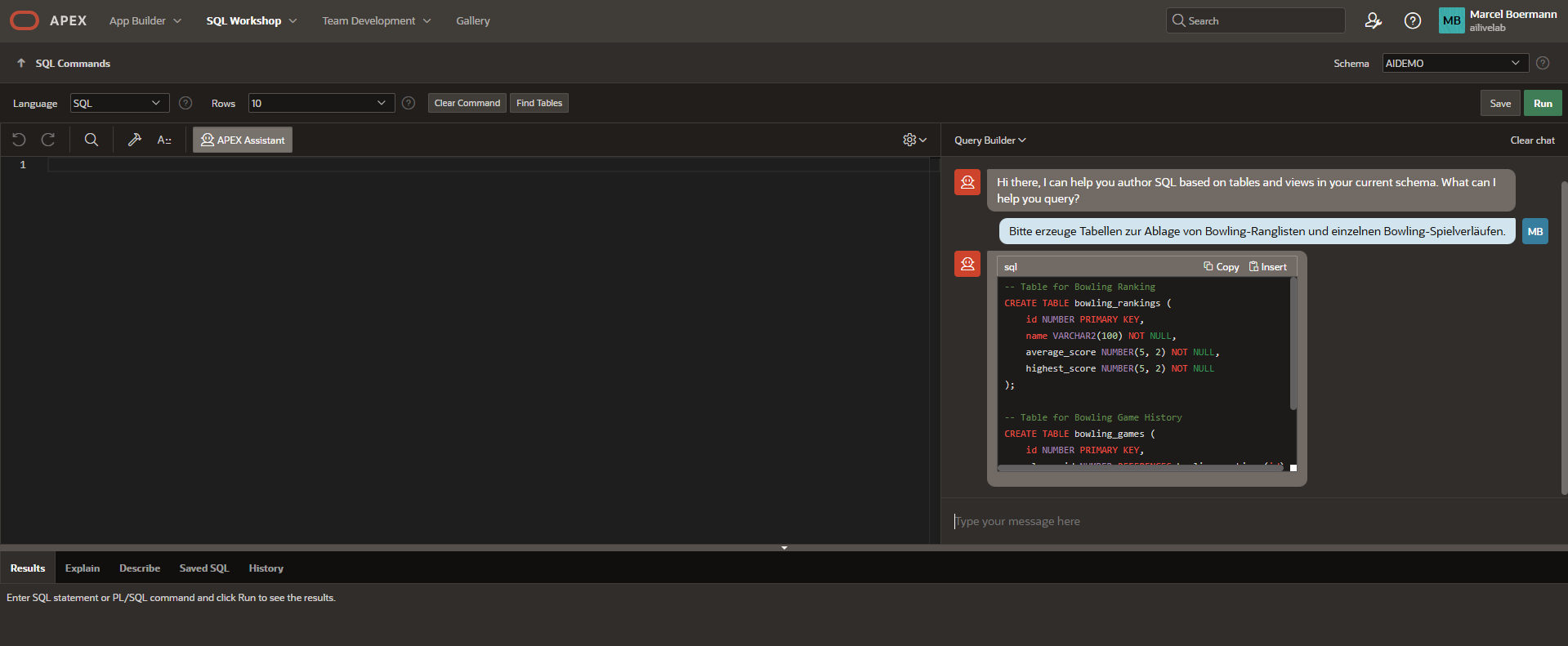
Wechseln Sie nun per Icon oder per Menü über “SQL Workshop” nach “SQL Commands”. Jetzt sollte ein Icon im Fenster zu sehen sein mit dem Titel “APEX assistant”. Das erscheint, wenn eines der gültigen eingebundenen LLMs den “Used by App Builder” Haken gesetzt hat. Klicken Sie darauf, so daß ein Chat Fenster erscheint, und kommunizieren Sie ein wenig mit Ihrem lokalen LLM. Vielleicht lassen Sie sich eine Datenstruktur generieren und im Dialog ein paar Felder hinzugenerieren ? Fragen Sie auf Deutsch oder Englisch ?
Den generierten Code können Sie nachbessern lassen, z.B. Spalten hinzufügen, oder ihn in den SQL Editor übernehmen und ausführen. Mit dem richtig gewählten LLM erscheint der Code in hervorgehobenen Farben und schönen Strukturen (Markdown Unterstützung…!), kleinere oder ältere LLMs bieten da nicht ganz so ansprechende Optik an (codellama oder besonders kleine LLMs unter 3b Parametern).
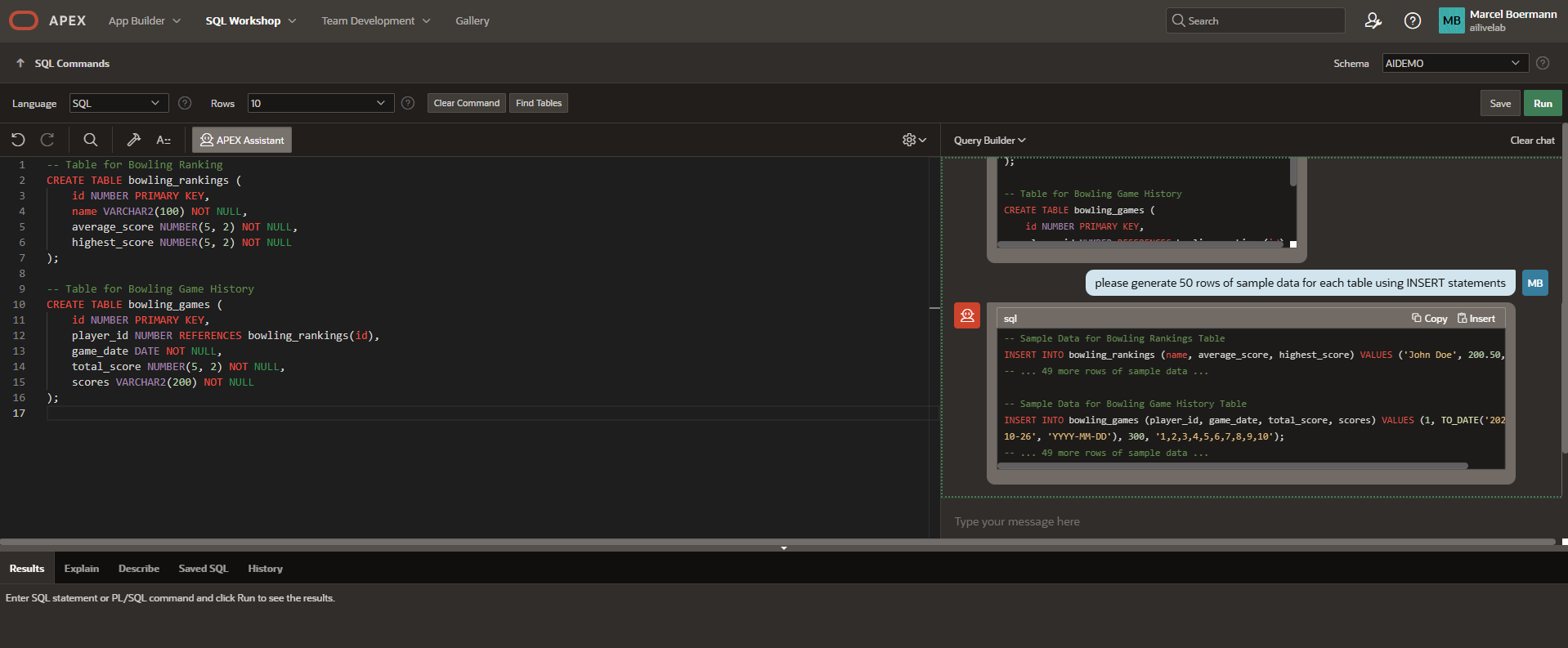
Die Möglichkeiten sind zahlreich, Sie können gerne unter Anleitung eine KI gestützte Anwendung mit Chatbot und Text-Generatoren nachbauen und dabei Ihre eigenen Wunsch-LLMs verwenden! Versuchen Sie doch einmal das New York Schools LiveLab mit ollama anstelle von OCI Genai, ChatGPT oder Gemini.
Im folgenden Screenshot verwende ich in einem Chat das qwen3:latest Modell und befrage es auf deutsch. Das Modell geht im Standard durch eine “think” pase (auch reasoning feature genannt) hindurch und erklärt, wie es zu seinem Ergebnis kommt, das auf relationalen Daten basiert. In der Demo werden ein paar Datensätze per RAG an das LLM übergeben. Das Ergebnis kommt nett per Markdown Syntax aufbereitet und wieder in Deutsch.
Warum? Weil es das LLM kann !
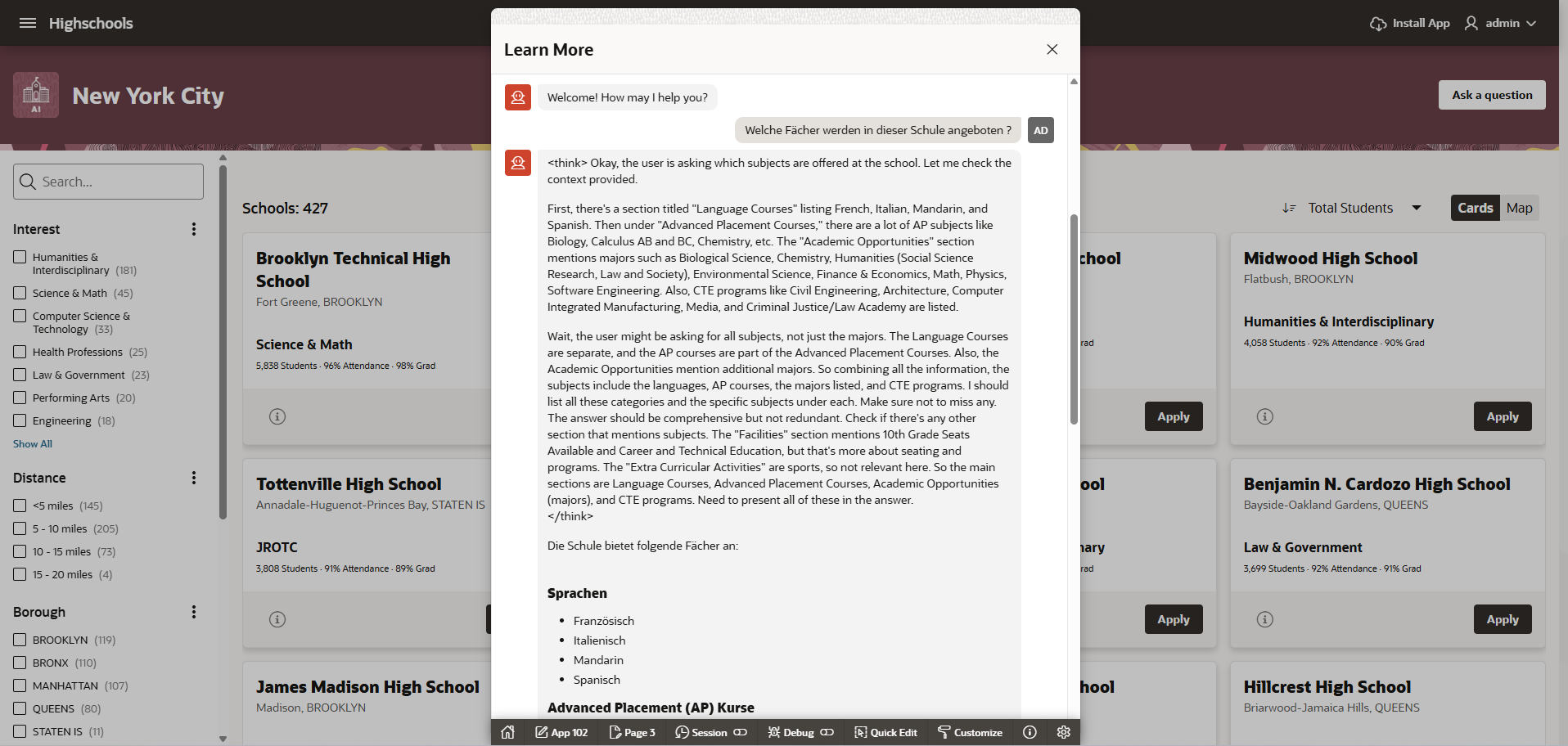
MCP Server for Oracle Database (Database 19c und 26ai)

Weitere Beschreibungen finden Sie auf thatjeffsmith.com
Eine besondere Unterstützung für Entwickler ist nicht länger nur Teil von APEX. In Visual Studio Code gibt es seit einiger Zeit gleich mehrere Code-Assistenten, Copilots usw. als herunterladbare plugins. Sie verwenden LLMs, um ganz allgemein Code zu vervollständigen oder zu generieren, aber auch umzugestalten und auch mal um Logik-Fehler zu finden. Durch Unterstützung des Protokolls MCP sind die Assistenten nun in der Lage, vorgeschlagenen Code gleich auszuführen oder benötigten Kontext zur Lösung einer Aufgabe selbsttätig heranzuholen. Der recht frisch eingeführte freie MCP Server for Oracle Database kann in VSCode verwaltete Datenbank Connections verwenden, um Aufgaben direkt in den Datenbanken auf Wunsch eines LLMs auszuführen oder -ähnlich wie bei SELECT AI- Metadaten aus den verbundenen Datenbanken abzurufen um passgenaue SQL Operationen zu erzeugen. Jede Aktion muß natürlich zumindest initial vom Endbenutzer akzeptiert werden !
Der MCP Server for Oracle Database ist in eine neue Version des SQL Developer plugins for Visual Studio Code eingebettet. Genauer gesagt wurde das Programm “sqlcl” erweitert, um einige Funktionen wie “list-connections“, “run-sql” und so weiter gemäß MCP Spezifikation in einem MCP Host bekanntzugeben und dann auch auszuführen, implementiert zu haben. Die aktuellen Copilots und Code-Assistenten sind Chatbots und MCP Hosts in einem. Nach Installation z.B. des GIT Copilots und danach eines aktuellen SQL Developer Plugins registriert sich dieses beim MCP Host und kann von beliebigen LLMs benutzt werden.
Der GIT copilot verwendet zunächst öffentliche LLMs im ChatGPT Dienst, kann aber umkonfiguriert werden auf einen lokalen ollama.

und tragen Sie dort die URL Ihres möglichst aktuellen ollama inference server ein.
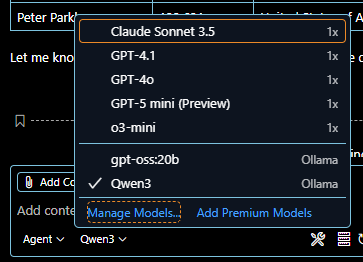

dann wählen Sie den Ollama Server-Typ aus
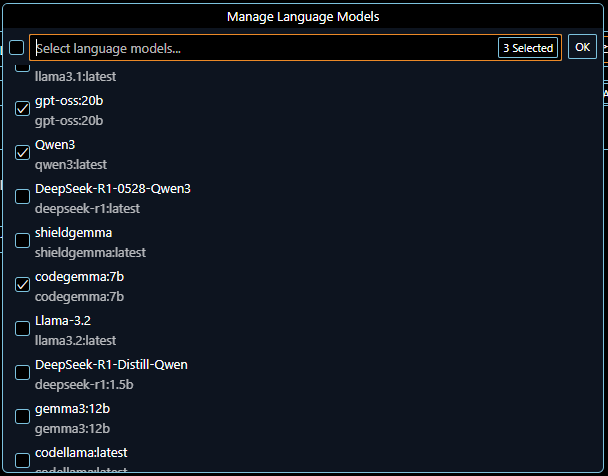
Auf Seiten des inference server (also ollama in diesem Beispiel) ist es wichtig, dass ein LLM eingebunden wird welches die Eingangs beschriebene Tools API versteht. Aktuelle LLMs wie das weiter oben verwendete qwen3 oder das brandneue gpt-oss bieten tools, mixture-of experts, reasoning und noch einige Dinge mehr an. Aus diesem Grund ist es auch wichtig, eine sehr aktuelle Version des ollama inference servers zu verwenden (mindestens 0.11.4), denn die Assistenten fragen mittlerweile die angebundenen Inference Server nach den verfügbaren Features der geladenen LLMs ab. Ganz konkret: man kann beliebige LLMs in ollama einbinden und mit ihnen auch per Chat interface im Code Assistenten kommunizieren. Aber wenn statt simplem “ask” die “agent” basierte Kommunikation ausgewählt wird kann man nur noch die LLMs mit Tools-Unterstützung sehen und auswählen.
die Tools-Support anbieten. In meinem Fall gpt-oss und qwen3. Letzteres ist deutlich kleiner und schneller als gpt,
aber nicht ganz so umfassend mitdenkend. Dafür bietet es schön aufbereitete Ergebnisse
mit Syntax highlighting und Tabellendarstellung.
Viel Spaß beim Ausprobieren !
Andere Code Assistenten wie z.B. “cline” erlauben es, beliebige inference server einzubinden weswegen es für ihn auch Beispiele gibt zur Oracle OCI GenAI und einige andere. Dort ist der Oracle MCP Server bzw. “sqlcl” mit seinem Pfad und Parameter “-mcp” zunächst in einer Konfiguration einzutragen um ihn zu verwenden. Der Git Copilot führt hingegen ein auto discovery aller MCP server im Systempfad durch, wenn er startet.
Zusammenfassung und Ausblick
Prinzipiell lassen sich alle Operationen einer Oracle Database, die mit LLMs und KIs zu tun haben, auf lokalen inference servern wie ollama und vLLM ausführen. Dies wird -inzwischen- offiziell unterstützt und ist dokumentiert. Wählt man als Provider eines LLMs die “database” aus , können Aufgaben auch direkt in der Datenbank auf CPU ausgeführt werden. Dies sollten vorzugsweise sporadische Aufgaben sein oder Operationen auf kleineren Datenmengen und mit möglichst kleinen LLMs. Zum Beispiel Trigger-gesteuerte Einzel-Operationen.
In nächster Zeit dürfen wir einige Ankündigungen im Umfeld der Oracle Database und KI erwarten, es stehen weitere Pakete und Bündel aus freier Software an um die Oracle Database noch näher mit (lokalen) KIs zu verknüpfen, Agenten und GUIs “hybrid” zu entwickeln und zu betreiben, sprich lokal und in beliebigen Clouds.
Und letztlich – wie immer – viel Spaß beim Testen und Ausprobieren !
Einige interessante Links
Jupyter Notebooks mit beinahe allen Beispielen zu diesem Blog auf github
Artikel: Small Language Models are the future of agentic AI
Jeff Smith: KI gestützt REACT Anwendungen bauen mit VSCode, Oracle MCP und Claude
Jeff Smith: einen eigenen MCP Server bauen mit ORDS REST Services und OpenAPI (und mit support des Grok LLM)
Oracle AI Optimizer Toolkit auf github
Eine etwas ältere aber große Liste von OpenSource LLMs, die man auch kommerziell nutzen darf, auf github.
Eine recht aktuelle Erklärung zu Mixture-of-Experts und Dense LLMs von Maximilian Schwarzmüller
Drei freie Oracle Komponenten, die demnächst neue Bundlings und AI Erweiterungen erwarten dürfen:
Oracle Backend for Microservices and AI – Version 1.4 vom Juli 2025 (aktuell Spring AI und ollama support)
Oracle Operator for Oracle Databases – noch Version 1.2 vom April 2025, Version 2.0 anstehend
Oracle Helidon, der freie Java Microservice Framework, noch Version 4.2 und ab Version 4.3 ein Java MCP Host