We’re excited to announce that OCI Streaming with Apache Kafka is now generally available, delivering the power and flexibility of Apache Kafka’s distributed event streaming capabilities on Oracle Cloud Infrastructure (OCI). With this new managed Kafka service, you can easily build and operate event-driven applications and real-time data pipelines in OCI’s secure, scalable environment—while benefiting from streamlined deployment, integration, and management.
Below, we explore the key features, benefits, and common use cases of OCI Streaming with Apache Kafka, and finish with a step-by-step guide to help you get started.
Why OCI Streaming with Apache Kafka?
As businesses increasingly require real-time data processing and analytics, Apache Kafka provides a robust backbone for streaming workloads. Now, with Oracle’s fully managed Kafka service on OCI, your teams can focus more on data and application innovation, and less on infrastructure management. Key advantages include:
- Fully Managed Kafka: Automatic provisioning, scaling, maintenance, and patching – OCI handles the operational heavy lifting.
- High Throughput & Scalability: Designed to scale across multiple availability domains, leveraging OCI’s high-throughput networking and resilient architecture.
- Comprehensive Security: Protect your data using robust networking, authentication (SASL-SCRAM, mTLS), and access control features.
Key Features
1. Flexible Cluster Options
- OCI Streaming with Apache Kafka offers flexible cluster configurations to support various workloads. Starter Clusters, recommended for development and testing, can be provisioned with 1 to 30 brokers. High Availability (HA) Clusters, designed for production use cases, support resilient deployment across multiple domains, require a minimum of 3 brokers, and can scale up to 30 brokers.
2. Custom Configurations
- You can quickly create a cluster using default configuration settings, or customize broker settings, replication factors, and other parameters to suit your specific requirements using the OCI CLI or Kafka API.
3. Security and Compliance
- Authentication: Secure clusters using SASL-SCRAM or mTLS. Integration with OCI IAM is planned for future updates.
- Access Control: Manage and restrict connectivity and permissions using Kafka Access Control Lists (ACLs), along with flexible VCN configurations to control network access as needed.
4. High Availability & Disaster Recovery
- In HA configurations, intra-region data replication enhances durability and availability.
- Cross-cluster (multi-region) replication and disaster recovery is supported via MirrorMaker 2.
Common Use Cases
OCI Streaming with Apache Kafka supports a range of mission-critical, real-time and artificial intelligence workflows:
-
Real-time AI Training Data Foundation: Stream and aggregate real-time data from diverse sources, providing up-to-date, high-quality datasets essential for training and retraining AI and large language models (LLMs) on fresh business or operational signals.
- Vector Database Pipelines for GenAI and RAG: Stream processed data, including vector embeddings, directly to integrated vector databases (such as those used in AI search or Retrieval-Augmented Generation scenarios), enabling AI models to leverage contextual and up-to-date information to enhance output relevance and accuracy.
-
AI Agent and Multi-Agent System Orchestration: Establish real-time communication and event sharing between AI microservices or agents, support agent state management, and coordinate dynamic workflows with streaming pipelines for more responsive and autonomous AI solutions.
- Realtime Data Analysis: Continuously stream IoT and patient device data for proactive health monitoring, predictive analysis, and timely intervention.
-
User Behavior Analytics: Capture and process real-time data on user interactions across web and mobile applications to gain actionable insights and personalized recommendations.
-
Demand Forecasting: Stream and analyze live sales and operational data to improve on-the-fly predictions, forecasting accuracy and support data-driven business decisions.
-
Fraud Detection: Continuously monitor financial transactions in real time to identify suspicious patterns, anomaly detection and respond swiftly to potential fraud threats.
-
Change Data Capture (CDC): Seamlessly stream database changes into analytics platforms or data lakes to keep downstream systems synchronized with the latest data with low latency.
Getting Started: Console Walkthrough
Pre-requisite: Policy Setup
Before provisioning your first Kafka cluster, you must grant the necessary permissions to both the raw Kafka service (referred to as rawfka) and your user groups. Update the policy statements below by replacing placeholders.
Service Permissions:
Allow service rawfka to use vnics in compartment <compartment>
Allow service rawfka to use network-security-groups in compartment <compartment>
Allow service rawfka to use subnets in compartment <compartment>
User Authorization:
Allow group <dynamic-group> to {
KAFKA_CLUSTER_INSPECT, KAFKA_CLUSTER_READ, KAFKA_CLUSTER_CREATE,
KAFKA_CLUSTER_DELETE, KAFKA_CLUSTER_UPDATE, KAFKA_CLUSTER_CONFIG_READ,
KAFKA_CLUSTER_CONFIG_INSPECT, KAFKA_CLUSTER_CONFIG_CREATE,
KAFKA_CLUSTER_CONFIG_UPDATE, KAFKA_CLUSTER_CONFIG_DELETE,
KAFKA_CLUSTER_MOVE
} in <compartment> | tenancy
SASL Super User Permissions (if required):
Allow service rawfka to {SECRET_UPDATE} in compartment <compartment>
Allow service rawfka to use secrets in compartment <compartment> where request.operation = ‘UpdateSecret’
Step-by-Step: Creating a Kafka Cluster
A detailed walkthrough with screenshots is available in the documentation. Below is a summary of the process:
1. View or Create Kafka Clusters: Navigate to your compartment to see existing Kafka clusters, or select “Create Cluster” to start.
2. Configure Cluster Details: Specify the cluster name, version, and compartment where you’d like to create the cluster.
3. Broker Settings: Select the cluster type (Starter or HA), number of brokers, and resource allocations (CPU, memory and storage).
4. Cluster Configuration: Apply default or custom Kafka configurations as needed.
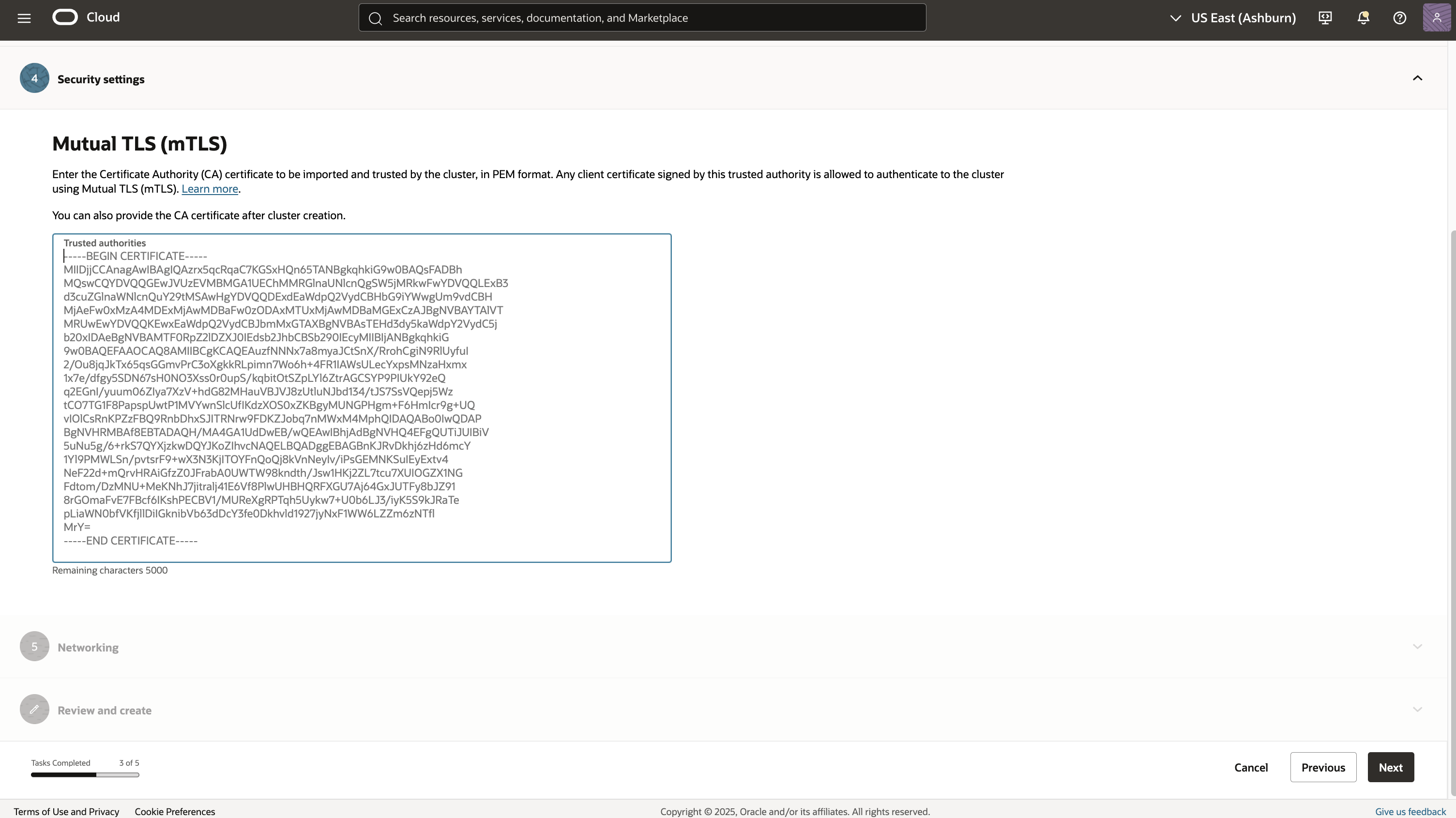
5. Security Settings: Set up mTLS (with appropriate certs) for intra-cluster security; configure SASL-SCRAM after deployment.
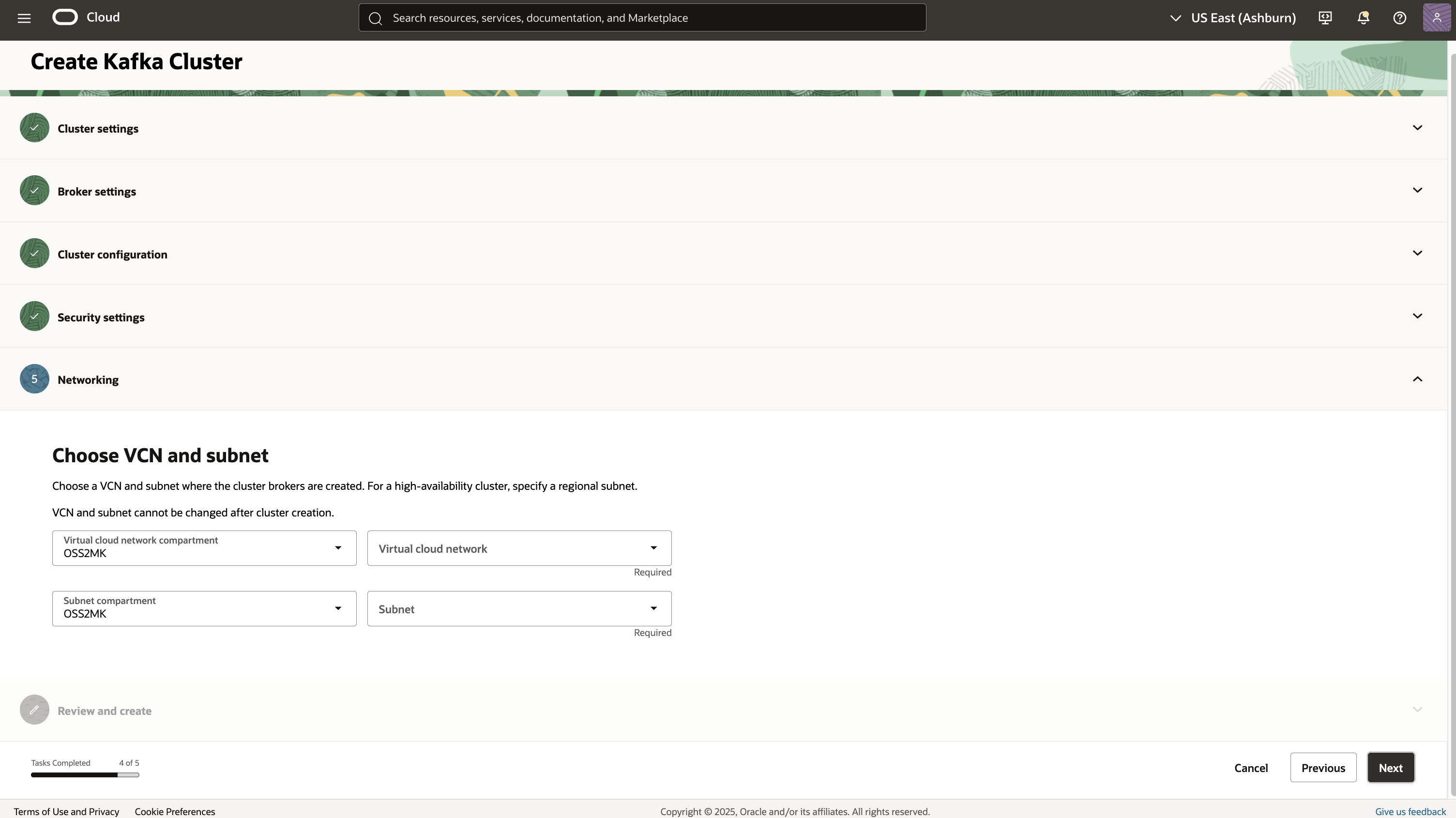
6. Networking: Choose your Virtual Cloud Network (VCN) and subnets—regional subnets are recommended for HA clusters.
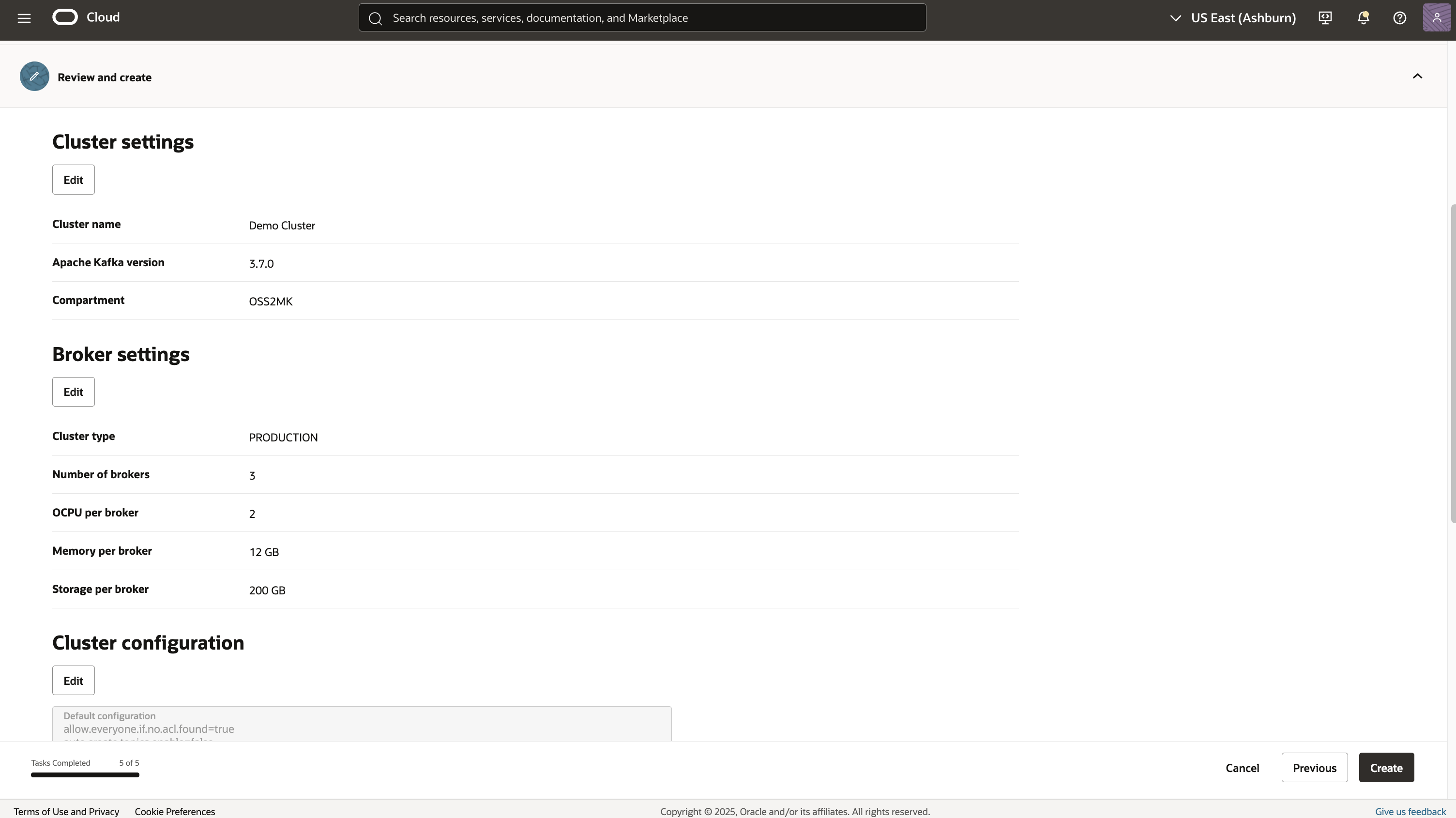
7. Review and Create: Confirm all settings before launching your new Kafka cluster.
Pricing Overview
OCI Streaming with Apache Kafka is billed based on infrastructure usage:
- Pricing depends on the number of brokers, CPU cores, memory, and storage.
- Service fee: $0.10 per OCPU per hour (or $0.05 per OCPU per hour for ARM A1 shapes).
- For the latest information, visit the OCI Pricing page .
Get Started Today
OCI Streaming with Apache Kafka is ready to help you harness the power of real-time streaming applications with reduced operational overhead—and with the scalability, availability, and security you expect from Oracle Cloud Infrastructure.
Start building your data streaming solutions now!
For questions or support, please refer to the official documentation or contact OCI Support.
