
What can you do if you don’t want to or aren’t allowed to transfer your data to cloud-based AI? Simple: you bring the AI into your own data center at the lowest possible cost. I would like to highlight some current standard methods for connecting large language models (LLMs) to an Oracle database. I would also like to describe some special-purpose large language models and which of the methods are compatible with version 19c.
A few months ago, I briefly outlined how to connect an Oracle Database 23ai Free Edition with local AI for testing and development purposes. With careful selection and attention to the license type, the underlying large language models can also be used productively, not just for testing. The environment described in the article served the purpose of making uploaded documents searchable so that they could serve as a knowledge base for the AI and be queried in a chat interface. The method known as “retrieval augmented generation,” or RAG for short, which was widely emphasized at the time, still provides the basis for enriching AI with local and private knowledge from unstructured and structured data on the fly, without having to create your own large language model with your own data in it.
Meanwhile, the development of large language models has continued, and they can now also be used more comprehensively and complexly locally: the topics of tool support, agents and Model Context Protocol (MCP), as well as mixture of experts and —very importantly— ever-larger supported context window sizes have also found their way into the APIs and tools surrounding the Oracle Database, which is why I would like to briefly describe each of them.
First of all, I would like to apologize for the exceptionally long blog post! Perhaps you won’t read the entire thing, but instead pick out the chapters that interest you most first:
Current LLM features, especially for local use
- Much space, much compute power?
- Saving space, increasing performance
- Distributing space and balancing workload
- Fast Mini-Experts
- Quick category thinkers
- Don’t talk, just do it – data formats, tools, agents, and MCP
Features of an Oracle Database that can use a local LLM (in a supported way)
- SELECT AI / DBMS_CLOUD_AI (Database 19c and 26ai)
- UTL_HTTP and JSON_OBJECT_T (Database 19c and 26ai)
- Vector Store / Vector Search or DBMS_VECTOR / DBMS_VECTOR_CHAIN (Database 26ai)
- Application Express Runtime and Design Time (Database 19c and 26ai)
- MCP Server for Oracle Database (Database 19c and 26ai)
Summary and outlook
Some interesting Links
Now and here, let the feast begin:
Current LLM features, especially for local use
Much space, much compute power?
If you want to run a large language model (LLM) locally or in close proximity to your own servers and databases, the primary considerations are storage requirements, performance, and acceptable quality of results. Large language models operated in cloud environments are usually all-rounders that perform their now numerous tasks as well as possible, which is why they require a considerable amount of GPU main memory and powerful GPUs with many computing cores. Such LLMs are usually based on several hundred billion parameters (200B, 400B, 600B, etc.) and currently consume up to 400GB of expensive GPU memory per instance just to operate. Added to this are numerous context windows, which are memory areas for the currently running queries of end users and agents with their respective chat history and context information, which are incorporated into ever-larger prompts via the RAG mechanism. This is really not necessary for local, non-generic use on this scale!
Saving space, increasing performance
Initially, strategies were developed to redesign large language models for operation on weaker GPU systems so that they require less space. Quantization reduces the accuracy of the parameters or vectors in the LLMs, greatly increases the processing speed, and also significantly reduces the space requirements. However, the results are no longer as sophisticated or intelligent as before, but they are still significantly better than LLMs with a correspondingly lower number of parameters. Whereas vectors and parameters were originally represented as precisely as possible with 64-bit floating point numbers, nowadays only 32-bit, 16-bit, and even 4-bit floating point numbers are commonly used and offered for download. The gpt-oss LLM released in the summer of 2025, for example, was subjected to a 4.25-bit (approx.) quantization method (MXFP4).
Distributing space and balancing workload


 Current inference servers, i.e., programs that manage, load, and execute LLMs, are capable of distributing large LLMs across multiple local GPU devices. Unfortunately, this does not provide any performance benefits through parallelization, but it drastically reduces the disadvantage of having to gradually pass an overly large LLM from disk through GPU memory. GPU manufacturer nvidia offers a network/infiniband/RDMA-compatible feature called nvlink for its large solutions to make the already large GPUs even larger, so to speak. Conversely, several smaller LLMs can also be loaded and operated simultaneously, or several inference servers can be used, each with its own smaller GPU, and coordinated via a load balancer. For the sake of completeness, it should be mentioned that the Oracle Database supports access to various (HuggingFace tgi, vLLM/triton, ollama) local inference servers either directly or via an OpenAI-compatible REST API, which is usually already available. Oracle recently announced upcoming availability of a “private AI container” with some pre-loaded LLMs and the possibility to run other LLMs through a portable file format called “ONNX”.
Current inference servers, i.e., programs that manage, load, and execute LLMs, are capable of distributing large LLMs across multiple local GPU devices. Unfortunately, this does not provide any performance benefits through parallelization, but it drastically reduces the disadvantage of having to gradually pass an overly large LLM from disk through GPU memory. GPU manufacturer nvidia offers a network/infiniband/RDMA-compatible feature called nvlink for its large solutions to make the already large GPUs even larger, so to speak. Conversely, several smaller LLMs can also be loaded and operated simultaneously, or several inference servers can be used, each with its own smaller GPU, and coordinated via a load balancer. For the sake of completeness, it should be mentioned that the Oracle Database supports access to various (HuggingFace tgi, vLLM/triton, ollama) local inference servers either directly or via an OpenAI-compatible REST API, which is usually already available. Oracle recently announced upcoming availability of a “private AI container” with some pre-loaded LLMs and the possibility to run other LLMs through a portable file format called “ONNX”.
Fast Mini-Experts
![]()
![]()
![]() Parallel to quantization, it was decided to specialize large language models and train them only for specific purposes. This resulted in significantly smaller and faster LLMs. Such small experts (affectionately referred to as “nerds” by me) are particularly well suited for general but less in-depth chatting in multiple languages, generating program code (including SQL, of course), summarizing texts, describing images, or even just generating vectors from texts (creating embeddings) to compare them with other vectors, e.g., those resulting from search queries. With around 7-12 billion parameters and approximately 5-10 GB of memory requirements, the smaller expert models deliver very good, albeit deliberately one-sided, results. For development purposes or particularly specific requirements, the same expert LLMs are available in even smaller versions, although below 3 billion parameters I could only expect the simplest answers or less complex decisions or categorizations. However, this felt lightning fast, and there are certainly use cases for this as well.
Parallel to quantization, it was decided to specialize large language models and train them only for specific purposes. This resulted in significantly smaller and faster LLMs. Such small experts (affectionately referred to as “nerds” by me) are particularly well suited for general but less in-depth chatting in multiple languages, generating program code (including SQL, of course), summarizing texts, describing images, or even just generating vectors from texts (creating embeddings) to compare them with other vectors, e.g., those resulting from search queries. With around 7-12 billion parameters and approximately 5-10 GB of memory requirements, the smaller expert models deliver very good, albeit deliberately one-sided, results. For development purposes or particularly specific requirements, the same expert LLMs are available in even smaller versions, although below 3 billion parameters I could only expect the simplest answers or less complex decisions or categorizations. However, this felt lightning fast, and there are certainly use cases for this as well.
Examples:
qwen3 (Alibaba OpenSource LLM) is available for download in variants of 0.6 , 1.7, 4, 8, 14, 30 and 235 Billion parameters.
gemma3 (OpenSource Variant of Google Gemini) is available for download in variants of 1, 4, 12, 27 and 270 Billion parameters.
deepseek-r1 (OpenSource Model of deepseek research lab) is available for download in variants of 1.5, 7, 8, 14, 32, 70 and 671 Billion parameters.
phi3 (OpenSource Model of Microsoft) is available for download in variants of 3.8 und 14 Billion parameters, phi4 only with14 Billion parameters.
Individual expert LLMs can be downloaded separately, e.g., codegemma, shieldgemma, qwen2.5-math, deepseek-coder, etc., some of which have multiple capabilities such as vision, reasoning, coding, mathematics, etc.
Quick category thinkers
In the meantime, the trend has shifted toward offering the most frequently recurring areas of application with their specific expert LLMs in a single package. This has given rise to mixture-of-experts LLMs. In this case, a small generic subarea of the LLM often decides which expert subarea is best suited to handle the task at hand and pulls it in. The advantage: even if the entire LLM is too large for the GPU, the most frequently used sub-experts (specialists…) can remain in the main memory, so the entire LLM does not have to be sent through the memory for every request. The LLMs and their files have now become larger again, but that doesn’t matter so much anymore. However, if you have the option to decide for yourself which expert LLM to use, then you should do so! If the use cases are already defined, it is still faster to assign an LLM directly than to first query the one that will ultimately be used. Speaking of querying and using – a good transition to tool support, agents, and MCP. Because that’s exactly what they do, which is what I just warned against. The convenience and possibilities are enormous.
Quick Examples:
- A good description of the architecture of mixture-of-experts LLMs can be found in a German heise media article about the new Chinese GLM-4.5.
- The GPT LLM from OpenAI, known from ChatGPT, was recently made available for download under an open source license and streamlined as gpt-oss. gpt-oss also comprises several expert LLMs based on the same principle. A more detailed description of gpt-oss can be found in OpenAI’s announcement blog.
- A very high-quality LLM in a wide range of sizes is qwen3, produced by Alibaba. Not only does the different number of parameters influence the sizes, but also the possible choice between a complete mixture-of-experts LLM and several dense LLMs, i.e., individual experts.
Don’t talk, just do it – data formats, tools, agents, and MCP
In the early days, prompts were as precise as possible, i.e., instructions to the AI on how it should behave and in what form it should respond. General instructions were transferred in the system prompt as soon as the LLM was loaded, and they could also be overwritten or supplemented by prompts marked as such in the queries and chat histories. Good prompts reduce AI hallucinations, for example. If there is a lack of information and context to answer a question, the AI should not draw its own conclusions and possibly present them as facts. Prompts were soon formulated to return results and decisions in a structured form, as a CSV list, XML, or JSON document. This often worked best by providing an example of the desired result structure.
An example of a prompt or call to an LLM that describes the desired result format using a sample structure. Simply send it via POST operation to an inference server of your choice and the URI /api/chat (ollama API) or /v1/chat/completions (OpenAI compatible API).
{"model": "llama3.2:1b","messages": [
{"role": "system", "content": "Which 5 keywords would You use in a google search to find best answers to the user's question?
Please respond with a JSON that best answers the given prompt.
Respond in the format {"keywords":[{keywords chosen}]}.
Do not use variables."},
{"role": "user", "content": "can men get breast cancer too ?" }
],
"stream": False, "options": {"use_mmap": True,"use_mlock": True,"num_thread": 8}}
A possible, structured result of the call (excerpt):
{
"model": "llama3.2:1b",
"message": {
"role": "assistant",
"content": "{\"keywords\":[\"male breast cancer\",\"common types of breast cancer\",\"causes of breast cancer in men\",\"statistics on male breast cancer\"]}"
},
...
This type of prompt was probably used frequently, as a standard syntax was soon incorporated into common LLMs, allowing data structures to be specified that the LLM could fill in response to a query. The “Format API” was born, and its successor was not long in coming.
An example of a prompt that uses the Format API to describe data structures:
{
"model": "llama3.1",
"messages": [{"role": "user", "content": "Tell me about Canada."}],
"stream": False,
"format": {
"type": "object",
"properties": {
"name": {
"type": "string"
},
"capital": {
"type": "string"
},
"languages": {
"type": "array",
"items": {
"type": "string"
}
}
},
"required": [
"name",
"capital",
"languages"
]
}
}
A possible result of the call (excerpt). The LLM fills in the data fields, so to speak, to the best of its knowledge and belief:
{
"model": "llama3.1",
"message": {
"role": "assistant",
"content": "{ \"name\": \"Canada\" , \"capital\": \"Ottawa\" , \"languages\": [\"English\", \"French\"] }"
},
...
Very soon, another standard syntax was incorporated into the common LLMs—and, necessarily, into the operating inference servers as well. Instead of just formulating data structures, function definitions and descriptions can now be transferred. If the LLM cannot answer a question itself with certainty because it lacks context, it selects the most suitable function from a list of available functions. It is supposed to provide the data that matches the query. The LLM fills in all the necessary parameters for the function call as best it can and returns the call structure as the result, rather than the actual result. This is roughly how the “Tools API” works. The program that made the request to the LLM can respond to the result structure and actually execute the functions suggested by the LLM. The result of the function calls can then be passed back to the LLM (or another one!), ideally together with the previous chat and call history, and then the original request is actually answered.
An example of a prompt that uses the Tools API and describes the available functions in an explanatory manner. Based on the end user’s request, the LLM decides whether it can answer it itself or which function should be called to establish the necessary context, i.e., to obtain the required data.
{"model": "llama3.1:latest",
"messages": [
{"role": "system", "content": "User birth date: January 20th, 1973."},
{"role": "user", "content": "Wie ist das Wetter in Aachen ?"}
],
"tools" : [
{ "type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
},
},
"required": ["location"],
},
}
},
{"type": "function",
"function": {
"name": "get_random_joke",
"description": "Get a random joke",
"parameters": {
"type": "object",
"properties": {},
"required": [],
},
}}
],
"stream": False, "options": {"use_mmap": True,"use_mlock": True,"num_thread": 8, "temperature": 0}}
So, if, as in this example, the context provided (the end user’s date of birth) is not sufficient to answer the question (“What is the weather like in Aachen?”), the LLM fills in the parameters of the most likely function and returns the call syntax. The LLM is quite good at deciding whether to tell us a joke or retrieve the current weather in Aachen.
{
"model": "llama3.1:latest",
"created_at": "2025-08-05T13:02:28.69570032Z",
"message": {
"role": "assistant",
"content": "",
"tool_calls": [
{
"function": {
"name": "get_current_weather",
"arguments": {
"location": "Aachen, Germany",
"unit": "celsius"
}
}
}
]
},
........
The code or program that sent the original prompt could then actually execute the real existing function at the request of the LLM. Furthermore, the result of the function call is simply appended to the existing JSON document and passed back to the LLM, which would then formulate the final response from the context information.
This has led to the creation of agents that ensure that a lot happens between a seemingly innocuous chat request and the AI response, often in several iterations. Agents are essentially programs and entire workflows that, at the request of the AI, gather data from various sources such as relational databases, web content, etc., and may also format, validate, or summarize it. Of course, such agents can also be programmed or formulated directly in an Oracle database in PL/SQL, Java, or APEX, where the necessary data is already available. It doesn’t always have to be Python, but that is also supported by Oracle with state-of-the-art drivers and API plugins, e.g., for the LangChain and LlamaIndex frameworks. The original ancestors BPEL, Service Bus, and BPMN are probably left out here and have their raison d’être in other, more classic areas.

Further explanations can be found in the blog “Standardizing AI Tooling with MCP”
by Suman Debnath, a more detailed one about the Oracle MCP server follows further down here.
And yet, there is now a small, local event-streaming-based middleware for registering and coordinating agents and tools: MCP hosts. In order to use the Tools API explained above in a standardized way, register new tools (and thus agents), and execute them, inference servers and various data pools now have communication servers at their disposal that can do more than just chat. A chatbot no longer communicates exclusively with an LLM or inference server, but instead actively exchanges information with an MCP host as an MCP client. The host enriches a chat request with available tools, executes tools immediately if necessary (calling the MCP server programs behind the tool definitions), and returns the results to the chatbot. The history and tool results are sent in a package to the inference server in order to obtain the best possible final answer. I would like to recall the topic of context window size explained above, because more space is gradually becoming increasingly urgent.
Many of the previous AI features of an Oracle Database did not require an MCP server or tool support. In most cases, proper prompts and complete contexts were transferred to the AI in single-turn calls and via RAG, for example, table metadata, comments, and very strict system instructions. However, extensions that support MCP are now also being released in direct connection with the Oracle Database. Entire (free) software packages and partial solutions from Oracle Database, inference servers, and MCP hosts are in preparation and will be presented soon.
Features of an Oracle Database that can use a local LLM (in a supported way)
-
SELECT AI / DBMS_CLOUD_AI (Database 19c and 26ai)
-
UTL_HTTP and JSON_OBJECT_T (Database 19c and 26ai)
-
Vector Store / Vector Search or DBMS_VECTOR / DBMS_VECTOR_CHAIN (Database 23ai)
-
Application Express Runtime and Design Time (Database 19c and 26ai)
-
MCP Server for Oracle Database (Database 19c and 26ai)
SELECT AI / DBMS_CLOUD_AI (Database 19c and 26ai)
Generate SQL commands that match the database structure using AI and execute them immediately, directly within the Oracle database. This feature was initially only available in autonomous databases, but can now also be installed and used in Oracle Database Version 19c in the form of a PL/SQL package called DBMS_CLOUD_AI. Support Note 2748362.1 and a blog entry on oracle-base.com explain how this works.
To use a non-cloud LLM with DBMS_CLOUD_AI, an access profile must first be stored in the database. This structure contains the access data for a local inference server and specifies which database objects should be made known to the LLM so that the LLM can refer to them. An example of the configuration for accessing an Ollama inference server could look like this:
-- allow network access of demo-user SH towards ollama server
BEGIN
DBMS_NETWORK_ACL_ADMIN.APPEND_HOST_ACE(
host => 'ollama.meinnetzwerk.com',
ace => xs$ace_type(privilege_list => xs$name_list('http'),
principal_name => 'SH',
principal_type => xs_acl.ptype_db)
);
END;
-- Dummy Credentials in case of unprotected access to the inference server
BEGIN
DBMS_CLOUD.CREATE_CREDENTIAL(
credential_name => 'OLLAMA_CRED',
username => 'OLLAMA',
password => 'OLLAMA'
);
END;
-- define access profile - what is allowed, what LLM to use in ollama
-- you can give schema names instead of a list of tables
-- the LLM to be used is called "codegemma:7b" and can create program code like SQL very well.
BEGIN
DBMS_CLOUD_AI.CREATE_PROFILE(
profile_name =>'OLLAMA',
attributes =>'{
"credential_name": "ollama_cred",
"comments": true,
"constraints": true,
"annotations": true,
"enforce_object_list": true,
"object_list": [{"owner": "SH", "name": "customers"},
{"owner": "SH", "name": "countries"},
{"owner": "SH", "name": "supplementary_demographics"},
{"owner": "SH", "name": "profits"},
{"owner": "SH", "name": "promotions"},
{"owner": "SH", "name": "sales"},
{"owner": "SH", "name": "products"}],
"model" : "codegemma:7b",
"provider_endpoint": "ollama.meinnetzwerk.com",
"conversation" : "true"
}');
END;
A quick warning before we begin: the DBMS_CLOUD_AI package is also undergoing continuous development. The parameter “provider_endpoint” used here for integrating any inference server via its OpenAI-compatible REST API was NOT yet known in the package for “non-autonomous” Database 19c and 26ai in October 2025. If you encounter any insurmountable problems here, I recommend trying the new MCP Server for Oracle Database instead of DBMS_CLOUD_AI. This problem should be solved as soon as the recently announced “private AI container” becomes available though.
The configuration of the ollama inference server is not described in detail here. But please do not forget to load the LLM codegemma:7b into the ollama server with an “ollama pull codegemma:7b” before you use or call it.
Once a profile has been defined, you can activate it and make various calls to your AI. When the profile is activated, the metadata of the available objects is compiled and stored in the database so that a call to the LLM receives a predefined prompt with instructions and all table descriptions. Activation and test calls could then look as follows:
-- activate the profile
BEGIN
DBMS_CLOUD_AI.SET_PROFILE('OLLAMA');
END;
-- very unprecise question to the LLM, can it handle that ?
SELECT DBMS_CLOUD_AI.GENERATE(prompt => 'how many customers',
profile_name => 'OLLAMA',
action => 'runsql') result
FROM dual;
RESULT
==================================
[{ "TOTAL_CUSTOMERS" : 55500 }]
-- Instead of executing the SQL directly, display the generated SQL.
SELECT DBMS_CLOUD_AI.GENERATE(prompt => 'how many customers',
profile_name => 'OLLAMA',
action => 'explainsql') explain
FROM dual;
EXPLAIN
==================================
sql
SELECT COUNT(*) AS total_customers
FROM SH.CUSTOMERS;
-- chatting with the LLM in general instead of generating SQLs
SELECT DBMS_CLOUD_AI.GENERATE(prompt => 'what is oracle autonomous database',
profile_name => 'OLLAMA',
action => 'chat') chat
FROM dual;
CHAT
===================================
**Oracle Autonomous Database**
Oracle Autonomous Database is a cloud-based, fully managed database service that eliminates the need for manual database administration. It is a self-service, pay-as-you-go database that provides a secure, scalable, and high-performance environment for applications.
-- little more complex enquiry
SELECT DBMS_CLOUD_AI.GENERATE(prompt => 'which 10 customers have spent the most money ? please also show the country name for each customer.',
profile_name => 'OLLAMA',
action => 'showsql') sql
FROM dual;
SQL
===================================
SELECT c.CUST_FIRST_NAME || ' ' || c.CUST_LAST_NAME AS customer_name,
SUM(s.AMOUNT_SOLD) AS total_spent,
co.COUNTRY_NAME
FROM SH.CUSTOMERS c
JOIN SH.SALES s ON c.CUST_ID = s.CUST_ID
JOIN SH.COUNTRIES co ON c.COUNTRY_ID = co.COUNTRY_ID
GROUP BY c.CUST_FIRST_NAME, c.CUST_LAST_NAME, co.COUNTRY_NAME
ORDER BY total_spent DESC
FETCH FIRST 10 ROWS ONLY
The beauty of a local inference server is that it makes it easier to gain insight into the data that has been sent to the LLM through the ether. The last question formulated in the example is “which 10 customers have spent the most money? Please also show the country name for each customer.” The prompt generated by the database contains much more detail than just the actual question. Namely, it also includes a context framework in the form of numerous metadata and very precise instructions on how to determine and format the result. In principle, this is the whole secret behind the term RAG, retrieval augmented generation: you tell the AI what to talk about and what it is allowed to know in connection with the query. This knowledge was pre-filtered and processed as efficiently as possible before the query was sent to the LLM, with only the most necessary information being reproduced. Here’s a perhaps odd example: I don’t always give the LLM the entire Bible to work with, but only relevant verses. The example is odd because common LLMs actually already contain the Bible as a knowledge base for their general knowledge…
Due to its size, only an excerpt of the prompt listed below is shown here. It should also be noted that the LLM used supports a sufficiently large context window. The more metadata, comments, and annotations there are, the better the AI’s understanding of the data model and the better the result. Unfortunately, this also slows down the call to the LLM…
### Your task is to ALWAYS answer queries using ONLY the available tables provided in the context, no other tables and Oracle system views. If the context does not provide the necessary tables, respond by explaining the reason. Available Oracle SQL tables provided: --'facts table, without a primary key; all rows are uniquely identified by the combination of all foreign keys' # CREATE TABLE \"SH\".\"SALES\" (\"PROD_ID\" NUMBER 'FK to the products dimension ...... ................ --'dimension table' # CREATE TABLE \"SH\".\"CUSTOMERS\" (\"CUST_ID\" NUMBER 'primary key' , \"CUST_VALID\" VARCHAR2(1) , \"CUST_EFF_TO\" DATE , \"CUST_EFF_FROM\" DATE , \"CUST_SRC_ID\" NUMBER , \"CUST_TOTAL_ID\" NUMBER , \"CUST_TOTAL\" VARCHAR2(14) , \"CUST_EMAIL\" VARCHAR2(50) 'customer email id' , \"CUST_CREDIT_LIMIT\" NUMBER 'customer credit limit' , \"CUST_INCOME_LEVEL\" VARCHAR2(30) 'customer income level' , \"CUST_MAIN_PHONE_NUMBER\" VARCHAR2(25) 'customer main phone number' , \"COUNTRY_ID\" NUMBER 'foreign key to the countries table (snowflake)' , \"CUST_STATE_PROVINCE_ID\" NUMBER , \"CUST_STATE_PROVINCE\" VARCHAR2(40) 'customer geography: state or province' , \"CUST_CITY_ID\" NUMBER , \"CUST_CITY\" VARCHAR2(30) 'city where the customer lives' , \"CUST_POSTAL_CODE\" VARCHAR2(10) 'postal code of the customer' , \"CUST_STREET_ADDRESS\" VARCHAR2(40) 'customer street address' , \"CUST_MARITAL_STATUS\" VARCHAR2(20) 'customer marital status; low cardinality attribute' , \"CUST_YEAR_OF_BIRTH\" NUMBER(4,0) 'customer year of birth' , \"CUST_GENDER\" CHAR(1) 'gender; low cardinality attribute' , \"CUST_LAST_NAME\" VARCHAR2(40) 'last name of the customer' , \"CUST_FIRST_NAME\" VARCHAR2(20) 'first name of the customer') --'dimension table without a PK-FK relationship with the facts table, to show outer join functionality' # CREATE TABLE \"SH\".\"PROMOTIONS\" (\"PROMO_ID\" NUMBER(6,0) 'primary key column table' , \"AMOUNT_SOLD\" NUMBER(10,2) 'invoiced amount to the customer' , \"QUANTITY_SOLD\" NUMBER(10,2) 'product quantity sold with the transaction' , \"PROMO_ID\" NUMBER 'promotion identifier, without FK constraint (intentionally) to show outer join optimization' , \"CHANNEL_ID\" NUMBER 'FK to the channels dimension table' , \"TIME_ID\" DATE 'FK to the times dimension table' , \"CUST_ID\" NUMBER 'FK to the customers dimension table') ................... Given an input Question, create a syntactically correct Oracle SQL query to run. Pretty print the SQL query. - Pay attention to using only the column names that you can see in the schema description. - Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table. - Please double check that the SQL query you generate is valid for Oracle Database. - Consider table name, schema name and column name to be case sensitive and enclose in double quotes. - Only use the tables listed below. - If the table definition includes the table owner, you should include both the owner name and user-qualified table name in the Oracle SQL. - DO NOT keep empty lines in the middle of the Oracle SQL. - DO NOT write anything else except the Oracle SQL. - Always use table alias and easy to read column aliases. For string comparisons in WHERE clause, CAREFULLY check if any string in the question is in DOUBLE QUOTES, and follow the rules: - If a string is in DOUBLE QUOTES, use case SENSITIVE comparisons with NO UPPER() function. - If a string is not in DOUBLE QUOTES, use case INSENSITIVE comparisons by using UPPER() function around both operands of the string comparison. Note: These rules apply strictly to string comparisons in the WHERE clause and do not affect column names, table names, or other query components. Question: which 10 customers have spent the most money ? please also show the country name for each customer.
UTL_HTTP and JSON_OBJECT_T (Database 19c and 26ai)
Convenient features such as those in DBMS_CLOUD_AI manage LLM access and automatically generate comprehensive prompts for database-related queries. This convenience may not always be desirable, and you may want to instruct the AI yourself to generate structured data or answer questions about data in your database. In that case, you can also formulate the calls completely freely, because the underlying REST API of common inference servers is disclosed and documented; you just need to work more with JSON documents and data structures. In some cases, the Oracle database documentation refers to the use of UTL_HTTP packages and the JSON data type, for example, if REST APIs that are not directly supported are to be used. Here is a small example of a direct call —with simplified, hard-coded RAG— to a local LLM, without further ado:
-- allow network acces of user SH to the ollama server
BEGIN
DBMS_NETWORK_ACL_ADMIN.APPEND_HOST_ACE(
host => 'ollama.meinnetzwerk.com',
ace => xs$ace_type(privilege_list => xs$name_list('http'),
principal_name => 'SH',
principal_type => xs_acl.ptype_db)
);
END;
-- Please define the following function or procedure as an SH user. It calls an LLM and allows a user request.
-- The knowledge base for answering the query is passed in the prompt, hard-coded here for readability.
-- The JSON syntax used is typical for chat interfaces on inference servers such as OpenAI, Ollama, and others.
CREATE OR REPLACE FUNCTION rag_with_genai_function( rag_question in varchar2) return varchar2
AS
l_url VARCHAR2(400) := 'https://ollama.meinnetzwerk.com/api/chat';
req utl_http.req;
resp utl_http.resp;
body VARCHAR2(4000);
buffer VARCHAR2(8192);
BEGIN
-- Define the right prompt: how to respond and how closely the AI should adhere to the knowledge base.
-- The LLM to be used—llama3.1:latest—is generic, small, and fast.
-- System instructions come in the “system” role, user requests in the “user” role.
body := '{"model": "llama3.1:latest","messages": [{"role": "system", "content": " '||
'Your answers should begin with the phrase ''According to the information found in my database''.' ||
'Please answer the following question only with information given in the provided DOCUMENTS"} ,' ||
-- The knowledge base could consist of data from relational tables or document fragments found via full-text search.
-- Hard-coded here for brevity
'{"role": "system", "content": "DOCUMENTS: It has been proven that men can get breast cancer too "} , ' ||
'{"role": "system", "content": "DOCUMENTS: Male breast cancer is very rare "} , ' ||
-- Here, the end user question is inserted into the prompt.
'{"role": "user", "content": "'|| rag_question ||'"}],' ||
-- Tuning parameters on the inference server; for the time being, it is essential to refrain from streaming in order to obtain a complete response.
'"stream": false, "options": {"use_mmap": true,"use_mlock": true,"num_thread": 8}}';
-- Databases sometimes need to access the internet via proxies, but this is not usually the case with a local LLM.
-- Therefore, this has been commented out.
-- utl_http.set_proxy('http://username:passwd@192.168.22.33:5678');
-- the HTTP request is constructed here
req := utl_http.begin_request(l_url, 'POST', 'HTTP/1.1');
utl_http.set_header(req, 'Accept', '*/*');
utl_http.set_header(req, 'Content-Type', 'application/json');
utl_http.set_header(req, 'Content-Length', length(body));
utl_http.write_text(req, body);
-- now the inference server is called and the result is retrieved
resp := utl_http.get_response(req);
BEGIN
utl_http.read_text(resp, buffer);
EXCEPTION
WHEN utl_http.end_of_body THEN
utl_http.end_response(resp);
END;
buffer := json_value (buffer, '$.message.content' returning varchar2);
return (buffer);
END;
Calling the function with a question that matches the transferred knowledge base should result in a concise answer from the LLM:
-- run as user SH please
select rag_with_genai('can men get breast cancer too?') as answer from dual;
ANSWER
============================
According to the information found in my database, yes, men can get breast cancer. However, it is considered relatively rare compared to breast cancer in women.
Vector Store / Vector Search bzw. DBMS_VECTOR / DBMS_VECTOR_CHAIN (Database 26ai)
The actual storage, indexing, and searching of vectorized data is done using proprietary means; no LLM is used for this purpose. However, database functions from the DBMS_VECTOR and DBMS_VECTOR_CHAIN packages can be used to calculate vectors from data, for example from text fragments, and then store them. The process of calculating vectors from arbitrary data using an LLM is also called embedding generation. Similarly, a search query formulated as text should be converted into vectors so that it can be compared with existing vectors in the database. The DBMS_VECTOR package can also be used for this purpose.
The functions contained in the respective packages for generating embeddings (TO_EMBEDDING or TO_EMBEDDINGS, depending on whether individual values or arrays are transferred) can be parameterized in such a way that they either use an LLM loaded into the database to generate embeddings or transfer the data to a separate inference server to calculate embeddings. The LLMs within the database perform their operations on the local CPU, preferably in parallel if possible, and the separate inference servers presumably have access to GPUs.
Interestingly, the network round trips for external calls to inference servers take a significant amount of time. Without batching operations, e.g., by transferring entire data arrays instead of individual values, the results of calculations on smaller data sets (search queries, individual table columns, individual text chunks) would be faster on the local CPU and without network access than on the GPU in the (local) network.
This technique works particularly well when the generation of embeddings is entrusted to very small LLMs that exist solely for the purpose of generating embeddings. Classical sentence-transformer LLMs are used to calculate embeddings from texts. Such LLMs are only a few hundred megabytes in size, rather than gigabytes like the more comprehensive text generator experts. Why not try it yourself and see the difference!
Experiment 1:
Local in-Database LLM – load and create embedding
First, download a sentence transformer LLM from huggingface, for example nomic-embed-text-v1.5, in ONNX (open neural network exchange) format.
Then we load the file into the database and generate an embedding, locally on the CPU and without a network:
BEGIN
-- the database now knows directory /tmp and names it MODEL_DIR
-- thats where the downloaded ONNX file should be too
CREATE OR REPLACE DIRECTORY MODEL_DIR AS '/tmp';
-- Was the ONNX file downloaded as name "model.onnx" ?
-- Please adapt if appropriate
DBMS_VECTOR.LOAD_ONNX_MODEL(
'MODEL_DIR',
'model.onnx',
'nomic_model',
JSON('{"function":"embedding","embeddingOutput":"embedding","input":{"input": ["DATA"]}}')
);
END;
SELECT TO_VECTOR(VECTOR_EMBEDDING(nomic_model USING 'can men get breast cancer too' AS DATA)) as VECTOR_DATA from dual;
VECTOR_DATA
=======================================
[-1.78362778E-003,-2.63432469E-002,9.18012578E-003,7.73889478E-003,2.33698897E-0
02,-3.50732245E-002,1.72414538E-002,-2.08509713E-003,-1.78824551E-002,1.553251E-
001,-6.05734661E-002,3.72434705E-002,-8.30145925E-003,3.46281789E-002,6.17512912
E-002,1.59628168E-002,4.11528721E-002,-4.06850036E-003,-3.26767527E-002,3.306468
2E-002,1.62407178E-002,-6.36792406E-002,-7.9902567E-002,-6.57038093E-002,-5.2594
0545E-002,-8.08598101E-002,1.15027493E-002,-1.02846622E-002,3.99888493E-002,-7.6
2334326E-003,-7.13080391E-002,6.25135154E-002,-6.12752996E-002,-5.82841132E-003,
5.41676134E-002,-3.1681329E-002,-2.57817637E-002,1.22085335E-002,1.16529651E-001
,-3.23723853E-002,2.40268558E-002,-3.10333222E-002,-3.51821259E-002,6.46591336E-
002,8.10852274E-002,-1.8553853E-002,-9.99582652E-003,-7.44895916E-003,-2.5479279
5E-002,-5.58673963E-002,2.54160687E-002,-9.53436568E-002,2.905301E-002,3.8869246
..........
Experiment 2:
Local LLM on separate inference server – load and create embedding
First, please load the LLM into your inference server, for example with
ollama pull nomic-embed-text:v1.5
Then configure the call to the ollama inference server from the database and transfer the data to be calculated there:
-- in sqlplus, activate dbms_output.put_line visible outputs
SET SERVEROUTPUT ON
-- Instead of concatenating texts, JSON_OBJECT_T could also be used.
-- and fill and convert with PUT statements or TO_STRING.
-- Then the tedious counting of parentheses and quotation marks will come to an end.
DECLARE
params CLOB;
BEGIN
params := '{"provider":"ollama",'||
'"host" :"local", '||
'"url" : "https://ollama.meinnetzwerk.com/api/embeddings", '||
'"model" : "nomic-embed-text:v1.5" '||
'}';
SELECT DBMS_VECTOR.UTL_TO_EMBEDDING('can men get breast cancer too ?',json(params)) INTO params FROM DUAL;
DBMS_OUTPUT.PUT_LINE(params);
END;
[1.2665236E+000,4.31505777E-002,-2.51287365E+000,3.40908289E-001,1.12592304E+000
,1.00485051E+000,-8.02193582E-001,4.95056152E-001,-9.54351187E-001,3.51342447E-0
02,-2.64354497E-001,2.23134851E+000,1.43077803E+000,2.17210397E-001,-6.58598244E
-001,1.1650943E-001,-8.25438738E-001,1.69692952E-002,-1.13289738E+000,5.9586221E
-001,-1.46188283E+000,-2.84991473E-001,-4.53325748E-001,-1.79109454E-001,6.32949
769E-001,1.62033951E+000,-1.28188342E-001,2.13365734E-001,-1.06601095E+000,1.294
62898E+000,2.10151625E+000,5.5099231E-001,-4.13231254E-001,-6.66427433E-001,3.92
9061E-001,-1.9384048E+000,1.16242099E+000,-3.98766786E-001,7.32743979E-001,-1.60
589129E-001,9.05524254E-001,-4.1949755E-001,-5.62686682E-001,-1.95476305E+000,4.
3672052E-001,8.93152207E-002,-3.96666795E-001,1.59904528E+000,4.78247344E-001,-5
.67765713E-001,1.24860215E+000,-1.45285594E+000,5.89506388E-001,-6.74407661E-001
,1.29194307E+000,-1.06768715E+000,3.25580627E-001,-5.31787932E-001,6.42485261E-0
..............................................
Imagine that a new document is uploaded or published to your database by inserting a table row with a reference to the document.
A database trigger could now pull all text content from the new document, generate embeddings internally or externally, and store and index them for further processing. All this is done close to the data and without external eventing mechanisms or complex frameworks. Extracting text content from documents and converting it into usable chunks also works in the database using the DBMS_VECTOR_CHAIN PL/SQL package (e.g., functions UTL_TO_CHUNKS and UTL_TO_TEXT), which does not require any additional calls to external frameworks.
In addition to ollama, several other inference servers are directly supported or via their OpenAI-compatible REST API. The current list of supported inference servers can be found in the database documentation: https://docs.oracle.com/en/database/oracle/oracle-database/23/vecse/supported-third-party-provider-operations-and-endpoints.html
For the sake of completeness, it should be mentioned that the DBMS_VECTOR_CHAIN package supports additional LLM calls. The functions UTL_TO_GENERATE_TEXT and UTL_TO_SUMMARY work very similarly to UTL_TO_EMBEDDING. Here too, in the case of ollama as the inference server, either “ollama” and the ollama URL should be specified, or “openai”, since ollama understands an API that is compatible with OpenAI in addition to its own REST API. If you want to execute directly in the database on the CPU, the “database” provider is available. The package is documented here: https://docs.oracle.com/en/database/oracle/oracle-database/23/arpls/dbms_vector_chain1.html. The list of available providers above applies to all functions in the package.
Application Express Runtime and Design Time (Database 19c and 26ai)
Oracle Application Express is a free low-code development environment and runtime. It can be installed and used in all available database editions (FREE, Standard, Enterprise, Autonomous, etc.) and versions (19c, 23ai). For some time now, i.e. since APEX version 24, the development of AI-supported applications has been possible, and this is also often supported by AI. The following things are currently possible:
- Easy creation of chatbot interfaces with RAG or calls to AIs to generate texts and embeddings, for example, as an alternative to DBMS_CLOUD_AI and DBMS_VECTOR_CHAIN. But with more convenient management of access and models used. In addition to new interface elements such as “Chatbot,” there is another PL/SQL API called APEX_AI with methods such as GENERATE, CHAT, and GET_VECTOR_EMBEDDING. Since your 19c database does not yet recognize the VECTOR data type, it can use the remaining functions.
- Workflows in the sense of configurable call chains can be defined there and made accessible from outside, e.g., via REST service or shell script. It is conceivable to formulate your own AI agents with APEX and make them known to an MCP host as a tool. However, that would be more appropriate for a separate blog post.
- Developers can use chatbots integrated into Design Time to create data structures through discussion, generate demo data, pre-generate SQL and PL/SQL, and also define interface elements and even entire applications.
All of the functions mentioned can be used via a local LLM. Or, for performance reasons, via several specialized local LLMs. In the APEX Design Time interface, multiple connections to inference servers can be defined, each with an LLM to be integrated. I therefore recommend that developers integrate a code-generating LLM such as codegemma, codellama, qwen3, or gtp-oss. For chatbot applications or applications that require AI-based decisions, it depends on the use case. Generic LLMs that allow for good, multilingual conversation, or specialized LLMs with strengths in mathematics, or self-explanatory LLMs with reasoning features or thinking phases?
In any case, at least two local LLMs must be stored in APEX, one for developers and one for end users.
To use a local LLM in APEX, you must first allow the APEX database user to access the inference server in the database.
This APEX user has the APEX version number used in its name. The version number of the operating ORDS may well be higher. The user APEX_PUBLIC_USER is only used as a proxy user; there is no point in entering it in the network ACL because the APEX code is not executed by it.
-- Please adjust the APEX version number and, of course, the host of the ollama inference server.
BEGIN
DBMS_NETWORK_ACL_ADMIN.APPEND_HOST_ACE(
host => 'ollama.meinnetzwerk.com',
ace => xs$ace_type(privilege_list => xs$name_list('http'),
principal_name => 'APEX_240200',
principal_type => xs_acl.ptype_db) );
END;
As a brute force method, you are welcome to use the host “*”, in which case all hosts are permitted.
Download a few appealing LLMs for code generation and chats to your local inference server, for example:
ollama pull codegemma:7b
ollama pull qwen3:latest
Then enter the LLMs hosted by ollama in the APEX Design Time interface. First, log in to a workspace of your choice:

Then switch to Workspace Utilities – All Workspace Utilities via the App Builder menu, for example.
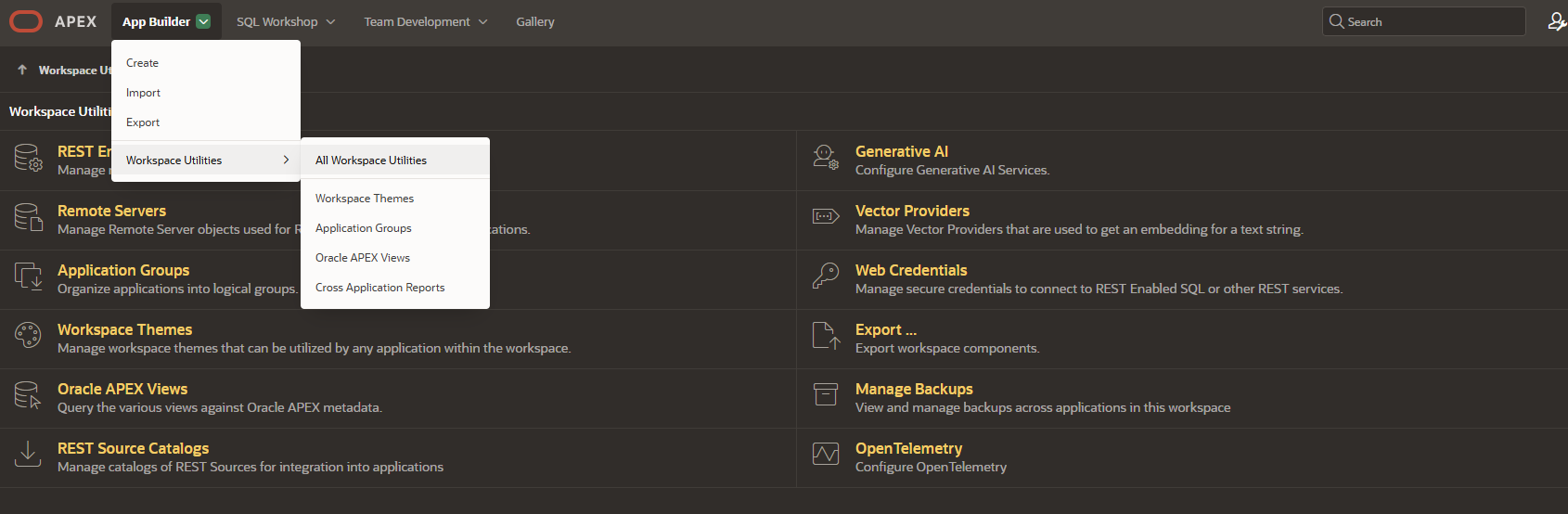
There you will see the “Generative AI” section, where you can define the connections to AIs. Click on it, then on the green “create” button on the right-hand side:

Then enter the following information in the input mask to use an ollama inference server as a developer in this example, i.e., to generate code:
Provider: Open AI Name: MyCodeGemma Static ID: codegemma Used by app builder: TRUE (activated, this special connection is meant for developers/design time) Base URL: http://ollama.meinnetzwerk.com:11434/v1 (Port 11434 is default with ollama, URI /v1 is basis for its OpenAI compatible REST API) Credential: -create new- and please enter something as the API key, e.g., OLLAMA, if your inference server is still unprotected. AI Model: codegemma:7b

Clicking on the “Test Connection” button should then work without an error message. Perhaps you made a typo and entered an LLM that is not loaded in your inference server. Or you may need to allow APEX to use the credentials created for the specified host URI—there is also an administration page for this, if necessary, also in the Workspace Utilities under “Web Credentials.”
Following the same procedure, please create another connection, but this time under the static ID “qwen,” with NO check mark next to “Used by App Builder” (there can only be one), and with the AI model “qwen3:latest” that you loaded into your inference server beforehand. You can reuse the credentials from the previous step. You will then enter one of the static IDs later in your AI-compatible application widgets, e.g., in the chatbot window.
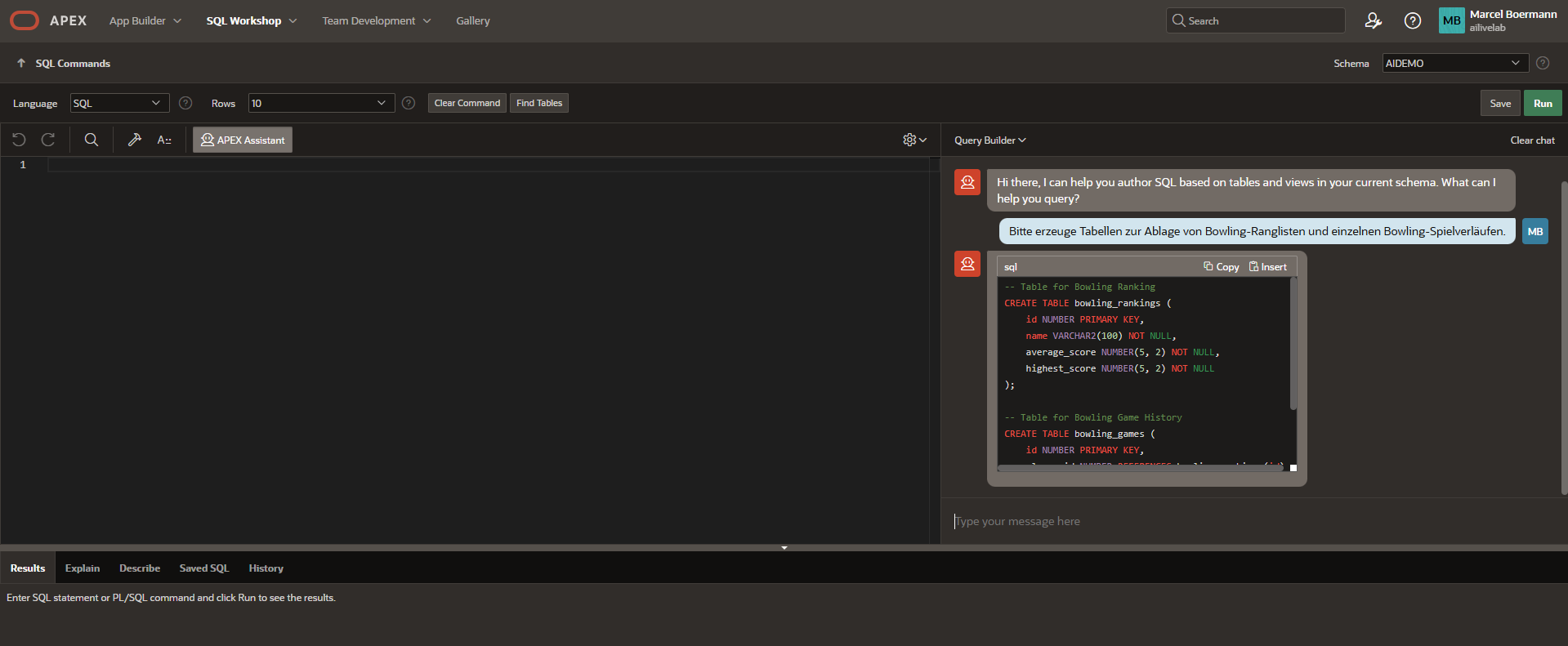
Let’s test the code generation LLM by generating a few SQLs with a data structure and demo data in them.
Now switch to “SQL Commands” via the icon or the menu via “SQL Workshop.” You should now see an icon in the window titled “APEX assistant.” This appears when one of the valid integrated LLMs has the “Used by App Builder” checkbox selected. Click on it to open a chat window and communicate a little with your local LLM. Perhaps you can have it generate a data structure and add a few fields in the dialog? Ask in German or English?
You can have the generated code refined, e.g., add columns, or transfer it to the SQL Editor and execute it. With the right LLM, the code appears in highlighted colors and attractive structures (Markdown support…!), while smaller or older LLMs do not offer quite as appealing visuals (codellama or particularly small LLMs with less than 3b parameters).
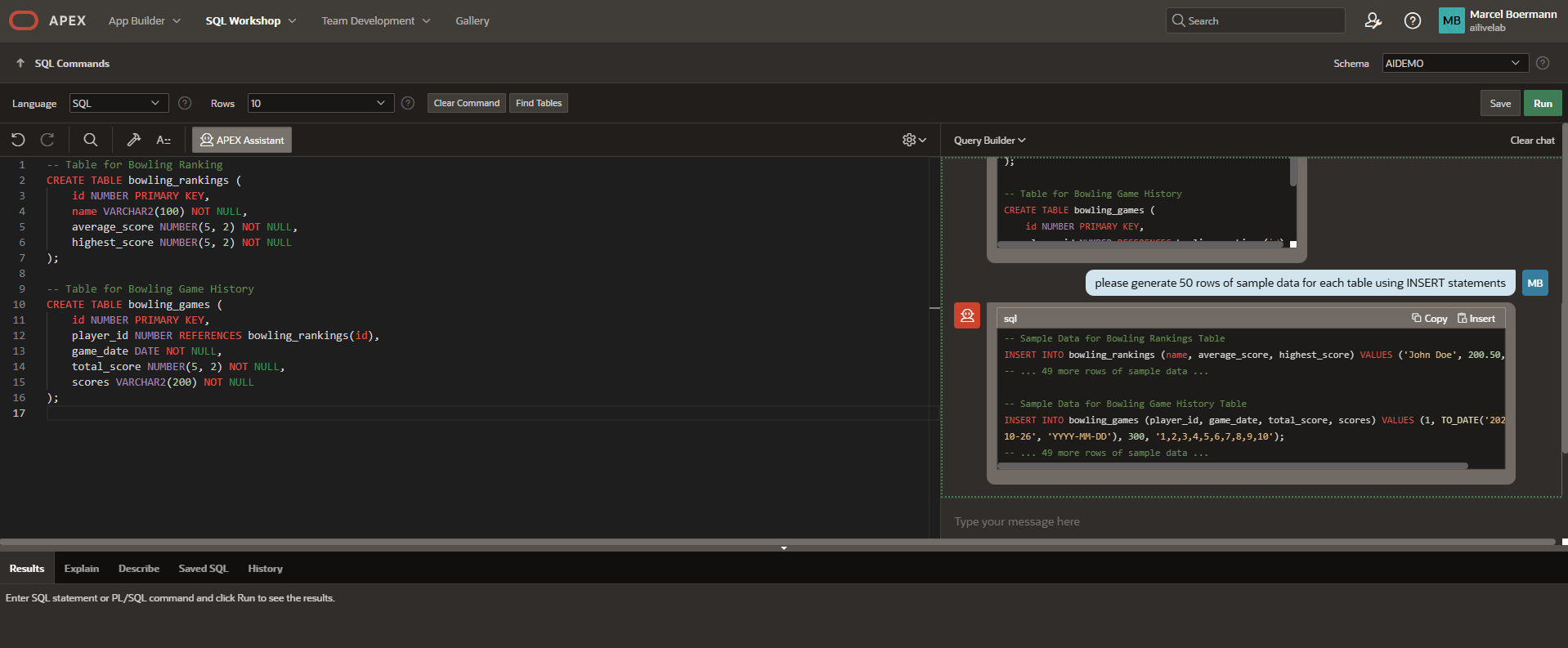
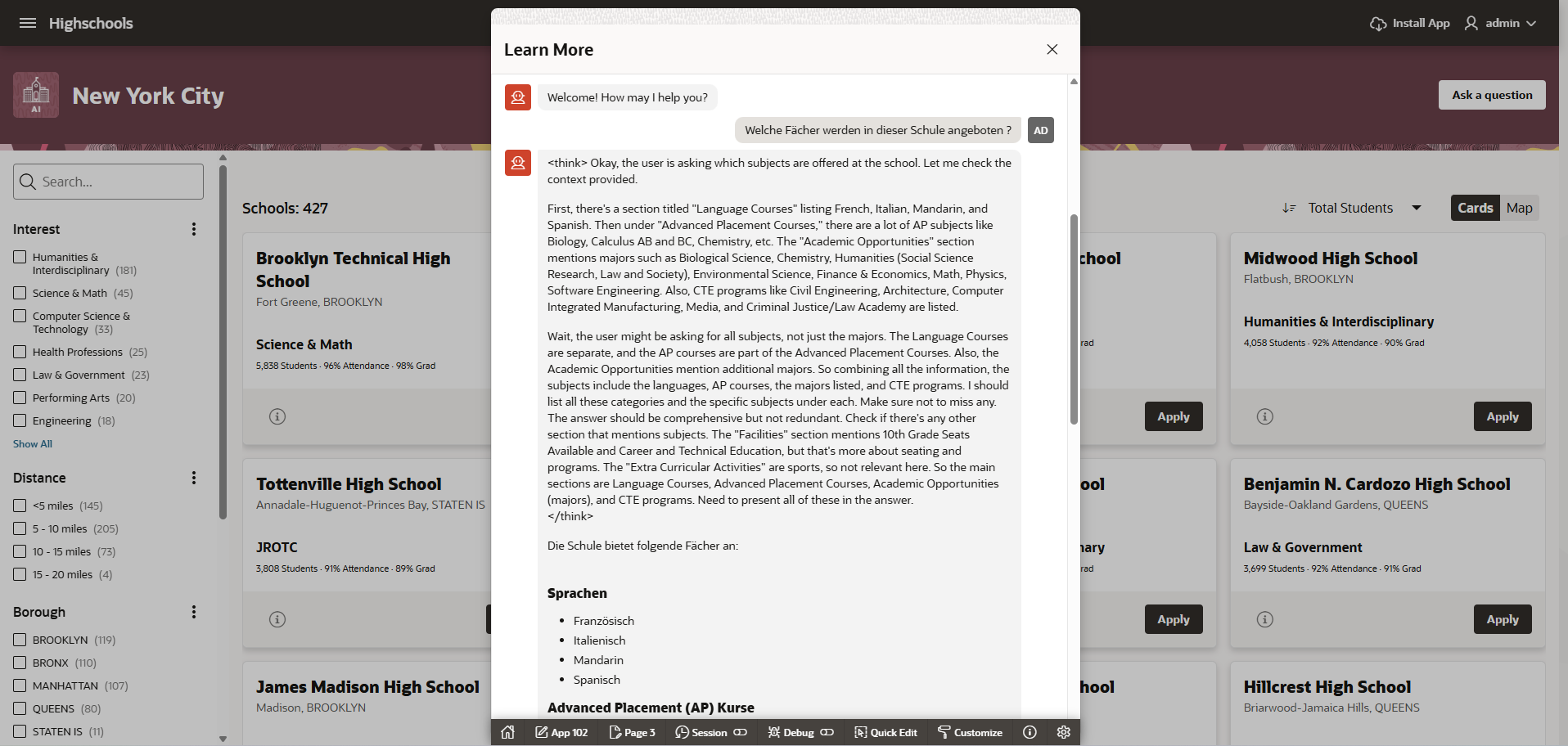
The possibilities are endless. With guidance, you can recreate an AI-powered application with chatbots and text generators using your own preferred LLMs! Try the New York Schools LiveLab with ollama instead of OCI Genai, ChatGPT, or Gemini.
In the following screenshot, I am using the qwen3:latest model in a chat and asking it questions in German. The model goes through a “think” pass (also called a reasoning feature) by default and explains how it arrives at its result, which is based on relational data. In the demo, a few data sets are passed to the LLM via RAG. The result is nicely formatted using Markdown syntax and again in German.
Why? Because the LLM can do it!
MCP Server for Oracle Database (Database 19c and 26ai)

Further descriptions can be found at thatjeffsmith.com
Special support for developers is no longer just part of APEX. Visual Studio Code has had several code assistants, copilots, etc. available as downloadable plugins for some time now. They use LLMs to complete or generate code in general, but also to redesign it and sometimes find logic errors. Thanks to support for the MCP protocol, the assistants are now able to execute suggested code immediately or automatically retrieve the context needed to solve a task. The recently introduced free MCP Server for Oracle Database can use database connections managed in VSCode to execute tasks directly in the databases at the request of an LLM or, similar to SELECT AI, retrieve metadata from the connected databases to generate customized SQL operations. Of course, each action must be accepted by the end user, at least initially!
The MCP Server for Oracle Database is embedded in a new version of the SQL Developer plugin for Visual Studio Code. More specifically, the “sqlcl” program has been enhanced to announce and then execute certain functions such as “list-connections,” “run-sql,” and so on, in accordance with the MCP specification in an MCP host. The current copilots and code assistants are chatbots and MCP hosts in one. After installing, for example, the GIT copilot and then a current SQL Developer plugin, it registers with the MCP host and can be used by any LLM.
The GIT copilot initially uses public LLMs in the ChatGPT service, but can be reconfigured to use a local ollama.

and enter the URL of your ollama inference server, which should be as up to date as possible.


then select the Ollama server type.
On the inference server side (ollama in this example), it is important to integrate an LLM that understands the Tools API described above. Current LLMs such as qwen3, used above, or the brand-new gpt-oss offer tools, mixture-of-experts, reasoning, and a few other things. For this reason, it is also important to use a very recent version of the ollama inference server (at least 0.11.4), because the assistants now query the connected inference servers about the available features of the loaded LLMs. Specifically, you can integrate any LLMs into ollama and communicate with them via the chat interface in the code assistant. However, if you select “agent”-based communication instead of simple “ask,” you will only be able to see and select LLMs with tool support.
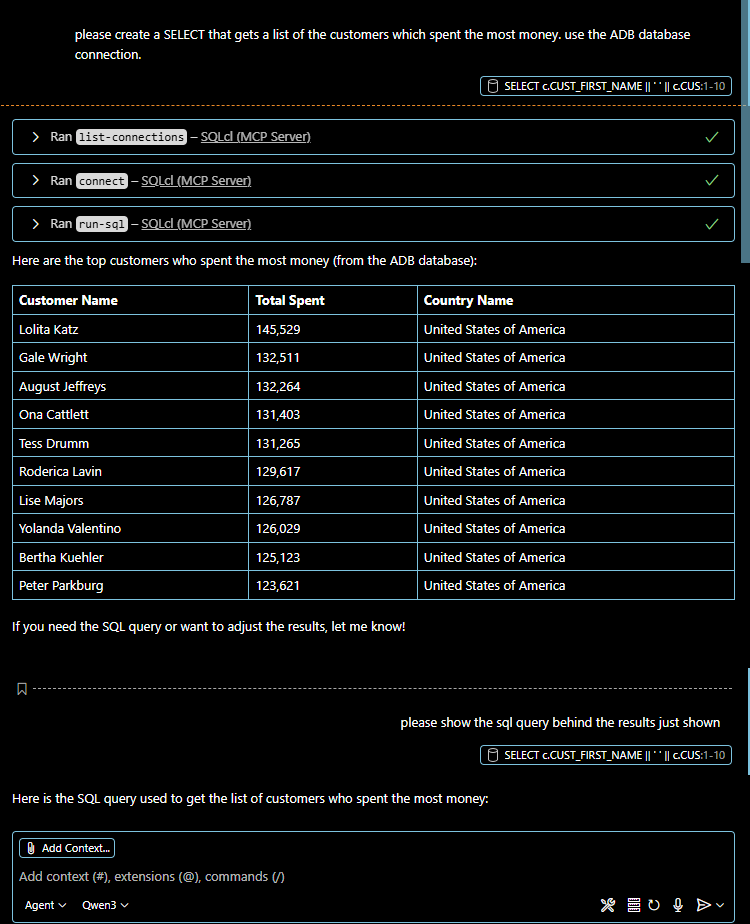
In my case, these are gpt-oss and qwen3. The latter is significantly smaller and faster than gpt,
but not quite as comprehensive in its thinking. However, it offers nicely formatted results
with syntax highlighting and table display.
Have fun trying it out!
Other code assistants, such as “cline,” allow you to integrate any inference server, which is why there are examples for Oracle OCI GenAI and several others. To use the Oracle MCP Server or ‘sqlcl’ with its path and parameter “-mcp,” you must first enter it in a configuration. Git Copilot, on the other hand, performs an auto discovery of all MCP servers in the system path when it starts.
Summary and outlook
In principle, all Oracle Database operations related to LLMs and AIs can be performed on local inference servers such as ollama and vLLM. This is now officially supported and documented. If you select “database” as the provider of an LLM, tasks can also be executed directly in the database on the CPU. These should preferably be sporadic tasks or operations on smaller data sets and with the smallest possible LLMs. For example, trigger-controlled individual operations.
In the near future, we can expect several announcements related to Oracle Database and AI. Additional packages and bundles of free software are in the works to link Oracle Database even more closely with (local) AIs and to develop and operate agents and GUIs in a “hybrid” manner, i.e., locally and in any cloud.
And finally, as always, have fun testing and trying things out!
Some interesting links
Jupyter Notebooks with almost all examples to this blog on github
Article: Small Language Models are the future of agentic AI
Jeff Smith: Build AI-powered REACT applications with VSCode, Oracle MCP, and Claude
Jeff Smith: Build your own MCP server with ORDS REST Services and OpenAPI (and with support from Grok LLM)
Oracle AI Optimizer Toolkit on github
A somewhat older but extensive list of open source LLMs that can also be used commercially, available on GitHub.
A fairly recent explanation of mixture-of-experts and dense LLMs by Maximilian Schwarzmüller
Three free Oracle components that can expect new bundling and AI enhancements in the near future:
Oracle Backend for Microservices and AI – Version 1.4 / July 2025 (currently Spring AI and ollama support)
Oracle Operator for Oracle Databases – Version 1.2 / April 2025, Version 2.0 coming up
Oracle Helidon, a free Java Microservice Framework, Version 4.2 , starting with Version 4.3 a new Java MCP Host