Introduction
Oracle Cloud Infrastructure (OCI) has invested heavily in high-performance computing over the past several years, and the OCI HPC stack has matured significantly since its inception more than five years ago. With each release, the stack has evolved to support increasingly complex workloads and deployment patterns. This blog introduces OCI HPC Cluster Stack 3.0.0, a major update that brings new paradigms for simplifying HPC/GPU cluster deployment, configuration, and lifecycle management. Release 3.0.0 incorporates new automation, architectural improvements, and a more modular design to make large-scale cluster operations easier than ever.
As large-scale AI training and inference workloads continue to grow, customers require tightly coupled GPU clusters with high-speed, low-latency internode communication powered by RDMA-enabled networking. OCI’s HPC Cluster Stack provides a streamlined path to deploy such clusters using Terraform and Ansible artifacts engineered and validated by the OCI HPC team.
With a single deployment, the stack provisions a complete cloud-native HPC/GPU environment that includes:
- A VCN configured with a public subnet, private subnet, and a cluster network, along with all required gateways (IGW, NAT, SRG, etc.) and security lists to ensure controlled, secure access.
- A Controller Node deployed in the public subnet, serving as the cluster’s management plane and administrative hub. It is preloaded with automation scripts, configuration utilities, and tools required to operate the cluster.
- A Login Node, also in the public subnet, offering users a stable environment to submit jobs, compile applications, and access shared resources.
This new release builds on OCI’s proven HPC foundation while introducing enhancements that improve performance, simplify operations, and reduce the overall time to value when deploying GPU-accelerated clusters for AI and scientific computing workloads.
Brief History
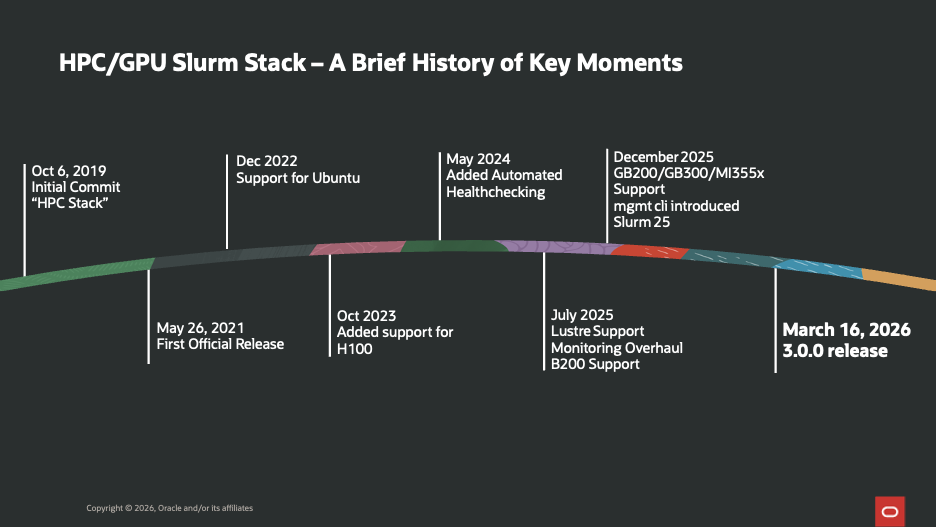
The OCI HPC/GPU Slurm Stack has evolved significantly over the past several years, driven by customer demand for scalable, high-performance AI and HPC workloads. What began as an initial commit in 2019 quickly matured into a production-ready solution with the first official release in 2021, establishing a strong foundation for cloud-based HPC deployments.
As adoption grew, the stack expanded its capabilities to support a broader ecosystem. In 2022, Ubuntu support was introduced, making the platform more flexible for diverse enterprise environments. With the rapid advancement of AI/ML workloads, 2023 marked a major milestone with the addition of NVIDIA H100 GPU support, enabling customers to run next-generation training and inference workloads at scale.
The pace of innovation accelerated further in 2024 and 2025. Automated health checks improved cluster reliability and operational efficiency, while enhancements such as Lustre support and monitoring overhaul strengthened performance visibility. Support for newer GPU architectures like B200 and next-generation systems such as GB200/GB300 and MI355x demonstrated the stack’s commitment to staying ahead of hardware advancements. The introduction of the management CLI and Slurm 25 integration further streamlined cluster operations.
All of these milestones culminate in the 3.0.0 release (March 2026), representing a major step forward in usability, scalability, and enterprise readiness—making the stack a comprehensive solution for modern AI and HPC workloads on OCI.
Event Driven Cluster Automation and Dynamic Scaling
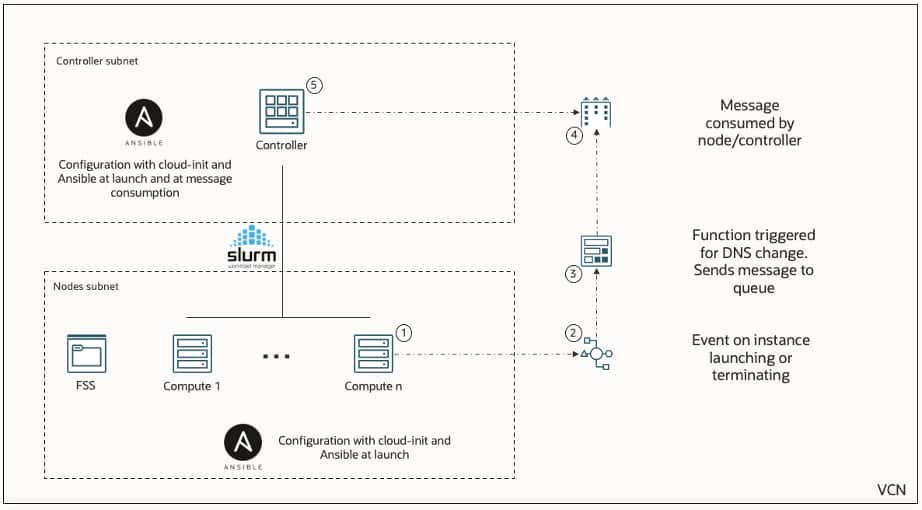
One of the key architectural enhancements in Stack 3.0 is the introduction of an event-driven automation framework that tightly integrates OCI services with Slurm-based cluster operations. This design enables dynamic and intelligent lifecycle management of compute nodes based on real-time events. When a compute instance is launched or terminated within the cluster, an OCI event is generated. This event triggers a serverless function, which publishes a message to a queue. The controller node continuously consumes messages from this queue and takes appropriate actions—such as updating Slurm node states, registering new nodes, or removing decommissioned ones.
At the same time, both the controller and compute nodes are configured using cloud-init and Ansible during provisioning, ensuring consistent and repeatable setup across the cluster. This combination of infrastructure automation and event-driven orchestration eliminates manual intervention, reduces operational overhead, and ensures that the cluster state in Slurm always remains in sync with the underlying OCI infrastructure. Overall, this architecture brings cloud-native elasticity to traditional HPC environments, allowing customers to scale their GPU clusters seamlessly while maintaining reliability and operational efficiency.
Deployment
For teams requiring more control, such as custom networking, cluster tuning, CI/CD integration, or specialized GPU configurations, the full codebase is available on GitHub. The deployment gives you complete flexibility to tailor variables, Ansible playbooks, or architectural components.
Steps:
- Access the GitHub repository: https://github.com/oracle-quickstart/oci-hpc/
- Review the README for prerequisites, configuration variables, and module descriptions.
- To deploy directly using Oracle Resource Manager, click the Deploy to Oracle Cloud button:
Resource Manager will prompt for input variables and then run the Terraform plan to build the full HPC stack – including Controller, Login, GPU/CPU compute nodes, and the supporting networking constructs.
Node Configuration
Node configuration has been redesigned to be more modular, decentralized, and scalable. While the cluster continues to leverage the familiar Ansible-based automation framework from previous releases, the workflow has been enhanced to make each node self-configuring, reducing dependencies on the Controller and improving overall reliability during large-scale deployments. To ensure consistency across the entire cluster, all configuration artifacts – including Ansible playbooks, roles, and templates – are stored centrally under the /config directory. This directory is exported to all nodes using the OCI Managed NFS service.
When you create or modify a custom Ansible role under the shared /config path, it is immediately available to every node in the environment. Each compute node – whether GPU or CPU – executes its configuration workflow independently and asynchronously.
Cluster Management Utility (mgmt)
OCI HPC Cluster Stack 3.0.0 introduces an enhanced Cluster Management Utility, known as mgmt, designed to simplify day-to-day administrative operations and lifecycle management of HPC and GPU clusters. This utility is installed on the Controller Node and provides a unified command-line interface that interacts directly with the OCI API to perform both routine and advanced maintenance tasks.
The mgmt utility serves as the operational brain of the cluster, allowing administrators to efficiently manage, inspect, and modify the cluster without manually interacting with the OCI Console or Terraform state. The utility organizes functionality across several command groups, including:
- clusters
- configurations
- database
- fabrics
- login
- network
- nodes
- recommendations
- services
To explore the available commands, simply run:
mgmt –help
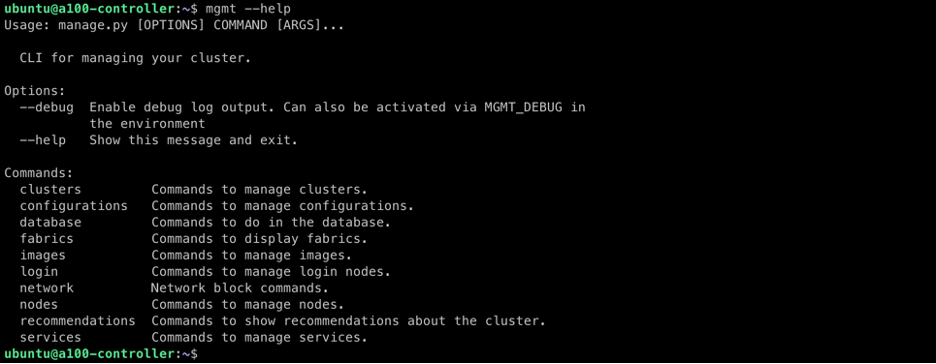
Each command category contains subcommands tailored for specific operational tasks. Syntax help for any category is easily accessible using:
mgmt <command> –help
Here are a few commonly used commands:
1. List nodes of a cluster
mgmt nodes list –cluster a100

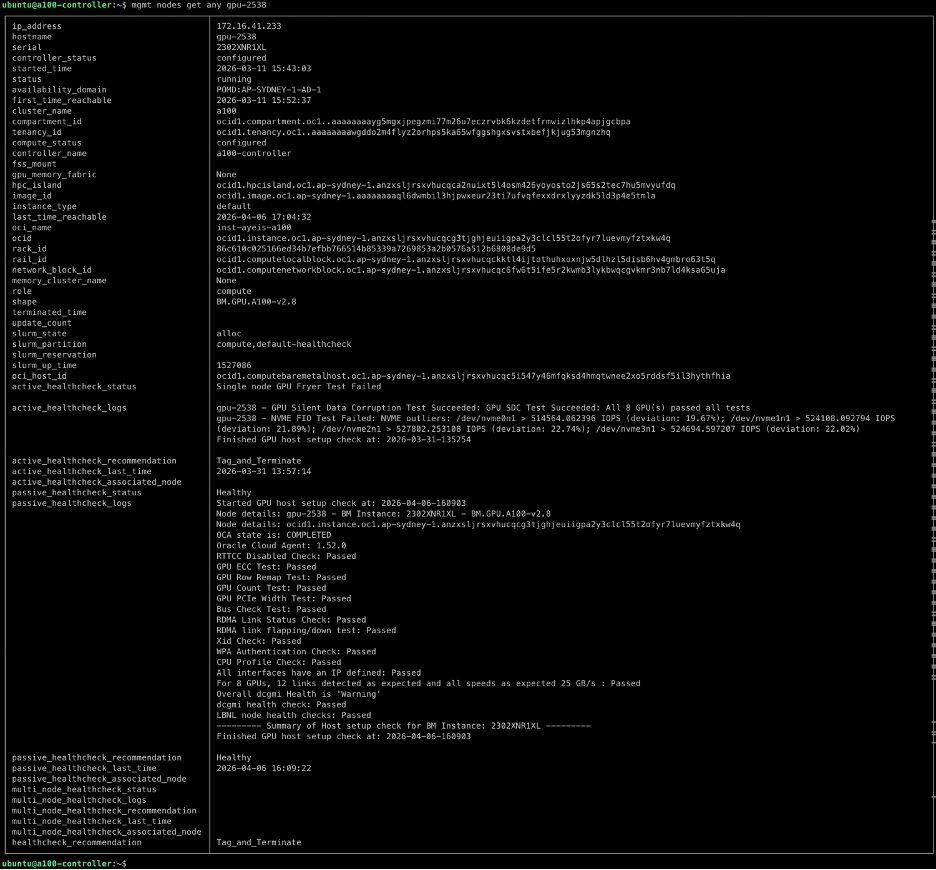
2. Query node information by serial, IP, OCID, or hostname
mgmt nodes get any gpu-2538
Cluster Health Automation
OCI HPC Cluster Stack 3.0.0 comes with enhanced GPU health monitoring features to ensure the optimal performance and reliability of NVIDIA and AMD GPUs. These health checks are facilitated by automated passive and active health checks that run autonomously as a part of a comprehensive monitoring solution.
Passive checks run periodically without occupying GPUs or impacting running workloads, and when the nodes are idle, active checks conduct GPU stress tests and use NVIDIA Collective Communication Library (NCCL) for NVIDIA GPUs and ROCm Communication Collectives Library (RCCL) for AMD GPUs to assess both single-node and multi-node communication performance, verifying the efficiency of data exchange across GPUs within an RDMA cluster.
Results of these health checks and additional monitoring data collected through NVIDIA DCGM Exporter and AMD SMI Exporter are then collated and visualized in pre-configured Grafana dashboards at your convenience. These dashboards provide insights at cluster, node, and GPU levels, facilitating proactive maintenance and optimization of the HPC environment. For further details check out our latest blog on monitoring GPU clusters: https://blogs.oracle.com/cloud-infrastructure/high-performance-gpu-fleet-visibility
Convenience Features
Several convenience features have been added to the stack to make administration of complex and large-scale GPU/HPC clusters more self-service and easier overall. In addition to some of the basic commands for listing details, health checking, and adding/removing nodes listed above, automations for advanced OCI tooling have been included in the mgmt toolset to further aid and automate system administration.
This includes:
- OCI image management
- Boot Volume Replacement
- Gathering Console History
- Ansible reconfigurations
- Multi-node command execution
- Automated Slurm configuration
- Tagging and Terminating Unhealthy nodes
Previously operations such as these would require some engineering uplift and scripting to be performed or would have to be done manually through the console. We have additionally wrapped these functions into a custom recommendation engine that communicates with our automated health checks to collate and perform all recommended tasks to nodes in your cluster at once.
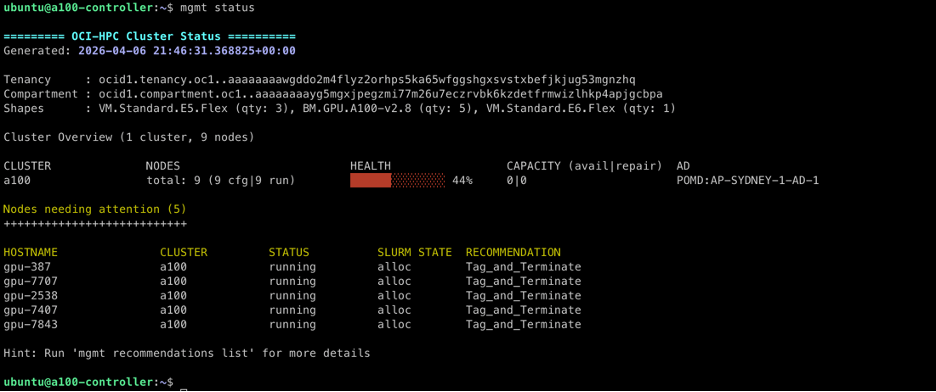
mgmt recommendations list

mgmt status
Conclusion
The release of OCI HPC Cluster Stack 3.0.0 marks a pivotal advancement in Oracle Cloud Infrastructure’s commitment to empowering customers with scalable, high-performance computing environments tailored for the demands of AI, scientific simulations, and beyond. By introducing modular node configurations, the intuitive mgmt utility for streamlined operations, robust GPU health monitoring, and a suite of convenience features, this update significantly reduces deployment complexity, enhances reliability, and accelerates time-to-insight for large-scale clusters. As OCI continues to innovate in HPC and GPU technologies, we invite you to explore this release and unlock new possibilities for your most ambitious computing challenges.


