Today, approximately 36% of all global data is generated by the healthcare industry. Driven by advancements in AI, widespread EHR adoption, and the proliferation of wearables, total global healthcare data has surpassed 10,000 exabytes as of 2025. This data explosion continues to accelerate, fueled by the development of personalized treatments, 360-degree patient views, and the integration of Large Language Models (LLMs), Agentic AI, and advanced analytics.
A centralized data hub enables healthcare applications—spanning payers, providers, patient care systems, and pharmacies—to seamlessly access and process information. This facilitates intelligent, data-driven decision-making that improves patient outcomes, controls costs, and increases operational efficiency.
The healthcare industry has been a leader in big data adoption, consistently implementing cutting-edge solutions and architectures to efficiently collect, process, store, and distribute data to stakeholders. Within this ecosystem, Apache Kafka plays a critical role in addressing key big data challenges. It enables the ingestion of diverse data sets, real-time processing upon arrival, and the distribution of high-quality data to consumers. Furthermore, Kafka’s distributed computing model scales seamlessly, allowing for the processing of hundreds of terabytes to petabytes of data.
Kafka meets Kubernetes
Apache Kafka is an open-source, distributed event-processing platform designed to run on physical or virtual machines. It scales horizontally to process data with high throughput, low latency, and real-time capabilities, making it a preferred choice for real-time data pipelines, data integration, and analytics. Utilizing a pub-sub architecture, Kafka employs distributed, fault-tolerant message brokers to publish topics that subscribers can consume at a massive scale.
Integrating Kafka with Kubernetes enhances its inherent fault tolerance and scalable broker architecture. This integration leverages Kubernetes’ POD-based, near-linear scaling, ensuring efficient CPU and memory utilization and improved portability. Furthermore, running Kubernetes on Oracle Cloud abstracts the complexity of using ZooKeeper for cluster resource management. This orchestration serves as an emerging pattern for achieving high availability and scalability for Kafka connectors running within PODs.
Strimzi, a CNCF open-source project, addresses additional challenges such as building connector plugins and generating accurate connector property files. By providing operator patterns, Strimzi eliminates plumbing complexity through Custom Resource Definitions (CRDs) for Kafka connectors, RBAC, MirrorMaker, cluster roles, and bindings.
Core Components & Concepts:
- Producers: Applications that publish (write) data to Kafka topics.
- Consumers: Applications that subscribe to (read) and process data from topics.
- Topics: Channels where data is stored in partitioned, ordered, and immutable logs.
- Brokers: Servers that make up the Kafka cluster and manage the data.
- Connect & Streams: Kafka Connect enables connecting to external systems, while Kafka Streams is a library for processing data within Kafka.
Why Healthcare should care about Kafka and Data Hub
Effective healthcare data management is critical for accelerating insights and simplifying workflows. Data Lakehouse and centralized data hubs enable healthcare organizations to collect, curate, and develop intelligent applications. By leveraging diverse data formats and real-time processing, these architectures democratize data across every facet of the business.
- Health Insurance Providers: Require centralized data that is accessible across various business applications and users to accelerate claims processing, ensure regulatory compliance, and mitigate fraud.
- Hospitals & Care Providers: Depend on comprehensive patient histories to deliver personalized care, monitor progress in real-time, and proactively prevent medical escalations or emergencies.
- Pharmacy Systems: Must optimize inventory management and reduce waste through effective medicine pricing, driven by regulatory adherence and real-time market information.
- Drug Discovery & Research: Need to process vast amounts of genomic data, combining it with health metadata and biological information to generate high-quality datasets for developing advanced models, such as protein folding and amino acid structures.
Apache Kafka is a cornerstone of the healthcare Lakehouse architecture, facilitating the ingestion of terabytes to petabytes of data at scale. By combining real-time streams with dimensional metadata, it enables actionable insights through any analytics tool. Furthermore, deploying Kafka on Kubernetes ensures seamless scalability, high throughput, and low-latency processing, empowering analytics at a massive scale.
Using Oracle Kubernetes to deploy and scale Kafka
Oracle Cloud Infrastructure (OCI) Streaming with Apache Kafka is a fully managed service that enables the creation and operation of Kafka clusters within an OCI tenancy. It provides the complete functionality of Apache Kafka with 100% open-source API compatibility. This fully managed solution automates critical operational tasks, including patching, upgrades, backups, high availability (HA), cross-region replication, and performance management. The service features automated node recovery from broker failures, allowing producers and consumers to transition seamlessly to recovered or replacement nodes, thereby minimizing downtime and performance degradation.
Organizations can start with a single broker node and scale to thousands of nodes on demand to meet evolving workload requirements. To ensure maximum durability, data is replicated using high-density, redundant storage across multiple availability domains. Properly tuned clusters can achieve sub-100 ms latency and a throughput of approximately 10 MB/s per partition. Additionally, storage capacity can scale up to 16 TB per broker, supporting petabyte-scale data requirements. Oracle ensures robust security and isolation through a single-tenancy model, where each cluster is dedicated exclusively to a single customer.
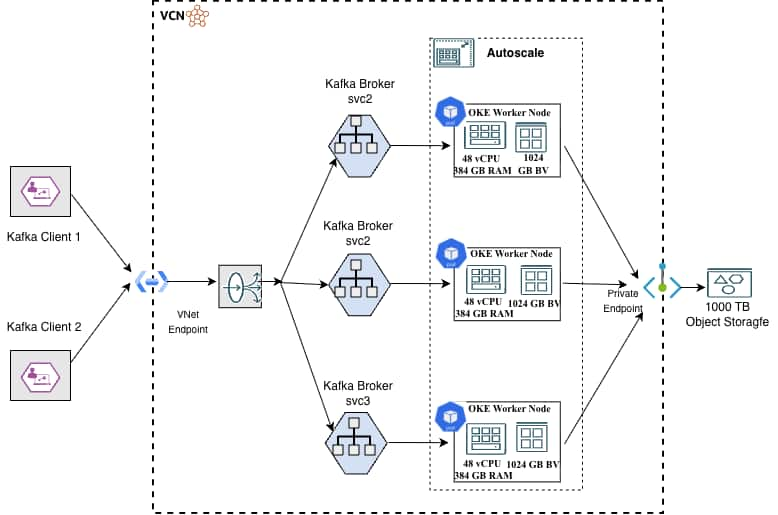
Architecture
At the time of writing, the total cost with a 25 node and 10 TB object storage with above specification will cost as follows:
Apache Kafka clusters can be deployed on Oracle Cloud Infrastructure (OCI) using the Oracle Cloud Infrastructure Kubernetes Engine (OKE). This architecture leverages flexible virtual machine shapes, specifically the E6 standard compute instances powered by the latest 5th Generation AMD EPYC™ (Turin) processors. A typical high-performance configuration utilizes the VM.Standard.E6.Flex shape, provisioned with 24 OCPUs (48 vCPUs), 384 GB of RAM, and 1 TB of balanced block volume storage per node.
While clusters can be configured with any number of nodes, a minimum of three broker nodes is recommended for production environments to ensure high availability and fault tolerance. These nodes can be scaled horizontally or vertically with minimal impact on service uptime, allowing the cluster to optimize performance as demand grows. To further enhance cost efficiency and durability, “hot” data can be dehydrated into low-cost OCI Object Storage. This storage layer can be securely accessed from within a Virtual Cloud Network (VCN) using private endpoints, ensuring that data traffic remains isolated from the public internet.
| Description | Part Qty | Instance Qty | Usage Qty | Unit Price | Monthly Cost |
| Cloud Infrastructure Kubernetes Engine (OKE) | |||||
| OCI Kubernetes Engine – Enhanced Cluster (Cluster Per Hour) | 1 | 1 | 730 | $0.10 | $73.00 |
| Compute – Standard – E6 – OCPU (OCPU Per Hour) | 24 | 25 | 730 | $0.030 | $13,140.00 |
| Compute – Standard – E6 – Memory (Gigabytes Per Hour) Capacity Type: On-Demand | 384 | 25 | 730 | $0.0020 | $14,016.00 |
| Boot Volume | |||||
| Storage – Block Volume – Storage (Gigabyte Storage Capacity Per Month) | 1000 | 25 | 1 | $0.0255 | $637.50 |
| Storage – Block Volume – Performance Units (Performance Units Per Gigabyte Per Month) | 10000 | 25 | 1 | $0.0017 | $425.00 |
| Object Storage | |||||
| Object Storage – Storage (Gigabyte Storage Capacity Per Month) | 10000 | 1 | 1 | $0.0255 | $255.00 |
| Monthly Total | $28,546.50 |
Deployment:
Create oracle cloud account and tenancy – https://docs.oracle.com/en/engineered-systems/private-cloud-appliance/3.0-latest/admin/admin-adm-tenancy-new.html
Set up Oracle Kubernetes engine service – https://github.com/oracle-quickstart/terraform-oci-oke-quickstart
Setup Strimzi Kafka Connector
Install Strimzi using YAML
Kubectl create -f ‘https://strimzi.io/install/latest?namespace=kafka” – n kafka
Sample Kafka.yaml file –
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
version: 3.2.3
replicas: 3
listeners:
– name: plain
port: 9092
type: internal
tls: false
– name: tls
port: 9093
type: internal
tls: true
config:
offsets.topic.replication.factor: 1
transaction.state.log.replication.factor: 1
transaction.state.log.min.isr: 1
default.replication.factor: 1
min.insync.replicas: 1
inter.broker.protocol.version: “3.2”
storage:
type: ephemeral
zookeeper:
replicas: 3
storage:
type: ephemeral
entityOperator:
topicOperator: {}
userOperator: {}
To setup Kafka connect image you can refer the example code provided here.
Set up mTLS and Key Vault using instructions here
Cluster security and management:
- OCI Streaming with Apache Kafka supports SCRAM-SHA-512 that allows salted password that uses cryptographic hashing algorithm to protect user’s credentials.
- You can load user credentials into OCI Key vault for secured and authorized access integrated using OCI IAM service.
- IAM policies on oracle cloud lets set up role-based access controls (RBAC) for cluster management and usage.
- You can use Kafka ACLs to configure authorization to use Kafka cluster resources.
- Optionally you can configure mTLS enabling two-way authentication adding another layer of security beyond standard TLS.
- Data stored in block volumes attached to broker nodes are always and by default encrypted at rest.
Take aways:
Deploying Kafka on Kubernetes using Oracle Streaming with Apache Kafka offers significant benefits in terms of scalability, resilience, and operational efficiency. However, it requires careful planning and consideration of various factors including deployment method, resource allocation, networking, and storage. Following best practices for high availability, performance tuning, and security will ensure a robust Kafka deployment that can handle the demands of modern streaming applications. By understanding the unique challenges of running Kafka on Kubernetes and implementing appropriate solutions, organizations can build reliable, scalable streaming platforms that drive their data-intensive applications. Running Kafka on oracle cloud infrastructure provides ease of management of Kafka as a data hub with full management service, durability of data and resiliency and improved overall economy.
For further information to run your Kafka cluster on Oracle cloud infrastructure please refer –
