Did you know that Oracle Database provides a special database in-memory functionality for fast lookup operations? It’s made for lookup queries in data streaming applications, such as Internet of Things (IoT) applications, which request data for clients at a very high frequency.
A separate memory area in the SGA, the so-called memoptimize pool, buffers the data queried from tables and provides high-performance results. When configured, key-value lookups based on primary key values directly use a memory hash index from the pool during execution. You only need to decide which table data should be buffered. No changes are necessary within the applications.
You can find several postings about this topic e.g. the posting from Andy Rivenes from 2021. My first German posting about it was published in 2018. Last time during a discussion with one of my colleagues we found licence changes since then, so I decided to re-write the posting in English.
Note: MemOptimized Rowstore feature is included in Enterprise Edition with Oracle Database 21c and from Oracle Database 19c Release Update 19.12 (see Licensing Information User Manual).
How does it work now? In the first step, you need to configure the memoptimize pool. Then enable fast lookup at the table level with a special attribute and populate the pool. That’s it! No changes on the application level or additional maintenance are required.
Activating MemOptimized Rowstore
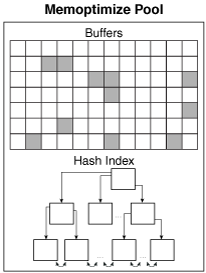
The Memoptimize Pool consists of two parts – the buffer area and the hash index.
To avoid disk I/O, the buffers of a MEMOPTIMIZE FOR READ defined table are pinned into the memoptimize pool until the table is marked as NO MEMOPTIMIZE FOR READ again. The memoptimize pool uses the same structure as the database buffer cache. However, it is completely separated from the database buffer cache. The hash index is a non-persistent segment structure consisting of several, non-contiguous memory units. Each memory unit contains several hash buckets. A special mapping structure then ensures that a memory unit is mapped to the corresponding primary key. 75% of the Memoptimize Pool is occupied by the MemOptimized Buffer Cache; the remaining 25% is used by the hash index.
The initialization parameter MEMOPTIMIZE_POOL_SIZE must be set to an integer value (the pool is deactivated by default). The size is a fixed value: To change the size of the memoptimize pool, the value of MEMOPTIMIZE_POOL_SIZE must be changed manually and the database instance restarted.
Note: The COMPATIBILITY parameter must be set to at least 18.0.0.
Let’s check the configuration and set the value to 500 MB. This means that 500 MB of the SGA will be used exclusively for the memoptimize pool. The minimum value is 100 MB.
SQL> select value, ISSES_MODIFIABLE, ISSYS_MODIFIABLE, ISPDB_MODIFIABLE
from v$parameter where upper(name)='MEMOPTIMIZE_POOL_SIZE';
VALUE ISSES ISSYS_MOD ISPDB
--------------- ----- --------- -----
0 FALSE IMMEDIATE FALSE
SQL> ALTER SYSTEM SET MEMOPTIMIZE_POOL_SIZE = 500M SCOPE=SPFILE;
System altered.
The database must be restarted for the value to be accepted. We then check the memory setting.
SQL> SHOW PARAMETER MEMOPTIMIZE_POOL_SIZE NAME TYPE VALUE ------------------------------------ ----------- ----------------- memoptimize_pool_size big integer 512M
Using MemOptimized Rowstore
After the configuration of the pool, only two steps are required to enable fast lookup:
- Enable the table attribute MEMOPTIMIZE FOR READ with the ALTER or CREATE TABLE command
- Populate the rowstore with DBMS_MEMOPTIMIZE.POPULATE
The hash index will be automatically generated and maintained by Oracle database. No further operations are required.
The memoptimize pool stores the data (fast lookup data) of all tables that are activated for fast lookup. The PL/SQL package DBMS_MEMOPTIMIZE is used to explicitly populate or delete fast lookup data for a table in the memoptimize pool (see also the documentation DBMS_MEMOPTIMIZE)
Note: The feature can be switched off with ALTER TABLE … NO MEMOPTIMIZE FOR READ.
Let’s illustrate the usage. Connect to one of your pluggable databases and create a test table SH.SALES_TAB with data from the SH.SALES table. Please note an important prerequisite is the existence of a primary key.
SQL> create table sh.sales_tab (sales_id NUMBER(6) primary key,
prod_id NUMBER(6) not null,
cust_id NUMBER not null,
time_id DATE not null,
quantity_sold NUMBER(3) not null,
amount_sold NUMBER(10,2) not null);
Table created.
SQL> insert into sh.sales_tab (sales_id,prod_id, cust_id, time_id, quantity_sold, amount_sold)
select rownum, PROD_ID, CUST_ID, TIME_ID, QUANTITY_SOLD, AMOUNT_SOLD from sh.sales;
918843 rows created.
Now let's enable the feature for the data stored in SH.SALES_TAB.
SQL> ALTER TABLE SH.SALES_TAB MEMOPTIMIZE FOR READ;
Table altered.
SQL> execute dbms_stats.gather_table_stats('SH','SALES_TAB');
PL/SQL procedure successfully completed.
Keep in mind the following restrictions:
- The table must have a primary key.
- The table must not be compressed.
- Deferred Segment Creation is not supported (see also parameter DEFERRED_SEGMENT_CREATION)
- There is no support for Reference Partitioned Tables.
In all these cases there is a corresponding error message such as
alter table reference_emp memoptimize for read * ERROR at line 1: ORA-62151: The MEMOPTIMIZE FOR READ feature cannot be enabled on a table with specified partitioning type. Help: https://docs.oracle.com/error-help/db/ora-62151/
In the last step, the rowstore must be filled. This is done with the procedure DBMS_MEMOPTIMIZE.POPULATE.
SQL> execute dbms_memoptimize.populate(schema_name=>'SH',table_name=>'SALES_TAB'); PL/SQL procedure successfully completed.
That’s it! Now let’s test it and display the execution plan.
SQL> select * from sh.sales_tab where sales_id=5;
SALES_ID PROD_ID CUST_ID TIME_ID QUANTITY_SOLD AMOUNT_SOLD
---------- ---------- ---------- --------- ------------- -----------
5 113 11443 27-MAY-19 1 27.59
SQL> select * from dbms_xplan.display_cursor();
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------------------------------
SQL_ID dfn2vxgz8vuyf, child number 0
-------------------------------------
select * from sh.sales_tab where sales_id=5
Plan hash value: 1271039271
------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 3 (100)| |
| 1 | TABLE ACCESS BY INDEX ROWID READ OPTIM| SALES_TAB | 1 | 27 | 3 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN READ OPTIM | SYS_C009384 | 1 | | 2 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("SALES_ID"=5)
The two new operations for table and index access – TABLE ACCESS BY INDEX ROWID READ OPTIM and INDEX UNIQUE SCAN READ OPTIM – indicate that the MemOptimized Rowstore is being used.
Note: The SQL*Plus format specification SET LINESIZE WINDOW provides good support for the output of execution plans.
Let us now change the table by adding a row with SALES_ID 920000 and changing the TIME_ID of the row with SALES_ID 5.
SQL> insert into sh.sales_tab values (920000, 11160, 17450, sysdate, 20, 800); 1 row created. SQL> update sh.sales_tab set time_id=sysdate where sales_id=5; 1 row updated. SQL> commit; Commit complete.
The MemOptimized Rowstore is also used here. The rowstore with hash index and memoptimize buffer cache is automatically maintained by the Oracle database.
SQL> select * from sh.sales_tab where sales_id=5;
SALES_ID PROD_ID CUST_ID TIME_ID QUANTITY_SOLD AMOUNT_SOLD
---------- ---------- ---------- --------- ------------- -----------
5 113 11443 02-APR-24 1 27.59
SQL> select * from dbms_xplan.display_cursor();
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------------------------------
SQL_ID dfn2vxgz8vuyf, child number 0
-------------------------------------
select * from sh.sales_tab where sales_id=5
Plan hash value: 1271039271
------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 3 (100)| |
| 1 | TABLE ACCESS BY INDEX ROWID READ OPTIM| SALES_TAB | 1 | 27 | 3 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN READ OPTIM | SYS_C009384 | 1 | | 2 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("SALES_ID"=5)
19 rows selected.
But with the following queries, it is different …
SQL> select * from sh.sales_tab where sales_id<2;
SALES_ID PROD_ID CUST_ID TIME_ID QUANTITY_SOLD AMOUNT_SOLD
---------- ---------- ---------- --------- ------------- -----------
1 113 6394 27-MAY-19 1 27.59
SQL> select * from dbms_xplan.display_cursor();
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------
SQL_ID am8db887c1ysq, child number 0
-------------------------------------
select * from sh.sales_tab where sales_id<2
Plan hash value: 3649983992
---------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 4 (100)| |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| SALES_TAB | 1 | 27 | 4 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | SYS_C009384 | 1 | | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("SALES_ID"<2)
19 rows selected.
Or with this query here …
SQL> select * from sh.sales_tab where prod_id=113 and sales_id=5;
SALES_ID PROD_ID CUST_ID TIME_ID QUANTITY_SOLD AMOUNT_SOLD
---------- ---------- ---------- --------- ------------- -----------
5 113 11443 02-APR-24 1 27.59
SQL> select * from dbms_xplan.display_cursor();
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------------------------------
SQL_ID 7ardctj97y51k, child number 0
-------------------------------------
select * from sh.sales_tab where prod_id=113 and sales_id=5
Plan hash value: 1271039271
-------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 3 (100)| |
|* 1 | TABLE ACCESS BY INDEX ROWID| SALES_TAB | 1 | 27 | 3 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | SYS_C009384 | 1 | | 2 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("PROD_ID"=113)
2 - access("SALES_ID"=5)
20 rows selected.
Summary
Fast Lookup enables fast retrieval/query of data from a database for high-frequency queries. Fast Lookup uses a separate memory area in the SGA, the so-called memoptimize pool, to buffer the data queried from tables to improve query performance. The memoptimzed rowstore provides higher performance results because queries use the hash index and bypass the SQL execution layer so that they are processed directly in the data layer. Please note, the MemOptimized Rowstore feature can only be used with a single equality predicate on the primary key. Other types of query are not supported.
In addition, Memoptimized Rowstore offers a Fast Ingest capability for the processing of high-frequency, single-line data inserts in a database. In contrast to the Fast Lookup, Fast Ingest uses the LARGE POOL to buffer the INSERTs before they are written to the hard disk to increase performance. This will be covered in an upcoming posting.
Further Readings
